TL;DR
- 场景:用 Hive 构建离线数仓,处理订单主表拉链、订单明细聚合与 DWS 宽表生成。
- 结论:订单主表适合按创建日分区 + 拉链管理,订单商品表走常规事实处理,DWS 再做轻聚合与维度退化。
- 产出:给出 DWD/DWS 表设计、分层职责、装载脚本思路,以及一份错误速查卡。

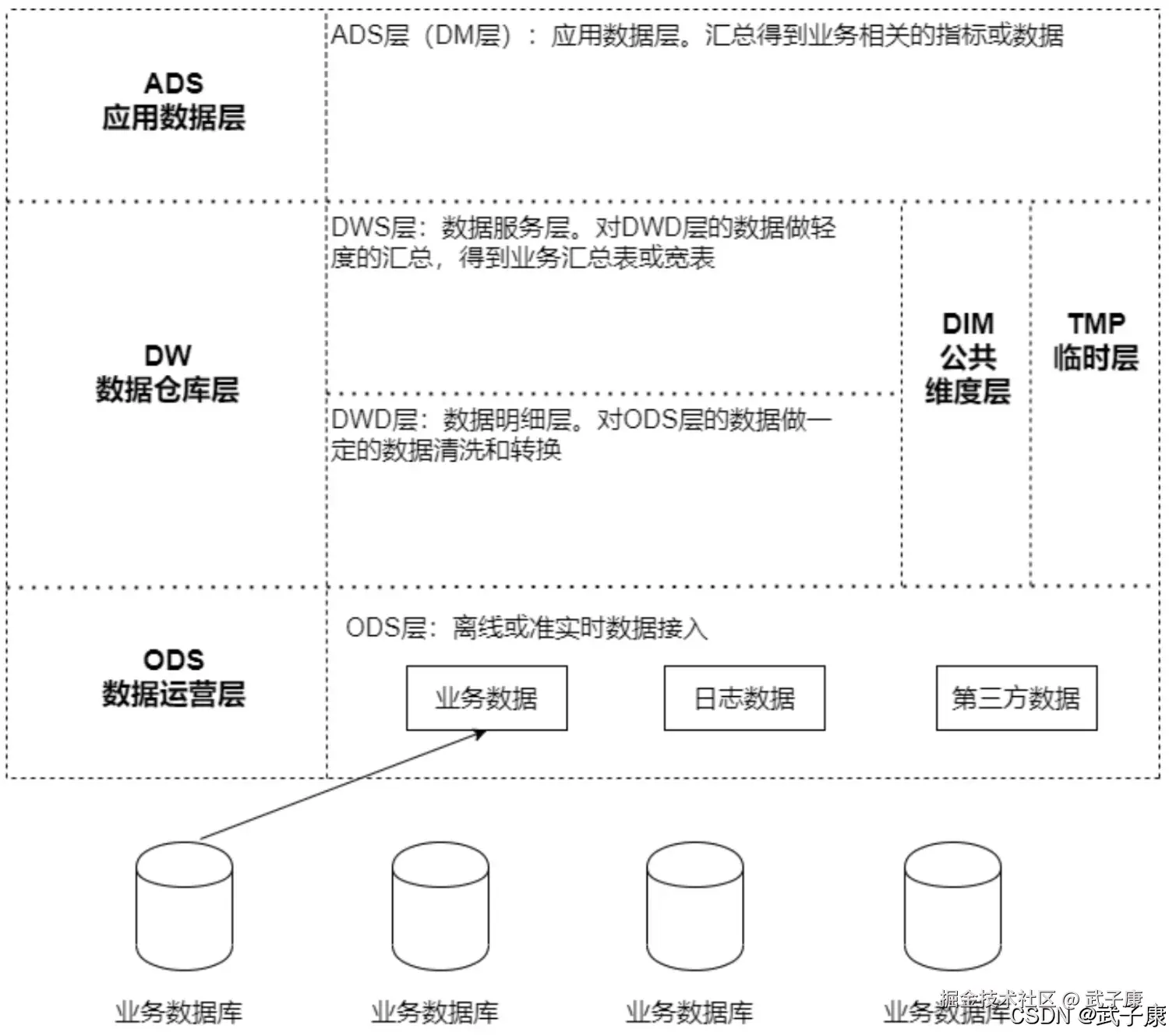
基本介绍
要处理的表有两张:订单表、订单产品表:
- 订单表是周期性事实表,为保留订单状态,可以使用拉链表进行处理
- 订单产品表普通的事实表,用常规的方法进行处理(如果有数据清洗、数据转换的需求 ODS=>DWD。如果没有数据清洗、数据转换的需求,保留在ODS,不做任何变化)
订单状态:
- -3 用户拒收
- -2 未付款订单
- -1 用户取消
- 0 等待发货
- 1 配送中
- 2 用户确认收货
订单从创建到最终完成,是有时间限制的,业务上也不允许订单一个月之后,订单状态仍然在发生变化。
DWD 层的定位
DWD 层可以理解为数仓的"细化层"或"明细层",其核心作用是将原始数据从 ODS 层向更高质量、更具业务价值的方向转化。具体定位如下:
- 处于 数仓分层体系 的中间部分。
- 对 ODS 层 的数据进行业务逻辑处理、数据清洗、去重、规范化等操作,形成细化的业务事实表。
- 为 DWS 层 和其他上层应用提供标准化的数据源。
DWD 层的特点
- 细粒度:数据保留了明细级别信息,通常是事实表,每条记录与业务事件或过程直接对应。
- 业务逻辑清晰:通过一定的逻辑处理,明确数据的业务含义,数据更加贴近真实业务。
- 清洗规范:对数据进行清洗、校验和补充,确保数据质量(如去重、格式化)。
- 冗余优化:降低原始数据中的冗余度,只保留对业务分析有价值的信息。
- 可溯源性:保留明细数据,以支持对问题的深入追溯分析。
DWD 层的常见处理逻辑
在构建 DWD 层时,通常会执行以下关键步骤:
数据清洗
- 去重:去除重复记录,确保数据唯一性。
- 异常处理:处理缺失值、异常值等数据质量问题。
- 格式标准化:统一时间格式、数值单位等。
数据补充
- 添加维度信息:通过与维度表关联补充更多业务相关字段。
- 填充缺失值:使用默认值或业务规则填充数据。
业务逻辑处理
- 数据分层:根据业务模块分组存储(如用户行为、商品信息、订单数据等)。
- 数据解耦:将复杂的业务逻辑分解成单独的表。
历史快照
- 有时需要保留数据的历史版本(比如每日商品价格快照)。
WD 层的作用
DWD 层的建立有助于提高整个数仓的规范性和可用性:
- 保证数据质量:通过清洗和转换,过滤掉 ODS 中的无效数据,确保上游数据的准确性。
- 便于分析建模:提供标准化、明细化的数据供 DWS 层建模和分析使用。
- 支持灵活查询:DWD 层数据粒度细,方便灵活查询和支持多样化的业务需求。
- 缩短分析链路:减少 DWS 和应用层的数据处理负担。
DWD层建表
在大数据领域,DWD 是 Data Warehouse Detail 的缩写,属于数仓分层体系中的一部分。它是数仓中数据模型设计的重要环节,通常位于 ODS(Operational Data Store,操作数据层) 和 DWS(Data Warehouse Summary,数据汇总层) 之间。DWD 层的主要作用是对 ODS 层的数据进行清洗、规范化、细化,生成具备事实意义的明细数据,为后续的数据分析和建模提供支持。
- 与维表不同,订单事实表的记录数非常多
- 订单有生命周期,订单的状态不可能永远处于变化中(订单的生命周期一般在15天左右)
- 订单是一个链表,而且是分区表
- 分区的目的:订单一旦中止,不会重复计算
- 分区的条件:订单创建日期,保证相同的订单在同一个分区
sql
-- 订单事实表(拉链表)
DROP TABLE IF EXISTS dwd.dwd_trade_orders;
create table dwd.dwd_trade_orders(
