数据库全品类技术详解:原理、特性、场景与实战案例
数据库是现代软件架构的核心基础设施,不同数据结构、业务负载、查询模式与扩展性需求,对应不同类型数据库的最优解。本文从原理、核心特性、适用场景、技术案例、代表产品五个维度,完整梳理关系型、NoSQL、专用型、融合型四大类数据库,提供可直接落地的技术参考。
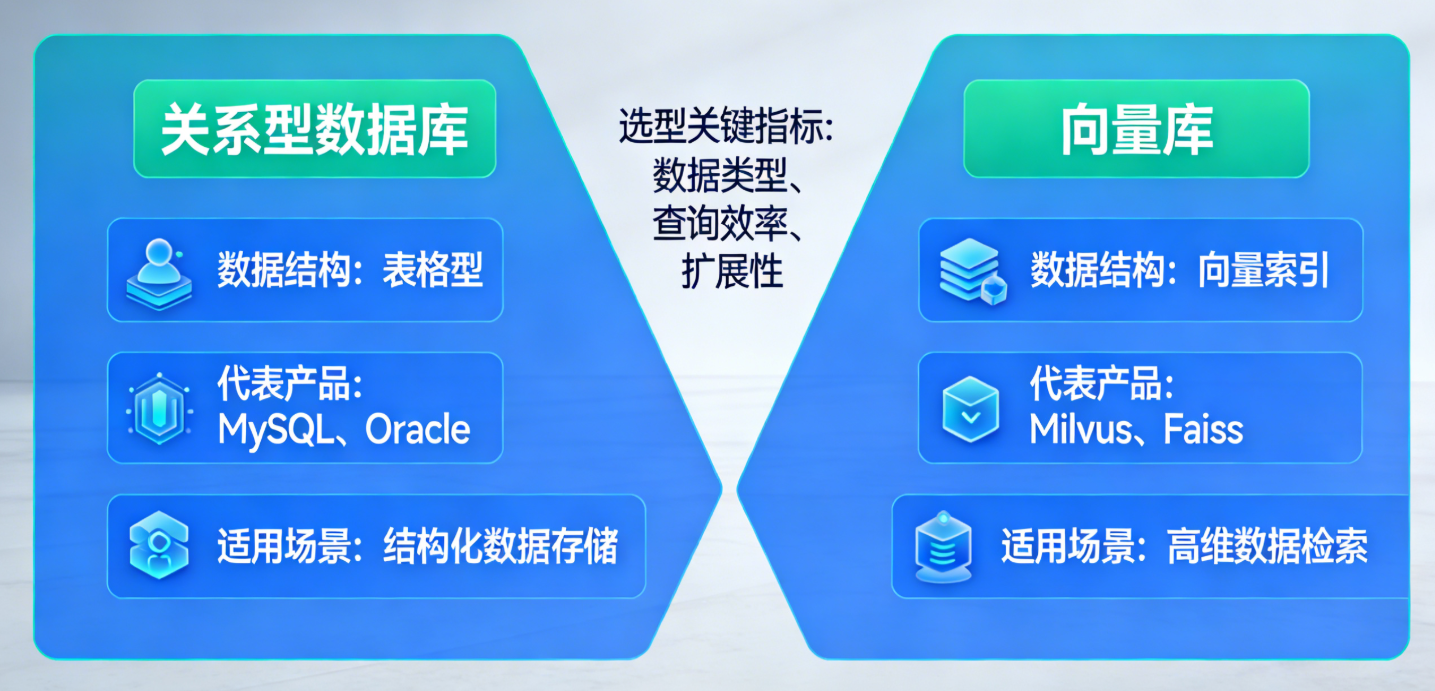
一、关系型数据库(RDBMS)
核心原理
数据以二维表(Table) 结构化存储,行(Row)对应实体记录,列(Column)对应属性;表之间通过外键(Foreign Key)建立关联,使用SQL 作为统一查询语言,严格遵循ACID事务特性。
- Atomicity(原子性):事务要么全部执行,要么全部回滚
- Consistency(一致性):执行前后数据约束保持有效
- Isolation(隔离性):并发事务互不干扰
- Durability(持久性):提交后数据永久生效
关键技术特性
- 强事务与数据一致性,支持分布式事务(XA/TCC)
- 支持多表关联查询(JOIN)、子查询、聚合函数
- 固定 Schema,预定义表结构与字段类型
- 成熟的索引机制(B + 树、哈希索引)
典型业务场景与案例
电商订单系统订单表、用户表、商品表、支付表通过外键关联;下单时扣减库存、生成订单、记录支付流水需在同一事务中完成,避免超卖或数据不一致。
银行转账系统A 账户扣款、B 账户入账必须原子执行,任何一步失败则整体回滚,保证资金安全。
企业 ERP/CRM 管理系统客户、合同、财务、库存数据强关联,需要复杂报表与多维度统计查询。
主流产品
MySQL、PostgreSQL、SQL Server、Oracle
二、非关系型数据库(NoSQL)
NoSQL = Not Only SQL,面向高并发、海量数据、灵活结构设计,放弃部分强一致性,换取高性能与水平扩展。
1. 键值数据库(Key-Value Store)
核心原理
数据以Key-Value键值对存储,Key 全局唯一,Value 可为字符串、数字、JSON、列表、哈希等,底层近似分布式哈希表。
技术特性
- O (1) 读写复杂度,单实例可达10 万 + QPS
- 支持数据分片、主从复制、集群横向扩展
- 内存 / 磁盘混合存储,支持数据过期与持久化
场景与案例
分布式缓存电商首页热点商品、秒杀库存、用户登录 Session 存入 Redis,大幅降低 MySQL 查询压力。
分布式锁秒杀、库存扣减场景使用 Redis 分布式锁,防止超卖与重复提交。
实时计数器视频播放量、文章点赞数、直播间在线人数高频更新。
代表产品
Redis(内存型)、Memcached(纯缓存)
2. 文档数据库(Document DB)
核心原理
