
简介:逻辑回归是一种广泛应用于二分类问题的概率模型,尽管名称中包含"回归",实则为经典分类算法。本文详细介绍了如何使用Python及scikit-learn库实现逻辑回归的完整流程,涵盖环境搭建、数据预处理、模型训练、评估与优化等关键步骤。通过实际代码示例,帮助读者掌握从数据清洗到交叉验证的全过程,并可扩展至多分类与大规模数据场景,适用于机器学习初学者和实践者快速上手。
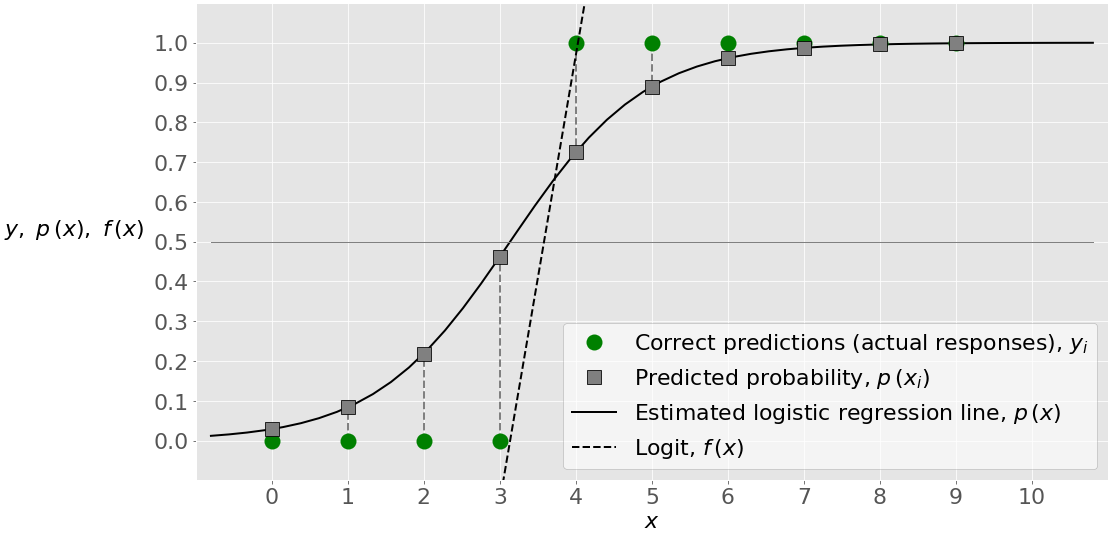
1. 逻辑回归算法原理与应用场景
逻辑回归的基本数学原理
逻辑回归虽名为"回归",实为经典的二分类算法。其核心思想是通过线性组合特征输入 z = w\^T x + b ,再将结果输入 Sigmoid函数 :
\sigma(z) = \frac{1}{1 + e^{-z}}
输出值落在 (0,1) 区间,可解释为样本属于正类的概率。 为学习最优权重 $ w $ 和偏置 $ b $,采用 **对数损失函数(Log Loss)** : J(w,b) = -\\frac{1}{m} \\sum_{i=1}\^{m} \\left\[ y_i \\log(\\hat{y}_i) + (1 - y_i)\\log(1 - \\hat{y}_i) \\right\]
并通过 梯度下降法 迭代更新参数,最小化损失。
应用场景与实际案例
逻辑回归因其可解释性强、训练高效,在金融、医疗、互联网等领域广泛应用:
-
信用评分 :银行利用用户收入、负债等特征预测违约概率;
-
医疗诊断 :基于体检指标判断是否患有某疾病(如糖尿病);
-
用户行为预测 :电商平台预测用户是否会购买某商品。
这些场景共同特点是:需输出概率、强调模型透明性,且特征以结构化数据为主,为后续Python实践奠定理论基础。
2. Python环境配置与数据预处理基础
在现代数据科学和机器学习项目中,构建一个稳定、可复用且高效的开发环境是成功实施模型训练与部署的第一步。Python作为当前最主流的编程语言之一,凭借其丰富的第三方库支持、简洁语法以及活跃的社区生态,成为数据分析与建模的首选工具。本章将系统性地介绍如何搭建适合逻辑回归及其他机器学习任务的Python开发环境,并深入讲解数据预处理的基础操作,涵盖从环境配置到原始数据加载的完整流程。
良好的环境管理不仅能避免依赖冲突,还能提升项目的可移植性和协作效率。与此同时,真实世界的数据往往存在格式不统一、缺失、噪声等问题,因此掌握数据导入与初步解析技能至关重要。通过本章的学习,读者将能够独立完成从零开始的环境搭建,熟练使用核心数据处理库读取多种格式的数据文件,并为后续章节中的清洗、特征工程和建模打下坚实的技术基础。
2.1 开发环境搭建
构建一个健壮的Python开发环境是进行任何数据科学项目的基础。许多初学者常常直接在系统全局环境中安装包,导致不同项目之间出现版本冲突或依赖混乱。为避免此类问题,必须采用科学的环境管理策略,确保每个项目拥有独立、隔离的运行环境。本节将详细介绍Python版本选择、主流开发工具配置以及虚拟环境的创建与管理方法。
2.1.1 Python版本选择与安装
目前,Python有两个主要版本系列:Python 2 和 Python 3。由于 Python 2 已于 2020 年停止官方维护,所有新项目都应使用 Python 3 ,推荐版本为 Python 3.8 至 3.11 之间的稳定发行版。这些版本对机器学习库(如 NumPy、Pandas、Scikit-learn)提供了最佳兼容性,同时具备良好的性能优化。
以 Windows 系统为例,安装步骤如下:
- 访问 https://www.python.org/downloads/ 下载对应操作系统的安装包。
- 勾选"Add Python to PATH"选项,以便在命令行中直接调用
python和pip。 - 安装完成后,在终端执行以下命令验证安装是否成功:
bash
python --version
pip --version预期输出示例:
Python 3.9.16
pip 23.0.1 from C:\Python39\lib\site-packages\pip (python 3.9)参数说明 :
--version:用于查看程序版本信息。若提示"不是内部或外部命令",说明未正确添加至系统PATH,需手动配置环境变量。
对于 macOS 用户,可通过 Homebrew 安装:
bash
brew install python@3.9Linux 用户(Ubuntu/Debian)可使用 APT 包管理器:
bash
sudo apt update
sudo apt install python3.9 python3-pip无论哪种方式,关键是确保所安装的 Python 版本满足后续库的最低要求。例如,Scikit-learn 1.3+ 要求 Python ≥ 3.8。
2.1.2 Jupyter Notebook与PyCharm开发工具配置
开发工具的选择直接影响编码效率与调试体验。在数据科学领域, Jupyter Notebook 和 PyCharm 是两类最具代表性的工具,分别适用于探索性分析与工程化开发。
Jupyter Notebook 配置
Jupyter Notebook 提供交互式编程界面,非常适合数据探索、可视化和快速原型设计。安装方式如下:
bash
pip install jupyter notebook启动服务:
bash
jupyter notebook该命令会在默认浏览器中打开 Web 界面,默认监听 http://localhost:8888 。用户可在其中创建 .ipynb 文件,逐块执行代码并嵌入 Markdown 文档说明。
优势分析 :
支持实时输出图表(配合 Matplotlib/Seaborn)
易于分享分析过程(导出为 HTML/PDF)
内核支持多语言(Python/R/Julia)
PyCharm 配置
PyCharm 是 JetBrains 推出的专业 Python IDE,尤其适合大型项目开发。社区版免费,专业版提供远程调试、数据库工具等高级功能。
安装后配置步骤:
-
打开 PyCharm → Create New Project
-
设置项目路径与解释器(Interpreter),建议指向虚拟环境中的 Python 可执行文件
-
安装必要插件:Python、Scientific Mode、Jupyter Support
两者对比见下表:
| 特性 | Jupyter Notebook | PyCharm |
|---|---|---|
| 适用场景 | 探索性分析、教学演示 | 工程开发、团队协作 |
| 调试能力 | 弱(依赖 print/log) | 强(断点调试、变量监视) |
| 项目结构管理 | 松散(单个 notebook) | 规范(模块化组织) |
| 版本控制友好度 | 中等(diff 显示不佳) | 高(集成 Git) |
| 学习曲线 | 低 | 中高 |
推荐组合使用:前期用 Jupyter 进行数据探索,后期迁移到 PyCharm 实现模块化封装。
2.1.3 虚拟环境管理(conda/virtualenv)
为了避免不同项目间依赖冲突,必须使用虚拟环境技术实现依赖隔离。
使用 virtualenv 创建虚拟环境
bash
# 安装 virtualenv
pip install virtualenv
# 创建名为 ml_env 的虚拟环境
python -m venv ml_env
# 激活环境(Windows)
ml_env\Scripts\activate
# 激活环境(macOS/Linux)
source ml_env/bin/activate
# 查看当前 Python 解释器路径
which python激活后,所有通过 pip install 安装的包仅存在于该环境中,不会影响全局或其他项目。
使用 Conda 管理环境(推荐用于数据科学)
Conda 是 Anaconda 发行版自带的包与环境管理器,能同时管理 Python 包和其他非 Python 依赖(如 R、C++ 库)。
bash
# 创建带指定 Python 版本的环境
conda create -n logit_env python=3.9
# 激活环境
conda activate logit_env
