论文总结
1、提出了首个利用图像和表格数据训练单模编码器的自监督对比学习框架。
2、有开源代码:https : / / github . com / paulhager / MMCL - Tabular Imaging。这项工作算是在表格+影像融合领域最经典的工作了,后面很多模型或者方法,都把这篇论文作为对比实验,例如STiL-model、TIP等等。
3、引入了一种新的监督对比学习形式,将真实标签作为表格特征( Laa F );LaaF 的核心机制 :
在预训练阶段,将标签作为表格特征之一,通过图像与表格的多模态对比学习,强制图像编码器学习与疾病相关的形态学特征(如器官体积、尺寸等)。这些特征在表格中明确存在、且与图像直接对应,使得图像编码器能够"间接"掌握临床关键信息。预训练完成后,下游任务仅使用图像即可获得优于纯图像预训练的性能,实现了"多模态预训练、单模态推理"的目标。
4、局限性:1)只包含分类任务,未来可以进一步包括回归任务和分割任务;2)只包括了来自英国Biobank人口数据集的白人受试者,但是像冠状病等部分疾病已有研究证明具有种族差异。
摘要
医学数据集,尤其是生物样本库,通常包含丰富的表格数据,包含丰富的临床信息和图像。实际上,临床医生通常在多样性和规模上拥有较少的数据,但仍希望部署深度学习解决方案。结合医学数据集规模的增加和昂贵的注释成本,能够多模预训练和单模预测的无监督方法的需求日益增长。为满足这些需求,我们提出了首个利用图像和表格数据训练单模编码器的自监督对比学习框架。我们的解决方案结合了SimCLR和SCARF,这两种领先的对比学习策略,既简单又高效。在我们的实验中,我们通过利用心脏磁共振图像和来自4万名英国生物样本库受试者的120个临床特征,预测心肌梗死和冠状动脉疾病(CAD)的风险,展示了我们框架的强大性。此外,我们还展示了利用DVM汽车广告数据集对自然图像方法的普遍化性。我们利用表格数据的高可解释性,通过归因和消融实验发现,描述大小和形状的形态表特征在对比学习过程中具有极其重要的地位,并提升了所学嵌入的质量。最后,我们引入了一种新型的监督对比学习形式------标签作为特征(LaaF),在多模态预训练中将地面真实标签作为表形式附加,表现优于所有监督对比基线。
引言
现代医学数据集日益多模态化,通常同时包含影像数据和表格数据。图片数据可通过计算机断层扫描、超声或磁共振扫描仪获取,而表格数据通常来自实验室检测、病史和患者生活方式问卷。临床医生有责任将这些表格和影像数据整合并解读,以诊断、治疗和监测患者。例如,心脏病专家可能会询问患者的家族史,并记录其体重、胆固醇水平和血压,以便在检查心脏影像时更好地做出诊断。除了诊断,多模态数据对于推进对生物样本库开发驱动的疾病理解也至关重要。生物样本库远远超出医院典型数据集的规模,汇集了大量来自庞大人群的信息。多模态生物样本库包括德国国家队列21,拥有20万名受试者;Lifelines52,拥有167,000名受试者,以及英国生物样本库54,拥有50万名受试者。