TL;DR
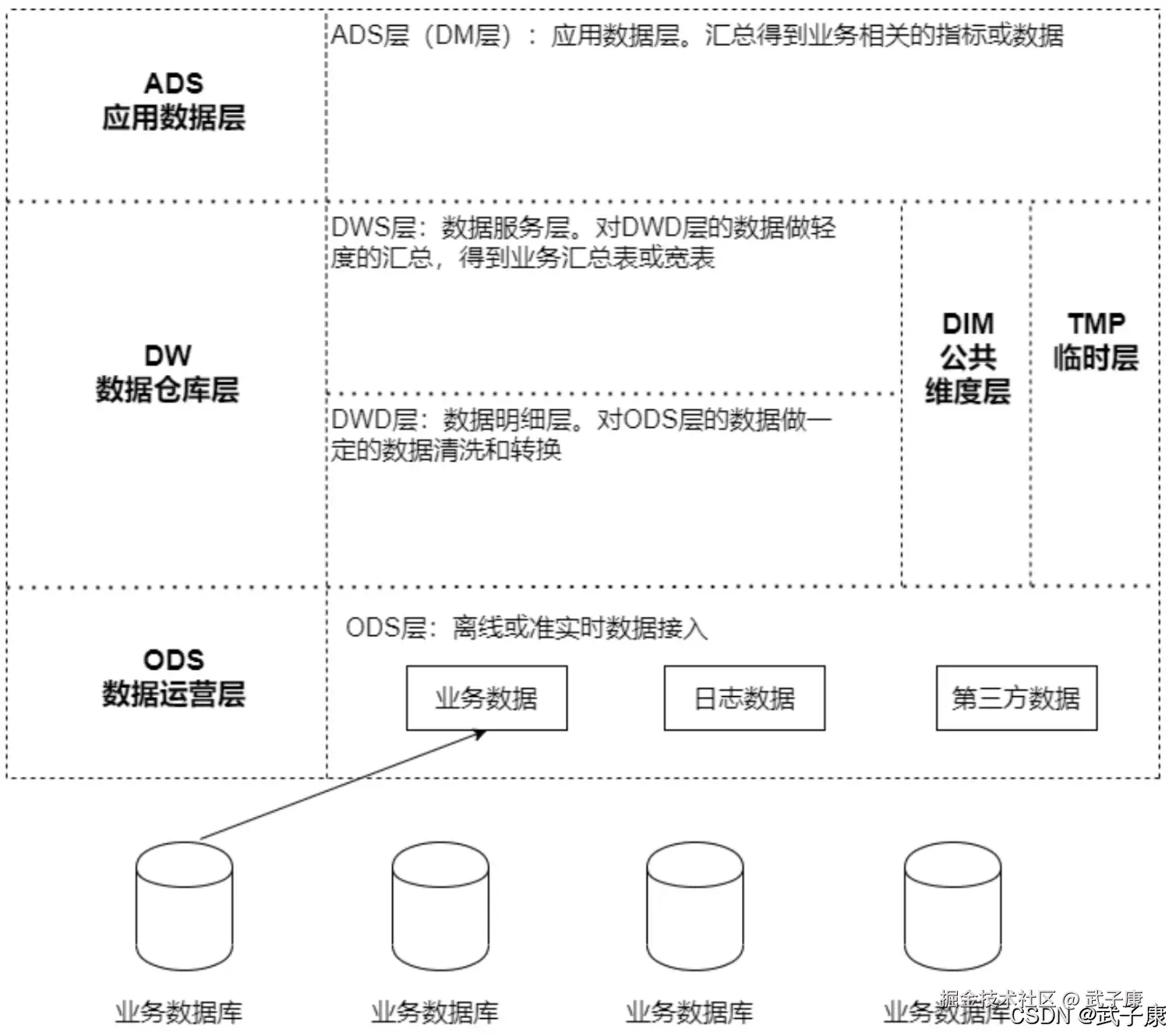
- 场景:基于 Hive 离线数仓,对订单按全国、大区、城市及一级/二级商品分类做 ADS 汇总统计。
- 结论:一笔订单可能对应多商品多分类,订单数必须用 count(distinct orderid) 控制重复统计,金额与件数按明细聚合。
- 产出:给出 ADS 建表、装载脚本、统计口径说明,以及与 Airflow 调度衔接的工程化落地框架。

ADS层开发
需求:计算当天
- 全国所有订单信息
- 全国、一级商品分类订单信息
- 全国、二级商品分类订单信息
- 大区所有订单信息
- 大区、一级商品分类订单信息
- 大区、二级商品分类订单信息
- 城市所有订单信息
- 城市、一级商品分类订单信息
- 城市、二级商品分类订单信息
用到的表:
- dws.dws_trade_orders_w
ADS层建表
sql
-- ADS层订单分析表
DROP TABLE IF EXISTS ads.ads_trade_order_analysis;
create table if not exists ads.ads_trade_order_analysis(
areatype string, -- 区域范围:区域类型(全国、大
区、城市)
regionname string, -- 区域名称
cityname string, -- 城市名称
categorytype string, -- 商品分类类型(一级、二级)
category1 string, -- 商品一级分类名称
category2 string, -- 商品二级分类名称
totalcount bigint, -- 订单数量
total_productnum bigint, -- 商品数量
totalmoney double -- 支付金额
)
partitioned by (dt string)
row format delimited fields terminated by ',';ADS层加载数据
编写一个脚本加载数据
shell
vim ads_load_trade_order_analysis.sh1笔订单,有多个商品,多个商品有不同的分类,这会导致一笔订单有多个分类,它们是分别统计的:
shell
#!/bin/bash
source /etc/profile
if [ -n "$1" ]
then
do_date=$1
else
do_date=`date -d "-1 day" +%F`
fi
sql="
with mid_orders as (
select regionname,
cityname,
firstname category1,
secondname category2,
count(distinct orderid) as totalcount,
