本文基于TensorRT-LLM 1.0 开源代码研究总结,会持续调整内容,仅用于自学笔记整理。
一.宏观架构
1.1 两层架构关系:
在生产环境中,Triton 是对外的网关层,TRT-LLM 是内部核心引擎。
|--------------------------|------|------------------------------------------------------|
| 组件 | 角色 | 核心职责 |
| Triton Inference Service | 外部网关 | 多框架并发推理、HTTP/gRPC协议(KServe)、GPU监控指标、Dynamic Batching |
| TensorRT-LLM | 内部引擎 | 真正执行推理计算、KV Cache管理、In-flight Batching、量化加速 |
1.2 Dynamic Batching
• 在 Triton 层面,动态批处理(Dynamic Batching)会将到达时间相近的请求合并,以提高 CUDA 核心的饱满度和整体吞吐量,但这会稍微增加先到请求的响应时间。
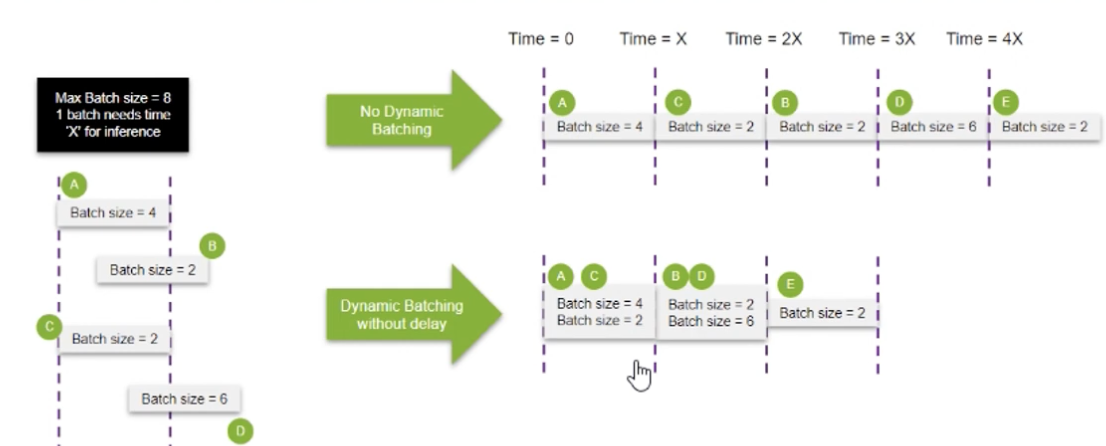
dynamic batching是根据请求到达的时间将部分请求合并成一批同时输入到模型中,提高cuda调用的饱满度,两个请求同时进入GPU处理同时完成同时返回,提高吞吐量。但是A请求的响应时间会久一点
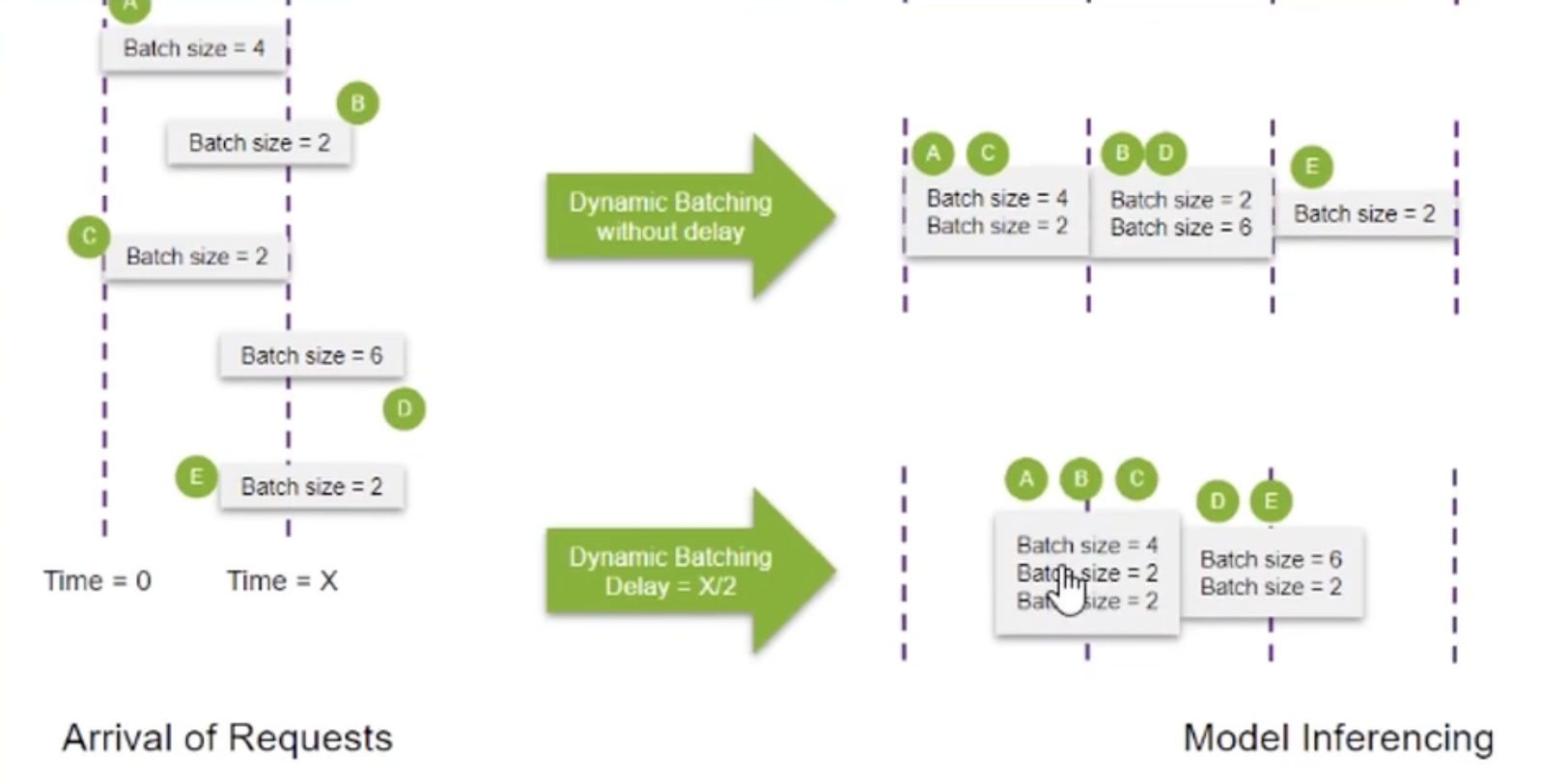
总结就是:
- 根据请求到达时间,将时间相近的请求合并成一批同时送入GPU
- 提高 CUDA 核心饱满度,提升整体吞吐量
- 代价:先到的请求A需要等待一小段时间才能被处理,响应延迟略有增加
1.3 整体数据流
- 客户端请求(HTTP / CAPI)进入 Triton
- Dynamic Batching 合并近似时间的请求
- 进入模型调度队列(Per Model Scheduler Queues)
- 分发到对应的 GPU/CPU Backend(TensorFlow、PyTorch、TRT-LLM 等)
- 模型推理执行,response 返回
- Model Repository 管理模型的加载与卸载
架构图:
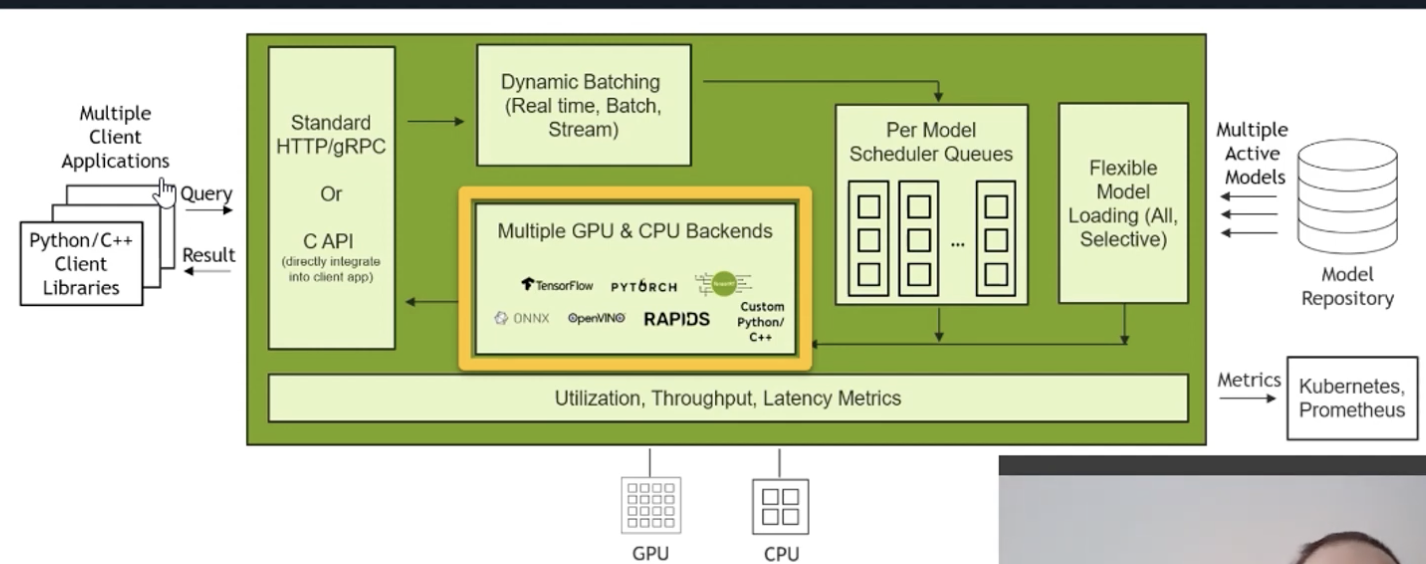
前端请求可能来自于各种客户端,可能有HTTP或者CAPI的调用。进入Dynamic batching做一定的整合,然后进入后端进入模型调度队列,再送入对应的GPU/CPU backend 后端模型处理框架来做具体的模型推理,response 返回。
后面的module repository是对所有模型以某种格式对他们有一个管理对外提供服务,包括模型装载和卸载。
还有一些吞吐量和延时的监控 metrics.还包含很多GPU的加速比如模型层的融合 计算量更小还有量化等等。
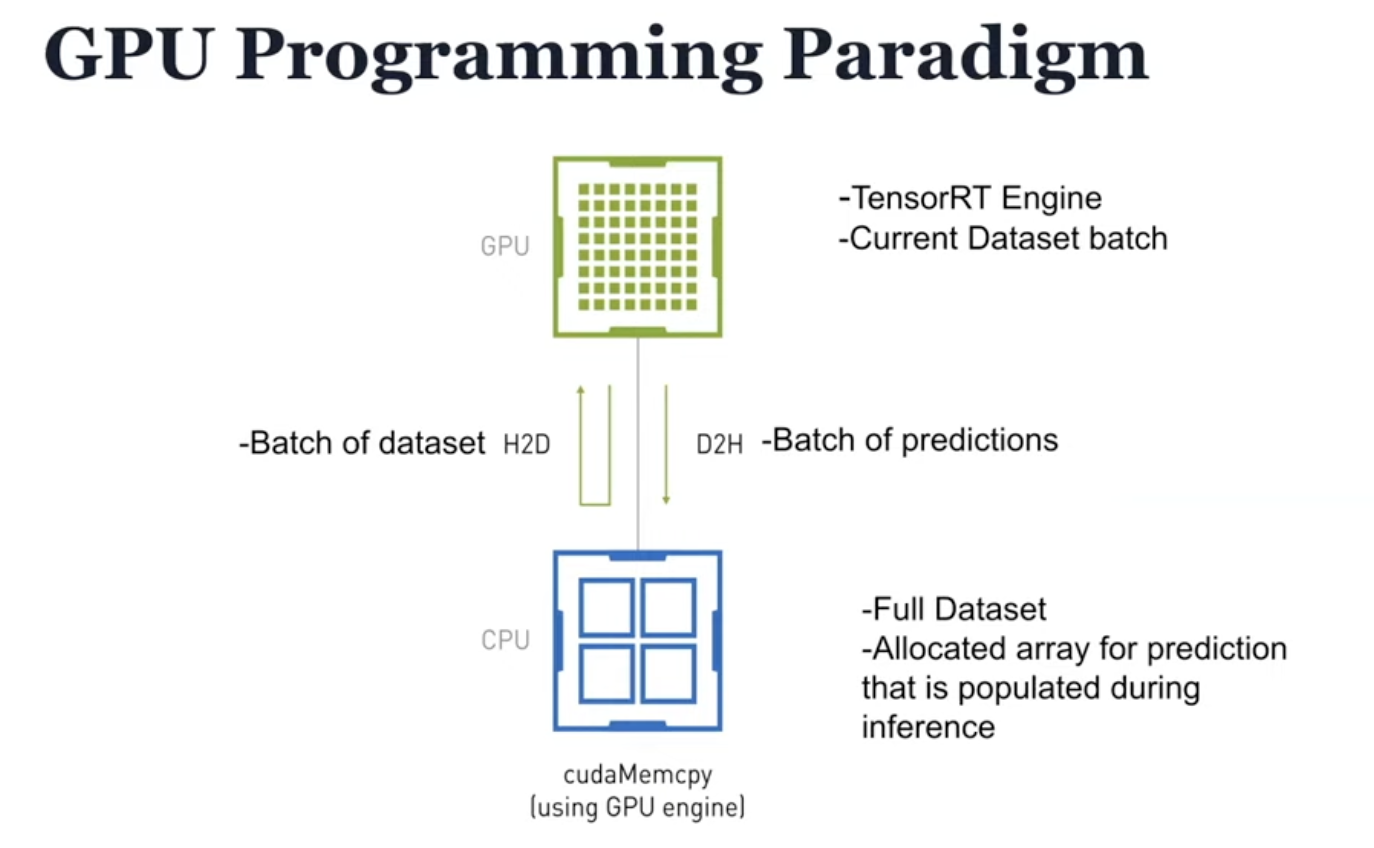
GPU编程范式补充:GPU执行时,数据需先从CPU内存(Host)通过cudaMemcpy拷贝到GPU显存(Device),即H2D(Host to Device)传输。推理结果再通过D2H传回CPU。这是架构图中未明确说明的底层数据流动。
二. BatchManager & Executor
1. Executor: 最高层 C++接口
Executor 是 TRT-LLM 对外暴露的最高层 C++ **接口,目标是隐藏底层复杂性:**多 GPU 通信、批处理调度和内存管理的复杂性。
- 请求管理:接收 Prompt、采样参数、最大生成长度,返回异步响应流
- 架构封装:内部封装 BatchManager,决定请求的进出队列时机
- 资源分配:协调多 GPU 的张量并行(Tensor Parallelism)和流水线并行(Pipeline Parallelism)
关键循环:
执行循环结构(executionLoop) :
fetchNewRequests
->>forwardAsync(异步提交GPU计算)
->>forwardSync(等待结果)
->>postProcessRequests(后处理/返回)
每次循环迭代= 一个step= 生成一个token。
2. 多GPU并行策略
Executor 负责协调的两种多 GPU 并行策略本质上解决的是同一个问题:单张 GPU 装不下或算不完一个大模型,需要把工作拆分到多张 GPU 上。但两者的拆分维度完全不同。
1) 张量并行**(** Tensor Parallelism , TP )
核心思想:把同一层(layer)内的权重矩阵横向切开,分到多张GPU上并行计算,最后合并结果。每张GPU持有模型每一层的一部分权重。
|-------------|------------------------------------------|------------------------|
| 部件 | 切分方式 | 通信操作 |
| QKV 投影权重 | 按 head 维度列切分,每张 GPU 负责一部分 attention head | AllReduce(合并各 GPU 的输出) |
| FFN(前馈网络)权重 | 第一层按列切分(每 GPU 负责一部分中间维度),第二层按行切分 | AllReduce(合并各 GPU 的输出) |
以TP=4的LLaMA-70B为例,每层内部计算过程如下:
输入 hidden_state (全量,每张 GPU各有一份相同副本)
|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| ├─ GPU0: 负责 head 0~7 的 QKV 计算 + attention ├─ GPU1: 负责 head 8~15 的 QKV 计算 + attention ├─ GPU2: 负责 head 16~23 的 QKV 计算 + attention └─ GPU3: 负责 head 24~31 的 QKV 计算 + attention |
AllReduce ─► 4 张 GPU 的结果求和合并,每张 GPU 得到完整输出
|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| ✓ 张量并行特性总结 优点:每张 GPU 只存模型一层权重的 1/N,显存占用大幅降低;各 GPU 并行计算同一层,延迟低,适合单次推理的低延迟场景。 代价:每一层计算结束后必须执行 AllReduce 通信(所有 GPU 求和),通信量与 hidden_size 成正比。GPU 之间需要 NVLink 高速互联,否则通信瓶颈会抵消并行收益。 典型配置:TP=2 或 TP=4(单机内,NVLink 连接)。TP 超过 8 时通信开销往往大于并行收益。 |
2)流水线并行(Pipeline Parallelism , PP)
核心思想:把模型不同的层( Layer )分配到不同的 GPU 上,数据像流水线一样依次流过各 GPU 。每张 GPU 只存和计算模型的一段层。
|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 以 PP=4 的 LLaMA-70B 为例(共 80 层 Transformer): GPU 0: Layer 0~19 (Embedding + Transformer layers 0-19) GPU 1: Layer 20~39 (Transformer layers 20-39) GPU 2: Layer 40~59 (Transformer layers 40-59) GPU 3: Layer 60~79 (Transformer layers 60-79 + LM Head) |
