摘要:
越来越多的时序任务需要把预测的时间范围拓展到更远的未来(即长期预测 )。 近年来针对时间序列预测的深度模型(已经取得了不错的研究成果,解决了不少传统方法的问题。其中以基于 Transformer 的模型表现尤为突出Transformer 之所以表现好,核心是其自带的自注意力机制------ 这个机制让它在为序列数据(时间序列是典型的序列数据)建模长程依赖关系时,具备天然的巨大优势(能捕捉到序列中相隔很远的时间点之间的关联);
Transformer模型在长期预测任务中的不足
**长序列本身的模式纠缠,导致有效时间依赖难以捕捉:**直接从超长的时间序列里找不同时间点的关联(时间依赖)是不可靠的。因为长序列里会混杂着趋势、季节、噪声等多种时间模式,这些模式相互缠绕、彼此干扰,会把真正有价值的时间关联给掩盖住,让模型无法精准识别出哪些时间点之间存在真实、有效的依赖关系。
**Transformer 的计算瓶颈:**其核心的自注意力机制,计算复杂度是序列长度的二次方(序列越长,计算量、内存占用会呈指数级暴涨),直接用在长序列预测中,计算成本高到根本无法实现。
**现有改进版引发信息利用瓶颈:**为了解决计算问题,之前的 Transformer 类预测模型,都把思路放在将自注意力改进为稀疏版本上,虽然大幅提升了计算效率、性能也有改善,但依然只计算单个时间点的关联、聚合孤立的单点特征。这种稀疏化改进,本质是通过减少点与点之间的连接来提效率,而这种无差别的稀疏点连接,会直接导致模型丢失大量有效信息(比如跨周期的关键关联),效率提上去了,但信息利用却打了折扣,最终形成了时间序列长期预测的核心瓶颈。
Autoformer
模型的总体结构如图所示,与Transformer结构类似。
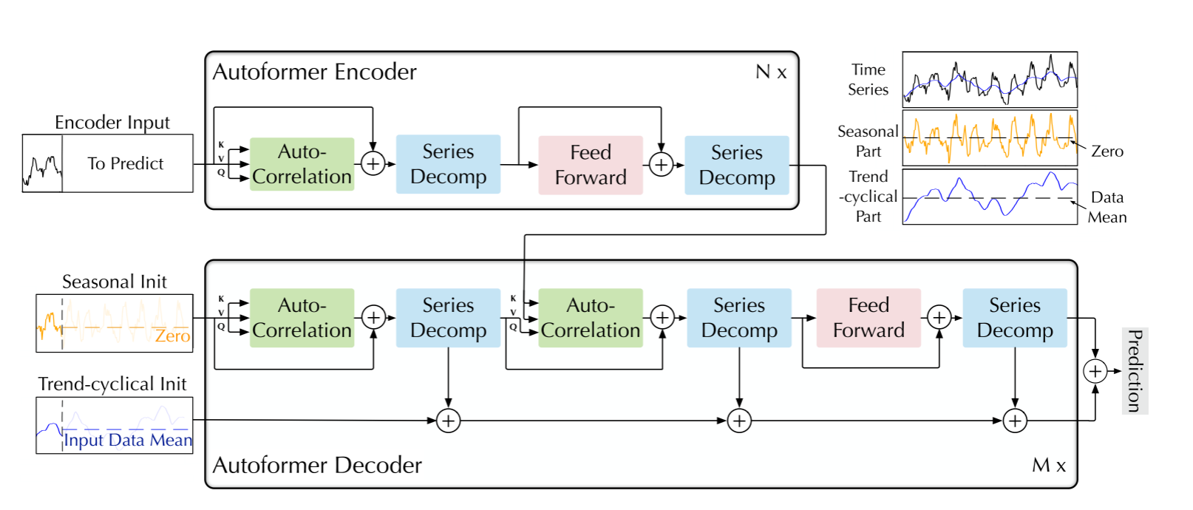
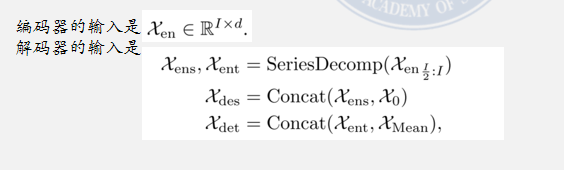
通过Series Decomp模块将时间序列分解为季节部分和提取的趋势-周期部分;
