一、写在前面
这篇文章记录的是一次完整的本地验证过程,目标很明确:围绕生成式推荐场景,基于 openYuanrong 做一个可以真实运行、可以看到故障切换效果。
本文验证的核心方向有三个:
- Worker 不依赖固定的 DaemonSet 思路,能够以多副本方式灵活部署。
- 单节点故障后,业务能够快速感知并完成切换,中断时间控制在 3 秒以内。
- 通过热点数据快照和恢复加载机制,增强缓存场景的可靠性。
为了把这个方向做成一个真正可运行、可观察的案例,本文使用了三部分内容:
- openYuanrong 上游三个仓库,用来说明项目结构和能力边界。
openyuanrong-real-demo,这是基于 openYuanrong datasystem 做的真实演示工程。openyuanrong-visual-console,这是一个 Vue + Nest.js 的可视化控制台,用来把 Worker 状态和故障切换过程直接展示在页面上。
需要说明的是,本文演示的核心数据访问能力来自 openYuanrong datasystem,页面只是把真实执行过程可视化,并没有脱离 openYuanrong 另起一套假的逻辑。
二、三个上游仓库分别是什么
先把 openYuanrong 的三个上游仓库说明白,这样后面的目录关系才不会混淆。
1. yuanrong
仓库地址:
bash
https://gitcode.com/openeuler/yuanrong这是 openYuanrong 的总仓,包含总体工程结构、接口、部署目录和文档。理解整个项目时,这个仓库是入口。
2. yuanrong-datasystem
仓库地址:
bash
https://gitcode.com/openeuler/yuanrong-datasystem这是本文真正直接使用到的部分。本文中的 Worker、KV 读写、会话缓存预热、故障切换验证,全部落在 datasystem 这一层。
3. yuanrong-functionsystem
仓库地址:
bash
https://gitcode.com/openeuler/yuanrong-functionsystem这是 openYuanrong 的函数执行与调度相关部分。本文的演示重点不在 functionsystem,但为了把 openYuanrong 的整体组成说明完整,仍然把它纳入工作目录。
从本文的演示目标来看,可以这样理解三者关系:
yuanrong负责总览和整体组织。yuanrong-datasystem负责数据访问与缓存能力,本文的验证重点在这里。yuanrong-functionsystem负责函数执行能力,本文不直接使用,但属于 openYuanrong 的整体能力版图。
三、本文配套工程说明
除了上游三个仓库,本文还配套了两个演示目录:
openyuanrong-real-demoopenyuanrong-visual-console
它们的作用分别如下:
