医疗影像往往对比度低,微小病灶很容易与背景融为一体。经典的 YOLO 架构(如采用 PAFPN)在提取这类特征时容易丢失细节。而近期火热的 Mamba 虽然擅长长序列建模,但缺乏局部结构感知,且通常需要海量数据预训练。这篇发表于BIBM2025的工作:MedMamba-YOLO: A Vision State Space Model for Medical Image Detection ,基于 YOLOv8 进行重构,提出了 MedMamba-YOLO ,在没有任何预训练(Training from scratch)的情况下,仅用 3.8M 参数就在医疗数据集上取得了优异的成绩。本文将深入模型的底层,为你拆解该模型架构中的四大核心模块:CPIB、MSF-FPN、SAVSSB、HMDA,并将作者开源代码中与模型相关的重点提取出来,方便大家在自己的研究中直接复用。
一、 骨干网络特征增强:CPIB (Cross Path Interaction Block)
在医疗图像中,为了从复杂的背景中提取出微弱的病灶特征,网络需要极强的特征辨识能力 。标准的C2f模块采用直接分流与拼接的策略,在信息传递时缺乏分支间的交互。作者设计了CPIB模块来替代C2f。
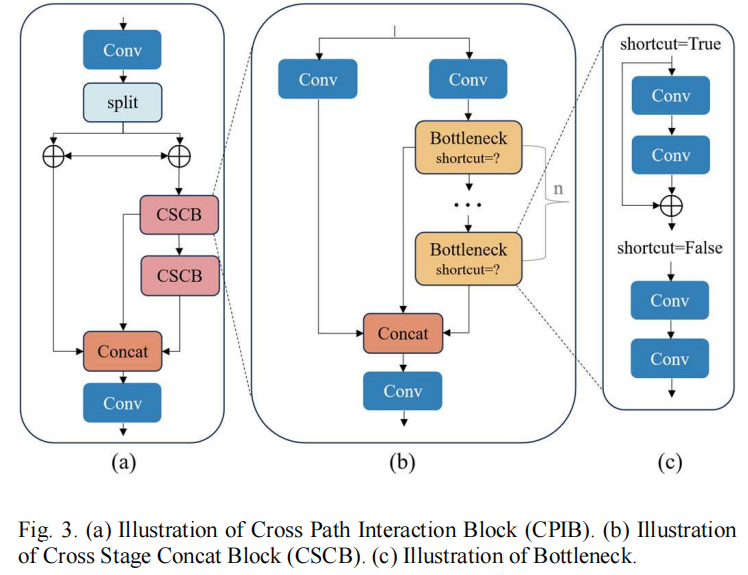
CPIB的工作机制如下:
通道切分与交叉交互 :输入特征经过 1×11 \times 11×1 卷积降维后,在通道维度被均分为两半(对应代码中的 y[0] 和 y[1])。随后强制执行双向信息流交互:分支0加上分支1的特征,分支1也加上分支0的特征。
残差堆叠:交互后的分支1被送入连续的CSCB(包含多个残差Bottleneck)模块进行深层特征提取 。
特征聚合 :最后将所有分支在通道维度拼接,通过 1×11 \times 11×1 卷积输出 。这种设计使得网络在早期就能实现特征互补。
CPIB代码如下:
python
import torch
import torch.nn as nn
def autopad(k, p=None, d=1):
if d > 1:
k = d * (k - 1) + 1 if isinstance(k, int) else [d * (x - 1) + 1 for x in k]
if p is None:
p = k // 2 if isinstance(k, int) else [x // 2 for x in k]
return p
class Conv(nn.Module):
default_act = nn.SiLU()
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, d=1, act=True):
super().__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p, d), groups=g, dilation=d, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()
