前言
https://blog.csdn.net/jllws1/article/details/158778175?spm=1011.2124.3001.6209是前一篇贴.++在前面的重定位分析中,有部分内容不准确++,在这篇帖子里尝试继续解读重定位
引入
思考本身也是有方法的,简单描述:
思考和解决问题的过程,是分析和推导的过程.推导可以正向推导,也可以逆向推导.分析是把问题细化到可以用现有知识解决的程度.如果解决不了,可以做假设,把得到的答案归纳,总结得出结论.
数据和空间的关系
如前多次所述:数据以地址标识和访问.数据=指针+偏移.偏移量由程序员掌握.
不管是软件层面的数据对象,还是硬盘中的文件,都是一样.
数据必存在于某个空间中.每块数据空间都需要一个数据(对象)表来做索引.例如:假设有一块地址空间占65536字节,地址编号从0x0000到0xffff(16位地址),里面的数据应该用索引表来管理,如下:
|-------|--------|-----|------|-------|
| 数据块序号 | 数据类型 | 标识符 | 起始地址 | 长度 |
| 1 | int | / | 0x00 | 4 |
| 2 | double | / | 0x04 | 8 |
| 3 | School | / | 0x0d | 20 |
| 4 | 空置 | / | 0x14 | 65504 |
| | | | | |
| 某一块65536字节空间 |||||
空间中放了一个int型数据,一个double型数据,一个School类型数据(20字节,见前贴),剩余空置
---可以推导出内存空间同样有数据(对象)表,
----数据表可以嵌套,例如School类型的数据对象用类型数据表来嵌套,说明包含的数据对象所占空间
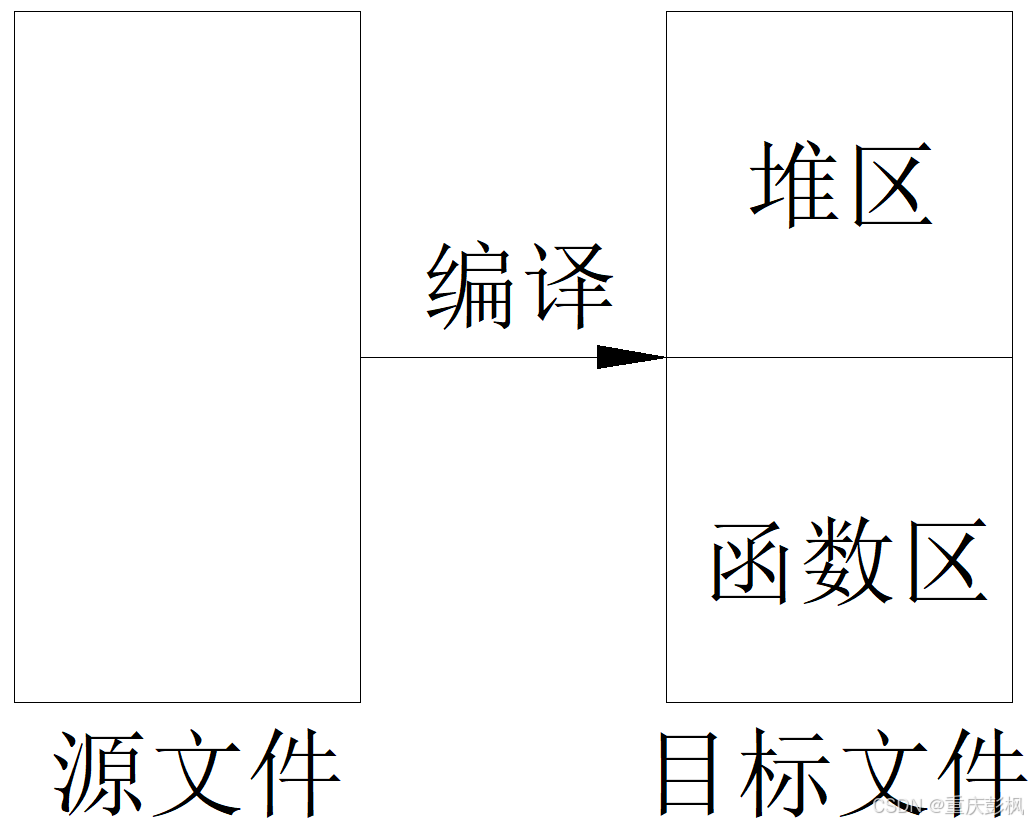
从源文件到目标文件的分析
假设:每个源文件编译后对应一个数据空间.
