文章目录
- 引言
- 1、背景与核心动因:为什么必须做数据脱敏?
-
- [1.1 数据安全合规的刚性要求](#1.1 数据安全合规的刚性要求)
- [1.2 企业数据资产的风险防控需求](#1.2 企业数据资产的风险防控需求)
- [1.3 数据流通与价值释放的前提保障](#1.3 数据流通与价值释放的前提保障)
- 2、数据脱敏的核心分类与适用场景
-
- [2.1 按脱敏时机与生效范围:静态脱敏 vs 动态脱敏](#2.1 按脱敏时机与生效范围:静态脱敏 vs 动态脱敏)
- [2.2 按数据处理时效性:批量脱敏 vs 实时脱敏](#2.2 按数据处理时效性:批量脱敏 vs 实时脱敏)
- [2.3 补充分类](#2.3 补充分类)
- 3、行业通用的数据脱敏实现方法与选型对比
-
- [3.1 主流脱敏技术方案详解](#3.1 主流脱敏技术方案详解)
- [3.2 不同方案的优劣势与适用场景对比](#3.2 不同方案的优劣势与适用场景对比)
- 4、GCP敏感数据保护(SDP/DLP)核心能力介绍
-
- [4.1 GCP SDP是什么?](#4.1 GCP SDP是什么?)
- [4.2 核心功能模块与脱敏能力](#4.2 核心功能模块与脱敏能力)
- [4.3 GCP生态原生集成优势](#4.3 GCP生态原生集成优势)
- [5、GCP SDP数据脱敏全流程实操](#5、GCP SDP数据脱敏全流程实操)
-
- [5.1 前置环境与权限准备](#5.1 前置环境与权限准备)
-
- [5.1.1 GCP账号与项目创建](#5.1.1 GCP账号与项目创建)
- [5.1.2 启用核心API服务](#5.1.2 启用核心API服务)
- [5.1.3 服务账号创建与密钥配置](#5.1.3 服务账号创建与密钥配置)
- [5.1.4 测试环境准备:BigQuery 数据集与敏感测试表构建](#5.1.4 测试环境准备:BigQuery 数据集与敏感测试表构建)
- [5.2 第一步:敏感数据自动发现与分类分级](#5.2 第一步:敏感数据自动发现与分类分级)
-
- [5.2.1 基于 SDP 创建数据发现扫描任务](#5.2.1 基于 SDP 创建数据发现扫描任务)
- [5.2.2 敏感数据识别结果核验与标签管理](#5.2.2 敏感数据识别结果核验与标签管理)
- [5.3 第二步:GCP 生态 3 种核心脱敏方案落地](#5.3 第二步:GCP 生态 3 种核心脱敏方案落地)
-
- [5.3.1 方案 1:BigQuery 原生 SQL 零代码脱敏(轻量场景)](#5.3.1 方案 1:BigQuery 原生 SQL 零代码脱敏(轻量场景))
-
- [5.3.1.1 字符替换/掩码脱敏实现](#5.3.1.1 字符替换/掩码脱敏实现)
- [5.3.1.2 内置加密函数强脱敏实现](#5.3.1.2 内置加密函数强脱敏实现)
- [5.3.2 方案 2:DLP API + 代码实现灵活脱敏(定制化场景)](#5.3.2 方案 2:DLP API + 代码实现灵活脱敏(定制化场景))
- [5.4 脱敏效果验证与合规审计](#5.4 脱敏效果验证与合规审计)
- 6、落地最佳实践与避坑指南
-
- [6.1 不同业务场景的脱敏方案选型建议](#6.1 不同业务场景的脱敏方案选型建议)
- [6.2 性能与可用性平衡的核心技巧](#6.2 性能与可用性平衡的核心技巧)
- [6.3 常见踩坑问题与解决方案](#6.3 常见踩坑问题与解决方案)
- 7、总结与拓展
引言
在《数据安全法》《个人信息保护法》(PIPL)、欧盟GDPR等全球合规监管框架下,企业对个人敏感信息(PII)的保护已从"可选项"变为"刚性要求"。数据脱敏作为数据安全治理的核心能力,能够实现"数据可用不可见",在平衡安全合规与数据价值释放的同时,规避数据泄露的合规风险与业务风险。
本文将从脱敏的核心理论出发,拆解行业通用实现方案,再带大家完成GCP Sensitive Data Protection(原Cloud DLP)从环境准备、敏感数据发现到全场景脱敏落地的全流程实操,覆盖从轻量查询到企业级大规模数据处理的全场景需求。
1、背景与核心动因:为什么必须做数据脱敏?
1.1 数据安全合规的刚性要求
全球主流数据合规法规均对敏感个人信息的处理提出了明确的保护要求,违规成本极高。
数据脱敏是满足合规要求的核心技术手段,能够有效证明企业对敏感数据的保护义务履行情况。
1.2 企业数据资产的风险防控需求
企业数据泄露80%以上来自内部场景:开发测试、数据分析、第三方合作等环节直接使用生产原始数据,极易造成敏感数据泄露。同时,数据共享、数据归档、数据上云等场景,也面临着敏感数据暴露的风险。
数据脱敏通过对敏感信息的变形、替换、加密处理,降低原始数据的敏感等级,即使数据发生泄露,也无法还原出真实的个人敏感信息,从根源上降低数据安全风险。
1.3 数据流通与价值释放的前提保障
数据作为核心生产要素,需要在分析、建模、共享、交易等场景中释放价值。但原始敏感数据无法直接在跨部门、跨企业场景中流通,而数据脱敏能够在不泄露敏感信息的前提下,保留数据的统计特性、业务格式,实现"安全与价值"的平衡,是数据要素流通的核心前提。
2、数据脱敏的核心分类与适用场景
2.1 按脱敏时机与生效范围:静态脱敏 vs 动态脱敏
这是行业最核心的分类维度,二者的核心逻辑、适用场景完全不同,不可混淆。
- 静态脱敏(SDM,离线脱敏) :核心逻辑是「先脱敏,后使用」,对生产数据的副本 进行全量脱敏处理,脱敏后的数据再同步到开发、测试、分析等非生产环境。全程不触碰生产库原始数据,不影响生产业务运行。
适用场景:非生产环境数据供给、离线数据共享、历史数据归档、第三方数据交付。 - 动态脱敏(DDM,在线脱敏) :核心逻辑是「访问时实时脱敏」,不修改生产库的原始数据,在用户访问数据的过程中,根据访问者的身份、权限、角色,实时返回不同脱敏程度的数据。权限越高,可查看的原始数据越多;权限越低,脱敏程度越高。
适用场景:生产库多角色访问控制、实时数据接口调用、在线报表查询、生产环境直接数据分析。
2.2 按数据处理时效性:批量脱敏 vs 实时脱敏
该维度与静态/动态脱敏存在交叉,核心区分是数据处理的延迟要求。
- 批量脱敏 :对存量、大批量数据进行一次性或周期性的脱敏处理,比如T+1对前一日全量数据进行脱敏,支持错峰运行。特点是处理数据量大、对实时性要求低、资源占用可控。
适用场景:离线数仓全量数据脱敏、历史数据归档、非生产环境全量数据同步。 - 实时脱敏 :对增量、流式数据进行毫秒级脱敏处理,在数据产生、传输、写入的过程中同步完成脱敏,全程无原始敏感数据落地。特点是低延迟、高并发、对性能要求高。
适用场景:实时数仓入湖入仓、业务系统实时数据接口、流式数据处理、动态脱敏场景。
2.3 补充分类