def forward(self, x):
return self.act(self.bn(self.conv(x)))
class Bottleneck(nn.Module):
def __init__(self, c1, c2, shortcut=True, g=1, k=(3, 3), e=0.5):
super().__init__()
c_ = int(c2 * e)
self.cv1 = Conv(c1, c_, k[0], 1)
self.cv2 = Conv(c_, c2, k[1], 1, g=g)
self.add = shortcut and c1 == c2
def forward(self, x):
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
class CSCB(nn.Module):
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5):
super().__init__()
c_ = int(c2 * e)
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv((2+n) * c_, c2, 1)
self.m = nn.ModuleList(Bottleneck(c_, c_, shortcut, g, k=((3, 3), (3, 3)), e=1.0) for _ in range(n))
def forward(self, x):
y = [self.cv1(x), self.cv2(x)]
y.extend(m(y[-1]) for m in self.m)
return self.cv3(torch.cat(y, 1))
class CPIB(nn.Module):
def __init__(self, c1, c2, shortcut=False, g=1, e=0.5, c5=1):
super().__init__()
self.c = int(c2 * e)
self.cv1 = Conv(c1, 2 * self.c, 1, 1)
self.cv4 = Conv(3 * self.c, c2, 1)
self.cv2 = CSCB(self.c, self.c, c5, shortcut)
self.cv3 = CSCB(self.c, self.c, c5, shortcut)
def forward(self, x):
y = list(self.cv1(x).chunk(2, 1))
# 核心:双向信息交互
temp = y[0]
y[0] = y[0] + y[1]
y[1] = y[1] + temp
y[1] = self.cv2(y[1])
y.append(self.cv3(y[1]))