# 安装常用库
conda install numpy pandas scikit-learn jupyter
# 导出环境配置(便于共享)
conda env export > environment.ymlenvironment.yml 示例内容:
yaml
name: logit_env
channels:
- defaults
dependencies:
- python=3.9
- numpy
- pandas
- scikit-learn
- jupyter他人可通过 conda env create -f environment.yml 快速重建相同环境。
以下是两种工具的对比流程图:
逻辑分析 :
流程图清晰展示了两种环境搭建路径的关键决策点与操作顺序。Conda 更适合初学者和复杂依赖场景,而
virtualenv+pip组合更轻量,适合已有 Python 基础的开发者。
2.2 依赖库的安装与使用
为了高效处理数据并实现逻辑回归模型,必须掌握几个核心 Python 库的基本用法。本节重点介绍 NumPy、Pandas 和 Scikit-learn 的安装方式及其基本功能,辅以代码示例帮助理解其在数据预处理中的实际应用。
2.2.1 NumPy:数组与矩阵运算基础
NumPy 是 Python 科学计算的核心库,提供高性能的多维数组对象 ndarray 及丰富的数学函数。
安装命令:
bash
pip install numpy基本使用示例:
python
import numpy as np
# 创建一维数组
arr = np.array([1, 2, 3, 4])
print("一维数组:", arr)
# 创建二维矩阵
matrix = np.array([[1, 2], [3, 4]])
print("二维矩阵:\n", matrix)
# 数组属性
print("维度:", arr.ndim) # 1
print("形状:", matrix.shape) # (2, 2)
print("数据类型:", arr.dtype) # int64
# 向量化运算(无需循环)
squared = arr ** 2
print("平方结果:", squared) # [1 4 9 16]逐行解读 :
np.array()将列表转换为 NumPy 数组;
shape返回元组表示各轴长度;
**表示幂运算,NumPy 自动对每个元素广播操作;所有运算均在 C 层级执行,速度远超原生 Python 循环。
NumPy 还支持广播机制、切片、掩码索引等高级操作,是 Pandas 的底层支撑。
2.2.2 Pandas:DataFrame结构与数据操作
Pandas 构建于 NumPy 之上,提供了类似电子表格的 DataFrame 数据结构,极大简化了结构化数据的操作。
安装:
bash
pip install pandas基本操作示例:
python
import pandas as pd
# 创建 DataFrame
data = {
'Name': ['Alice', 'Bob', 'Charlie'],
'Age': [25, 30, 35],
'City': ['Beijing', 'Shanghai', 'Guangzhou']
}
df = pd.DataFrame(data)
print(df)
# 常用操作
print("\n第一行:")
print(df.iloc[0])
print("\n年龄大于28的记录:")
print(df[df['Age'] > 28])
print("\n描述性统计:")
print(df.describe())输出:
Name Age City
0 Alice 25 Beijing
1 Bob 30 Shanghai
2 Charlie 35 Guangzhou
第一行:
Name Alice
Age 25
City Beijing
Name: 0, dtype: object
年龄大于28的记录:
Name Age City
1 Bob 30 Shanghai
2 Charlie 35 Guangzhou
描述性统计:
Age
count 3.000000
mean 30.000000
std 5.000000
min 25.000000
25% 27.500000
50% 30.000000
75% 32.500000
max 35.000000参数说明 :
iloc[]:按整数位置索引;布尔索引
df[condition]返回满足条件的行;
describe()自动生成数值列的统计摘要。
Pandas 的强大之处在于其灵活的数据筛选、分组聚合( groupby )、合并( merge )等功能,是数据预处理阶段不可或缺的工具。
2.2.3 Scikit-learn:机器学习工具包简介
Scikit-learn 是基于 NumPy、SciPy 和 Matplotlib 构建的开源机器学习库,封装了大量经典算法,接口统一易用。
安装:
bash
pip install scikit-learn简单示例:加载内置数据集并查看基本信息
python
from sklearn.datasets import load_breast_cancer
# 加载乳腺癌数据集
data = load_breast_cancer()
X = data.data # 特征矩阵 (569 x 30)
y = data.target # 标签向量 (569,)
print("特征数量:", X.shape[1])
print("样本数量:", X.shape[0])
print("类别标签:", data.target_names)
print("特征名称前5个:", data.feature_names[:5])输出:
特征数量: 30
样本数量: 569
类别标签: ['malignant' 'benign']
特征名称前5个: ['mean radius' 'mean texture' 'mean perimeter' 'mean area'
'mean smoothness']逻辑分析 :
load_breast_cancer()返回字典式对象,包含.data,.target,.feature_names等属性;此数据集常用于二分类任务,目标是根据细胞特征判断肿瘤良恶性;
特征已标准化处理,可直接用于模型训练。
Scikit-learn 的设计哲学是"一致性",所有模型遵循 fit() , predict() , transform() 等标准接口,极大降低了学习成本。
2.3 数据导入与格式解析
真实项目中,数据通常存储在外部文件中,如 CSV、Excel、JSON 或数据库。能否准确高效地加载这些数据,是进入建模流程的前提。本节详细讲解如何使用 Pandas 从常见格式中读取数据,并进行初步的类型检查与格式转换。
2.3.1 从CSV文件中读取数据(pd.read_csv)
CSV(Comma-Separated Values)是最常见的文本数据格式,广泛用于数据交换。
假设有一个名为 customer_data.csv 的文件,内容如下:
id,name,age,income,purchased
1,Alice,28,50000,1
2,Bob,35,70000,0
3,Charlie,,60000,1
4,Diana,29,55000,读取代码:
python
import pandas as pd
df = pd.read_csv('customer_data.csv')
print(df.head())常用参数说明:
| 参数 | 作用 | 示例 |
|---|---|---|
sep |
指定分隔符 | sep=';' |
header |
指定哪一行作列名 | header=0 (默认) |
index_col |
设定索引列 | index_col='id' |
na_values |
自定义缺失值标识 | na_values=['', 'NULL'] |
dtype |
强制指定列类型 | dtype={'age': 'int64'} |
增强版读取:
python
df = pd.read_csv(
'customer_data.csv',
index_col='id',
na_values=['', 'NULL'],
