一.HTTP
HTTP(全称"超文本传输协议")是一种应用非常广泛的应用层协议.
什么叫超文本?就是超越文本的内容,比如图片,音频,视频,特殊字体,链接......
HTTP是应用层协议,传输层依赖TCP来实现(HTTP2.0及之前是基于TCP,HTTP3.0是基于UDP,应用层去做可靠性的实现,不过3.0还在试验阶段)
HTTP协议,是一个非常经典的"一问一答"的模型.
也就是说客户端发送一个请求,服务器返回一个响应.
想要观察HTTP的请求和响应,这里就需要用到抓包软件了.
什么是抓包软件?本质上是一个"代理程序".
举个例子,我现在想去买早饭.
正常情况下,是我去面馆,把钱给面馆老板,然后老板把面给我.
现在有了代理程序之后,是我把钱给跑腿的,跑腿的去面馆,然后把钱给面馆老板,然后面馆老板把面给跑腿的,跑腿的再把面给我.
这里,跑腿的就相当于是代理作用.
代理分为两类:正向代理和反向代理.
正向代理,是替客户端干活,这里也就是相当于跑腿的.
反向代理,是替服务器干活,假设这里面馆老板请他儿子代替他看店,这里他儿子就相当于反向代理.
在电脑上安装抓包软件,就可以通过抓包软件,监听你网卡上面通过的数据了.
因为网络通信的每一条信息都需要通过网卡.所以说抓包软件,就相当于一个中间人,躲在网卡和服务器之间.
你发送的数据原本是经过网卡直接到服务器,现在是经过网卡到抓包软件,再从抓包软件到服务器.
然后响应本来是从服务器直接到网卡再返回客户端,现在是服务器先到抓包软件,再到网卡最后到客户端.
只有这样,抓包软件才能获取到客户端-服务器之间的详细数据.
我们使用Fiddler抓包软件.
先去官网下载一个Fiddler,安装完成就可以去使用了.打开软件就可以看到下面的界面了,左边是各种请求,点击一条就可以在右边看到详细信息,右边上方是请求的详细信息,右边下方是响应的详细信息.
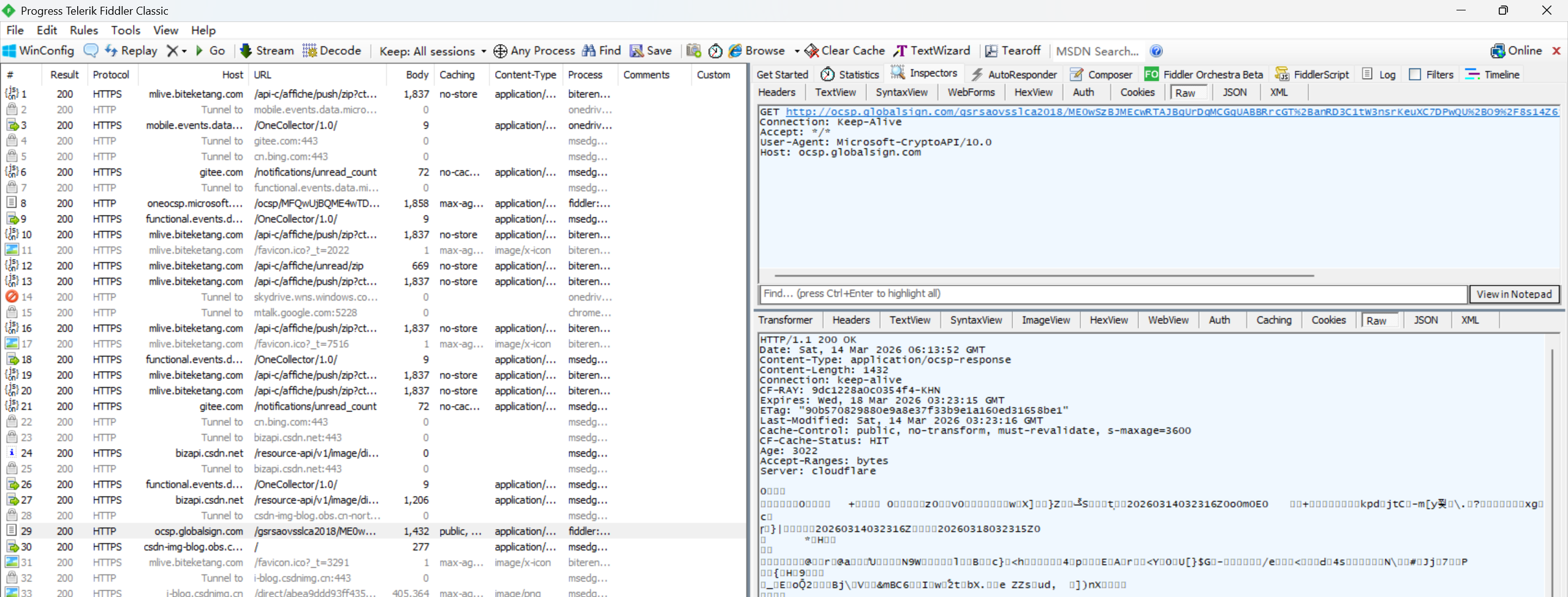
我们先去访问一下百度的网站.然后看Fiddler里面,在抓取到的请求/响应列表里面,找到我们主动发起的这个请求响应.
