笔记6:混合检索方案设计
一、RAG的核心缺陷
问题背景
L2生成的剧情文本通常很长,直接切片做RAG存在严重问题:
| 问题 | 表现 |
|---|---|
| 叙事完整性破坏 | 切片只保留片段,丢失上下文关联 |
| 序列逻辑断裂 | 一个完整序列被切成多个碎片 |
| 边界切割问题 | 关键信息刚好切在边界处 |
| 检索结果失真 | 返回的切片无法支撑决策 |
示例
L2生成:"拍卖会打脸"序列(5000字)
- 压抑阶段:反派嘲讽、众人轻视(2000字)
- 爆发阶段:主角亮宝、全场震惊(2000字)
- 余韵阶段:天价成交、反派失声(1000字)
传统切片(1000字/片,200字重叠):
- 片段1:嘲讽的前半部分
- 片段2:嘲讽的后半部分 + 亮宝的开头
- 片段3:亮宝的中段
- 片段4:震惊 + 成交
结果:检索"拍卖会打脸",返回的是破碎的片段,无法理解完整序列。
二、混合检索方案(初步设计)
架构总览
L2生成长剧情文本
↓
Agent数据集处理流程
↓
┌───┴───┐
↓ ↓
向量数据库 MD文本库
(摘要+标签) (完整切片)
↓ ↓
标签指针 ──→ 片段数据
(多维度切分)核心设计
1. 双库分离
| 库 | 存储内容 | 作用 |
|---|---|---|
| 向量数据库 | 摘要 + 标签 + 指针 | 快速检索,定位相关内容 |
| MD文本库 | 完整切片文本 | 提供完整上下文 |
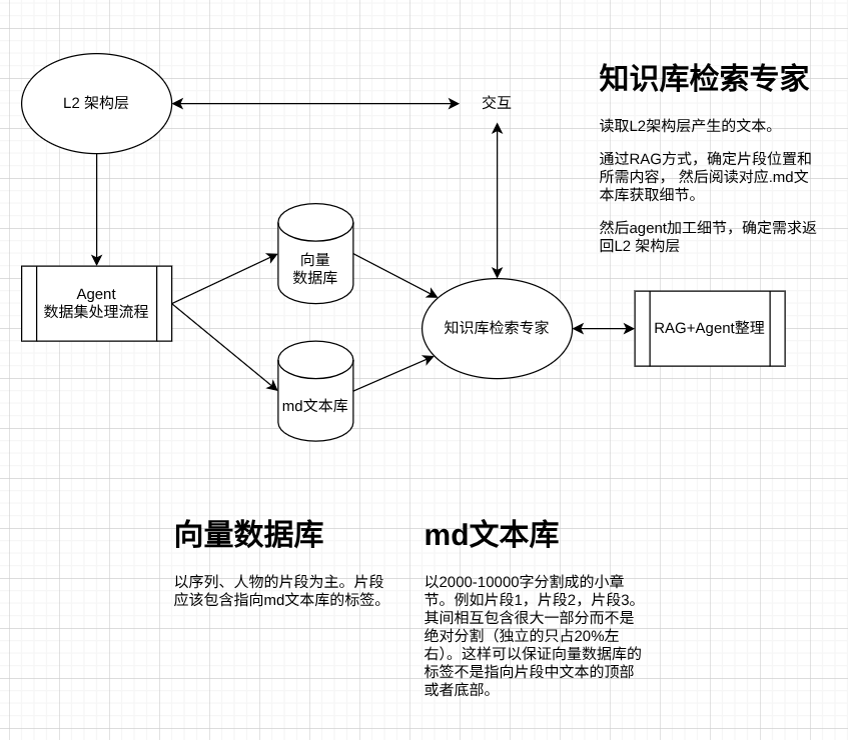
2. 知识库检索专家
定位:L2专家会议的参与者,负责从知识库获取必要信息
职责:
- 理解当前专家会议的讨论语境
- 判断需要检索的维度
- 调用向量数据库获取标签
- 根据标签获取完整文本
- 智能加工后返回给专家会议
工作流:
专家会议讨论 → 检索专家监听 → 判断需求
↓
选择检索维度
↓
查询向量数据库
↓
获取标签/指针
↓
读取MD文本库
↓
智能加工处理
↓
返回专家会议三、多维度切片方案
设计思路
放弃机械的重叠切片,采用多维度智能切分。同一份原始文本,从不同角度切分成不同粒度的片段。
维度设计
| 维度 | 切片单位 | 切片边界 | 适用场景 |
|---|---|---|---|
| 剧情维度 | 序列/事件 | 序列开始/结束 | 剧情架构师查询完整情节 |
| 人物维度 | 角色相关段落 | 人物出场/退场 | 人物设计师查询角色行为 |
| 爽点维度 | 情绪段落 | 情绪转折点 | 网络编辑评估爽点节奏 |
| 功能维度 | 叙事功能 | 功能边界 | 分析剧情结构 |
切片示例
原始文本:拍卖会打脸序列(5000字)
剧情维度切片:
- 切片A:"拍卖会打脸"完整序列(5000字)
- 边界:序列开始(入场)→ 序列结束(离场)
人物维度切片:
- 切片B1:主角戏份(1500字)
- 切片B2:反派赵少戏份(2000字)
- 切片B3:鉴定师戏份(800字)
- 切片B4:群众反应(700字)
爽点维度切片:
- 切片C1:压抑阶段(2000字)
- 切片C2:爆发阶段(2000字)
- 切片C3:余韵阶段(1000字)