dtype={'purchased': 'Int64'} # 支持含 NaN 的整型
)
print(df.dtypes)逻辑分析 :
Int64是 Pandas 提供的可空整型,允许在整数列中保留NaN;
na_values可识别多种表示缺失的方式;设置
index_col可避免额外调用set_index()。
2.3.2 从Excel文件中读取数据(pd.read_excel)
Excel 文件( .xlsx )常用于企业报表,Pandas 支持直接读取。
python
# 读取第一个工作表
df_excel = pd.read_excel('sales_report.xlsx')
# 读取指定工作表
df_sheet2 = pd.read_excel('sales_report.xlsx', sheet_name='Q2')
# 读取多个工作表
dfs = pd.read_excel('sales_report.xlsx', sheet_name=None) # 返回字典
for name, sheet_df in dfs.items():
print(f"Sheet: {name}")
print(sheet_df.head())注意事项 :
需安装
openpyxl或xlrd引擎:pip install openpyxlExcel 支持公式、样式、多表,但解析速度慢于 CSV;
对于大文件,建议先导出为 CSV 再处理。
2.3.3 数据格式转换与数据类型检查
正确识别数据类型对后续建模至关重要。错误的类型可能导致内存浪费或计算错误。
python
# 检查数据类型
print(df.dtypes)
# 转换类型
df['age'] = pd.to_numeric(df['age'], errors='coerce') # 错误转为 NaN
df['name'] = df['name'].astype('category') # 分类变量节省内存
df['income'] = df['income'].astype('float32') # 降低精度节约空间
# 查看内存使用
print(df.memory_usage(deep=True))类型映射建议:
| 原始类型 | 推荐转换 | 说明 |
|---|---|---|
| 整数(无缺失) | int32 / int64 |
根据范围选择 |
| 整数(含缺失) | Int32 (注意大写) |
Pandas nullable 类型 |
| 浮点数 | float32 |
多数情况下足够 |
| 文本唯一值少 | category |
显著减少内存占用 |
| 时间字符串 | datetime64 |
使用 pd.to_datetime() 转换 |
python
# 示例:日期转换
df['signup_date'] = pd.to_datetime(df['signup_date'], format='%Y-%m-%d')扩展说明 :
使用
errors='coerce'可将无法解析的值自动设为NaT(时间缺失)或NaN,避免程序中断;format参数提高解析速度。
综上所述,合理的数据类型管理不仅提升运行效率,也为后续特征工程奠定基础。
3. 数据清洗与特征预处理
在机器学习建模过程中,原始数据往往存在噪声、缺失、不一致和格式混乱等问题。若直接将未经处理的数据输入模型,不仅可能导致训练失败,还会显著降低模型的预测性能。因此, 数据清洗与特征预处理 是构建高质量机器学习系统的基石环节。这一阶段的核心任务是从"脏数据"中提取出结构清晰、语义明确且适合建模的特征集。尤其对于逻辑回归这类对输入数据敏感的线性模型而言,良好的数据质量直接影响其收敛速度与泛化能力。
本章节系统地讲解从原始数据到可建模数据的完整转化流程,涵盖缺失值处理、异常值检测、重复记录识别等关键清洗步骤,并深入探讨分类变量编码、特征分离与标签映射等预处理技术。通过结合Pandas与Scikit-learn的实际操作示例,帮助读者掌握工业级数据准备的最佳实践路径。
3.1 数据清洗的核心步骤
数据清洗是数据预处理中最基础也是最关键的一步。它旨在发现并修正数据集中存在的错误或不合理信息,确保后续分析建立在可靠的数据基础之上。一个典型的数据清洗流程包括三个主要子过程: 缺失值处理、异常值检测与处理、以及重复数据去重 。这些操作虽然看似简单,但在实际项目中常常占据整个数据科学工作流的60%以上时间。
3.1.1 缺失值识别与处理策略(删除、填充、插值)
缺失值是指数据集中某些字段没有观测值的情况,通常以 NaN (Not a Number)表示。它们可能由于采集设备故障、用户未填写问卷、系统传输中断等原因产生。面对缺失值,首要任务是识别其分布模式。
使用Pandas可以快速统计每列的缺失情况:
python
import pandas as pd
# 示例数据加载
df = pd.read_csv("credit_data.csv")
# 查看各列缺失数量及占比
missing_info = pd.DataFrame({
'missing_count': df.isnull().sum(),
'missing_ratio': df.isnull().sum() / len(df)
})
print(missing_info[missing_info['missing_count'] > 0])| 字段名 | missing_count | missing_ratio |
|---|---|---|
| income | 150 | 0.15 |
| employment_years | 80 | 0.08 |
| credit_score | 20 | 0.02 |
代码逻辑逐行解析:
第4行:读取CSV文件生成DataFrame;
第7--9行:构造一个新的DataFrame,包含每列的缺失数量和比例;
isnull().sum()返回每列NaN的数量;除以
len(df)得到缺失率;最后筛选出至少有一个缺失值的列进行展示。
根据缺失比例和业务背景,选择合适的处理策略:
- 删除法 :当某列缺失率超过30%,且无法推断其意义时,建议直接删除该特征。
- 均值/中位数/众数填充 :适用于数值型或类别型变量,简单高效但可能引入偏差。
- 前向/后向填充(ffill/bfill) :适用于时间序列数据。
- 插值法 :利用相邻点之间的数学关系估算缺失值,如线性插值、样条插值。
例如,使用中位数填充收入字段:
python
df['income'].fillna(df['income'].median(), inplace=True)参数说明:
median()计算中位数,比均值更鲁棒;
inplace=True表示原地修改,避免创建新对象。
更高级的方法还包括基于回归、KNN或多重插补(MICE)的技术,可在 sklearn.impute 模块中实现:
python
from sklearn.impute import KNNImputer
imputer = KNNImputer(n_neighbors=5)
df[['income', 'credit_score']] = imputer.fit_transform(df[['income', 'credit_score']])该方法利用相似样本的k近邻来填补缺失值,适合多变量联合建模场景。
3.1.2 异常值检测方法(箱线图、Z-score)与处理策略
异常值(Outliers)指明显偏离大多数观测值的数据点,可能是录入错误、测量误差或真实极端事件的结果。若不加以处理,异常值会对模型参数估计造成严重干扰,尤其是逻辑回归这种基于梯度优化的方法。
常用检测方法有两种:
箱线图法(IQR Rule)
四分位距(Interquartile Range, IQR)定义为上四分位数(Q3)与下四分位数(Q1)之差。任何小于 Q1 - 1.5×IQR 或大于 Q3 + 1.5×IQR 的值被视为异常值。
python
def detect_outliers_iqr(series):
Q1 = series.quantile(0.25)
Q3 = series.quantile(0.75)
IQR = Q3 - Q1
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQR
