🎙️ Day 2:语音识别基础 + CTC 详解
今天的目标:理解语音识别(ASR)为什么难,掌握端到端ASR的核心算法------CTC ,这是面试中必考的知识点。
第一步:语音识别的问题定义
1.1 ASR 到底在做什么?
输入: 一段音频波形(或 FBank 特征序列) X = (x₁, x₂, ..., x_T) T 帧
输出: 一段文字序列 Y = (y₁, y₂, ..., y_U) U 个字/token
目标: 找到最可能的文字 Y* = argmax P(Y|X)比如:
输入: [80维FBank × 500帧] (约5秒音频)
输出: "今天天气真不错" (7个汉字)1.2 为什么语音识别很难?
核心难点 = 对齐问题 (Alignment Problem)
音频帧: x₁ x₂ x₃ x₄ x₅ x₆ x₇ x₈ x₉ x₁₀ x₁₁ x₁₂ ... (几百帧)
文字: 今 天 天 气 真 不 错 (7个字)
问题: 哪些帧对应"今"?哪些帧对应"天"? → 我们不知道!-
输入序列(帧)比输出序列(文字)长很多(通常 10~50 倍)
-
我们没有"帧-字"的精确对齐标注(标注成本太高)
-
不同人说话速度不同,同一个字对应的帧数不固定
🎯 CTC、Attention、Transducer 等算法的核心目的,都是解决这个对齐问题。
第二步:传统 ASR Pipeline(快速了解)
面试时偶尔会问到传统方法,了解框架即可,不需要深入。
2.1 传统三件套
┌───────────────────────────────────────────────┐
│ 传统 ASR Pipeline │
│ │
音频 ─→ 特征提取 ─→ ┌──────────┐ ┌──────────┐ ┌──────────┐ ─→ 文字
(MFCC) │ 声学模型 │ × │ 语言模型 │ × │ 解码器 │
│ (AM) │ │ (LM) │ │(Decoder) │
│ GMM-HMM │ │ N-gram │ │ WFST │
└──────────┘ └──────────┘ └──────────┘| 组件 | 作用 | 传统方法 |
|---|---|---|
| 声学模型 (AM) | 给定音频,预测音素/状态的概率 | GMM-HMM → DNN-HMM |
| 语言模型 (LM) | 哪些词序列更合理 | N-gram |
| 发音词典 | 词 → 音素序列的映射 | 人工编写 |
| 解码器 | 综合 AM+LM,搜索最优路径 | WFST (加权有限状态转换器) |
贝叶斯公式:
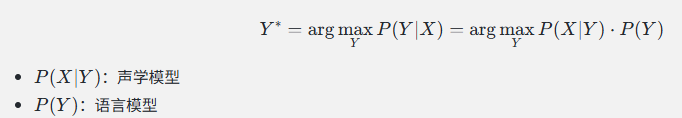
2.2 HMM 解决对齐问题的思路(简要了解)
HMM 的做法:
- 每个音素用 3-5 个状态表示
- "你好" → n-i-h-ao → 每个音素3个状态 → 共12个HMM状态
- 每个状态可以"自循环"(停留) 或 "跳转到下一个状态"
- 通过 Viterbi 算法找到最优的 状态-帧 对齐
问题:
- 需要音素级标注 / 发音词典
- Pipeline 太复杂,每个组件分开优化
- 错误会在组件间传播这就是为什么端到端(End-to-End)方法兴起的原因 👇
2.3 端到端 ASR 的三大范式
端到端 = 一个模型直接从音频到文字,不需要分开的AM/LM/Decoder
三大范式:
┌────────┐
│ CTC │ ← 今天重点学!
└────────┘
┌────────────────────┐
│ Attention Seq2Seq │ ← Day 3-4 学
└────────────────────┘
┌──────────────┐
│ Transducer │ ← Day 3-4 学
└──────────────┘第三步:CTC 详解 ⭐⭐⭐⭐⭐
CTC (Connectionist Temporal Classification),2006年由 Alex Graves 提出。 这是面试中问得最多的语音算法之一,必须彻底理解。
3.1 CTC 解决什么问题?
回到对齐问题:
输入: T=12 帧的 FBank 特征
输出: "CAT" (3个字符)
我们不知道哪些帧对应 C,哪些对应 A,哪些对应 TCTC 的核心思想:不要管具体对齐,把所有可能的对齐方式都考虑进来,求和!