- 增量脱敏:仅对新增/变更的数据进行脱敏处理,避免全量重复处理,大幅提升处理效率,适配有持续数据流入的业务场景。
- 可逆脱敏:脱敏后的数据可通过密钥、算法还原为原始数据,比如格式保留加密(FPE)、确定性加密,适合需要后续还原数据的业务场景。
- 不可逆脱敏:脱敏后的数据无法还原为原始数据,比如掩码、加盐哈希、空值处理,安全性更高,适合无需还原的测试、分析、归档场景。
3、行业通用的数据脱敏实现方法与选型对比
3.1 主流脱敏技术方案详解
| 脱敏技术 | 实现原理 | 核心特点 |
|---|---|---|
| 掩码/替换脱敏 | 对敏感字段的部分字符进行固定替换(如手机号138****1234),保留数据格式 | 实现简单、零代码门槛、格式兼容性强,是最常用的轻量脱敏方案 |
| 格式保留加密(FPE) | 基于加密算法对数据进行可逆加密,加密后保留原始数据的格式与长度 | 高安全性、可逆、不影响业务系统运行,适配生产库核心敏感字段保护 |
| 加盐哈希脱敏 | 通过SHA-256等哈希算法+随机盐值,对数据进行不可逆转换 | 不可逆、极高安全性、防碰撞,适合密码存储、无需还原的归档数据 |
| 数据泛化/截断 | 将具体数据值替换为范围值(如年龄28岁→20-30岁,地址精确到市) | 保留数据统计特性,适配数据分析、机器学习建模场景 |
| 数据置换/洗牌 | 对敏感字段的值在数据集内随机打乱,保留数据分布与格式 | 保留数据业务特性,适配开发测试、性能测试场景 |
| 空值/删除 | 直接将敏感字段置空或删除 | 最高安全性、零实现成本,完全丢失数据价值,仅适配无需该字段的场景 |
3.2 不同方案的优劣势与适用场景对比
| 脱敏技术 | 核心优势 | 核心劣势 | 安全等级 | 典型适用场景 |
|---|---|---|---|---|
| 掩码替换 | 实现简单、格式兼容、零代码门槛 | 安全性中等,易被暴力破解 | 中 | 前端展示、报表查询、低敏感数据脱敏 |
| 格式保留加密(FPE) | 高安全、可逆、保留数据格式 | 需密钥管理、有性能开销 | 高 | 生产库动态脱敏、业务系统敏感字段保护 |
| 加盐哈希 | 不可逆、极高安全性、防碰撞 | 无法还原、破坏数据格式 | 极高 | 密码存储、数据去重、无需还原的归档数据 |
| 数据泛化 | 保留统计特性、支撑数据分析 | 丢失精准数据、不支持业务交易 | 中 | 数据分析、机器学习建模、合规数据共享 |
| 数据置换 | 保留数据分布与格式、适配测试场景 | 关联字段易被还原、需配合其他方案 | 中低 | 开发测试环境数据供给、性能测试 |
| 空值删除 | 最高安全性、实现成本为0 | 完全丢失数据价值 | 极高 | 无需该字段的归档、废弃数据处理 |
4、GCP敏感数据保护(SDP/DLP)核心能力介绍
4.1 GCP SDP是什么?
GCP Sensitive Data Protection(简称SDP,原Cloud DLP)是谷歌云原生的企业级数据安全服务,覆盖敏感数据自动发现→分类分级→脱敏变形→风险审计的全生命周期管理。原生集成GCP全生态产品,无需复杂的第三方组件对接,即可实现跨GCP服务的统一数据保护,同时支持混合云、多云环境的敏感数据治理,是谷歌云数据安全体系的核心组件。
4.2 核心功能模块与脱敏能力
- 敏感数据自动发现:内置超过150种预定义敏感信息类型(InfoType),覆盖全球主流PII数据(中国身份证/手机号、银行卡、邮箱、护照、医疗数据、金融数据等),支持自定义敏感类型,可自动扫描GCP各服务中的结构化/非结构化数据,完成自动化分类分级。
- 全场景脱敏能力:内置上述所有主流脱敏技术,支持无代码配置化脱敏,也支持API定制化开发,覆盖静态/动态、批量/实时全场景,同时支持符合监管要求的去标识化、差分隐私能力。
- 风险评估与合规审计:自动识别数据泄露风险,生成可视化风险报告,原生集成GCP Cloud Audit Logs,全操作可追溯,满足GDPR、PIPL、HIPAA等全球合规审计要求。
- 细粒度规则管理:支持通过模板复用敏感类型配置、脱敏规则,统一企业级数据保护规范,适配多业务、多团队的规模化落地。
4.3 GCP生态原生集成优势
- 与BigQuery深度集成:支持直接在BigQuery SQL中调用脱敏能力,无需数据导出,零代码实现查询时脱敏,也支持全表/数据集的批量扫描与脱敏,是GCP最常用的轻量脱敏方案。
- 与Dataflow集成:在流式/批量数据处理管道中原生嵌入DLP脱敏能力,实现数据入湖入仓过程中的实时脱敏,适配TB/PB级企业级大规模数据处理场景。
- 与Cloud Storage集成:支持对对象存储中的CSV、JSON、图片、文档等非结构化数据进行敏感数据扫描与脱敏,覆盖全类型数据资产。
- 与Cloud IAM集成:基于GCP统一身份权限体系,实现细粒度的访问控制,遵循最小权限原则,保障脱敏操作的安全性。
5、GCP SDP数据脱敏全流程实操
5.1 前置环境与权限准备
5.1.1 GCP账号与项目创建
注意:所有操作中 location 需要相同。
前提:
- GCP账号(拥有项目创建、IAM权限配置权限、计费权限)
- 可选:gcloud CLI(用于快速验证GCP配置)
(1)创建 GCP 项目
- 登录GCP控制台,点击顶部"选择项目"→"新建项目"。
- 填写项目名称(如 gcp-dlp-demo),自动生成项目ID(记下来,后续全程使用),点击"创建"。
- 等待项目创建完成(约1分钟),切换到该项目。
5.1.2 启用核心API服务
需启用的核心API:Sensitive Data Protection API、BigQuery API、Cloud Dataflow API(企业级方案可选)。
- 在GCP Console左侧导航栏,进入「API和服务」→「库」;
- 分别搜索上述API,点击进入详情页后,点击「启用」;
- 启用完成后,可在「API和服务」→「已启用的API和服务」中核验。
启用成功示例:
5.1.3 服务账号创建与密钥配置
服务账号用于代码调用 DLP API、BigQuery 等服务,需遵循最小权限原则配置。
服务账号创建:
- 首页 → Quick access → IAM & Admin → Service Accounts → Create service account
- 配置:
- 服务账号名称:bq-dlp-service-account
- 服务账号ID:自动生成(无需修改)
- 描述:用于 DLP 脱敏 BigQuery 数据的服务账号
- 点击"创建并继续",添加以下角色(最小权限原则):
- DLP Administrator(DLP 操作)
- BigQuery Data Editor(BigQuery 数据读写)
- BigQuery Job User(执行 BigQuery 作业)
