文章目录
- [1. 为什么需要大模型自评判?](#1. 为什么需要大模型自评判?)
- [2. 大模型自评判的核心原理](#2. 大模型自评判的核心原理)
-
- [2.1 为什么可行?](#2.1 为什么可行?)
- [3. 两大主流评测模式](#3. 两大主流评测模式)
-
- [3.1 单点打分(Point-wise Scoring)](#3.1 单点打分(Point-wise Scoring))
- [3.2 成对对比(Pairwise Comparison)](#3.2 成对对比(Pairwise Comparison))
- [3.3 覆盖的评估维度](#3.3 覆盖的评估维度)
- [4. 评判模型选型建议](#4. 评判模型选型建议)
- [5. 递归顾问:代码落地实现](#5. 递归顾问:代码落地实现)
-
- [5.1 递归顾问的抽象模型](#5.1 递归顾问的抽象模型)
- [5.2 SelfRefineEvaluationAdvisor 完整实现](#5.2 SelfRefineEvaluationAdvisor 完整实现)
- [5.3 核心设计要点](#5.3 核心设计要点)
- [6. 完整 Spring Boot 集成示例](#6. 完整 Spring Boot 集成示例)
-
- [6.1 配置要点](#6.1 配置要点)
- [6.2 运行输出样例](#6.2 运行输出样例)
- [7. 落地最佳实践](#7. 落地最佳实践)
-
- [7.1 五大关键要点](#7.1 五大关键要点)
- [7.2 递归顾问的限制与注意事项](#7.2 递归顾问的限制与注意事项)
- 参考资料
1. 为什么需要大模型自评判?
评估大语言模型生成内容的质量是一大核心难题------尤其在应用投入生产后,评估工作的重要性愈发凸显。
传统自动化指标 (ROUGE、BLEU)基于词汇重叠度计算分数,无法捕捉现代大模型输出中富含的细微语义和上下文关联。人工评估虽是"黄金标准",但成本高昂、速度缓慢,无法支撑大规模批量评测。
大模型自评判(LLM-as-a-Judge) 提供了一条高效路径:直接利用大模型自身完成 AI 生成内容的质量打分。相关研究表明,成熟的评判专用模型与人工判断的吻合度最高可达 85%,甚至高于人与人之间评判的共识率(81%)。
Spring AI 框架提供的递归顾问组件(Recursive Advisors) ,为落地大模型自评判模式提供了简洁优雅的开发框架,可搭建带自动化质量管控、具备自我迭代优化能力的 AI 系统。
完整可运行示例代码位于
evaluation-recursive-advisor-demo工程。
2. 大模型自评判的核心原理
大模型自评判本质上是一种评测手段:由一个大模型去打分、判定其他模型(或自身)生成内容的优劣。它不再单纯依赖人工标注员或传统自动化指标,而是指定一个评判大模型,依据预设标准对回复进行打分、分类或优劣对比。
2.1 为什么可行?