openyuanrong-real-demo负责真正启动 ETCD、两个 datasystem Worker,以及演示应用。openyuanrong-visual-console负责把演示流程做成页面,方便观察状态、日志和切换路径。
最终的目录结构如下:
text
openyuanrong/
├── yuanrong
├── yuanrong-datasystem
├── yuanrong-functionsystem
├── openyuanrong-real-demo
├── openyuanrong-visual-console如果是按本文配套代码包一起查看,openyuanrong-real-demo 和 openyuanrong-visual-console 已经包含在工程目录中,直接使用即可。
四、实验环境
本文在如下环境中完成验证:
text
Node.js v24.12.0
npm 11.6.2
Docker 29.2.0
Compose v5.0.2本地需要提前满足两个条件:
- Docker Desktop 已经启动。
- 终端可以正常执行
git、node、npm和docker compose。
五、从克隆仓库开始准备环境
先创建一个工作目录,然后把三个上游仓库克隆下来。
bash
mkdir -p ~/workspace/openyuanrong
cd ~/workspace/openyuanrong
git clone https://gitcode.com/openeuler/yuanrong
git clone https://gitcode.com/openeuler/yuanrong-datasystem
git clone https://gitcode.com/openeuler/yuanrong-functionsystem执行完成后,可以看到如下三个目录:
bash
ls输出应当包含:
text
yuanrong
yuanrong-datasystem
yuanrong-functionsystem接下来,把本文配套的两个演示目录放到同级目录中:
openyuanrong-real-demoopenyuanrong-visual-console
放好之后,再执行一次:
bash
ls应当可以看到完整目录:
text
openyuanrong-real-demo
openyuanrong-visual-console
yuanrong
yuanrong-datasystem
yuanrong-functionsystem六、先安装可视化控制台依赖
页面控制台使用的是 Vue + Nest.js,因此先安装前后端依赖。
bash
cd ~/workspace/openyuanrong/openyuanrong-visual-console
npm install --workspaces安装成功后,终端会输出类似结果:
text
added 213 packages in 2m到这里,页面工程已经准备完成。
七、启动可视化控制台
1. 启动后端
打开第一个终端窗口,执行:
bash
cd ~/workspace/openyuanrong/openyuanrong-visual-console