- Dataflow Admin(可选):Dataflow任务管理权限
- 点击"继续"→"完成"。
密钥配置:
- 找到刚创建的服务账号,点击右侧"⋮" → "Manage Keys"。
- 切换到"Keys"标签 → "Add key" → "Create new Key"。
- 密钥类型选择 JSON,点击"创建",密钥文件会自动下载(如 bq-dlp-demo-xxxx.json)。
- 保存密钥文件:建议放在项目根目录的 secrets/ 文件夹(后续配置 .gitignore 避免提交)。
5.1.4 测试环境准备:BigQuery 数据集与敏感测试表构建
我们将创建包含常见敏感数据的BigQuery测试表,用于后续的扫描与脱敏操作。
(1)创建数据集
- 导航至 BigQuery → "Studio" → 点击项目ID旁的"创建数据集"。
- 配置参数:
- 数据集ID:test_dataset(仅字母/数字/下划线)
- 位置:europe-west2(London 伦敦,需与后续DLP操作区域一致)
- 其他保持默认,点击"创建"。
(2)创建测试表并插入敏感数据
-
在 test_dataset 旁点击"创建表",选择"空表":
-
表ID: sensitive_user_data
-
架构配置(添加以下字段):
名称 类型 模式 id INTEGER NULLABLE name STRING NULLABLE phone STRING NULLABLE id_card STRING NULLABLE email STRING NULLABLE description STRING NULLABLE 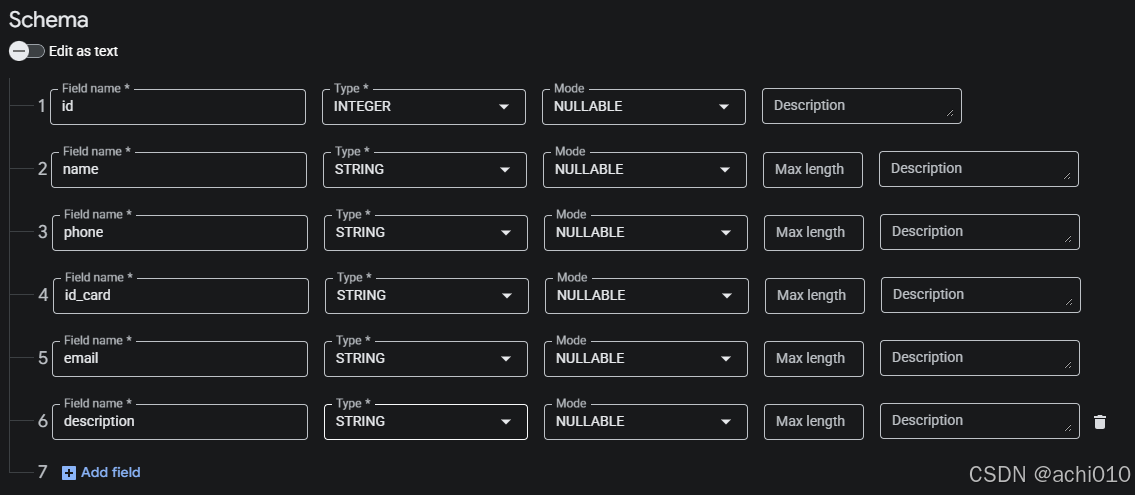
-
-
点击"创建表",然后执行以下SQL插入测试数据:
sql
INSERT INTO `[你的项目ID].test_dataset.sensitive_user_data`
(id, name, phone, id_card, email, description)
VALUES
(1, '张三', '13800138000', '110101199001011234', 'zhangsan@example.com', '没用的备用信息'),
(2, '李四', '13900139000', '310101198505156789', 'lisi@example.com', '相关描述信息');
-- 删除数据
DELETE `[你的项目ID].test_dataset.sensitive_user_data` WHERE 1=1;- 验证:
- 方法一:通过 Preview 查看数据
- 方法二:执行 SELECT * FROM 你的项目ID.test_dataset.sensitive_user_data,确认数据插入成功。
5.2 第一步:敏感数据自动发现与分类分级
脱敏的核心前提是先找到敏感数据,再做针对性脱敏。企业级场景中,数据资产规模大、字段多,无法人工枚举敏感字段,需通过 SDP 实现自动化敏感数据发现。
5.2.1 基于 SDP 创建数据发现扫描任务
- 进入GCP Console → Sensitive Data Protection ,打开 SDP 控制台;
- Sensitive Data Protection → Learn about your data → Deep inspection → Create job and job triggers,开始配置扫描任务;
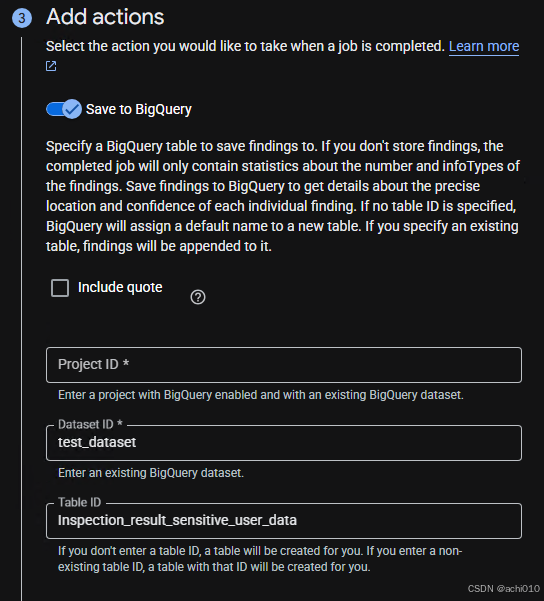
- 步骤 1:名称、位置、存储系统(扫描的存储)、范围,输入扫描名称 dlp-bigquery-demo-scan,选择对应区域,选择对应存储系统,选择数据范围(默认1000条),点击继续;
- 步骤 2:配置检测设置,可选择「全部预定义InfoType」,也可自定义规则(通过 Manage infoTypes 或者 Inspection rulesets -> Add a releset),置信度阈值默认 POSSIBLE ,点击继续;
- 步骤 3:配置结果存储,点击继续;
- 步骤 4:调度设置,测试环境选择立即运行一次,生产环境可配置周期性调度,点击继续;
- 步骤 5(可选):预览所有配置;
- 所有配置完成后,点击创建,扫描任务立即启动。
步骤 1 示例
步骤 2 示例
步骤 3 示例
5.2.2 敏感数据识别结果核验与标签管理
- 等待扫描任务完成(小数据量几十秒即可完成),在扫描列表中点击任务名称,查看扫描结果;
- 结果页可查看 SDP 自动识别的敏感字段、对应敏感类型、匹配数量、置信度,比如 phone_number 被识别为中国手机号, id_card 被识别为中国身份证号;
- 可基于识别结果,对敏感字段进行分类分级标记,制定对应的脱敏规则,高敏感字段采用高强度脱敏方案,中低敏感字段采用轻量脱敏方案。
说明:如果使用默认规则进行扫描,由于多规则重叠匹配,会导致扫描结果中对相同字段进行重复标记。
5.3 第二步:GCP 生态 3 种核心脱敏方案落地
5.3.1 方案 1:BigQuery 原生 SQL 零代码脱敏(轻量场景)
该方案无需额外开发、无需数据导出,直接在 BigQuery SQL 中完成脱敏,不修改原始数据,仅对查询结果进行脱敏处理,适配临时查询、报表展示、轻量分析等场景,是 GCP 中最常用的轻量脱敏方案。
5.3.1.1 字符替换/掩码脱敏实现
通过 BigQuery 字符串函数,对敏感字段的部分字符进行替换,保留数据格式,适配绝大多数展示类场景。
直接通过 BigQuery 的 SQL 进行字符替换,规则说明:
- 手机号:保留前 3 位和后 4 位,中间 4 位替换为*(如:13812345678 → 138****5678)
- 身份证号:18 位保留前 6 位和后 4 位,中间 8 位替换为*;15 位保留前 6 位和后 3 位,中间 6 位替换为*
- 邮箱:保留 @前第一个字符,其余字符替换为*,@和域名完整保留(如:abc123@xxx.com → a*****@xxx.com)
sql
SELECT
id, -- 不处理
name, -- 不处理
-- 手机号脱敏:保留前3后4,中间4个*
CASE
WHEN LENGTH(TRIM(phone)) = 11 THEN CONCAT(SUBSTR(phone, 1, 3), '****', SUBSTR(phone, 8, 4))
ELSE phone -- 非11位手机号不处理(可根据需求调整)
END AS masked_phone,
-- 身份证号脱敏:区分18位/15位
CASE