3.2 Blank 标记 ⭐
CTC 引入一个特殊标记 <blank> (通常用 - 或 ε 表示),含义是"这一帧不输出任何字符"。
扩展后的输出词汇表:{a, b, c, ..., z, <blank>} 或 {所有汉字, <blank>}
3.3 CTC 的工作流程
┌──────────┐
音频特征 ──→ │ Encoder │ ──→ 每帧一个概率分布(包含blank)
(T帧) │(RNN/CNN/ │ (T帧 × |Vocab+1| 维的矩阵)
│Conformer)│
└──────────┘
│
▼
┌─────────────┐
│ CTC 解码 │ ──→ 文字序列
└─────────────┘Step 1: Encoder 对每一帧输出一个概率分布
帧1: P(C)=0.3, P(A)=0.1, P(T)=0.1, P(--)=0.5, ...
帧2: P(C)=0.6, P(A)=0.2, P(T)=0.0, P(--)=0.2, ...
帧3: P(C)=0.1, P(A)=0.5, P(T)=0.1, P(--)=0.3, ...
...
帧12: P(C)=0.0, P(A)=0.1, P(T)=0.4, P(--)=0.5, ...
(-- 表示 blank)Step 2 : 定义一个映射函数 B(多对一的折叠规则)
折叠规则:
1. 去掉所有 blank(-)
2. 合并连续的相同字符
例子:
B("C C - A - - T T -") = "CAT" ✅
B("- C A - T - - - -") = "CAT" ✅
B("C - C A T - - - -") = "CCAT" → 不对!这会变成 "CCAT"
等等... 仔细看:
B("C - C A T") → 去blank → "CCAT" → 合并连续 → "CAT" ❌
不!先合并再去blank 还是 先去blank再合并?
正确顺序是:先合并连续相同字符,再去掉blank
B("C C - A - T T") → 合并连续: "C - A - T" → 去blank: "CAT" ✅
或者等价地:先去blank,再合并连续
B("C C - A - T T") → 去blank: "C C A T T" → 合并: "CAT" ✅🔥 面试关键问题:如何区分 "hello" 中的两个 l?
"h e l - l o"→ 合并连续相同 →"h e l - l o"→ 去blank →"h e l l o"= "hello" ✅如果没有 blank:
"h e l l o"→ 合并连续 →"h e l o"= "helo" ❌所以 blank 的另一个重要作用是:分隔连续的相同字符!
3.4 CTC 训练:前向算法
训练时,我们要最大化:
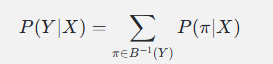
即:所有能折叠成目标文字 Y 的路径 π 的概率之和。
每条路径的概率 = 各帧概率的乘积(条件独立性假设):
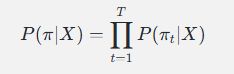
问题: 路径数量是指数级的!不可能枚举。
解决方案: 动态规划(前向-后向算法)
3.5 前向算法详解
关键构造: 在目标序列中插入 blank
目标: "CAT"
扩展: "- C - A - T -"
索引: 1 2 3 4 5 6 7
扩展序列长度 = 2U + 1 = 2×3 + 1 = 7
(每个字符前后都插入 blank)定义前向变量:
\\alpha(t, s) = \\text{在时刻 } t \\text{,处于扩展序列第 } s \\text{ 个位置的所有合法路径的概率和}
状态转移规则:
扩展序列: - C - A - T -
索引 s: 1 2 3 4 5 6 7
在每个时刻 t,位置 s 可以从哪里来?
规则:
(a) 自循环:s → s (停留在同一个位置)
(b) 向前一步:s-1 → s (移动到下一个位置)
(c) 跳一步:s-2 → s (跳过中间的blank,但仅当 s 和 s-2 不是同一个字符时)为什么有规则 (c) 的限制?
