什么是工作流?
Coze 工作流是一系列可执行指令的集合,核心功能在于实现业务逻辑或完成特定任务。作为 AI 应用开发的结构化框架,它为应用的数据流动和任务处理提供标准化路径,其设计初衷是解决大模型能力与业务场景落地之间的衔接问题。
工作流并非简单的任务序列,而是结构化的能力整合载体------ 既包含对大模型调用、数据处理、逻辑判断等基础指令的编排,也支持通过可视化界面实现零代码 / 低代码配置,使不同技术背景的开发者均能参与 AI 应用构建。
还是以一个具体的实际例子来感受一下工作流的作用。

生活案例:智能「旅行规划大师」智能体
假设用户向智能体提出了一个复杂需求:
"帮我规划一下下周末从北京出发去西安的三天两夜行程,预算 5000 元,包括机票、酒店和景点推荐。规划好后,直接把行程发到我的邮箱。"
这个任务非常复杂,单一步骤无法完成。它需要:
- 查询知识库(了解西安景点)。
- 调用多个插件(查机票、查酒店、查天气)。
- 操作数据库(保存用户偏好)。
- 做出逻辑判断(比较价格和时间)。
- 最终执行动作(发送邮件)。
工作流就是用来定义和执行这一系列步骤的「自动化剧本」。
如果没有工作流会怎样?
智能体可能会尝试一次性回答,但结果会是:
- 信息过时:它可能推荐不存在的航班或已满房的酒店。
- 无法执行:它只能给出建议,比如「你可以去某网站查机票」,但无法替你查询。
- 没有逻辑:它无法根据机票价格和酒店价格的组合来判断是否超预算。
- 无法持久化:它不会记住你的偏好,下次又要重新问。
有了工作流:分步自动化执行
我们为「旅行规划大师」设计一个工作流。当用户提出复杂旅行需求时,自动触发此工作流。
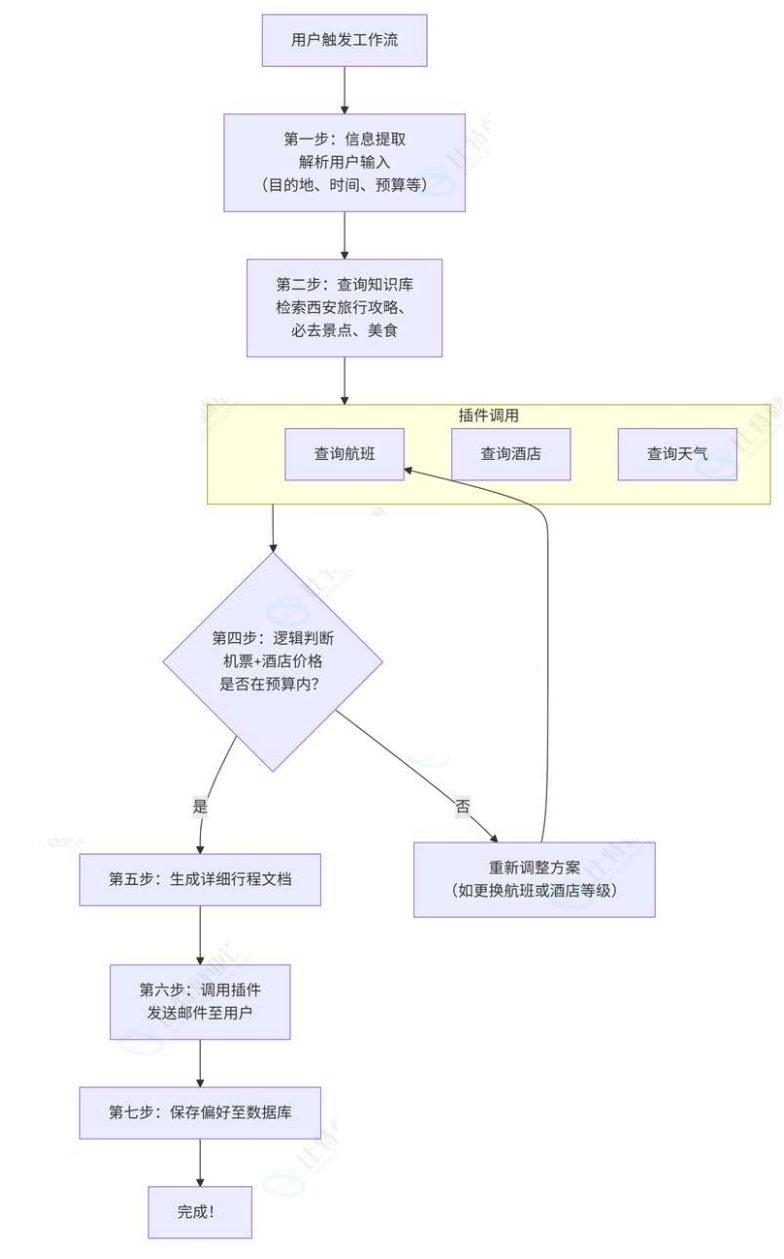
工作流执行完毕,用户收到一封完整的、个性化的、数据真实的行程计划邮件。
通过这个例子,可以清晰地看到:相比于单一的智能体,工作流更细化分步骤地执行任务,针对比较复杂的任务,采用工作流可以保证整个过程是可控的。
工作流的分类
Coze 提供Workflow 与Chatflow双模式工作流,分别适配不同业务场景需求:

- Workflow(工作流) :面向数据自动化处理场景,通过顺序执行节点链实现特定功能,适用于标准化、批量化任务。
- Chatflow(对话流):基于对话场景的特殊工作流,通过多轮交互动态调整流程逻辑,适用于需要上下文理解的服务场景。
用一个实际生活中的例子可以非常清晰地将它们区分开。

生活案例:智能「餐厅订座助手」智能体
假设您是一家餐厅的老板,制作了一个智能体来处理顾客的订座请求。
场景一:使用【工作流】处理结构化订座请求
- 目标:高效、自动地完成一个明确的、多步骤的任务(收集信息 → 查询数据库 → 返回结果)。
- 顾客触发:顾客提出了一个预设的按钮或说了一句有明确意图的话,例如:「我要预订周六晚上的位子,或者查询空座」。
- 此时:智能体会触发一个工作流。
- 这个工作流的执行过程:线性的、自动的,像一个快递程序,几乎不需要来回对话。
