前言
我又做了一个新项目: 里面涉及到关于聊天啊, 通信那种内容吧, 于是抽出几天利用ai来速通一下Netty( 写的可能不好, 但我尽可能写全 )
这里写目录标题
- 前言
-
- [首先来看看什么是NIO呢? 为啥学Netty就要学NIO呢?](#首先来看看什么是NIO呢? 为啥学Netty就要学NIO呢?)
- NIO基础
-
- NIO三大组件:
-
- [Channel & Buffer](#Channel & Buffer)
- [2.selector 设计:](#2.selector 设计:)
- 三的组件的使用
-
- ByteBuffer(集装箱:读写数据的缓冲区)
- Channel(通道:数据传输的高速公路)
- [Selector(管家:管理所有 Channel)](#Selector(管家:管理所有 Channel))
- [NIO 主从多线程 Reactor 模型](#NIO 主从多线程 Reactor 模型)
首先来看看什么是NIO呢? 为啥学Netty就要学NIO呢?
一、先对比:平时写的 IO 代码 vs NIO 文件操作
| IO操作 | NIO 文件操作 | |
|---|---|---|
| 操作对象 | FileOutputStream、BufferedWriter 等流 | FileChannel + ByteBuffer 通道 + 缓冲区 |
| 读写方式 | 「流模式」:一字节 / 一行地读,单向流动 | 「块模式」:整段数据读进缓冲区,可双向操作切换模式读写 |
| 性能 | 频繁上下文切换,大文件 / 高并发下慢 | 减少拷贝次数,大文件传输效率高 |
| 代码风格 | 流式调用,逐行写(比如 bw.write()) | 先写缓冲区,再刷到通道(buffer.flip()+channel.write()) |
简单来说:
- 你写的 BIO 是「小文件 / 低并发」场景的常规写法,简单易上手,但性能上限低;
- NIO 的 FileChannel 是「大文件 / 高并发」场景的优化方案,核心是缓冲区 + 通道,减少数据拷贝;
这里再补充一个概念( 后面有用到 ):
阻塞 BIO vs 非阻塞 NIO
BIO(阻塞 IO):
- 一个线程只能管一个连接
- 调用 accept()、read() 会卡住线程,死等
- 连接一多,线程爆炸,服务器扛不住
NIO(非阻塞 IO):
- 一个线程可以管理成千上万个连接
- accept()、read() 不会卡住线程
- 没有事件就去干别的,有事件再处理
- 这就是高并发通信的基础(聊天、推送、网游都用它)
一句话:非阻塞 = 不傻等,一个线程管理一堆连接。
二、NIO 和 Netty 的关系:Netty 是 NIO 的豪华升级版🫣
为什么所有 Netty 教程都先学 NIO?因为 Netty 本质是对 JDK NIO 的「封装 + 优化 + 增强」,没有 NIO 基础,学 Netty 就是「空中楼阁」。
NIO基础
NIO三大组件:
NIO的三大组件分为: Selector, ByteBuffer 和 Channel , 因为NIO主要是由Selector控制着channel将数据读入写入buffer. 所以这仨分开来看:
Channel & Buffer
channel 有一点类似于stream, 它类似一个数据通道( 既可以读数据也可以写数据 ) 将数据弄到buffer( 这个有点像缓存 )里

常见的Channel:
- SocketChannel
- FileChannel
- ServerSocketChannel
- DatagramChannel
这里需要特别注意一个关键点:
并不是所有 Channel 都支持非阻塞模式。
- FileChannel 只能运行在阻塞模式,不能切换非阻塞;
- 而 SocketChannel、ServerSocketChannel 这类网络通信 Channel,支持非阻塞模式。
这也是为什么网络 NIO 必须使用 ServerSocketChannel + SocketChannel ------
只有支持非阻塞的 Channel,才能注册到 Selector 中,实现一个线程管理成千上万个连接。
换句话说:
Selector 只认非阻塞的 Channel,阻塞 Channel 无法注册到 Selector!
所以后面我们写 NIO 网络代码时,一定会加上这行关键代码:
channel.configureBlocking(false);
这是使用 Selector 的前提,也是实现高并发通信的基础。
2.selector 设计:
selector的作用就是配合一个线程来管理多个channel, 获取这些channel上发生的事件( channel必须工作在非阻塞模式下 ), 适合连接数多但流量低的场景.
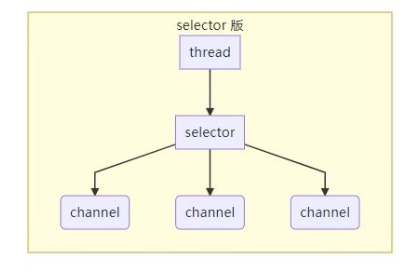
三的组件的使用
ByteBuffer(集装箱:读写数据的缓冲区)

