文章目录
- [1. 实战概述](#1. 实战概述)
- [2. 实战步骤](#2. 实战步骤)
-
- [2.1 查看Excel文件](#2.1 查看Excel文件)
- [2.2 显示Excel文件包含的工作表名](#2.2 显示Excel文件包含的工作表名)
- [2.3 读取指定工作表](#2.3 读取指定工作表)
- [2.4 读取全部工作表](#2.4 读取全部工作表)
- [3. 实战小结](#3. 实战小结)
1. 实战概述
- 本次实战通过 Python 的 pandas 库读取本地 Excel 文件《智慧树AI智慧课程建设标准.xlsx》,依次查看文件结构、列出全部7个工作表名称,并分别读取单表与多表数据,初步探索各表内容,为后续课程资源数据的清洗、整合与分析奠定基础。
2. 实战步骤
2.1 查看Excel文件
- 文件:
E:\excelfiles\智慧树AI智慧课程建设标准.xlsx
- 查看文件内容
2.2 显示Excel文件包含的工作表名
-
执行代码
pythonimport pandas as pd path = 'E:/excelfiles/智慧树AI智慧课程建设标准.xlsx' excel_file = pd.ExcelFile(path) print("工作表:", excel_file.sheet_names)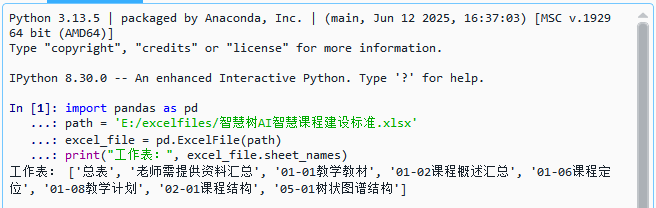
-
结果说明 :该代码成功加载本地 Excel 文件,通过
pd.ExcelFile获取文件信息并打印所有工作表名称。结果显示包含"总表"、"老师需提供资料汇总"等共7个工作表,说明数据结构清晰,适合后续多表读取与分析处理。
2.3 读取指定工作表
-
执行代码
pythondataframe1 = pd.read_excel(path, sheet_name=1, header=0) dataframe1.head(10)
-
结果说明:该代码读取了Excel文件中索引为1的工作表,以第一行为列名,显示前10行数据。结果包含"资源类别"、"资源内容"等字段,部分列为"Unnamed",表明存在未命名列。数据主要为课程资源类型及是否需提供的信息,格式清晰,适合后续清洗与分析。
2.4 读取全部工作表
-
执行代码
pythondataframes = pd.read_excel(path, sheet_name=[0,1,2,3,4,5,6], header=0) print(f'工作表:{dataframes.keys()}') for key in dataframes.keys(): print(f"\n--- 工作表 {key} ---") print(dataframes[key].head(3))
-
结果说明:该代码成功读取Excel文件中7个工作表(索引0-6),并逐个输出前3行数据。各表内容涵盖课程概述、资源类型、教材信息、教学模块等,结构清晰,部分列名为"Unnamed",表明存在未命名列,适合后续数据清洗与整合分析。
3. 实战小结
- 本次实战成功实现了对多工作表 Excel 文件的高效读取与初步探查。首先利用
pd.ExcelFile快速获取所有工作表名称,确认文件包含"总表""老师需提供资料汇总"等7个逻辑清晰的子表;随后分别演示了读取单个工作表(如索引1的资源清单)和批量读取全部工作表的方法。通过.head()查看数据样例,发现部分列存在"Unnamed"命名问题,提示后续需进行列名清洗与标准化。整体流程展示了 pandas 在教育数据处理中的实用价值,为构建结构化课程知识库提供了可靠的数据导入方案,也为自动化分析多表关联信息打下坚实基础。