英国生物样本库包含数千个来自患者问卷、实验室检测和医学检查的数据字段,此外还有影像学和基因分型信息。生物样本库已被证明在机器学习模型训练中非常有用,用于预测贫血39、早期脑衰老32和心血管疾病1, 51。在临床实践中,广泛关注基于这些大规模人群研究开发的算法。然而,在繁忙的临床工作流程中,获取相同质量的数据------无论是模态多样性还是特征数量------是不可行的20。此外,低病害频率使得监督治疗难以进行。因此,显然需要能够从生物样本库规模数据集中学习并应用于临床的无监督策略,因为临床上数据量和维度都远远较少。
我们的贡献 为满足这些需求,我们提出了第一个利用成像和表格数据的对比框架,如图1所示。我们的框架基于SimCLR 13和SCARF 6,这两种领先的对比学习解决方案,简单且有效。我们展示了预训练策略在具有挑战性的任务中的实用性通过磁共振影像预测心脏健康。除了医学影像,我们还展示了我们的框架也可以应用于结合自然图像和表格数据,使用DVM汽车广告数据集29。 实验中,我们观察到我们的工具在对比学习中利用了形态计量特征。形态测量特征描述物体的大小和形状,因此与可提取的成像特征相关。我们通过归因方法(如积分梯度55)和消融实验,定量展示了这些特征在对比学习过程中的重要性。 最后,我们引入了一种新的监督对比学习方法,称为标签作为特征(LaaF)。通过将目标标签作为表格特征附加,我们的方法优于之前将标签纳入对比框架的策略。我们的方法也非常灵活,可以与上述策略结合,进一步提升绩效。
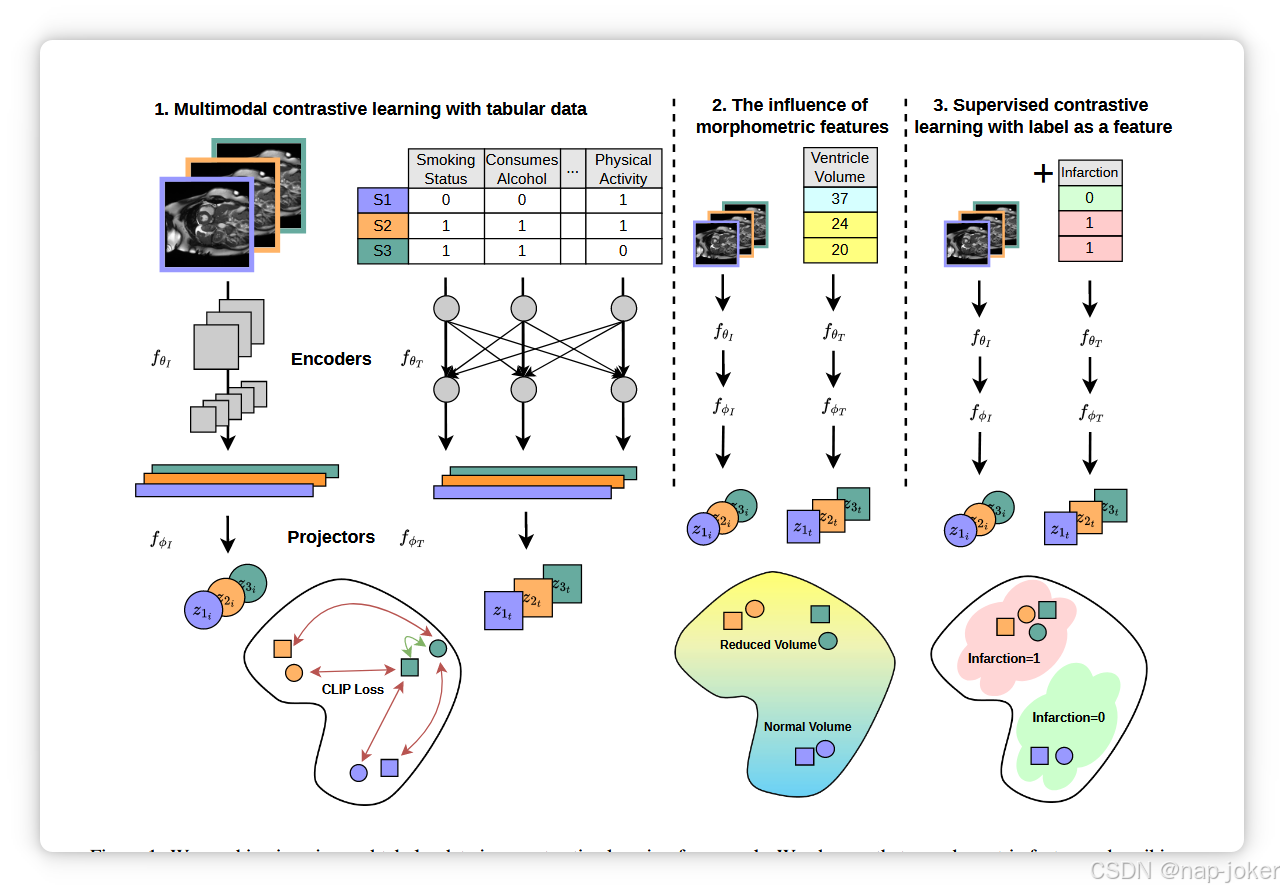
图1。我们将影像数据和表格数据结合在对比式学习框架中。我们观察到,描述形状和大小的形态测量特征在多模态对比训练中尤为重要,其纳入提升了后续任务的表现。通过简单地将标签作为表格特征添加,我们引入了一种新型的监督对比学习,其表现优于所有其他监督对比策略。
相关工作
自监督学习与图像的目标是从未标记的数据中提取有用的特征。历史上,这通常通过解决手工制作的预训练任务来尝试,如拼图44, 58, 59, 72、着色36, 63, 71、图像修复45和上下文预测7, 12, 19。使用这些方法的主要难点在于它们往往会对预训练任务的具体细节进行过拟合,限制了其在后续任务中的效用。
对比学习已成为预训练任务的流行且性能优异的继任者。对比学习通过生成样本的增强视图并最大化其投影嵌入相似度,同时最小化其他样本投影嵌入之间的相似性来训练编码器24。近年来,SimCLR 13、MOCO 25、BYOL、23 等实现使其广为人知。我们以SimCLR的对比框架为基础开展工作。
利用表格数据的深度学习最近开始产生与经典机器学习方法竞争的结果4, 8, 28,尽管在许多应用中它们仍低于更简单的算法8, 53。自监督学习正在表格领域被探索,采用如VIME 66的框架以及SubTab 61和SCARF 6等对比方法。我们的表格增强基于SCARF中使用的增强。