ByteBuffer 正确使用姿势
- 向 buffer 写入数据,例如调用 channel.read(buffer)
- 调用 flip() 切换至读模式
- 从 buffer 读取数据,例如调用 buffer.get()
- 调用 clear() 或 compact() 切换至写模式
java
public class TestByteBuffer {
public static void main(String[] args) {
// FileChannel
// 1. 输入输出流,2. RandomAccessFile
try (FileChannel channel = new FileInputStream("data.txt").getChannel()) {
// 准备缓冲区
ByteBuffer buffer = ByteBuffer.allocate(10);
while(true) {
// 从 channel 读取数据,向 buffer 写入
int len = channel.read(buffer);
log.debug("读取到的字节数 {}", len);
if(len == -1) { // 没有内容了
break;
}
// 打印 buffer 的内容
buffer.flip(); // 切换至读模式
while(buffer.hasRemaining()) { // 是否还有剩余未读数据
byte b = buffer.get();
log.debug("实际字节 {} ", (char) b);
}
buffer.clear(); // 切换为写模式
}
} catch (IOException e) {
}
}
}🙌🙌🙌ByteBuffer 的工作原理可简单总结为:
三个核心属性:
- capacity(容量):缓冲区总大小,固定不变。
- position(位置):当前读写指针,写入时指向下一个可写位置,读取时指向下一个可读位置。
- limit(限制):当前操作的上限,写模式下等于 capacity,读模式下等于已写入数据的末尾。
✅ 简单说:"写满翻转读,读完清空再写" ------ 通过 position 和 limit 控制读写边界,flip/clear 实现模式切换,高效复用缓冲区。
两种模式切换:
写模式 → 读模式:调用 flip(),将 position 重置为 0,limit 设为之前 position 的值(即有效数据长度)。
读模式 → 写模式:调用 clear() 或 compact(),恢复 position=0、limit=capacity,准备重新写入。
工作流程:
写入数据 → flip() 切换读模式 → 读取数据 → clear()/compact() 切换回写模式 → 循环重复。
Channel(通道:数据传输的高速公路)

🚀 Channel 正确使用姿势(非阻塞模式)
- 创建并配置通道为非阻塞
- 调用 ServerSocketChannel.open() 创建服务通道。
- 立即调用 configureBlocking(false) 设置为非阻塞模式。
- 绑定监听端口
- 调用 bind(new InetSocketAddress(port)) 启动监听。
此时通道开始接受连接请求,但不会阻塞等待。
- 非阻塞接受连接 & 管理客户端通道
- 调用 ssc.accept() 获取新连接:
- 有连接 → 返回 SocketChannel
- 无连接 → 返回 null,线程不阻塞,继续执行
- 对新获得的 SocketChannel 也调用 configureBlocking(false)
将其加入集合(如 List)统一管理。
- 非阻塞读写数据 + 条件判断
- 遍历所有已注册的 SocketChannel
- 调用 channel.read(buffer):
- 有数据 → 返回字节数 > 0 → 处理数据(flip → read → clear)
- 无数据 → 返回 0 → 跳过,不阻塞
- 客户端断开 → 返回 -1 → 应移除该 channel(本例未处理,实际需补充)
- 写操作同理:channel.write(buffer) 也可能只写部分,需循环直到写完或返回 0。
java
// 创建 ByteBuffer
ByteBuffer buffer = ByteBuffer.allocate(16);
// 1. 创建服务器通道
ServerSocketChannel ssc = ServerSocketChannel.open();
ssc.configureBlocking(false); // 设置为非阻塞模式
// 2. 绑定监听端口
ssc.bind(new InetSocketAddress(8080));
// 3. 连接集合
List<SocketChannel> channels = new ArrayList<>();
while (true) {
// 4. accept 建立与客户端连接(非阻塞)
log.debug("connecting...");
SocketChannel sc = ssc.accept(); // 非阻塞:无连接时返回 null,线程继续运行
if (sc != null) {
log.debug("connected... {}", sc);
sc.configureBlocking(false); // 客户端通道也设为非阻塞
channels.add(sc);
}
// 5. 遍历所有已连接的客户端通道,读取数据(非阻塞)
for (SocketChannel channel : channels) {
log.debug("before read... {}", channel);
int read = channel.read(buffer); // 非阻塞:无数据时返回 0,不卡住
if (read > 0) { // 只有读到数据才处理
buffer.flip(); // 切换为读模式
debugRead(buffer); // 打印内容
buffer.clear(); // 清空,准备下次写入
log.debug("after read...{}", channel);
}
}
}Selector(管家:管理所有 Channel)

SelectionKey(凭证:Channel 和 Selector 的绑定关系)