`orderId` int,
`orderNo` string,
`userId` bigint,
`status` tinyint,
`productMoney` decimal,
`totalMoney` decimal,
`payMethod` tinyint,
`isPay` tinyint,
`areaId` int,
`tradeSrc` tinyint,
`tradeType` int,
`isRefund` tinyint,
`dataFlag` tinyint,
`createTime` string,
`payTime` string,
`modifiedTime` string,
`start_date` string,
`end_date` string
) COMMENT '订单事实拉链表'
partitioned by (dt string)
STORED AS PARQUET;DWD层数据加载
编写一个脚本来进行处理:
shell
vim dwd_load_trade_orders.sh编写的内容如下所示:
shell
#!/bin/bash
source /etc/profile
if [ -n "$1" ]
then
do_date=$1
else
do_date=`date -d "-1 day" +%F`
fi
sql="
set hive.exec.dynamic.partition.mode=nonstrict;
set hive.exec.dynamic.partition=true;
INSERT OVERWRITE TABLE dwd.dwd_trade_orders
partition(dt)
SELECT orderId,
orderNo,
userId,
status,
productMoney,
totalMoney,
payMethod,
isPay,
areaId,
tradeSrc,
tradeType,
isRefund,
dataFlag,
createTime,
payTime,
modifiedTime,
case when modifiedTime is not null
then from_unixtime(unix_timestamp(modifiedTime,
'yyyy-MM-dd HH:mm:ss'),'yyyy-MM-dd')
else from_unixtime(unix_timestamp(createTime,
'yyyy-MM-dd HH:mm:ss'), 'yyyy-MM-dd')
end as start_date,
'9999-12-31' as end_date,
from_unixtime(unix_timestamp(createTime, 'yyyy-MM-dd
HH:mm:ss'), 'yyyy-MM-dd') as dt
FROM ods.ods_trade_orders
WHERE dt='$do_date'
union all
SELECT A.orderId,
A.orderNo,
A.userId,
A.status,
A.productMoney,
A.totalMoney,
A.payMethod,
A.isPay,
A.areaId,
A.tradeSrc,
A.tradeType,
A.isRefund,
A.dataFlag,
A.createTime,
A.payTime,
A.modifiedTime,
A.start_date,
CASE WHEN B.orderid IS NOT NULL AND A.end_date >
'$do_date'
THEN date_add('$do_date', -1)
ELSE A.end_date END AS end_date,
from_unixtime(unix_timestamp(A.createTime, 'yyyy-MM-dd
HH:mm:ss'), 'yyyy-MM-dd') as dt