WHEN LENGTH(TRIM(id_card)) = 18 THEN CONCAT(SUBSTR(id_card, 1, 6), '********', SUBSTR(id_card, 15, 4))
WHEN LENGTH(TRIM(id_card)) = 15 THEN CONCAT(SUBSTR(id_card, 1, 6), '******', SUBSTR(id_card, 13, 3))
ELSE id_card -- 非标准长度不处理
END AS masked_id_card,
-- 邮箱脱敏:保留@前第一个字符,其余替换为*
CASE
WHEN REGEXP_CONTAINS(email, '@') THEN
CONCAT(
SUBSTR(SPLIT(email, '@')[OFFSET(0)], 1, 1), -- 取@前第一个字符
REPEAT('*', LENGTH(SPLIT(email, '@')[OFFSET(0)]) - 1), -- @前剩余字符替换为*
'@',
SPLIT(email, '@')[OFFSET(1)] -- 保留@后的域名
)
ELSE email -- 非标准邮箱格式不处理
END AS masked_email,
description -- 不处理
FROM
`[你的项目ID].test_dataset.sensitive_user_data`; -- 替换为你的项目、数据集、表名关键函数解释:
- SUBSTR(str, start_pos, length):截取字符串,start_pos从 1 开始(BigQuery 的字符串索引不是 0 开头)
- CONCAT(str1, str2, ...):拼接多个字符串
- LENGTH(TRIM(str)):先去除字符串首尾空格,再计算长度(避免空格导致的长度判断错误)
- SPLIT(str, delimiter):按分隔符拆分字符串,OFFSET(0)取第一个拆分结果,OFFSET(1)取第二个
- REPEAT('', n):生成 n 个连续的,比手动写多个*更灵活
- REGEXP_CONTAINS(str, pattern):判断字符串是否包含指定正则表达式(这里用于校验邮箱是否有@)
注意事项:
- 如果字段是NULL或空字符串,上述逻辑会直接返回原值,你可根据需求补充IS NULL判断(如WHEN phone IS NULL THEN '')
- 若手机号 / 身份证号存在非数字字符(如空格、字母),需先通过REGEXP_REPLACE清洗(如REGEXP_REPLACE(phone, '\^0-9', ''))
- 脱敏规则可灵活调整:比如邮箱想保留前 2 位,只需把SUBSTR(SPLIT(email, '@')OFFSET(0), 1, 1)改为SUBSTR(..., 1, 2),同时REPEAT的长度减 2 即可。
- 脱敏前建议先清洗字段(去空格、过滤非目标字符),避免长度判断错误导致脱敏失效。
优点:
- 轻量易实现:基于BigQuery原生字符串函数(SUBSTR/CONCAT/REPEAT等),无需依赖第三方库或自定义函数,新手可快速上手,SQL编写和维护成本低。
- 规则灵活可控:可精准调整脱敏位数(如手机号改保留前2后3、邮箱保留前2位),适配不同业务的脱敏要求,且支持非标准数据(如非11位手机号、无@的邮箱)的兼容处理。
- 性能高效:仅涉及字符串截取/拼接/长度计算,无复杂逻辑,在BigQuery分布式架构下,可高效处理千万级甚至亿级规模的数据集。
- 兼容性好:天然适配BigQuery的SQL语法,无需额外环境配置,可直接嵌入查询、视图、ETL任务中。
缺点:
- 安全性较弱:脱敏规则固定(如手机号必保留前3后4),无随机性,不满足高合规要求。
- 异常场景覆盖有限:未处理极端异常数据(如身份证号含特殊字符、邮箱多@、手机号含字母),需额外编写清洗逻辑(如正则过滤非数字)。
- 无统一管理能力:脱敏规则硬编码在 SQL 中,若企业需统一修改规则(如全公司调整身份证脱敏位数),需逐个修改相关 SQL,维护成本随场景增多上升。
- 不可逆但非加密级:仅为字符替换,不属于加密脱敏(如哈希/掩码),无法满足金融、医疗等强监管行业的合规要求。
适用场景:
- 内部非核心数据处理:如内部运营报表、业务分析、数据可视化等场景,仅需基础脱敏保护隐私,无需严格合规认证。
- 一次性/临时性数据脱敏:如导出数据给第三方合作方、临时查询脱敏数据,快速实现且无需搭建复杂脱敏系统。
- 中小规模/规则固定的场景:数据集规模适中、脱敏规则长期不变(如固定保留手机号前3后4),无需动态调整脱敏程度。
不适用场景:
- 高合规要求场景:金融、医疗、政务等需符合《个人信息保护法》等强监管要求的领域,需采用随机脱敏、加密脱敏、动态脱敏等方案。
- 企业级统一脱敏管理:需跨团队、跨项目统一管控脱敏规则,或需动态调整脱敏程度(如管理员看全量、普通员工看脱敏后)。
- 极端异常数据占比高的场景:如手机号/身份证号大量含特殊字符、格式混乱,需复杂清洗+动态规则的场景。
小结:
- 该方法是BigQuery中轻量、高效、低成本的基础脱敏方案,核心适配内部分析、临时处理等低合规要求的场景;
- 其核心短板是静态规则导致安全性不足,且无统一管理能力,不适配高合规、企业级统一管控的场景;
5.3.1.2 内置加密函数强脱敏实现
参考文档:https://docs.cloud.google.com/bigquery/docs/reference/standard-sql/dlp_functions
针对高敏感数据,可使用 BigQuery 内置的 DLP_DETERMINISTIC_ENCRYPT 加密函数,实现可逆强脱敏,同时支持细粒度的密钥权限控制,仅拥有密钥权限的用户可还原原始数据。这种方式属于确定性加密,安全性更高且支持可逆解密,同时能保留数据的关联性(相同明文加密后得到相同密文)。
核心前提与背景:
DLP_DETERMINISTIC_ENCRYPT 是 BigQuery 结合 Google Cloud DLP(Data Loss Prevention)和 KMS(Key Management Service)提供的加密函数,核心特点:
- 确定性加密:相同明文 + 相同密钥 + 相同上下文 → 相同密文(可用于分组、关联分析);
- 可逆性:通过对应密钥可解密还原原值(需严格管控密钥权限);
- 高安全性:依赖 Google Cloud KMS 的对称加密密钥,符合合规要求(如GDPR、个人信息保护法);
- 权限管控:需配置 KMS 密钥的访问权限,仅授权账号可加密/解密。
(1)前置准备(必须完成)
使用该函数前需先创建 Cloud KMS 密钥,步骤如下:
-
创建KMS密钥环(Key Ring):
-
进入 Google Cloud 控制台 → 搜索"Key Management Service"