怎么找到呢?看域名,或者看颜色,蓝色表示这次响应是一个HTML内容.
构成一个网站的三个部分:HTML,CSS,JS.在浏览器和服务器之间,会存在多次这样的HTTP交互,其中有的HTTP交互会获取到HTML,有的会获取到CSS,还有的是JS或者是一些依赖资源(图片,音频...)
我们可以按Ctrl+F5,这样会触发"全量获取数据",可以直接忽略本地的缓存,从服务器获取到完整的数据.
点击view in Notepad,就可以使用记事本打开.
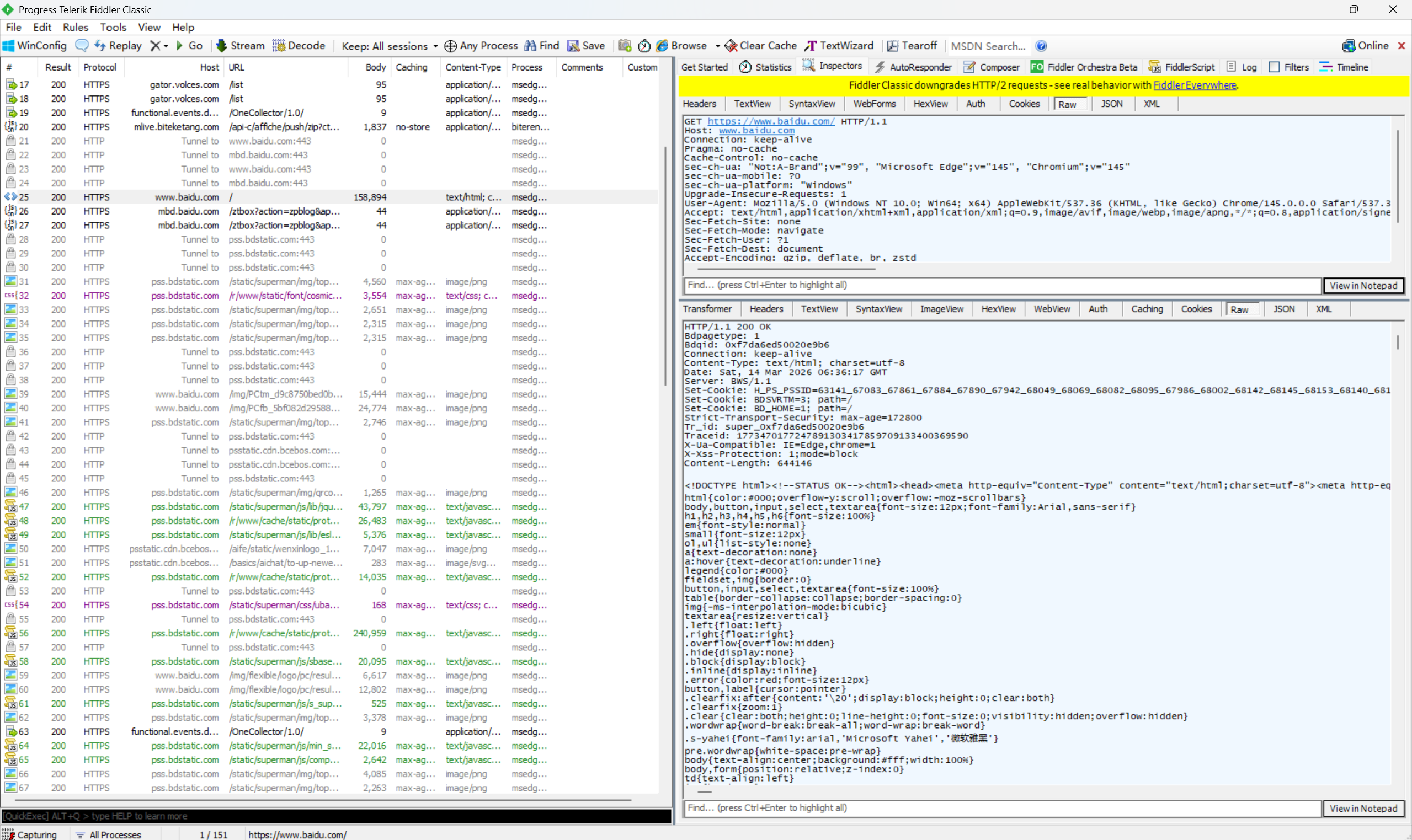
先看请求的详细情况.