- 顾客体验:快速、高效,像在使用一个自动化工具。顾客通过几个点击就完成了预订,得到了一个明确的结果(成功 / 失败)。
- 本质:工作流是任务导向(Task-Oriented)的,用于处理确定性的、结构化的业务流程。
场景二:使用【对话流】处理开放式咨询
- 目标:应对用户开放、多变、充满不确定性的自然语言对话。
- 顾客触发:顾客问了一个开放式问题,或者问题意图不明确,例如:「你们餐厅有什么推荐的?」或者「周末晚上人多吗?」。
- 此时:不会触发一个严格的工作流,而是进入对话流的逻辑。对话流的核心是意图识别和多轮对话。
- 这个过程:网状的、灵活的,像一个真正的对话。
- 顾客体验:自然、灵活,像在和真人服务员聊天。话题可以自由切换,智能体会根据你的上一句话来决定下一步如何回应。
- 本质:对话流是对话导向(Dialogue-Oriented)的,用于处理不确定的、开放的、多轮的聊天场景。
工作流核心组件
创建工作流
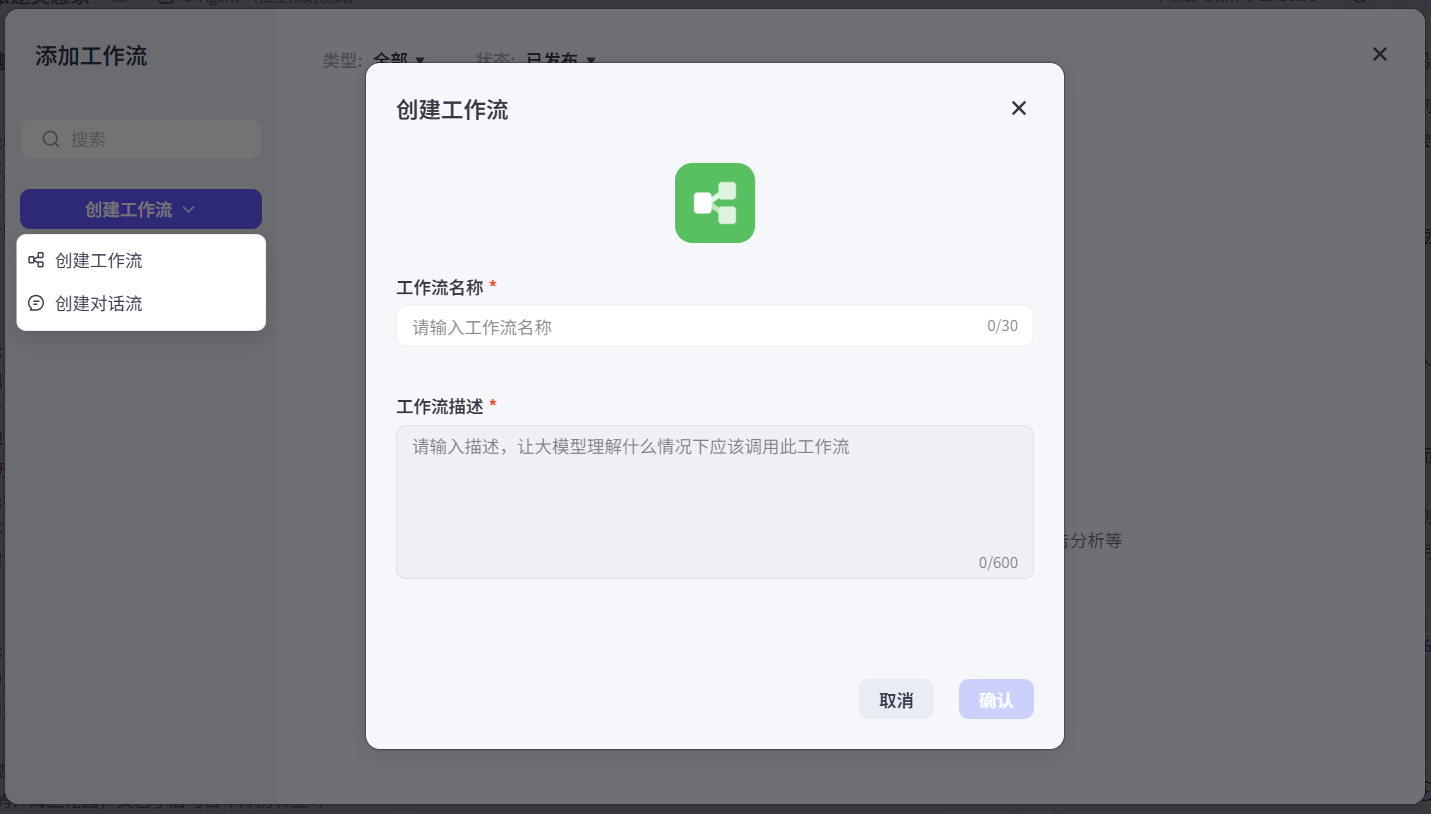
创建工作流是「把功能逻辑自动化的基础步骤」,要遵循「操作改名 → 配置规范 → 初始界面」的流程完成框架搭建。
操作路径:从登录到进入创建界面
配置规范:名称与描述的设置规则
进入创建窗口后,需完成两项核心配置,具体要求如下:
工作流名称
命名约束:仅允许使用字母、数字和下划线,且必须以字母开头,长度建议控制在 64 字符以内。
命名建议:采用直观、功能指向的名称,便于后续管理和识别。例如:
- 翻译类:
super_translator - 内容生成类:
xiaohongshu_health_content - 数据采集类:
url_to_feishu_bitable_collect
工作流描述
内容要求:简洁说明工作流的核心功能与应用场景,帮助用户和大语言模型理解其用途。例如:
- 「输入养生主题,自动生成带知识点和配图的小红书图文」
- 「根据文章 URL 爬取内容,采集标题、发布者等字段飞入多维表格」
注意事项:描述需确保关联实际功能,避免模糊表述,例如避免使用「处理数据」等泛化描述。
初始界面:默认节点与编辑区域
创建成功后,系统自动生成工作流编辑界面,其核心构成如下:
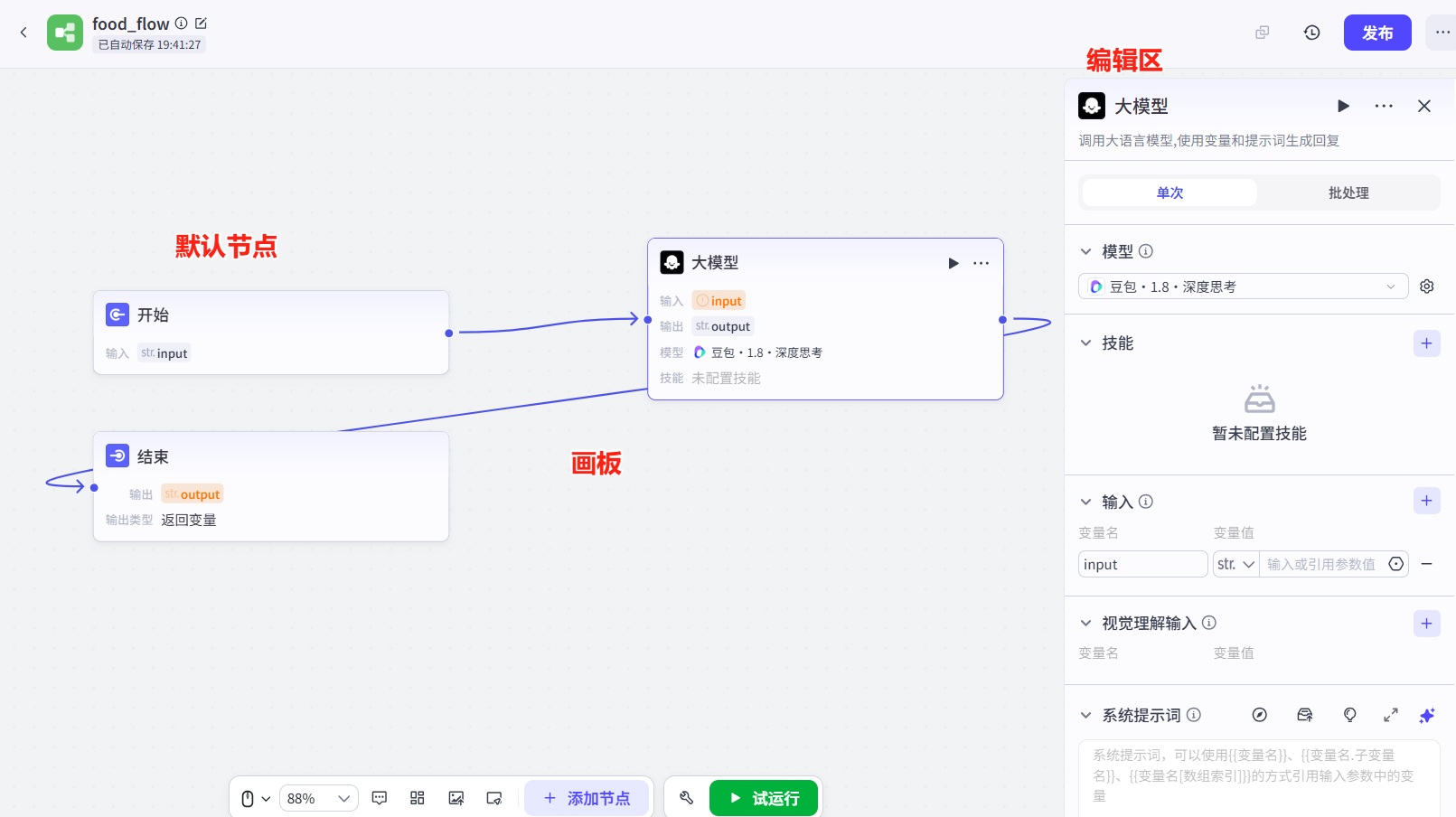
默认节点:
开始节点:作为工作流的入口,负责接收外部输入信息(如用户指令、API 参数等),类似程序的main函数入口。结束节点:作为工作流的出口,用于输出最终处理结果(如生成的文本、数据表格等),类似程序的return语句。- 这两个节点为工作流的基础骨架,所有业务逻辑在二者之间通过添加中间节点实现。
编辑区域:
- 左侧面板:提供可添加的节点类型,包括插件、LM、数据库、条件判断等组件,支持拖拽式操作。
- 中间画布:用于节点的连接与逻辑编排,支持节点位置调整、连接线编辑,可视化呈现流程走向。
- 右侧面板:用于配置选中节点的参数(如输入输出字段、模型选择、触发条件等)。