return series[(series < lower_bound) | (series > upper_bound)]
outliers = detect_outliers_iqr(df['income'])
print(f"检测到 {len(outliers)} 个异常值")逻辑分析:
函数接受一个Series对象;
使用
quantile()计算Q1和Q3;构造上下边界;
返回落在区间外的所有值。
可视化可通过matplotlib绘制箱线图:
python
import matplotlib.pyplot as plt
plt.boxplot(df['income'])
plt.title("Income Distribution with Outliers")
plt.ylabel("Income")
plt.show()Z-Score法
Z-score衡量某个值距离均值的标准差数。一般认为|Z| > 3的数据为异常值。
python
from scipy import stats
import numpy as np
z_scores = np.abs(stats.zscore(df.select_dtypes(include=[np.number])))
outlier_indices = np.where(z_scores > 3)
print(f"共发现 {len(outlier_indices[0])} 个异常点")参数说明:
select_dtypes(include=[np.number])只选取数值型列;
stats.zscore对每列标准化;
np.abs取绝对值;
np.where找出满足条件的索引位置。
处理策略包括:
-
删除异常记录;
-
将其限制在合理范围内(Winsorization);
-
单独标记为特殊类别用于建模。
以下为不同方法对比表格:
| 方法 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| IQR | 不依赖正态分布,鲁棒性强 | 忽略多维相关性 | 单变量异常检测 |
| Z-Score | 数学解释清晰,易于实现 | 假设数据服从正态分布 | 多变量标准化后联合检测 |
| DBSCAN | 能发现任意形状簇中的离群点 | 参数敏感,计算复杂度较高 | 高维空间聚类式异常检测 |
此外,还可通过 流程图 直观展示异常值处理流程:
该流程体现了从方法选择到结果输出的完整决策路径。
3.1.3 重复数据处理与去重操作
重复数据指的是完全相同或高度相似的记录多次出现在数据集中。这可能源于数据库合并、爬虫重复抓取或人为误操作。
检测全表重复行:
python
duplicated_rows = df[df.duplicated()]
print(f"发现 {len(duplicated_rows)} 条完全重复的记录")
duplicated()默认保留首次出现的记录,其余标记为True。
若需基于部分关键字段判断重复(如身份证号+姓名),可指定子集:
python
duplicated_subset = df[df.duplicated(subset=['id', 'name'], keep=False)]参数说明:
subset指定用于判断重复的列;
keep=False表示所有重复项都标记为True,便于批量查看。
去重操作如下:
python
df_clean = df.drop_duplicates(subset=['id', 'name'], keep='first')
keep='first'保留第一次出现的记录,其余删除;也可设为last或False。
值得注意的是,在医疗或金融领域,即使字段值相同,也可能代表不同时间点的真实行为(如客户每月还款记录)。因此,去重前必须结合业务逻辑确认是否应保留时间维度信息。
综上所述,数据清洗不仅是技术操作,更是理解数据生成机制的过程。只有准确识别问题根源,才能制定合理的修复策略,为后续建模打下坚实基础。
3.2 特征编码与数值化转换
机器学习算法本质上只能处理数值型输入。然而,现实世界中的许多特征是以文本形式存在的分类变量(Categorical Variables),如性别、职业、地区等。因此,必须将这些非数值特征转化为数值表示,这一过程称为 特征编码 。不同的编码方式会影响模型的学习效率与表达能力,尤其在逻辑回归中,不当的编码可能导致虚假排序或维度爆炸。
3.2.1 分类变量的处理方法(Label Encoding、One-hot Encoding)
Label Encoding
Label Encoding 将每个类别映射为一个整数标签。例如:
| 职业 | 编码值 |
|---|---|
| 教师 | 0 |
| 医生 | 1 |
| 工程师 | 2 |
实现方式:
python
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
df['occupation_encoded'] = le.fit_transform(df['occupation'])
fit_transform()先拟合类别到数字的映射,再应用转换。
⚠️ 潜在问题 :Label Encoding 引入了人为的"顺序"关系。模型可能会误认为"工程师 > 医生 > 教师",从而赋予错误权重。因此,仅适用于有序类别(Ordinal),如学历等级(高中<本科<硕士)。
One-Hot Encoding
One-Hot Encoding 为每个类别创建一个新的二元特征列,值为0或1。避免引入顺序假设。
python
encoded = pd.get_dummies(df['occupation'], prefix='occ')
df = pd.concat([df, encoded], axis=1)结果如下:
| occ_教师 | occ_医生 | occ_工程师 |
|---|---|---|
| 1 | 0 | 0 |
| 0 | 1 | 0 |
| 0 | 0 | 1 |
prefix添加前缀以便区分来源字段。
优势在于无序类别间平等对待,适合逻辑回归等线性模型。但缺点是当类别数过多时会导致 维度灾难 。
3.2.2 使用Pandas实现One-hot编码(pd.get_dummies)
pd.get_dummies 是最常用的One-hot编码工具,支持自动处理DataFrame中的所有类别列。
python
# 自动对所有object类型列进行one-hot编码
df_encoded = pd.get_dummies(df, columns=['gender', 'region'], drop_first=True)参数说明:
columns明确指定要编码的列;
drop_first=True删除第一个类别作为基准组,防止多重共线性(Dummy Variable Trap);若不删除,则n个类别生成n列;删除后生成n-1列。
例如,性别有两个值(男、女),启用 drop_first 后只保留"gender_男"一列,"女"作为参考类别。
该操作极大简化了预处理流程,但仍需注意内存占用问题。对于高基数类别(如邮政编码、商品ID),不宜直接使用One-hot。
3.2.3 高维稀疏编码的优化策略
当类别数量极大(>1000)时,One-hot会产生大量稀疏列,导致内存消耗剧增、训练变慢。此时应采用以下优化策略:
目标编码(Target Encoding)
用目标变量的统计量(如均值)代替类别标签。例如,在信用评分任务中,可用每个职业对应的违约率作为编码值。
python
target_mean = df.groupby('occupation')['default'].mean()
df['occ_target_enc'] = df['occupation'].map(target_mean)注意:需在训练集上计算映射,避免数据泄露。
嵌入编码(Embedding Encoding)
借助神经网络将高维类别映射到低维稠密向量空间。虽常用于深度学习,但可通过预训练嵌入层导出特征供逻辑回归使用。
类别聚合(Category Aggregation)
将低频类别合并为"其他"类别:
python
freq = df['occupation'].value_counts()
mask = df['occupation'].isin(freq[freq < 10].index)