return self.cv4(torch.cat(y, 1))二、 颈部网络重构:MSF-FPN (多尺度融合特征金字塔)
由于医疗影像中目标的尺度跨度通常极大(如微小的血小板与占据大半个视野的肿瘤),传统的串行FPN在逐层传递信息时易造成深层语义与浅层空间特征的衰减。
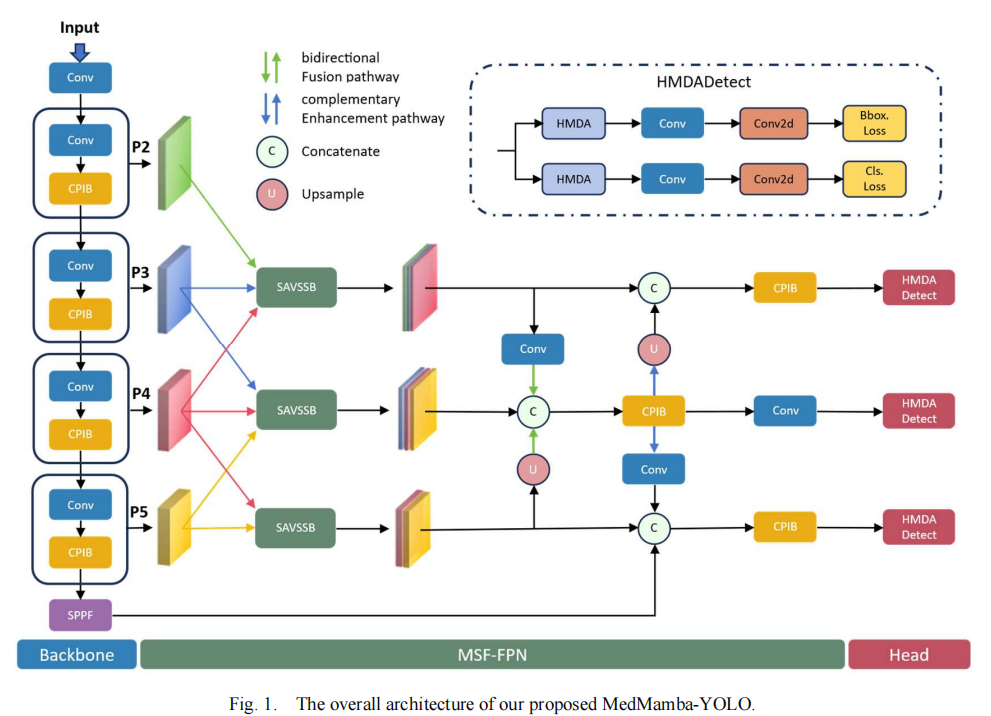
其工作机制是:
多尺度并行输入:与常规的只接受单一前驱节点不同,MSF-FPN的融合节点同时拉取骨干网络的P3、P4、P5层特征。
特征对齐融合 (FAF):在接收到多尺度特征后,通过最近邻插值(Nearest-neighbor interpolation)将不同分辨率的特征图对齐到中间尺度,并在通道维度进行拼接 。
互补增强路径:设计了双向的融合路径,在深浅层语义之间建立直接的跳跃连接,以确保结构一致性 。
可以从MedMamba-YOLO.yaml中看到这一配置:
python
head:
- [[2, 4, 6], 1, SAVSSB, [256, 896]] # 10
- [[4, 6, 8], 1, SAVSSB, [512, 1792]] # 11
- [[6, 8], 1, SAVSSB, [1024, 1536]] # 12
# ...后续拼接与上采样逻辑注意看 head 部分的前三行,[2, 4, 6] 表示同时拉取第2、4、6层的特征输入至SAVSSB模块。
三、 空间与状态空间的融合:SAVSSB与GDSA
SAVSSB(Spatial-Aware Visual State Space Block)是MSF-FPN的核心处理单元。Mamba模型(SSM)具有线性的时间复杂度并擅长全局长序列建模,但其将2D图像展平为1D序列的处理方式,会导致局部2D空间结构感知能力下降 。
SAVSSB通过内部的 GDSA (分组空洞空间注意力) 弥补了这一缺陷 。
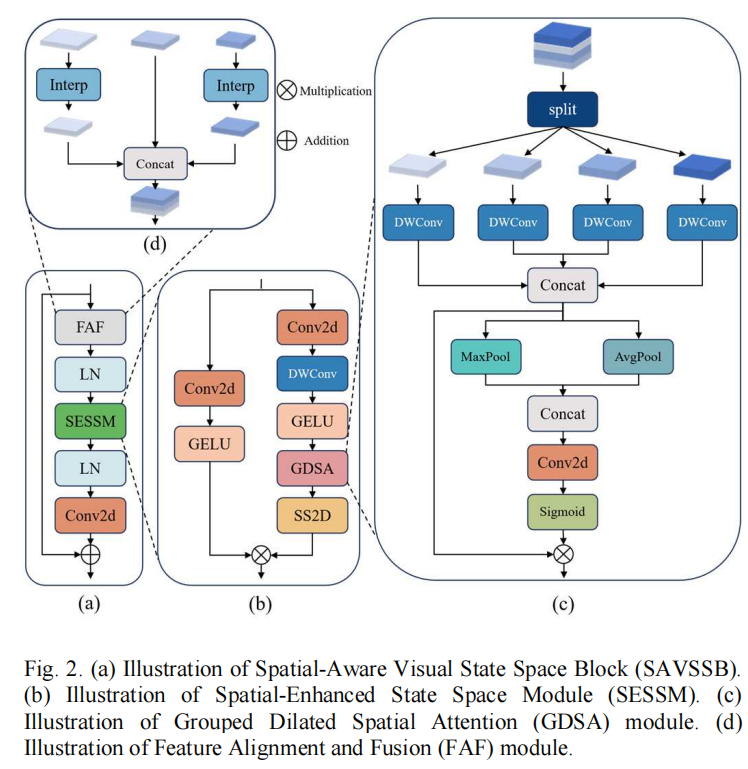
其工作机制是:
GDSA分组空洞卷积:在将特征送入Mamba之前,GDSA将特征沿通道分为4组。分别应用空洞率(Dilation)为1、2、3、4的深度可分离卷积 。这使得网络同时具备了4种不同大小的感受野。随后通过全局最大池化和平均池化生成空间注意力权重,突出显著特征。
SESSM状态空间建模:利用门控机制(GELU分支)与Mamba的核心选择性扫描算子(SS2D)结合。GDSA处理后的特征送入SS2D进行全局依赖提取,最后两分支相乘输出 。
GDSA.py 与 SAVSSB.py 的精简核心类如下:
python
# ============ GDSA.py ============
import torch
import torch.nn as nn
class GDSA(nn.Module):
"""Grouped Dilated Spatial Attention module."""