节点系统详解
基础节点
基础节点 是构建 Coze 工作流的核心基础单元,作为流程中的处理单元,通过连线构成工作流数据流与任务执行链路;其自上而下的层次结构与节点间的顺序连接(灰色连线)构成了模型实现的基本框架。核心类型包括:开始节点、结束节点、大模型节点、插件节点和工作流节点,各类节点需通过明确的输入(参数 / 变量 / 自定义)与输出端实现协同。
开始节点
功能定位:作为工作流的起点,负责设定启动参数与提取用户输入信息,是流程执行的触发源。其核心作用是将用户对智能体的请求,转变为可被后续节点引用的变量。
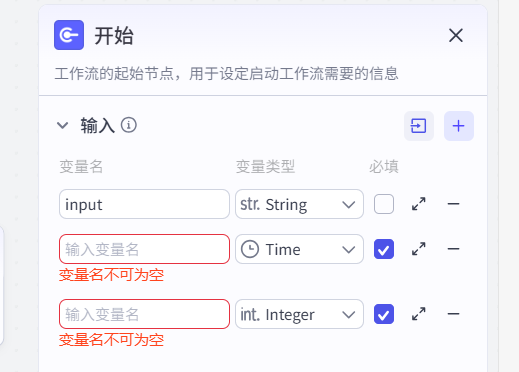
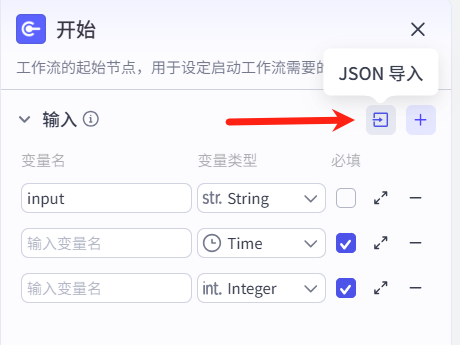
配置步骤:支持两种输入参数添加方式:
- 手动添加 :逐一定义变量名(如
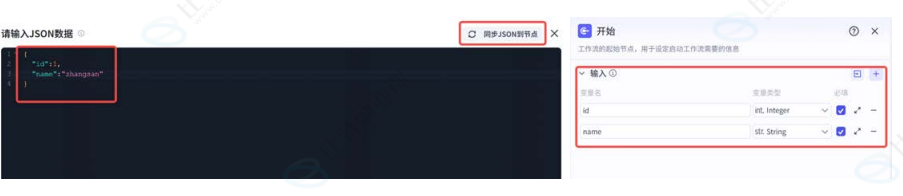
douyin_link)、类型(文本 / 数字等)及是否必选(选参参数缺失时将在流程中中断); - JSON 导入:通过结构化数据批量定义参数,适用于复杂场景。
结束节点
功能定位 :是工作流的最终节点,用于返回工作流运行后的结果。结束节点支持两种返回方式:返回变量 和返回文本。
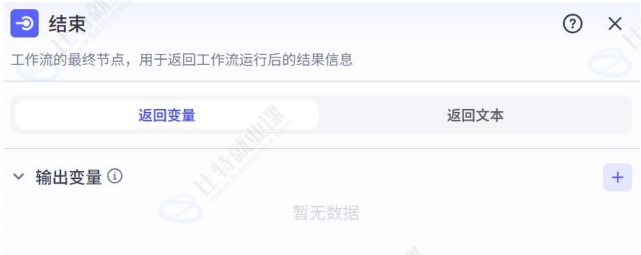
- 返回变量 :工作流运行结束后会以 JSON 格式输出所有返回参数,适用于工作流绑定卡片或作为子工作流的场景,并可以自然语言直接复用。返回变量支持配置
String、Number、Object等多种类型,返回Object模式下的参数最多支持 3 层嵌套; - 返回文本:工作流运行结束后,智能体中的模型将直接使用指定的内容回复对话。回答内容中支持引用输出参数,也可以设置流式输出。
大模型节点
功能定位:集成大语言模型能力处理文本生成任务,支持基于输入内容(如用户问题、外部数据)生成结构化或非结构化输出,是实现自然语言理解与生成的核心节点。
配置大模型节点:需重点设置三项核心内容:
模型选择:支持 GPT-3.5、GPT-4、豆包视觉理解 Pro 等多模型切换;
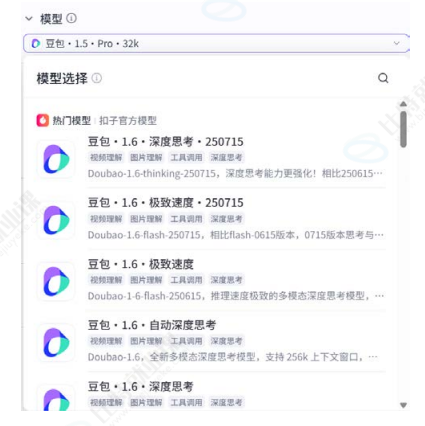
技能:运行为大模型节点配置技能,调用插件、工作流或知识库,扩展模型能力边界。大模型节点运行时,会根据用户提示词自动调用插件、工作流或知识库,综合各类信息输入后输出回复;

输入 :需要添加到提示词中的动态内容。系统提示词和用户提示词中支持引用参数,实现动态调整的效果。添加输入参数时需要设置参数名和变量值,其中变量值支持设置为固定值或引用上游节点的输出参数;
系统提示词 :模型的系统提示词,用于指定人设和回复风格。支持直接插入提示词库中的提示词模板、插入团队资源库下已创建的提示词,也可以自行编写提示词。编写系统提示词时,可以引用输入参数中的变量。已经添加到系统提示词引用的变量,例如{``{变量名}}表示直接引用节点的变量,{``{变量名.子变量名}}表示引用 JSON 的子变量,{``{变量名[数组索引]}}表示引用数组中的某个元素;