**注意:**流动的是激活值(activation),不是权重。权重在训练结束后就固定分布在各GPU上,不会在GPU间移动。
Pipeline Bubble问题:
朴素PP的致命问题是大量气泡(idle时间)。以单batch为例,在任一时刻只有一张GPU在工作,其他GPU全部空等:
|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 时间轴 ─────────────────────────────► GPU0: ** 计算** idle idle idle GPU1: idle ** 计算** idle idle GPU2: idle idle ** 计算** idle GPU3: idle idle idle ** 计算** ← GPU 利用率仅 25% |
Micro-batch填充Bubble, 让他们在pipeline中交织执行,GPU0处理完mB0后立即处理mB1. 此时GPU1开始处理mB0,各GPU流水作业:
|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 时间轴 ─────────────────────────────────────────────► GPU0: mB0 mB1 mB2 mB3 bubble GPU1: wait mB0 mB1 mB2 mB3 GPU2: wait wait mB0 mB1 mB2 mB3 GPU3: wait wait wait mB0 mB1 mB2 mB3 ← bubble大幅减少 |
|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| ✓ 流水线并行特性总结 优点:每张 GPU 只存模型 1/N 的层,显存需求线性降低;GPU 间通信只在层边界传递激活值(P2P 点对点),通信量远小于 TP 的 AllReduce。 代价:Pipeline Bubble(流水线气泡)不可完全消除,micro-batch 越多 bubble 占比越小,但不能为零。增加 micro-batch 数量会增加单个请求的排队延迟。 典型配置:PP=2 或 PP=4(跨机器,PCIe 或 InfiniBand 连接)。TRT-LLM 1.0 中实际较少用到 PP,主要依赖 TP。 |
③ TP vs PP 对比与组合使用
|------|-----------------------|---------------------------|
| 维度 | 张量并行(TP) | 流水线并行(PP) |
| 切分对象 | 同一层的权重矩阵(列/行切分) | 不同的层(按 Layer 分段) |
| 通信方式 | AllReduce(每层都需要,通信量大) | P2P Send/Recv(仅在层边界,通信量小) |
| 互联要求 | 需要 NVLink 高速互联(单机内) | 可跨机器(InfiniBand / PCIe) |
| 主要瓶颈 | AllReduce 通信延迟 | Pipeline Bubble(idle 时间) |
| 适用场景 | 单机多卡(8 GPU 以内),低延迟优先 | 超大模型跨机部署(单机内存不足时) |
两者可以组合使用( TP × PP )。以 8 台机器 × 8 卡为例( 64 GPU ),设置 TP=8 , PP=8 :每台机器内的 8 张卡做张量并行, 8 台机器之间做流水线并行,充分利用机器内的高速 NVLink 和机器间低通信量的 PP 特性。
机器0 GPU0\~7, TP=8: Layer 0~9 (PP Stage 0)
机器**1 GPU8\~15, TP=8: Layer 10~19 (PP Stage 1) ...**以此类推
3. TrtGptModelInflightBatching: 中央协调器
这是整个推理流水线的中央协调器,内部持有所有子组件的引用,按照in-flight batching的节奏协调他们工作。

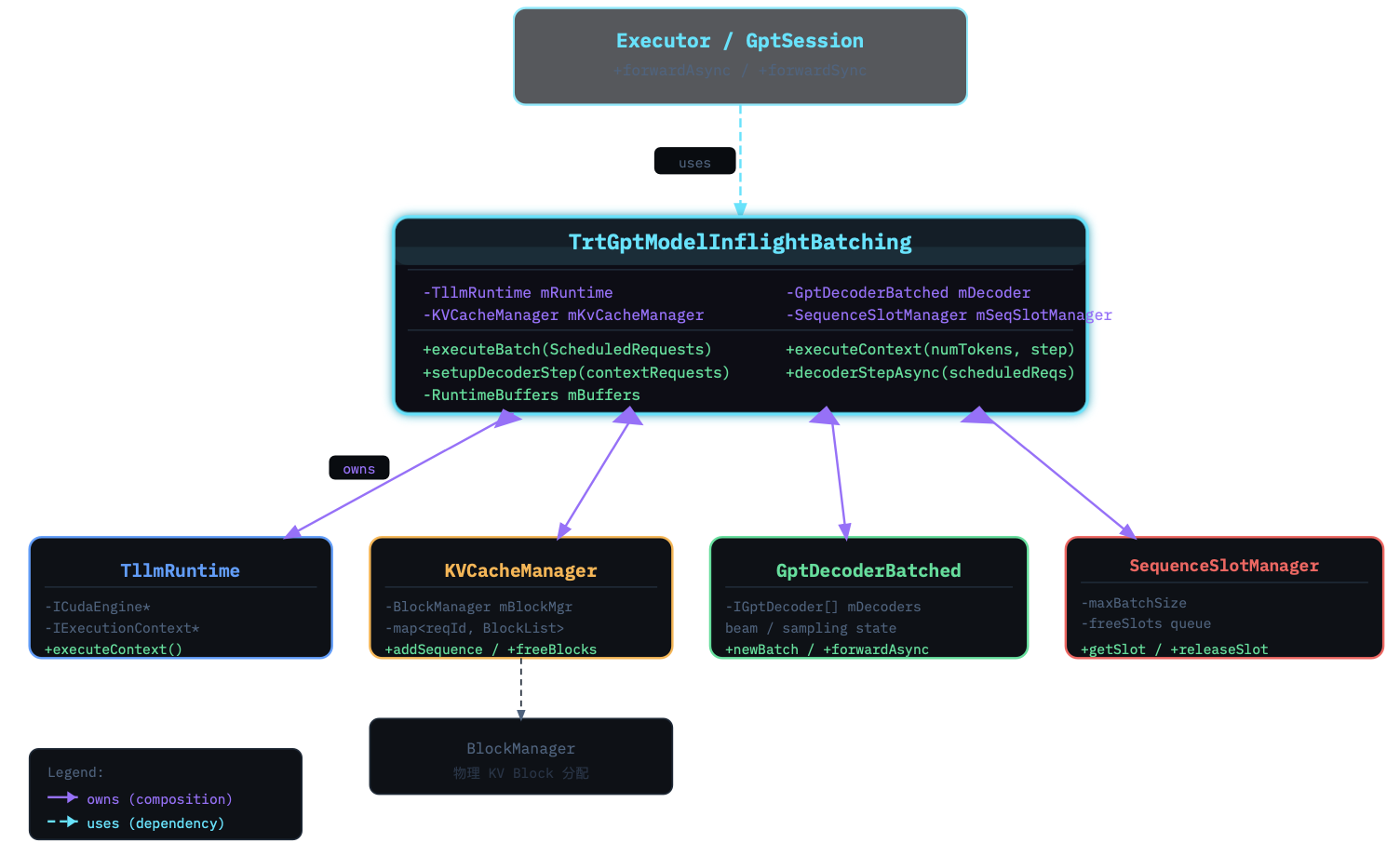
这是一个偏向底层的核心类(通常被 BatchManager 调用),专门用于处理具有 In-flight Batching(动态批处理/连续批处理) 能力的模型推理。
• 核心计算:它直接与编译好的 TensorRT Engine 交互。当 Executor 将一批请求交给底层时,这个类负责执行实际的 GPU 前向传播(Forward Pass)。
• 混合阶段处理:这是 In-flight Batching 的核心。它能够在一个 Batch 内,同时处理处于 Context 阶段(Prefill,计算 Prompt 的 KV Cache)的请求和处于 Generation 阶段(Decode,逐字生成)的请求。
• KV Cache 管理交互:它与 Paged KV Cache 管理器深度配合,在生成新 Token 时动态申请和释放显存块。
2.1 五大核心成员
|---------------------------------------|-----------------------|----------------------------------------------------|
| 成员 | 类型 / 别名 | 职责 |
| TllmRuntime (mRuntime) | TensorRT Engine 直接包装器 | 持有 ICudaEngine 和 IExecutionContext,负责实际 GPU 前向计算 |
| KVCacheManager (mKvCacheManager) | Paged KV Cache 管理器 | 将显存切成固定大小 Block,动态分配/回收,实现前缀共享 |
| GptDecoderBatched (mDecoder) | 批量 Token 解码器 | 接收 Engine 输出的 logits,执行 top-p/top-k/beam search 采样 |
| RuntimeBuffers (mBuffers) | GPU/CPU 缓冲区集合 | 每个 step 准备 input_ids、position_ids、KV Cache 地址表等张量 |
| SequenceSlotManager (mSeqSlotManager) | 序列槽位管理器 | 将每条请求映射到 batch tensor 中固定大小的「槽」,保证并发请求不互相覆盖 |
1. TllmRuntime 详解
TllmRuntime是TensorRT Engine的直接包装器,内部包含两个核心对象:
|-------------------|---------------|-----------------------------------------------------------------------------------------------------------------------|
| 对象 | 特性 | 存储内容 |
| ICudaEngine | 静态知识库(只读、无状态) | build 一次可被多线程读取。存储:优化后的 CUDA kernel 二进制、网络拓扑、权重数据(frozen)、Profile 的 kernel 选择方案、binding 的 shape/dtype 元信息 |
