
简介:ETL(抽取-转换-加载)是构建数据仓库的核心流程,涵盖数据抽取、清洗转换和加载到目标系统的全过程。本文围绕两套高频ETL面试题展开,深入解析ETL流程、常用工具、设计原则及常见问题应对策略。通过真实项目案例与实战经验,帮助读者掌握ETL核心技术,提升面试通过率与数据处理能力。
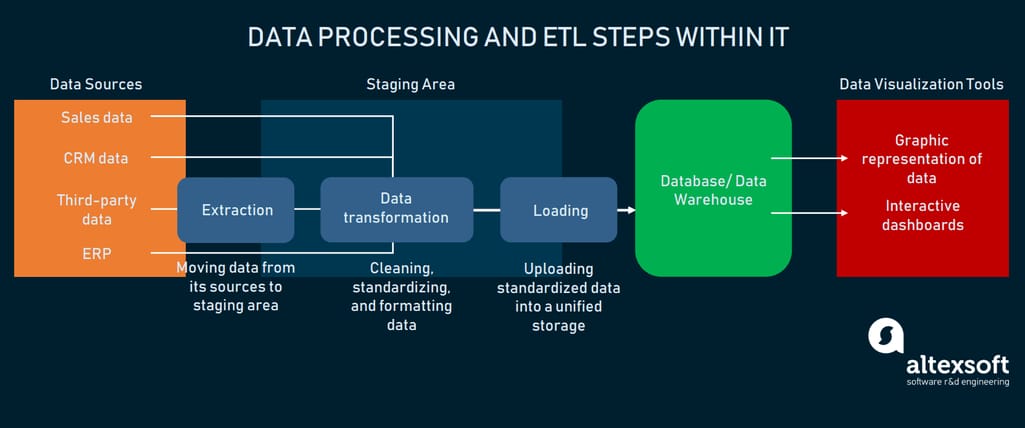
1. ETL核心流程详解
ETL(Extract, Transform, Load)是构建现代数据仓库与数据平台的核心流程,贯穿数据从业务系统到分析决策的全过程。本章将从整体视角出发,系统解析ETL流程的三大核心阶段: 数据抽取、数据转换与数据加载 。通过本章学习,读者将掌握ETL的整体流程框架,理解各阶段的关键任务与技术要点,为后续章节中深入探讨抽取策略、转换技巧与加载优化打下坚实基础。
ETL流程不仅决定了数据的完整性与准确性,也直接影响数据平台的性能与可维护性。在实际项目中,ETL工程师需要综合考虑数据源类型、数据量级、业务需求和系统架构,设计出高效、稳定的数据处理流程。本章将为读者构建一个清晰的ETL认知体系,帮助理解其在整个数据生命周期中的关键作用。
2. 数据抽取方法与策略
数据抽取是ETL流程的起始环节,是构建数据仓库和实现数据集成的基础。本章将围绕数据抽取的核心方法与策略展开,从抽取类型、数据源适配、常见问题与优化,以及元数据管理四个方面,深入探讨如何高效、稳定地完成数据抽取任务。通过本章内容,读者将掌握不同数据源下的抽取策略、问题处理方式及元数据管理的最佳实践,为构建健壮的ETL流程打下坚实基础。
2.1 数据抽取的基本类型
在ETL流程中,数据抽取的策略直接影响后续处理的效率与准确性。常见的数据抽取方式主要分为 全量抽取 和 增量抽取 两种。理解其区别与适用场景,是制定数据抽取策略的第一步。
2.1.1 全量抽取与增量抽取的对比
全量抽取是指每次抽取操作都将源系统中的全部数据导入目标系统。这种方式适用于数据量小、变化频率低的场景,优点是实现简单,数据一致性容易保障,但缺点在于效率低、资源消耗大。
增量抽取则只抽取自上次抽取以来发生变化的数据,通常依赖于时间戳、序列号或变更日志等机制。该方式适用于数据量大、变更频繁的系统,能显著减少数据传输量,提升效率。
| 对比维度 | 全量抽取 | 增量抽取 |
|---|---|---|
| 数据量 | 大 | 小 |
| 抽取频率 | 可低频 | 高频 |
| 实现复杂度 | 简单 | 复杂 |
| 资源消耗 | 高 | 低 |
| 数据一致性 | 易于保证 | 需机制支持 |
| 适用场景 | 小型系统、静态数据 | OLTP系统、日志数据 |
2.1.2 抽取方式的选择标准
在选择抽取方式时,应综合考虑以下因素:
- 数据变化频率 :若数据更新频繁,优先考虑增量抽取。
- 系统性能要求 :对性能敏感的环境应选择增量抽取以减少负载。
- 数据一致性要求 :如需高一致性,可结合增量与校验机制。
- 源系统支持能力 :是否支持时间戳、事务日志、CDC(Change Data Capture)等功能。
- 目标系统处理能力 :目标系统是否具备实时处理能力或批量处理窗口。
在实际项目中,通常采用 混合模式 :初始阶段使用全量抽取建立基线,后续采用增量抽取更新变化。
2.2 数据源类型与抽取策略
根据数据源的类型不同,抽取策略也应有所区别。本节将重点介绍关系型数据库、非结构化数据(如日志、XML)以及实时数据流的抽取技术。
2.2.1 关系型数据库的抽取方式
关系型数据库是最常见的数据源类型,常见的抽取方式包括:
- 基于时间戳的增量抽取 :
适用于有更新时间字段的表,例如last_modified。
sql
-- 示例:基于时间戳的增量抽取
SELECT * FROM orders
WHERE last_modified > '2024-04-01';逻辑分析 :
-
last_modified字段用于标识数据变更时间; -
每次抽取只需查询该时间点之后的数据;
-
该方式依赖字段的准确性和一致性。
-
基于数据库日志(如MySQL binlog、Oracle Redo Log) :
利用数据库事务日志进行实时或近实时抽取,常用于数据同步和数据集成平台。
-
使用ETL工具内置的CDC功能 :
如 Informatica PowerCenter、Talend 的 CDC 组件,支持自动捕捉数据变化。
2.2.2 非结构化数据(如日志、XML)的抽取策略
非结构化数据的抽取主要依赖解析与转换技术。常见的抽取方式包括:
- 日志文件抽取 :
通常使用脚本或工具(如 Logstash、Flume)读取日志文件,按行或块解析。
bash
# 使用Logstash抽取日志示例
input {
file {
path => "/var/log/app/*.log"
start_position => "beginning"
}
}
filter {
grok {
match => { "message" => "%{COMBINEDAPACHELOG}" }
}
}
output {
elasticsearch {
hosts => ["localhost:9200"]
}
}逻辑分析 :
-
input定义日志文件路径; -
filter使用 grok 正则解析日志格式; -
output将解析后的数据输出至 Elasticsearch。
