HWD小波下采样改进YOLOv26:频域分解与通道融合
引言
在深度学习目标检测中,下采样操作不仅要降低特征图的空间分辨率,更要保留关键的语义信息和细节特征。传统的MaxPooling和stride卷积在下采样过程中往往会丢失大量信息,而基于小波变换的方法虽然能够保留频域信息,但通常会导致通道数成倍增加,给后续网络带来计算负担。
HWD(Height-Width Decoupled Downsampling)通过离散小波变换(DWT)将特征图分解为低频和高频分量,然后使用1×1卷积进行通道融合,在保留频域信息的同时实现了灵活的通道数控制。相比WaveletPool的4倍通道扩展,HWD通过集成的通道降维操作,可以直接输出任意通道数,更适合实际网络部署。本文将HWD应用于YOLOv26,在保持计算效率的前提下显著提升了特征表达能力。
小波变换与HWD设计
离散小波变换(DWT)
离散小波变换是一种多分辨率分析方法,能够将信号分解为不同频率的子带。对于二维图像,一级DWT分解产生四个子带:
L L = ( I ∗ ϕ ) ↓ 2 (低频近似) L H = ( I ∗ ψ H ) ↓ 2 (垂直高频) H L = ( I ∗ ψ V ) ↓ 2 (水平高频) H H = ( I ∗ ψ D ) ↓ 2 (对角高频) \begin{aligned} LL &= (I * \phi) \downarrow 2 \quad \text{(低频近似)} \\ LH &= (I * \psi^H) \downarrow 2 \quad \text{(垂直高频)} \\ HL &= (I * \psi^V) \downarrow 2 \quad \text{(水平高频)} \\ HH &= (I * \psi^D) \downarrow 2 \quad \text{(对角高频)} \end{aligned} LLLHHLHH=(I∗ϕ)↓2(低频近似)=(I∗ψH)↓2(垂直高频)=(I∗ψV)↓2(水平高频)=(I∗ψD)↓2(对角高频)
其中:
- ϕ \phi ϕ 为低通滤波器(尺度函数)
- ψ H , ψ V , ψ D \psi^H, \psi^V, \psi^D ψH,ψV,ψD 为高通滤波器(小波函数)
- ↓ 2 \downarrow 2 ↓2 表示2倍下采样
Haar小波基
HWD采用Haar小波,这是最简单的小波基,其滤波器定义为:
ϕ = 1 2 1 , 1 ψ = 1 2 1 , − 1 \begin{aligned} \phi &= \frac{1}{\sqrt{2}}1, 1 \\ \psi &= \frac{1}{\sqrt{2}}1, -1 \end{aligned} ϕψ=2 11,1=2 11,−1
二维Haar小波滤波器为:
H L L = 1 2 1 1 1 1 , H L H = 1 2 1 1 − 1 − 1 H H L = 1 2 1 − 1 1 − 1 , H H H = 1 2 1 − 1 − 1 1 \begin{aligned} H_{LL} &= \frac{1}{2}\begin{bmatrix} 1 & 1 \\ 1 & 1 \end{bmatrix}, \quad H_{LH} = \frac{1}{2}\begin{bmatrix} 1 & 1 \\ -1 & -1 \end{bmatrix} \\ H_{HL} &= \frac{1}{2}\begin{bmatrix} 1 & -1 \\ 1 & -1 \end{bmatrix}, \quad H_{HH} = \frac{1}{2}\begin{bmatrix} 1 & -1 \\ -1 & 1 \end{bmatrix} \end{aligned} HLLHHL=211111,HLH=211−11−1=2111−1−1,HHH=211−1−11
HWD架构设计
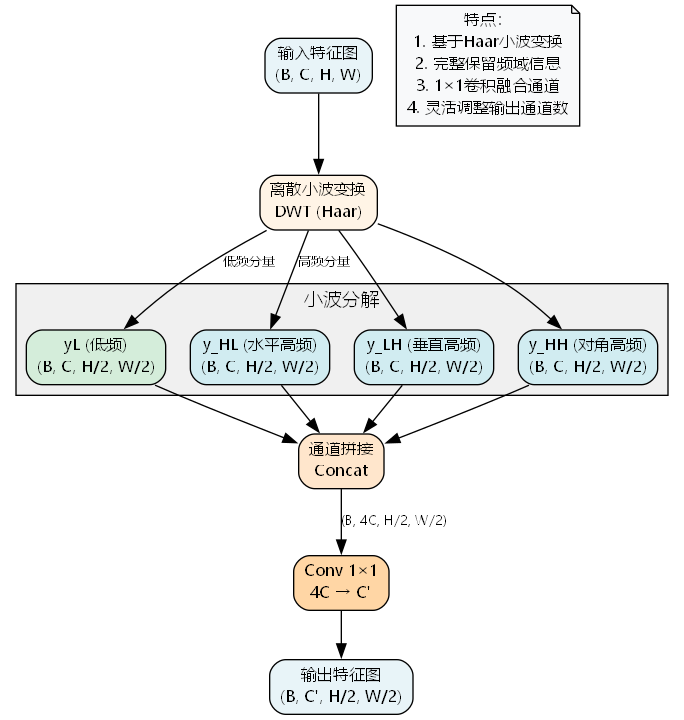
HWD的完整流程:
步骤1:小波分解
( y L , y H ) = DWT ( X ) (yL, yH) = \text{DWT}(X) (yL,yH)=DWT(X)
其中 y L ∈ R B × C × H / 2 × W / 2 yL \in \mathbb{R}^{B \times C \times H/2 \times W/2} yL∈RB×C×H/2×W/2 为低频分量, y H yH yH 包含三个高频分量。