def __init__(self, channel, kernel_size=3):
super().__init__()
assert kernel_size in (3, 7), "kernel size must be 3 or 7"
padding = 3 if kernel_size == 7 else 1
self.a = int(channel / 4)
self.dilation = [1, 2, 3, 4]
# 4组不同空洞率的卷积
self.cv2 = nn.Conv2d(self.a, self.a, kernel_size, padding=self.dilation[0]*(kernel_size-1)//2, bias=False, dilation=self.dilation[0], groups=self.a)
self.cv3 = nn.Conv2d(self.a, self.a, kernel_size, padding=self.dilation[1]*(kernel_size-1)//2, bias=False, dilation=self.dilation[1], groups=self.a)
self.cv4 = nn.Conv2d(self.a, self.a, kernel_size, padding=self.dilation[2]*(kernel_size-1)//2, bias=False, dilation=self.dilation[2], groups=self.a)
self.cv5 = nn.Conv2d(self.a, self.a, kernel_size, padding=self.dilation[3]*(kernel_size-1)//2, bias=False, dilation=self.dilation[3], groups=self.a)
self.cv1 = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)
self.act = nn.Sigmoid()
def forward(self, x):
y = list(x.chunk(4, 1))
y[0] = self.cv2(y[0])
y[1] = self.cv3(y[1])
y[2] = self.cv4(y[2])
y[3] = self.cv5(y[3])
y = torch.cat(y, 1)
# 生成注意力掩码并加权
return y * self.act(self.cv1(torch.cat([torch.mean(y, 1, keepdim=True), torch.max(y, 1, keepdim=True)[0]], 1)))
# ============ SAVSSB.py (SESSM 核心逻辑) ============
class SESSM(nn.Module):
def __init__(self, d_model=96, dim=150, d_state=16, ssm_ratio=1.0, d_conv=3, **kwargs):
super().__init__()
d_expand = int(ssm_ratio * d_model)
self.in_proj = nn.Conv2d(dim, d_expand * 2, kernel_size=1)
self.act = nn.GELU()
self.GDSA = GDSA(d_expand)
# 此处省略底层 SS2D 算子初始化...
def forward(self, x: torch.Tensor, **kwargs):
x = self.in_proj(x)
x, z = x.chunk(2, dim=1) # 门控分支分离
z1 = self.act(z)
# 经过 GDSA 增强局部空间感知
x = self.GDSA(self.act(x))
# 进入 Mamba 的 2D 选择性扫描引擎
y = self.forward_core(x, channel_first=True)
y = y.permute(0, 3, 1, 2).contiguous()
# 门控相乘
y = y * z1
return self.dropout(self.out_proj(self.norm_1(y)))四、异构自适应检测头:HMDA (Heterogeneous Multi-scale Dilated Attention)
YOLOv8的原生检测头在所有尺度分支上均采用相同的结构。而HMDADetect的核心思想是:不同尺度的特征需要不同大小的感受野 。
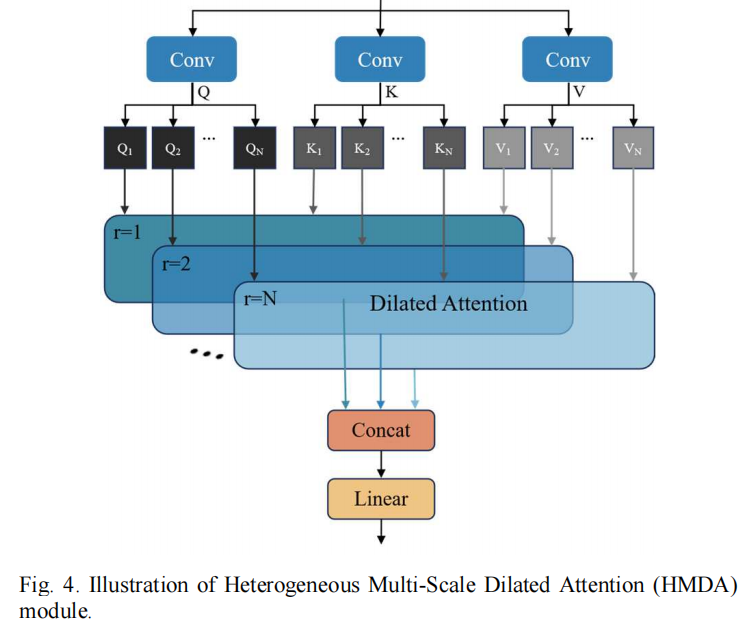
工作机制是:
异构空洞配置:
- 浅层特征图(负责检测小目标):配置较小的空洞率组合
[1, 2],以聚焦局部边界细节 。 - 深层特征图(负责检测大目标):配置较大的空洞率组合
[1, 2, 3, 4],以获取覆盖整个目标的宽广视野 。
多分支注意力计算 :输入特征被分割为多份,各自在指定的空洞率下通过局部滑动窗口(代码中使用 Unfold 实现)提取特征,进行点积注意力计算,最后再进行融合 。
HMDADetect.py 核心部分代码如下:
python