| IExecutionContext | 运行时状态机(有状态) | 一次只能跑一个推理。存储:当前绑定的 input/output device pointer、激活的 optimization profile index、中间激活值显存、关联的 CUDA stream、当前请求的动态 shape 值 |
***为何每个Profile需要独立的Context?***这是TensorRT的硬性约束:一个IExecutionContext在同一时刻只能绑定一个Profile。因为Context持有的中间激活值显存大小是按绑定Profile的max shape来预留的。Profile 0(prefill, 大seq)和 Profile 1(decode, 大batch)的max shape不同,显存布局不同,不能混用。因此TRT-LLM中 mContext0服务prefill, mContexts1服务decode。
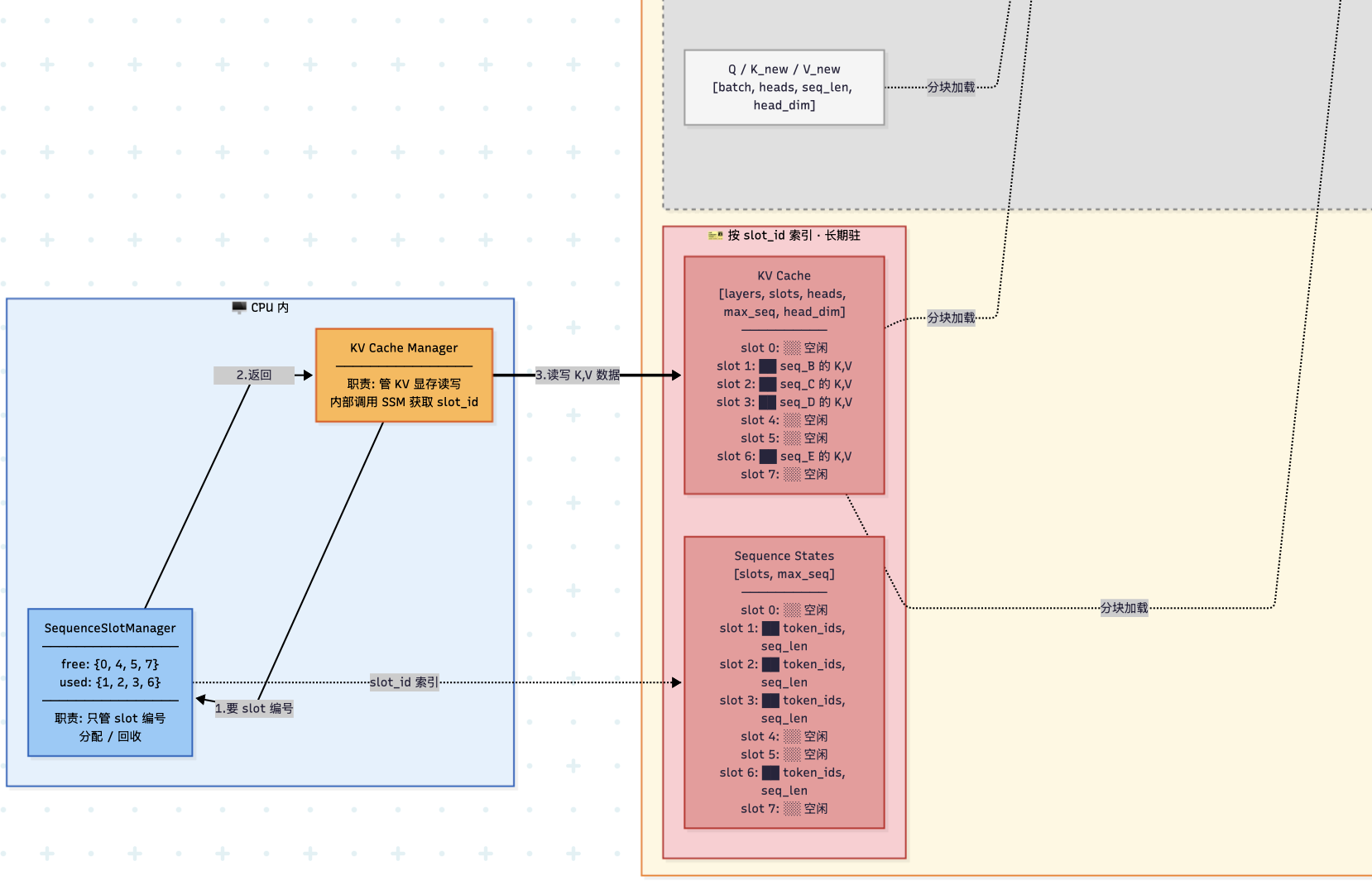
2. KVCacheManager 详解
类比:KVCacheManager就想酒店前台,负责管理房间(Block)的分配与回收
- 初始化池子:调用 allocatePools 预先占领 GPU 显存,防止推理时频繁申请导致卡顿。
- 动态记账:每生成一个 Token,经理就检查当前的 Block 够不够用。不够用了,就从池子里分配一个空闲 Block。
- 跨请求调度:如果开启了 enableBlockReuse,它会像"拼车"一样,让相同前缀的请求共用物理显存块,从而极大地节省显存并提升吞吐量。
KVCacheManager 与Decoder交互时序:
- 准备阶段:BatchManager 询问 KVCacheManager 各个请求的KV数据写入哪个地址,生成Block Table(块表:本质上是一组显存指针的索引), 这个表被传递给 GPU 算子(Paged Attention 算子),确保计算出的 KV 数据精准落入对应的 Block 空间
- 推理阶段:GPU算子(Paged Attention)根据Block Table 自动写入数据,无需Decoder参与
- 结果反馈:Decoder选出Next Token后通知KVCacheManager; 若请求未结束,KVCacheManager 检查当前 Block 是否已满;若请求结束(EOS),立即回收该请求所有Block
3. GptDecoderBatched 详解
decoder的核心职责不是进行矩阵乘法(那是Engine的事),而是做决策,根据Engine输出的概率分布(logits)选出下一个token。
Decoder 的工作流程如下:
- 接收 Engine输出的Logits(巨大矩阵,表示下一个词的概率分布)
- 执行采样逻辑(top-k/ top-p/ beam search/ repetition_penalty等):
• 如果配置了 topK=40,Decoder 就会在词表中找出概率最大的前 40 个。
• 如果设置了 repetition_penalty,它会检查之前生成了什么词,降低它们的权重。 - 确定 Next Token:最终选出一个 Token ID(比如"3021")。
- 状态更新:判断这个 Token 是不是结束符(EOS),或者是否达到了最大长度。
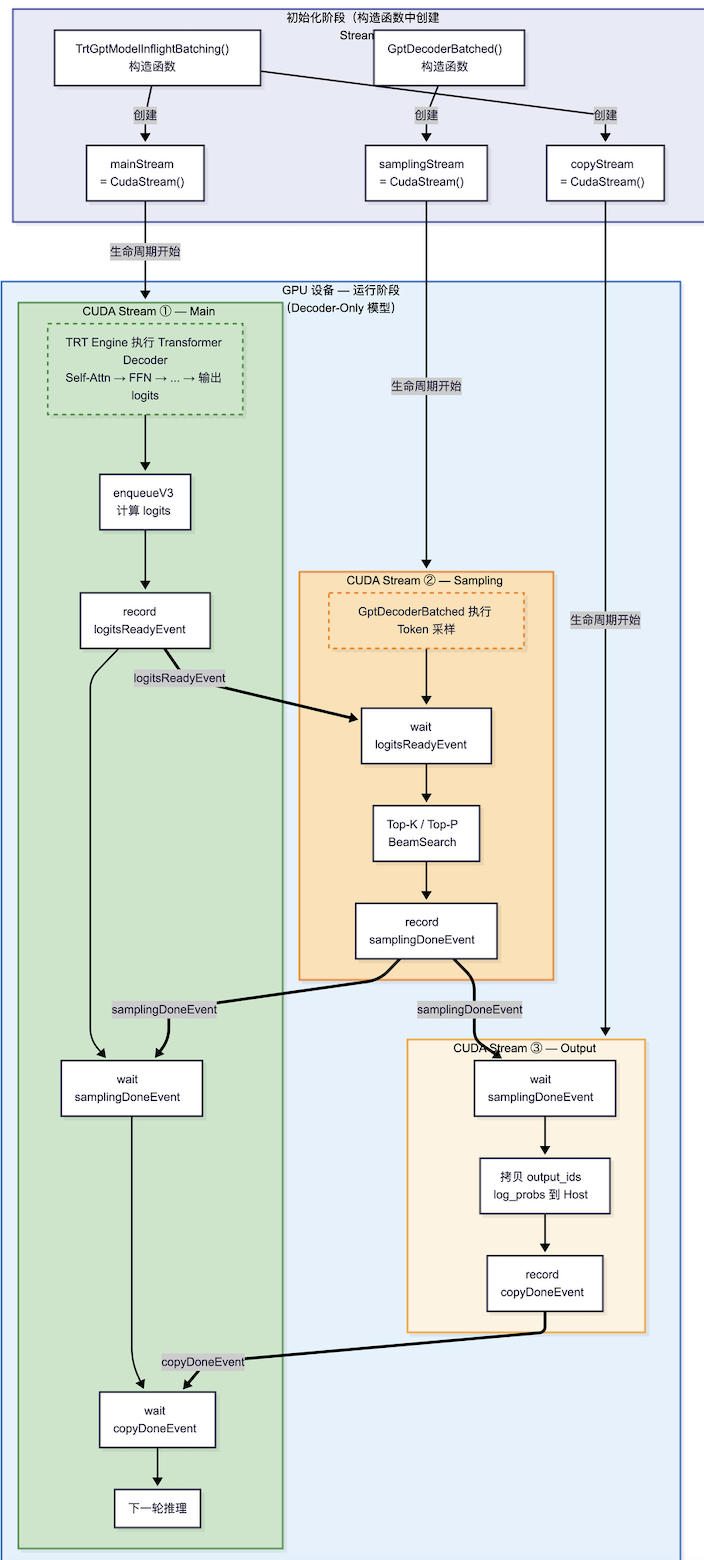
Decoder与Engine共享一个CUDA stream的原因:
*为什么共享stream:*你把 Engine::enqueue(计算指令)和 Decoder::forward(采样指令)按顺序丢进同一个流。若不共享stream,Decoder可能跑的太快,在Engine还未写完logits时就去读取,导致读到乱码或全0。通过同一个stream保序,GPU保证先完成Engine计算,再执行Decoder的采样操作。
GPU实现采样的高效技巧:
- Top-K: 使用部分排序(Partial Sort)而非全排序。基于分桶或Bitonic Sort的并行算法,利用CUDA warp-level shfl 指令在寄存器内交换数据,避免访问慢速显存(HBM)
- Top-P: 先快速筛选出高概率候选词(如1024个)再并行计算前缀和(Prefix Sum), 最后二分查找定位阈值P的位置,也就是说把词按概率从高到低排好,一个一个往下加,直到累计概率超过了P(比如 {P=0.9})。效果:它比 Top-K 更聪明。如果模型很确定(前两个词概率就 95% 了),候选集就很小;如果模型很犹豫(概率分布很平坦),候选集就会变大。
- 算子融合(Kernel Fusion): 将 Softmax、Top-K 筛选、随机采样合并为一个 CUDA Kernel,数据只需读入显存一次,在寄存器内完成全部计算,极大减少 HBM 带宽浪费
- Temperature:
Temperature 是在 Decoder 生成文本时,对 logits(模型输出的原始分数) 进行缩放,从而控制下一个 token 的概率分布形状。
假设模型输出 3 个词的 logits 为[5, 3, 1]:
T = 1.0 (标准) → softmax(5, 3, 1) → 0.84, 0.11, 0.04
T = 0.5 (低温) → softmax(10, 6, 2) → 0.98, 0.02, 0.00 ← 更尖锐
T = 2.0 (高温) → softmax(2.5, 1.5, 0.5)→ 0.51, 0.31, 0.19 ← 更平坦
所以 T->0 几乎等价于greedy decoding,直选最优解;T → ∞ 趋近均匀分布 **"**随机乱选"
采样策略补充对比:
|--------------------|-----------------------------------------------|
| Greedy Search | 每次选概率最高的词,速度快但结果单一 |
| Top-K | 固定广度: 只从前K个高概率词中采样,K=1时退化为Greedy |
| Top-P | (Nucleus Sampling,动态广度):更智能,模型确定时候选集小,犹豫时候选集大 |
| Beam Search(束搜索) | 保留N条最优路径,适合翻译/摘要,但多样性差且计算量大,现代对话模型较少使用 |
| Temperature | 控制概率分布的「平滑度」,高Temperature更随机,低Temperature更确定 |
| repetition_penalty | 降低已生成词的权重,减少重复 |
4. RuntimeBuffers
CPU/GPU 缓冲区集合,每个step通过setTensorAddress告诉TRT引擎各个具名tensor的显存地址:
cpp
// 告诉引擎:名叫 "input_ids" 的输入tensor,数据在显存地址 ptr_A
context->setTensorAddress("input_ids", ptr_A);
// 告诉引擎:名叫 "kv_cache_block_pointers" 的tensor,在 ptr_B
context->setTensorAddress("kv_cache_block_pointers", ptr_B);
// 输出写到哪里
context->setTensorAddress("output_logits", ptr_C);TRT 引擎在编译时就确定了计算图的数据流,运行时只需要知道各个Tensor的实际显存地址即可launch kernel.