如果扩展序列是 "- C - A - T -"
位置5(-) 可以从位置3(-) 跳过来? 不行!因为位置3和5都是blank,
跳过4(A)会导致漏掉字符A
位置4(A) 可以从位置2(C) 跳过来? 可以!因为它们不同,
跳过blank(位置3)是合法的
位置6(T) 可以从位置4(A) 跳过来? 可以!因为它们不同公式:
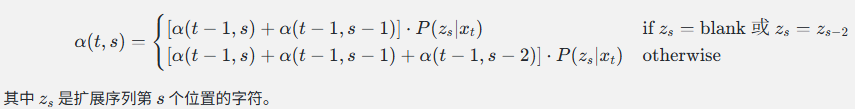
3.6 前向算法可视化
用一个简单的例子来画出整个格子:
目标: "AB"
扩展: "- A - B -" (长度5)
时间 t → 1 2 3 4 5 6
┌─────┬─────┬─────┬─────┬─────┬─────┐
s=1 (-) │α1,1 │α2,1 │α3,1 │α4,1 │α5,1 │α6,1 │
├─────┼─────┼─────┼─────┼─────┼─────┤
s=2 (A) │α1,2 │α2,2 │α3,2 │α4,2 │α5,2 │α6,2 │
├─────┼─────┼─────┼─────┼─────┼─────┤
s=3 (-) │ 0 │α2,3 │α3,3 │α4,3 │α5,3 │α6,3 │
├─────┼─────┼─────┼─────┼─────┼─────┤
s=4 (B) │ 0 │ 0 │α3,4 │α4,4 │α5,4 │α6,4 │
├─────┼─────┼─────┼─────┼─────┼─────┤
s=5 (-) │ 0 │ 0 │ 0 │α4,5 │α5,5 │α6,5 │
└─────┴─────┴─────┴─────┴─────┴─────┘
初始化:
α(1,1) = P(blank|x₁) ← 从 blank 开始
α(1,2) = P(A|x₁) ← 从 A 开始
α(1,s) = 0, s > 2 ← 不可能一开始就在后面的位置
最终结果:
P("AB"|X) = α(T, 4) + α(T, 5)
↑B结尾 ↑blank结尾
(必须走到最后一个或倒数第二个位置)转移示意:
α(t,s) 的来源箭头示意(以 s=4(B) 为例):
t-1 t
┌──┐ ┌──┐
│s=2│(A)──→│ │ ← 从A跳过blank到B(规则c,A≠B,合法)
├──┤ ↗ │s=4│
│s=3│(-)──→│(B)│ ← 从blank到B(规则b)
├──┤ ↗ │ │
│s=4│(B)──→│ │ ← 自循环(规则a)
└──┘ └──┘
所以: α(t,4) = [α(t-1,4) + α(t-1,3) + α(t-1,2)] × P(B|x_t)3.7 用代码实现 CTC 前向算法
import numpy as np
def ctc_forward(log_probs, targets, blank=0):
"""
CTC 前向算法
Args:
log_probs: (T, V) 每帧的对数概率,V是词汇表大小(含blank)
targets: 目标序列(不含blank),如 [1, 2] 代表 "AB"
blank: blank 的索引
Returns:
log_likelihood: log P(Y|X)
"""
T, V = log_probs.shape
U = len(targets)
# Step 1: 构建扩展序列 (插入blank)
# "AB" → [blank, A, blank, B, blank]
L = 2 * U + 1
extended = np.zeros(L, dtype=int)
for i in range(U):
extended[2 * i] = blank
extended[2 * i + 1] = targets[i]
extended[-1] = blank
print(f"目标序列: {targets}")
print(f"扩展序列: {extended}")
print(f"T={T} 帧, 扩展序列长度 L={L}")
# Step 2: 初始化 alpha 矩阵 (用log域计算避免下溢)
# 用 -inf 表示概率为 0
LOG_ZERO = -float('inf')
alpha = np.full((T, L), LOG_ZERO)
# t=0 时刻,只能从位置0(blank)或位置1(第一个字符)开始
alpha[0, 0] = log_probs[0, extended[0]] # blank
alpha[0, 1] = log_probs[0, extended[1]] # 第一个字符
# Step 3: 递推
for t in range(1, T):
for s in range(L):
# 当前扩展序列位置 s 对应的字符
current_label = extended[s]
# 规则 a: 自循环 (s → s)
score = alpha[t-1, s]
# 规则 b: 从前一个位置来 (s-1 → s)
if s >= 1:
score = np.logaddexp(score, alpha[t-1, s-1])
# 规则 c: 跳一步 (s-2 → s)
# 条件: s >= 2 且 当前不是blank 且 当前字符 ≠ s-2位置的字符
if s >= 2 and current_label != blank and current_label != extended[s-2]:
score = np.logaddexp(score, alpha[t-1, s-2])
# 乘以当前帧输出该字符的概率
alpha[t, s] = score + log_probs[t, current_label]