npm --workspace backend run start:dev启动成功后,可以看到关键日志:
text
Mapped {/api/demo/status, GET} route
Mapped {/api/demo/logs, GET} route
Mapped {/api/demo/actions/start, POST} route
Mapped {/api/demo/actions/warmup, POST} route
Mapped {/api/demo/actions/failover, POST} route
Mapped {/api/demo/actions/restart-primary, POST} route
Mapped {/api/demo/actions/cleanup, POST} route
Mapped {/api/demo/actions/clear-logs, POST} route
Mapped {/api/demo/events, GET} route
Visual console backend listening on http://127.0.0.1:30012. 启动前端
打开第二个终端窗口,执行:
bash
cd ~/workspace/openyuanrong/openyuanrong-visual-console
npm --workspace frontend run dev -- --host 127.0.0.1 --port 5173启动成功后,可以看到:
text
VITE v6.4.1 ready in 98 ms
Local: http://127.0.0.1:5173/3. 打开页面
浏览器访问:
text
http://127.0.0.1:5173这时页面处于初始状态,界面上还没有开始真正的 Worker 演示流程。
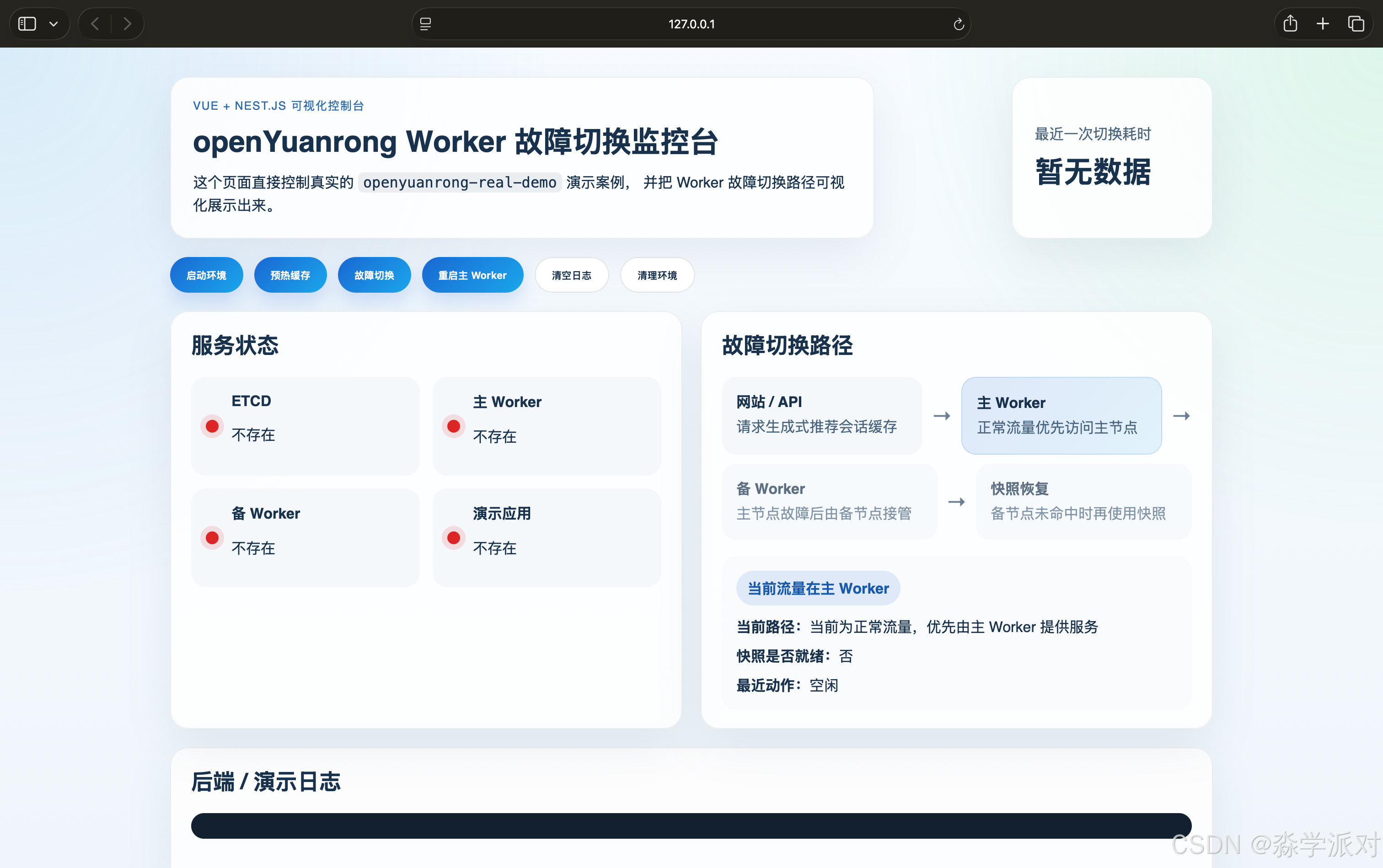
4. 为什么页面能够拉起真实的 openyuanrong-real-demo
很多人在第一次看到这里时,会有一个很自然的问题:页面本身只是一个 Vue + Nest.js 项目,它为什么能够把另一个目录下的 Docker 环境真正拉起来。
这里的关键不在前端,而在后端。
openyuanrong-visual-console 的后端服务中,预先保存了 openyuanrong-real-demo 的本地路径。当前演示代码中,这个路径就是:
text
/Users/luqingjiedemac/gitcode_obj/openyuanrong/openyuanrong-real-demo当页面上点击"启动环境"时,请求会先进入可视化控制台后端,然后由后端在这个目录下执行:
bash
docker compose up --build -d这里最重要的一点是:Docker 不是自己在磁盘里搜索到了 openyuanrong-real-demo,而是后端明确把命令的执行目录切到了这个路径下。因为当前目录就是 openyuanrong-real-demo,所以 Docker Compose 会自动读取该目录中的 docker-compose.yml,并据此启动:
yr-etcdyr-worker-1yr-worker-2yr-demo-app
也就是说,整个调用链路实际上是下面这样:
text
浏览器页面
↓
openyuanrong-visual-console 前端
↓
openyuanrong-visual-console 后端
↓
在 openyuanrong-real-demo 目录下执行 docker compose 命令
↓
Docker Compose 读取 openyuanrong-real-demo/docker-compose.yml
↓
启动 etcd、worker 和 demo-app因此,页面本身不是在"模拟"容器状态,而是在调用真实的后端命令;后端也不是"猜测" demo 在哪里,而是拿着一个明确的本地路径,在这个路径中直接执行 Docker Compose。
读者如果想进一步确认这一点,可以在点击"启动环境"之后,在 openyuanrong-real-demo 目录中手动执行下面的命令:
bash
cd ~/workspace/openyuanrong/openyuanrong-real-demo
docker compose ps如果页面确实成功拉起了真实环境,那么这里会看到:
yr-etcdyr-worker-1yr-worker-2yr-demo-app
四个服务的运行状态。
八、页面驱动真实 openYuanrong 演示
这一步开始,页面上的每一个按钮,驱动的都是真实的 openyuanrong-real-demo,并不是前端本地模拟。
建议操作顺序固定为:
- 清空日志
- 启动环境
- 预热缓存
- 故障切换
这样最适合做演示,也最适合写博客和做截图。
Step 1. 点击"清空日志"
先点击页面上的"清空日志"按钮,把上一次演示留下来的日志清空。这样后面看到的内容就是一条完整、干净的验证链路。
清空之后,页面的日志区域会被清空,最近动作恢复为空闲状态。
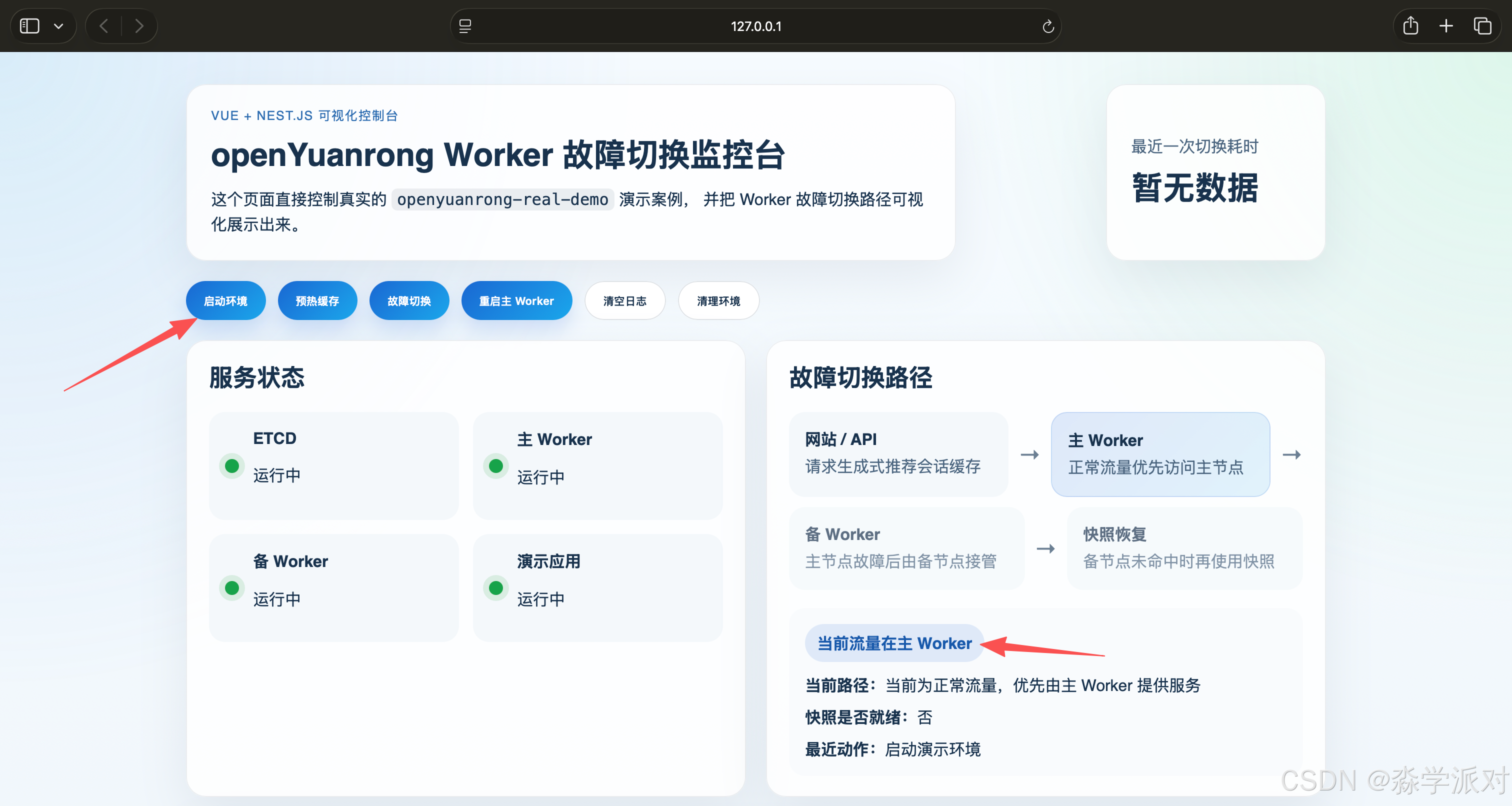
Step 2. 点击"启动环境"
点击"启动环境"按钮后,后端会调用真实的 Docker 编排,启动:
yr-etcdyr-worker-1yr-worker-2yr-demo-app
页面中服务状态会依次变为运行中。
此时后端日志中可以看到真实启动输出,关键成功日志如下:
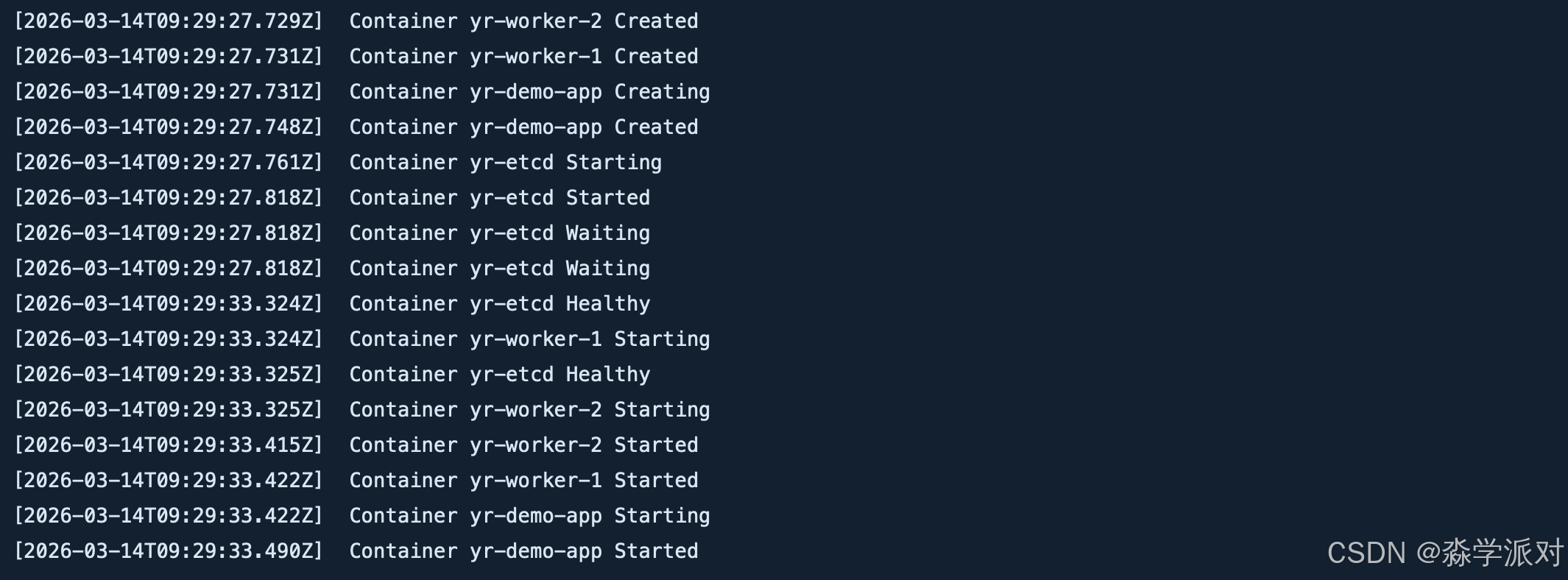
text
$ docker compose up --build -d
Image openyuanrong-real-demo-yr-worker-1 Built
Image openyuanrong-real-demo-yr-worker-2 Built
Image openyuanrong-real-demo-demo-app Built
Container yr-etcd Healthy