import torch
import torch.nn as nn
class DilateAttention(nn.Module):
def __init__(self, head_dim, qk_scale=None, attn_drop=0, kernel_size=3, dilation=1):
super().__init__()
self.head_dim = head_dim
self.scale = qk_scale or head_dim ** -0.5
self.kernel_size = kernel_size
# 利用 Unfold 实现空洞局部窗口
self.unfold = nn.Unfold(kernel_size, dilation, dilation * (kernel_size - 1) // 2, 1)
self.attn_drop = nn.Dropout(attn_drop)
def forward(self, q, k, v):
B, d, H, W = q.shape
q = q.reshape([B, d // self.head_dim, self.head_dim, 1, H * W]).permute(0, 1, 4, 3, 2)
k = self.unfold(k).reshape([B, d // self.head_dim, self.head_dim, self.kernel_size * self.kernel_size, H * W]).permute(0, 1, 4, 2, 3)
attn = (q @ k) * self.scale
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
v = self.unfold(v).reshape([B, d // self.head_dim, self.head_dim, self.kernel_size * self.kernel_size, H * W]).permute(0, 1, 4, 3, 2)
x = (attn @ v).transpose(1, 2).reshape(B, H, W, d)
return x
class MultiDilatelocalAttention(nn.Module):
def __init__(self, dim, n, num_heads=8, qkv_bias=True, qk_scale=None, attn_drop=0., proj_drop=0., kernel_size=3):
super().__init__()
self.dim = dim
self.num_heads = num_heads
head_dim = dim // num_heads
# 核心:根据层级 n 异构配置空洞率
if n == 0:
dilation = [1, 2]
elif n == 1 or n == 2:
dilation = [1, 2, 3, 4]
self.dilation = dilation
self.kernel_size = kernel_size
self.scale = qk_scale or head_dim ** -0.5
self.num_dilation = len(dilation)
self.qkv = nn.Conv2d(dim, dim * 3, 1, bias=qkv_bias)
self.dilate_attention = nn.ModuleList(
[DilateAttention(head_dim, qk_scale, attn_drop, kernel_size, dilation[i])
for i in range(self.num_dilation)])
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
def forward(self, x):
B, C, H, W = x.shape
y = x.clone()
qkv = self.qkv(x).reshape(B, 3, self.num_dilation, C // self.num_dilation, H, W).permute(2, 1, 0, 3, 4, 5)
y1 = y.reshape(B, self.num_dilation, C // self.num_dilation, H, W).permute(1, 0, 3, 4, 2)
for i in range(self.num_dilation):
y1[i] = self.dilate_attention[i](qkv[i][0], qkv[i][1], qkv[i][2])
y2 = y1.permute(1, 2, 3, 0, 4).reshape(B, H, W, C)
y3 = self.proj(y2)
return self.proj_drop(y3).permute(0, 3, 1, 2)
class HMDADetect(nn.Module):
# 检测头封装,集成 MultiDilatelocalAttention
def __init__(self, nc=80, ch=()):
super().__init__()