HTTP请求格式:
1.首行(请求的第一行):方法+URL+版本
2.请求头(header),从第二行开始,往后若干行,直到遇见空行
包含请求的属性,冒号分割的键值对,每组属性之间使用\n分割;遇到空行表示header部分结束
3.空行.(请求头的结束标记)
4.请求正文(body),有的有,有的没有
HTTP响应格式:
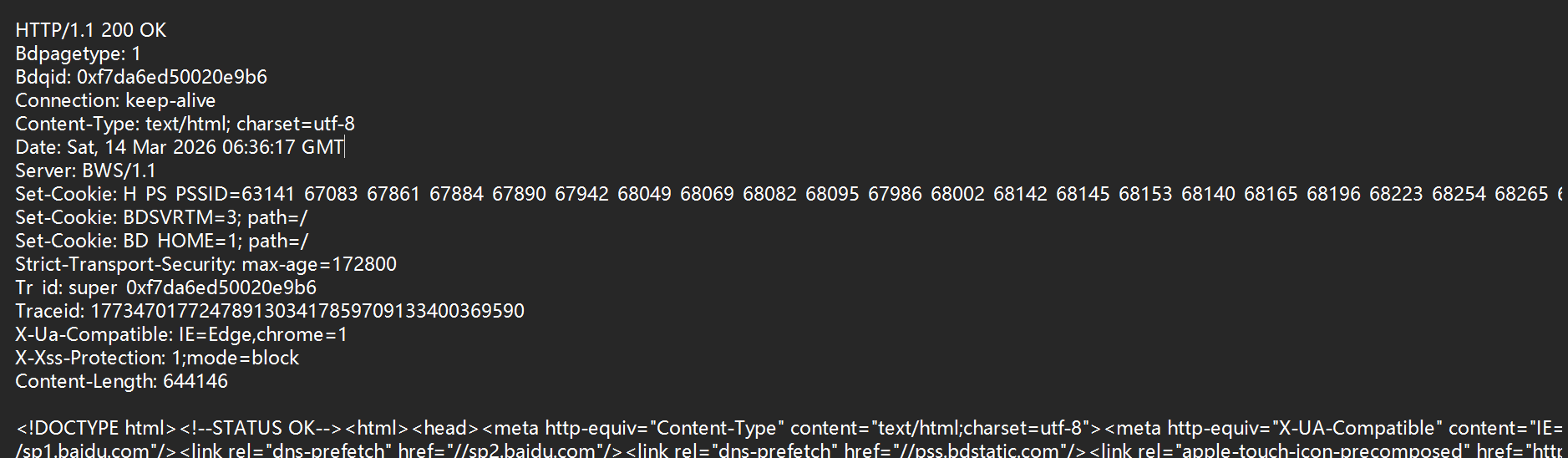
1.首行:版本号+状态码+状态码解释
2.响应头(header):
请求的属性,冒号分割键值对,每组属性用\n分割,遇到空行表示header部分结束.
3.空行(响应报头的结束标记)
4.正文(body):当前的正文就包含了网页的HTML,body存在,header中会存在一个content-length表示body的长度.
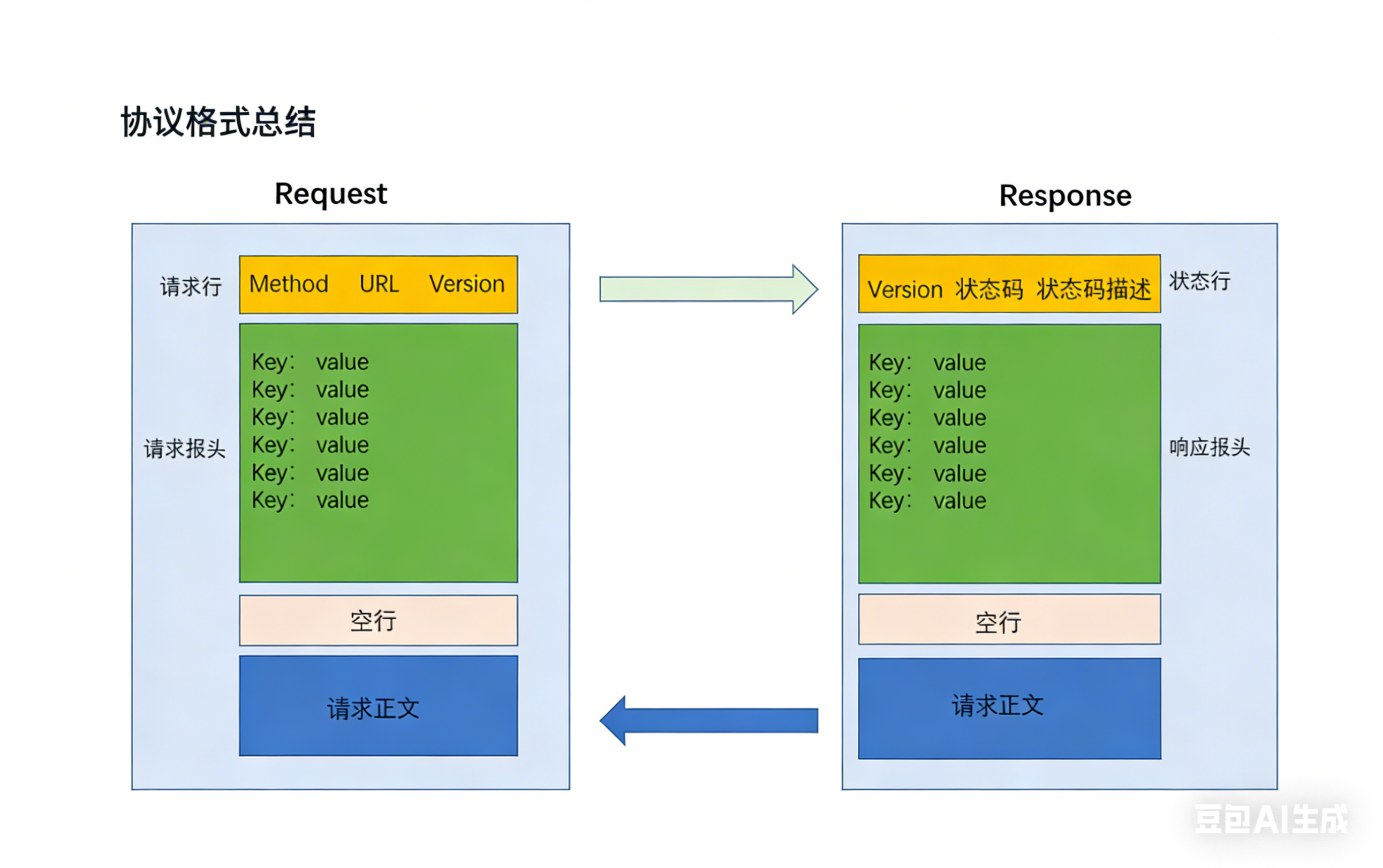
1.认识URL
平时我们俗称的 "网址" 其实就是说的 URL (Uniform Resource Locator 统一资源定位符).
互联网上的每个文件都有一个唯一的 URL,它包含的信息指出文件的位置以及浏览器应该怎么处理它.
URL 的详细规则由 因特网标准 RFC1738 进行了约定.

1.协议方案名:也就是说当前使用的是http还是https
2.登录信息:这个已经淘汰了,现在已经没有网站使用这种认证方式了.
3.服务器地址:服务器的IP地址,域名.
4.服务器端口号:服务器的端口号
5.带层次的文件路径:一个机器上的一个服务器程序,可能管理很多资源,这些资源可能是真实的文件,也可能是虚拟的,动态生成的资源(根据请求计算出来的响应).