df['occupation'] = df['occupation'].where(~mask, 'Other')将出现次数少于10次的职业统一归为"Other"。
以下为不同编码方式的对比总结:
| 编码方式 | 是否引入顺序 | 维度增长 | 是否易过拟合 | 推荐使用场景 |
|---|---|---|---|---|
| Label Encoding | 是 | 无 | 中 | 有序类别(如评级) |
| One-Hot | 否 | O(n) | 低 | 低基数无序类别(≤10类) |
| Target Encoding | 否 | O(1) | 高(需交叉验证) | 高基数类别 + 足够样本 |
| Embedding | 否 | O(k) | 中 | 深度学习 pipeline |
同时,可通过流程图展示编码选择决策路径:
此图清晰展示了根据不同条件选择最优编码方案的逻辑链条。
3.3 特征与目标变量分离
完成数据清洗与特征编码后,下一步是将数据划分为 特征矩阵X 和 目标向量y ,这是几乎所有监督学习任务的标准输入格式。
3.3.1 数据集的特征列与标签列划分(X与y)
假设我们正在构建一个用户购买预测模型,原始数据包含多个字段:
| user_id | age | income | gender | region | purchase |
|---|---|---|---|---|---|
| 1 | 35 | 80000 | Male | North | 1 |
其中,"purchase"为目标变量(1表示购买,0表示未购买),其余为特征。
分离操作如下:
python
X = df.drop(columns=['purchase', 'user_id']) # 特征矩阵
y = df['purchase'] # 标签向量注意移除无关标识字段(如
user_id),否则可能引入信息泄露。
也可以通过列名列表显式选择:
python
feature_cols = ['age', 'income', 'gender_Male', 'region_North']
X = df[feature_cols]
y = df['purchase']推荐做法是在前期就定义好特征工程流水线,确保训练与推理时的一致性。
3.3.2 标签的二值化与类别映射
虽然目标变量常以0/1形式存在,但有时也会以字符串或其他格式存储,如"是/否"、"Yes/No"、"Positive/Negative"。
此时需要进行 标签二值化 :
python
from sklearn.preprocessing import LabelEncoder
le_y = LabelEncoder()
y_binary = le_y.fit_transform(df['purchase_status']) # 如 Yes->1, No->0也可手动映射:
python
label_map = {'No': 0, 'Yes': 1}
y = df['purchase_status'].map(label_map)
map()方法适用于已知映射关系的小规模转换。
若目标变量为多类别(如产品A/B/C),则属于多分类问题,将在第六章详细讨论。
此外,应检查标签分布是否均衡:
python
print(y.value_counts(normalize=True))输出示例:
0 0.85
1 0.15表明正负样本比例为8.5:1.5,存在 类别不平衡 问题。这会影响逻辑回归的阈值设定与评估指标选择,需在后续章节中引入SMOTE、加权损失等技术应对。
最终,完整的数据准备流程可归纳为如下表格:
| 步骤 | 工具/函数 | 输出形式 | 注意事项 |
|---|---|---|---|
| 缺失值处理 | fillna, KNNImputer | 完整数值矩阵 | 避免测试集信息泄露 |
| 异常值处理 | IQR, Z-score, clip | 干净数据集 | 结合业务判断是否保留 |
| 去重 | drop_duplicates | 无重复记录 | 考虑时间戳避免误删 |
| 分类编码 | get_dummies, LabelEncoder | 数值化特征矩阵 | 防止Dummy Variable Trap |
| 特征与标签分离 | drop(), column selection | X: DataFrame, y: Series | 移除唯一ID与目标变量 |
| 标签二值化 | map(), LabelEncoder | 0/1 向量 | 明确正类对应哪个原始值 |
至此,原始数据已完成向机器学习友好格式的全面转化,为下一阶段的模型训练奠定了坚实基础。
4. 模型训练与评估流程详解
在机器学习流程中,模型训练与评估是核心环节之一。本章将深入探讨逻辑回归模型的训练与评估流程,涵盖从数据集划分、模型实例化、训练预测到性能评估的全过程。通过具体的代码示例、参数分析和评估指标解析,帮助读者全面掌握模型构建与评估的关键步骤。
4.1 训练集与测试集划分
4.1.1 使用train_test_split函数划分数据集
在进行模型训练之前,通常需要将数据划分为训练集和测试集,以评估模型在未见过的数据上的表现。 scikit-learn 提供了 train_test_split 函数来实现这一操作。
python
from sklearn.model_selection import train_test_split
# 假设X是特征矩阵,y是目标标签
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)代码解析:
test_size=0.2:表示测试集占总数据的20%,训练集占80%。random_state=42:设置随机种子,确保每次划分的结果一致。
4.1.2 比例设置与随机种子控制
| 参数名 | 作用说明 | 推荐值 |
|---|---|---|
| test_size | 测试集比例 | 一般为0.2~0.3 |
| train_size | 训练集比例(可选) | 与test_size互补 |
| random_state | 控制随机划分的种子值 | 固定值如42、123等 |
| stratify | 保持训练集和测试集中类别分布一致 | 当y为分类标签时推荐使用 |
逻辑分析:
设置 stratify=y 可以确保训练集和测试集中类别分布与原始数据一致,尤其在类别不平衡的情况下非常关键。例如,在信用评分数据中,如果"违约"样本较少,使用 stratify 可避免测试集中没有"违约"样本。
4.2 LogisticRegression模型实例化
4.2.1 常用参数说明(penalty、C、solver、max_iter)
python
from sklearn.linear_model import LogisticRegression
model = LogisticRegression(penalty='l2', C=1.0, solver='lbfgs', max_iter=100, random_state=42)参数说明:
| 参数名 | 含义说明 | 推荐值 |
|---|---|---|
| penalty | 正则化类型,可选'l1'或'l2' | 'l2'(默认) |
| C | 正则化强度的倒数,C越大正则化越弱 | 1.0(默认) |
| solver | 优化算法,不同solver支持不同正则化方式 | 'lbfgs'(推荐) |
| max_iter | 最大迭代次数,防止收敛过慢 | 100~1000(视数据而定) |
| random_state | 控制随机性,保证结果可重复 | 固定值如42 |
4.2.2 参数选择对模型性能的影响分析
- penalty 与 solver 的匹配性 :
| solver | 支持的penalty类型 |
|---|---|
| liblinear | l1, l2 |
| lbfgs | l2 |
| saga | l1, l2, elasticnet |
- C 值对模型的影响 :
- 较小的C值:更强的正则化,防止过拟合。
- 较大的C值:更关注训练误差,可能过拟合。
python
# 示例:不同C值的模型比较
from sklearn.metrics import accuracy_score
