采用YOLO5模型进行模型预测时,其输入数据格式应满足指定的格式要求,如果是单张图片,其输入格式要求为1,3,640,640,具体含义为1张3通道的高640、宽640的图片,如下图所示:

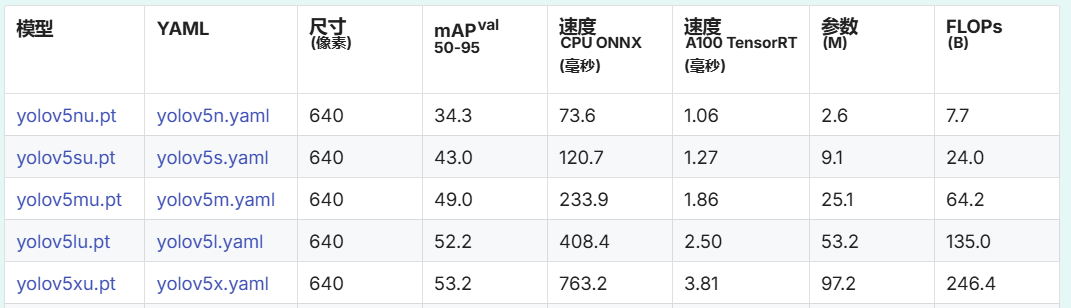
更通用的描述是输入数据的格式遵循BCHW格式(Batch、Channel、Height、Width),其中:
1)B:代表Batch,即一次推理处理的图片数量,有x张图片B应该是x,同时Microsoft.ML.OnnxRuntime模块返回的结果数量也为x;
2)C:代表Channel,即图像的色彩通道数,3表示RGB三通道彩色图像;
3)H:代表Height,即输入图像的高度,单位是像素;
4)W:代表Width,即输入图像的宽度,单位是像素。
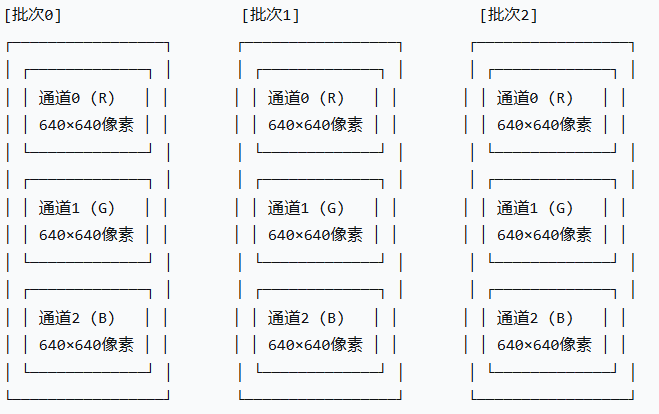
以处理3张图片为例,输入数据的顺序如下:
1)第1张图的所有数据、第2张图的所有数据、第3张图的所有数据;
2)单张图数据内,按通道优先的方式存储,先存储R通道的所有640×640像素数据(从左向右,从上向下),再存储G通道所有像素数据、B通道所有像素数据。
大致的示意图如下(示意图来自DeepSeek):
 除了上述要求,还需要对输入的图像数据归一化,以便加速模型收敛、提高泛化能力,更详细的说明见参考文献3。
除了上述要求,还需要对输入的图像数据归一化,以便加速模型收敛、提高泛化能力,更详细的说明见参考文献3。
基于上述分析,采用YOLO5模型进行模型预测时主要对输入图像进行3类处理:
1)图片尺寸处理,将原始图片调整到模型要求的尺寸,本文中为640*640,由于图片通常不为正方形,需要将图片等比例缩放至宽或者高为640,然后将另一维度的数据填充至640,也即Letterbox缩放,详细说明可见参考文献4-5,前一篇文章中预处理函数内也有类似的代码;
2)数据归一化;
3)数据格式转换,将图片数据处理为上面所述的BCHW格式。
OpenCvSharp提供了不少图片处理函数,可以减少数据预处理代码量,但OpenCvSharp的图片数据默认为BGR方式,需要将其转换为RGB,因此在C#内调用Microsoft.ML.OnnxRuntime +OpenCvSharp+YOLO5进行模型预测时图片数据预处理通常包含4个方面:
1)图片缩放及填充;
2)图片从BGR转换为RGB;
3)数据归一化;
4)数据格式转换(BCHW)。
图片数据预处理之后,即可调用Microsoft.ML.OnnxRuntime模块使用YOLO5模型进行模型预测。
参考文献:
1https://docs.ultralytics.com/zh/modes/predict
2https://blog.csdn.net/weixin_42513209/article/details/156468458
3https://blog.csdn.net/weixin_66423182/article/details/131076920