FROM (SELECT * FROM dwd.dwd_trade_orders WHERE
dt>date_add('$do_date', -15)) A
left outer join (SELECT * FROM ods.ods_trade_orders
WHERE dt='$do_date') B
ON A.orderId = B.orderId;
"
hive -e "$sql"DWS层建表及数据加载
DIM、DWD => 数据仓库分层、数据仓库理论 需求:计算当天
- 全国所有订单信息
- 全国、一级商品分类订单信息
- 全国、耳机商品分类订单信息
- 大区所有订单信息
- 大区、一级商品分类订单信息
- 大区、二级商品分类订单信息
- 城市所有订单信息
- 城市、一级商品分类订单信息
- 城市、二级商品分类订单信息
需要的信息:订单表、订单商品表、商品信息维表、商品分类维表、商品地域维表:
- 订单表:订单ID、订单状态
- 订单商品表:订单ID、商品ID、商家ID、单价、数量
- 商品信息维表:商品ID、三级分类ID
- 商品分类维表:一级名称、一级分类ID、二级名称、二级分类ID、三级名称、三级分类ID
- 商家地域维表:商家ID、区域名称、区域ID、城市名称、城市ID
订单表、订单商品表、商品信息表:订单ID、商品ID、商家ID、三级分类ID、单价、数量(订单明细表) 订单明细表、商品分类维表、商家地域维表:订单ID、商品ID、商家ID、三级分类名称、三级分类名称、三级分类名称、单价、数量、区域、城市 => 订单明细宽表
DWS层建表
dws_trade_orders (订单明细)由以下表轻微聚合而成:
- dwd.dwd_trade_orders(拉链表、分区表)
- ods.ods_trade_order_product(分区表)
- dim.dim_trade_product_info(维表、拉链表)
dws_trade_orders_w(订单明细宽表)由以下表组成:
- ads.dws_trade_orders(分区表)
- dim.dim_trade_product_act(分区表)
- dim.dim_trade_shops_org(分区表)
sql
-- 订单明细表(轻度汇总事实表)。每笔订单的明细
DROP TABLE IF EXISTS dws.dws_trade_orders;
create table if not exists dws.dws_trade_orders(
orderid string, -- 订单id
cat_3rd_id string, -- 商品三级分类id
shopid string, -- 店铺id
paymethod tinyint, -- 支付方式
productsnum bigint, -- 商品数量
paymoney double, -- 订单商品明细金额
paytime string -- 订单时间
)
partitioned by (dt string)
STORED AS PARQUET;
-- 订单明细表宽表
DROP TABLE IF EXISTS dws.dws_trade_orders_w;
create table if not exists dws.dws_trade_orders_w(
orderid string, -- 订单id
cat_3rd_id string, -- 商品三级分类id
thirdname string, -- 商品三级分类名称
secondname string, -- 商品二级分类名称
firstname string, -- 商品一级分类名称
shopid string, -- 店铺id
shopname string, -- 店铺名
regionname string, -- 店铺所在大区
cityname string, -- 店铺所在城市
paymethod tinyint, -- 支付方式
productsnum bigint, -- 商品数量