6.查询字符串(query string):请求中的参数,通过参数进行进一步的解释说明,键值对格式,=分割键和值,通过&分割多个键值对.
7.片段标识符:标识网页的某个部分,实现"页面内跳转"功能,文档类网站会带有这个.
我们可以举个具体的例子:

java
https://cn.bing.com/search?
q=fiddler
&form=ANNTH1
&refig=69b50766456645c282b108a9647c691c
&pc=CNNDDB
&ucpdpc=UCPD
&adppc=EdgeStart我们使用去搜索fiddler,可以看到这边的URL.通过不同的查询字符串,可以让客户端给服务器传递多一些参数.
这些query string的键值对的含义,都是程序员自定义的.
一个完整的URL包含很多信息,主要关系4个部分:
(1)IP (2)端口 (3)路径 (4)查询字符串
在上面这个URL中,我们有IP地址,路径和查询字符串
但是我们看https://www.baidu.com/这个URL.好像只有IP地址,其他的东西好像都没有.
这是因为,在一个URL中,有些部分是可以被省略的.
如果没有端口号,浏览器会给一个默认值.
一次通信,需要,源IP,源端口,目的IP,目的端口.
源IP,源端口,浏览器客户端,端口号,系统会分配空闲的端口
目的IP,目的端口.URL中的端口,描述的是你访问的服务器的端口,而不是你浏览器客户端的端口.
URL中如果不写端口,浏览器会根据协议类型给出默认端口号(知名端口号).
https:// =>端口号给443. http:// =>端口号给80.
带层次的路径也能省略,省略之后就变成一个/
/表示访问"根目录",通常对应到一个网站的主页.
query string本来就不是必须的,都是属于程序员自行约定的.
片段标识符也可以省略.