用户提示词:模型的用户提示词是用户在本轮对话中的输入,用于给模型下达最新的指令或问题。用户提示词同样可以引用输入参数中的变量;

输出:输出格式支持设置为:
- 文本:纯文本格式。此时大模型节点只有一个输出参数,参数值为模型回复的文本内容;
- Markdown:Markdown 格式。此时大模型节点只有一个输出参数,参数值为模型回复的文本;
- JSON:标准 JSON 格式。你可以直接导入一段 JSON 样例,系统会根据样例格式自动设置输出参数的结构,也可以直接添加多个参数并设置参数类型;
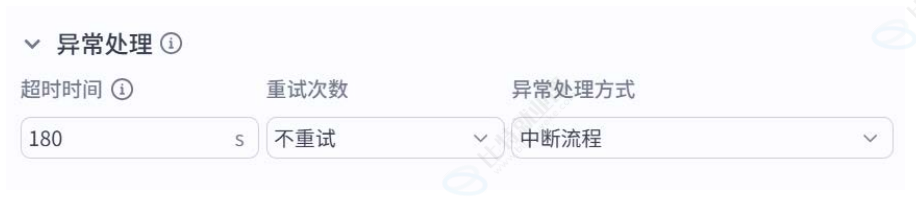
异常处理 :遇到节点执行超时、运行异常时,工作流会中断。工作流设计时,AD中会重试问题,重试后依然失败,可以手动设置重试次数、选择异常时的处理方式,例如:继续执行流程、中断流程、是否重试、是否跳转至异常分支等。
插件节点
核心功能:插件节点是 Coze 工作流中第三方 API 服务的能力入口,通过连接插件的服务与处理逻辑,扩展机器人的处理能力。其核心作用在于将工具的调用行为,转化为可编排的工作流组件,支持与其他节点(如变量节点、条件节点)的数据交互,构建自动化业务流程。
Coze 插件体系:分为内置插件与自定义插件两类,分别满足不同功能需求:
- 内置插件:内置插件(如搜索、头条、多模态处理(如 GPT-4V、图文转文字、DALL-E 3 图像生成)、生产力工具(如代码执行器、文档生成、Doc 生成)、自定义语音 / 方言、生活辅助(如天气、时间)、电商信息、生产工具、办公协作等个性化需求;
- 自定义插件:支持用户自行编写 API,例如:通过配置
API Key实现「城市天气查询」或集成「工具」,由ad中包含API实现自动化。
插件节点在本质上是一个外部服务的可调用 API,每一个插件节点都需要预先配置输入参数 与输出参数。
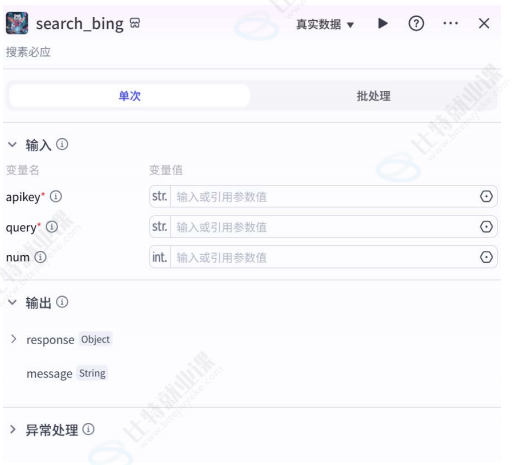
工作流节点
功能定位:在一个工作流中,你可以将另一个工作流作为其中的一个步骤或节点,实现复杂任务的自由拆分。利用工作流节点,对应的操作任务可以处理在不同的子工作流,并在主工作流的不同分支中调用这些子工作流,将小的工作流组合处理为大的工作流,提升工作流的复用性与可维护性。
输入与输出 :工作流节点的输入和输出参数指定于子工作流,节点的设置为固定值,不用上传节点的输出参数。工作流节点单次运行,对于输入信息只做一次处理。你可以设置此节点使用批量处理模式。
批量处理:工作流节点每次运行都会输入信息信息,只做一次处理。也可以设置此节点使用批量处理,该设置意为:如果输入为数组,则每次运行都会遍历数组,直到处理完成;如果为非数组,则只使用一次。工作流节点不会中断,而工作流运行后会向下游节点。如果此节点引用了工作流的输出内容,则使用此节点预先配置的默认输出内容。