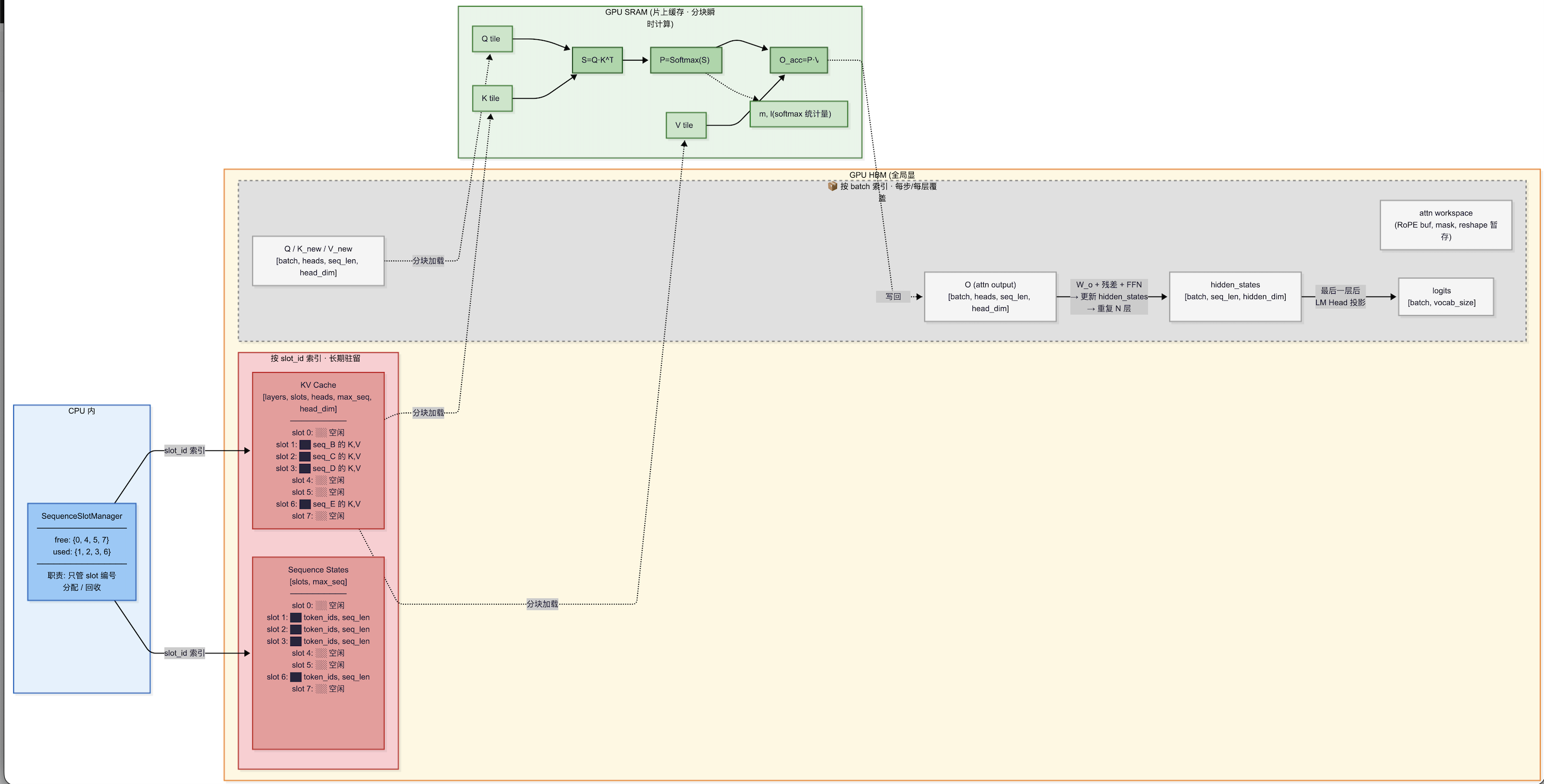
5. SequenceSlotManager
在 GPU 运行时,为了实现高效的并行计算,系统会预先开辟一块连续的内存空间,用于存放当前正在处理的所有请求的状态信息(比如:每个请求现在算到第几个 Token 了、Logits 放在哪、采样参数是什么)。假设系统设置最大并发数(max_batch_size)为 256,那么 GPU 上就有 256 个slot。
Slot ID:就是这些工位的编号(从 0 到 255)。 任务:每一个进入系统的活跃请求(Sequence),都必须先"入座"到一个 Slot 编号上,才能开始计算。
SequenceSlotManager 的核心职责
它的工作非常具体,主要包含以下三点:
- 分配 (Allocate):当一个新请求通过调度器进入执行队列时,SequenceSlotManager 会找出一个当前处于空闲状态(Idle)的 Slot ID 分配给它。
- 释放 (Release):当某个请求生成完毕(遇到结束符或达到最大长度)离开系统时,将对应的 Slot ID 重新标记为空闲,供下一个请求使用。
- 映射关系的维护 (Mapping): 记录 Request ID ↔ Slot ID 的对应关系
- 索引表:提供 Slot ID 作为索引,告诉 GPU 算子去哪里读取该请求的 Block Table
设计原因: 为何不直接用 Request ID?Request ID 通常是不连续的大数字,GPU 难以做连续内存访问。Slot ID 数量固定(= max_batch_size),使用 Slot ID 作索引可使所有状态数据在显存中「整齐排列」(Compact 布局),GPU 线程通过简单位移即可命中目标,访存效率极高。
它与其他组件的关系图
-
Scheduler (调度器):决定哪个请求可以开始跑了,然后向 SequenceSlotManager 要一个 Slot。2. SequenceSlotManager:给出一个 Slot ID(比如 Slot 7)。
-
KVCacheManager:根据 Slot 7,把这个请求的 KV 数据存入对应的显存块。
-
Decoder/Engine:在执行时,读取 Slot 7 里的状态,算出结果。
不同数据所在buffer的管理图:
如果将KV CacheManager的工作职责加入:局部放大左下角:
三. 调度器 Scheduler
调度器决定了什么时候把请求放进 GPU 计算。TRT-LLM 采用双层调度架构:
3.1 双层调度架构
TRT-LLM 采用双层调度框架,职责分明:
|-------------------------|--------|----------------------------------------------------------------------|
| 层级 | 维度 | 核心问题 |
| 第一层:CapacityScheduler | 资源维度筛选 | 根据 KV Cache Block 的可用数量,决定哪些请求「可以执行」(显存够吗?) |
| 第二层:MicroBatchScheduler | 计算维度分组 | 决定「如何分组执行」,处理Chunked Context 和 Pipeline Parallelism 的 micro-batch 切分 |
第一阶段:CapacityScheduler(容量调度)
核心准则:绝不超载(显存容量) + 尽量塞满(算力利用率)。唯一盯着的资源是 KV Cache Blocks(由 KVCacheManager 管理)
在每一轮推理(Iteration/Step)开始前,决定哪些新请求可以加入批次,以及哪些旧请求可以继续执行。
两种调度策略
- 保守策略(Guaranteed Completion):只有当剩余 KV Cache 足以支撑当前批次所有请求跑到 max_new_tokens 时,才允许新请求进入。极度安全,但吞吐量低
- 激进策略(Optimistic Over-subscription,主流):只要当前显存够这一步运行就让请求进来。若后续显存满了,则踢掉队列末尾(最新的)请求
为什么踢队尾而不是队首?( LIFO 抢占)
- 队尾请求资源消耗最少:刚开始 prefill 或尚未完成,已消耗计算最少
- KV Cache 占用最小:释放后能为新请求提供最多空间
- 重新调度代价最小:处于 prefill 阶段,不需要处理复杂的 beam state 或 draft token 回滚
- 数学最优性:抢占代价 = 被抢占请求的重调度开销 + 已浪费计算量,队尾请求使该值最小
队列顺序(按进入时间):
请求A: 已生成800 tokens ← 队首(最老)
请求B: 已生成400 tokens
请求C: 已生成100 tokens
请求D: 刚开始 prefill ← 队尾(最新)
抢占后被踢走的请求会怎样?「将其放回等待队列(waitingQueue.push_front)」,即重新排队等待。这意味着被抢占的请求不会丢失,但已经完成的 prefill 计算(及其 KV Cache)会被丢弃,重新调度时需重新进行 prefill。这是激进策略的真实代价。
代码逻辑:
cpp
// 激进策略伪代码
while (!canFitNewRequest(newRequest)) {
// 从队列末尾找一个可抢占的已启动请求
auto victim = runningQueue.back(); // ← 队尾!
// 释放其KV Cache
kvCacheManager.freeBlocks(victim);
// 将其放回等待队列
waitingQueue.push_front(victim);
runningQueue.pop_back();
// 检查是否现在能容纳新请求
}可用 KV Cache Blocks
│
├─ 已运行请求的增量需求(decode step)
└─ 新请求的prefill需求(最保守估计 or 激进估计)
第二阶段 :MicroBatchScheduler(流水线调度)
MicroBatchScheduler 做三件事:
① 按状态分流
- contextRequests:isContextInitState(),即 prefill 请求
- generationRequests:isGenerationInProgressState(),即 decode 请求
- 硬约束:batchNumTokens + reqTokens > maxNumTokens 则 break;scheduledSize >= maxBatchSize 则 break
② Chunked Context (核心职责)
当一个 prefill 请求的 context 太长、放不进当前 batch 的 token 配额时,不跳过它,而是切块执行:
|--------------------|---------------------------------------------------------------------------------------------------------------|---------------------------|
| 模式 | 执行示意 | 效果 |
| 没有 Chunked Context | iteration 1: 4096 token prefill 独占 iteration 2: decodedecodedecode | decode 请求在 prefill 期间全部饿死 |
| 有 Chunked Context | iteration 1: prefill chunk 1/4decodedecode iteration 2: prefill chunk 2/4decodedecode | prefill 和 decode 交织,延迟更平滑 |
两种公平策略:
- kEQUAL_PROGRESS(公平):所有 context 请求轮转均匀分配 token 配额,防止长请求饿死短请求
- kFIRST_COME_FIRST_SERVED(先到先得):先来的请求优先吃满配额,早到请求的 TTFT(Time To First Token)更低
forwardAsync
└── mCapacityScheduler(activeRequests, kvCacheManager)
→ fittingRequests (KV Cache 维度筛选)
└── mMicroBatchScheduler(fittingRequests)
→ {contextRequests, generationRequests} (batch 维度限制)
capacityScheduler是资源容量决策;决定"本轮能接受多少请求进入执行" 关注:KV Cache容量、内存、并发上限。
③ Draft Token 裁剪( Speculative Decoding 配套)
fitDraftTokens():speculative decoding 生成的 draft token 如果放不进当前 chunk 的剩余空间,裁掉多余部分,按 block 边界对齐。
Speculative Decoding 补充:一种加速技术,使用小的 draft model 快速猜测多个 token(draft tokens),再用大模型一次性验证。如果猜对了,相当于一次 forward pass 生成了多个 token,大幅提升吞吐量。MicroBatchScheduler 的 draft token 裁剪就是为了适配这个机制。
3.3 调度的具体流程 (Iteration-based)
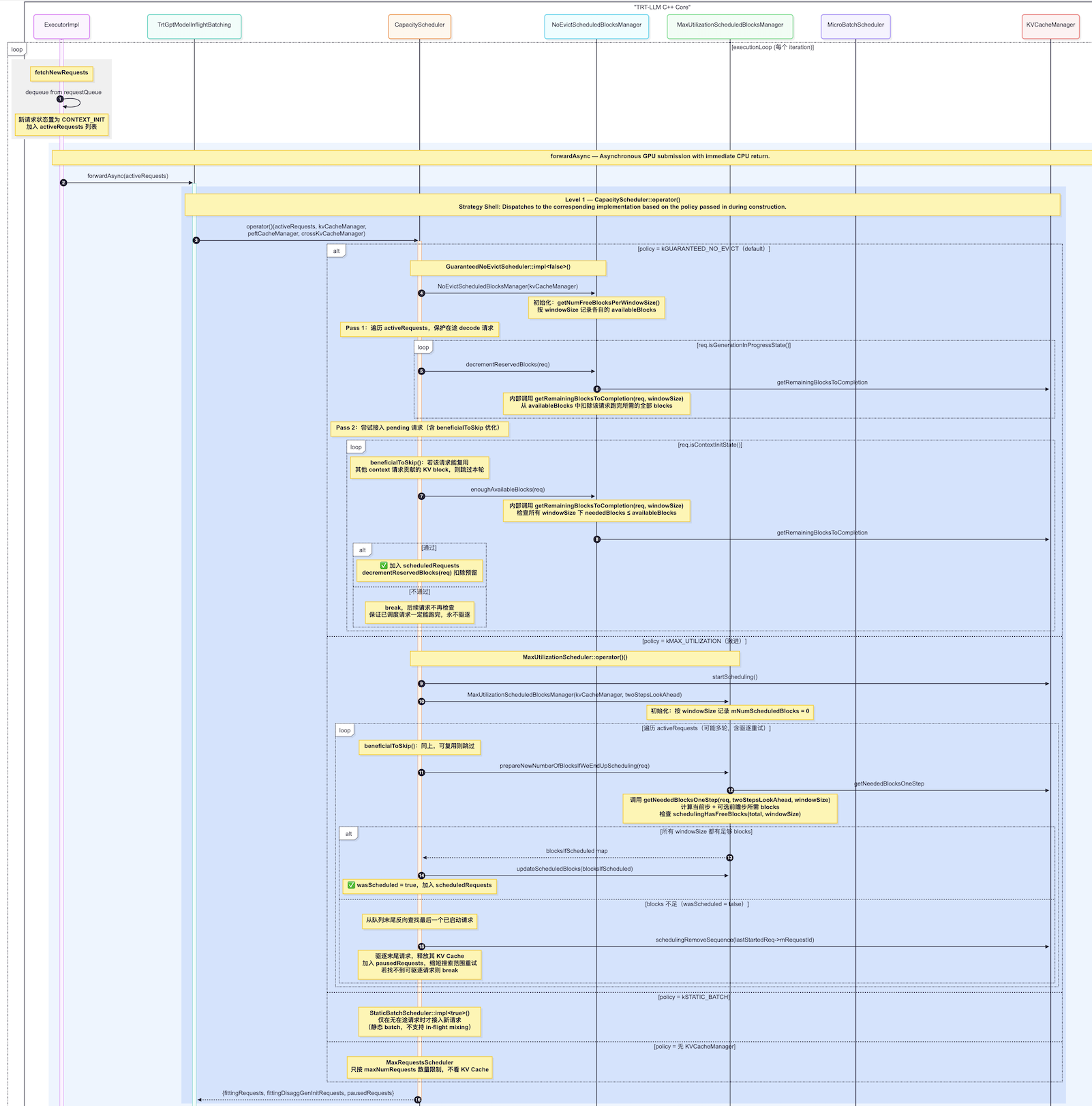
在每一轮 step() 开始时,CapacityScheduler 会执行以下逻辑:
第一步:状态盘点 (Resource Update)
它会向 KVCacheManager 询问:
• "池子里还剩下多少个空闲的物理 Block?"