- XML/JSON 数据抽取 :
使用 XPath 或 JSONPath 提取结构化信息,常见于 Web 服务或配置文件中。
python
import xml.etree.ElementTree as ET
tree = ET.parse('data.xml')
root = tree.getroot()
for order in root.findall('order'):
print(order.find('order_id').text)逻辑分析 :
-
使用
ElementTree解析 XML; -
遍历
order节点,提取order_id字段; -
可结合 XPath 表达式提取复杂结构。
2.2.3 实时数据流的抽取技术
随着实时数据分析需求的增加,越来越多的数据源采用消息队列或流式处理方式,如 Kafka、Kinesis、Flink 等。
- Kafka 消费者抽取示例 :
python
from kafka import KafkaConsumer
consumer = KafkaConsumer(
'topic_name',
bootstrap_servers='localhost:9092',
auto_offset_reset='earliest'
)
for message in consumer:
print(message.value)逻辑分析 :
-
创建 Kafka 消费者实例;
-
订阅指定 Topic;
-
循环读取并处理消息内容;
-
auto_offset_reset='earliest'表示从最早的消息开始消费。
- 流程图:实时数据流抽取流程
说明 :
-
数据源将事件写入 Kafka;
-
Kafka Producer 发送数据至 Broker;
-
Kafka Consumer 消费数据并交由 ETL 引擎处理。
2.3 数据抽取中的常见问题与优化
数据抽取过程中常常面临数据一致性、性能瓶颈、源系统变更等问题,需采取相应的策略进行优化。
2.3.1 数据一致性问题的处理
数据一致性是数据抽取中最为关键的挑战之一,尤其是在分布式系统或并发抽取场景中。
常见处理方式 :
- 事务控制 :在支持事务的系统中使用事务机制确保数据完整性。
- 快照机制 :对源系统进行快照抽取,避免数据在抽取过程中发生变更。
- 版本号控制 :使用版本字段或时间戳进行一致性校验。
- 双写校验 :在目标系统写入后回查源系统确认数据一致性。
2.3.2 性能瓶颈与并发控制
抽取过程中的性能瓶颈可能来源于网络带宽、源系统负载、数据量过大等。
优化策略 :
- 并行抽取 :将数据按分区或键值划分,多线程/多进程并发抽取。
- 分页查询 :对于大数据量表,使用 LIMIT/OFFSET 或游标方式分页抽取。
- 压缩与批量传输 :使用 GZIP 或 Snappy 压缩数据,提升网络传输效率。
- 缓存机制 :在抽取前缓存部分数据,避免重复查询。
2.3.3 数据源变更的应对策略
源系统结构或内容的变更可能导致抽取失败或数据错误。
应对策略 :
- 元数据监控 :定期扫描源系统的元数据变化。
- Schema 版本控制 :记录源数据结构的历史版本,确保兼容性。
- 异常处理机制 :在抽取程序中加入异常捕获与自动修复逻辑。
- 数据校验机制 :抽取后进行字段完整性与格式校验。
2.4 抽取过程中的元数据管理
元数据是描述数据的数据,在数据抽取过程中起着至关重要的作用。良好的元数据管理有助于提升系统的可维护性与可追溯性。
2.4.1 元数据的作用与分类
元数据主要分为以下几类:
| 类型 | 描述 |
|---|---|
| 技术元数据 | 数据库结构、字段类型、索引信息等 |
| 业务元数据 | 数据含义、数据用途、业务规则等 |
| 操作元数据 | 抽取时间、抽取状态、执行日志等 |
| 管理元数据 | 权限控制、数据生命周期、安全策略等 |
元数据的作用包括:
- 支持数据血缘追踪与影响分析;
- 提高数据质量与一致性;
- 辅助自动化ETL流程;
- 支持数据治理与合规审计。
2.4.2 元数据采集与维护实践
元数据的采集与维护应贯穿整个数据抽取流程,以下是推荐的实践方法:
-
自动化采集 :
-
使用脚本或工具(如 Apache Atlas、Alation)自动抓取源系统的元数据。
-
在抽取过程中记录操作日志与执行参数。
-
-
元数据存储 :
-
使用元数据仓库(如 Hive Metastore、PostgreSQL)集中管理。
-
支持版本控制与变更记录。
-
-
元数据同步机制 :
-
定期同步源系统的结构变更。
-
设置变更通知机制,及时更新元数据。
-
-
可视化与查询 :
-
构建元数据查询接口或可视化平台。
-
支持字段级搜索、影响分析、血缘图谱等功能。
-
示例:使用 SQL 查询元数据信息(以 PostgreSQL 为例)
sql
-- 查询表结构元数据
SELECT column_name, data_type, is_nullable
FROM information_schema.columns
WHERE table_name = 'orders';逻辑分析 :
-
查询
orders表的字段名、数据类型和是否可为空; -
可用于自动构建数据映射关系或校验数据一致性。
元数据血缘图表示例(mermaid) :
说明 :
-
表示数据从源系统抽取,经过ETL处理,最终用于报表展示;
-