评测任务本身远比内容生成简单。
内容生成:兼顾多重约束、从零创作原创文本(难)
评测打分:校验已有文本的各项指标(易)
批评容易创作难,发现问题远比规避问题简单。让大模型充当评判者,只需它完成轻量化、目标明确的任务,不需要从零构建输出。
3. 两大主流评测模式
3.1 单点打分(Point-wise Scoring)
评判模型逐条评估单条回复并给出评分与改进意见,系统依据反馈自动优化提示词,实现自我修正。
输入:问题 + 回答
输出:{ rating: 3, evaluation: "大体可用但...", feedback: "建议补充..." }3.2 成对对比(Pairwise Comparison)
评判模型从两条候选回复里选出更优质的一条,广泛用于 A/B 测试场景。
输入:问题 + 回答A + 回答B
输出:A 优于 B / B 优于 A / 两者相当3.3 覆盖的评估维度
评判大模型可持续覆盖以下质量维度:内容相关性、事实准确度、与参考资料一致性、指令遵从度、整体逻辑通顺度与表达清晰度,适用场景涵盖医疗、金融、RAG、对话系统等。
4. 评判模型选型建议
GPT-4、Claude 这类通用大模型可以充当基础评判工具,但专门针对评测场景训练的评判专用模型,评测效果稳定优于通用大模型。
Judge Arena 排行榜 持续收录、对比各类模型在评测任务上的表现得分,选型时建议参考。
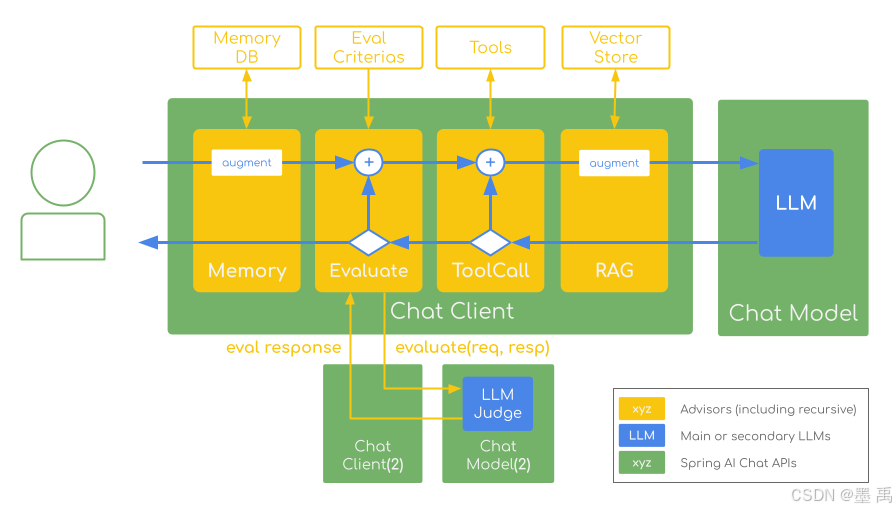
5. 递归顾问:代码落地实现
Spring AI 的 ChatClient 提供流畅式 API,非常适合搭建大模型自评判逻辑。框架内置的 顾问(Advisors) 体系能够模块化、可复用地拦截、修改、增强 AI 交互流程。递归顾问在此基础上拓展出循环执行能力,完美适配带自我修正的评测工作流。
5.1 递归顾问的抽象模型
java
public class MyRecursiveAdvisor implements CallAdvisor {
@Override
public ChatClientResponse adviseCall(ChatClientRequest request, CallAdvisorChain chain) {
// 首次调用链路执行生成
ChatClientResponse response = chain.nextCall(request);
// 评测不达标则循环重试优化
while (!evaluationPasses(response)) {
// 根据评测反馈修正请求入参
ChatClientRequest modifiedRequest = addEvaluationFeedback(request, response);
// 复制当前顾问链路,发起递归重试调用
response = chain.copy(this).nextCall(modifiedRequest);
}
return response;
}
}核心机制:chain.copy(this).nextCall(modifiedRequest) 复制一份独立的子链路执行递归调用,保证多轮评测中顾问执行顺序不乱。
5.2 SelfRefineEvaluationAdvisor 完整实现
下面实现 SelfRefineEvaluationAdvisor(自优化评测顾问),完整落地大模型自评判流程:
生成回复 → 质量评测打分 → 不达标则携带反馈重试 → 循环迭代直至分数达标或触达上限该组件采用单点打分 模式,评判模型使用 1~4 分制逐条打分,搭配自我迭代策略:评测不合格时,把详细改进意见注入下一轮请求,形成闭环迭代优化。
java
public final class SelfRefineEvaluationAdvisor implements CallAdvisor {
// 默认评测提示词模板
private static final PromptTemplate DEFAULT_EVALUATION_PROMPT_TEMPLATE = new PromptTemplate("""
你将收到一组用户问题与助手回答。
你的任务是给出总分,衡量助手回答匹配用户诉求的完善程度。
评分区间1~4分:1分代表完全无帮助,4分代表完整妥善解答用户问题。
评分分级标准:
1分:回答极差,和问题完全无关/内容残缺不全
2分:基本无帮助,遗漏问题核心要点
3分:大体可用,能支撑需求但仍有优化空间
4分:回答优秀,贴合问题、表述直接、内容详实,完整覆盖用户所有诉求
输出严格遵循JSON格式:
{
"rating": 数字分值,
"evaluation": "打分理由,说明优劣",
"feedback": "针对回答具体、可落地的优化建议"
}
必须完整输出打分理由与总分。
以下是问答内容:
问题:{question}
回答:{answer}
输出评测结果:
""");
// 结构化评测结果实体
@JsonClassDescription("评测返回实体,存储打分、理由、优化建议")
public record EvaluationResponse(int rating, String evaluation, String feedback) {}