sum(productsnum) as total_productnum,
sum(paymoney) as totalmoney
from dws.dws_trade_orders_w
where dt='$do_date'
group by regionname, cityname, firstname, secondname
)
insert overwrite table ads.ads_trade_order_analysis
partition(dt='$do_date')
select '全国' as areatype,
'' as regionname,
'' as cityname,
'' as categorytype,
'' as category1,
'' as category2,
sum(totalcount),
sum(total_productnum),
sum(totalmoney)
from mid_orders
union all
select '全国' as areatype,
'' as regionname,
'' as cityname,
'一级' as categorytype,
category1,
'' as category2,
sum(totalcount),
sum(total_productnum),
sum(totalmoney)
from mid_orders
group by category1
union all
select '全国' as areatype,
'' as regionname,
'' as cityname,
'二级' as categorytype,
'' as category1,
category2,
sum(totalcount),
sum(total_productnum),
sum(totalmoney)
from mid_orders
group by category2
union all
select '大区' as areatype,
regionname,
'' as cityname,
'' as categorytype,
'' as category1,
'' as category2,
sum(totalcount),
sum(total_productnum),
sum(totalmoney)
from mid_orders
group by regionname
union all
select '大区' as areatype,
regionname,
'' as cityname,
'一级' as categorytype,
category1,
'' as category2,
sum(totalcount),
sum(total_productnum),
sum(totalmoney)