• "当前正在跑的这些请求,这一步需要增加多少 Block?"
第二步:处理"进行中"的请求 (Active Requests)
调度器优先保证已经在跑的请求。如果显存非常紧张,它会根据算法(通常是 FCFS - 先来后到)保留旧请求。
第三步:筛选"待进入"的请求 (Pending Queue)
它会扫描等待队列:
-
预估需求:计算新请求的 Prompt 长度,确定它入场需要占用多少个 Block。
-
容量校验:
• Available Blocks >= Required Blocks + Safety Margin
-
Slot 检查:询问 SequenceSlotManager 是否还有空闲的"工位"(Slot)。
-
准入:如果显存和工位都够,这个请求就被"激活",分配 SlotID。
- 关键决策算法:如何应对"显存爆炸"?
如果在推理中途,显存块用完了怎么办?CapacityScheduler 有一套**抢占(Preemption)**机制:
-
暂停(Suspend):选择一个或多个请求(通常是最后进来的那个)。
-
驱逐(Eviction):
• Swap(交换):将该请求的 KV Cache 从显存搬到系统内存(CPU RAM)。等显存宽裕了再搬回来。
• Recompute(重算):直接扔掉该请求的 KV Cache。等有空间了,重新跑一遍 Prompt。
-
腾挪:回收被驱逐请求占用的 Blocks,分给优先级更高的请求。
-
与其他组件的交互关系
它不是一个单一的调度器,而是一个策略壳,里面封装了两种具体实现:
CapacityScheduler
├── GuaranteedNoEvictScheduler (默认策略,保守)
└── MaxUtilizationScheduler (激进策略,高吞吐)
四. 完整的初始化阶段:
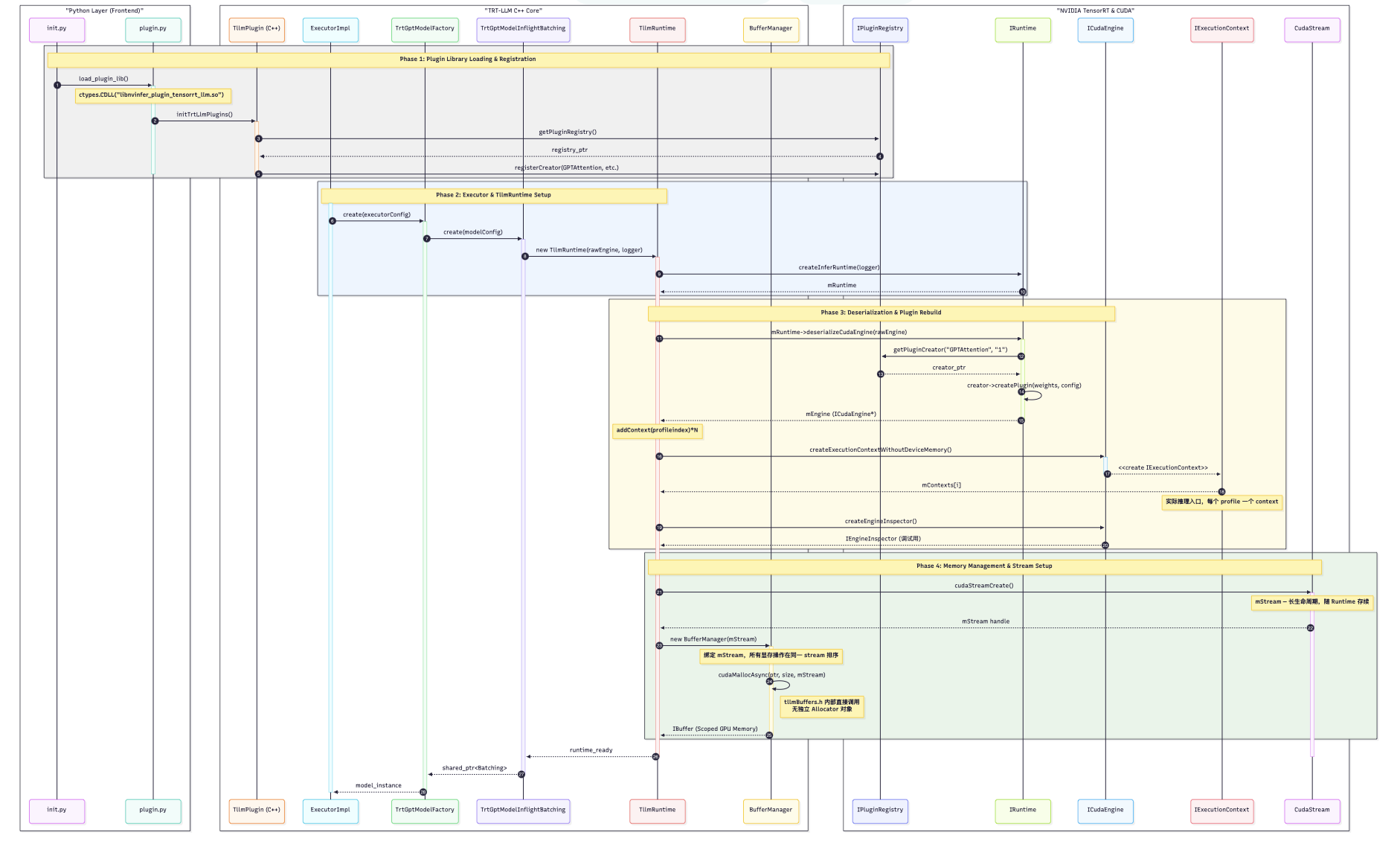
Phase1: plugin libaray loading & registeration

程序启动时,加载libnvinfer_plugin_tensorrt_llm.so 动态链接器自动执行 .init_array 段中的函数(attribute((constructor)) 函数),调用 initTrtLlmPlugins,将所有自定义 Plugin Creator 注册进 TRT 全局 Registry。
两个so文件的区别: libtensorrt_llm.so:Runtime 核心类(TllmRuntime、KVCacheManager、GptSession 等)。libnvinfer_plugin_tensorrt_llm.so:所有 TRT Plugin 的Creator + initOnLoad 注册逻辑。
程序启动
│
├─ dlopen(libnvinfer_plugin_tensorrt_llm.so)
│ └─ 静态初始化器执行
│ └─ REGISTER_TENSORRT_PLUGIN(XxxCreator)
│ └─ getPluginRegistry().registerCreator(...)
│ ↓ 全局 Registry 里有了所有 Creator
│
├─ runtime->deserializeCudaEngine(blob, size)
│ └─ TRT 解析每个 layer
│ └─ 遇到 Plugin layer → 读出 (name, ver, ns)
│ └─ registry.getPluginCreator(name, ver, ns)
│ └─ creator->deserializePlugin(name, data, len)
│ └─ new GPTAttentionPlugin(data, len)
│ ↑ Plugin 实例重建完成
│
└─ ExecutionContext 创建,可以推理
其中
libnvinfer_plugin_tensorrt_llm.so 被加载
│
│ Linux ELF .so 加载时,动态链接器会自动执行
│ .init_array 段中注册的所有函数
│ (attribute((constructor)) 函数就放在这里)
▼
void attribute((constructor)) initOnLoad()
{
// tllmPlugin.cpp 中的实现
initTrtLlmPlugins(nullptr, "tensorrt_llm");
// 等价于把所有 Creator 注册进 TRT 全局 registry
}
Phase2: Executor & tllmRuntime setup
创建 Executor 实例,初始化 TllmRuntime ,为每个 Profile ( prefill/decode )创建独立的 IExecutionContext 和对应的显存块。
Phase3: Engine反序列化 & plugin rebuild

-
Engine **序列化时,**每个 Plugin layer 存储了 (pluginName, pluginVersion, pluginNamespace, pluginState) 四元组。
|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| // Engine 序列化时,每个 Plugin layer 存储: struct PluginSerializedData { char pluginName\[\]; // e.g. "CustomAttentionPlugin" char pluginVersion\[\]; // e.g. "1" char pluginNamespace\[\]; // e.g. "tensorrt_llm" byte pluginState\[\]; // Plugin 自定义的权重/参数数据 // 由 Plugin::serialize() 写入 }; | -
反序列化时,TRT 读出三元组,从 Registry 查找对应 Creator,调用 creator->deserializePlugin() 重建 Plugin 实例(包含权重和参数)。
|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 序列化 vs 反序列化核心点:Engine 文件(.plan 文件)是「可移植的推理快照」,包含优化好的 CUDA kernel 和 Plugin 的状态数据。但 Plugin 的 Creator 类必须在程序启动时提前注册,否则反序列化时找不到对应 Creator 会报错。这是 TRT-LLM 为什么必须先执行 Phase 1 加载 Plugin 库的根本原因。 |
TensorRT-LLMTRACE tensorrt_llm::batch_manager::TrtGptModelInflightBatching::TrtGptModelInflightBatching(std::shared_ptr<nvinfer1::ILogger>, const tensorrt_llm::runtime::ModelConfig&, const tensorrt_llm::runtime::WorldConfig&, const tensorrt_llm::runtime::RawEngine&, bool, const tensorrt_llm::executor::ExecutorConfig&, bool) start
这是整个batch manager的核心对象被构造, 他是负责 管理整个推理生命周期的主类,完整的类签名告诉你它的依赖:
代码位置:
cpp/tensorrt_llm/batch_manager/trtGptModelInflightBatching.cpp
→ TrtGptModelInflightBatching::TrtGptModelInflightBatching() 构造函数
ILogger: TensorRT的日志接口
ModelConfig: 所有模型配置
WorldConfig: MPI 的TP/PP配置
RawEngine: 刚加载的engine对象
Executor: Exexutor层面的配置(调度策略等)
Phase4: GPU Stream & Buffer Context 绑定
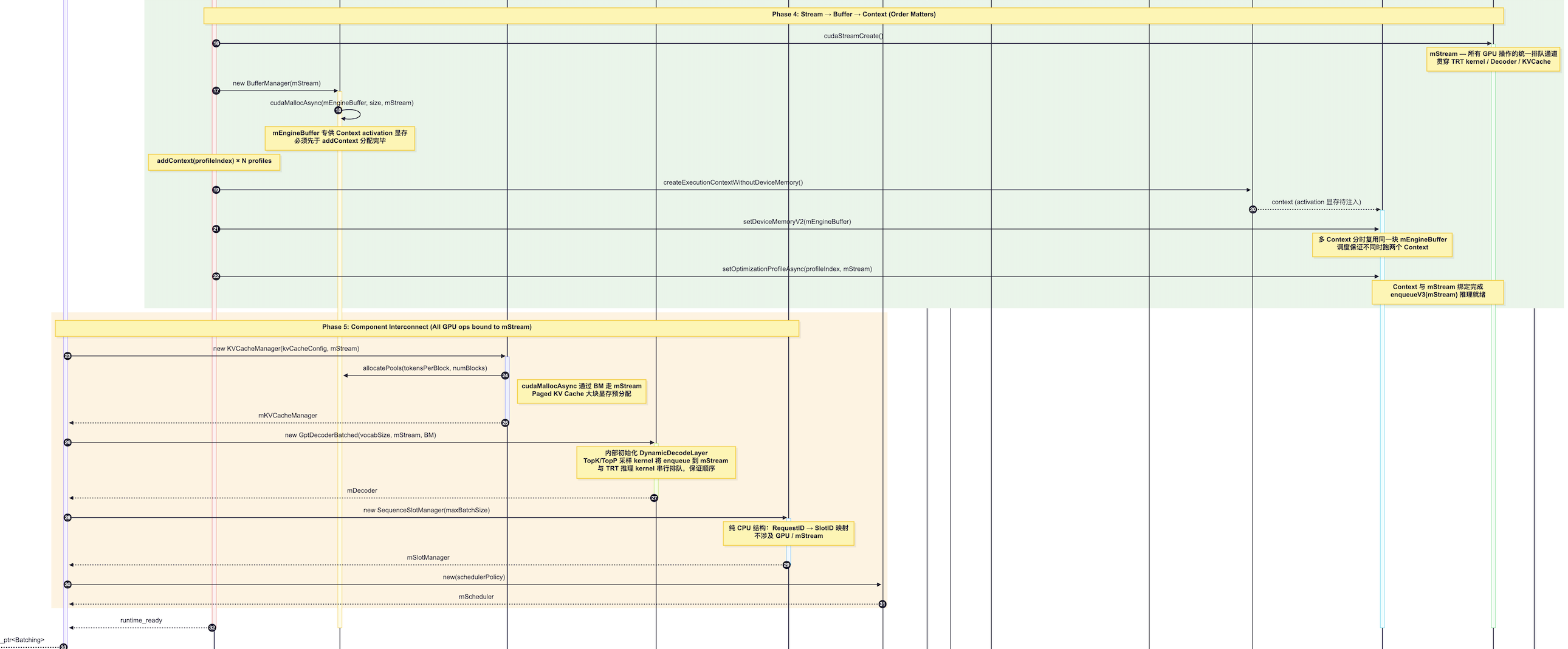
创建 CUDA Stream(mStream),为各 Context 分配显存(mEngineBuffer),完成 Decoder、KVCacheManager、SequenceSlotManager 等所有子组件的初始化。TrtGptModelInflightBatching 构造完成后,系统进入等待请求的状态。
五. 完整的推理流程:
5.1 关键概念
PrepareBuffers & Tensor Address 绑定
"绑定"是告诉 TensorRT :「这个张量的数据放在显存的哪个位置」。通过 context.setTensorAddress() 完成:
- input_ids:当前 step 的 token ID 数组
- sequence_lengths:各序列的长度
- kv_cache_block_pointers:KV Cache 的 Block Table(非连续显存块的地址索引)
- output_logits:Engine 输出写入的位置
enqueueV3究竟做了什么?