paymoney double, -- 订单明细金额
paytime string -- 订单时间
)
partitioned by (dt string)
STORED AS PARQUET;DWS层加载数据
shell
vim dws_load_trade_orders.sh写入的内容如下所示:
sql
#!/bin/bash
source /etc/profile
if [ -n "$1" ]
then
do_date=$1
else
do_date=`date -d "-1 day" +%F`
fi
sql="
insert overwrite table dws.dws_trade_orders
partition(dt='$do_date')
select t1.orderid as orderid,
t3.categoryid as cat_3rd_id,
t3.shopid as shopid,
t1.paymethod as paymethod,
t2.productnum as productsnum,
t2.productnum*t2.productprice as pay_money,
t1.paytime as paytime
from (select orderid, paymethod, paytime
from dwd.dwd_trade_orders
where dt='$do_date') T1
left join
(select orderid, productid, productnum, productprice
from ods.ods_trade_order_product
where dt='$do_date') T2
on t1.orderid = t2.orderid
left join
(select productid, shopid, categoryid
from dim.dim_trade_product_info
where start_dt <= '$do_date'
and end_dt >= '$do_date' ) T3
on t2.productid=t3.productid;
insert overwrite table dws.dws_trade_orders_w
partition(dt='$do_date')
select t1.orderid,
t1.cat_3rd_id,
t2.thirdname,
t2.secondname,
t2.firstname,
t1.shopid,
t3.shopname,
t3.regionname,
t3.cityname,
t1.paymethod,
t1.productsnum,
t1.paymoney,
t1.paytime
from (select orderid,
cat_3rd_id,
shopid,
paymethod,
productsnum,
paymoney,
paytime
from dws.dws_trade_orders
where dt='$do_date') T1
join
(select thirdid, thirdname, secondid, secondname,
firstid, firstname
from dim.dim_trade_product_cat
where dt='$do_date') T2
on T1.cat_3rd_id = T2.thirdid
join
(select shopid, shopname, regionname, cityname
from dim.dim_trade_shops_org
where dt='$do_date') T3
on T1.shopid = T3.shopid
"
hive -e "$sql"- dwd.dwd_trade_orders(拉链表、分区表)
- ods.ods_trade_order_product(分区表)