Container yr-worker-1 Started
Container yr-worker-2 Started
Container yr-demo-app Started到这里,openYuanrong datasystem 的基础演示环境已经真正跑起来了。
从实现逻辑上看,这一步对应的是下面这条链路:
- 页面按钮触发前端请求。
- 前端请求进入
openyuanrong-visual-console的 Nest.js 后端。 - 后端在
openyuanrong-real-demo目录下执行docker compose up --build -d。 - Docker Compose 根据
docker-compose.yml启动etcd、两个 Worker 和一个demo-app。 - 页面再通过后端读取容器状态,并把结果更新到页面上。
这一步之所以重要,是因为它对应了本文第一个目标方向,也就是 Worker 的灵活部署能力。在这个演示中,Worker 不是以"每台节点固定一个实例"的方式去组织,而是直接以两个副本的方式独立启动。换句话说,当前案例已经把 Worker 当成一个可以按业务需求部署和伸缩的服务来使用,而不是依赖固定节点形态。
从 openYuanrong 的角度来看,它在这一层的优势主要体现在两个方面:
- Worker 是一个可以独立拉起的数据服务实例,便于按业务规模组织部署。
- 数据访问接口和 Worker 生命周期是解耦的,前端页面并不关心底层数据节点如何启动,只需要通过后端统一调度即可。
因此,页面上看到的"主 Worker、备 Worker、演示应用均已运行",本质上是在说明:这套系统已经具备了多 Worker 副本的运行形态,能够支撑后续的故障切换和数据恢复演示。
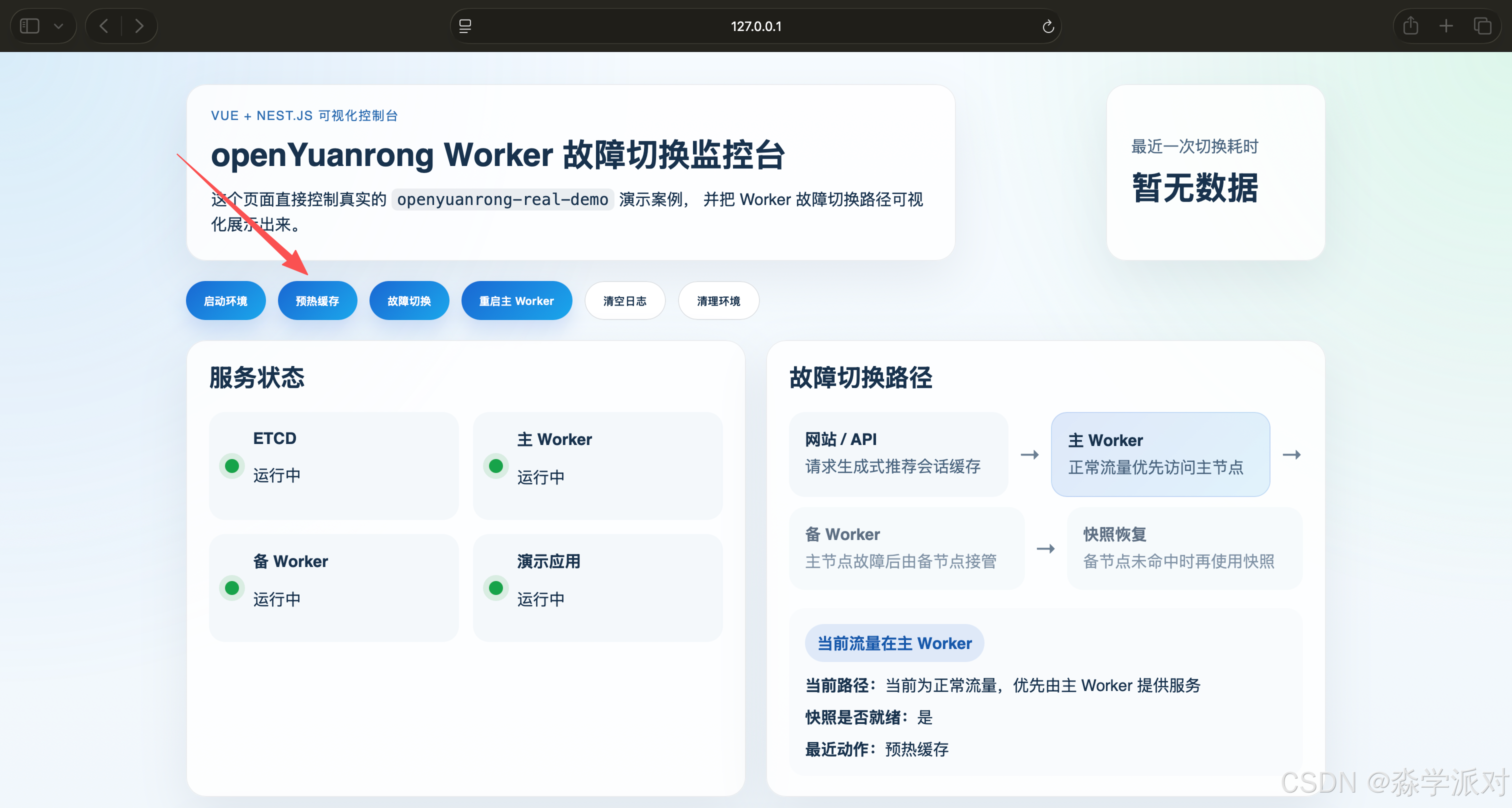
Step 3. 点击"预热缓存"
点击"预热缓存"按钮后,页面背后会执行:
text
docker compose exec -T demo-app python /app/demo_client.py这一步做的事情有三件:
- 把生成式推荐会话缓存写入主 Worker。
- 从主 Worker 读取热点 key。
- 把热点 key 写入快照文件,并预加载到备 Worker。
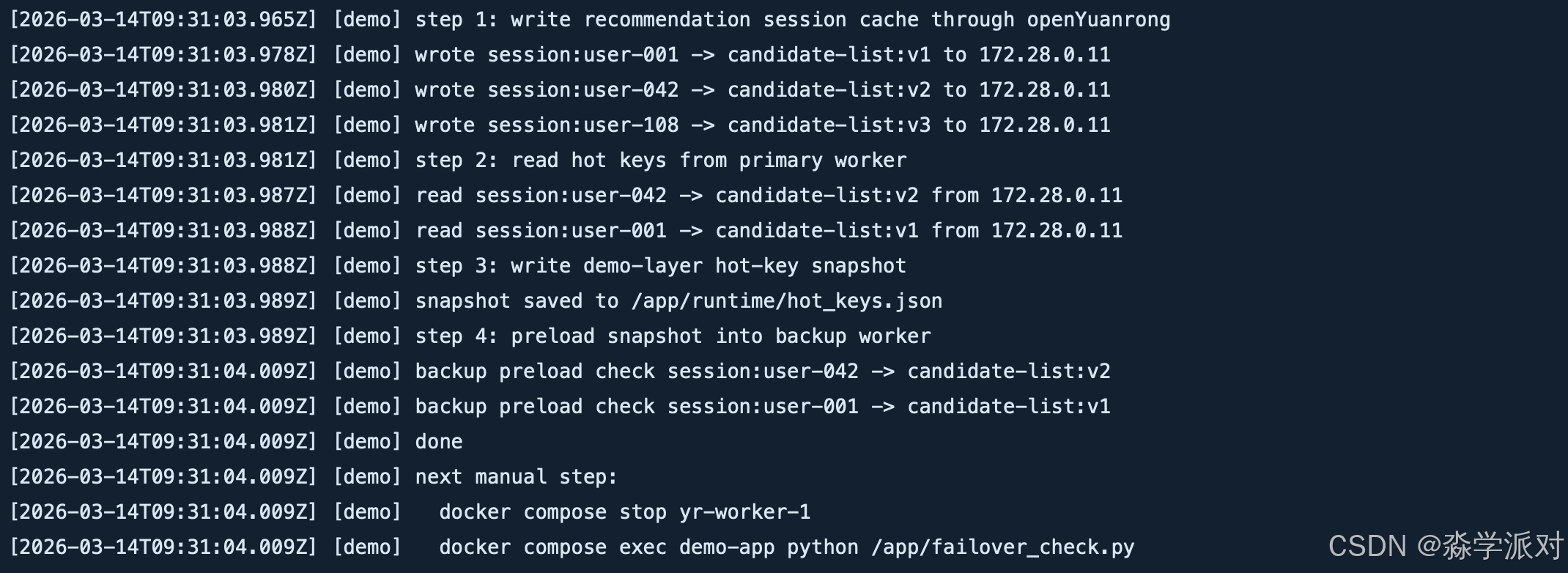
从页面的日志区域可以看到完整成功输出。实际验证时,关键日志如下:
text
[demo] waiting for workers
[demo] step 1: write recommendation session cache through openYuanrong
[demo] wrote session:user-001 -> candidate-list:v1 to 172.28.0.11
[demo] wrote session:user-042 -> candidate-list:v2 to 172.28.0.11