for C in [0.1, 1.0, 10]:
model = LogisticRegression(C=C, solver='lbfgs', max_iter=1000)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
print(f"C={C}: Accuracy={accuracy_score(y_test, y_pred)}")4.3 模型训练与预测
4.3.1 fit方法的使用与内部机制简介
python
model.fit(X_train, y_train)fit 方法会使用训练数据进行模型参数的学习。逻辑回归通过最大化似然函数(或最小化对数损失)来更新权重参数。其优化过程依赖于梯度下降或拟牛顿法(如LBFGS)。
训练过程流程图:
4.3.2 predict方法实现分类预测
python
y_pred = model.predict(X_test)predict 方法会根据模型输出的概率,将样本分类为0或1(默认阈值0.5)。
4.3.3 predict_proba方法获取预测概率
python
y_proba = model.predict_proba(X_test)该方法返回每个样本属于每个类别的概率值。例如,对于二分类问题,输出是一个二维数组,第一列为类别0的概率,第二列为类别1的概率。
代码分析:
python
import numpy as np
# 手动计算类别判断
y_pred_manual = np.where(y_proba[:, 1] > 0.5, 1, 0)这种方式允许我们调整分类阈值,以适应不平衡数据或不同业务需求。
4.4 模型性能评估
4.4.1 准确率(Accuracy)的计算与适用场景
准确率是分类正确的样本数占总样本数的比例。
python
from sklearn.metrics import accuracy_score
acc = accuracy_score(y_test, y_pred)
print(f"Accuracy: {acc:.4f}")适用场景:
-
数据类别分布均衡。
-
不关心误判的具体类型(如医疗诊断中不能只看准确率)。
4.4.2 精确率(Precision)、召回率(Recall)、F1分数的定义与意义
| 指标 | 公式 | 意义说明 |
|---|---|---|
| Precision | TP / (TP + FP) | 表示预测为正类的样本中有多少是真正的正类 |
| Recall | TP / (TP + FN) | 表示真正的正类样本中有多少被正确预测 |
| F1 Score | 2 * (Precision * Recall) / (Precision + Recall) | 综合Precision和Recall的调和平均值 |
python
from sklearn.metrics import precision_score, recall_score, f1_score
print(f"Precision: {precision_score(y_test, y_pred):.4f}")
print(f"Recall: {recall_score(y_test, y_pred):.4f}")
print(f"F1 Score: {f1_score(y_test, y_pred):.4f}")4.4.3 使用classification_report与confusion_matrix进行可视化评估
python
from sklearn.metrics import classification_report, confusion_matrix
print(classification_report(y_test, y_pred))
print(confusion_matrix(y_test, y_pred))输出示例:
precision recall f1-score support
0 0.85 0.90 0.87 100
1 0.78 0.70 0.74 50
accuracy 0.83 150
macro avg 0.81 0.80 0.80 150
weighted avg 0.82 0.83 0.82 150
[[90 10]
[15 35]]混淆矩阵解释:
| 预测\实际 | 0(负类) | 1(正类) |
|---|---|---|
| 0 | TN=90 | FP=10 |
| 1 | FN=15 | TP=35 |
总结:
- 精确率和召回率在不平衡数据中尤为重要。
- 使用
classification_report可快速查看各类别的评估指标。 - 混淆矩阵能直观展示模型的分类错误类型。
本章完整展示了从数据划分到模型训练、预测与评估的全流程。下一章将深入探讨如何通过超参数调优进一步提升模型性能。
5. 超参数调优与模型优化策略
逻辑回归模型虽然结构简单,但其性能在很大程度上依赖于超参数的选择和数据处理策略。本章将深入探讨如何通过超参数调优、交叉验证、网格搜索以及特征选择等方法,提升模型的泛化能力和预测准确性。
5.1 超参数调优概述
在机器学习中,超参数是指在训练模型之前由用户设定的参数,而不是通过训练过程自动学习得到的参数。逻辑回归中的关键超参数包括正则化强度(C)、求解器(solver)、正则化类型(penalty)等。
5.1.1 正则化参数C的作用与选择
正则化是防止模型过拟合的重要手段。逻辑回归中通过参数 C 控制正则化的强度:
C值越大,正则化强度越小,模型越倾向于复杂,容易过拟合;C值越小,正则化强度越大,模型更简单,有助于防止过拟合。
python
from sklearn.linear_model import LogisticRegression
# 示例:不同C值对模型的影响
model_c1 = LogisticRegression(C=1.0, penalty='l2', solver='liblinear')
model_c0_1 = LogisticRegression(C=0.1, penalty='l2', solver='liblinear')代码逻辑分析:
-
C=1.0表示使用默认的正则化强度; -
penalty='l2'表示使用L2正则化; -
solver='liblinear'是一个适用于小数据集和二分类问题的求解器。
在实际应用中,我们可以通过交叉验证来寻找最优的 C 值。
5.1.2 求解器(solver)与正则化方式的匹配
逻辑回归支持多种求解器,不同求解器适用于不同规模的数据集和正则化方式:
| 求解器 | 支持的正则化方式 | 适用场景 |
|---|---|---|
liblinear |
L1 / L2 | 小数据集、二分类任务 |
lbfgs |
L2 | 中等数据集、多分类任务 |
saga |
L1 / L2 / ElasticNet | 大数据集、支持稀疏数据 |
例如:
python
# 使用 L1 正则化 + saga 求解器
model_l1 = LogisticRegression(penalty='l1', solver='saga', max_iter=1000)代码逻辑分析:
-
penalty='l1'启用L1正则化,有助于特征选择; -
solver='saga'是支持L1正则化的求解器之一; -
max_iter=1000防止迭代次数不足导致收敛失败。
5.2 交叉验证技术实现
交叉验证是一种评估模型泛化性能的有效方法,尤其适用于数据量较小的情况。K折交叉验证(K-Fold CV)是其中最常用的一种方法。
5.2.1 K折交叉验证(K-Fold CV)原理
K折交叉验证的基本思想是将数据集划分为K个互斥的子集(称为"折"),依次将每个子集作为测试集,其余K-1个子集作为训练集进行模型训练与验证。
- 优点:充分利用所有数据,评估结果更稳定;
- 缺点:计算成本较高(K次训练)。
5.2.2 cross_val_score函数实现交叉验证
Scikit-learn 提供了 cross_val_score 函数,可以方便地实现K折交叉验证。
python
from sklearn.model_selection import cross_val_score
