前言
和https://blog.csdn.net/jllws1/article/details/158696538?spm=1011.2124.3001.6209内容相连
引入
前面分析了数据都是以地址 形式表示和访问的.符号解析保证相同的符号访问相同的地址.但里面的地址是在编译后文件使用的,不是内存地址.
程序编译完后,是放入硬盘(或外存)中的字节码,调用内存后,再依次经过缓存(从低到高)进入寄存器进行运算.程序本身是个字节块,内容有数据块,代码块及其他数据内容.重定位要解决地址问题.
另外在上一篇帖子中还有些表,如数据类型表,数据表,函数表,函数指针表等(统称为信息表),他们也是需要加入编译后的文件中的.++编译后的文件=被编译的源文件+信息表++.
重定位
数据是由地址表示和访问的.地址是第一重要的,但地址的值是可以改变的,例如上面提到的,从数据加载到内存,到高速缓存,到寄存器,其地址在一直改变.所以地址可以以"空间"来讨论.当数据从空间A移动到空间B时,需要把地址偏移.
笔者为了方便说明,建立了三个概念:源代码空间,编译代码空间,内存空间.他们不一定和现实吻合
源代码空间
源代码空间的抽象:完全由源代码编译后形成的空间,由函数(代码块),全局变量/静态变量,数据类型定义,数据表等内容所组成.
数据由地址表示,但在意的是地址内的数值.地址是可以随时改变的.基于这个思路,为了简化操作,把编译文件做一个内容划分,后面再看把他们组合起来.
1>主函数main属于一个空间
因为主函数里面的内存分配都是在栈空间,所以分开不会影响数据分布
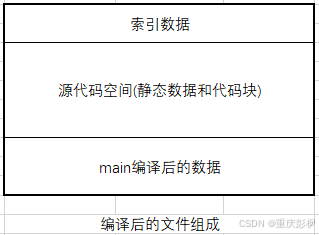
2>函数表,数据表,数据类型表,其他表,统称为索引数据,属于一个空间
这部分是编译时的辅助数据,编译后可能用到可能用不到,后面分析
因此源代码空间只有静态数据和代码块.图示
以下模拟编译源文件,按照通常的内容,有静态数据,数据类型声明,函数定义.源代码参考如下:
//源代码---非完整
//生成一个叫demo1.object的目标文件
#include<stdio.h>
/*数据类型定义*/
struct School{
short stu_number;
short room_number;
double square;
Grade* grades;
}
struct School red_star(2000,100,1000000,0); //括号内的0是空指针
/*函数声明*/
void fun1();
/*函数声明*/
void fun2(){
fun1();
static struct School sun_rise(1000,50,500000,0); //日出小学
}1.数据类型声明
识别"struct+空格+字符串(School)"为一个类型定义,填写数据类型表 ,记录每个数据类型的长度,不产生数据,如:
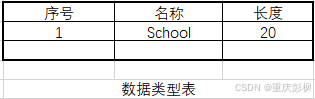
此外,每个具体数据类型给一张类型数据表,如下:
|----|--------|-------------|------|
| 序号 | 数据类型 | 标识符 | 占据空间 |
| 1 | short | stu_number | 2 |
| 2 | short | room_number | 2 |
| 3 | double | square | 8 |
| 4 | 指针 | grades | 8 |
| | | | |
| School类型数据表 ||||
他的作用是每当需要访问具体数据时,用作指针偏移的地址计算,下面讲述
每遇到1个struct定义的类型,数据类型表加1项内容,再生成1张类型数据表.
2.全局变量red_star
在示例代码中,red_star是第一个生成的静态数据对象.
数据对象red_star的图示如下(不属于索引表,只用作理解用):
|----|------------|-------------|-----------|-----------|
| 地址 | 0x00~0x01 | 0x02~0x03 | 0x04~0x0b | 0x0c~0x13 |
| 值 | 2000 | 100 | 1,000,000 | 0 |
| 标识 | stu_number | room_number | square | grades |
| 含义 | 学生人数/学校 | 房间数 | 面积 | 指空 |
| | | | | |
| red_star数据图示 |||| |
将产生一个数据对象表中的对象,假设源文件编译后生成一个叫demo1.object的文件
|----|--------|----------|------------|
| 序号 | 数据类型 | 标识符 | 访问地址(起始地址) |
| 1 | School | red_star | 0x00 |
| | | | |
| | | | |
| demo1.object数据对象表(初始版本) ||||
试想其编译后的机器指令,如下:
//汇编代码,程序计数器PC略
movw $2000,%rdi
movw %rdi,0x00 //对应stu_number
movw $100,%rdi
movw %rdi,0x02 //对应room_number
movq $100000,%rdi
movq %rdi,0x04 //对应square
movd $0,%rdi
movd %rdi,0x0c //对应指针grades问题来了,代码铁定++无法执行++,因为指向的地址0x00是内存地址,而不是空间demo1.object的地址.