-
启用服务(注意:费用问题!),启用后会显示 API Enabled 状态
-
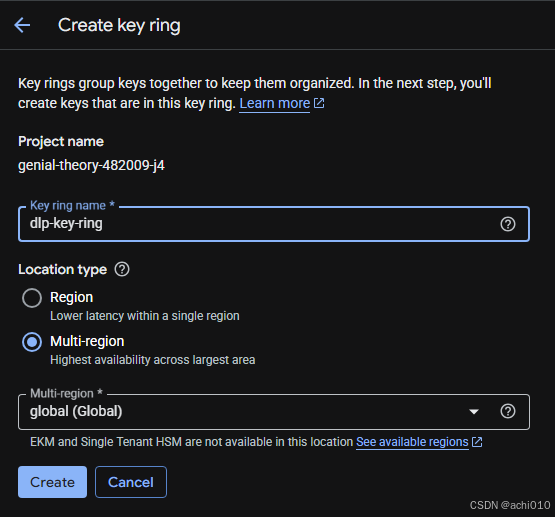
进入管理页面(第一次开通服务,需要等待几分钟时间),选择区域(需与 BigQuery 数据集区域一致) → 创建密钥环(Create key ring,如 dlp-key-ring)。
-
-
创建对称加密密钥:
- 在密钥环下创建Symmetric encrypt/decrypt(算法默认不可变更 Google symmetric key),命名如 dlp-deterministic-key。
注意:过期时间。相同明文,使用不同的密钥,加密后得到密文不同。
-
授权 BigQuery 访问 KMS 密钥:
- 给 BigQuery 服务账号(格式:service-PROJECT_NUMBER@gcp-sa-bigquery.iam.gserviceaccount.com)授予 Cloud KMS CryptoKey Encrypter/Decrypter 角色(允许加密/解密)。
(2)DLP_DETERMINISTIC_ENCRYPT 函数语法
根据 BigQuery 官方文档,DLP_DETERMINISTIC_ENCRYPT 有以下两种形式(核心区别是是否包含可选的 context):
sql
-- 形式 1:仅必选参数(key + plaintext + surrogate)
DLP_DETERMINISTIC_ENCRYPT(
key, -- 必选:KMS密钥完整路径
plaintext, -- 必选:待加密的敏感字符串
surrogate -- 必选:替代值生成规则
)
-- 形式 2:必选参数 + 可选 context
DLP_DETERMINISTIC_ENCRYPT(
key, -- 必选:KMS密钥完整路径
plaintext, -- 必选:待加密的敏感字符串
surrogate, -- 必选:替代值生成规则
context -- 可选:上下文字符串,增强加密唯一性
)参数详细解释(贴合官方定义)
| 参数名 | 类型 | 是否必选 | 核心含义 & 约束(官方要求) |
|---|---|---|---|
| key | STRING | 是 | KMS对称加密密钥的完整路径,格式固定:projects/PROJECT_ID/locations/REGION/keyRings/KEY_RING/cryptoKeys/KEY_NAME;仅支持 GOOGLE_SYMMETRIC_ENCRYPTION 算法的密钥 |
| plaintext | STRING | 是 | 待加密的敏感字段(手机号/身份证/邮箱),仅支持字符串类型;若字段是数字(如INT64类型手机号),需先通过 CAST 转换为字符串 |
| surrogate | STRING | 是 | 【核心必选】替代值生成规则,控制加密后密文的格式: - 设为 NULL:输出原始加密字节(可读性差,不推荐); - 设为自定义前缀(如 'PHONE'):生成以该前缀为标识的唯一替代值(推荐); - 仅允许字母、数字、下划线(a-zA-Z0-9_+) |
| context | STRING | 否 | 上下文字符串,用于增强加密唯一性:相同明文 + 不同context → 不同密文;建议设为字段名(如 'phone'),避免跨字段密文冲突 |
(3)正确的实操示例(加密)
生成 DEK 并加密得到 wrapped_key(用 gcloud 命令行)
打开 Google Cloud Shell(或本地安装 gcloud CLI),执行以下命令(替换你的项目 / 密钥信息):
shell
# I. 生成随机DEK(32字节,符合AES-256标准)
DEK=$(openssl rand 32 | base64)
# II. 用KMS密钥加密DEK,得到wrapped_key(Base64格式)
WRAPPED_KEY=$(echo -n $DEK | base64 -d | gcloud kms encrypt \
--project=your-project-id \
--location=europe-west2 \
--keyring=dlp-key-ring \
--key=dlp-deterministic-key \
--plaintext-file=- \
--ciphertext-file=- | base64)
# III. 输出WRAPPED_KEY(复制这个值,后续SQL要用)
echo $WRAPPED_KEY加密(脱敏)示例
sql
-- 替换为你的KMS密钥路径、项目/数据集/表名
DECLARE kms_key_path STRING DEFAULT 'gcp-kms://projects/your-project-id/locations/your_datase_locations/keyRings/dlp-key-ring/cryptoKeys/dlp-deterministic-key';
DECLARE DLP_KEY_VALUE BYTES;
SET DLP_KEY_VALUE =
FROM_BASE64('wrapped_key');
SELECT
id,
name,
-- 手机号加密(完整参数:key + plaintext + surrogate + context)
DLP_DETERMINISTIC_ENCRYPT(
-- 第一步:用DLP_KEY_CHAIN生成合规的密钥结构体
DLP_KEY_CHAIN(
kms_key_path, -- kms_resource_name
DLP_KEY_VALUE -- wrapped_key(普通场景设为NULL)
),
TRIM(CAST(phone AS STRING)), -- 转换为字符串并去空格
'PHONE_SURROGATE', -- 替代值前缀(标识手机号密文)
'phone' -- 上下文:字段名
) AS encrypted_phone,
-- 身份证号加密(完整参数)
DLP_DETERMINISTIC_ENCRYPT(
-- 第一步:用DLP_KEY_CHAIN生成合规的密钥结构体
DLP_KEY_CHAIN(
kms_key_path, -- kms_resource_name
DLP_KEY_VALUE -- wrapped_key(普通场景设为NULL)
),
TRIM(id_card),
'ID_CARD_SURROGATE',
'id_card'
) AS encrypted_id_card,
-- 邮箱加密(仅必选参数,省略context)
DLP_DETERMINISTIC_ENCRYPT(
-- 第一步:用DLP_KEY_CHAIN生成合规的密钥结构体
DLP_KEY_CHAIN(