[demo] wrote session:user-108 -> candidate-list:v3 to 172.28.0.11
[demo] step 2: read hot keys from primary worker
[demo] read session:user-042 -> candidate-list:v2 from 172.28.0.11
[demo] read session:user-001 -> candidate-list:v1 from 172.28.0.11
[demo] step 3: write demo-layer hot-key snapshot
[demo] snapshot saved to /app/runtime/hot_keys.json
[demo] step 4: preload snapshot into backup worker
[demo] backup preload check session:user-042 -> candidate-list:v2
[demo] backup preload check session:user-001 -> candidate-list:v1
[demo] done这组日志非常关键,因为它证明了三件事情已经真实发生:
- openYuanrong
KVClient已经完成真实写入。 - 热点 key 已经被读取出来。
- 快照已经生成,并且备 Worker 已经完成预热。
从项目内部逻辑看,这一步是整个方向验证里最能体现"生成式推荐缓存场景"的部分。
页面上点击"预热缓存"之后,真正执行逻辑的是 openyuanrong-real-demo/app/demo_client.py。这个脚本在 demo-app 容器里运行,流程可以拆成四步:
- 等待主 Worker 和备 Worker 都处于可访问状态。
- 通过 openYuanrong 的
yr.datasystem.KVClient把会话缓存写入主 Worker。 - 从主 Worker 再次读取热点 key,确认热点数据已经可以被访问。
- 把这些热点 key 保存成快照文件,并重新预加载到备 Worker。
这一步为什么适合作为"生成式推荐方向"的演示,是因为它和真实业务很接近。生成式推荐服务通常会把这些内容放在会话缓存里:
- 当前用户会话的候选集
- 上一次召回或粗排结果
- 大模型生成前的上下文缓存
- 高频访问的热点会话数据
本案例里的这些 key:
session:user-001session:user-042session:user-108
就可以把它理解成一组被推荐服务频繁访问的会话缓存。
从目标方向上看,这一步同时支撑了两个点。
第一,它证明了 openYuanrong datasystem 确实在承担"在线会话缓存"的角色,而不是只做静态演示。数据是通过真实 KVClient 写进去的,也是通过真实 Worker 读出来的。
第二,它把"热点数据落盘增强可靠性"的方向具体化了。虽然这里使用的是案例层的热点快照,而不是完整的生产级外部持久化链路,但对读者来说,已经能非常直观地理解这个设计思路:
- 热点数据先进入主 Worker。
- 应用把真正重要的热点 key 提取出来。
- 热点 key 被保存为快照。
- 备 Worker 提前装载这些热点数据。
这套机制的价值在于,当主 Worker 发生故障时,备 Worker 并不是完全冷启动状态,而是已经具备了一部分热点数据承接能力。这对于生成式推荐这种追求稳定时延的场景很重要,因为它可以减少缓存完全丢失后带来的重新计算开销。
从 openYuanrong 的优势来看,这一步体现得很明显:
- openYuanrong 提供了统一的 KV 访问接口,应用不需要自己维护底层数据访问协议。
- Worker 作为独立的数据节点,可以把主写入和备份预热这两条路径组织起来。
- 在此基础上,业务层可以很自然地叠加热点快照和恢复策略,形成更完整的可靠性方案。
Step 4. 点击"故障切换"
点击"故障切换"按钮后,页面背后会执行两步:
第一步,强制移除主 Worker:
text
docker rm -f yr-worker-1第二步,执行故障切换检查:
text
docker compose exec -T demo-app python /app/failover_check.py这一步的意义就是验证"主 Worker 故障后,业务能否快速识别并切到备 Worker"。
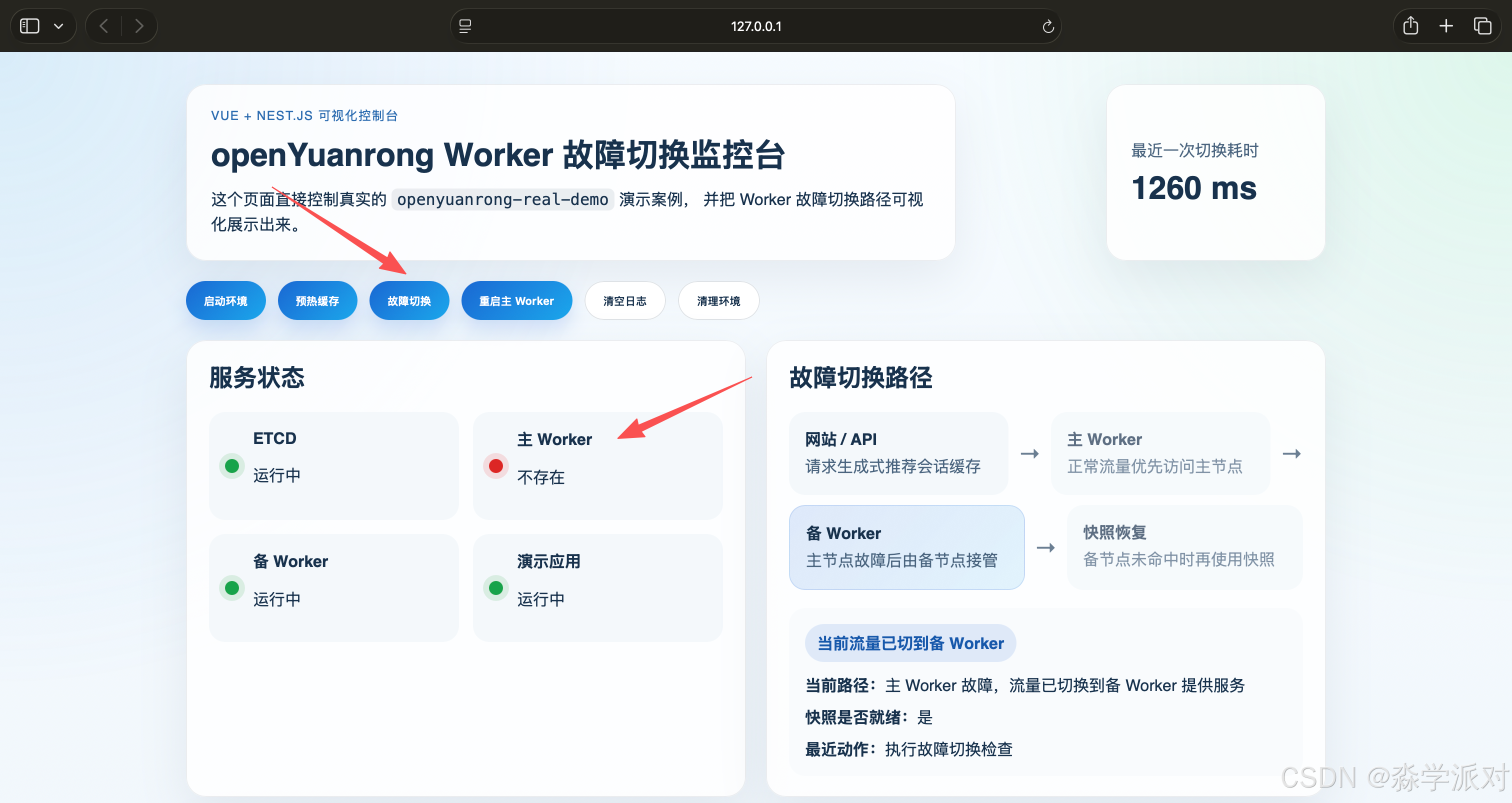
页面状态会发生两个非常直观的变化:
- "主 Worker" 的状态从运行中变为不存在。
- "故障切换路径" 区域的高亮从主 Worker 切换到备 Worker。
在实际验证中,页面底部日志会出现如下关键内容:
text
$ docker rm -f yr-worker-1
yr-worker-1
$ docker compose exec -T demo-app python /app/failover_check.py
[failover] primary is unreachable by quick probe, skip direct read
[failover] backup served session:user-042 -> candidate-list:v2
[failover] application failover time: 1.29s这段日志可以直接说明本文要验证的第二个方向已经跑通:
- 主 Worker 故障后,应用没有长时间阻塞。
- 业务首先快速感知主 Worker 不可达。
- 然后直接切换到备 Worker。
- 整个应用侧故障切换耗时约为 1.29 秒,满足"小于 3 秒"的目标。
从项目内部实现来看,这一步对应的是 openyuanrong-real-demo/app/failover_check.py 的逻辑。它不是简单地"主节点失败了就报错退出",而是按一条明确的恢复路径顺序执行:
- 先对主 Worker 做快速连通性探测。
- 如果主 Worker 不可达,则跳过直接读取主 Worker。
- 立刻尝试从备 Worker 读取热点数据。