地址和空间之间是有联系的,地址以空间为参照.地址和空间的关系如下:
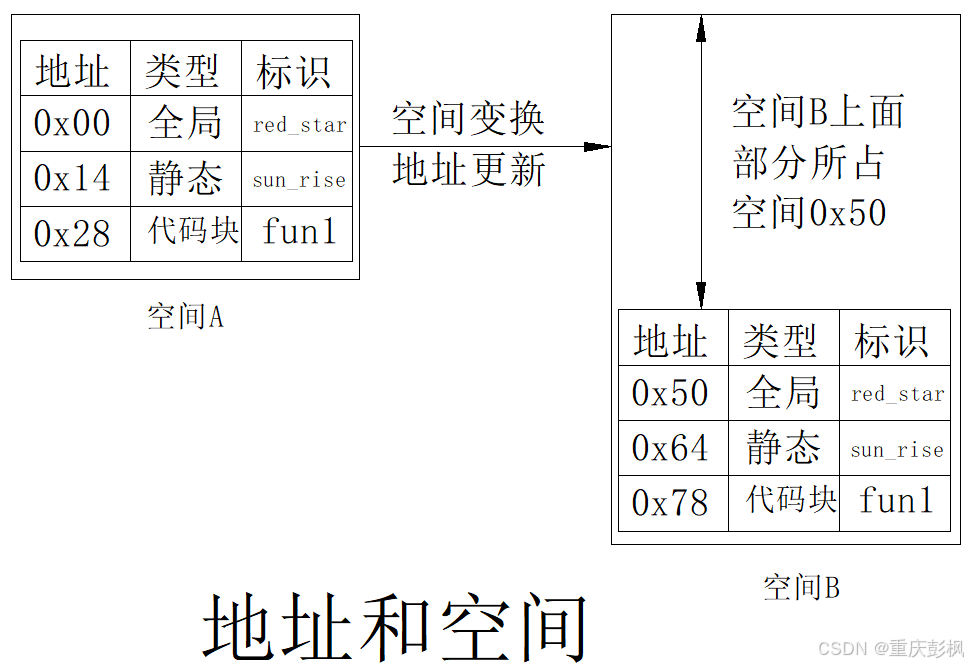
该图同时可以用于将多个目标文件连接在一起,最终空间B映射为++内存空间++.
上一篇帖子提到过:数据在内存空间中是不断移动的,从外存到内存到高速缓存再到寄存器
怎么解决这个问题,使得每次空间变换都能访问到准确数据?用相对地址的方法.
1.为每个目标文件(.o)建立数据对象表,确定该目标文件中数据块的相对位置
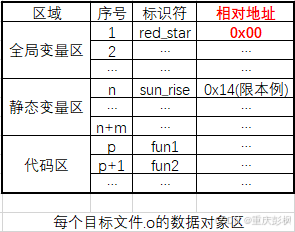
2.目标文件块每次移动,记录在新空间中的起始地址
假设上图中的空间B是内存空间,则记录下0x50.
3.将记录下的地址传给某寄存器,作为指针访问数据
当main中要访问red_star的数据,如red_star.stu_number时,能找到对应数据,
//伪代码,汇编
movq $0x50,%rdi //%rdi指向目标文件
/*从相对地址取得绝对地址*/
moveq (装载0x00的地址) %rdx //把相对地址(这里是0x00)传给%rdx寄存器
//省略一步是从red_star地址查询类型数据表stu_number得到偏移值,取得最终相对地址
... //实际上red_star.stu_number的相对偏移为0
add %rdx %rdi //%rdi作为指针,取得绝对地址
move (%rdi) ... //取得red_star.stu_number的值这里的相对地址0x00查询数据对象区得到red_star的绝对地址,stu_number相对于red_star的绝对地址是0偏移,如果还有其他red_star的包含对象,查询类型数据表.例如room_number,先计算相对地址0x00+2=0x02,然后将0x02加上%rdi,使用(%rdi)访问room_number的值
3.局部静态变量sun_rise
源文件中有一个局部静态变量sun_rise,属于静态变量区.访问和全局变量一致.
4.代码块
代码块也是数据,所以被列入数据对象区.
每个函数代码块编译后的内容,几乎和外界无联系,这是函数设计的黑盒机制所决定的.
函数的调用和前面的数据访问是一样的.有一点需要注意的是:如果函数A调用了函数B,则函数B必须在函数A前面声明.这和平常写代码是一致的---如果本例中把fun2()声明在fun1()后面,编译将失败.
索引表
索引表包括了++数据对象表++ ,++数据类型表++ ,++类型数据表++
提一下类型数据表,他有两个作用:一是识别,只有出现的变量名出现才能通过编译,如red_star.stu_number,如果有一个变量red_star.number,提示找不到该变量编译失败(和写代码编译遇到情况一样).二是计算偏移量,取得变量名对应的相对地址.
索引表起到的是辅助作用,是否留在编译文件中或者保留做其他用暂时没探寻
小结
数据由地址表示和访问,地址和空间有联系,空间移动地址更新.
笔者啰啰嗦嗦写了一大堆,只对应了本书内容中的三句话.在本书P466-7.2静态链接下面的·重定位(relocation):
编译器和汇编器生成从地址0开始的代码和数据节.链接器通过把每个符号定义与一个内存位置关联起来,从而重定位这些节,然后修改所有对这些符号的应用,使得他们指向这个内存位置.
前贴笔者提到过本书内容写得很精致,**但要读透也不是那么容易.**笔者尝试分析编译器的行为,但毕竟不是写编译器,所以如果有错误也不见怪.
在计算机中解决问题的一个思路:如果有些事情目前做不到,多加数据多加算法,总可以做得到.