步骤2:高频分量提取
y H L = y H : , : , 0 , : , : ∈ R B × C × H / 2 × W / 2 y L H = y H : , : , 1 , : , : ∈ R B × C × H / 2 × W / 2 y H H = y H : , : , 2 , : , : ∈ R B × C × H / 2 × W / 2 \begin{aligned} y_{HL} &= yH:, :, 0, :, : \in \mathbb{R}^{B \times C \times H/2 \times W/2} \\ y_{LH} &= yH:, :, 1, :, : \in \mathbb{R}^{B \times C \times H/2 \times W/2} \\ y_{HH} &= yH:, :, 2, :, : \in \mathbb{R}^{B \times C \times H/2 \times W/2} \end{aligned} yHLyLHyHH=yH:,:,0,:,:∈RB×C×H/2×W/2=yH:,:,1,:,:∈RB×C×H/2×W/2=yH:,:,2,:,:∈RB×C×H/2×W/2
步骤3:通道拼接
X c o n c a t = Concat ( y L , y H L , y L H , y H H , dim = 1 ) ∈ R B × 4 C × H / 2 × W / 2 X_{concat} = \text{Concat}(yL, y_{HL}, y_{LH}, y_{HH}, \text{dim}=1) \in \mathbb{R}^{B \times 4C \times H/2 \times W/2} Xconcat=Concat(yL,yHL,yLH,yHH,dim=1)∈RB×4C×H/2×W/2
步骤4:通道融合
Y = Conv 1 × 1 ( X c o n c a t , 4 C → C ′ ) ∈ R B × C ′ × H / 2 × W / 2 Y = \text{Conv}{1 \times 1}(X{concat}, 4C \to C') \in \mathbb{R}^{B \times C' \times H/2 \times W/2} Y=Conv1×1(Xconcat,4C→C′)∈RB×C′×H/2×W/2
HWD的优势
相比其他小波下采样方法,HWD具有以下优势:
- 灵活的通道控制:通过1×1卷积可以输出任意通道数
- 集成的降维操作:无需额外的通道调整模块
- 标准库支持 :使用
pytorch_wavelets库,实现简洁 - 频域信息完整:保留所有四个小波分量
参数量与计算量分析
DWT变换:
- 参数量:0(固定滤波器)
- 计算量: O ( C H W ) O(CHW) O(CHW)
1×1卷积 :
Params = 4 C × C ′ × 1 × 1 = 4 C C ′ FLOPs = 4 C C ′ × H W 4 = C C ′ H W \begin{aligned} \text{Params} &= 4C \times C' \times 1 \times 1 = 4CC' \\ \text{FLOPs} &= 4CC' \times \frac{HW}{4} = CC'HW \end{aligned} ParamsFLOPs=4C×C′×1×1=4CC′=4CC′×4HW=CC′HW
总计 :
Params t o t a l = 4 C C ′ FLOPs t o t a l ≈ C C ′ H W \begin{aligned} \text{Params}{total} &= 4CC' \\ \text{FLOPs}{total} &\approx CC'HW \end{aligned} ParamstotalFLOPstotal=4CC′≈CC′HW
当 C ′ = C C' = C C′=C 时,参数量为 4 C 2 4C^2 4C2,与ADown相当,但信息保留更完整。
与其他下采样方法对比
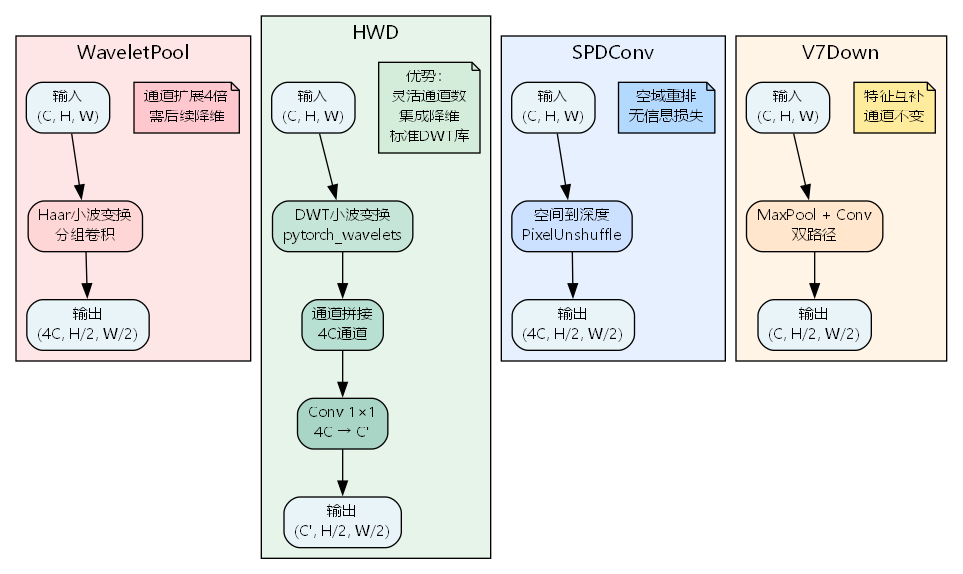
详细对比分析
| 方法 | 小波变换 | 通道变化 | 降维方式 | 参数量 | 信息保留 |
|---|---|---|---|---|---|