🚀 Selector + Channel 正确使用姿势(多路复用非阻塞模式)
- 创建 Selector 并注册通道
- 调用 Selector.open() 创建选择器。
- 创建 ServerSocketChannel → 设非阻塞 → 绑定端口。
- 调用 channel.register(selector, OP_ACCEPT) 将服务通道注册到 Selector,监听"接受连接"事件。
- 阻塞等待事件发生
- 调用 selector.select() ------ 线程在此阻塞,直到有客户端连接或有数据可读。
- 一旦有事件,方法返回,线程恢复执行。
- 遍历并处理就绪事件
- 调用 selector.selectedKeys() 获取所有就绪的 SelectionKey。
- 遍历每个 SelectionKey:
- 判断事件类型:isAcceptable() / isReadable() / isWritable()
- 根据类型执行对应操作:
- accept() → 获取新 SocketChannel → 设非阻塞 → 注册 OP_READ
- readable() → 从 channel.read(buffer) 读取数据
- 清理已处理事件 & 循环继续
- 必须调用 iter.remove() 移除当前处理过的 SelectionKey,否则下次循环会重复处理!
- (可选)调用 key.cancel() 标记取消,但不如 remove() 直接有效。
- 回到步骤 2,继续 select() 等待下一个事件。
java
// 1. 创建 Selector
Selector selector = Selector.open();
// 2. 创建 ServerSocketChannel 并注册到 Selector
ServerSocketChannel ssc = ServerSocketChannel.open();
ssc.configureBlocking(false); // 必须设为非阻塞
ssc.bind(new InetSocketAddress(8080));
// 注册 accept 事件到 selector
SelectionKey ssKey = ssc.register(selector, SelectionKey.OP_ACCEPT);
log.debug("register key: {}", ssKey);
while (true) {
// 3. select() 阻塞等待事件发生(有连接或数据才唤醒)
selector.select();
// 4. 获取所有已就绪的 SelectionKey
Set<SelectionKey> selectedKeys = selector.selectedKeys();
Iterator<SelectionKey> iter = selectedKeys.iterator();
while (iter.hasNext()) {
SelectionKey key = iter.next();
log.debug("key: {}", key);
// 5. 根据事件类型处理
if (key.isAcceptable()) { // 如果是 accept 事件
ServerSocketChannel channel = (ServerSocketChannel) key.channel();
SocketChannel sc = channel.accept(); // 接受新连接
sc.configureBlocking(false); // 新通道也必须非阻塞
// 注册 read 事件到 selector
SelectionKey scKey = sc.register(selector, SelectionKey.OP_READ);
log.debug("{} registered for READ", sc);
} else if (key.isReadable()) { // 如果是 read 事件
SelectableChannel channel = key.channel(); // 拿到触发事件的 channel
// TODO: 这里应该调用 channel.read(buffer) 处理数据
// 实际项目中需配合 ByteBuffer 使用
}
// ⚠️ 重要:手动移除已处理的 key,避免重复处理
iter.remove();
// 或者:key.cancel(); (但推荐用 iter.remove())
}
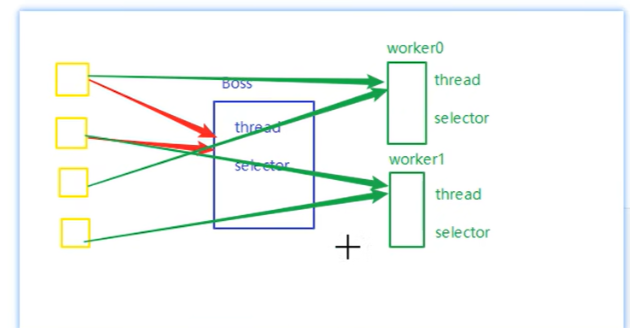
}NIO 主从多线程 Reactor 模型
咱们先把这个模型的每个角色搞懂, 再来看看为什么要用这个模型:
Boss(主 Reactor):
- 只有 1 个线程 + 1 个 Selector
- 只负责接收新连接
- 不处理读写,只把新连接分配给 Worker
Worker(从 Reactor):
- 图里有 worker0、worker1 两个,每个都是 1 个线程 + 1 个 Selector
- 负责已建立连接的读写事件
- 多个 Worker 可以并行处理,充分利用多核 CPU
🔍 为啥要这么设计?
1. 职责分离:
- Boss 只干 "接通客户端"(accept),不处理读写,避免新连接等待
- Worker 只干 "服务"(read/write),多个 Worker 并行处理,把多核 CPU 用满
2. 避免单 Selector 瓶颈:
- 如果只用 1 个 Selector 管所有连接,高并发下 Selector 遍历事件会成为瓶颈
- 拆成多个 Selector,每个管一部分连接,并行处理,吞吐量更高
3. 负载均衡:
- 新连接来了,Boss 会把它均匀分配到不同 Worker 上(比如图里用 AtomicInteger 做轮询)
- 避免某个 Worker 压力过大,其他空闲
小白啊!!!写的不好轻喷啊🤯如果觉得写的不好,点个赞吧🤪(批评是我写作的动力)
...。。。。。。。。。。。...
...。。。。。。。。。。。...