功能维度切片:
- 切片D1:铺垫功能(入场+嘲讽)
- 切片D2:转折功能(亮宝)
- 切片D3:反馈功能(震惊+成交)
检索场景示例
场景:网络编辑评估"拍卖会打脸的爽点节奏是否合理"
检索专家处理:
1. 识别语境:网络编辑,关注爽点节奏
2. 选择维度:爽点维度
3. 检索结果:
- 压抑阶段(2000字)+ 标签:压抑强度=中
- 爆发阶段(2000字)+ 标签:爆发强度=高
- 余韵阶段(1000字)+ 标签:余韵强度=低
4. 智能加工:
- 分析情绪曲线:压抑→爆发→余韵
- 评估节奏:压抑略短,建议延长
5. 返回给网络编辑四、粒度冲突与解决
问题
不同维度的切片粒度不同,可能存在冲突:
- 人物维度:主角戏份跨多个序列
- 剧情维度:单个序列完整呈现
- 爽点维度:按情绪阶段切分
解决思路
分别返回,侧重不同,Agent统一处理
查询:"主角在拍卖会的表现"
检索结果:
├── 剧情维度:拍卖会打脸序列(完整上下文)
├── 人物维度:主角戏份(聚焦主角)
└── 爽点维度:主角相关的爽点段落
知识库检索专家:
- 理解查询意图(人物行为分析)
- 优先返回人物维度切片
- 补充剧情维度作为上下文参考
- 加工整合后返回五、待深入讨论的问题
1. 索引结构设计
- 多维度索引:多套独立索引 vs 一套索引+多维度标签?
- 标签体系:需要哪些标签字段?
- 指针结构:如何高效关联向量库与文本库?
2. 切分Agent设计
- 切分Agent需要理解哪些叙事学概念?
- 如何自动识别序列边界、情绪转折点、功能边界?
- 人工预标注 vs 全自动切分?
3. 检索策略
- 多维度检索时,如何选择返回哪些维度的切片?
- 检索结果的优先级排序?
- 切片长度上限是多少?
4. 与L2专家会议的集成
- 检索专家如何"监听"专家会议?
- 何时主动检索,何时被动响应?
- 检索结果如何呈现给专家?
5. 数据格式
- MD文本库的具体格式?
- 向量数据库的数据结构?
- 标签字段设计?
六、后续工作
- 深入思考索引结构和切分Agent设计
- 设计具体的标签体系和数据格式
- 实现一个最小原型验证可行性
- 与现有的L2专家会议流程集成测试
七、Agent+RAG混合方案的扩展应用
洞察
这套混合检索方案不仅适用于L2的长文本问题,对于L3和L4的RAG映射处理同样具有参考价值。Agent+RAG的混合方式比单纯的RAG方法更智能、更可控。
L3叙事层的应用
L3的核心任务是"映射":将网文效果指令翻译为叙事学技术指令。
单纯RAG的问题:
- 检索到的映射规则可能不完整
- 无法理解当前细纲的具体语境
- 多条映射规则冲突时无法判断
Agent+RAG混合方案:
L3叙事层 + 映射检索专家
工作流:
1. 读取L2产出的精修大纲
2. 映射检索专家监听当前任务
3. 判断需要哪些映射规则(视角?节奏?话语模式?)
4. 检索L3映射关系库
5. Agent智能加工:根据具体场景选择/组合映射规则
6. 产出细纲指令待思考:
- L3的映射检索专家需要理解哪些概念?
- 多条映射规则冲突时如何仲裁?
- 映射规则是否需要"优先级"或"适用条件"标签?