源文件简单抽象:源文件=数据类型定义+全局变量+函数(代码块)定义
编译器对源文件的解析上一帖有过分析,需要建立数据类型表,类型数据表,数据对象表.
每个源文件编译后生成的是一些指令流.内容有生成静态数据的指令流和函数解析后的指令流.
------推导:数据类型表和类型数据表,可以作为编译的辅助文件,不出现在数据空间中.数据均以地址的形式存在,编译形成的目标文件是一堆数字,不需要这两个表.
另外,生成静态数据的指令流,也不必存在目标文件中,只要划分一个堆区,写进去就好了.
目标文件空间的内容抽象
一个数据对象(索引)表,一个堆区和一个代码区.其中索引的内容是数据的地址
|-------|-----|--------|----------|------|----|
| 数据块序号 | 区域 | 数据类型 | 标识符 | 起始地址 | 长度 |
| 1 | 堆区 | School | red_star | 0x00 | 20 |
| 2 | 堆区 | School | sun_rise | 0x14 | 20 |
| 3 | 函数区 | 函数 | fun1 | 0x28 | 40 |
| 4 | 函数区 | 函数 | fun2 | 0x4c | 40 |
| | | | | | |
| 目标文件数据索引表 ||||||
目标文件空间示意图
当目标文件从当前空间移动到新空间,修改目标文件数据索引表的起始地址值即可.保证访问到的数据不会出错.例如:将目标文件整体移动到以0xffff0000开始的空间,则取出索引表的地址,将其每项的起始地址加0xffff0000,得到以下表
|-------|-----|--------|----------|------------|----|
| 数据块序号 | 区域 | 数据类型 | 标识符 | 起始地址 | 长度 |
| 1 | 堆区 | School | red_star | 0xffff0000 | 20 |
| 2 | 堆区 | School | sun_rise | 0xffff0014 | 20 |
| 3 | 函数区 | 函数 | fun1 | 0xffff0028 | 40 |
| 4 | 函数区 | 函数 | fun2 | 0xffff004c | 40 |
| | | | | | |
| 目标文件移动到内存中以0xffff0000开始的地址后的数据索引表 ||||||
注意:为什么不把数据索引表本身也列入目标文件中?这个做法是笔者个人的看法---目标文件数据索引表可以交给操作系统来管理.即使要列入目标文件,也就是做了次数据空间移动,方法是一样的.因为索引表本身是需要占空间的,每个目标文件占空间大小也不一样不好弄,可以编译完后生成另一个文件来储存索引表.
链接
链接这个词有点像在"高级"地表达"连接".
1.整合.是否所有的目标文件会整合到一起,例如堆区合并,函数区合并,再修改对应的起始地址以使准确读取数据?和前面的数据在空间移动类似,建立一个新的空间,将数据有序的添加进去.稍微麻烦一点,每移动一次数据要更新一次起始地址.
2.检测去重名.如果多个目标文件中有同名的静态变量和函数.对C语言的编译器来说,按照后进来为主,自动覆盖前面的变量或函数定义.在C语言中命名是个令人头疼的问题,命名对写大型软件也有些影响.对于其他高级语言,例如C++/Java来说,在类中命名的变量或者函数,不存在去重问题
3.在链接阶段,数据索引表起到了查找数据的作用.++生成exe文件后,数据索引表也没有存在的必要++,原因和前面数据类型表和类型数据表是相同的:数据是通过地址来访问的,但最终需要的是"数值".
小结
上一篇帖子中把静态数据生成到一个位置上是不准确的,实际上应该放到堆区.堆区位置在哪里?是编译器决定的.本贴内容属于个人理解,和实际情况可能有出入.
重定位本质上是用类型来识别数据的方法,内存的抽象如下:
|-------|-------|-------|-----|------------|-----|
| 数据块序号 | 文件名 | 说明 | 标识符 | 起始地址 | 长度 |
| 1 | a.o | 目标文件 | / | 0xffff0000 | / |
| 2 | b.exe | 可执行文件 | / | / | / |
| 3 | c.dat | 数据文件 | / | / | / |
| 4 | ... | ... | ... | ... | ... |
| | | | | | |
| 内存的抽象 ||||||
文件以后缀名区分文件性质.操作系统对每种文件采取不同的解析方法.例如本贴提出了简单的目标文件模型,操作系统知道每个地址代表的是什么意思,以及在多少字节开始解析成指令流等等.
核心仍然是那句话:数据以地址标识和访问.