再看一个例子:

java
https://www.baidu.com/s?
ie=utf8
&f=8
&rsv_bp=1
&rsv_idx=1
&tn=baidu
&wd=%E8%9B%8B%E7%B3%95
&fenlei=256
&rsv_pq=0xfc486b96000e3f4e
&rsv_t=27cd5FdjKYm3WebAYCcTSSamcHohiVEJKgq9PQqXtsteM30tXhH0ymeUvmit
&rqlang=en
&rsv_enter=1
&rsv_dl=tb
&rsv_sug3=8
&rsv_sug1=3
&rsv_sug7=101
&rsv_btype=i
&inputT=2795
&rsv_sug4=2795
&rsv_sug=1这里有人就会发现了,为什么在浏览器上面wd = 蛋糕,而复制之后却变成了乱码.
这是因为一个机制,url encode.
为什么需要URL encode这个机制呢?这是因为在URL中,本身有些字符是有特殊含义的,比如&,?,又或者URL中不能出现空格,所以为了解决这些情况,我们就会把&,空格这些特殊字符进行转换.
怎么转换呢?就是把特殊字符转换成%+十六进制ASCII码.如果是中文,就转换为UTF-8
我们去查蛋糕的utf-8的编码.
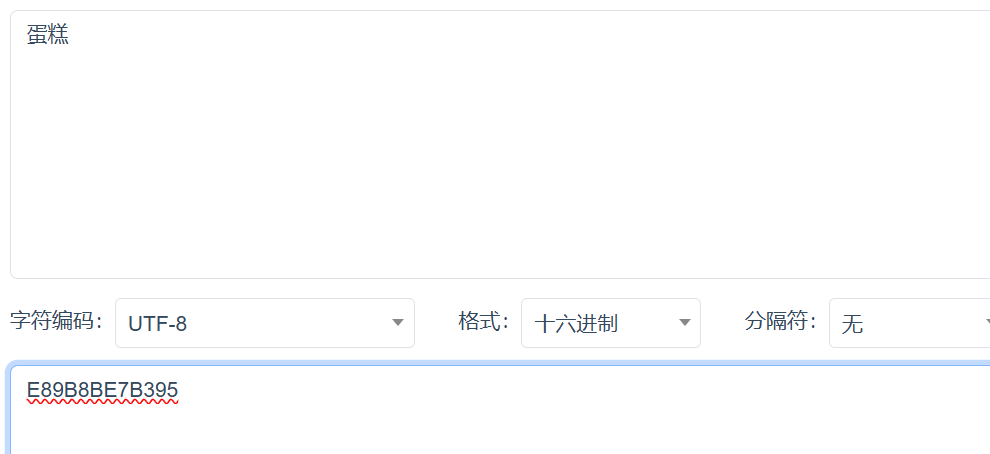
可以看到这里和wd=后面对应的就一样了.
2.HTTP的方法
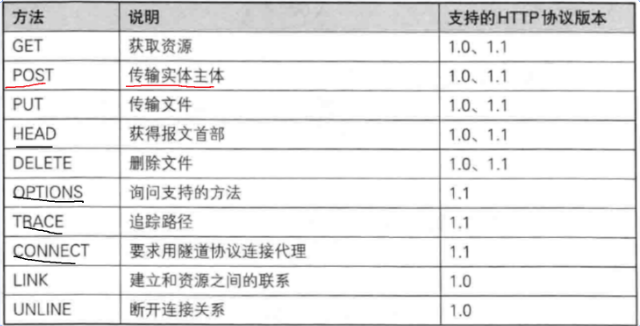
HTTP有很多方法,但是我们不需要全部学习,只需要学习几个就可以了,剩下的用的挺少.
GET:我想从服务器上获取某个资源.
POST:向服务器上传某个资源.
PUT:向服务器上传某个资源(文件)
DELETE:删除服务器的某个资源.
GET方法:
GET是在HTTP中最常见到的方法,很多操作,都会触发HTTP的GET请求.
(1)只在在浏览器地址栏输入URL,或者点击收藏夹
(2)在页面上点击链接跳转
(3)HTML简介加载其他资源的时候(CSS,JS,图片...)
(4)也可以通过js/java/c++/python代码手动构造GET请求
就像下面这个http请求,首行开头就是GET方法.
GET请求的特点:
1.GET请求一般没有body(正文部分),但是如果你通过代码构造一个GET请求,故意加上body部分也是可以的.
2.GET请求想要给服务器传递数据,往往是通过路径/query string来进行传递.
POST方法:
POST请求通常用于以下场景:
(1)登入的时候 
body提交的就是用户名和密码.
(2)上传资源和文件.

body部分就是我们上传的图片的内容.
通过HTTP body部分传输内容的时候,有时候会把二进制的内容,通过base64编码,编程文本内容.
body中是完全可以放二进制的内容的(压缩的结果),之所以用base64转成文本内容,还是因为当前传输的图片本身比较小,按照文本的方式去处理,服务器代码处理起来好实现.
什么是base64编码?简单来说,就是通过4个ASCII字符表示原来3个字节的二进制的数据.
body可以存二进制,但是URL的query string不能,如果想存的话,可以进行base64编码.
POST的基本特点:
1.带有body,通过body给服务器传递数据.
2.不太需要query string传递了,通常情况下是没有query string.