随着多模态数据集数量的增加和多模态训练策略的提升,多模态对比学习与图像的学习变得越来越重要。像CLIP 49这样的方法结合了图像和文本,是通用视觉模型,能够以零镜头方式解决新任务。其中一些模型使用互联网规模的数据集,被称为基础模型,如UniCL 65、Florence 68、ALIGN 31和Wu Dao 2.0 18。在图像语言领域之外,利用两种不同的成像方式47, 58------音频和视频37、视频与文本64, 73以及影像与遗传数据57,也取得了多模态对比学习的进展。虽然已有关于生成式自监督表格和成像模型的文献334,但其范围有限,仅使用两到四个临床特征。据我们所知,目前尚无结合图像和表格数据的对比自监督框架,我们本研究旨在解决这一问题。 研究表明,在对比框架内的监督学习在某些情况下优于二元交叉熵的损失,并创造更稳健的嵌入33。
监督对比学习33最大化了同一类批次中所有视图的投影嵌入相似度。这也解决了对比学习中的假阴性问题,即对比损失会最小化不同样本间的嵌入相似度,即使它们属于同一类,也符合下游任务(即假阴性)。通过利用现有标签,监督对比学习能够绕过这一问题,并且优于其他通过启发式方式识别和消除假阴性的方法15,30。我们在多模态对比框架中提出了一种监督学习解决方案,利用表格数据的独特优势,将标签附加为表格特征。
方法
表格和成像数据的对比框架
我们的多模态框架基于SimCLR 13。设我们的数据集为x,唯一的样本为j。每批次包含对增强的成像xji和表格xjt样本。每个增强成像样本xji批处理通过成像编码器fθI生成嵌入xfji。批次中每个增补表样本xjt都通过表编码器fθT生成嵌入xfjt 。嵌入通过独立的投影中心fφI和fφT传播,并作为投影zji和zjt被带入共享潜在空间,随后L2归一化到单位超球面上。投影在共享潜空间中根据"CLIP"损失49被拉拽和推挤,该损失最大化同一样本投影的余弦相似度,最小化不同样本投影的相似性。与原始InfoNCE43失落及随后的CLIP不同,我们仅对不同模态之间的投影进行对比,从不对单一模态内进行对比。I和T可以互换使用,因此,毫无一般性,图像的投影定义为:
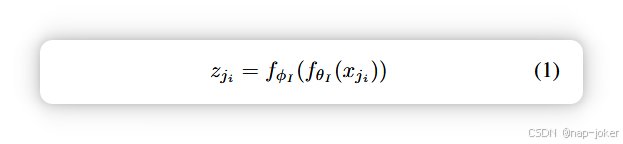
考虑批次中所有受试者 N,成像模态的损失为:
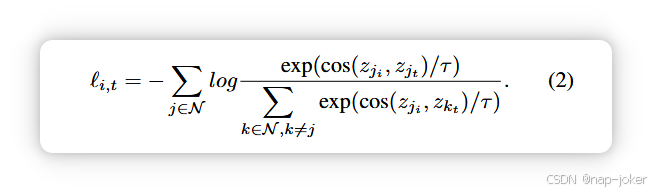
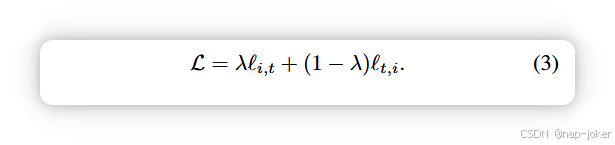
批处理中的图像基于 13 中规定的标准对比增强:水平翻转、旋转、颜色抖动和重新裁剪。为了保留MR图像中的细粒度特征,我们在心脏数据集上不使用高斯模糊 5 。为了有效地增加表格数据,在 6 之后,随机选择一个主题特征的一部分是"损坏的" (即增广)。每个损坏的特征的值从数据集中看到的该特征的所有值中替换采样。完整的实施细节见补充材料。