# ... 初始化逻辑 ...
self.cv2 = nn.ModuleList(
nn.Sequential(MultiDilatelocalAttention(x, i), Conv(x, c2, 3), nn.Conv2d(c2, 4 * self.reg_max, 1)) for i, x in enumerate(ch)
)
self.cv3 = nn.ModuleList(
nn.Sequential(MultiDilatelocalAttention(x, i), Conv(x, c3, 3), nn.Conv2d(c3, self.nc, 1)) for i, x in enumerate(ch)
)
# ... 前向传播与BBox解码逻辑 ...检测效果
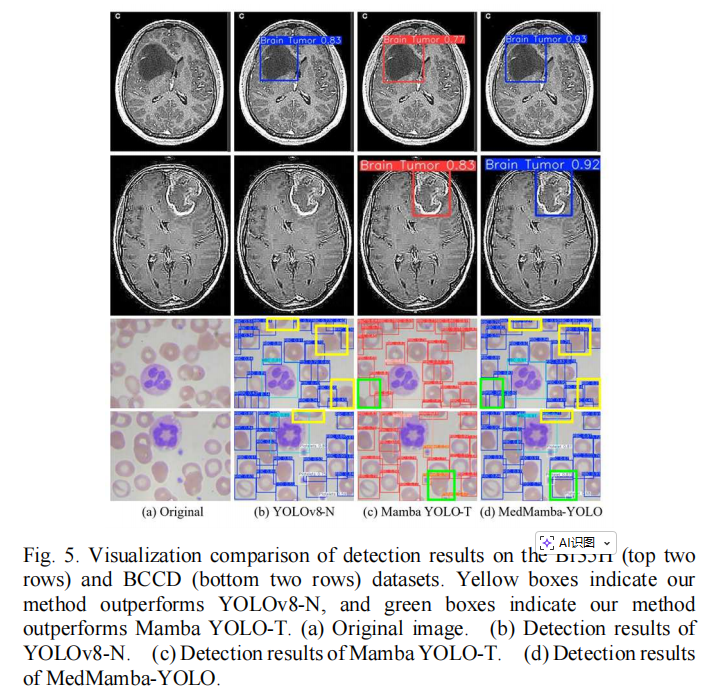
作者选取了两个极具代表性的小样本医疗数据集来测试模型:Br35H(脑肿瘤 MRI 数据集,训练集仅 500 张) 和 BCCD(血细胞显微数据集,训练集仅 205 张) 。实验结果主要从以下三个维度证明了 MedMamba-YOLO 的实力:
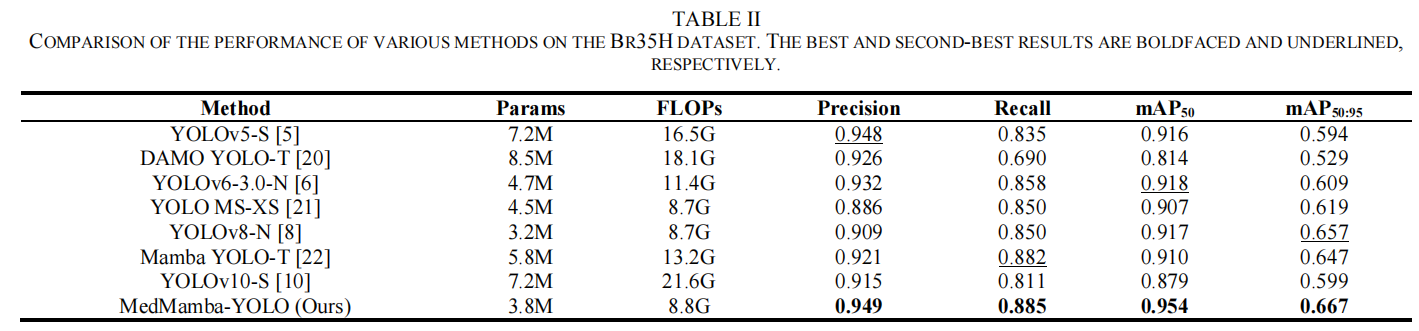
1. 轻量化与高精度(Br35H 脑肿瘤检测)
在 Br35H 数据集上,MedMamba-YOLO 展现出了惊人的参数利用率。
计算代价低 :模型的参数量仅为 3.8M ,计算量为 8.8 GFLOPs 。
精度好 :在完全没有使用任何预训练权重 (Training from scratch)的情况下 ,模型的 mAP50mAP_{50}mAP50 达到了 0.954 ,mAP50:95mAP_{50:95}mAP50:95 达到了 0.667 。
横向对比 :相比于近期同样基于 Mamba 架构的 Mamba YOLO-T(参数 5.8M,mAP50mAP_{50}mAP50 0.910) ,以及参数量是其近两倍的 YOLOv10-S(参数 7.2M,mAP50mAP_{50}mAP50 0.879) ,MedMamba-YOLO 在体量更小的情况下,实现了精度的绝对反超 。