经典面试题:
GET和POST的区别:
核心结论:大部分情况下GET和POST其实是没有本质区别的.只是HTTP的两个不同的方法,
大部分情况下,使用GET和使用POST的场景是可以互换的.
主要区别:
(1)GET通常没有body,通过query string传递数据给服务器.POST通常有body,不需要通过query string传递数据,
(2)语义上的区别,GET表示"获取",POST表示"提交".
至于PUT方法,和POST方法大致是一样的,DELETE方法,和GET类似,一般不带有body,通过query string传输数据.
3.HTTP报头(header)
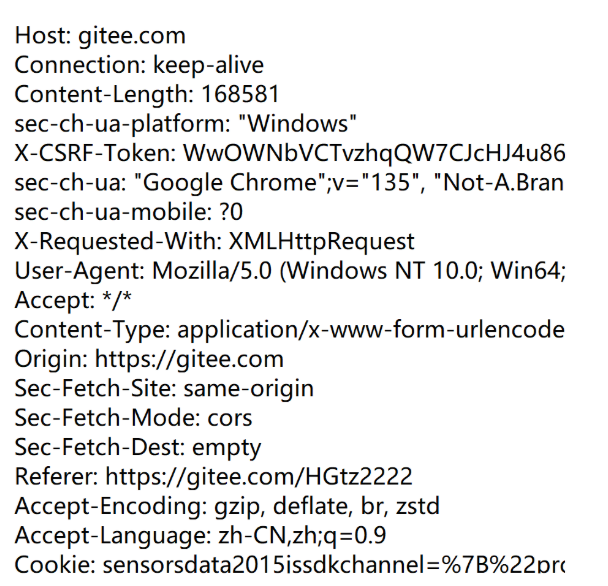
1.HOST:请求中的header,描述了访问的服务器IP和端口(可以省略)
2.Content-Length:描述了body的长度
这个属性就解决了粘包问题.
在我们之前学习TCP协议的时候就知道当多个TCP数据包到达服务器的时候,就会将这些数据包的载荷部分放在缓存区,这时候,就会出现粘包问题.
HTTP就是基于TCP的.如果一个TCP连接中传输多个HTTP请求/响应,我妈就需要让应用程序知道从哪到哪是一个完整的应用层数据包.
有了Conten-Length这个属性,我们就可以区分包和包的边界.
服务器怎么区分从哪到哪是一个完整的HTTP请求呢?
(1).如果没有body,直接读到空行即可.
(2).如果有body,header中会存在Content-Length这样的属性,取出Content-Length的值,找到空行,空行后面就是body的值,然后再读Content-length这么多字节就可以了
3.Content-Type:描述了body的数据格式.

服务器会根据这个Content-Type的值决定body怎么使用.
如果一个请求/响应中,有body,但是没有Content-Length或者Content-Type,就是一个非法的"请求/响应".
但是浏览器回去猜一个Content-Type,会根据body中的数据格式去猜.
这就叫"鲁棒性".
4.User-Agent:

这个属性的作用就是用来区分当前设备是PC端还是移动端.其他的一些作用已经过时了.
5.Referer
Referer这个请求头不是所有请求头油.在页面跳转的时候,我们可以根据Referer表示该页面从哪个网站跳转过来的.
一般这种属性是给服务器看的,比如投一个广告,可以看到这个广告是从哪个页面跳转过来的,从而计算广告收益.
6.Cookie:

Cookie的内容也是键值对,用;区分键值对,用=区分键和值.
我们知道有很多危险的网站,会对计算机的数据,个人隐私等等进行盗取.所以,浏览器为了把控安全,会限制一个网站的权限.
浏览器会禁止网站访问你的硬盘,业禁止网站调用你电脑上的其他应用程序.
但是如果一个网站希望在你电脑上面存储一些数据呢?这时候就需要用到Cookie了,
Cookie中的内容,就是服务器返回给浏览器的,浏览器会把Cookie的值保存到本地(硬盘上).
为了安全,不允许网站随意访问硬盘,而是只能按照"键值对"的方式去存储简单数据.
后续浏览器访问该网站的时候,Cookie中的数据通过HTTP请求报头带到服务器上面.
