1 Ollama简介
随着人工智能技术的快速发展,大型语言模型 LLM 已成为NLP领域的重要工具。然而,这些模型的运行通常需要大量的计算资源和复杂的部署流程。为了解决这个问题,Ollama应运而生,成为了一个高效的本地大语言模型LLM运行专家。
Ollama是一个开源的大型语言模型服务工具,它帮助用户快速在本地运行大模型。通过简单的安装指令,用户可以执行一条命令就在本地运行开源大型语言模型,如Llama 2。Ollama极大地简化了部署和管理LLM的过程,使得用户能够快速地在本地运行大型语言模型。
2 Windows下Ollama的安装
2.1 下载安装Ollama
-
Ollama主页:https://ollama.com/download/ ,支持macOS, Linux 和 Windows 系统,如果是macOS、Linux系统,直接安装使用即可;如果是Windows,需要按照以下教程进行安装使用:
-
点击下载按钮,获取
OllamaSetup.exe安装程序。
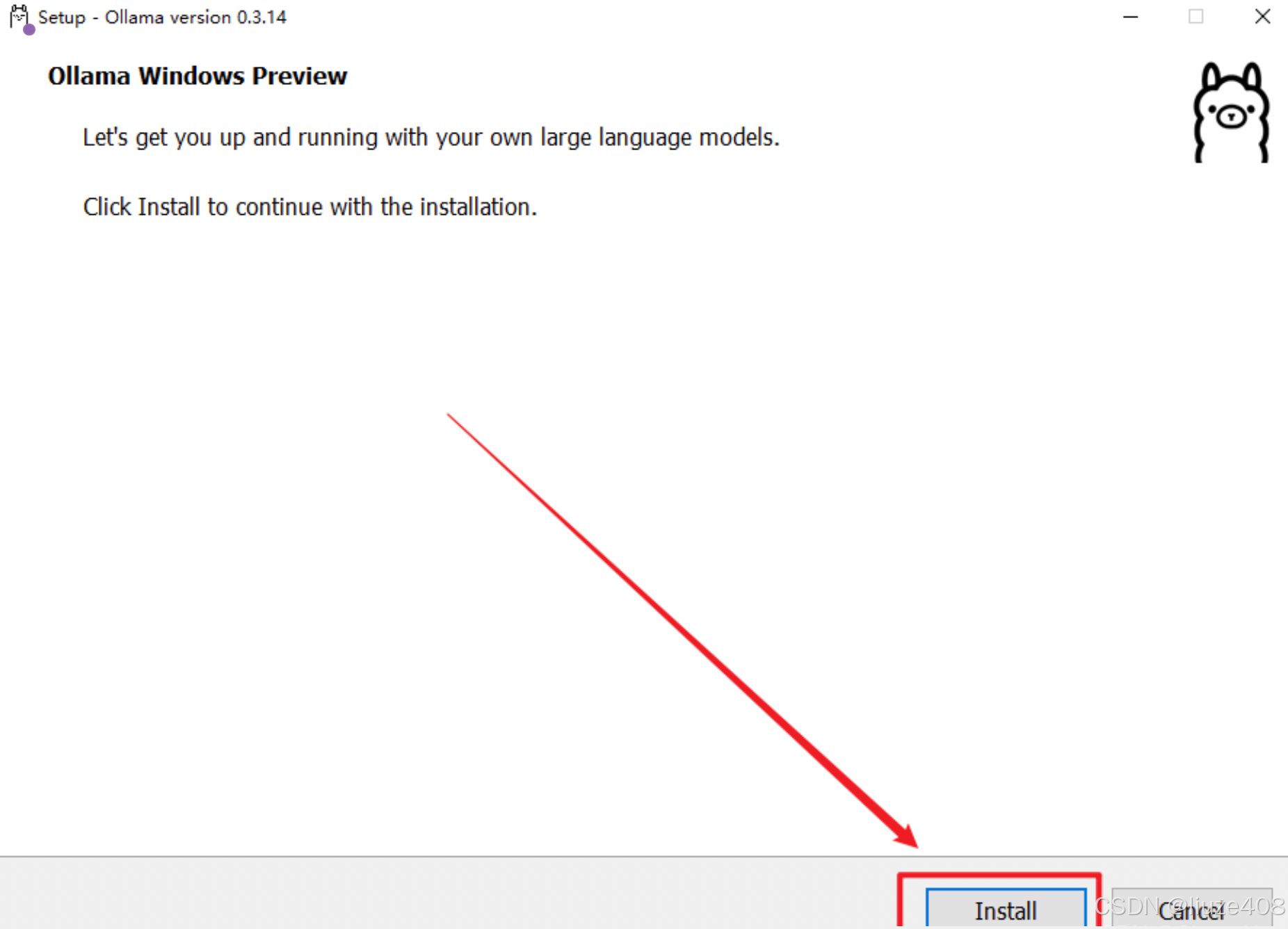
- 双击安装文件,点击「Install」开始安装。目前的Ollama会默认安装到C盘,路径如下:
C:\Users\%username%\AppData\Local\Programs\Ollama,并不会让用户自定义选择安装路径。
- 安装完成后,会在电脑右下角出现Ollama图标!