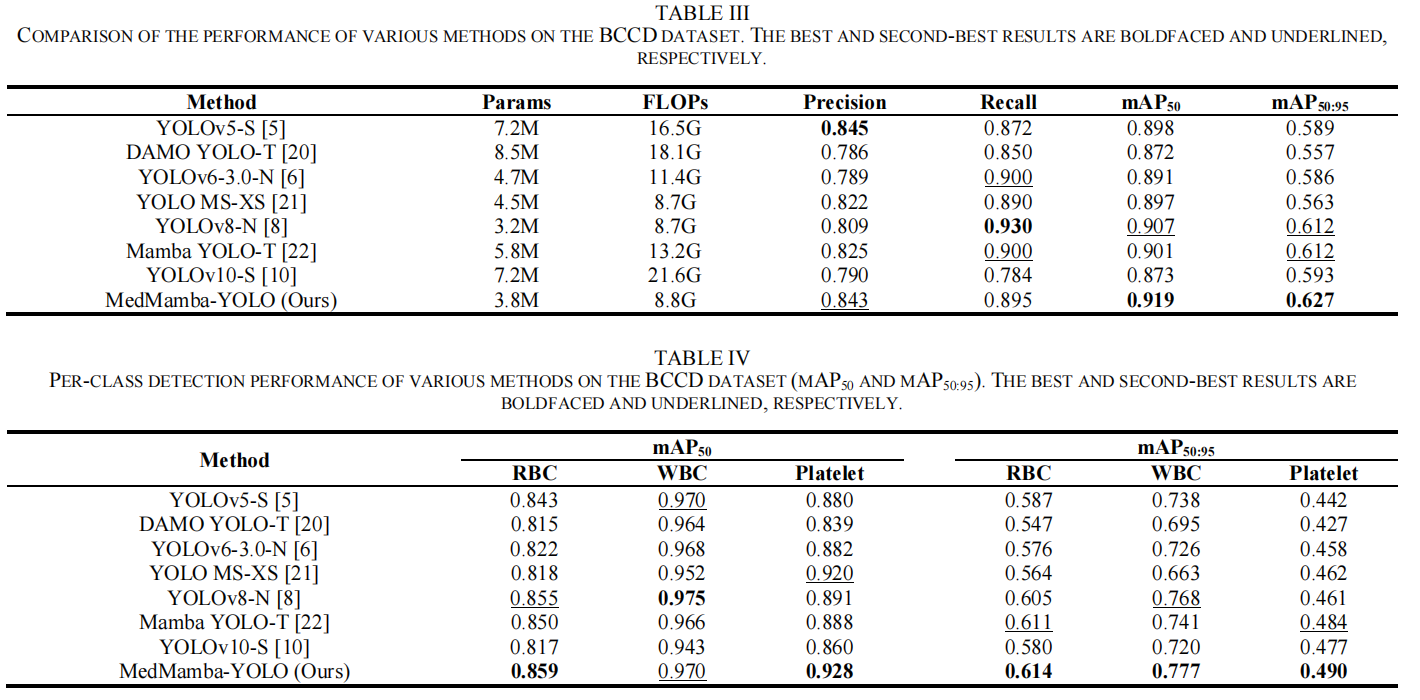
2. 微小与高相似度目标的突破(BCCD 血细胞检测)
血细胞图像中,血小板(Platelet)由于体积极小且容易与背景噪声混淆,是检测的重灾区。
MedMamba-YOLO 在血小板这一困难类别上取得了 0.928 的 mAP50mAP_{50}mAP50 。
相比于基线模型 YOLOv8-N,其在血小板的 mAP50mAP_{50}mAP50 提升了 3.7% ,mAP50:95mAP_{50:95}mAP50:95 提升了 2.9% 。这直接证明了模型中的 GDSA(空洞空间注意力)和 HMDA(异构检测头)在捕获细粒度边缘特征时的强大能力。
3. 消融实验
作者通过消融实验清晰地拆解了各个模块的独立贡献。以 YOLOv8-N 为基线(mAP50mAP_{50}mAP50 为 0.917) :
仅加入 MSF-FPN (含 SAVSSB) ,精度飙升至 0.940,证明了 Mamba 跨尺度上下文建模的威力 。
仅加入 CPIB ,精度提升至 0.930,证明了双向信息流对结构一致性的增强有效 。
当三个模块全部集成时,达到了最终的 0.954 。这说明模块之间并非无效堆砌,而是实现了优势互补 。

批判性分析
1.亮点
破除 Mamba 的"预训练依赖魔咒" : 学术界普遍认为,状态空间模型(SSMs/Mamba)由于缺乏 CNN 的局部归纳偏置,往往需要海量数据进行预训练才能收敛。本文最惊艳的一点在于,通过融合空洞卷积(GDSA/HMDA)为 Mamba 提供强烈的局部空间感知,使得模型能够在只有几百张图像的医疗数据集上从零开始 (from scratch) 快速收敛 。这极大地降低了 Mamba 在医疗领域的落地门槛。
"对症下药"的模块设计: 作者针对医疗图像的痛点(对比度低、边界模糊、小目标)给出了闭环的解法。例如,用 CPIB 的交叉特征相加来防止微弱信号在深层网络中消散 ;用 HMDA 在浅层强制关注局部、深层关注全局 。这种非暴力的结构调优极具启发性。