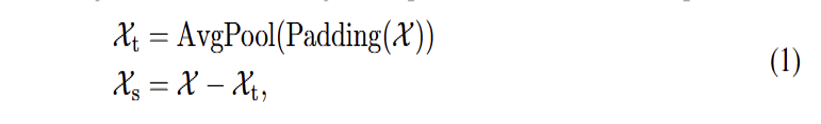
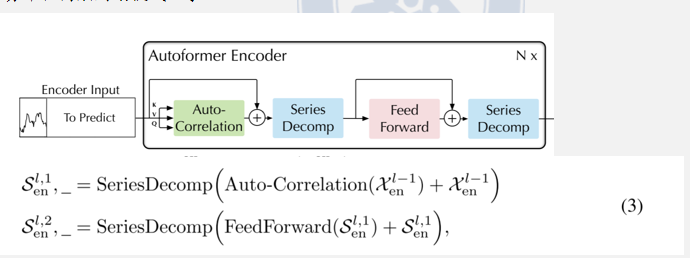
编码器的核心任务是专门建模序列的季节分量;需要把趋势分量剥离出去,避免缓慢变化的趋势干扰高频周期模式的学习。
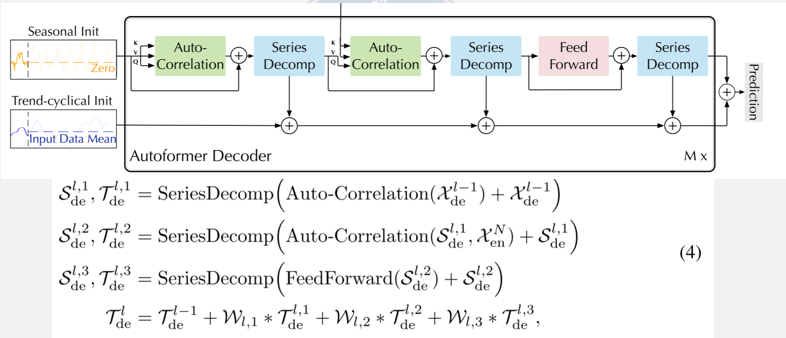
Autoformer 解码器的结构与工作逻辑,核心是分开建模趋势和季节分量+渐进式优化预测。 **趋势 - 周期分量累积结构:**专门处理缓慢变化的趋势和周期部分,通过逐步累积的方式,从中间隐藏变量里提取潜在趋势。
**堆叠的 Auto-Correlation 机制:**专门建模高频波动的季节分量,用「自相关 + 循环移位聚合」来捕捉周期规律。
自相关机制:通过计算序列的自相关来发现基于周期的相关性,并通过时间延迟聚合来聚集相似的子序列。
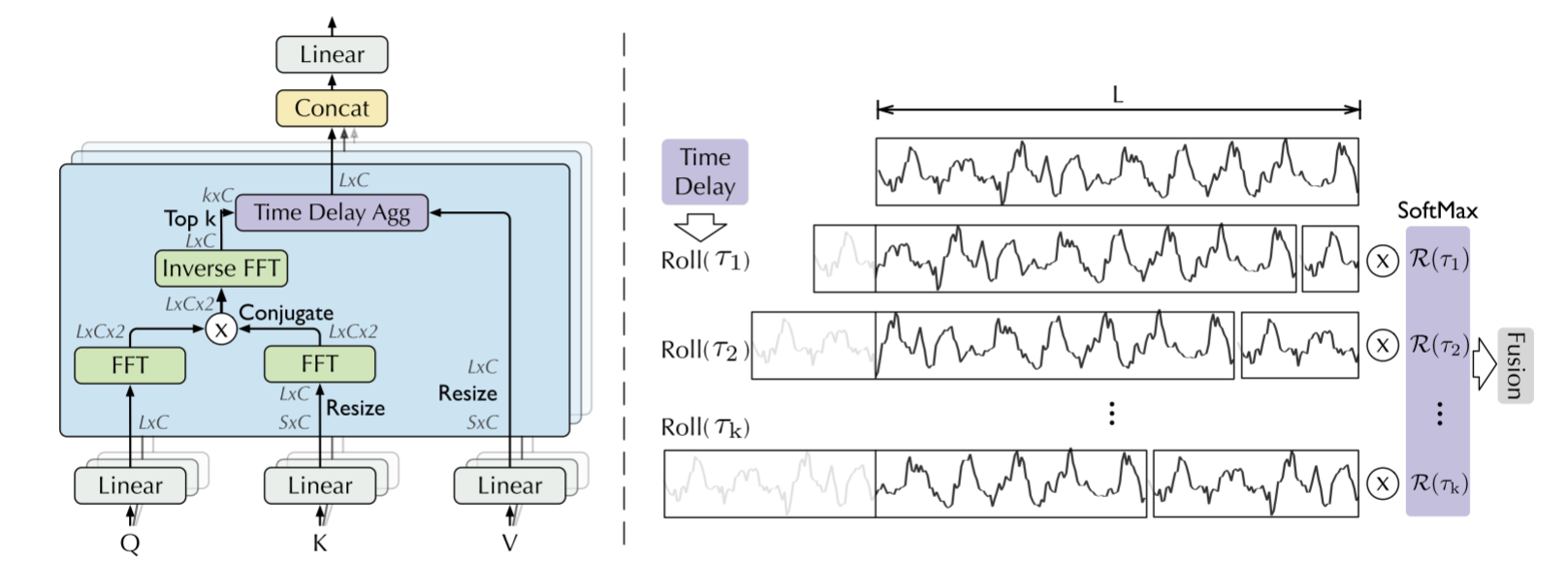