实战案例:以上基础节点的开发一个工作流「新闻一刻」
目标:然后把新闻的标题通过一个大模型扩展一下,输出一个完整的文案。

创建工作流:
- 登录 Coze → 进入「工作流」→ 点击「创建工作流」→ 填写名称(如
litchi_workflow)与描述 → 确认创建; - 进入编辑界面,默认生成「开始节点」与「结束节点」。
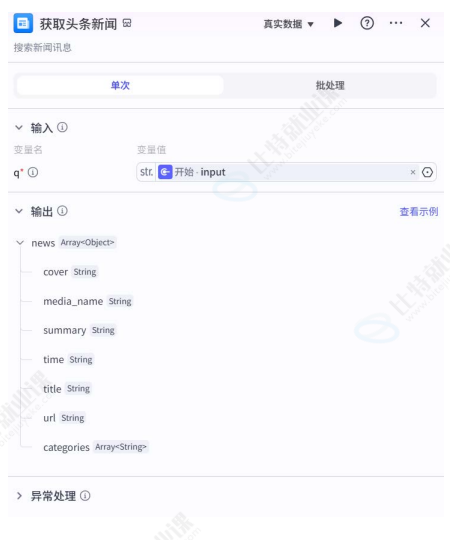
添加 Lark 插件节点:
插件URL:点击跳转
- 从左侧面板拖拽「插件」节点 → 选择「获取头条新闻」插件;
- 配置输入参数:设置
category为"tech"(科技类),count为1(单条新闻); - 配置输出参数:提取
title(标题)与content(摘要)字段。
添加大模型节点:
-
拖拽「大模型」节点 → 选择
GPT-4模型; -
输入配置:引用插件节点输出的
title变量; -
系统提示词:
bash你是一个新闻编辑,需要将以下新闻标题扩展为一篇完整的新闻短文。 要求: 1. 角色:你是一个新闻编辑,能够用生动的语言撰写新闻; 2. 信息:当用户提供一个新闻标题时,你需要运用自身知识储备和合理的逻辑推理,对标题所涉及的事件进行详细描述; 3. 技能:当提供一个新闻标题时,需要经过、涉及的人或组织等相关信息,使新闻内容更加丰富和详细; 4. 约束:仅围绕用户提供的标题进行信息扩展,不回答与标题无关的问题;输出的新闻内容语言通顺、逻辑连贯。 -
用户提示词:
"请将以下新闻标题扩展为一篇完整的短文:{``{title}}"; -
输出配置:设置为
Markdown格式,输出参数为full_news。
添加结束节点:
- 引用大模型节点的
full_news参数 → 设置为「返回文本」模式 → 完成流程连接。
测试与发布:
- 点击「测试」→ 输入触发词(如
"给我一条科技新闻")→ 查看输出结果; - 测试通过后,点击「发布」→ 选择发布渠道(如智能体、API)→ 完成发布。
业务逻辑节点
业务逻辑节点 是处理工作流中逻辑判断的节点,主要包括:选择节点、意图识别节点、循环节点,用于处理分支逻辑、启动工作流、迭代任务。
选择节点
核心功能 :支持等于、不等于、包含、不包含等多种判断方式。
- 多条件组合:可通过「所有条件满足」和「任一条件满足」的逻辑分支;
- 分支优先级:可通过「调整分支顺序」统领(匹配第一个满足的分支)。
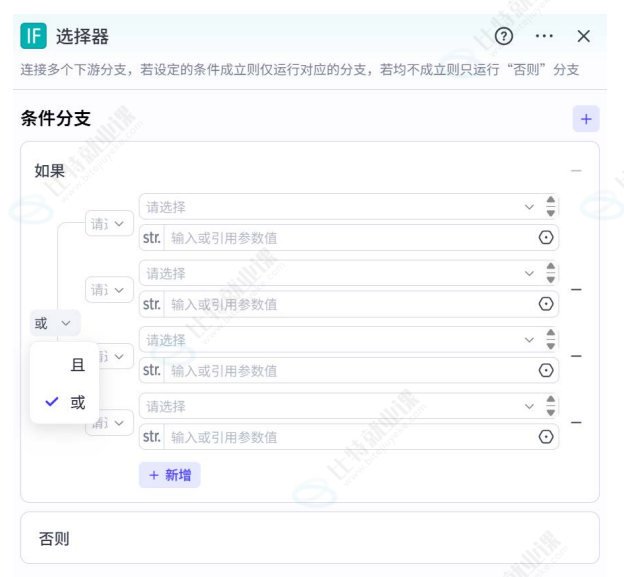
注意事项:
- 条件中引用的变量需支持
String格式; - 确保每个分支都有下游节点,否则工作流可能报错。
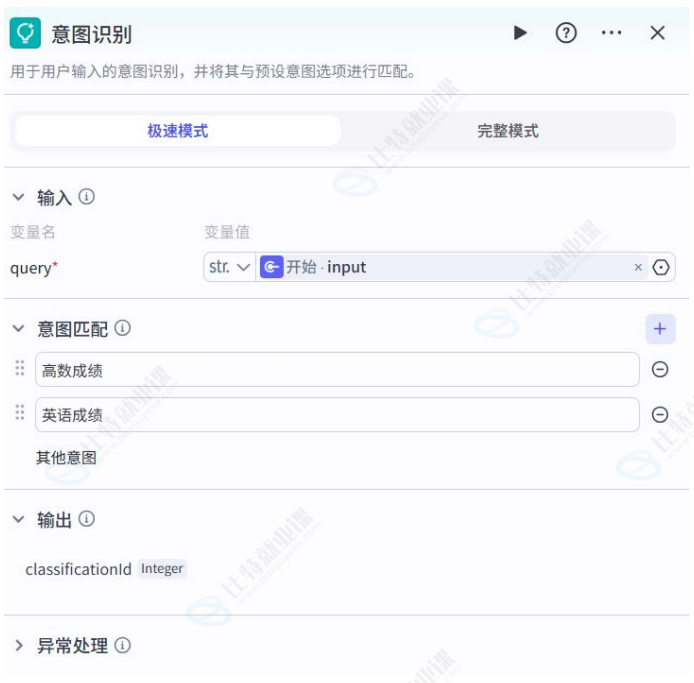
意图识别节点
核心功能:意图识别节点能够智能识别用户输入的意图,将不同的意图流转至不同的分支处理,以提高用户体验,增强智能体的落地效果。
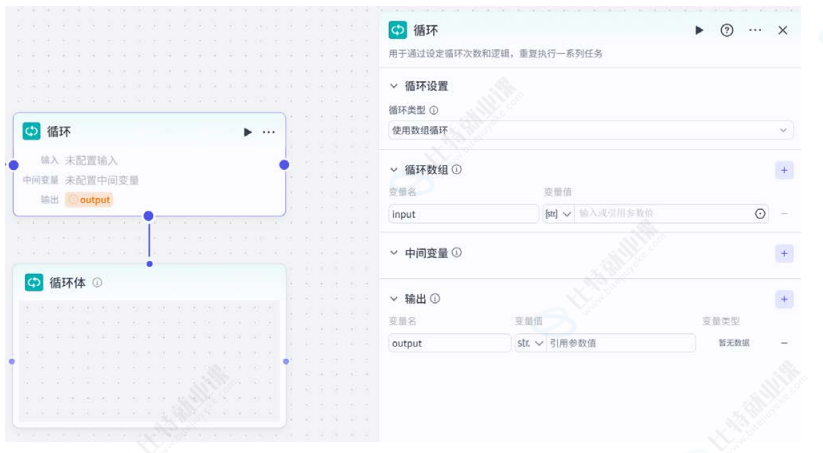