有助于追溯数据来源与影响路径。
以上为第二章的完整章节内容,涵盖了数据抽取的核心方法、策略、问题处理与元数据管理,内容深入、结构清晰,并结合代码、表格与流程图增强理解与实操性。
3. 数据清洗与转换关键技术
在ETL流程中,数据清洗与转换是承上启下的关键环节。数据在从源系统抽取之后,往往存在格式不统一、数据缺失、异常值、重复记录等问题,这些问题如果不加以处理,将直接影响后续的数据分析和决策支持。本章将深入探讨数据清洗的核心任务、数据转换的常用方法、数据质量保障机制以及转换过程的性能优化策略,帮助读者掌握数据处理的关键技术。
3.1 数据清洗的核心任务
数据清洗是ETL流程中最基础但又最重要的环节之一。其核心任务在于识别并修正数据中的错误,确保进入数据仓库的数据是干净、准确、一致的。清洗工作通常包括处理缺失值、异常值和重复数据,以及进行数据标准化与格式统一。
3.1.1 缺失值、异常值与重复数据的处理
在数据清洗过程中,缺失值、异常值和重复数据是常见的问题。处理这些数据的方式直接影响数据质量,也影响后续分析的准确性。
- 缺失值处理 :缺失值的处理方式包括删除记录、填充默认值、使用平均值或中位数填充、利用模型预测等。例如,在Python中可以使用Pandas库进行缺失值处理:
python
import pandas as pd
# 读取数据
df = pd.read_csv('data.csv')
# 填充缺失值为0
df.fillna(0, inplace=True)
# 删除缺失值行
df.dropna(inplace=True)逻辑分析 :
fillna()方法用于填充缺失值,inplace=True表示在原数据上进行修改。
dropna()方法用于删除包含缺失值的行。
- 异常值处理 :异常值可能来源于输入错误或极端情况。可以使用统计方法(如Z-score、IQR)检测异常值,并决定是否剔除或修正。
python
# 使用IQR方法识别异常值
Q1 = df['column_name'].quantile(0.25)
Q3 = df['column_name'].quantile(0.75)
IQR = Q3 - Q1
# 过滤出非异常值
df_clean = df[~((df['column_name'] < (Q1 - 1.5 * IQR)) | (df['column_name'] > (Q3 + 1.5 * IQR)))]逻辑分析 :
IQR方法是一种稳健的异常值检测方法。
(Q1 - 1.5 * IQR)和(Q3 + 1.5 * IQR)是异常值的上下限。使用
~表示取反,保留非异常值。
- 重复数据处理 :重复数据会导致分析结果偏差,可以通过去重操作处理。
python
# 删除重复行
df.drop_duplicates(inplace=True)逻辑分析 :
drop_duplicates()方法默认会比较所有列,若某行所有列都相同则视为重复。可通过
subset参数指定某些列作为去重依据。
3.1.2 数据标准化与格式统一
数据标准化是将不同来源的数据统一到一致的格式和单位中,以便后续分析。例如日期格式、单位转换、字符串标准化等。
python
# 将日期列转换为统一格式
df['date'] = pd.to_datetime(df['date'])
df['date'] = df['date'].dt.strftime('%Y-%m-%d')
# 单位统一(如将千克转为克)
df['weight'] = df['weight'] * 1000逻辑分析 :
pd.to_datetime()将字符串转换为日期类型。
dt.strftime()指定输出的日期格式。通过乘法运算将千克转换为克。
数据清洗流程图(mermaid)
数据清洗常见问题与处理策略(表格)
| 问题类型 | 常见场景 | 处理策略 |
|---|---|---|
| 缺失值 | 用户未填写、系统错误 | 填充默认值、插值法、删除记录 |
| 异常值 | 错误输入、极端情况 | 统计检测、人工审核、剔除或修正 |
| 重复数据 | 导入重复、系统故障 | 去重操作、主键校验 |
| 格式不统一 | 不同系统输出格式不一致 | 统一字段命名、单位转换、标准化处理 |
3.2 数据转换的常用方法
数据转换是将清洗后的数据按照业务需求进行加工,使其符合目标结构和业务逻辑。常见的转换方法包括聚合、拆分、映射操作,维度建模及SQL在数据转换中的应用。
3.2.1 聚合、拆分与映射操作
- 聚合操作 :用于将数据按某个维度进行汇总,如求和、平均值、计数等。
sql
-- SQL中使用GROUP BY进行聚合
SELECT department, AVG(salary) AS avg_salary
FROM employees
GROUP BY department;逻辑分析 :
GROUP BY department按部门分组。
AVG(salary)计算每个部门的平均工资。
- 拆分操作 :将一个字段拆分为多个字段,常用于处理复合字段。
python
# 使用str.split()拆分姓名字段
df[['first_name', 'last_name']] = df['full_name'].str.split(' ', expand=True)逻辑分析 :
str.split()方法按空格分割姓名。
expand=True表示拆分为多列。