Cookie的使用场景:
通过cookie保存一些没那么重要但是有用的信息,比如"上次访问时间","保存用户的身份标识"

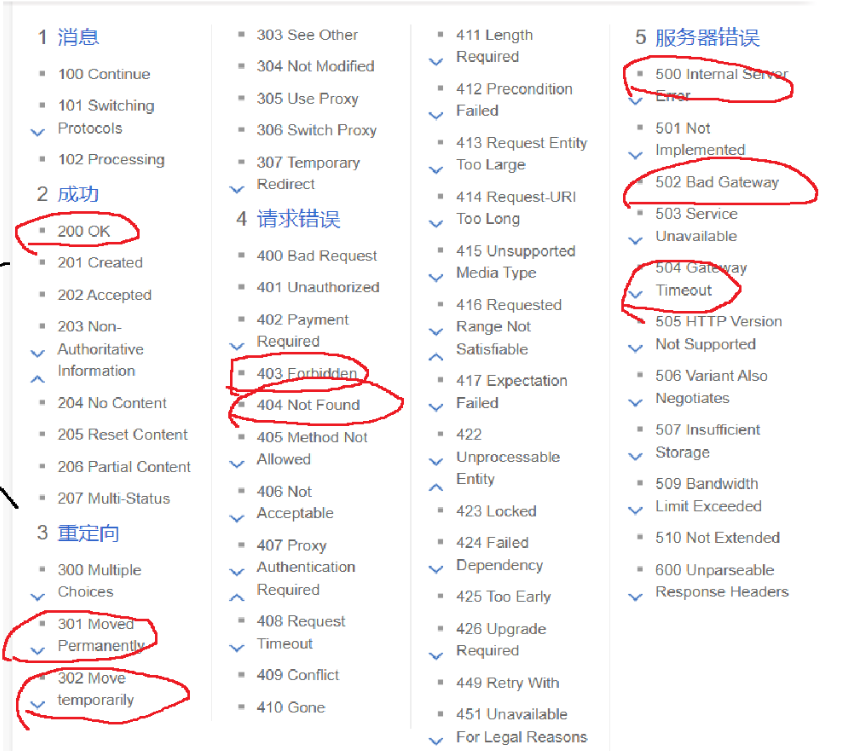
7.HTTP状态码:
我们不需要全部了解,只需要了解关键的,直到不同数字开头代表的不同含义即可.
200 OK ->表示访问成功,HTTP层面的成功,不代表业务层面的成功.
2开头的都算成功,但是成功和成功之间也有差异.
404 Not Found ->表示客户端要访问的资源不存在. URL中的层次结构路径就是资源.
403 Forbidden ->表示访问被拒绝(没有权限).
4开头的都表示"客户端出错了",用户打开的方式不对.
500 intermal Server Error ->表示服务器抛出异常,挂了.
502 Bad Gateway ,504Gateway Timeout ->表示网关有问题.
5开头都表示"服务器出错",需要程序员修复.
301 Moved Permanently 302 Move Temporarily ->重定向,浏览器会做缓存,下次访问旧地址,浏览器会自动访问新地址.有些重定向是临时的,有些是永久的.
3开头都表示重定向,3开头的响应一般不需要body,但是在header中需要location,表示接下来要跳转到哪个页面.
二.HTTPS
HTTPS,相当于在HTTP的基础上,引入加密层(SSL/TSL)
HTTPS = HTTP +SSL/TSL
主要就是加密,通过引入对称加密,非对称加密,证书等手段进行加密.
什么是加密?
加密就是把 明文(要传输的信息)进行一系列变换,生成 密文。
解密就是把 密文 再进行一系列变换,还原成 明文。
密钥,就是在加密和解密过程中需要的数据.
加密的方式有很多,但整体可以分为两种:对称加密 和非对称加密
对称加密:
所谓对称加密,就是通过同一个"密钥",把明文加密成密文,再把密文解密成明文.
引入对称加密之后,即使数据被截获,但是由于黑客不知道密钥是啥,因此也无法进行解密.
但是我们要知道,服务器同一时刻是给很多客户提供服务的,这么多客户端,每个人的密钥都是不同的(相同的话,太容易扩散,黑客很容易就能拿到).因此服务器就需要维护每个客户端和每个密钥之间的关联关系,这个是很麻烦的.
比较理想的做法就是在客户端和服务器建立连接的时候,就协商好这次用的密钥是啥.
但是如果把密钥明文传输,这样黑客也就能拿到密钥了,这样的加密操作就相当于形同虚设了.
非对称加密:
为了解决这个问题,我们引入了非对称加密.
非对称加密需要用到两个密钥,一个叫"公钥",另一个叫"私钥"
公钥和私钥是配对的,可以通过公钥把密文解密成明文,通过私钥把明文加密成密文,也可以反过来使用.