from mid_orders
group by regionname, category1
union all
select '大区' as areatype,
regionname,
'' as cityname,
'二级' as categorytype,
'' as category1,
category2,
sum(totalcount),
sum(total_productnum),
sum(totalmoney)
from mid_orders
group by regionname, category2
union all
select '城市' as areatype,
'' as regionname,
cityname,
'' as categorytype,
'' as category1,
'' as category2,
sum(totalcount),
sum(total_productnum),
sum(totalmoney)
from mid_orders
group by cityname
union all
select '城市' as areatype,
'' as regionname,
cityname,
'一级' as categorytype,
category1,
'' as category2,
sum(totalcount),
sum(total_productnum),
sum(totalmoney)
from mid_orders
group by cityname, category1
union all
select '城市' as areatype,
'' as regionname,
cityname,
'二级' as categorytype,
'' as category1,
category2,
sum(totalcount),
sum(total_productnum),
sum(totalmoney)
from mid_orders
group by cityname, category2;
"
hive -e "$sql"备注:由于在 dws.dws_trade_orders_w中,一笔订单可能有多条记录,所有在统计订单数量的时候用count(distinct orderid)
最后小结
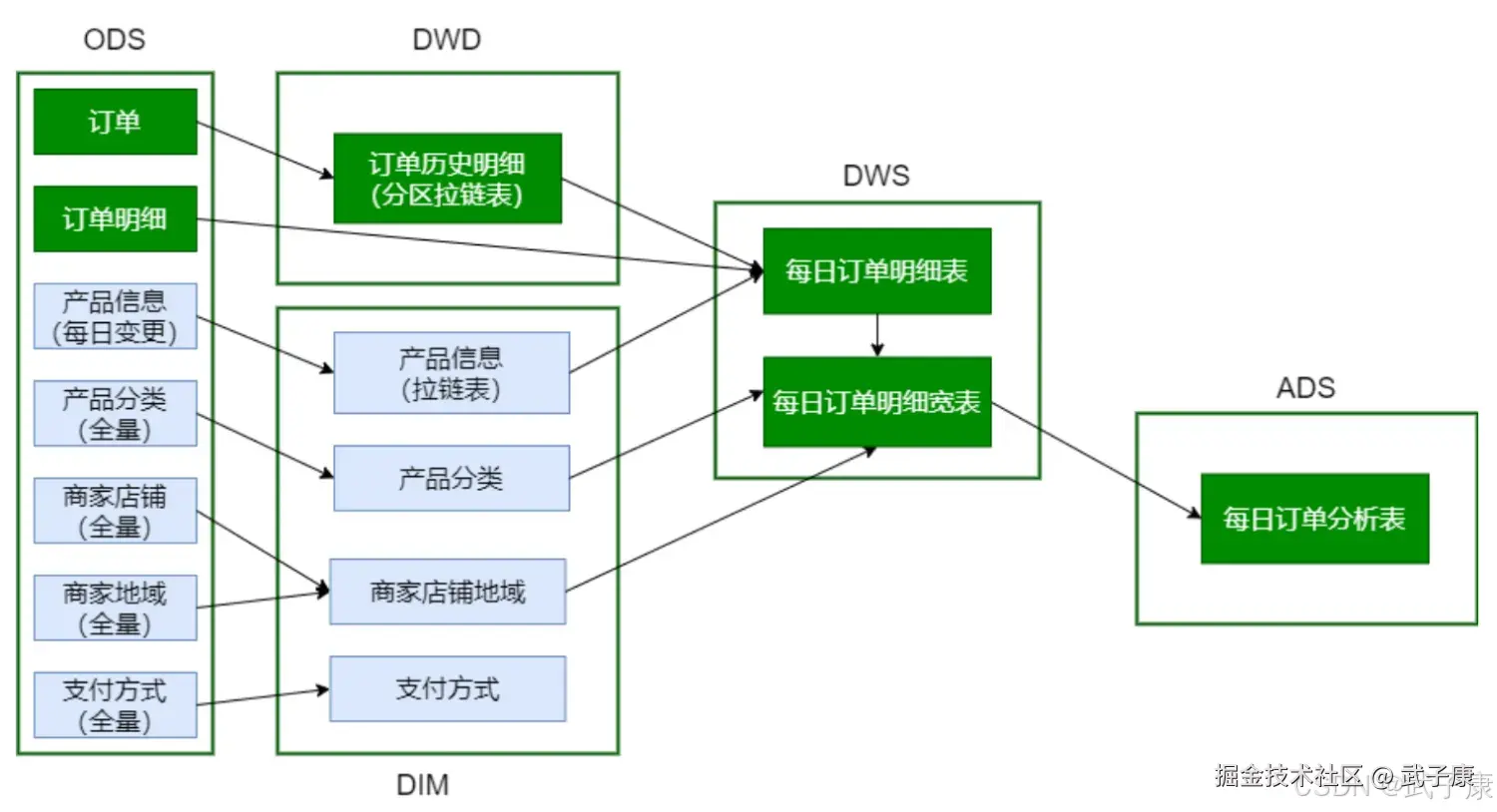
shell
# 加载ODS数据(含DataX迁移数据)
/data/lagoudw/script/trade/ods_load_trade.sh
# 加载DIM层数据
/data/lagoudw/script/trade/dim_load_product_cat.sh
/data/lagoudw/script/trade/dim_load_shop_org.sh