kms_key_path, -- kms_resource_name
DLP_KEY_VALUE -- wrapped_key(普通场景设为NULL)
),
TRIM(email),
'EMAIL_SURROGATE' -- 仅必选参数:key + plaintext + surrogate
) AS encrypted_email,
description
FROM
`your-project.your-dataset.user_info`;(4)正确的实操示例(解密 - 还原原值)
解密函数 DLP_DETERMINISTIC_DECRYPT 的参数需与加密时完全匹配(key、surrogate、context 缺一不可):
sql
-- 替换为你的KMS密钥路径、项目/数据集/表名
DECLARE kms_key_path STRING DEFAULT 'gcp-kms://projects/your-project-id/locations/your_datase_locations/keyRings/dlp-key-ring/cryptoKeys/dlp-deterministic-key';
DECLARE DLP_KEY_VALUE BYTES;
SET DLP_KEY_VALUE =
FROM_BASE64('wrapped_key');
SELECT
phone,
-- 解密手机号(匹配加密时的surrogate和context)
DLP_DETERMINISTIC_DECRYPT(
DLP_KEY_CHAIN(
kms_key_path, -- kms_resource_name
DLP_KEY_VALUE -- wrapped_key(普通场景设为NULL)
),
'PHONE_密文',
'PHONE_SURROGATE',
'phone'
) AS decrypted_phone,
FROM
`your-project.your-dataset.encrypted_user_info`
where id = 1;(5)关键注意事项
- 权限严格管控:执行加密的账号需拥有KMS密钥的cloudkms.cryptoKeyVersions.useToEncrypt 权限,解密需 cloudkms.cryptoKeyVersions.useToDecrypt 权限,需在 Google Cloud IAM 中配置。
(6)优缺点分析及适用场景
优点:
-
保留等值查询/关联能力(核心优势):确定性加密的核心特性是「相同明文生成相同密文」,这意味着加密后的敏感数据仍能支持 WHERE 等值查询、GROUP BY 分组、JOIN 表关联等操作。例如加密手机号后,仍能查询"某手机号是否存在"、"按加密后的用户ID分组统计订单量",这是哈希(不可逆)、随机加密(相同明文不同密文)无法实现的。
-
无缝集成 BigQuery,使用成本低:直接在 BigQuery SQL 中调用,无需额外的 ETL 流程或外部工具,比如可直接对表中列执行加密,对新手友好,开发和维护成本低。
-
合规性与可逆性兼顾
- 符合 GDPR、CCPA、PCI DSS 等合规要求,能有效脱敏手机号、身份证、银行卡号等敏感数据;
- 可通过 DLP_DETERMINISTIC_DECRYPT 函数解密(需密钥权限),满足"必要时恢复原始数据"的场景(如客服核对用户信息)。
-
完善的密钥管理:对接 Google Cloud KMS(密钥管理服务),支持密钥轮换、细粒度权限控制(如仅允许特定角色解密),符合企业级安全最佳实践,避免密钥泄露/丢失的风险(相对手动管理密钥)。
缺点:
-
安全性低于随机加密(核心风险):由于"相同明文 → 相同密文",攻击者可通过「频率分析」破解:比如高频出现的密文大概率对应高频明文,存在字典攻击风险,安全性远低于随机加密(AEAD)。
-
性能开销明显:加密/解密操作会增加 BigQuery 查询延迟,尤其是对大规模数据集(亿级行)操作时,查询耗时可能增加 20%-50%,影响实时分析场景的性能。
-
数据类型与使用限制:仅支持 STRING、BYTES 类型,对 STRUCT、ARRAY 等复杂类型需先拆解;且加密后的密文长度固定(约 64 字节),会增加存储成本。
-
密钥强依赖:加密和解密必须使用同一密钥:密钥泄露会导致所有加密数据被破解,密钥永久丢失则数据无法恢复,对密钥管理流程要求极高。
适用场景:
-
需保留等值查询的敏感数据加密
- 典型场景:电商订单表的用户手机号/身份证号加密(需查询"某用户是否有订单")、金融客户表的银行卡号加密(需按卡号分组统计交易)、医疗数据的患者 ID 加密(需关联患者病历和检查报告)。
-
合规脱敏+业务分析兼顾:需满足合规要求脱敏敏感数据,但又不能完全丧失数据的分析价值(如按加密后的邮箱统计用户活跃度、按加密后的手机号筛选高价值用户)。
-
跨表/跨项目数据关联:加密后的密文在不同 BigQuery 数据集/项目间保持一致性,可用于跨表/跨项目的等值关联(如用户表和交易表通过加密后的用户ID关联)。
-
可逆脱敏需求:无需永久不可逆脱敏(如哈希加盐),需要在授权后解密原始数据(如银行客服核对客户手机号、电商售后查询用户地址)。
不适用场景:
- 高敏感且无需等值查询的数据:如密码、支付验证码、登录token,应使用哈希(加盐)或随机加密,避免频率分析风险。
- 实时高性能查询场景:如实时风控、实时报表,加密带来的性能损耗会影响结果返回速度。
- 无密钥管理能力的场景:如果团队无法保障 Cloud KMS 密钥的安全(如权限混乱、密钥未轮换),则不建议使用。
小结
- 核心优势:保留等值查询/关联能力,集成 BigQuery 易用性高,兼顾合规脱敏与数据可分析性;
- 核心风险:安全性低于随机加密,存在频率分析风险,依赖密钥的安全管理;
- 适用核心场景:需加密敏感数据,且必须保留等值查询、分组、关联能力的业务场景。高敏感、无需等值操作或实时高性能要求的场景需避免使用。
5.3.2 方案 2:DLP API + 代码实现灵活脱敏(定制化场景)
该方案适配定制化脱敏需求,可集成到业务系统、数据管道中,统一管理脱敏规则,支持跨服务调用,适配结构化/非结构化数据脱敏,本文以 Python 为例。
(1)前置准备
- 安装依赖库
bash
pip install google-cloud-dlp google-cloud-bigquery- 配置环境变量,指定服务账号密钥路径
bash
# Linux/Mac
export GOOGLE_APPLICATION_CREDENTIALS="./key.json"
# Windows PowerShell
$env:GOOGLE_APPLICATION_CREDENTIALS="./key.json"(2)完整脱敏代码示例 example_dlpapi_bigquery_data_masking.py