from sklearn.datasets import load_breast_cancer
# 加载乳腺癌数据集
data = load_breast_cancer()
X, y = data.data, data.target
# 实例化模型
model = LogisticRegression()
# 执行5折交叉验证
scores = cross_val_score(model, X, y, cv=5, scoring='accuracy')
print("Cross-validation scores:", scores)
print("Mean CV accuracy:", scores.mean())代码逻辑分析:
-
cv=5表示执行5折交叉验证; -
scoring='accuracy'表示使用准确率作为评估指标; -
scores是长度为5的一维数组,表示每折的准确率; -
scores.mean()计算平均准确率。
建议: 通常将
cv设置为5或10,以平衡评估精度与计算开销。
5.3 网格搜索优化(GridSearchCV)
网格搜索是一种系统化地尝试不同参数组合的方法,能够自动找到在验证集上表现最佳的参数组合。
5.3.1 参数搜索空间的定义与设置
我们可以使用字典结构定义参数搜索空间,例如:
python
param_grid = {
'C': [0.01, 0.1, 1, 10, 100],
'penalty': ['l1', 'l2'],
'solver': ['liblinear', 'saga']
}5.3.2 最佳参数组合的自动搜索与评估
使用 GridSearchCV 可以自动进行网格搜索并评估模型:
python
from sklearn.model_selection import GridSearchCV
# 实例化网格搜索
grid_search = GridSearchCV(LogisticRegression(), param_grid, cv=5, scoring='accuracy')
# 执行搜索
grid_search.fit(X, y)
# 输出最佳参数
print("Best parameters:", grid_search.best_params_)
print("Best cross-validation score:", grid_search.best_score_)代码逻辑分析:
-
param_grid是前面定义的参数空间; -
cv=5表示使用5折交叉验证; -
best_params_返回最佳参数组合; -
best_score_返回对应的最佳平均准确率。
5.3.3 使用best_estimator_获取最优模型
一旦完成搜索,可以使用 best_estimator_ 获取最优模型:
python
best_model = grid_search.best_estimator_
test_score = best_model.score(X_test, y_test)
print("Test score with best model:", test_score)说明:
-
best_estimator_返回的是一个训练好的模型; -
可以直接用于新数据的预测或评估。
建议: 在大规模数据或参数空间较大时,可考虑使用
RandomizedSearchCV以减少搜索时间。
5.4 特征选择与降维策略
在模型训练中,过多的特征可能导致模型过拟合或训练效率低下。因此,合理的特征选择和降维策略是提升模型性能的重要手段。
5.4.1 特征重要性评估方法(如L1正则化)
L1正则化具有稀疏特性,能自动进行特征选择。通过查看逻辑回归模型的系数可以判断特征的重要性:
python
model = LogisticRegression(penalty='l1', solver='saga', max_iter=1000)
model.fit(X, y)
# 查看特征系数
import numpy as np
coef = model.coef_[0]
important_features = np.argsort(np.abs(coef))[::-1] # 按绝对值排序
print("Top 5 important features:", important_features[:5])代码逻辑分析:
-
model.coef_返回每个特征的权重; -
np.argsort对特征权重的绝对值进行排序; -
[::-1]表示逆序排列,即从大到小排序。
5.4.2 方差阈值筛选与相关系数分析
方差阈值筛选
特征方差太小通常对模型没有帮助,可以通过 VarianceThreshold 进行筛选:
python
from sklearn.feature_selection import VarianceThreshold
selector = VarianceThreshold(threshold=0.1)
X_high_variance = selector.fit_transform(X)参数说明:
-
threshold=0.1表示保留方差大于0.1的特征; -
fit_transform自动计算并筛选。
相关系数分析
使用皮尔逊相关系数可以分析特征与目标变量之间的线性关系:
python
import pandas as pd
# 转换为DataFrame便于分析
df = pd.DataFrame(X, columns=data.feature_names)
df['target'] = y
# 计算与目标变量的相关系数
correlations = df.corr()['target'].sort_values(ascending=False)
print("Top 5 correlated features:\n", correlations[1:6]) # 排除目标变量自身5.4.3 主成分分析(PCA)降维技术简介
主成分分析(PCA)是一种无监督的降维方法,适用于特征之间存在冗余的情况。
python
from sklearn.decomposition import PCA
# 保留95%的信息量
pca = PCA(n_components=0.95)
X_reduced = pca.fit_transform(X)
print("Original shape:", X.shape)
print("Reduced shape:", X_reduced.shape)代码逻辑分析:
-
n_components=0.95表示保留95%的方差信息; -
fit_transform同时进行训练和降维; -
输出显示降维后的特征数量显著减少。
建议: 在使用PCA前应先进行特征标准化(如
StandardScaler)。
总结与延展
通过本章的学习,我们掌握了如何使用超参数调优、交叉验证、网格搜索和特征选择等策略来提升逻辑回归模型的性能。这些方法不仅适用于逻辑回归,也为后续更复杂的模型优化提供了基础。
在第六章中,我们将进一步探讨如何将逻辑回归扩展到多分类任务,并处理大规模数据时的优化技巧。
6. 多分类扩展与大规模数据优化
6.1 多分类逻辑回归扩展
逻辑回归虽然最初设计用于二分类任务,但在实际应用中,许多问题涉及多个类别。例如,在图像识别中判断一张图片是猫、狗还是鸟;在文本分类中识别新闻属于体育、财经还是科技类别。为应对这类问题,需将逻辑回归从二分类推广至多分类。
6.1.1 二分类到多分类的扩展策略
主要有两种策略实现多分类: One-vs-Rest (OvR) 和 Softmax 回归(多项式逻辑回归) 。
- One-vs-Rest (OvR) :对每个类别训练一个二分类器,将其与其他所有类别区分开。预测时选择置信度最高的类别。
- Softmax 回归 :直接建模多类概率分布,输出每个类别的归一化概率,适用于互斥的多分类问题。
python
from sklearn.linear_model import LogisticRegression
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
# 加载鸢尾花数据集(3类)
X, y = load_iris(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 使用 OvR 策略(默认)