- 输入验证与绑定:检查所有 I/O tensor 是否已绑定,验证 shape 合法性(动态 shape 推断)
- Shape 推断:根据实际输入形状推断所有中间/输出 tensor 的形状
- Workspace 分配检查:验证 scratch workspace 是否足够
- CUDA Graph 检查:shape 未变化时,直接 replay 已录制的 Graph(CPU overhead ≈ 0);shape 变化则回退到逐个 launch kernel 或重新 capture Graph
- Kernel Launch(核心):向 stream 提交 Embedding、RoPE、Attention、FFN、LayerNorm、LM Head 等所有 kernel
│ 按照 TRT 优化后的执行计划,向 stream 提交:
│ ├─ cuBLAS GEMM kernels(QKV projection, FFN等)
│ ├─ Flash Attention / Paged Attention kernels
│ ├─ 自定义 plugin kernels(如 RotaryEmbedding)
│ └─ 内存拷贝操作(D2D,用于KV Cache管理) - 立即返回(异步!):CPU 不等待 GPU 完成,继续处理下一个 micro-batch(CPU/GPU Overlap)
enqueueV3本质上是向CUDA stream 提交一个完整推理step的异步计算图,其异步特性正是TRT-LLM能做到CPU/GPU overlap、pipeline流水线的基础。
5.2 CPU/GPU Overlap
首先最重要的是GPU-CPU overlap,如下图所示:
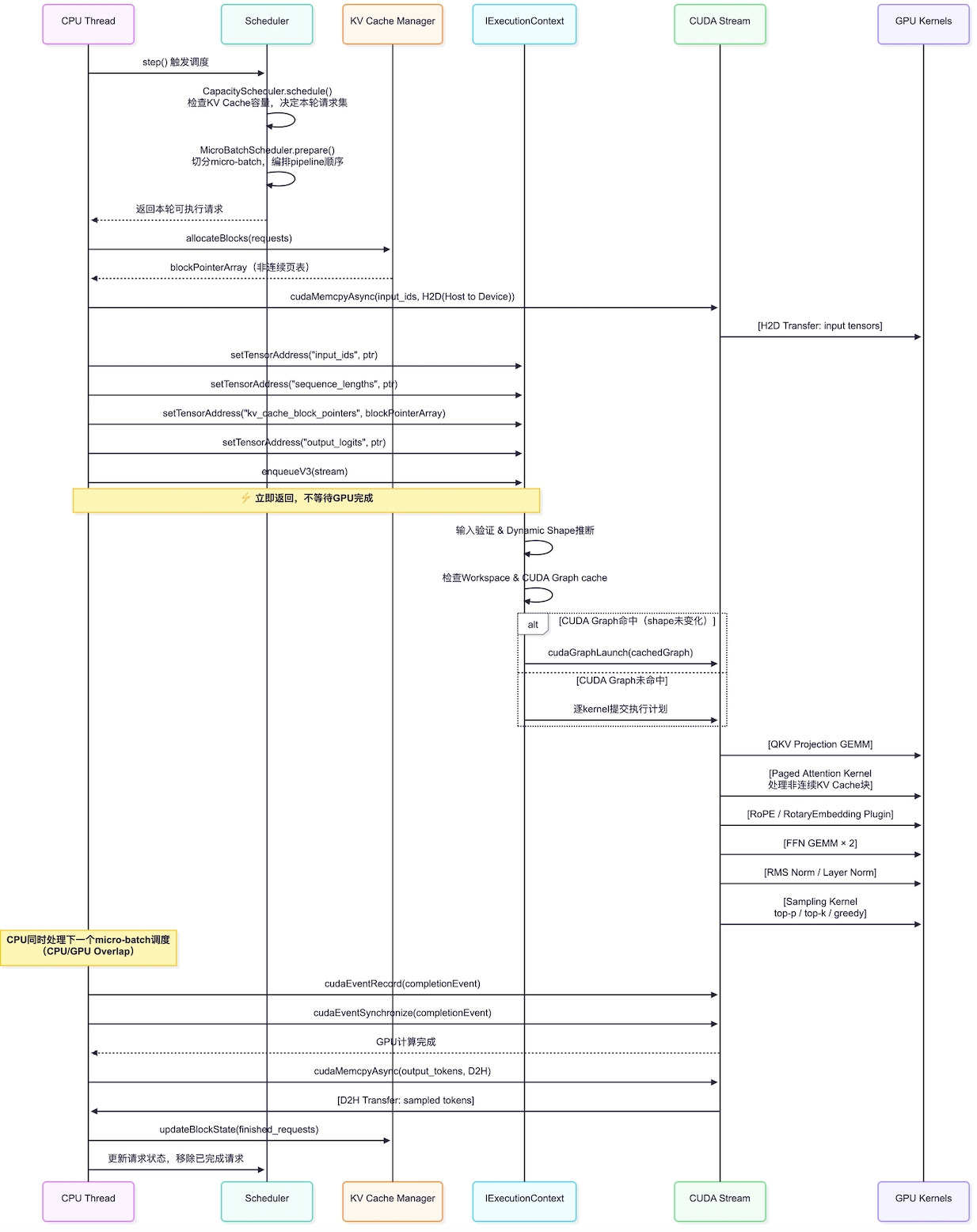
TRT-LLM **性能的关键之一:**enqueueV3 提交完 GPU 任务后立即返回,CPU 趁机调度下一个 micro-batch,做下一次迭代的调度工作:
|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Overlap 示意: CPU enqueueV3(mB0) → 立即去准备 mB1 的调度 周期性 query mB0 的 event(cudaEventQuery) mB0 完成 → 处理输出 token → 更新 KV Cache 状态 同时 mB1 可能已经在 GPU 上跑了一半 Stream: H2D copy → kernel_0 → kernel_1 → EventRecord → ... ↑ 插入一个 Event 标记 |
- H2D :Host to Device,即 CPU内存->GPU显存的数据拷贝
调度器在 CPU 上组装好这一批 request 的输入(token id 数组、序列长度等),这些数据在 CPU 内存里,GPU kernel 执行时需要从显存读取,所以要先拷过去。 - CUDA graph是什么?
正常情况下每次 enqueueV3,CPU 要逐个把几十个 kernel 的启动命令提交给 GPU driver,这个过程本身有 CPU overhead(每个 kernel launch 约几微秒,几十个加起来就是几百微秒)。
CUDA Graph 的思路是把这些 kernel 的启动序列录制成一张图,之后直接回放:
第一次执行(录制阶段):
CPU: launch kernel_0 → launch kernel_1 → ... → launch kernel_N
↓ 同时录制成 Graph
之后执行(回放阶段):
CPU: cudaGraphLaunch(graph) ← 一次调用替代N次 kernel launch
GPU: 自动按照录制的顺序执行所有 kernel
graph命中与未命中:
命中(hit):
本次 batch 的 shape 和上次完全相同
→ 直接 replay,CPU overhead ≈ 0
→ 延迟极低
未命中(miss):
batch size 变了,或 sequence length 变了
→ shape 变化导致 kernel 参数不同,旧 graph 无法复用
→ 回退到逐个 launch kernel
→ 或者重新 capture 一张新 graph(有开销)
这也是为什么 TRT-LLM 里有 "padding to fixed shape" 的选项------通过把输入 pad 到固定几种 shape,最大化 CUDA Graph 命中率,用显存换延迟。
5.3 GPU Kernel、Plugin 和 CUDA Stream 协同
CUDA Stream 是保序的异步队列,同一 stream 内的操作严格按顺序执行。在 enqueueV3 内部,所有操作( H2D 拷贝、各种 kernel 、 EventRecord 、 D2H 拷贝)都在同一个 stream 排队,顺序自动保证:
H2D: input_ids\] → \[QKV GEMM\] → \[RoPE Plugin\] → \[Paged Attention Plugin\] → \[FFN GEMM x2\] → \[RMSNorm\] → \[Sampling\] → \[EventRecord\] → \[D2H: tokens
多 micro-batch 时,可使用多个 stream 并行执行(不同 stream 间 GPU 可并行,只要显存够用):
Stream_0: mB0_kernels... → EventRecord_0
Stream_1: mB1_kernels... → EventRecord_1 ← 与stream_0部分重叠执行
Stream_2: mB2_kernels... → EventRecord_2
Driver 内部大致是这样的结构(非开源,但行为可观测):
CUstream_st (driver内部):
├── command_queue\[\] ← 环形缓冲区,存放待执行命令
├── dependency_list\[\] ← 与其他stream的事件依赖
├── current_position ← 当前执行到哪
└── device_id ← 属于哪个GPU
TRT-LLM 1.0 整体偏保守,大量用 streamSynchronize 阻塞等待
cpp
// executorImpl.cpp line 1775-1782
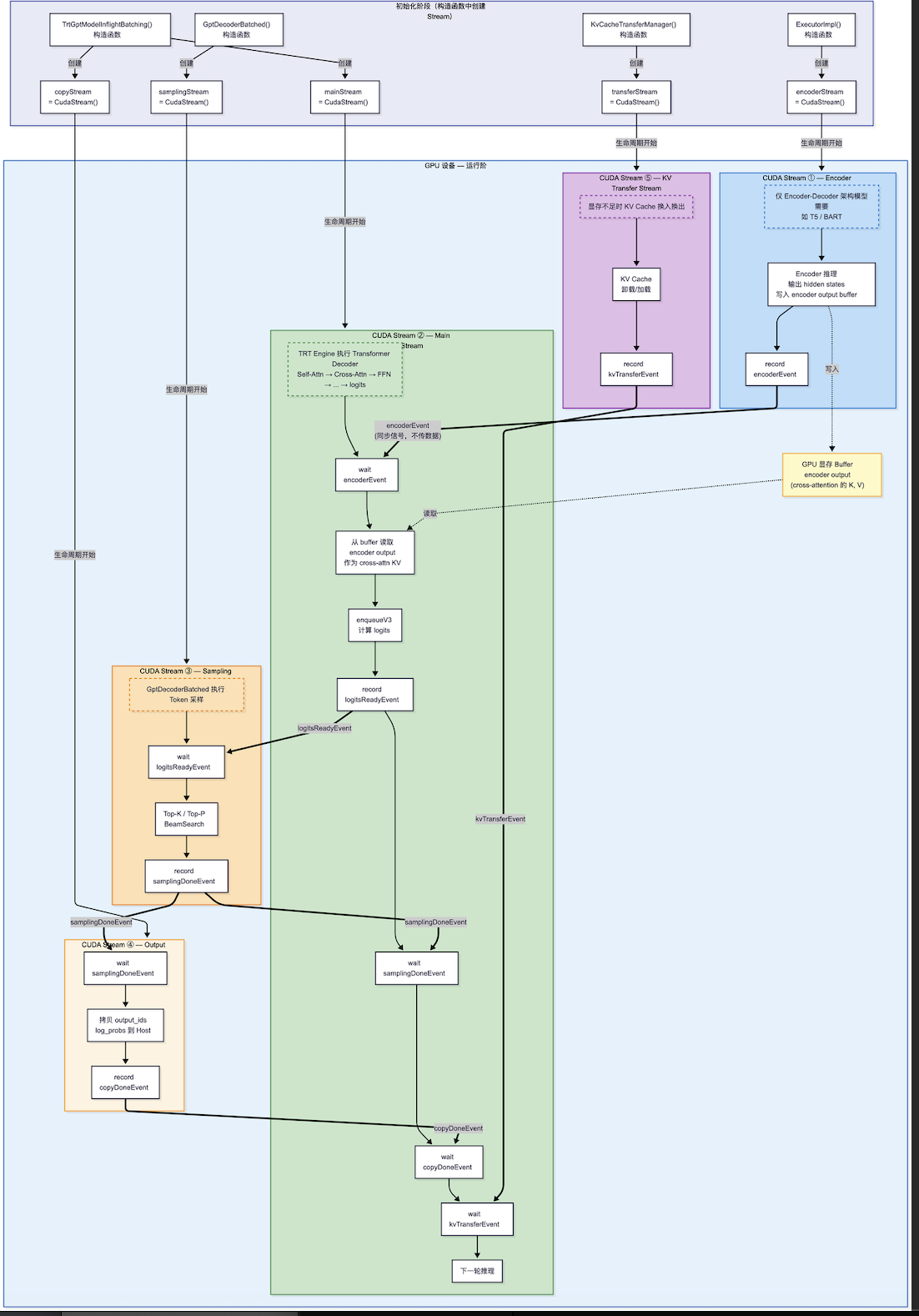
if (mEncoderModel)
{
mEncoderModel->forwardAsync(activeRequests);
auto const& encoderStream = *(mEncoderModel->getRuntimeStreamPtr());
auto const& decoderStream = *(mModel->getRuntimeStreamPtr());
runtime::CudaEvent encoderFinished; // ← 创建event
encoderStream.record(encoderFinished); // ← 在encoder stream上打标记