python
from google.cloud import dlp_v2
from google.cloud import bigquery
# 初始化客户端
dlp_client = dlp_v2.DlpServiceClient(
# 不支持 gRPC 的环境中使用 DLP API 时,通过 http 协议调用
# transport="rest"
)
bq_client = bigquery.Client()
# 核心配置参数
PROJECT_ID = "你的GCP项目ID"
DATASET_ID = "test_dataset"
TABLE_ID = "sensitive_user_data"
LOCATION = "global"
def deidentify_with_mask(project_id, table_data):
"""基于DLP API实现掩码脱敏"""
parent = f"projects/{project_id}/locations/{LOCATION}"
# 配置要识别的敏感信息类型
info_types = [
{"name": "EMAIL_ADDRESS"},
{"name": "PERSON_NAME"}
]
# 配置脱敏规则:掩码替换
deidentify_config = {
"info_type_transformations": {
"transformations": [
{
"info_types": info_types,
"primitive_transformation": {
"character_mask_config": {
"masking_character": "*",
"number_to_mask": 8,
"reverse_order": False
}
}
}
]
}
}
# 配置检测规则
inspect_config = {
"info_types": info_types,
"min_likelihood": dlp_v2.Likelihood.POSSIBLE,
"include_quote": True
}
# 构造输入数据格式
rows = []
headers = [{"name": col} for col in table_data[0].keys()]
for row in table_data:
values = [{"string_value": str(val)} for val in row.values()]
rows.append({"values": values})
table = {"headers": headers, "rows": rows}
item = {"table": table}
# 调用DLP API执行脱敏
response = dlp_client.deidentify_content(
request={
"parent": parent,
"deidentify_config": deidentify_config,
"inspect_config": inspect_config,
"item": item
}
)
# 解析脱敏结果
deidentified_rows = []
for row in response.item.table.rows:
row_data = {}
for i, header in enumerate(headers):
row_data[header["name"]] = row.values[i].string_value
deidentified_rows.append(row_data)
return deidentified_rows
if __name__ == "__main__":
# 从BigQuery读取原始数据
query = f"""
SELECT * FROM `{PROJECT_ID}.{DATASET_ID}.{TABLE_ID}` LIMIT 100
"""
query_job = bq_client.query(query)
table_data = [dict(row) for row in query_job.result()]
# 执行脱敏并打印结果
deidentified_result = deidentify_with_mask(PROJECT_ID, table_data)
print("脱敏后的结果:")
for row in deidentified_result:
print(row)代码说明:可通过修改 deidentify_config 配置,切换加密、哈希、泛化等脱敏规则,同时可将脱敏结果写回 BigQuery 或其他存储系统,实现批量脱敏处理。
优点
- 极高的灵活性与定制化能力:可完全自定义脱敏规则、支持复杂业务流程嵌入、可自定义敏感信息类型(InfoType)。
- 全场景数据类型支持:不仅支持结构化数据(BigQuery表、数据库、CSV/JSON文件),还支持非结构化数据(文本、图片、文档)的敏感数据识别与脱敏,覆盖企业全类型数据资产;可集成到混合云、多云环境的数据管道中,不局限于GCP生态,适配跨云数据治理需求。
- 统一规则管理与规模化落地:可通过SDP模板复用脱敏规则与敏感类型配置,多业务线、多团队共用一套企业级数据保护规范,避免规则分散与不一致;支持通过代码批量处理数据,适配周期性、自动化的脱敏任务,无需人工干预。
- 细粒度的权限与审计支持:基于 GCP IAM 实现细粒度的 API 访问权限控制,遵循最小权限原则;所有API调用操作均记录在 Cloud Audit Logs 中,全流程可追溯,满足合规审计要求。
缺点
- 开发与维护成本较高:需要具备一定开发能力的团队(Python/Java/Go等)进行代码编写、调试与维护,零技术背景的业务团队无法直接使用;业务规则变更时,需同步修改代码并重新发布,迭代周期较长,维护成本随业务复杂度上升而增加。
- 存在性能与延迟开销:每次脱敏需通过网络调用 DLP API,存在固定的网络延迟与 API 响应时间,不适合对延迟要求极高(毫秒级)的实时业务场景;大规模批量数据处理时,API 调用配额可能成为瓶颈,需提前申请提升配额,或通过分批处理、限流控制避免任务失败。
- 安全与复杂度风险:需妥善管理服务账号密钥,若密钥泄露可能导致API被滥用、敏感数据泄露;代码逻辑复杂时,可能引入 Bug 导致脱敏不彻底或数据损坏,需充分测试与代码审查。
- 成本不可控性:DLP API 按调用量与数据处理量计费,大规模数据处理时成本可能快速上升,需做好成本监控与预算管理;开发、测试、维护过程中产生的人力成本也需纳入整体考量。
适用场景
-
定制化需求高的业务系统集成
- 典型场景:业务系统在用户提交数据、接口返回数据时,需根据用户角色、业务场景动态调整脱敏规则;