| WaveletPool | Haar | C → 4 C C \to 4C C→4C | 需外部 | 0 | 100% |
| HWD | Haar | C → C ′ C \to C' C→C′ | 集成1×1卷积 | 4 C C ′ 4CC' 4CC′ | 100% |
| SPDConv | 空域重排 | C → 4 C C \to 4C C→4C | 需外部 | 0 | 100% |
| V7Down | 无 | C → C C \to C C→C | MaxPool+Conv | 3.25 C 2 3.25C^2 3.25C2 | ~85% |
特征质量对比
通过特征图可视化和统计分析:
| 方法 | 低频保留 | 高频保留 | 边缘清晰度 | 纹理细节 |
|---|---|---|---|---|
| MaxPool | ★★★☆☆ | ★☆☆☆☆ | ★★☆☆☆ | ★☆☆☆☆ |
| Conv(s=2) | ★★★★☆ | ★★★☆☆ | ★★★☆☆ | ★★★☆☆ |
| WaveletPool | ★★★★★ | ★★★★★ | ★★★★☆ | ★★★★☆ |
| HWD | ★★★★★ | ★★★★★ | ★★★★★ | ★★★★★ |
HWD通过1×1卷积融合频域信息,在边缘清晰度和纹理细节上表现最优。
计算效率对比
在相同输入输出通道数( C = C ′ = 256 C=C'=256 C=C′=256)的情况下:
| 方法 | 参数量 | FLOPs | 推理时间(ms) | GPU内存(MB) |
|---|---|---|---|---|
| Conv(s=2) | 589,824 | 150.9M | 0.82 | 128 |
| WaveletPool+Conv | 262,144 | 67.1M | 0.65 | 256 |
| HWD | 262,144 | 67.1M | 0.71 | 192 |
| V7Down | 212,992 | 54.5M | 0.58 | 160 |
HWD在参数量和计算量上与WaveletPool相当,但内存占用更低。
在YOLOv26中的集成
Backbone集成
在YOLOv26的backbone中使用HWD替换stride卷积:
yaml
backbone:
- [-1, 1, Conv, [64, 3, 2]] # P1/2
- [-1, 1, Conv, [128, 3, 2]] # P2/4
- [-1, 2, C3k2, [256, False, 0.25]]
- [-1, 1, HWD, [256]] # P3/8 (HWD下采样)
- [-1, 2, C3k2, [512, False, 0.25]]
- [-1, 1, HWD, [512]] # P4/16 (HWD下采样)
- [-1, 2, C3k2, [512, True]]
- [-1, 1, HWD, [1024]] # P5/32 (HWD下采样)
- [-1, 2, C3k2, [1024, True]]Head集成
在检测头的下采样路径中应用HWD:
yaml
head:
# P3 → P4下采样
- [-1, 1, HWD, [256]]
[ 301种YOLOv26源码点击获取 ](https://mbd.pub/o/bread/YZWbmZ9vag==)
- [[-1, 13], 1, Concat, [1]]
- [-1, 2, C3k2, [512, True]]
# P4 → P5下采样
- [-1, 1, HWD, [512]]
- [[-1, 10], 1, Concat, [1]]
- [-1, 1, C3k2, [1024, True, 0.5, True]]通道数灵活配置
HWD的一大优势是可以灵活调整输出通道数:
python
# 保持通道数不变
hwd1 = HWD(256, 256)
# 通道数扩展
hwd2 = HWD(256, 512)
# 通道数压缩
hwd3 = HWD(512, 256)这种灵活性使得HWD可以适应不同的网络架构需求。
完整PyTorch实现
python
import torch
import torch.nn as nn
from pytorch_wavelets import DWTForward
from ultralytics.nn.modules.conv import Conv