/data/lagoudw/script/trade/dim_load_payment.sh
/data/lagoudw/script/trade/dim_load_product_info.sh
# 加载DWD层数据
/data/lagoudw/script/trade/dwd_load_trade_orders.sh
# 加载DWS层数据
/data/lagoudw/script/trade/dws_load_trade_orders.sh
# 加载ADS层数据
/data/lagoudw/script/trade/ads_load_trade_order_analysis.shAirflow简介
Airflow是Airbnb开源的一个用Python编写的调度工具,与2014年启动,2015年春季开源,2016年加入Apache软件基金会的孵化计划。 Airflow将一个工作流制定为一组任务的有向无环图(DAG),并指派到一组计算节点上,根据相互之间的依赖关系,有序执行。 Airflow的优势如下:
- 灵活易用,Airflow是Python编写的,工作流的定义也使用Python编写
- 功能强大,支持多种不同类型的作业,可自定义不同类型的作业,如Shell、Python、MySQL、Oracle、Hive等
- 简洁优雅,作业的定义简单明了
- 易扩展,提供各种基类供扩展,有多种执行器可供选择
Apache Airflow 是一个开源的任务调度和工作流管理平台,主要用于开发、调试和监控数据管道。Airflow 通过使用 Python 脚本定义任务和依赖关系,帮助用户以编程的方式构建动态的、可视化的工作流。
体系架构
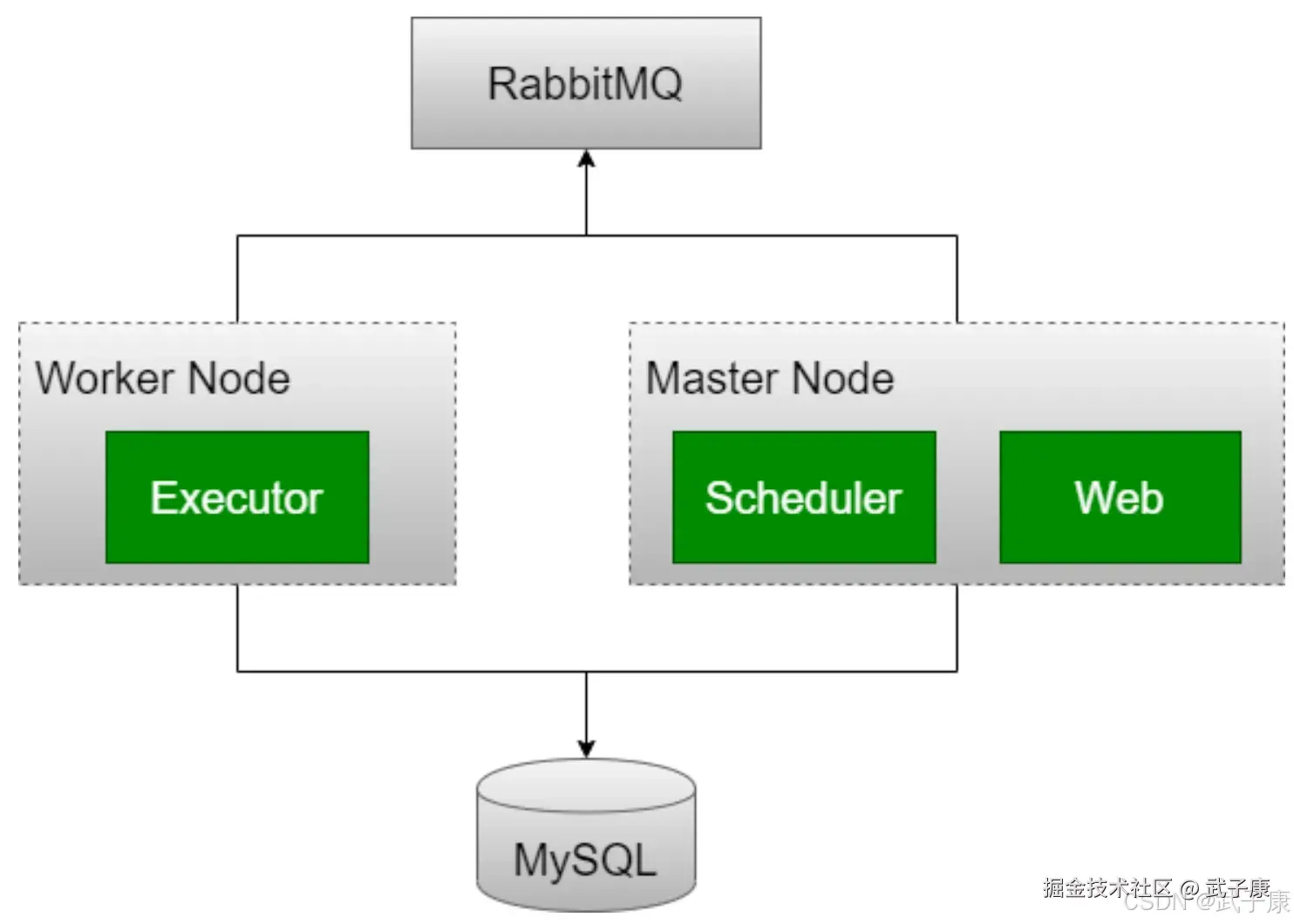
- WebServer守护进程,接受HTTP请求,通过Python Flask Web应用程序与Airflow进行交互,WebServer提供功能的功能包括:中止、恢复、触发任务,监控正在运行的任务,断点续跑任务,查询任务的状态,日志等详细信息。
- Scheduler守护进程,周期性地轮询任务的调度计算,以确定是否触发任务执行
- Worker守护进程,Worker负责启动机器上的Executor来执行任务,使用CeleryExecutor后可以在多个机器人部署Worker服务
核心特性
基于代码的工作流定义
工作流以 Python 脚本定义,称为 DAG(Directed Acyclic Graph,有向无环图)。每个 DAG 包括一组任务及其依赖关系。 支持参数化和动态生成 DAG,适合复杂工作流场景。
任务调度
支持灵活的任务调度,用户可以通过时间间隔、特定时间点等方式定义任务的运行周期。 调度器自动根据依赖关系按顺序触发任务执行。
任务分布式执行
任务可以分布式运行,支持横向扩展,能够通过多个 Worker 节点提高任务处理能力。