- 如果备 Worker 也未命中,再回退到热点快照恢复。
页面上为什么会出现"主 Worker 不存在、备 Worker 高亮接管"的现象,原因正是这里的处理逻辑已经从"单点访问"切换成了"主节点优先、故障后自动切备、必要时再从快照恢复"的多级路径。
这一步最能体现本文第二个方向的核心价值,也就是"单节点故障场景下的快速感知和故障隔离"。如果没有这样的处理,主 Worker 一旦故障,应用通常会出现两个问题:
- 请求长时间等待超时,用户侧感知明显。
- 即使后面有备节点,也来不及快速接管。
而在当前案例中,应用首先做的是一次非常轻量的快速探测,而不是直接在主 Worker 上长时间阻塞。探测失败后,流量立即转向备 Worker,因此页面上最终看到的是:
- 主 Worker 状态消失
- 备 Worker 仍然运行
- 当前路径切到备 Worker
- 故障切换耗时约 1.29 秒
从 openYuanrong 的视角来看,这里的优势在于:
- 底层已经有可独立运行的多个 Worker 副本,业务才能谈得上切换路径。
- 业务访问依赖的是统一的 KV 能力,不需要因为切换 Worker 而改动应用访问方式。
- 在主 Worker 不可用的情况下,备 Worker 可以继续承接读请求,从而把单节点故障影响控制在较小范围内。
如果把这一步放回生成式推荐场景中去理解,就会更清楚它的价值。推荐服务通常对在线时延比较敏感,特别是会话缓存已经命中的情况下,服务期望直接读取缓存完成后续生成或排序。一旦主缓存节点故障,如果没有快速切换机制,用户请求就可能退化成重新计算,造成明显时延波动。而当前案例证明,基于 openYuanrong 的 Worker 形态和统一 KV 访问能力,可以把这个风险收敛到秒级切换范围内。
九、清理环境
演示完成后,可以清理 Docker 环境。
进入 openyuanrong-real-demo 目录,执行:
bash
cd ~/workspace/openyuanrong/openyuanrong-real-demo
docker compose down -v执行完成后,容器、网络和卷会被清理干净。
十、结语
这次实践的重点,不是把 openYuanrong 做成一个大而全的生产系统,而是围绕"生成式推荐缓存高可用"这个方向,做出一个真实可运行、真实可观察、真实可验证的最小闭环。
从结果看,这个闭环已经成立:
- openYuanrong datasystem 的 Worker 和 KV 访问是真实运行的。
- 预热缓存、热点快照和备 Worker 预加载是真实执行的。
- 主 Worker 故障后的快速切换是真实发生的。
- 页面日志和状态变化可以作为演示和材料输出的直接依据。
项目中用到的所有的案例代码都已开源:
https://gitcode.com/openeuler/yuanrong
https://gitcode.com/openeuler/yuanrong-functionsystem
https://gitcode.com/openeuler/yuanrong-datasystem