- dim.dim_trade_product_info(维表、拉链表)
- dim.dim_trade_product_cat(分区表)
- dim.dim_trade_shops_org(分区表)
错误速查
| 症状 | 根因定位 | 修复 |
|---|---|---|
| Shell 脚本执行直接报错 | #!/bin/bash 使用了全角感叹号 | 查看脚本首行改为 #!/bin/bash |
| Hive SQL 解析失败 | SQL 中存在多余换行、逗号或字段别名不一致 | 先单独 hive -e 执行 SQL清理换行拼接问题,统一字段命名 |
| 拉链表 end_date 更新异常 | 仅按 orderId 左连接,未严格区分"新状态覆盖旧状态"的更新条件 | 检查 join 后的 B.orderId is not null 命中情况明确新增、更新、未变化三类数据逻辑 |
| 历史订单被漏算 | 只回扫近 15 天分区,但真实业务状态变化超过 15 天 | 抽查超周期订单将回扫窗口与业务 SLA 对齐,或增加异常补偿机制 |
| DWD 读取结果不对 | where dt='$do_date' 只取当天分区,可能拿不到当前有效订单快照 | 对比拉链表 start_date/end_date查询时按有效期过滤,不要只按分区日期取数 |
| DWS 明细金额不准 | productnum * productprice 未考虑优惠、退款、运费分摊 | 对账订单支付金额与明细金额明确金额口径:原价、实付、优惠后金额分别建字段 |
| 宽表关联后数据变少 | 使用 join 而非 left join,维表缺失导致事实被过滤 | 对比 join 前后记录数维表不完备时优先 left join,并补默认维度值 |
| 表名引用混乱 | 文中写了 ads.dws_trade_orders,应为 dws.dws_trade_orders | 检查 DWS 宽表来源表统一库名,避免 ADS/DWS 混用 |
| 字段名不一致导致报错 | 如 pay_money 与 paymoney、productnum 与 productsnum 混用 | 检查建表与查询字段统一命名风格,一处定义,全链路一致 |
| 维表快照时间不一致 | 有的维表按拉链有效期过滤,有的按 dt='$do_date' 过滤 | 检查各维表时间字段统一维度取数口径:日快照或拉链有效期二选一 |
| 订单状态口径混乱 | 未限制是否只统计已支付/已完成订单 | 检查 DWS 装载 where 条件明确状态过滤规则,例如只保留已支付订单 |
| 分区策略效果一般 | 拉链表本质关注有效期,但当前按创建日分区会增加跨期维护复杂度 | 看更新脚本扫描路径评估是否保留创建日分区,或改为快照式/增量式策略 |
其他系列
🚀 AI篇持续更新中(长期更新)
AI炼丹日志-29 - 字节跳动 DeerFlow 深度研究框斜体样式架 私有部署 测试上手 架构研究 ,持续打造实用AI工具指南! AI研究-132 Java 生态前沿 2025:Spring、Quarkus、GraalVM、CRaC 与云原生落地
💻 Java篇持续更新中(长期更新)
Java-218 RocketMQ Java API 实战:同步/异步 Producer 与 Pull/Push Consumer MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务已完结,Dubbo已完结,MySQL已完结,MongoDB已完结,Neo4j已完结,FastDFS 已完结,OSS已完结,GuavaCache已完结,EVCache已完结,RabbitMQ已完结,RocketMQ正在更新... 深入浅出助你打牢基础!
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈! 大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解