decoderStream.wait(encoderFinished); // ← decoder stream等encoder完成
}整理了一下TRT-LLM 1.0中使用了cuda stream event 进行同步的主要几个stream:
decoder-only:
encoder-decoder 架构:
5.4 CUDA Graph
-
正常情况下每次 enqueueV3 , CPU 需逐个提交几十个 kernel 的启动命令(每个约几微秒,合计数百微秒开销)。 CUDA Graph 的思路是把启动序列录制成图,之后直接回放:
|-----------|---------------------------------|----------------------------------------------|
| 状态 | 条件 | 处理方式 |
| 命中(hit) | 本次 batch 的 shape 与上次完全相同 | 直接 replay,CPU overhead ≈ 0,延迟极低 |
| 未命中(miss) | batch size 或 sequence length 变化 | 回退到逐个 launch kernel,或重新 capture 新 Graph(有开销) |
实践技巧: 「Padding to Fixed Shape」选项:通过将输入 pad 到固定的几种 shape,最大化 CUDA Graph 命中率,用显存换延迟。这是 TRT-LLM 中的一种性能调优手段。
// TRT 内部(闭源,但接口如此)
bool ExecutionContext::enqueueV3(cudaStream_t stream) {
// 遍历执行计划中的每个节点
for (auto& node : mExecutionPlan->nodes) {
if (node.type == GEMM) {
// cuBLAS 也接受 stream 参数,保证排在同一队列
cublasSetStream(mCublasHandle, stream);
cublasGemmEx(mCublasHandle, ...);
}
else if (node.type == PLUGIN) {
// 调用 Plugin 的 enqueue,把 stream 传进去
plugin->enqueue(inputDesc, outputDesc,
inputs, outputs, workspace, stream);
// Plugin 内部用这个 stream launch 自定义 kernel
}
}
}
所有操作用同一个 stream,顺序就自动保证了,因为 stream 是 FIFO 队列。
六. Flash Attention vs Paged Attention 分工 + 量化
6.1 两者分工
|-----------------|------------------------|-------------------------------|-----------------------------|
| 技术 | 解决的问题 | 核心手段 | 使用场景 |
| Flash Attention | 解决 Attention 计算本身的效率问题 | 减少 HBM 读写次数,分块计算,节省显存带宽 | 主要用于 Prefill 阶段(context 计算) |
| Paged Attention | 解决 KV Cache 存储管理的效率问题 | 将 KV Cache 分页,允许非连续存储,提升显存利用率 | 主要用于 Decode 阶段(生成阶段) |
核心要点
两者不互斥,TRT-LLM 实际是融合的:「带分页 KV Cache 的 Flash Attention kernel」。GPTAttentionPlugin 根据 input_seq_len 判断:> 1 时走 enqueueContext(Flash Attention),= 1 时走 enqueueGeneration(Paged Attention + MHA)。
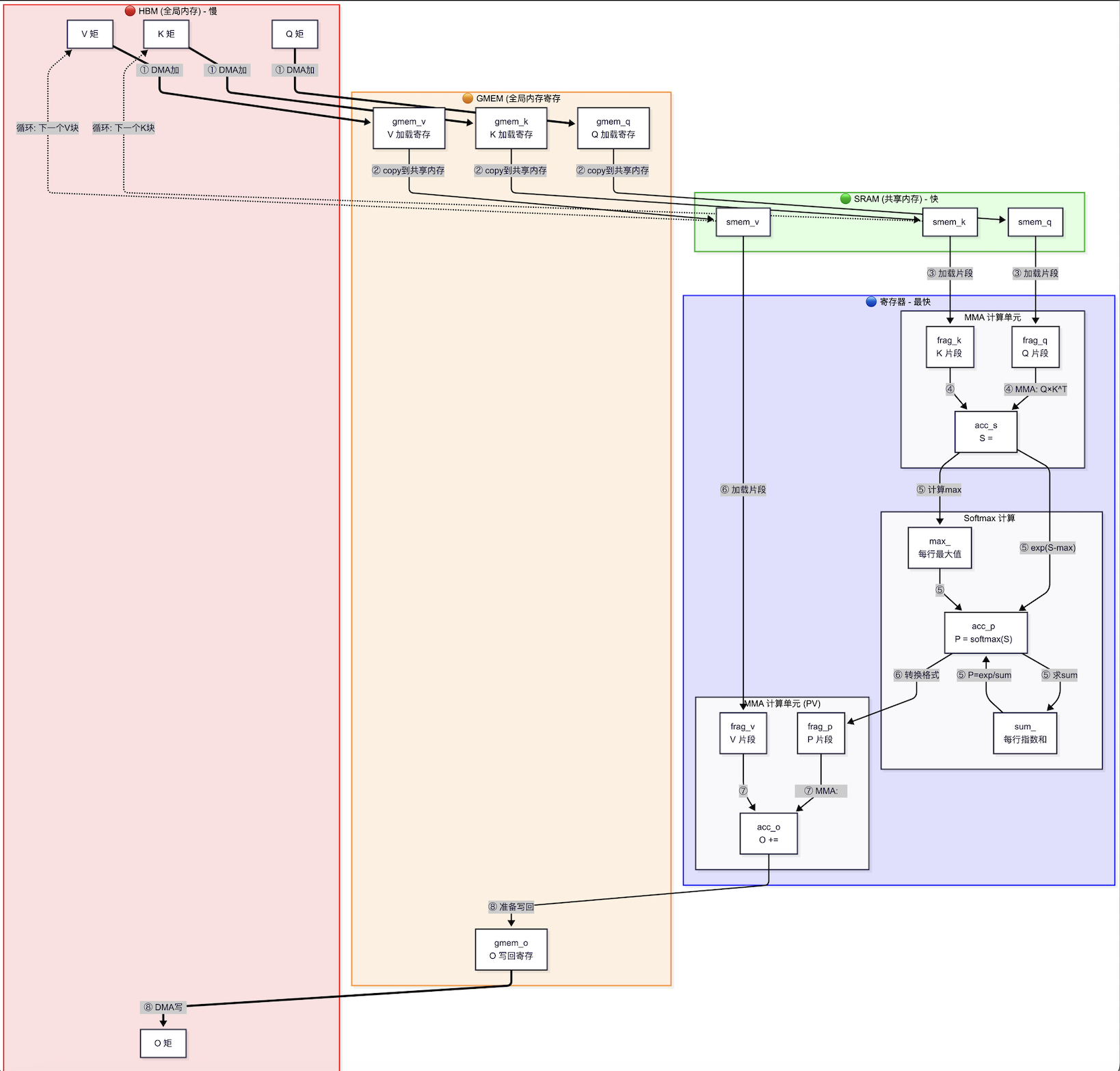
6.2 Flash Attention算法核心
- 外层循环遍历 Q 序列块,内层循环遍历 KV 序列块
- GEMM 1:计算当前 Q 块与 K 块的注意力分数(acc_p = Q × K^T,存在寄存器)
- 在线 Softmax:使用 Fragment_updater 维护 running max 和 running sum,增量更新,无需全部看完才计算
- GEMM 2:计算加权输出(local_acc_o = Softmax(P) × V,存在寄存器)
- 累加更新:acc_o_updater.update_o() 将 local_acc_o 按正确的缩放因子合并进全局 acc_o
内存层次:
- HBM(全局显存):存储完整的 Q、K、V 矩阵和最终输出 O
- SRAM(共享内存):分块缓存 smem_q、smem_k、smem_v,支持双缓冲(Double Buffering)
- 寄存器(Fragment):存储中间计算结果 acc_p、acc_o,速度最快,不访问 HBM
Fragment(寄存器片段)的含义补充:Fragment_accumulator 存储在 GPU 寄存器中,既不是 HBM 也不是 SRAM。每个线程负责输出矩阵的一小块(MMAS_M × VALID_MMAS_N 个 MMA 运算结果),这是 CUDA Warp-level MMA(矩阵乘加)指令的基本单元。Flash Attention 的性能突破正来自于始终将中间结果保留在寄存器中,最小化 HBM 访问次数。
Flash Attention计算图绘制如下:
-
mask用于控制注意力计算中哪些位置应该被"屏蔽", 推理过程中仅prefill用到;
-
fmha 是一个 C++ 命名空间(namespace),全称是 Flash Multi-Head Attention。
-
Fragment 的含义:就是指"寄存器片段",Fragment_accumulator 存在GPU寄存器中,既不是HBM 也不是 SRAM!
fmha::Fragment_accumulator acc_o本质上就是一个二维数组,存储中间计算结果, 展开后大概是 float acc_o24; // 举例:2行4列的浮点数数组
为什么是二维数组acc_o[MMAS_M][VALID_MMAS_N]? -
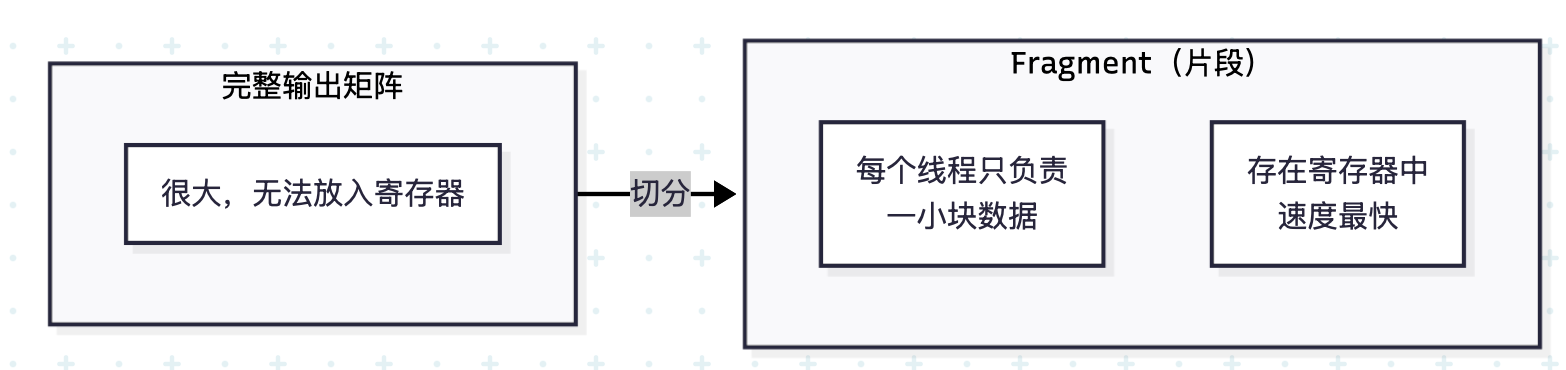
一个线程负责输出矩阵的多个小块 MMAS_M = 行方向的块数(比如 2),VALID_MMAS_N = 列方向的块数(比如 4),每个 Fragment_accumulator 存一个小块的数据
acc_o00 acc_o01 acc_o02 acc_o03
acc_o10 acc_o11 acc_o12 acc_o13
-
fmha::Fragment_updater<Traits_o, Cta_tile_o> acc_o_updater;
维护 Flash Attention 在线计算需要的 max 和 sum 状态
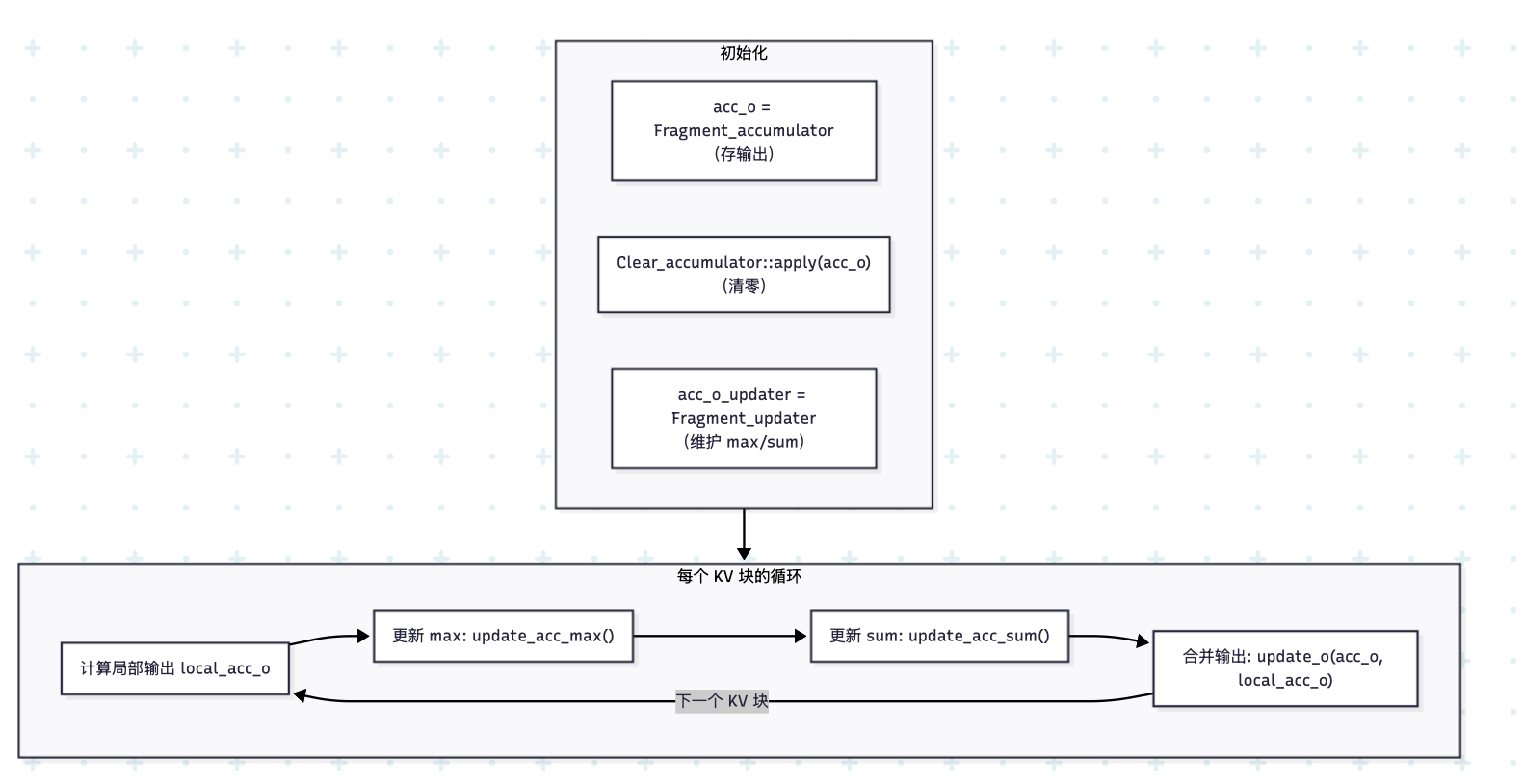
各个变量存什么?