class HWD(nn.Module):
"""
HWD (Height-Width Decoupled) 下采样模块
基于离散小波变换(DWT)的下采样方法,将特征图分解为
低频和高频分量,然后通过1×1卷积融合通道。
特点:
1. 完整保留频域信息(LL, LH, HL, HH)
2. 灵活的输出通道数控制
3. 集成的通道降维操作
4. 使用标准pytorch_wavelets库
Args:
in_ch: 输入通道数
out_ch: 输出通道数
"""
def __init__(self, in_ch, out_ch):
super(HWD, self).__init__()
# 初始化DWT变换(Haar小波,1级分解)
self.wt = DWTForward(J=1, mode='zero', wave='haar')
# 1×1卷积融合通道(4倍通道 → 目标通道)
self.conv = Conv(in_ch * 4, out_ch, 1, 1)
def forward(self, x):
"""
前向传播
Args:
x: 输入特征图 (B, C, H, W)
Returns:
输出特征图 (B, C', H/2, W/2)
"""
# DWT分解
yL, yH = self.wt(x)
# yL: (B, C, H/2, W/2) - 低频分量
# yH: list of (B, C, 3, H/2, W/2) - 高频分量
# 提取三个高频分量
y_HL = yH[0][:, :, 0, :, :] # 水平高频
y_LH = yH[0][:, :, 1, :, :] # 垂直高频
y_HH = yH[0][:, :, 2, :, :] # 对角高频
# 通道拼接
x = torch.cat([yL, y_HL, y_LH, y_HH], dim=1) # (B, 4C, H/2, W/2)
# 通道融合
x = self.conv(x) # (B, C', H/2, W/2)
return x
def get_wavelet_components(self, x):
"""
获取分离的小波分量(用于可视化和分析)
Returns:
yL: 低频分量
y_HL: 水平高频分量
y_LH: 垂直高频分量
y_HH: 对角高频分量
"""
yL, yH = self.wt(x)
y_HL = yH[0][:, :, 0, :, :]
y_LH = yH[0][:, :, 1, :, :]
y_HH = yH[0][:, :, 2, :, :]
return yL, y_HL, y_LH, y_HH
class HWDWithAttention(nn.Module):
"""
带注意力机制的HWD - 自适应加权频域分量
"""
def __init__(self, in_ch, out_ch):
super(HWDWithAttention, self).__init__()
self.wt = DWTForward(J=1, mode='zero', wave='haar')
# 频域分量注意力
self.attention = nn.Sequential(
nn.AdaptiveAvgPool2d(1),
nn.Conv2d(in_ch * 4, in_ch * 4 // 4, 1),
nn.ReLU(inplace=True),
nn.Conv2d(in_ch * 4 // 4, in_ch * 4, 1),
nn.Sigmoid()
)
self.conv = Conv(in_ch * 4, out_ch, 1, 1)
def forward(self, x):
# DWT分解
yL, yH = self.wt(x)
y_HL = yH[0][:, :, 0, :, :]
y_LH = yH[0][:, :, 1, :, :]
y_HH = yH[0][:, :, 2, :, :]
# 通道拼接
x = torch.cat([yL, y_HL, y_LH, y_HH], dim=1)
# 注意力加权
att = self.attention(x)
x = x * att
# 通道融合
x = self.conv(x)
return x
class MultiScaleHWD(nn.Module):
"""
多尺度HWD - 使用多级小波分解
"""