# Step 4: 最终结果
# 合法的结束位置:最后一个blank(L-1) 或 最后一个字符(L-2)
log_likelihood = np.logaddexp(alpha[T-1, L-1], alpha[T-1, L-2])
return log_likelihood, alpha
# ========== 测试 ==========
np.random.seed(42)
T = 8 # 8 帧
V = 4 # 词汇表: {0:blank, 1:A, 2:B, 3:C}
# 模拟 Encoder 输出的 log 概率
logits = np.random.randn(T, V)
# Softmax + log
log_probs = logits - np.log(np.sum(np.exp(logits), axis=1, keepdims=True))
# 目标: "AB" → [1, 2]
targets = [1, 2]
log_likelihood, alpha = ctc_forward(log_probs, targets, blank=0)
print(f"\nlog P('AB'|X) = {log_likelihood:.4f}")
print(f"P('AB'|X) = {np.exp(log_likelihood):.6f}")
# 可视化 alpha 矩阵
import matplotlib.pyplot as plt
plt.figure(figsize=(10, 5))
# 将 -inf 替换为一个很小的数用于显示
alpha_display = np.where(alpha == -float('inf'), np.nan, alpha)
plt.imshow(alpha_display.T, aspect='auto', origin='lower', cmap='viridis')
plt.colorbar(label='Log Probability')
plt.xlabel('Time (t)')
plt.ylabel('Extended label index (s)')
labels = ['blank', 'A', 'blank', 'B', 'blank']
plt.yticks(range(len(labels)), labels)
plt.title('CTC Forward Algorithm — Alpha Matrix')
plt.show()第四步:CTC 训练与解码
4.1 CTC Loss
训练时,我们最大化 (P(Y|X)),等价于最小化:
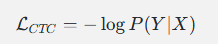
PyTorch 已经内置了 CTC Loss:
import torch
import torch.nn as nn
# ========== PyTorch CTC Loss 使用方法 ==========
ctc_loss = nn.CTCLoss(blank=0, reduction='mean', zero_infinity=True)
# 模拟数据
T = 50 # 输入序列长度(帧数)
B = 4 # batch size
V = 30 # 词汇表大小(含blank)
U_max = 10 # 最大目标序列长度
# Encoder 输出 (需要 log_softmax)
# 注意: PyTorch CTC 要求输入形状 (T, B, V)
log_probs = torch.randn(T, B, V).log_softmax(dim=2)
# 目标序列 (不含blank, 所有batch的目标拼接成一维)
targets = torch.randint(1, V, (B, U_max)) # (B, U_max), 值在 [1, V-1]
# 输入长度和目标长度
input_lengths = torch.full((B,), T, dtype=torch.long)
target_lengths = torch.randint(3, U_max+1, (B,), dtype=torch.long)
# 计算 CTC Loss
loss = ctc_loss(log_probs, targets, input_lengths, target_lengths)
print(f"CTC Loss: {loss.item():.4f}")4.2 CTC 解码方法
训练完模型后,推理时我们需要解码------从 Encoder 输出的概率矩阵中找到最可能的文字。
方法1:贪心解码 (Greedy Decoding)
每帧取概率最大的标记 → 折叠 → 文字
帧: 1 2 3 4 5 6 7 8
最大: - C C - A - T T
折叠: → "C - A - T" → 去blank、合并 → "CAT"def ctc_greedy_decode(log_probs, blank=0, idx_to_char=None):
"""
CTC 贪心解码
Args:
log_probs: (T, V) 每帧的log概率
blank: blank索引
idx_to_char: 索引到字符的映射
Returns:
decoded: 解码后的字符列表
"""
# Step 1: 每帧取 argmax
best_path = np.argmax(log_probs, axis=1)
print(f"Best path (argmax): {best_path}")
# Step 2: 折叠 — 合并连续相同 + 去掉blank
decoded = []
prev = None
for idx in best_path:
if idx != prev: # 合并连续相同
if idx != blank: # 去掉blank