- 映射操作 :将字段值映射到另一个值域,如将地区编码映射为地区名称。
python
# 使用map()进行映射
mapping = {'010': '北京', '021': '上海', '020': '广州'}
df['city'] = df['area_code'].map(mapping)逻辑分析 :
map()方法根据字典进行值映射。如果找不到映射关系,返回
NaN。
3.2.2 维度建模与缓慢变化维度处理
维度建模是数据仓库中常见的建模方式,主要分为星型模型和雪花模型。在维度建模中,处理缓慢变化维度(Slowly Changing Dimension, SCD)是关键问题。
- SCD类型1 :覆盖旧值,不保留历史。
- SCD类型2 :增加新记录,保留历史。
- SCD类型3 :添加字段保留部分历史。
sql
-- SCD类型2示例
INSERT INTO dim_customer
(customer_id, customer_name, address, start_date, end_date)
SELECT
customer_id,
new_name,
new_address,
CURRENT_DATE,
'9999-12-31'
FROM
temp_customer
WHERE
change_flag = 1;逻辑分析 :
当客户信息变更时,插入新记录并设置
end_date为未来日期。原记录的
end_date设置为变更日期前一日。
3.2.3 SQL在数据转换中的应用
SQL是数据转换中最为广泛使用的语言之一,支持复杂的逻辑处理、多表关联、条件判断等。
sql
-- 使用CASE语句进行条件转换
SELECT
product_id,
product_name,
CASE
WHEN price > 100 THEN '高价位'
WHEN price BETWEEN 50 AND 100 THEN '中价位'
ELSE '低价位'
END AS price_category
FROM products;逻辑分析 :
CASE语句实现价格区间的分类。将连续的价格数据转换为离散的类别。
数据转换流程图(mermaid)
数据转换方法对比(表格)
| 转换方法 | 适用场景 | 优点 | 缺点 |
|---|---|---|---|
| 聚合 | 汇总统计、报表生成 | 简洁高效,易于理解 | 丢失细节信息 |
| 拆分 | 复合字段处理 | 提高字段粒度 | 增加字段数量 |
| 映射 | 编码转义、字段标准化 | 提高数据可读性 | 依赖映射表维护 |
| 维度建模 | 数据仓库结构设计 | 支持复杂分析查询 | 设计复杂,需考虑SCD处理 |
3.3 数据质量保障机制
数据质量是数据仓库成功与否的关键因素之一。良好的数据质量保障机制包括数据质量评估标准、清洗规则的制定与自动化。
3.3.1 数据质量评估标准
数据质量评估通常从以下几个维度进行:
- 完整性 :数据是否完整无缺。
- 准确性 :数据是否真实反映业务情况。
- 一致性 :数据在不同系统间是否一致。
- 唯一性 :是否存在重复数据。
- 及时性 :数据是否及时更新。
python
# 示例:评估数据完整性
missing_rate = df.isnull().sum() / len(df)
print("字段缺失率:\n", missing_rate)逻辑分析 :
isnull().sum()计算每个字段的缺失数量。除以总行数得到缺失率,用于评估完整性。
3.3.2 清洗规则的制定与自动化
清洗规则的制定应基于业务需求,包括字段格式、取值范围、唯一性约束等。自动化清洗可以通过脚本或ETL工具实现。
python
# 自动化清洗示例:校验手机号格式
import re
def validate_phone(phone):
pattern = r'^1[3-9]\d{9}$'
return bool(re.match(pattern, phone))
df['valid_phone'] = df['phone'].apply(validate_phone)
df = df[df['valid_phone']]逻辑分析 :
使用正则表达式校验手机号格式是否合法。
apply()方法对每一行应用校验函数。过滤掉非法手机号记录。
数据质量保障流程图(mermaid)
数据质量指标示例(表格)
| 指标名称 | 描述 | 计算方式 |
|---|---|---|
| 完整性 | 字段缺失比例 | 缺失值数量 / 总记录数 |
| 准确性 | 数据是否符合业务逻辑 | 人工抽检或规则校验 |
| 一致性 | 多源数据是否一致 | 数据比对 |
| 唯一性 | 是否存在重复记录 | 去重前后记录数对比 |
| 及时性 | 数据更新延迟时间 | 当前时间 - 数据更新时间 |
3.4 转换过程的性能优化
在处理大规模数据时,转换过程的性能至关重要。性能优化主要包括并行处理、缓存机制以及复杂转换逻辑的拆分与重构。
3.4.1 并行处理与缓存机制
- 并行处理 :利用多线程或多进程加速数据转换。
python
from concurrent.futures import ThreadPoolExecutor
def process_chunk(chunk):
# 处理每个数据块
return chunk.apply(lambda x: x * 2)
# 分块处理
chunks = np.array_split(df, 4)