客户端在本地生成对称密钥,通过公钥加密,发送给服务器。
由于中间的网络设备没有私钥,即使截获了数据,也无法还原出内部的原文,也就无法获取到对称密钥。
服务器通过私钥解密,还原出客户端发送的对称密钥,并且使用这个对称密钥加密给客户端返回的响应数据。
后续客户端和服务器的通信都只用对称加密即可。由于该密钥只有客户端和服务器两个主机知道,其他主机 / 设备不知道密钥,即使截获数据也没有意义。
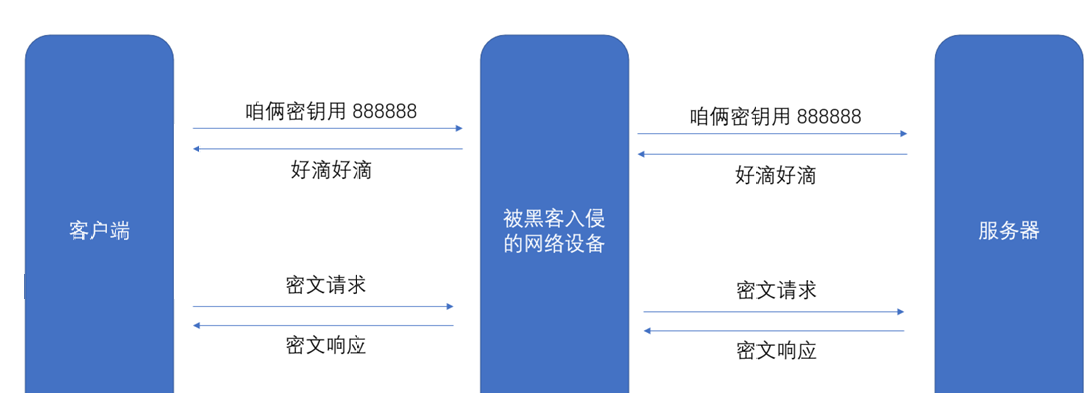
中间人攻击:
黑客可以使用中间人攻击,获取到对称密钥.
服务器具有非对称加密算法的公钥 S,私钥 S'
中间人具有非对称加密算法的公钥 M,私钥 M'
客户端向服务器发起请求,服务器明文传送公钥 S 给客户端
中间人劫持数据报文,提取公钥 S 并保存好,然后将被劫持报文中的公钥 S 替换成为自己的公钥 M,并将伪造报文发给客户端
客户端收到报文,提取公钥 M(自己当然不知道公钥被更换过了),自己形成对称秘钥 X,用公钥 M 加密 X,形成报文发送给服务器
中间人劫持后,直接用自己的私钥 M' 进行解密,得到通信秘钥 X,再用曾经保存的服务端公钥 S 加密后,将报文推送给服务器
服务器拿到报文,用自己的私钥 S' 解密,得到通信秘钥 X
双方开始采用 X 进行对称加密,进行通信。但是一切都在中间人的掌握中,劫持数据,进行窃听甚至修改,都是可以的
引入证书:
为了解决中间人攻击,我们可以引入证书.
服务端在使用 HTTPS 前,需要向 CA 机构申领一份数字证书,数字证书里含有证书申请者信息、公钥信息等。服务器把证书传输给浏览器,浏览器从证书里获取公钥就行了,证书就如身份证,证明该公钥的权威性。
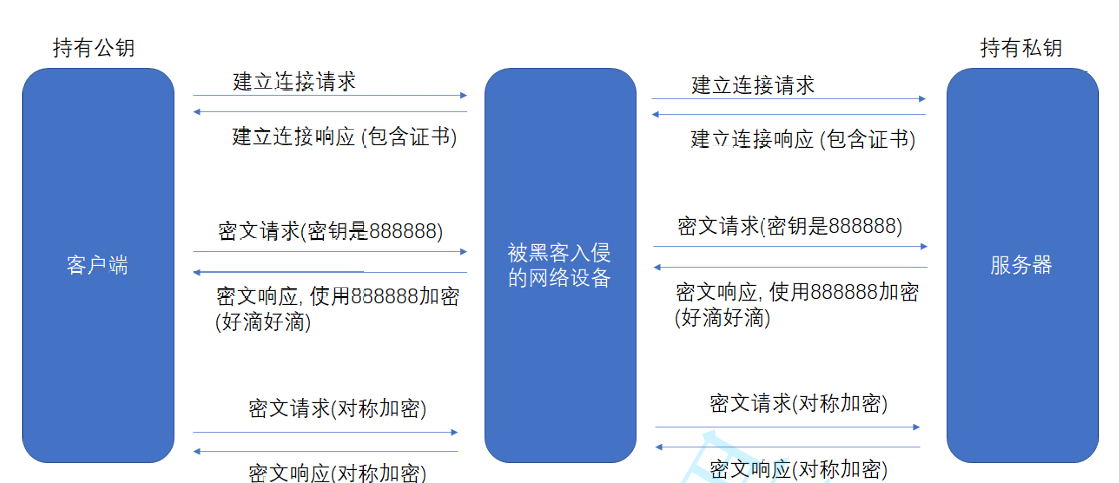
当客户端获取到这个证书之后,会对证书进行校验(防止证书是伪造的)。
判定证书的有效期是否过期
判定证书的发布机构是否受信任(操作系统中已内置的受信任的证书发布机构)。
验证证书是否被篡改:从系统中拿到该证书发布机构的公钥,对签名解密,得到一个 hash 值(称为数据摘要),设为 hash1。然后计算整个证书的 hash 值,设为 hash2。对比 hash1 和 hash2 是否相等。如果相等,则说明证书是没有被篡改过的。
JavaEE初阶的内容就到此为止了,后面会带大家了解JavaEE进阶的内容.