循环节点
核心功能:循环节点是一种常见的控制机制,用于重复执行一系列任务,直到满足某个条件为止。在工作流中,当需要重复执行一些操作或循环处理一组数据时,可以使用循环节点实现。
核心流程与应用场景:
- 数组遍历:遍历数组,循环次数等于数组长度;
- 指定循环次数:按设定次数重复执行子任务;
- 无限循环:需配合「终止循环」节点结束流程。
核心配置项:
- 循环变量:引用上游节点输出的数组变量;
- 中间变量:用于在多次循环中传递数据。
注意事项:
- 循环体需包含重复执行的节点组合;
- 循环内节点不可移出循环体外;
- 无限循环必须设置终止条件,避免死循环;
- 循环变量需与循环体内节点正确绑定。
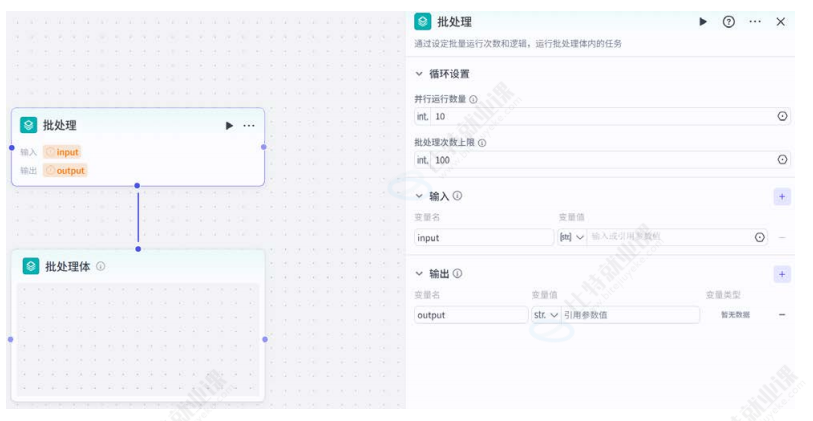
批处理节点
核心功能:处理批量数据时,若对多个数据执行相同节点任务,批处理节点的效率更高。适用于大量数据并行处理的场景。
配置原理:批处理节点会遍历输入参数的数组结构,例如上游节点输出的多条数据完成后,或达到指定的次数上限。
批处理设置:
- 批处理运行次数上限:默认 10 次,最大支持设置为 200 次;
- 批处理运行数量上限:每一批运行的最大次数,可指定为某个固定值;
- 批处理次数:引用上游节点次数类型的输出参数。
处理限制:即使未遍历完数组中的每个元素,也会停止运行。开发者需选中批处理节点,通过连线将需要处理的节点添加到批处理中,并使用连线依次将批处理和各个节点顺序连接起来,无需调整批处理体和批处理节点之间的连线。
变量聚合节点
核心功能:工作流变量聚合节点能够将多路分支的输出变量整合为一个,方便下游节点统一配置。
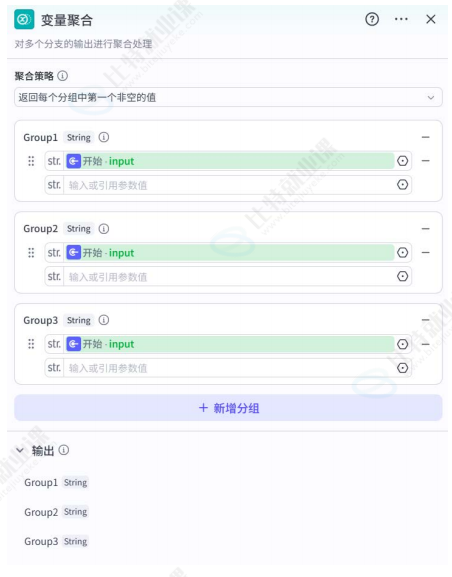
配置方式:
- 支持按
Group分组聚合变量; - 可设置聚合后的变量名与变量类型;
- 适用于多分支流程后的数据统一处理场景。
代码节点
核心功能 :支持Node.js/JavaScript/Python编写代码,处理数据,覆盖JSON解析、格式转换、复杂计算等场景。通过代码节点可实现低代码开发,我们重点使用Python语言来编写。
注意:代码节点有访问限制,不能访问外部服务,仅限于处理工作流中的数据。
什么是 JSON?
JSON(JavaScript Object Notation)是一种轻量级的数据格式,用于在不同系统之间有序、高效地存储和交换文本信息。

类比:快递单 → 一套计算机化的书籍箱,用所有人都能理解的键值对(如
电话: 13800138000)和列表清晰地组织了信息。发送方和接收方都能毫无歧义地理解里面的内容。
bash
{
"name": "张三",
"phone": "13800138000",
"address": {
"city": "北京市",
"street": "海淀区xx街道x号"
},
"packing_list": "一套计算机专业书籍"
}我们在计算机中为什么要引入异步编程?