with ThreadPoolExecutor(max_workers=4) as executor:
results = list(executor.map(process_chunk, chunks))
df = pd.concat(results)逻辑分析 :
ThreadPoolExecutor实现多线程并行处理。将数据分成4块并行处理,提高效率。
- 缓存机制 :避免重复计算,使用内存缓存中间结果。
python
from functools import lru_cache
@lru_cache(maxsize=128)
def expensive_function(x):
# 模拟耗时计算
return x ** 2逻辑分析 :
lru_cache缓存函数结果,减少重复计算。
3.4.2 复杂转换逻辑的拆分与重构
复杂的转换逻辑应拆分为多个独立步骤,便于调试与优化。
python
# 拆分复杂转换逻辑
def step1(data):
return data[data['value'] > 0]
def step2(data):
return data.groupby('category').mean()
def step3(data):
return data.reset_index()
# 顺序执行
df = step1(df)
df = step2(df)
df = step3(df)逻辑分析 :
每个函数处理一个步骤,职责单一。
顺序调用便于维护和优化。
性能优化策略对比(表格)
| 优化策略 | 适用场景 | 优点 | 缺点 |
|---|---|---|---|
| 并行处理 | 大规模数据转换 | 显著提升处理速度 | 增加资源消耗 |
| 缓存机制 | 高频重复计算 | 减少重复计算时间 | 内存占用增加 |
| 拆分逻辑 | 复杂转换流程 | 提高可维护性 | 增加代码量 |
| 重构逻辑 | 性能瓶颈处 | 优化执行路径 | 开发成本较高 |
性能优化流程图(mermaid)
4. 数据加载策略与实现
数据加载是ETL流程的最终阶段,决定了数据是否能够高效、准确地写入目标系统,如数据仓库、数据湖或OLAP系统。在实际生产环境中,加载策略的选择不仅影响数据的可用性,还直接关系到系统的性能、稳定性和一致性。本章将从加载的基本模式入手,深入探讨不同数据结构的加载策略、加载过程中的事务机制以及性能调优技巧,帮助读者构建完整的数据加载知识体系。
4.1 数据加载的基本模式
数据加载方式主要分为 批量加载 和 实时加载 两大类,其选择取决于业务需求、数据量大小、系统资源以及数据时效性要求。
4.1.1 批量加载与实时加载的适用场景
| 加载类型 | 特点 | 适用场景 | 优缺点 |
|---|---|---|---|
| 批量加载 | 定期执行、数据量大、延迟高 | 日终报表、月结统计、数据归档 | 优点:资源利用率高,适合大规模数据;缺点:实时性差 |
| 实时加载 | 数据流处理、延迟低、并发高 | 实时监控、预警系统、在线分析 | 优点:数据新鲜度高;缺点:资源消耗大,系统复杂度高 |
代码示例:使用 Sqoop 进行批量加载
bash
sqoop import \
--connect jdbc:mysql://localhost:3306/source_db \
--username root \
--password password \
--table sales_data \
--target-dir /user/hive/warehouse/sales \
--fields-terminated-by ',' \
--lines-terminated-by '\n' \
--num-mappers 4代码解析:
-
--connect:指定源数据库的JDBC连接地址。 -
--table sales_data:要导入的数据表名。 -
--target-dir:HDFS目标路径,用于存储加载后的数据。 -
--fields-terminated-by和--lines-terminated-by:定义字段和行的分隔符。 -
--num-mappers 4:设置并行度,提升批量加载性能。
适用场景分析:
-
适用于每日或每小时执行的批量任务,如销售数据汇总、库存更新等。
-
优点是可控制性强,便于调度和监控。
4.1.2 数据加载的频率与调度机制
数据加载的频率决定了数据的"新鲜度"。常见的调度机制包括:
- 定时调度 :通过 Cron、Airflow 等工具定期执行。
- 事件驱动 :基于 Kafka、Debezium 等实时数据流技术,当数据发生变化时触发加载。
- 混合模式 :部分数据实时加载,部分数据批量加载。
Mermaid 流程图:调度机制对比
调度机制的选择建议:
-
业务要求数据实时性强时,优先考虑事件驱动机制。
-
若系统资源有限或数据变化频率低,推荐使用定时调度。
-
对于关键数据,可采用混合调度策略,兼顾性能与实时性。
4.2 数据目标结构与加载方式
数据加载的目标结构通常包括 星型模型 、 雪花模型 、 数据仓库 和 数据湖 等。不同的目标结构决定了加载方式的选择和优化策略。
4.2.1 星型模型与雪花模型的加载策略
星型模型(Star Schema)和雪花模型(Snowflake Schema)是数据仓库中最常见的两种建模方式。