L4渲染层的应用
L4的核心任务是"渲染":根据细纲指令生成正文文本。
单纯RAG的问题:
- 检索到的参考文本风格可能不一致
- 无法根据当前章节的具体需求筛选
- 参考文本可能"带偏"生成方向
Agent+RAG混合方案:
L4渲染层 + 技法检索专家
工作流:
1. 读取L3产出的细纲指令
2. 技法检索专家分析当前场景需求
3. 检索L4微观技法库
4. Agent智能加工:筛选、组合、调整参考文本
5. 产出正文待思考:
- L4的技法检索专家如何判断"风格一致性"?
- 多个参考文本如何融合?
- 如何避免参考文本"过度影响"生成结果?
统一的Agent+RAG架构
┌─────────────────────────────────────────────────┐
│ 创作模型 │
├─────────────────────────────────────────────────┤
│ L1种子层 → L2架构层 → L3叙事层 → L4渲染层 │
│ ↓ ↓ ↓ │
│ 检索专家(剧情) 检索专家(映射) 检索专家(技法) │
│ ↓ ↓ ↓ │
│ ┌────┴───────────┴───────────┴────┐ │
│ ↓ Agent智能加工层 ↓ │
│ └────┬───────────┬───────────┬────┘ │
│ ↓ ↓ ↓ │
│ 向量数据库 向量数据库 向量数据库 │
│ (剧情库) (映射库) (技法库) │
│ ↓ ↓ ↓ │
│ MD文本库 MD文本库 MD文本库 │
└─────────────────────────────────────────────────┘待深入讨论的问题
- L3映射检索专家的职责边界:只检索映射规则,还是也参与映射决策?
- L4技法检索专家如何避免"风格漂移"?
- 三个检索专家是否需要共享某些信息(如当前故事的整体风格基调)?
- Agent智能加工层的具体逻辑:压缩?重组?摘要?推理?
- 是否需要一个"总检索协调者"来统筹三个检索专家?
八、业界相近的RAG增强方案
以下是检索到的业界方案,笔者未深入研读。如果读者发现本文的方案走不通,可以参考这些方案进行改进。
1. Query Transformations(查询变换)
LangChain提出的查询增强方法:
| 方法 | 说明 |
|---|---|
| Query Expansion | 将问题拆分成多个子问题分别检索 |
| Query Re-writing | 重写问题以提高检索效果 |
| Query Compression | 压缩对话历史为单一检索问题 |
参考 :https://blog.langchain.dev/deconstructing-rag/
2. Multi-Vector Retriever(多向量检索器)
核心思想:将"用于检索的内容"和"返回给LLM的内容"分离。
- 检索时:使用摘要、小切片或表格描述
- 返回时:返回完整的原文、原始表格
与本文方案的相似性:
- 本文的"向量库存摘要+标签,MD库存完整文本"与之类似
- 但本文增加了"多维度切分"和"Agent智能加工"
参考:LangChain Multi-Vector Retriever
3. Parent Document Retriever(父文档检索器)
核心思想:小切片检索,返回大切片(父文档)。
- 解决切片边界问题
- 但仍是机械的长度切分,没有语义边界
与本文方案的差异:
- 本文按叙事学概念(序列、情绪、功能)切分,而非机械长度
- 本文的"多维度切分"可以考虑不同粒度需求
参考:LangChain Parent Document Retriever
4. GraphRAG(微软)
核心思想:构建知识图谱而非简单切片。
- 从文本中提取实体、关系、声明
- 使用Leiden算法进行层级聚类
- 生成社区摘要,支持全局/局部搜索
与本文方案的相似性:
- 都关注"关系"和"层级"
- GraphRAG用知识图谱,本文用叙事学概念
与本文方案的差异:
- GraphRAG偏通用知识抽取
- 本文针对网文创作,有"爽点"、"功能"、"序列"等特定维度
参考 :https://microsoft.github.io/graphrag/
方案对比总结
| 方案 | 切片策略 | 索引结构 | 检索处理 | 适用场景 |
|---|---|---|---|---|
| Multi-Vector | 机械切分 | 摘要+原文分离 | 直接返回 | 通用 |
| Parent Document | 小切大返回 | 层级索引 | 直接返回 | 通用 |
| GraphRAG | 知识图谱 | 图结构 | 图遍历 | 复杂推理 |
| 本文方案 | 多维度语义切分 | 双库+Agent | Agent智能加工 | 网文创作 |
本文方案的创新点
- 叙事学驱动的切分维度:按人物、爽点、剧情、功能维度切分
- Agent作为检索专家:主动理解语境,智能加工检索结果
- 与创作流程深度绑定:L2/L3/L4各有专门的检索专家
创建时间:2026-03-19 状态:方案讨论中