使用集成梯度的可解释性
为了提高我们对多模态训练动力学的理解,我们分析了个体表特征在生成嵌入中的重要性。利用测试样本,我们取多模态模型的预训练的表格编码器,并计算嵌入的每个维度的集成梯度 55 。这整合了编码器沿着从基线样本(在我们的情况下是零向量)到测试样本的直线路径的梯度。这就得到了每个表格特征在生成该样本的下游预测时的重要性值。然后我们取绝对值和.计算每个特征在所有嵌入维度上的平均重要性。分类特征在所有选择中都有其意义。我们使用这些结果来分类特征,并更好地理解多模态环境下的训练如何影响单模态性能。
带标签的对比学习
在对比学习过程中融入标签通常是通过修改损失函数 15、33 来完成的。我们提出利用表格数据的独特结构,直接添加下游的类标签作为表格特征。我们探索了将我们的方法与现有的将标签纳入训练过程的策略相结合的好处,例如有监督的对比学习和假阴性消除。
实验和结果
数据集
作为第一个数据集,我们使用了来自英国Biobank人群研究的心脏MR图像和临床信息。我们的目的是预测心肌梗死和冠状动脉疾病( CAD )的过去和未来风险。我们使用了短轴心脏MR图像,它提供了心脏左、右心室的横截面视图。所用图像为双通道二维图像,通道为短轴位心脏MRI图像收缩期末和舒张期末的中间基底尖层面。短轴图像被选择为左心室功能和形态测量受到CAD 69 和心脏梗死 56 的影响。相反,左心室是一个高风险区域,在这个区域,心功能不全的早期预警信号可能是可见的 2、50、60 。 将图像补零至210 × 210像素,一种小型地震检波器归一化至0 ~ 1范围。经过(见补充材料)增强后,最终图像大小为128 × 128像素。在英国Biobank数据集中的5,000个数据字段中,选择了人口、生活方式和生理特征的子集作为表格数据。这些特征是根据已发表的与心脏结果的相关性来选择的。这些信息包括受试者的饮食 67 ,体力活动 42 ,体重 48 ,饮酒 46 ,吸烟状况 35 和焦虑 11 。仅包含覆盖率至少为80 %的特征。完整的特征列表见补充材料。 连续表格数据字段采用z - score标准化,均值为0,标准差为1,分类数据采用one - hot编码。数据集的总大小为40,874个独特的受试者,分为29,428个训练,7,358个验证,以及4,088个成像和表格数据的测试对。第一个预测目标是国际疾病分类定义的心肌梗死( ICD10 )编码。ICD10编码由世界卫生组织维护,用于记录住院期间的诊断,并通过英国生物样本库提供。第二个预测目标是CAD,同样由ICD10编码定义。每一类所使用的ICD编码均在补充资料中列出。我们将过去和未来的诊断结合起来,因为梗死和CAD可以在很多年内不被诊断,并且只有当患者需要治疗严重的心脏事件时才会被记录,这使得在疾病开始时很难确定。由于两种疾病在数据集( 3 % ,冠心病为6 %)中出现的频率都很低,因此使用所有正例被试和一组随机选择的负例被试来平衡微调训练的分割。 测试集和验证集保持不变。