| 变量 | 存储内容 | 位置 |
|---|---|---|
acc_o |
输出 O 的累加结果 | 寄存器 |
acc_p |
QK 乘积(softmax 前/后) | 寄存器 |
smem_q/k/v |
Q/K/V 的分块数据 | SRAM |
params.o_ptr |
最终输出 | HBM |
| 组件 | 作用 | 代码 |
|---|---|---|
| GEMM 1 | 计算注意力分数 | fmha::gemm(acc_p, frag_q, frag_k) |
| 在线 Max | 增量计算最大值 | softmax.reduce<Max_>() + update_acc_max() |
| 在线 Sum | 增量计算求和 | softmax.reduce<Sum_>() + update_acc_sum() |
| GEMM 2 | 计算加权输出 | fmha::gemm(local_acc_o, frag_p, frag_v) |
| 累加更新 | Flash Attention 核心 | acc_o_updater.update_o(acc_o, local_acc_o) |
内存层次结构
| 层次 | 用途 | 变量示例 |
|---|---|---|
| 全局内存 (Gmem) | 存储完整 Q,K,V,O | gmem_q, gmem_k, gmem_v, gmem_o |
| 共享内存 (Smem) | 中间缓存,支持双缓冲 | smem_q, smem_k, smem_v, smem_o |
| 寄存器 (Fragment) | 当前计算数据 | frag_q, frag_k, frag_v, frag_p |
两个GEMM操作
- GEMM 1:
P = Q × K^T(计算注意力分数) - GEMM 2:
O = Softmax(P) × V(计算加权输出)

6.3 Paged Attention Kernel 内部
Decode 阶段每步只有 1 个 query token (自回归),但需要 attend 到所有历史 KV 。 Paged Attention 通过非连续内存访问实现:
- 每个 thread block 处理一个 (batch, head) 对
- 加载当前 step 的 Query(只有 1 个 token)
- 循环遍历历史 KV Cache 的各个 Block(通过 block_pointers 间接寻址,这是 Paged 的核心)
- 计算 Q·K^T,得到注意力分数
- Softmax + 加权求和 V,得到输出
6.4 量化
量化不是在推理流程里做的,而是在推理之前的离线编译阶段就已经完成了。
离线阶段(一次性) 在线推理阶段(每次请求)
─────────── ────────────────── ─────────── ──────────────
原始权重 (FP32) 用户请求
↓ ↓
量化 ← 就在这里! Executor / Scheduler
↓ ↓
INT4/INT8 权重 + scale KVCacheManager 分配 block
↓ ↓
trtllm-build 编译 prepareBuffers
↓ ↓
.engine 文件 enqueueV3(stream)
↓
GPU Kernel 执行
(权重已经是量化后的)
量化具体发生在两个地方:
|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 1. convert_checkpoint.py(权重量化) # 这一步把 FP16 权重转成 INT4/INT8 # 同时计算并保存每层的 scale 因子 python convert_checkpoint.py \ --dtype float16 \ --use_weight_only \ --weight_only_precision int4 # ← 量化在这里发生 |
| 2. trtllm-build(编译进 engine) trtllm-build \ --gemm_plugin float16 \ --use_weight_only # ← 告诉 TRT 插入反量化 kernel 这一步把量化权重和对应的反量化逻辑融合编译进 .engine,生成专门的 W4A16 GEMM kernel。 |
推理时GPU里实际发生什么:
|------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 显存里存的是 INT4 权重(体积是FP16的1/4) ↓ 激活值(FP16)从寄存器读入 ↓ INT4 权重解包 → 乘以 scale → 反量化成 FP16(在寄存器里完成) ↓ 做点积累加 ↓ 输出 FP16 结果 关键点:权重在显存里始终是 INT4,反量化发生在寄存器里,不写回显存,这就是为什么既省显存又快。 |
量化模式一览:
|--------------------|----------------------|-----------------------------------|----------------|
| 量化模式 | 描述 | 核心机制 | 特点 |
| W4A16 | 权重 INT4,激活 FP16 | 显存节省 ~75%,计算使用 INT4 解包 + FP16 乘加 | 推理速度快,轻微精度损失 |
| W8A16 | 权重 INT8,激活 FP16 | 显存节省 ~50% | 比 W4A16 精度更高 |
| W8A8 (SmoothQuant) | 权重 INT8,激活 INT8 | INT8 矩阵乘法,需要激活值统计 | H100 以下 GPU 常用 |
| FP8 | 权重 FP8,激活 FP8 | H100 专属,硬件原生支持 | 精度与速度最优平衡 |
| INT8 KV Cache | KV Cache 压缩为 INT8 存储 | 大幅减少 KV Cache 显存占用 | 与权重量化正交,可叠加使用 |
量化补充说明:
-
量化 scale(缩放因子):INT4/INT8 权重在计算时需要乘以对应的 scale 才能还原近似的 FP16 值,scale 通常按 group 存储(per-group quantization)。
-
SmoothQuant 的思想:激活值的量化比权重更难,因为激活值的分布在 token 间变化大。SmoothQuant 通过数学变换将量化难度从激活转移到权重,使两者都更容易量化。
-
KV Cache 量化独立于权重量化:INT8 KV Cache 只压缩存储格式,读取时自动反量化,与 W4A16 等权重量化正交叠加。
tensorrt_llm/
├── quantization/ ← Python侧量化配置
│ ├── _utils.py
│ ├── mode.py ← 定义量化模式枚举
│ └── quantize.py ← 量化入口
│
└── cpp/tensorrt_llm/
├── kernels/
│ ├── weightOnlyBatchedGemv/ ← W4A16/W8A16 kernel
│ │ └── kernel.cu
│ ├── cutlass_kernels/ ← INT8/FP8 GEMM
│ │ ├── int8_gemm/
│ │ └── fpA_intB_gemm/ ← FP16激活 × INT4权重
│ └── quantization.cu ← 量化/反量化辅助kernel
│
└── plugins/
├── weightOnlyQuantMatmulPlugin/ ← W4A16插件
├── smoothQuantGemmPlugin/ ← SmoothQuant插件
└── fp8RowwiseGemmPlugin/ ← FP8插件
量化模式的定义:
quantization/mode.py
class QuantMode:
权重量化
W4A16 = "w4a16" # 权重INT4,激活FP16
W8A16 = "w8a16" # 权重INT8,激活FP16
激活+权重同时量化
W8A8 = "w8a8" # SmoothQuant: 权重INT8,激活INT8
FP8 = "fp8" # 权重FP8,激活FP8(H100专属)
KV Cache量化
INT8_KV_CACHE = "int8_kv_cache" # KV Cache压缩存储
W4A16 的核心 kernel
// weightOnlyBatchedGemv/kernel.cu (简化)
// 权重是 INT4 打包存储,激活是 FP16,输出是 FP16
template <int BITS> // BITS=4 for W4A16
global void weight_only_batched_gemv_kernel(
const half* activations, // FP16 激活
const uint8_t* weights, // INT4 权重(两个INT4打包进一个uint8)
const half* scales, // 反量化 scale(per-group)
half* output,
int m, int n, int k)
{
// 每个线程处理一列权重
// 解包 INT4 → 反量化为 FP16 → 做点积
uint8_t packed = weightsweight_idx;
// 解包两个INT4
int4_t w0 = (packed & 0x0F); // 低4位
int4_t w1 = (packed >> 4) & 0x0F; // 高4位
// 反量化:INT4 → FP16
half w0_fp16 = __int2half_rn(w0 - 8) * scalesgroup_idx;
half w1_fp16 = __int2half_rn(w1 - 8) * scalesgroup_idx;
// 与激活值做乘加
acc += __half2float(activationsk0) * __half2float(w0_fp16);
acc += __half2float(activationsk1) * __half2float(w1_fp16);
outputout_idx = __float2half(acc);
}
INT8 KV cache量化
// gptAttentionCommon.cpp 里的 KV Cache 量化路径
if (mKVCacheQuantMode.hasInt8KvCache()) {
// 存入KV Cache前量化
// Q: float → int8
invokeQuantizeKVCache(
reinterpret_cast<int8_t*>(kv_cache_buffer),
kv_ptr, // FP16 原始值
kv_scale_orig_quant, // scale
seq_len, num_heads, head_dim,
stream
);
}
// 读取KV Cache时反量化
if (mKVCacheQuantMode.hasInt8KvCache()) {
mmha_params.kv_scale_quant_orig = kv_scale_quant_orig;
// kernel内部自动处理 int8 → fp16 的反量化
}
七、整体架构关系总结
组件调用链路
用户请求
└─► Executor::enqueueRequest()
└─► BatchManager(内部)
└─► CapacityScheduler(KV Cache 维度筛选)
└─► MicroBatchScheduler(batch 维度分组)
└─► TrtGptModelInflightBatching::forwardAsync()
├─► KVCacheManager(分配 Block Table)
├─► RuntimeBuffers(准备输入 Tensor)
├─► TllmRuntime::executeContext()
│ └─► IExecutionContext::enqueueV3(stream)
│ └─► GPU Kernels(异步执行)
└─► GptDecoderBatched::forwardAsync()
└─► Sampling Kernel(top-k/top-p)
└─► Next Token → 通知 KVCacheManager
关键性能优化手段汇总
|---------------------------|-----------------------------------------|--------------------------|
| 优化手段 | 核心思路 | 收益 |
| In-flight Batching(连续批处理) | prefill 和 decode 请求混在同一 batch 内执行 | GPU 利用率提升,无需等待整批完成 |
| Paged KV Cache | KV Cache 分页管理,非连续物理存储 | 显存碎片减少,支持 Prefix Caching |
| CUDA Graph | 录制 kernel 启动序列,replay 时一次提交 | 减少 CPU-GPU 通信开销 |
| CPU/GPU Overlap | GPU 计算时 CPU 并行做下一轮调度 | 隐藏调度延迟 |
| Chunked Context | 长 prefill 分块与 decode 交织执行 | 降低 TTFT,避免 decode 饿死 |
| Flash Attention | 分块在线 Softmax,中间结果留在寄存器 | 大幅减少 HBM 读写次数 |
| 算子融合(Kernel Fusion) | Softmax + Top-K + Sampling 合并为一个 kernel | 减少显存带宽浪费 |
| 量化(W4A16/FP8等) | 降低权重和激活的数值精度 | 显存节省,计算加速 |
| Prefix Caching | 相同前缀的请求共用 KV Cache Block | 节省显存,减少重复计算 |