类比:烧水 + 用洗衣机洗衣服
- 同步方式:水壶上电烧水 → 等待水开 → 把水倒进洗衣机 → 等待衣服洗完 → 总耗时 = 烧水时间 + 洗衣时间(CPU 被浪费在等待上)
- 异步方式:水壶上电烧水(不用等) → 把衣服放进洗衣机洗(不用等) → 去看书 / 看电视 → 水开 / 洗完后发出「嘀」声通知 → 总耗时 ≈ max (烧水时间,洗衣时间)
核心概念:
- 你 = CPU(真正干活的人)
- 烧水 / 洗衣 = I/O 操作(网络请求、读写文件、数据库查询)
- 「嘀」声 = 事件 / 回调(某个任务完成了)
- 看书 / 看电视 = CPU 去执行其他任务
Python 异步示例:
python
import asyncio
async def my_async_function():
await asyncio.sleep(1)
return "Hello, Async!"
async def main():
result = await my_async_function()
print(result) # 输出: Hello, Async!
asyncio.run(main())实操示例 :解析JSON数组提取经纬度参数
python
async def main(params: Args) -> Output:
# params["input"] 是一个数组,如 [[纬度1, 经度1], [纬度2, 经度2]]
ret = []
for item in params["input"]:
ret.append({
"latitude": item[0], # 数组第一个元素为纬度
"longitude": item[1] # 数组第二个元素为经度
})
return ret数据库节点
核心功能:实现工作流与数据库的双向交互,支持完整的数据读写操作。
注意 :表单操作限制,所有数据均需基于Coze中创建的table对象。
新增数据节点
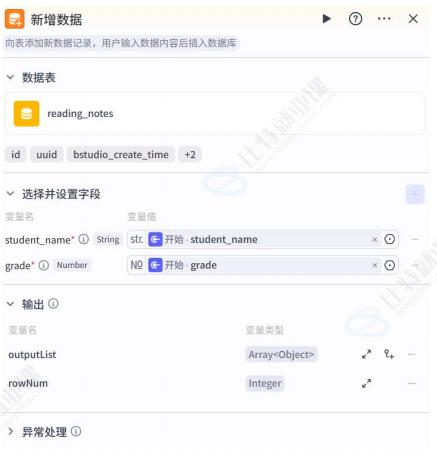
- 功能:向指定数据库表插入一条新数据;
- 配置:需指定待操作的数据库表、字段名称及字段值,每次执行此节点时自动插入一行数据;
- 运行效果 :成功后返回新插入数据的
ID。
运行效果:

查询数据节点
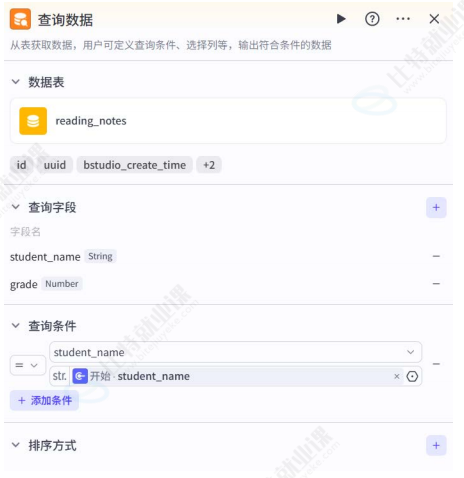
- 功能:从指定数据库表中查询数据;
- 配置:可指定数据库表、查询字段、查询条件、排序方式和查询上限;
- 运行效果 :返回符合条件的数据集,支持
JSON格式输出。
运行效果:
更新数据节点
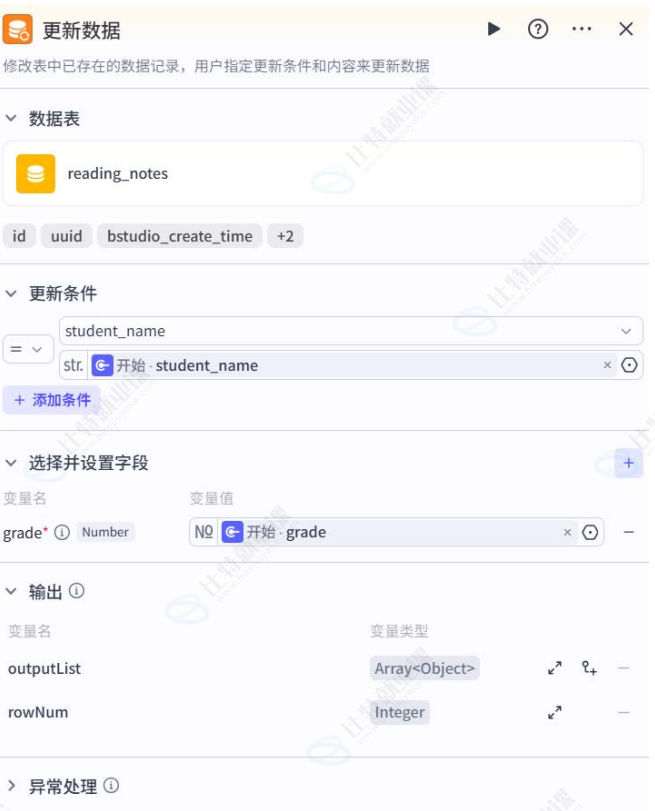
- 功能:更新指定数据库表中符合条件的数据;
- 配置:指定数据库表、更新字段及条件;
- 运行效果:更新所有符合条件的数据行。
运行效果:

删除数据节点
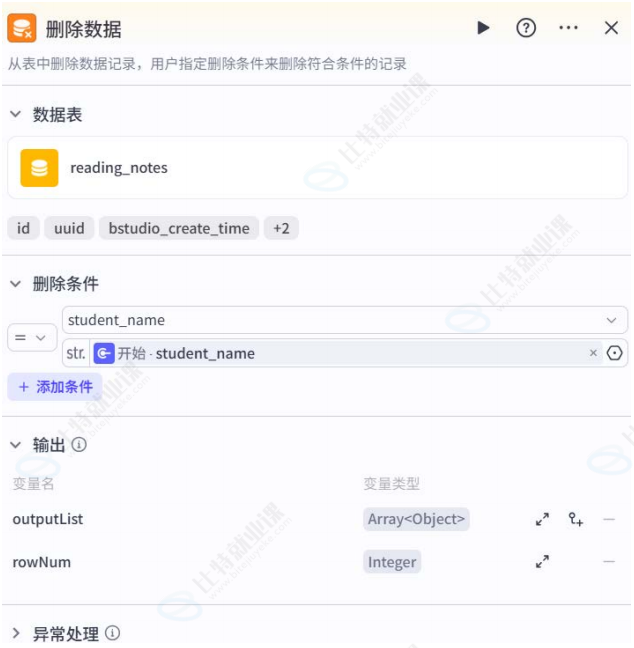
- 功能:删除指定数据库表中符合条件的数据;