可视化界面
Airflow 提供了功能强大的 Web UI,用于查看 DAG 的运行状态、日志以及历史记录。 图形化展示 DAG 结构,方便直观地了解工作流执行情况。
高可扩展性
支持通过插件机制扩展功能,例如自定义操作符(Operator)或 Hook。 内置多种操作符和连接器(如 BashOperator、PythonOperator、MySqlOperator 等)用于集成各种任务和外部系统。
依赖管理
Airflow 支持基于任务之间的依赖关系进行调度。用户可以显式地定义任务顺序和依赖。
重点概念
DAG
DAG(Directed Acyclic Graph)有向无环图
- 在AirFlow中,一个DAG定义了一个完整的作业,同一个DAG中的所有Task拥有相同的调度时间
- 参数:dag_id(唯一识别DAG),default_args(默认参数,如果当前DAG实例的作业没有配置相应参数,则采用DAG实例的default_agrs中的相应参数)
- schedule_interval:配置GAG的执行周期,可采用crontab语法
Task
- Task为DAG中具体的作业任务,依赖于DAG,必须存在于某个DAG中,Task在DAG中可以配置依赖关系
- dag:当前作业属于相应的DAG
- task_id 任务标识符
- owner:任务的拥有者
- start_date:任务的开始时间
错误速查
| 症状 | 根因 | 定位 | 修复 |
|---|---|---|---|
| 订单数明显偏大 | 一笔订单含多个商品或分类明细,直接 count(*) 重复统计 | 检查 dws.dws_trade_orders_w 是否一单多行;核对 orderid 在同一 dt 下重复情况 | 订单量统一使用 count(distinct orderid) |
| 金额统计偏大 | 若 paymoney 在 DWS 层已是订单级金额,按商品明细求和会重复累加 | 抽样查看同一 orderid 的 paymoney 是否重复出现 | 明确 DWS 字段口径;若为订单总额,需先按订单去重再聚合 |
| 全国分类汇总与大区/城市汇总对不上 | 分类口径与区域口径都是从 mid_orders 二次聚合,源数据本身已做过一次合并 | 对比 mid_orders 中同一分类、区域、城市的数据分布 | 保持所有下游汇总都从同一中间层口径出发,避免混用原表与中间表 |
| Hive 脚本执行失败 | Shell 首行 shebang 写错,#!/bin/bash 使用了全角符号 | cat -A ads_load_trade_order_analysis.sh 查看首行字符 | 改为标准写法 #!/bin/bash |