以文档(Document) 为单位存储,主流格式为BSON/BJSON,无需预定义表结构,单文档可嵌套对象与数组,支持文档级索引。
技术特性
- 动态 Schema,字段可随时增删改,无需 ALTER TABLE
- 支持嵌套查询、数组查询、全文索引
- 自动分片与副本集,支持海量存储
场景与案例
电商商品详情不同品类商品字段差异大(手机有内存 / 摄像头,衣服有尺码 / 颜色),用文档库无需分表。
内容平台博客、文章、评论、用户配置信息结构灵活,频繁迭代字段。
用户画像系统存储用户标签、行为、偏好等半结构化数据,支持快速查询与更新。
代表产品
MongoDB

三、专用场景数据库
针对特定数据形态与查询模式深度优化,性能远超通用数据库。
1. 搜索引擎数据库
核心原理
基于倒排索引(Inverted Index) :将文本分词后,建立词汇 → 文档 ID 列表映射,支持模糊匹配、同义词、拼音纠错、相关性打分排序。
技术特性
- 支持海量文本毫秒级检索
- 提供高亮、分页、聚合、过滤、排序能力
- 支持集群横向扩展与近实时数据同步
场景与案例
电商商品搜索用户输入 "轻薄游戏本",系统分词匹配标题 / 描述 / 参数,按销量 / 评分 / 价格排序。
站内全文搜索新闻、论坛、知识库按关键词快速定位内容。
日志检索平台服务器日志、用户行为日志秒级查询,辅助问题定位。
代表产品
Elasticsearch、Apache Solr
2. 向量数据库
核心原理
将图像、文本、音频、视频通过 AI 模型转为高维向量 (通常 128~16384 维),使用近似最近邻搜索(ANN) 算法快速计算相似度。
技术特性
- 支持海量向量高吞吐写入与低延迟查询
- 提供余弦相似度、欧氏距离等计算
- 支持过滤条件 + 向量检索混合查询
场景与案例
AI 知识库 / RAG文档切片向量化存储,用户提问转为向量,匹配最相关片段给大模型。
以图搜图图片生成特征向量,检索相似图片。
个性化推荐用户行为与商品向量化,实时匹配相似兴趣内容。
代表产品
Milvus、Pinecone、Chroma
3. 图数据库
核心原理
以节点(Node)+ 边(Edge)+ 属性(Property) 存储,专门处理深度关联、多跳关系,避免关系型数据库多表 JOIN 性能雪崩。
技术特性
- 高效遍历 3~10 层深度关系
- 支持最短路径、社区发现、链路预测、图算法
- 高并发关系查询毫秒级响应
场景与案例
社交网络查找 "朋友的朋友"、共同好友、二度人脉。
金融风控 / 反欺诈挖掘账户间资金链路、团伙欺诈、关联套现。
知识图谱构建企业、人物、产品、事件之间的关联关系。
代表产品
Neo4j
4. 时序数据库(TSDB)
核心原理
针对带时间戳 的流式数据优化,按时间分桶、连续存储、批量写入,聚焦高写入、高压缩、按时间范围聚合。