decoded.append(idx)
prev = idx
if idx_to_char:
decoded = [idx_to_char[i] for i in decoded]
return decoded
# 测试
np.random.seed(0)
T, V = 12, 5 # 12帧, 词汇表 {0:blank, 1:C, 2:A, 3:T, 4:E}
idx_to_char = {0: '-', 1: 'C', 2: 'A', 3: 'T', 4: 'E'}
# 构造一个"比较像CAT"的概率矩阵
log_probs = np.full((T, V), -5.0) # 初始化很小的概率
# 让前几帧倾向C,中间帧倾向A,后面帧倾向T
for t in range(3):
log_probs[t, 1] = -0.2 # C
log_probs[t, 0] = -1.0 # blank
for t in range(3, 5):
log_probs[t, 0] = -0.1 # blank
for t in range(5, 8):
log_probs[t, 2] = -0.3 # A
log_probs[t, 0] = -1.5
for t in range(8, 10):
log_probs[t, 0] = -0.1 # blank
for t in range(10, 12):
log_probs[t, 3] = -0.2 # T
log_probs[t, 0] = -1.0
result = ctc_greedy_decode(log_probs, blank=0, idx_to_char=idx_to_char)
print(f"Decoded: {''.join(result)}")方法2:Beam Search 解码
贪心解码可能不是全局最优的。Beam Search 保留 top-k 个候选:
Beam Width = 3
时刻1: 保留概率最高的3个前缀
→ ["-", "C", "A"]
时刻2: 每个前缀扩展所有可能字符,保留总概率最高的3个
→ ["C-", "CC", "-C"] (举例)
...每步都保留 top-k
最终: 选概率最高的那个前缀def ctc_beam_search(log_probs, blank=0, beam_width=5, idx_to_char=None):
"""
CTC Beam Search 解码(简化版)
Args:
log_probs: (T, V) 每帧的log概率
blank: blank索引
beam_width: beam 宽度
Returns:
best_sequence: 最佳解码序列
"""
T, V = log_probs.shape
# 每个 beam 是 (前缀tuple, log概率)
# 用两个字典分别追踪以blank结尾和以非blank结尾的前缀
beams = {(): 0.0} # 初始: 空前缀, log概率=0
for t in range(T):
new_beams = {}
for prefix, score in beams.items():
for c in range(V):
new_score = score + log_probs[t, c]
if c == blank:
# blank不改变前缀
new_prefix = prefix
elif len(prefix) > 0 and c == prefix[-1]:
# 和前缀最后一个字符相同
# 如果上一步是blank,则可以添加新字符(但简化版这里直接合并)
new_prefix = prefix # 简化:合并连续相同
else:
new_prefix = prefix + (c,)
if new_prefix in new_beams:
new_beams[new_prefix] = np.logaddexp(new_beams[new_prefix], new_score)
else:
new_beams[new_prefix] = new_score
# 剪枝: 只保留 top beam_width 个
sorted_beams = sorted(new_beams.items(), key=lambda x: x[1], reverse=True)
beams = dict(sorted_beams[:beam_width])
# 返回概率最高的前缀
best_prefix = max(beams, key=beams.get)
if idx_to_char:
return ''.join([idx_to_char[i] for i in best_prefix])
return best_prefix
# 测试
result_beam = ctc_beam_search(log_probs, blank=0, beam_width=5, idx_to_char=idx_to_char)
print(f"Beam Search Decoded: {result_beam}")注意:上面的 Beam Search 是简化版本。完整的 CTC Prefix Beam Search 需要正确处理"以blank结尾"和"以非blank结尾"两种情况,以正确处理重复字符。面试中理解核心思想即可。
第五步:CTC 的条件独立性假设 ⭐(面试重点)
5.1 CTC 的核心假设
回忆 CTC 路径概率的计算:
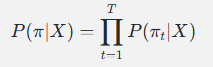
这意味着:每一帧的输出只依赖于输入 X(通过 Encoder),不依赖于其他帧的输出。
换句话说:各帧的输出之间是条件独立的(给定 X)。
5.2 这带来什么问题?