| 模型类型 | 结构特点 | 加载策略 | 优缺点 |
|---|---|---|---|
| 星型模型 | 事实表为中心,维度表直接连接 | 分步加载事实表和维度表 | 优点:查询效率高;缺点:冗余数据多 |
| 雪花模型 | 维度表进一步规范化 | 层级加载,先加载父维度,再加载子维度 | 优点:节省存储空间;缺点:查询复杂度高 |
SQL 示例:加载事实表与维度表
sql
-- 先加载时间维度表
INSERT INTO dim_date (date_id, date, year, month, day)
SELECT
date_id,
date,
EXTRACT(YEAR FROM date) AS year,
EXTRACT(MONTH FROM date) AS month,
EXTRACT(DAY FROM date) AS day
FROM raw_dates;
-- 再加载销售事实表
INSERT INTO fact_sales (sale_id, product_id, date_id, amount)
SELECT
sale_id,
product_id,
d.date_id,
amount
FROM raw_sales s
JOIN dim_date d ON s.sale_date = d.date;逻辑分析:
-
第一步先加载维度表,确保事实表可以正确关联。
-
第二步通过
JOIN操作将原始销售数据与时间维度关联后写入事实表。 -
采用分步加载有助于保证数据一致性,避免外键约束失败。
4.2.2 数据仓库与数据湖的加载差异
| 目标结构 | 存储特点 | 加载方式 | 适用场景 |
|---|---|---|---|
| 数据仓库 | 结构化、模式固定 | ETL后加载结构化数据 | BI分析、报表系统 |
| 数据湖 | 半结构化/非结构化、模式灵活 | ELT模式,先加载后处理 | 大数据分析、AI训练 |
表格对比:数据仓库与数据湖加载差异
| 维度 | 数据仓库 | 数据湖 |
|---|---|---|
| 数据格式 | 固定模式 | 灵活模式 |
| 加载方式 | ETL(抽取-转换-加载) | ELT(抽取-加载-转换) |
| 工具 | Hive、Snowflake | Delta Lake、Iceberg |
| 性能 | 查询快 | 写入快,读取慢 |
| 适用人群 | BI分析师 | 数据科学家、AI工程师 |
实践建议:
-
对于结构化数据,优先使用数据仓库进行加载,以支持高效查询。
-
对于非结构化数据或需要灵活处理的数据,推荐使用数据湖加载策略。
-
使用 Delta Lake 等格式可兼顾数据湖的灵活性与数据仓库的查询性能。
4.3 加载过程中的事务与一致性保障
在数据加载过程中,保障数据的一致性至关重要。特别是在分布式系统中,数据可能分散在多个节点上,事务控制和错误处理机制是保障数据完整性的关键。
4.3.1 ACID特性与数据一致性机制
ACID 是数据库事务处理的四大基本特性:
- A(原子性) :事务要么全部成功,要么全部失败。
- C(一致性) :事务执行前后,数据库的完整性约束不变。
- I(隔离性) :多个事务并发执行时,互不干扰。
- D(持久性) :事务一旦提交,结果将永久保存。
示例:使用 PostgreSQL 实现事务控制
sql
BEGIN;
-- 插入用户数据
INSERT INTO users (id, name, email) VALUES (1, 'Alice', 'alice@example.com');
-- 插入订单数据
INSERT INTO orders (order_id, user_id, amount) VALUES (101, 1, 200.00);
-- 提交事务
COMMIT;逻辑分析:
-
使用
BEGIN启动一个事务。 -
两个插入操作在同一个事务中执行。
-
若任意一步失败,可以通过
ROLLBACK回滚,保证数据一致性。
事务控制建议:
-
在加载数据前开启事务,避免脏数据写入。
-
在关键表操作中使用显式事务控制,如订单、用户等。
-
对于大批量加载任务,可采用分批次提交,降低锁竞争。
4.3.2 错误处理与回滚策略
在数据加载过程中,错误可能来源于网络中断、字段类型不匹配、主键冲突等。有效的错误处理机制应包括:
- 日志记录 :详细记录每一步操作的日志,便于排查问题。
- 部分回滚 :对失败的批次进行回滚,不影响已完成的部分。
- 重试机制 :对临时性错误(如网络波动)进行自动重试。
代码示例:使用 Python 脚本处理加载错误
python
import psycopg2
try:
conn = psycopg2.connect("dbname=test user=postgres password=secret")
cur = conn.cursor()
cur.execute("INSERT INTO users (id, name) VALUES (1, 'John')")
cur.execute("INSERT INTO users (id, name) VALUES (1, 'Jane')") # 主键冲突
conn.commit()
except Exception as e:
print("发生错误,执行回滚:", e)
conn.rollback()
finally:
cur.close()
conn.close()代码逻辑分析:
-
使用
try-except捕获异常。 -
当主键冲突时,
rollback()保证事务回滚。 -
最后关闭数据库连接,释放资源。
错误处理建议:
-
对于关键任务,设置自动重试次数,如3次。
-
对于不可恢复错误(如字段类型错误),应记录并通知开发人员。
-
使用日志工具(如 Log4j、ELK)集中管理加载日志。
4.4 加载性能调优
数据加载性能直接影响ETL任务的整体执行效率。在大数据环境中,性能调优可以从索引管理、分区策略、并发加载等多个方面入手。
4.4.1 索引管理与分区策略
索引可以加速查询,但在加载过程中会增加写入负担。合理的索引策略应在加载完成后创建,而非加载前。
分区策略示例:按时间分区
sql
-- 创建按月份分区的表
CREATE TABLE sales_data (
id INT,
amount DECIMAL(10,2),
sale_date DATE
) PARTITION BY RANGE (YEAR(sale_date) * 100 + MONTH(sale_date));
-- 创建2023年1月的分区
CREATE TABLE sales_data_202301 PARTITION OF sales_data
FOR VALUES FROM (202301) TO (202302);逻辑分析:
-
使用
PARTITION BY RANGE按年月分区。 -
每个分区独立存储,提升查询和加载效率。
-
分区策略可减少全表扫描,提升性能。
索引优化建议:
-
加载前禁用索引,加载完成后重建。
-
对于频繁查询的字段(如时间、用户ID)建立索引。
-
使用复合索引提高多条件查询效率。
4.4.2 并发加载与锁机制优化
在高并发加载场景下,锁机制可能会成为性能瓶颈。通过调整并发策略和锁粒度,可以有效提升加载效率。
示例:使用 Hive 多任务并发加载
sql
-- 启用动态分区并发加载
SET hive.exec.dynamic.partition.mode=nonstrict;
SET hive.exec.parallel=true;
INSERT OVERWRITE TABLE sales PARTITION (dt)
SELECT *, sale_date as dt FROM raw_sales;参数说明:
-
hive.exec.parallel=true:启用并行执行任务。 -
dynamic.partition.mode=nonstrict:允许动态分区插入。 -
该策略适用于Hive中多分区并行加载场景。
锁机制优化建议:
-
避免在同一时间对同一表进行大量写入操作。
-
使用乐观锁或版本控制机制处理并发更新。
-
对于读写密集型任务,使用写锁或行级锁减少阻塞。
本章深入讲解了数据加载的策略与实现方法,涵盖了批量与实时加载的适用场景、目标结构的加载方式、事务控制机制以及性能调优技巧。下一章将围绕ETL系统的设计原则与面试准备策略展开,帮助读者从工程实践与职业发展两个维度全面提升能力。
5. ETL设计原则与面试准备策略
5.1 ETL系统设计的核心原则
在构建高效、稳定的ETL系统时,设计原则起着至关重要的作用。一个优秀的ETL架构不仅需要满足当前业务需求,还应具备良好的扩展性、容错能力和性能表现。以下是ETL系统设计中必须遵循的四个核心原则:
5.1.1 数据质量保障机制
数据质量是ETL流程的生命线。设计时应从以下方面入手:
- 数据清洗规则 :在ETL流程中嵌入数据清洗步骤,如处理缺失值、去除重复记录、修正非法字符等。
- 数据验证机制 :在数据加载前进行数据完整性、一致性校验,如外键约束检查、业务规则验证等。
- 质量监控仪表盘 :建立数据质量评分体系,通过日志和报表实时监控数据健康状况。
sql
-- 示例:SQL清洗缺失值
UPDATE sales_data
SET customer_id = -1
WHERE customer_id IS NULL;代码说明 :将
customer_id为空的记录替换为默认值(如-1),以便在后续分析中识别异常数据。
5.1.2 可扩展性与灵活性设计
ETL系统应具备良好的扩展性,以应对未来数据量增长和业务逻辑变化。设计时应考虑:
- 模块化设计 :将抽取、转换、加载各阶段模块化,便于替换或升级。
- 参数化配置 :使用配置文件管理数据源、目标、调度频率等参数,避免硬编码。
- 支持多种数据源与目标 :系统应支持关系型数据库、NoSQL、API、文件系统等多种数据源与目标。
5.1.3 性能优化与资源管理
ETL系统的性能直接影响整体数据处理效率。优化手段包括:
- 并行处理 :对可并行执行的步骤进行任务拆分,如并行抽取多个分区表。
- 缓存机制 :利用内存缓存中间结果,减少重复计算。
- 资源调度 :合理分配CPU、内存资源,避免资源争用。
python
# 示例:使用Python并发处理多个数据源
import concurrent.futures
def extract_data(source):
print(f"Extracting data from {source}")
# 模拟数据抽取逻辑
return f"{source} data"
sources = ["Oracle", "MySQL", "PostgreSQL"]
with concurrent.futures.ThreadPoolExecutor() as executor:
results = list(executor.map(extract_data, sources))代码说明 :使用
ThreadPoolExecutor并发执行数据抽取任务,提高效率。
5.1.4 容错机制与日志管理
为了保障系统的稳定运行,需设计完善的容错与日志机制:
- 任务重试机制 :对于临时性错误(如网络中断),支持任务自动重试。
- 断点续传 :在任务失败时,能够从断点继续执行,避免重复处理。
- 详细日志记录 :记录每个ETL阶段的执行时间、状态、错误信息,便于排查问题。
5.2 ETL常用工具对比与选型
在实际项目中,选择合适的ETL工具对效率和维护成本有直接影响。以下是四种主流ETL工具的功能对比:
| 工具名称 | 类型 | 适用场景 | 优点 | 缺点 |
|---|---|---|---|---|
| Talend | 开源/商业 | 中小型项目、云集成 | 图形化界面、支持多平台 | 社区版功能有限 |
| Informatica | 商业 | 大型企业、复杂数据集成 | 强大的数据映射与调度能力 | 成本高,学习曲线陡峭 |
| SSIS(SQL Server Integration Services) | 商业 | Microsoft生态体系集成 | 与SQL Server无缝集成 | 跨平台支持差 |
| Apache NiFi | 开源 | 实时流数据处理、可视化数据流 | 支持流式数据、易于配置 | 高并发场景下性能受限 |
5.2.1 开源工具与商业工具的优劣分析
- 开源工具 :如Talend Open Studio、Apache NiFi,适合预算有限、技术团队较强的组织。它们具备良好的可定制性,但技术支持和企业级功能有限。
- 商业工具 :如Informatica PowerCenter、Microsoft SSIS,适合大型企业,提供完善的技术支持、监控和调度功能,但授权成本较高,部署复杂。
选型建议 :
中小型项目优先考虑Talend或NiFi;
大型企业建议使用Informatica或SSIS;
若需实时流处理,优先考虑NiFi或Kafka+Spark Streaming组合方案。
5.3 ETL面试题解析与应对思路
在ETL相关的技术面试中,面试官通常会围绕技术原理、系统设计、实际项目经验等方面提问。以下是常见题型及应对思路:
5.3.1 常见技术类面试题及答题要点
Q:ETL过程中如何处理增量数据?
- 答题思路 :说明使用时间戳、触发器、CDC(变更数据捕获)等方法实现增量抽取,并结合日志或快照表进行数据比对。
Q:如何优化ETL流程的性能?
- 答题思路 :提出并行处理、索引优化、缓存中间结果、压缩数据传输等策略,并结合实际项目举例说明。
5.3.2 设计类问题的解题逻辑与表达技巧
Q:请设计一个ETL流程,从多个数据源提取销售数据,加载到数据仓库中。
- 答题结构 :
-
明确数据源类型(如数据库、API、CSV文件)
-
说明抽取方式(增量/全量)
-
描述清洗和转换逻辑(如格式标准化、维度建模)
-
设计加载策略(如星型模型加载事实表与维度表)
-
提出性能优化与容错机制
表达技巧 :使用流程图或伪代码辅助说明,逻辑清晰、重点突出。
5.3.3 行为面试题的准备与案例组织
Q:请分享一次你在ETL项目中遇到的最大挑战及解决方法。
-
答题技巧 :
-
使用STAR法则(Situation, Task, Action, Result)结构化表达
-
突出技术难点与解决思路
-
展示团队协作与沟通能力
示例 :
Situation:项目中多个数据源存在不一致的时间格式
Task:需统一时间维度用于报表分析
Action:在ETL流程中增加时间标准化步骤,并建立规则引擎
Result:提升数据一致性,报表准确率提升95%
5.4 实战经验分享与面试准备建议
5.4.1 项目经验提炼与表达方法
在面试中,如何有效展示ETL项目经验是关键。建议:
- 突出技术亮点 :如使用NiFi实现实时数据流处理、通过SSIS实现高并发调度等。
- 量化成果 :如ETL流程优化后处理效率提升30%、数据一致性达到99.9%等。
- 结构化表达 :采用"背景→问题→解决→成果"结构进行陈述。
5.4.2 技术文档与简历优化建议
- 简历中突出关键词 :如ETL流程设计、数据清洗、维度建模、Talend/Informatica/SSIS/NiFi等工具使用经验。
- 撰写技术博客或GitHub项目 :展示ETL实战案例,如基于NiFi搭建实时ETL流水线。
- 准备项目文档 :整理项目背景、技术选型、架构图、性能指标等,作为面试参考资料。
5.4.3 面试模拟与反馈优化策略
- 模拟真实场景 :找同行或使用AI模拟面试,练习技术题与行为题。
- 记录与复盘 :录制模拟面试过程,分析表达逻辑、技术深度与沟通技巧。
- 持续优化 :根据反馈调整回答结构、补充技术细节,增强自信与应变能力。
示例面试准备流程图 :
流程说明 :该流程图展示了从准备到实战的完整ETL面试准备路径,帮助候选人系统化提升面试能力。
简介:ETL(抽取-转换-加载)是构建数据仓库的核心流程,涵盖数据抽取、清洗转换和加载到目标系统的全过程。本文围绕两套高频ETL面试题展开,深入解析ETL流程、常用工具、设计原则及常见问题应对策略。通过真实项目案例与实战经验,帮助读者掌握ETL核心技术,提升面试通过率与数据处理能力。