| 分区数据未落表 | insert overwrite table ... partition(dt='$do_date') 执行时变量为空或日期错误 | echo $do_date,单独打印 SQL 验证 | 保证日期参数存在;默认值逻辑保留,执行前先回显变量 |
| 统计结果为空 | where dt='$do_date' 对应分区无数据 | 先执行 select count(1) from dws.dws_trade_orders_w where dt='日期'; | 先确认 DWS 当日分区已生成,再跑 ADS |
| 中文区域名/分类名出现空值 | 上游维度关联不完整,导致 regionname/cityname/category 缺失 | 抽查空值占比:where regionname is null or cityname is null ... | 在 DWD/DWS 层补齐维度映射,或在 ADS 层显式兜底 |
| 后续查询性能一般 | ADS 表仍采用文本分隔存储,不利于压缩与扫描优化 | desc formatted ads.ads_trade_order_analysis 查看存储信息 | 生产环境优先改为 ORC/Parquet,并结合分区与压缩参数优化 |
| Airflow 只写了概念,无法直接调度 | 缺少 DAG、Operator、调度周期、任务依赖示例 | 查看文章是否给出实际 DAG 文件 | 增补最小可运行 DAG,把 ODS→DIM→DWD→DWS→ADS 串起来 |
| 文章主题发散 | 前半部分讲 Hive ADS,后半部分突然切 Airflow 概念,搜索意图不够聚焦 | 看标题、摘要、正文小节是否统一 | 拆成两篇,或明确"数仓统计 + 调度编排"双主线 |
其他系列
🚀 AI篇持续更新中(长期更新)
AI炼丹日志-29 - 字节跳动 DeerFlow 深度研究框斜体样式架 私有部署 测试上手 架构研究 ,持续打造实用AI工具指南! AI研究-132 Java 生态前沿 2025:Spring、Quarkus、GraalVM、CRaC 与云原生落地
💻 Java篇持续更新中(长期更新)
Java-218 RocketMQ Java API 实战:同步/异步 Producer 与 Pull/Push Consumer MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务已完结,Dubbo已完结,MySQL已完结,MongoDB已完结,Neo4j已完结,FastDFS 已完结,OSS已完结,GuavaCache已完结,EVCache已完结,RabbitMQ已完结,RocketMQ正在更新... 深入浅出助你打牢基础!
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈! 大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解