技术特性
- 单节点百万级 TPS 写入
- 极高压缩比(通常 10:1~40:1)
- 支持降采样、聚合、保留策略、自动过期
场景与案例
服务器 / 容器监控CPU、内存、网卡、磁盘指标每秒采集,按分钟 / 小时 / 天聚合
物联网 IoT工业传感器、智能电表、环境监测数据实时入库。
金融行情股票、期货逐笔 tick 数据与 K 线生成。
代表产品
InfluxDB、TimescaleDB、Prometheus(时序监控)
5. 列式数据库
核心原理
按列独立存储,同列数据连续存放,查询时只加载需要的列,大幅降低 IO,适合大规模分析。
技术特性
- 聚合查询(SUM/COUNT/AVG)性能比行存快 10~100 倍
- 高压缩比,相同数据体积仅行存 1/5~1/20
- 面向 OLAP(联机分析处理)优化
场景与案例
用户行为分析日亿级行为日志,统计 UV、PV、留存、漏斗转化。
数据仓库 / BI 报表企业经营数据、销售报表、财务分析。
海量日志分析安全审计、用户行为、接口调用统计。
代表产品
ClickHouse、Apache Druid、HBase
四、融合型数据库
兼顾事务一致性与分布式扩展性,解决 "传统 SQL 扩展难、NoSQL 无事务" 的痛点。
1. NewSQL
核心特性
- 支持标准 SQL 与 ACID 强事务
- 水平分片、自动容错、无感知扩容
- 兼容 MySQL/PostgreSQL 协议,迁移成本低
场景与案例
互联网高并发核心系统:订单、支付、账户系统,替代分库分表,支持千万级并发。
代表产品
TiDB、CockroachDB、Google Spanner
2. 多模数据库
核心特性
- 单库同时支持关系、文档、图、键值、向量等模型
- 统一查询入口,支持跨模型事务
- 降低多数据库运维成本
局限
全而不精,单一场性能不如专用数据库。
代表产品
ArangoDB、OrientDB;PostgreSQL 通过插件实现多模扩展
五、数据库选型标准(技术版)
- 强事务、强一致、复杂查询 → 关系型数据库(MySQL/PostgreSQL)
- 高并发缓存、会话、计数器 → Redis
- 结构灵活、半结构化数据 → MongoDB
- 全文搜索、模糊匹配 → Elasticsearch
- AI 向量检索、推荐、RAG → 向量数据库
- 深度关系、人脉、风控、图谱 → 图数据库
- 监控、IoT、时序指标 → 时序数据库
- 大数据分析、BI 报表、日志 → 列式数据库
- 高并发 + 强事务 + 分布式 → NewSQL
六、数据仓库与数据湖
- 数据仓库:面向结构化数据,清洗加工后用于分析,支持 BI 与报表。
- 数据湖:存储原始结构化 / 半结构化 / 非结构化数据(日志、图片、音频、视频),用于机器学习与深度挖掘。