model_ovr = LogisticRegression(multi_class='ovr', solver='liblinear')
model_ovr.fit(X_train, y_train)
# 使用 Softmax 回归(需兼容求解器如 'lbfgs')
model_softmax = LogisticRegression(multi_class='multinomial', solver='lbfgs')
model_softmax.fit(X_train, y_train)
print("OvR 模型准确率:", model_ovr.score(X_test, y_test))
print("Softmax 模型准确率:", model_softmax.score(X_test, y_test))参数说明 :
multi_class='ovr':启用 One-vs-Rest 策略;
multi_class='multinomial':启用 Softmax 回归;
solver必须支持 multinomial,如'lbfgs','newton-cg','sag'。
6.1.2 多项式逻辑回归(Multinomial Logistic Regression)实现
Softmax 回归属于多项式逻辑回归的一种形式,其核心思想是使用 Softmax 函数将线性输出转化为概率分布:
P(y=k|x) = \frac{e^{w_k^T x}}{\sum_{j=1}^K e^{w_j^T x}}
该方法在整个类别空间上进行联合优化,避免了 OvR 中类别不平衡带来的偏差。
6.1.3 多分类任务的评估指标
对于多分类问题,单一的准确率不足以反映模型性能,应引入更细粒度的评估方式:
| 类别 | 精确率 (Precision) | 召回率 (Recall) | F1分数 |
|---|---|---|---|
| 0 | 1.00 | 1.00 | 1.00 |
| 1 | 0.92 | 0.92 | 0.92 |
| 2 | 0.92 | 0.92 | 0.92 |
| 宏平均 | 0.95 | 0.95 | 0.95 |
| 加权平均 | 0.95 | 0.95 | 0.95 |
python
from sklearn.metrics import classification_report
y_pred = model_softmax.predict(X_test)
print(classification_report(y_test, y_pred))宏平均(macro avg)对每一类平等对待,适合类别均衡场景;加权平均(weighted avg)按样本数量加权,更适合不均衡数据。
6.2 大规模数据处理与性能优化
当数据量达到百万级甚至更高时,传统批量训练方式面临内存溢出和训练缓慢的问题。为此需采用一系列性能优化技术。
6.2.1 内存优化策略:数据类型转换与稀疏矩阵应用
通过降低数据精度或使用稀疏表示可显著减少内存占用。
python
import numpy as np
import pandas as pd
from scipy.sparse import csr_matrix
# 示例:模拟高维稀疏特征
data_dense = np.random.randint(0, 2, size=(10000, 5000)).astype(np.float32) # 占用约 200MB
data_sparse = csr_matrix(data_dense) # 转换为稀疏矩阵,压缩存储
print(f"密集矩阵大小: {data_dense.nbytes / 1e6:.2f} MB")
print(f"稀疏矩阵大小: {data_sparse.data.nbytes / 1e6:.2f} MB")同时,合理选择数据类型也能节省资源:
python
df = pd.DataFrame({
'age': np.random.randint(18, 90, 100000).astype('int8'), # 原为 int64 → 改为 int8
'income': np.random.rand(100000).astype('float32') # float64 → float32
})6.2.2 并行化计算提升训练效率
Scikit-learn 提供 n_jobs 参数实现并行训练,尤其在交叉验证和网格搜索中效果显著。
python
from sklearn.model_selection import GridSearchCV
param_grid = {'C': [0.1, 1, 10]}
grid_search = GridSearchCV(
LogisticRegression(multi_class='ovr'),
param_grid,
cv=5,
n_jobs=4, # 使用 4 个 CPU 核心
verbose=1
)
grid_search.fit(X_train, y_train)注意:并非所有求解器都支持并行,
liblinear不支持跨 fold 并行,而saga或sag在某些情况下可受益于多线程。
6.2.3 使用增量学习处理超大规模数据
对于无法一次性加载进内存的数据,可使用 SGDClassifier 实现在线学习:
python
from sklearn.linear_model import SGDClassifier
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import make_pipeline
# 构建增量学习流水线
clf = make_pipeline(StandardScaler(), SGDClassifier(loss='log_loss'))
# 分批次训练
for batch_data, batch_labels in data_stream_loader(): # 假设存在流式加载函数
clf.partial_fit(batch_data, batch_labels, classes=np.unique(y))partial_fit() 方法允许模型逐步更新权重,适用于实时系统和大数据场景。
6.3 模型部署与工程化实践
6.3.1 模型保存与加载
推荐使用 joblib 保存包含预处理器的完整流水线:
python
import joblib
# 保存模型
joblib.dump(model_softmax, 'logistic_multiclass_model.pkl')
# 加载模型
loaded_model = joblib.load('logistic_multiclass_model.pkl')相比 pickle , joblib 更高效地序列化 NumPy 数组和大型对象。
6.3.2 构建端到端的数据处理与预测流水线
使用 Pipeline 将特征处理与模型封装为一体:
python
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
pipeline = Pipeline([
('scaler', StandardScaler()),
('classifier', LogisticRegression(multi_class='multinomial', solver='lbfgs'))
])
pipeline.fit(X_train, y_train)
prediction = pipeline.predict(X_test)此结构便于版本控制、测试与部署。
6.3.3 部署到生产环境的注意事项
- API封装 :使用 Flask/FastAPI 提供 REST 接口;
- 性能监控 :记录响应时间、预测延迟、错误率;
- 模型热更新 :通过文件监听或数据库触发模型重载;
- 输入校验 :确保传入数据格式一致,防止异常崩溃。
简介:逻辑回归是一种广泛应用于二分类问题的概率模型,尽管名称中包含"回归",实则为经典分类算法。本文详细介绍了如何使用Python及scikit-learn库实现逻辑回归的完整流程,涵盖环境搭建、数据预处理、模型训练、评估与优化等关键步骤。通过实际代码示例,帮助读者掌握从数据清洗到交叉验证的全过程,并可扩展至多分类与大规模数据场景,适用于机器学习初学者和实践者快速上手。