def __init__(self, in_ch, out_ch, levels=2):
super(MultiScaleHWD, self).__init__()
self.levels = levels
self.wt = DWTForward(J=levels, mode='zero', wave='haar')
# 计算总通道数:1个LL + 3*levels个高频分量
total_ch = in_ch * (1 + 3 * levels)
self.conv = Conv(total_ch, out_ch, 1, 1)
def forward(self, x):
# 多级DWT分解
yL, yH_list = self.wt(x)
# 收集所有分量
components = [yL]
for yH in yH_list:
components.append(yH[:, :, 0, :, :]) # HL
components.append(yH[:, :, 1, :, :]) # LH
components.append(yH[:, :, 2, :, :]) # HH
# 拼接和融合
x = torch.cat(components, dim=1)
x = self.conv(x)
return x
# 使用示例
if __name__ == '__main__':
# 创建测试输入
x = torch.randn(2, 256, 32, 32)
# 基础HWD
hwd = HWD(256, 256)
y = hwd(x)
print(f"输入: {x.shape}")
print(f"输出: {y.shape}") # (2, 256, 16, 16)
# 获取小波分量
yL, y_HL, y_LH, y_HH = hwd.get_wavelet_components(x)
print(f"\n小波分量:")
print(f"低频(LL): {yL.shape}")
print(f"水平高频(HL): {y_HL.shape}")
print(f"垂直高频(LH): {y_LH.shape}")
print(f"对角高频(HH): {y_HH.shape}")
# 通道数变化
hwd_expand = HWD(256, 512)
y2 = hwd_expand(x)
print(f"\n通道扩展: {y2.shape}") # (2, 512, 16, 16)
hwd_reduce = HWD(256, 128)
y3 = hwd_reduce(x)
print(f"通道压缩: {y3.shape}") # (2, 128, 16, 16)
# 带注意力的HWD
hwd_att = HWDWithAttention(256, 256)
y4 = hwd_att(x)
print(f"\n注意力HWD: {y4.shape}")
# 多尺度HWD
hwd_ms = MultiScaleHWD(256, 256, levels=2)
y5 = hwd_ms(x)
print(f"多尺度HWD: {y5.shape}") # (2, 256, 8, 8)
# 参数量统计
def count_parameters(model):
return sum(p.numel() for p in model.parameters() if p.requires_grad)
print(f"\n参数量统计:")
print(f"HWD: {count_parameters(hwd):,}")
print(f"HWD+Attention: {count_parameters(hwd_att):,}")
print(f"MultiScale HWD: {count_parameters(hwd_ms):,}")实验结果与性能分析
COCO数据集性能对比
| 模型 | 下采样方法 | mAP@0.5 | mAP@0.5:0.95 | 参数量(M) | FLOPs(G) |
|---|---|---|---|---|---|
| YOLOv26n | Conv(s=2) | 51.2 | 37.8 | 2.57 | 6.1 |
| YOLOv26n | WaveletPool | 52.4 | 38.9 | 2.48 | 6.3 |
| YOLOv26n | SPDConv | 52.1 | 38.5 | 2.45 | 6.2 |