- 核心价值:通过代码将脱敏能力嵌入业务逻辑,实现"业务驱动的动态脱敏",不受固定模板限制。
-
跨服务、跨云的数据管道脱敏
- 典型场景:数据从本地 IDC /其他云平台同步至 GCP,或在 GCP 内部 Pub/Sub、Dataflow、BigQuery 等多服务间流转时,需在流转节点完成脱敏;
- 核心价值:API 的轻量调用特性,使其可轻松嵌入任意数据处理节点,实现"数据不落地脱敏"。
-
非结构化数据脱敏
- 典型场景:对 Cloud Storage 中的合同文档、客服聊天记录、图片中的敏感文字进行识别与脱敏;
- 核心价值:GCP SDP 对非结构化数据的支持,结合代码的灵活性,可实现复杂非结构化数据的自动化处理。
-
多团队、多业务线的规模化落地
- 典型场景:企业需统一各业务线的脱敏规则,避免"各自为政";
- 核心价值:通过模板复用 + 代码封装,将脱敏能力包装为企业内部服务,供多团队调用,统一规范与审计。
不适用场景
-
轻量临时查询与报表展示
- 典型场景:分析师临时查询 BigQuery 数据,需快速对结果脱敏;
- 替代方案:直接使用 BigQuery SQL 零代码脱敏,无需开发,效率更高。
-
零技术背景的业务团队自主操作
- 典型场景:业务团队需定期对测试数据脱敏,但无开发资源;
- 替代方案:Dataflow 内置模板,零代码完成操作。
-
对延迟要求极高的实时业务场景
- 典型场景:核心交易系统实时返回用户数据,要求延迟在毫秒级;
- 替代方案:使用格式保留加密(FPE)在数据库层完成脱敏,或动态脱敏产品,避免网络 API 调用的延迟。
-
超大规模批量数据的低成本快速处理
- 典型场景:一次性对 PB 级历史数据进行脱敏,预算有限;
- 替代方案:使用 Dataflow + DLP 批量模板,全托管自动处理,无需编写复杂代码,且可通过错峰运行降低成本。
小结
- DLP API + 代码实现灵活脱敏,是"灵活性优先"的企业级脱敏方案,核心价值在于"定制化能力"与"全场景适配",但需要以"开发成本"与"维护成本"为代价。
- 该方案的最佳定位是:作为企业脱敏体系的"补位方案"------当 BigQuery SQL、Dataflow 模板等零代码/低代码方案无法满足业务需求时,通过 API + 代码实现复杂、定制化的脱敏逻辑;同时,可将其封装为企业内部服务,供多团队复用,平衡"灵活性"与"规模化"。
- 对于有开发能力、对脱敏规则有定制化需求的企业,该方案是 GCP 生态中的核心选择;但对于轻量场景、零开发资源的团队,建议优先考虑更简单的替代方案。
5.4 脱敏效果验证与合规审计
(1)脱敏效果验证
- 对比原始数据与脱敏后的数据,确认敏感字段已按规则完成脱敏,无完整敏感信息泄露;
- 验证脱敏后的数据业务兼容性,比如格式是否保留、是否可正常用于统计分析、测试等场景;
- 验证可逆脱敏的权限控制,确认仅授权用户可还原原始数据,未授权用户无法解密。
(2)合规审计
- 全操作日志追溯:SDP 所有扫描、脱敏、API 调用操作,均会记录在 Cloud Audit Logs 中,可在操作审计 → 日志查看器中查看与导出;
- 合规报告导出:导出敏感数据扫描报告、脱敏规则配置、操作日志,用于合规审计,满足监管要求;
- 风险告警配置:针对敏感数据泄露风险、未授权脱敏操作,配置自动告警,及时响应安全事件。
6、落地最佳实践与避坑指南
6.1 不同业务场景的脱敏方案选型建议
| 业务场景 | 推荐方案 | 核心选型依据 |
|---|---|---|
| 临时查询、报表展示、轻量分析 | BigQuery SQL零代码脱敏 | 零门槛、快速实现、不修改原始数据、无额外成本 |
| 业务系统集成、定制化脱敏规则、跨服务调用 | DLP API + 代码实现 | 灵活性高、可定制、统一管理脱敏规则 |
| TB级离线数仓批量脱敏 | Dataflow + DLP批量脱敏 | 全托管、高可扩展、支持大规模数据、无需管理基础设施 |
| 实时数仓、流式数据入湖、业务实时接口 | Dataflow + DLP流式脱敏 + 动态脱敏 | 低延迟、高并发、实时生效、不修改原始数据 |
| 高敏感数据存储、核心业务系统字段保护 | 格式保留加密(FPE) + 动态脱敏 | 高安全性、可逆、保留数据格式、不影响业务运行 |
6.2 性能与可用性平衡的核心技巧
- 最小权限原则:为服务账号、用户分配最小必要权限,严格管控密钥与加密密钥集的访问权限,禁止过度授权;
- 分级脱敏:根据数据敏感等级匹配对应脱敏方案,高敏感数据用高强度加密,中低敏感数据用掩码脱敏,平衡安全与性能;
- 错峰运行:批量脱敏任务选择业务低峰期运行,避免占用生产资源,影响业务稳定性;
- 规则复用:通过 SDP 模板复用敏感类型配置与脱敏规则,统一企业级脱敏规范,避免重复配置;
- 先脱敏后存储:数据入湖入仓前完成脱敏,避免敏感数据落地,从根源降低泄露风险;
- 抽样扫描:超大规模数据集的敏感数据发现,采用抽样扫描降低成本与耗时,提升效率。
6.3 常见踩坑问题与解决方案
- 问题 :DLP API 调用配额超限,脱敏任务失败
解决方案:申请提升 DLP API 配额,批量任务分批处理,采用 Dataflow 内置 DLP 集成自动处理限流。 - 问题 :BigQuery SQL 脱敏规则不统一,存在数据泄露风险
解决方案:通过 BigQuery 授权视图统一配置脱敏规则,用户仅能访问授权视图,禁止直接访问原始表。 - 问题 :脱敏后的数据破坏格式,导致业务系统/测试环境无法使用
解决方案:采用格式保留加密、掩码替换等保留格式的脱敏方案,提前测试脱敏后的数据兼容性。 - 问题 :敏感数据识别准确率低,漏识别/误识别
解决方案:调整扫描置信度阈值,自定义 InfoType 适配企业内部数据格式,结合人工核验提升准确率。 - 问题 :密钥管理不当,导致加密数据无法还原或密钥泄露
解决方案:采用 Cloud KMS 管理密钥,开启密钥轮换,严格管控密钥访问权限,禁止硬编码密钥到代码中。
7、总结与拓展
数据脱敏不是一次性的技术操作,而是企业数据安全治理的常态化核心工作。本文从脱敏的核心动因、理论分类、通用方案,到 GCP SDP 的全流程实操,覆盖了从轻量查询到企业级大规模数据处理的全场景落地需求,帮助企业在满足合规要求的同时,平衡数据安全与价值释放。
拓展方向
- 进阶学习 GCP SDP 动态脱敏能力,实现 BigQuery 行级/列级动态脱敏,基于用户权限返回差异化脱敏结果;
- 结合 GCP Cloud IAM、VPC Service Controls、Security Command Center,构建完整的企业级数据安全防护体系;
- 学习差分隐私、数据匿名化等进阶技术,在保障数据安全的前提下,最大化释放数据的分析与建模价值。