2.2 环境配置
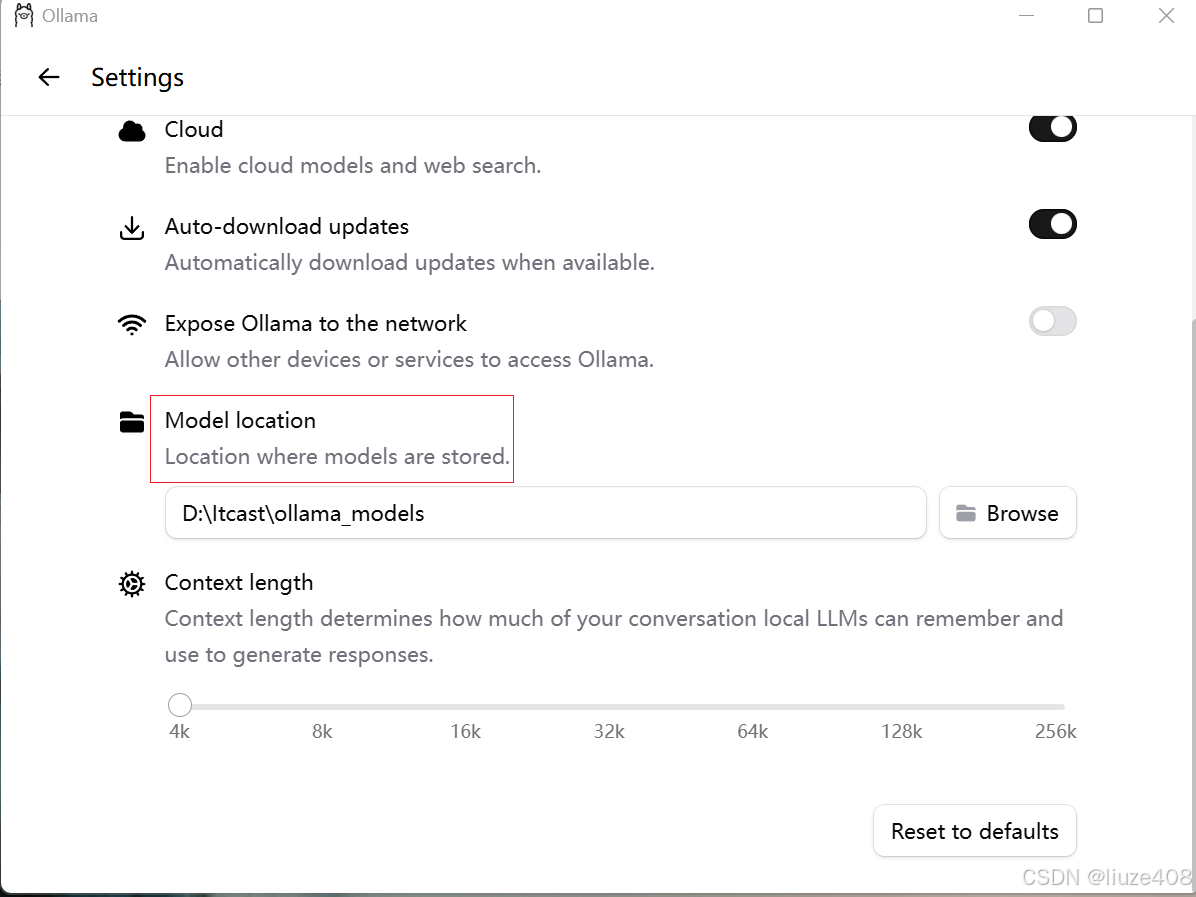
- 更改模型下载位置:模型默认下载到C盘,所以可以点击Settings进行自定义路径的设置
- 这里是在D盘自定义了文件夹(可以根据自己的电脑情况进行选择)
2.3 下载模型
-
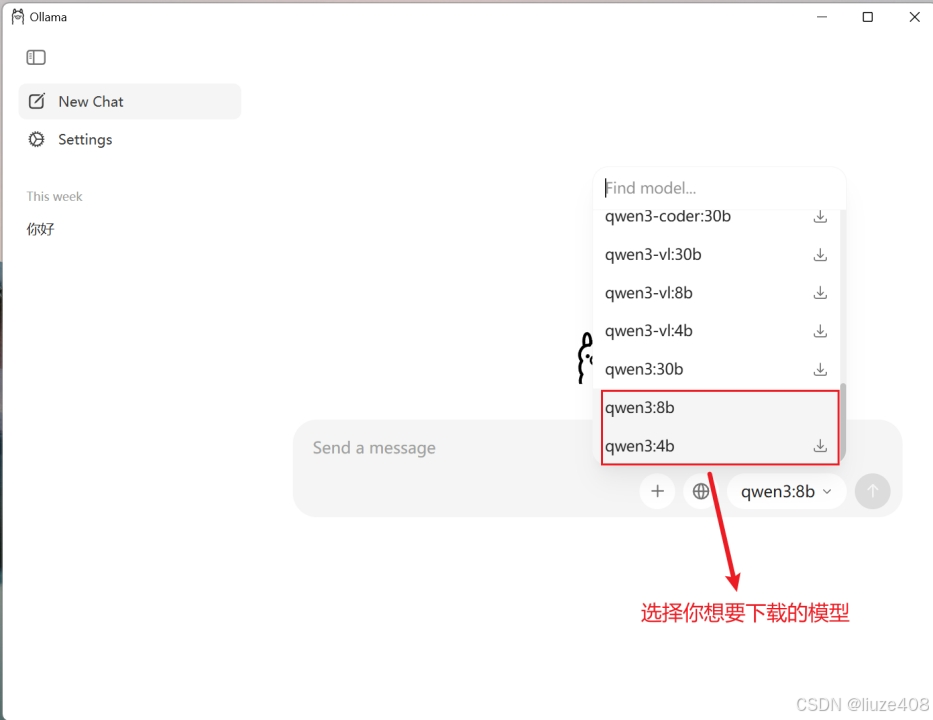
打开Ollama聊天对话框,选在自己想下载的模型
- 注意:模型越大,电脑要求越高,运行7B至少需要8GB显存,运行13B至少需要16G显存,如果没有GPU默认加载CPU;如果有默认加载GPU