我认为自相关机制可以看作一种与稀疏自注意力思路不同的相关性计算方式。它和普通自注意力机制一样,都需要先通过线性变换得到 Q、K、V;不同之处在于,Q 和 K 并不会在时域进行两两之间的点积运算,而是先分别通过 FFT 变换到频域,在频域内进行逐元素相乘(并非矩阵乘法),再通过逆 FFT 变换回时域,得到自相关序列,然后在自相关序列中选取权重最大的 k 个延迟 τ。之后根据这些延迟对 V 进行循环移位,让序列在时间上对齐,最后按照自相关权重对移位后的 V 进行加权融合,得到最终输出。
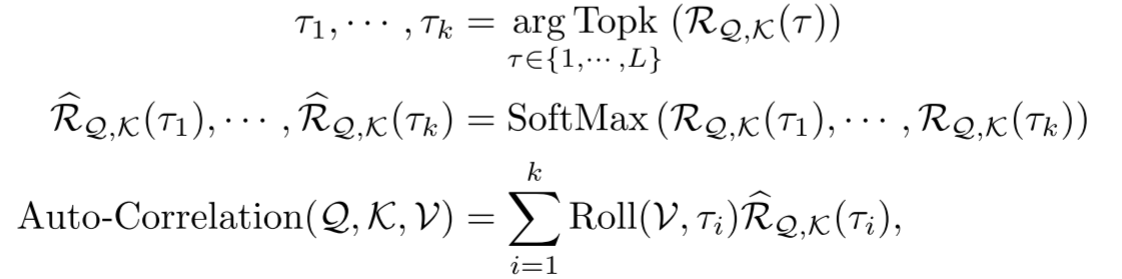
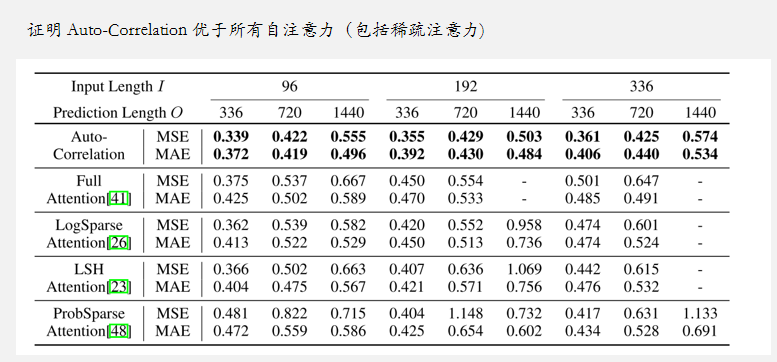
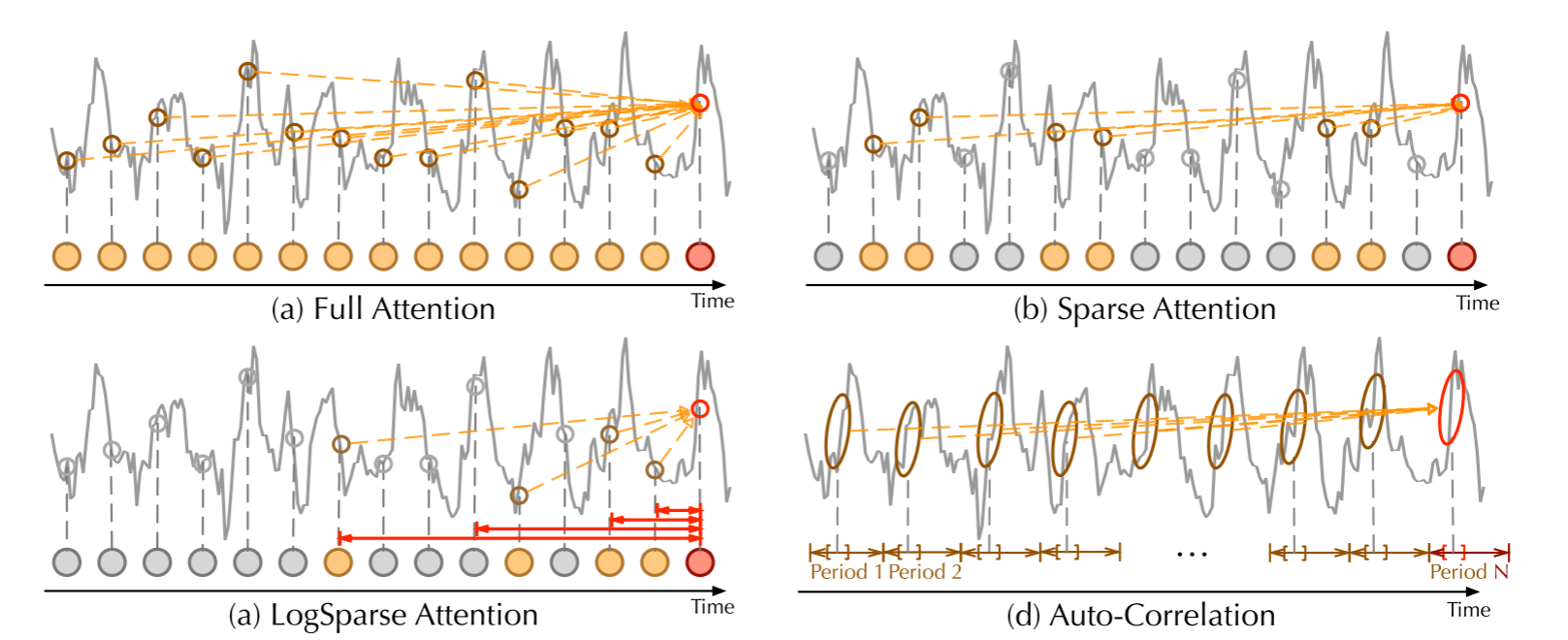
与不同注意力机制的对比:
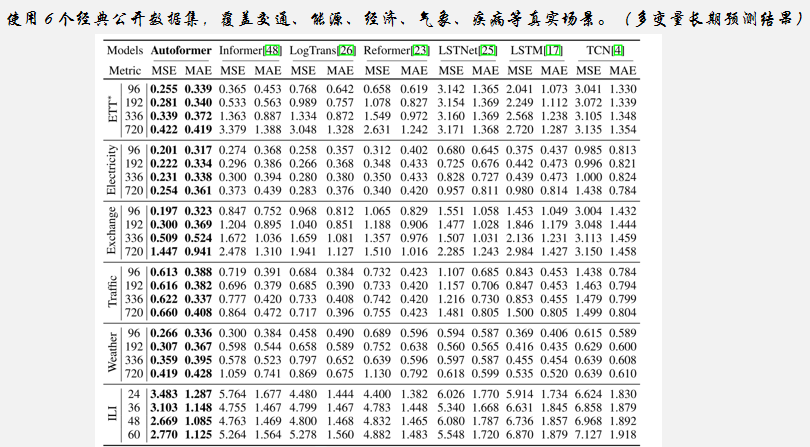
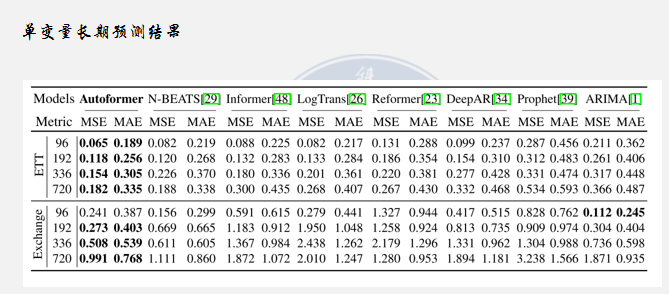
实验