2.局限与不足
数据集规模过小,存在过拟合隐患: 论文选用的 Br35H 训练集仅 500 张,BCCD 仅 205 张 。在如此小的数据集上取得 95% 以上的高分,一方面说明模型易于收敛,但另一方面也极易让人怀疑模型是否陷入了"过拟合"。文章缺乏在更大规模、更多样化的医疗目标检测数据集(如 DeepLesion,包含数万个病灶)上的泛化性验证。
对比基线的选择略显"非对称": 在横向对比实验中,作者以 YOLOv8 的 Nano 版本(YOLOv8-N, 3.2M)作为主要对比对象 。然而,在对比 YOLOv10 时,却选择了体量更大的 Small 版本(YOLOv10-S, 7.2M) 。由于 YOLOv10 采用了无 NMS 设计且结构较深,在极小样本(几百张图)上直接从零训练 YOLOv10-S 极易导致不收敛或性能崩塌。因此,YOLOv10-S 跑出较低的 0.879 可能是数据量不足导致的,而非其架构落后。如果作者能加入同量级的 YOLOv9-N 或 YOLOv10-N 进行对比,说服力会更强。
未充分释放 Mamba 的 3D 长序列潜力 : 医疗影像(如脑部 MRI,即 Br35H 的数据源)在真实临床中本质上是连续的 3D 切片序列。本文的 MedMamba-YOLO 仅仅是将 Mamba 的 2D 交叉扫描机制(SS2D)当作一种替代 CNN 的空间注意力机制在使用 ,依然是在处理单张 2D 图像。事实上,Mamba 真正的"杀手锏"是具有线性复杂度的极长序列建模能力。如果能将 Mamba 用于 Z 轴(跨越数十层连续的 MRI 切片)进行 3D 病灶建模,那将更具意义。
总结
通过阅读上述代码实现,我们可以发现 MedMamba-YOLO 的改进并非盲目的模块堆砌。CPIB 的通道交叉保证了微弱特征不丢失,MSF-FPN 与 SAVSSB 通过跨尺度连接与"CNN + Mamba"的互补机制构建了强大的时空感知能力,而 HMDA 进一步实现了对尺度变化的自适应兼容。理解这套设计逻辑,对改进其他工业视觉模型同样具有极高的参考价值。