-
如果默认的模型中不符合你的需求,可以在find model输入框中输入 <模型名称>,首次执行会从模型库中下载模型,所需时间取决于你的网速和模型大小。
在这里我建议可以先在find model中输入:qwen2.5:1.5b。用这个小模型下载后体验其功能,尽管没有GPU运行也会比较流畅
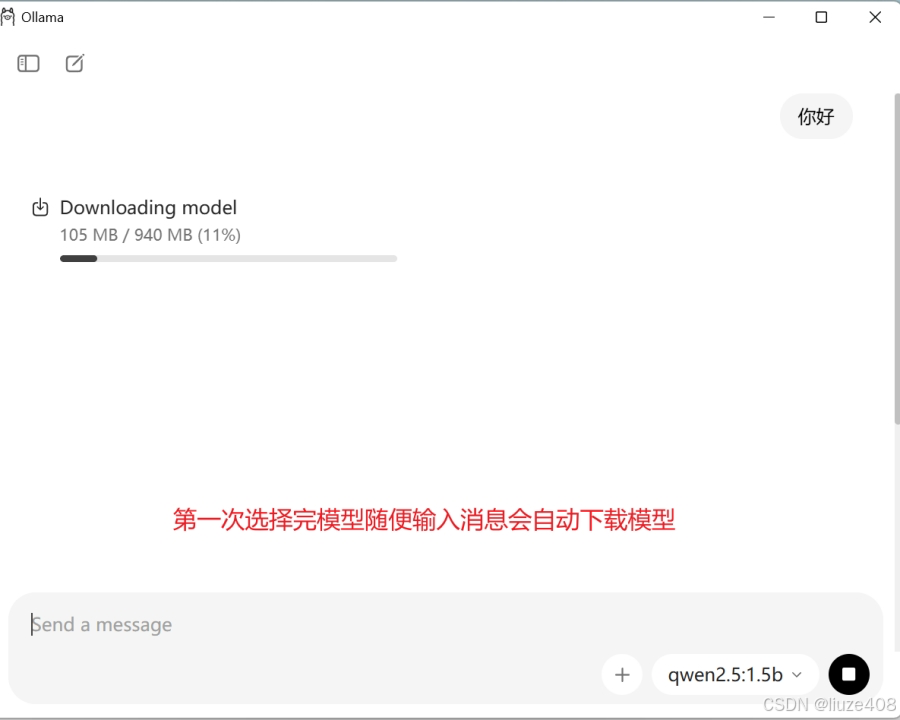
2.4 使用模型
-
等待下载模型完成后,就可以在聊天界面中使用了:
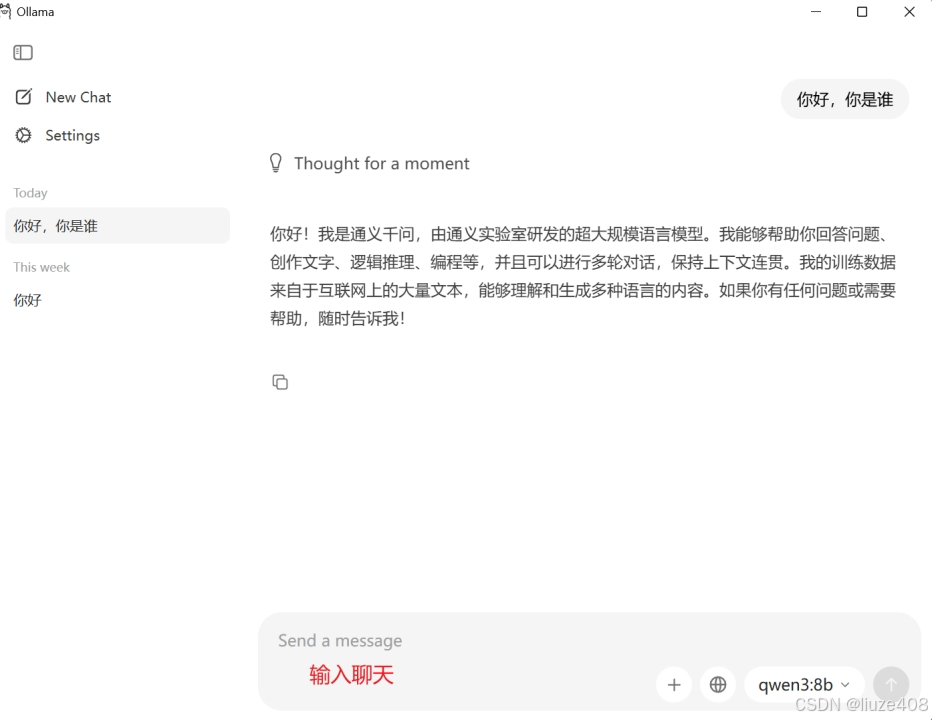
3 Mac下Ollama的安装
3.1 下载安装包
-
打开浏览器,访问Ollama官方网站:https://ollama.com/download
-
在官网找到Mac版本下载按钮,点击"Download for Mac"进行下载
3.2 安装程序
-
下载完成后,你会得到一个.dmg文件,双击打开它
-
将Ollama应用程序拖拽到Applications(应用程序)文件夹中
-
系统可能会提示需要移动到应用程序内,按照提示点击Next和Install按钮完成安装
3.3 启动Ollama
- 安装完成后,Ollama会自动启动。