@Override
public ChatClientResponse adviseCall(
ChatClientRequest chatClientRequest, CallAdvisorChain callAdvisorChain) {
var request = chatClientRequest;
ChatClientResponse response;
for (int attempt = 1; attempt <= maxRepeatAttempts + 1; attempt++) {
response = callAdvisorChain.copy(this).nextCall(request);
EvaluationResponse evaluation = this.evaluate(chatClientRequest, response);
if (evaluation.rating() >= this.successRating) {
logger.info("第{}轮评测通过,评测详情:{}", attempt, evaluation);
return response;
}
if (attempt > maxRepeatAttempts) {
logger.warn("已达最大重试次数{},评测未达标,返回末次结果;优化建议:{}",
maxRepeatAttempts, evaluation.feedback());
return response;
}
logger.warn("第{}轮评测未通过,评判理由:{},优化建议:{}", attempt,
evaluation.evaluation(), evaluation.feedback());
request = this.addEvaluationFeedback(chatClientRequest, evaluation);
}
throw new IllegalStateException("循环流程异常退出");
}
/**
* 调用评判大模型执行打分评测
*/
private EvaluationResponse evaluate(
ChatClientRequest request, ChatClientResponse response) {
var evaluationPrompt = this.evaluationPromptTemplate.render(
Map.of("question", this.getPromptQuestion(request),
"answer", this.getAssistantAnswer(response)));
return chatClient.prompt(evaluationPrompt).call().entity(EvaluationResponse.class);
}
/**
* 把评测优化建议追加到原始请求,生成重试用新请求体
*/
private ChatClientRequest addEvaluationFeedback(
ChatClientRequest originalRequest, EvaluationResponse evaluationResponse) {
Prompt augmentedPrompt = originalRequest.prompt()
.augmentUserMessage(userMessage -> userMessage.mutate().text(String.format("""
%s
上一轮回答评测未通过,优化建议:%s
请重新作答,直至评测达标!
""", userMessage.getText(), evaluationResponse.feedback())).build());
return originalRequest.mutate().prompt(augmentedPrompt).build();
}
}5.3 核心设计要点
| 设计要点 | 实现方式 | 解决的问题 |
|---|---|---|
| 递归链路隔离 | callAdvisorChain.copy(this).nextCall(request) 复制独立子链路 |
多轮评测中顾问执行顺序不乱 |
| 结构化评测输出 | Spring AI 自动将 JSON 解析为 EvaluationResponse 记录类 |
统一存储分值、评判理由、优化建议 |
| 生成/评测模型隔离 | 独立 ChatClient 对接专用评判模型 |
消除模型"自恋偏袒"偏差 |
| 反馈驱动迭代 | 低分回复附带改进意见注入下一轮请求 | 实现失败自学习 |
| 可配置熔断 | 自定义最大重试次数 | 触达上限后优雅降级,不无限循环 |
6. 完整 Spring Boot 集成示例
java
@SpringBootApplication
public class EvaluationAdvisorDemoApplication {
@Bean
CommandLineRunner commandLineRunner(
AnthropicChatModel anthropicChatModel, OllamaChatModel ollamaChatModel) {