假设 Encoder 对输入 X 的第 t 帧预测:
P("猫"|x_t) = 0.4
P("毛"|x_t) = 0.35
P("帽"|x_t) = 0.25
CTC 选了"猫"—— 但它不知道前面已经输出了"小",
如果知道前面是"小","猫"更合理;
如果前面是"帽子的","帽"更合理。
CTC 做不到这种"根据已输出内容动态调整后续输出"的能力!这就是 CTC 的根本局限: 它不能建模输出标签之间的依赖关系。
5.3 对比
| 特性 | CTC | Attention Seq2Seq |
|---|---|---|
| 输出依赖 | 各帧独立(条件独立假设) | Decoder自回归,能看到之前的输出 |
| 对齐方式 | 隐式对齐(求和所有路径) | 显式对齐(Attention权重) |
| 解码速度 | 快(非自回归/并行) | 慢(自回归,逐步生成) |
| 适合流式 | ✅ 天然支持 | ❌ 需要整个输入 |
5.4 CTC 解决独立性问题的方法
虽然 CTC 本身有条件独立假设,实际使用中通过以下方式缓解:
-
外部语言模型 (LM):解码时结合 N-gram 或 Neural LM(shallow fusion)
-
Hybrid CTC/Attention:联合训练 CTC + Attention,取长补短(WeNet 的做法)
-
强大的 Encoder:Conformer 等强 Encoder 已经在编码阶段捕获了丰富的上下文
第六步:CTC 优缺点完整总结 ⭐⭐⭐
优点
✅ 不需要帧级对齐标注 — 只需要 (音频, 文字) 对
✅ 训练简单 — 只需要一个 Encoder + CTC Loss
✅ 天然支持流式 — 每帧独立输出,不需要看到未来
✅ 解码速度快 — 尤其贪心解码
✅ 单调对齐 — 输入输出顺序一致(适合ASR这种单调任务)缺点
❌ 条件独立性假设 — 不能建模输出间依赖
❌ 需要输入长度 ≥ 输出长度 — 否则无法形成合法路径
❌ 只适合单调对齐任务 — 不适合机器翻译等重排序任务
❌ 输出是 token 级别 — 没有显式的注意力对齐,可解释性差
❌ 容易出现尖峰问题 (peaky behavior) — 大部分帧输出 blank,
真正的信息集中在少数帧Peaky Behavior(尖峰行为)
帧: 1 2 3 4 5 6 7 8 9 10 11 12
CTC输出: - - - C - - A - - - T -
↑ ↑ ↑
大部分帧输出blank,真正的字符只在很少几帧出现"尖峰"
这导致:
- 对 Encoder 的利用不够充分
- 大量帧的梯度信号很弱(都是blank)第七步:CTC 在实际框架中的应用
7.1 用 PyTorch 搭一个最简单的 CTC-based ASR 模型
import torch
import torch.nn as nn
class SimpleCTCModel(nn.Module):
"""
最简单的 CTC ASR 模型:
FBank → 几层LSTM → Linear → CTC
"""
def __init__(self, input_dim=80, hidden_dim=256, num_layers=3, vocab_size=4233):
"""
Args:
input_dim: 输入特征维度(FBank=80)
hidden_dim: LSTM 隐藏层维度
num_layers: LSTM 层数
vocab_size: 词汇表大小(含blank,blank=0)
"""
super().__init__()
# Encoder: 双向 LSTM
self.encoder = nn.LSTM(
input_size=input_dim,
hidden_size=hidden_dim,
num_layers=num_layers,
batch_first=True,
bidirectional=True,
dropout=0.1
)
# 投影层: 将 LSTM 输出映射到词汇表大小
self.fc = nn.Linear(hidden_dim * 2, vocab_size) # *2 因为双向
self.ctc_loss = nn.CTCLoss(blank=0, reduction='mean', zero_infinity=True)
def forward(self, x, x_lengths):
"""
Args:
x: (B, T, 80) FBank 特征
x_lengths: (B,) 每个样本的实际长度
Returns:
log_probs: (T, B, V) 用于 CTC Loss
"""
# Pack padded sequence for efficiency
packed = nn.utils.rnn.pack_padded_sequence(
x, x_lengths.cpu(), batch_first=True, enforce_sorted=False
)
output, _ = self.encoder(packed)
output, _ = nn.utils.rnn.pad_packed_sequence(output, batch_first=True)
# output: (B, T, hidden*2)
logits = self.fc(output) # (B, T, V)
log_probs = logits.log_softmax(dim=2) # (B, T, V)
# CTC 要求 (T, B, V)
log_probs = log_probs.permute(1, 0, 2)
return log_probs
def compute_loss(self, log_probs, targets, input_lengths, target_lengths):
"""计算 CTC Loss"""
return self.ctc_loss(log_probs, targets, input_lengths, target_lengths)
def decode(self, log_probs):
"""贪心解码"""
# log_probs: (T, B, V)
# argmax
best_path = log_probs.argmax(dim=2).T # (B, T)
results = []
for b in range(best_path.shape[0]):
# 折叠
path = best_path[b].tolist()
decoded = []
prev = None
for idx in path:
if idx != prev:
if idx != 0: # 0 = blank
decoded.append(idx)
prev = idx
results.append(decoded)