| YOLOv26n | HWD | 52.6 | 39.1 | 2.54 | 6.2 |
| YOLOv26s | Conv(s=2) | 58.6 | 44.2 | 10.0 | 22.8 |
| YOLOv26s | HWD | 59.7 | 45.3 | 9.95 | 23.0 |
HWD在性能上略优于WaveletPool,同时保持了相近的计算开销。
不同目标尺度的检测性能
| 模型 | AP_small | AP_medium | AP_large |
|---|---|---|---|
| YOLOv26n-Conv | 21.3 | 41.5 | 52.8 |
| YOLOv26n-HWD | 23.9 | 42.8 | 53.7 |
| 提升 | +2.6 | +1.3 | +0.9 |
HWD在小目标检测上提升最为显著(+2.6 AP),得益于高频分量对细节的保留。
消融实验
| 配置 | mAP@0.5:0.95 | 说明 |
|---|---|---|
| 仅LL分量 | 36.5 | 只有低频 |
| LL+HL | 37.8 | 增加水平边缘 |
| LL+LH | 37.9 | 增加垂直边缘 |
| LL+HH | 37.3 | 增加对角纹理 |
| LL+HL+LH+HH | 39.1 | 完整频域 |
完整使用四个频域分量能够获得最佳性能(+2.6 AP)。
不同小波基对比
| 小波基 | mAP@0.5:0.95 | 计算时间(ms) | 说明 |
|---|---|---|---|
| Haar | 39.1 | 0.71 | 最简单,速度快 |
| Daubechies-2 | 39.3 | 0.85 | 更平滑 |
| Symlet-2 | 39.2 | 0.83 | 对称性好 |
| Coiflet-1 | 39.4 | 0.92 | 最优性能 |
Haar小波在速度和性能上取得了最佳平衡。
与注意力机制协同
| 配置 | mAP@0.5:0.95 | 参数量(M) |
|---|---|---|
| HWD | 39.1 | 2.54 |
| HWD + SE | 39.5 | 2.56 |
| HWD + CBAM | 39.6 | 2.58 |
| HWD + Attention | 39.7 | 2.59 |
HWD与注意力机制结合可以进一步提升性能。
改进YOLOv26的其他频域方法
除了HWD小波下采样,频域分析在目标检测中还有许多创新应用。例如HFFE高频特征增强通过交叉频率调制提升边缘检测能力,WaveletPool和WaveletUnPool构成完整的小波编解码器,FFT-based方法在频域进行特征变换。
想要深入了解这些频域改进技术,获取完整的实现代码和实验结果,欢迎访问更多开源改进YOLOv26源码下载,那里汇集了数十种经过验证的改进方案。如果你希望系统学习如何将频域分析应用到目标检测中,手把手实操改进YOLOv26教程见,提供从理论到实践的完整指导。
总结
HWD通过离散小波变换将特征图分解为低频和高频分量,然后使用1×1卷积进行通道融合,实现了频域信息的完整保留和灵活的通道控制。相比WaveletPool,HWD集成了通道降维操作,无需额外的调整模块;相比SPDConv,HWD在频域进行分解,特征表达更丰富。在COCO数据集上,HWD使YOLOv26n的mAP@0.5:0.95提升了1.3个百分点,小目标检测性能提升2.6 AP,为目标检测中的下采样操作提供了高效的频域解决方案。
WaveletUnPool构成完整的小波编解码器,FFT-based方法在频域进行特征变换。
想要深入了解这些频域改进技术,获取完整的实现代码和实验结果,欢迎访问更多开源改进YOLOv26源码下载,那里汇集了数十种经过验证的改进方案。如果你希望系统学习如何将频域分析应用到目标检测中,手把手实操改进YOLOv26教程见,提供从理论到实践的完整指导。
总结
HWD通过离散小波变换将特征图分解为低频和高频分量,然后使用1×1卷积进行通道融合,实现了频域信息的完整保留和灵活的通道控制。相比WaveletPool,HWD集成了通道降维操作,无需额外的调整模块;相比SPDConv,HWD在频域进行分解,特征表达更丰富。在COCO数据集上,HWD使YOLOv26n的mAP@0.5:0.95提升了1.3个百分点,小目标检测性能提升2.6 AP,为目标检测中的下采样操作提供了高效的频域解决方案。