return args -> {
// Claude 负责生成,Ollama 本地模型负责评判
ChatClient chatClient = ChatClient.builder(anthropicChatModel)
.defaultTools(new MyTools())
.defaultAdvisors(
// 优先级 0:自优化评测顾问
SelfRefineEvaluationAdvisor.builder()
.chatClientBuilder(ChatClient.builder(ollamaChatModel))
.maxRepeatAttempts(15) // 最大重试 15 次
.successRating(4) // 满分 4 分才算达标
.order(0)
.build(),
// 优先级 2:日志打印顾问
new MyLoggingAdvisor(2)
)
.build();
var answer = chatClient.prompt("巴黎当前天气如何?").call().content();
System.out.println(answer);
};
}
// 天气查询工具(内置随机异常温度,触发评测重试)
static class MyTools {
final int[] temperatures = {-125, 15, -255};
private final Random random = new Random();
@Tool(description = "查询指定地点实时天气")
public String weather(String location) {
int temperature = temperatures[random.nextInt(temperatures.length)];
System.out.println(">>> 工具返回温度:" + temperature);
return location + "当前晴天,气温" + temperature + "摄氏度";
}
}
}6.1 配置要点
| 要点 | 说明 |
|---|---|
| 分工隔离 | Anthropic Claude 承载内容生成,Ollama 本地大模型专职评测,规避同源模型偏见 |
| 达标门槛严苛 | 必须拿到满分 4 分,最多允许 15 轮重试 |
| 工具模拟异常 | 天气接口 2/3 概率返回物理上不可能的极端温度,强制触发评测校验与重试 |
| 执行顺序 | 0 号评测顾问先校验输出、不合格自动重试;2 号日志顾问最后打印完整交互链路 |
6.2 运行输出样例
REQUEST: [{"role":"user","content":"巴黎当前天气如何?"}]
>>> 工具返回温度:-255
第1轮评测未通过,评判理由:温度数值不符合物理常识,存在数据错误,
优化建议:-255摄氏度属于不可能出现的气温,修正为合理常温数值
>>> 工具返回温度:15
第2轮评测通过,评判理由:回答气温真实合理,内容完整准确
RESPONSE: 巴黎当前晴天,气温15摄氏度可以看到:第一轮生成因工具返回了 -255°C 的离谱温度,被评判模型识别为不合格,带着反馈自动重试;第二轮工具返回 15°C 的合理值,评测通过,直接返回结果。
7. 落地最佳实践
7.1 五大关键要点
- 优先选用专业评判模型 ,评测精度更高(参考 Judge Arena 排行榜)
- 生成、评测两套模型物理分离,最大程度降低偏袒偏差
- 模型推理温度设为 0,保证打分、生成结果稳定可复现
- 评测提示词标准化 :固定整数分值区间、搭配
Few-Shot样例引导输出格式 - 高风险业务保留人工终审:金融、医疗等场景不可完全依赖 AI 评判
7.2 递归顾问的限制与注意事项
| 限制 | 说明 |
|---|---|
| 仅支持非流式 | 递归顾问当前不兼容流式输出(stream()) |
| 优先级管控 | 必须精细管控多个顾问的执行优先级顺序 |
| 成本考量 | 多轮调用会增加大模型接口计费成本 |
| 状态隔离 | 若内部顾问持有外部状态变量,迭代循环中极易出现状态错乱 |
| 强制熔断 | 必须配置重试上限与终止条件,杜绝死循环 |
递归顾问是
Spring AI 1.1.0-M4及以上版本新增的实验性功能。
参考资料
Spring AI 官方:
学术研究:
- Judge Arena 排行榜
- 《Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena》------该范式奠基论文
- 《The Judge's Verdict: A Comprehensive Analysis of LLM Judging Capabilities with Human Consensus》
- 《LLMs as Judges: A Comprehensive Survey on LLM-based Evaluation Methods》
- 《From Generation to Judgment: Opportunities and Challenges of LLM-as-a-Judge (2024)》