return results
# ========== 测试模型 ==========
model = SimpleCTCModel(input_dim=80, hidden_dim=256, num_layers=3, vocab_size=100)
# 模拟一个batch
B = 2
T1, T2 = 150, 200 # 两个样本的帧数不同
T_max = max(T1, T2)
x = torch.randn(B, T_max, 80) # FBank 特征
x_lengths = torch.tensor([T1, T2])
# 前向传播
log_probs = model(x, x_lengths)
print(f"Encoder output shape: {log_probs.shape}") # (T, B, V)
# 模拟目标
targets = torch.randint(1, 100, (B, 15)) # 两个样本各15个字
target_lengths = torch.tensor([12, 15])
# 计算 Loss
loss = model.compute_loss(log_probs, targets, x_lengths, target_lengths)
print(f"CTC Loss: {loss.item():.4f}")
# 贪心解码
decoded = model.decode(log_probs)
print(f"Decoded lengths: {[len(d) for d in decoded]}")
print(f"Decoded[0] (前20个token): {decoded[0][:20]}")7.2 Subsampling(下采样)------ 实际系统必备
实际的 ASR 系统中,原始 FBank 帧率太高了(每秒 100 帧),直接输入 Encoder 计算量巨大。通常会先下采样(通常 4 倍):
原始: 100 帧/秒
↓ 4倍下采样(Conv2d stride=2 做两次)
下采样后: 25 帧/秒
方法:
1. Conv2d Subsampling (Conformer/WeNet常用)
2. Stacking + Stride (传统方法: 把连续4帧拼起来)class ConvSubsampling(nn.Module):
"""
2层卷积实现 4 倍下采样(WeNet / Conformer 中的标准做法)
"""
def __init__(self, input_dim=80, output_dim=256):
super().__init__()
self.conv = nn.Sequential(
nn.Conv2d(1, 32, kernel_size=3, stride=2, padding=1), # 2倍下采样
nn.ReLU(),
nn.Conv2d(32, 32, kernel_size=3, stride=2, padding=1), # 再2倍 → 共4倍
nn.ReLU(),
)
# 计算卷积输出维度
# 输入: (B, 1, T, 80), 经过两次 stride=2:
# 频率维度: 80 → 40 → 20
# 时间维度: T → T/2 → T/4
self.linear = nn.Linear(32 * 20, output_dim) # 32通道 × 20频率bins
def forward(self, x, x_lengths):
"""
Args:
x: (B, T, 80)
x_lengths: (B,)
Returns:
out: (B, T/4, output_dim)
out_lengths: (B,)
"""
# 添加 channel 维度
x = x.unsqueeze(1) # (B, 1, T, 80)
x = self.conv(x) # (B, 32, T/4, 20)
B, C, T_sub, F = x.shape
x = x.permute(0, 2, 1, 3).contiguous().view(B, T_sub, C * F) # (B, T/4, 32*20)
x = self.linear(x) # (B, T/4, output_dim)
# 更新长度
out_lengths = ((x_lengths - 1) // 2 - 1) // 2 + 1 # 近似 T/4
return x, out_lengths
# 测试
subsampling = ConvSubsampling(input_dim=80, output_dim=256)
x = torch.randn(2, 200, 80)
x_lens = torch.tensor([200, 150])
out, out_lens = subsampling(x, x_lens)
print(f"Input: {x.shape} → Output: {out.shape}")
print(f"Input lengths: {x_lens} → Output lengths: {out_lens}")
# 200帧 → 约50帧, 4倍下采样🔥 面试常问:为什么要做 Subsampling?
减少计算量:Transformer/Conformer 的 self-attention 复杂度是 (O(T^2)),下采样 4 倍可以减少 16 倍的 attention 计算
CTC 需要:CTC 要求输入长度 ≥ 输出长度。中文 ASR 中一个字约对应 4-8 帧(下采样后约 1-2 帧),下采样后更接近输出长度
帧率降低但信息不丢:卷积可以聚合局部信息
第八步:CTC 与其他方法的对比预览
这个表非常重要,面试必考:
CTC Attention Transducer (RNN-T)
───────── ───────────── ──────────────────
结构 Encoder only Encoder-Decoder Encoder + Prediction
Network + Joiner
对齐方式 隐式对齐 显式对齐 隐式对齐
(前向算法求和) (Attention权重) (前向算法求和)
输出依赖 ❌ 条件独立 ✅ 自回归 ✅ Prediction Network
(看到之前输出) (看到之前输出)
流式支持 ✅ 天然支持 ❌ 需要整个输入 ✅ 天然支持
单调性 ✅ 单调 ❌ 可非单调 ✅ 单调
训练难度 简单 中等 较难
(内存消耗大)
代表框架 WeNet(CTC分支) ESPnet Google USM
FunASR Whisper 字节Seed-ASR
实际使用 通常和Attention 通常和CTC联合 流式场景首选
联合训练 训练(Hybrid)📝 Day 2 面试模拟题
Q1: CTC 是什么?解决了什么问题?