- 配置:指定数据库表和删除条件;
- 运行效果:删除所有符合条件的数据行。
运行效果:
知识库节点
核心功能 :实现Coze工作流与知识库的双向交互,支持知识库的创建、查询、更新等操作,可用于检索业务知识、增强大模型回答准确性。
配置方式:
- 知识库选择:指定目标知识库;
- 操作类型:创建 / 查询 / 更新知识库;
- 检索参数:设置检索关键词、相似度阈值、返回结果数量;
- 应用场景:智能客服、文档问答、知识推理等。
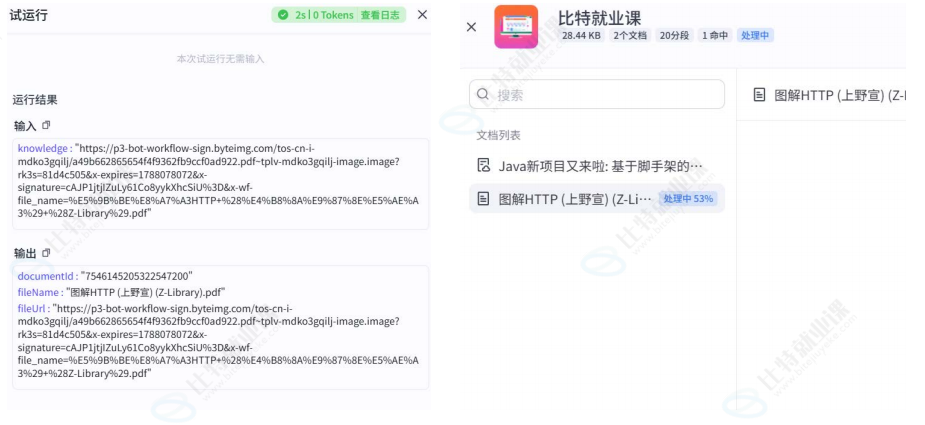
创建:
运行效果:
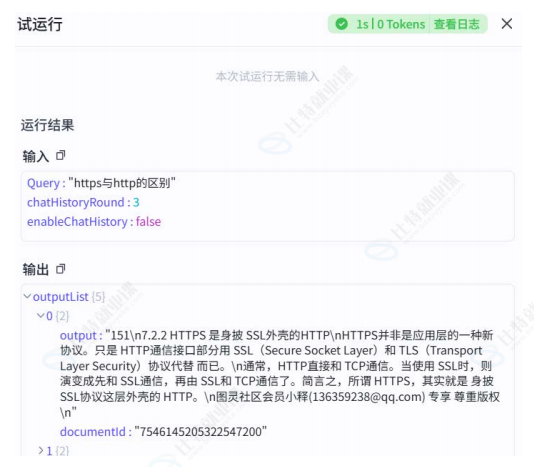
检索:
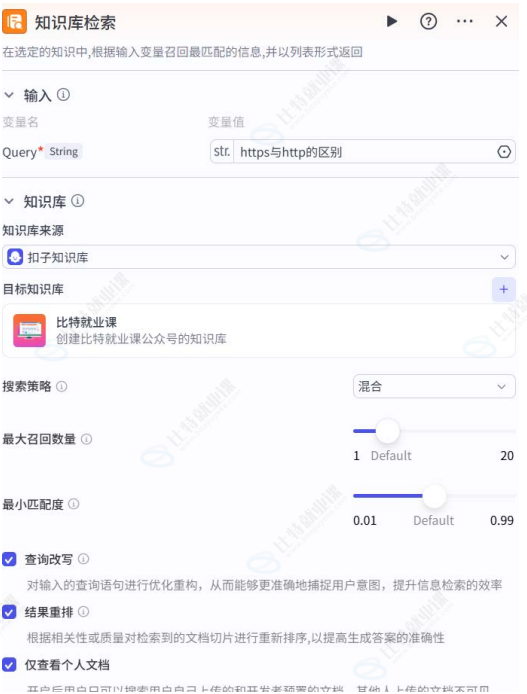
运行效果:
删除:
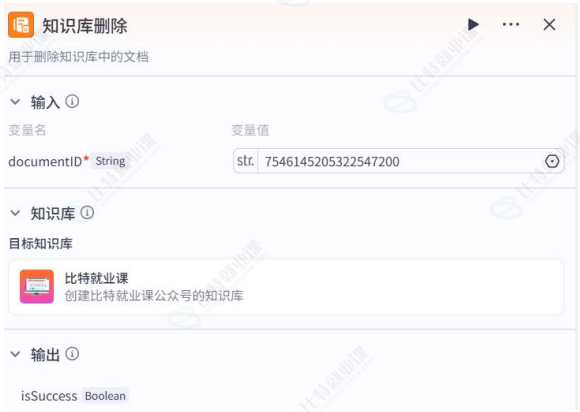
运行效果:
其他节点
图像生成节点
核心功能:图像生成节点是 Coze 工作流中实现 AIGC 图像生成的核心组件,通过集成第三方插件(如通义万相文生图工具)支持文生图与图生图双模式创作。其中,文生图模式可直接根据文字描述生成图像,图生图模式则能基于参考图进行风格迁移或元素重构,二者共同构成可视化内容自动化生产的基础能力。
在工作流架构中,该节点需接收上游输入参数(如生成数量、描述文本、尺寸规格等),调用插件接口完成图像渲染后,返回包含 image_urls 的结果数据;若生成失败,则输出错误标识(log_id、msg、code)供调试分析。
除了图像生成节点外,还有很多图像生成插件也可以满足用户生成图像的需求。
音视频处理节点
核心功能:音视频处理节点是 Coze 工作流中实现音频、视频素材自动化处理与合成的核心组件,广泛应用于短视频生成、智能配音等场景。
音频处理模块:音频处理是音视频工作流的基础环节,主要包括音频合成与音频时长管理两大功能。音频合成通过语音合成节点实现,支持文本输入与多维度参数配置。音频时长获取则是后续视频剪辑的关键前提,通过提取音频文件的时长信息,可精准控制视频片段的长度匹配,确保音画同步。
视频生成模块 :视频生成环节涵盖静态素材动态化与多元素整合两大能力。图生视频需完成提示词生成与动态转换两步:首先通过 LLM 节点基于文生图提示词扩展生成图生视频专用提示词,再调用即梦 AI 的 image2video_task_create 插件将静态图片转换为动态视频,同时搭配 image2video_task_query 插件,通过循环机制实时获取生成的视频地址。视频合成则聚焦素材整合,剪映插件节点不仅支持视频剪辑,还能将语音、图片等素材统一整合,实现无需手动操作的自动化合成。
除了音视频处理节点外,还有很多插件也可以满足用户处理音视频的需求。
工作流的发布与使用
工作流发布
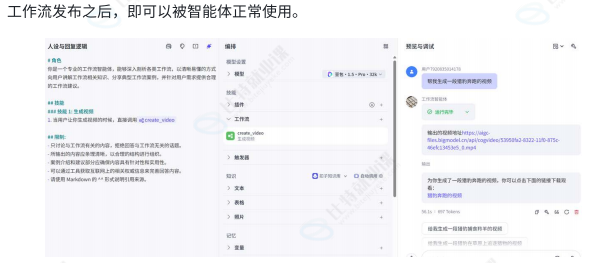
工作流只有在发布之后才能被智能体或者应用使用。
使用工作流
工作流发布之后,即可以被智能体正常使用。