CTC (Connectionist Temporal Classification) 是一种用于序列到序列映射的训练准则,主要解决输入输出不等长且没有帧级对齐标注的问题。它通过引入 blank 标记,枚举所有可能的对齐路径并求和,使用动态规划(前向-后向算法)高效计算。这样模型只需要 (音频, 文字) 对就能训练,不需要精确的帧-字对齐。
Q2: CTC 中 blank 的作用是什么?
Blank 有两个核心作用:
处理"不输出"的帧:语音中很多帧不对应任何有意义的字符(如静音、过渡段),blank 允许模型在这些帧"不输出"
分隔连续的相同字符:比如 "hello" 中的两个 l,如果没有 blank,"ll" 会被合并成 "l"。通过 "l-l"(中间插入 blank),折叠后得到 "ll"
Q3: CTC 的条件独立性假设是什么?有什么影响?
CTC 假设各帧的输出在给定输入 X 的条件下是条件独立的,即 (P(\pi|X) = \prod_t P(\pi_t|X))。这意味着 CTC 不能建模输出标签之间的依赖关系------每帧的预测不会参考之前已输出的内容。
影响:可能产生不合理的输出序列(如不通顺的文字)。实际中通过外部语言模型 (浅融合/重打分)或与 Attention 联合训练(Hybrid CTC/Attention)来弥补。
Q4: CTC 有什么优缺点?
优点:
不需要帧级对齐标注,只需 (音频, 文字) 对
训练简单,只需 Encoder + CTC Loss
天然支持流式识别(每帧独立输出)
解码速度快
缺点:
条件独立性假设,不能建模输出间依赖
输入长度必须 ≥ 输出长度
只适合单调对齐任务
Peaky behavior:大部分帧输出 blank,信息集中在少数帧
Q5: Greedy Decoding 和 Beam Search 的区别?
Greedy Decoding:每帧取概率最大的标记,然后折叠。速度最快,但只考虑了局部最优,可能不是全局最优。
Beam Search:每步保留概率最高的 top-k 个候选前缀,逐帧扩展。能搜索到更好的解,但速度较慢。还可以结合外部语言模型(LM fusion)进一步提升效果。
实际使用中,如果对延迟要求高,用 Greedy;对准确率要求高,用 Beam Search + LM。
Q6: 为什么实际系统中要做 Subsampling?
减少计算量:原始 FBank 帧率 100帧/秒,Transformer self-attention 复杂度 O(T²),4倍下采样减少 16 倍计算
降低内存占用:序列更短,注意力矩阵更小
CTC 约束:CTC 要求输入长度 ≥ 输出长度,下采样后帧数与字符数更匹配
不丢信息:卷积下采样通过卷积核聚合局部信息,比简单跳帧更好
✅ Day 2 完成!核心知识清单
✅ ASR 的问题定义:输入长序列→输出短序列,对齐未知
✅ 传统 ASR Pipeline:AM + LM + Decoder(了解即可)
✅ 端到端三大范式:CTC / Attention / Transducer
✅ CTC 的核心思想:blank + 所有路径求和
✅ Blank 的两个作用:处理"不输出"帧 + 分隔相同字符
✅ CTC 前向算法:扩展序列 + 动态规划
✅ CTC 折叠规则:合并连续相同 + 去blank
✅ CTC Loss = -log P(Y|X)
✅ 贪心解码 vs Beam Search
✅ 条件独立性假设及其影响
✅ CTC 优缺点(面试必背)
✅ CTC Peaky Behavior
✅ Subsampling 的作用
✅ CTC vs Attention vs Transducer 对比(预览)🚀 Day 3 预告
明天我们学习 ASR 的另外两大范式:
-
Attention-based Seq2Seq:Encoder-Decoder + Attention 机制
-
Transducer (RNN-T):CTC 的自然升级版
-
Hybrid CTC/Attention:WeNet 的核心架构
-
三种方法的深度对比
💡 作业:
手动在纸上画出 "CAT" 的 CTC 前向算法格子图,标出所有合法转移
不看笔记,用自己的话解释 CTC 的 blank 为什么必要
用自己的话解释 CTC 条件独立性假设的影响
跑通上面的代码,特别是手写前向算法那段