第二个数据集是数据视觉营销( Data Visual Marketing,DVM )数据集,由335 562条二手车广告创建 29 。DVM数据集包含1,451,784张不同角度的汽车( 45度增量)图像及其销售和技术数据。对于我们的任务,我们选择了从图像和伴随的广告数据中预测汽车模型。影像均为300 × 300像素,经过(见补充材料)增强后最终影像大小为128 × 128。所有提供有关汽车语义信息的字段都包括在内,如宽度、长度、高度、轴距、价格、广告年份、行驶里程、座位数、车门数、原始价格、发动机尺寸、车身类型、变速箱类型和燃料类型。 品牌和模特年份等唯一的目标识别信息被排除。宽度、长度、高度和轴距值随机抖动50毫米,以免被唯一识别。我们将该表格数据与来自每个广告的单个随机图像进行配对,得到一个70,565个训练对、17,642个验证对和88,207个测试对的数据集。剔除样本量小于100的车型,得到286个目标类。为了处理缺失的表格数据,我们使用了一个迭代的多变量插补器,它将缺失的特征建模为多个插补轮次上现有特征的函数。这是在标准化后进行的,以确保平均值和标准偏差仅从记录值计算。
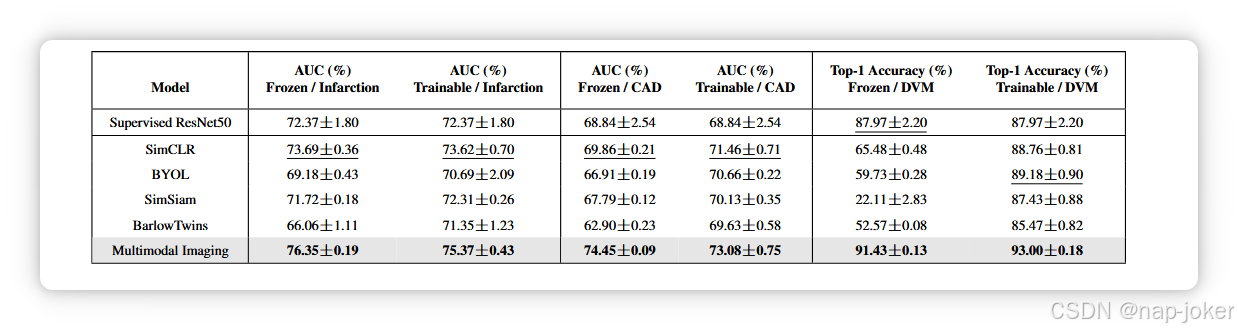
我们的框架在心肌梗死,冠状动脉疾病( CAD )和从图像中预测DVM汽车模型任务上的性能。我们的多模态预训练模型在每个任务上都优于其他所有模型。每种输入类型的最佳执行模型以粗体字体显示。我们的方法是突出灰度的。
实验配置
所有的成像编码器都是Res Net50s 26 ,生成大小为2048的嵌入。我们的多模态模型使用了一个表格式编码器,它是一个多层感知器( MLP ),具有一个大小为2048的隐藏层,可以生成大小为2048的嵌入。所有的权重都是随机初始化的。我们的成像投影仪是一个隐藏层大小为2048的MLP,我们的表格投影仪直接从具有全连接层的嵌入中生成投影。投影大小为128 13 。经过预训练后,去掉投影头并添加一个与输出类节点的全连接层。 为了评估模型的有效性,我们将其与全监督的ResNet50网络以及Sim CLR 13 、BYOL 22 、Sim Siam 17 、Barlow Twins 70 等多个对比解进行比较。我们使用冻结网络的线性探测来评估学习到的表示 13、15、33的质量。我们还对每个网络进行了基准测试,同时在微调过程中保留了所有可训练的权重,因为这通常会在冻结的对应网络上得到改善,并将在实际中使用。对于心脏分类任务,我们使用受试者工作特征曲线下面积( area under the receiver operating characteristic curve,AUC )作为我们的度量,因为数据集对于我们的目标是严重不平衡的。在只有3 - 6 %的正类标签的情况下,一个总是预测负类的模型可以达到94 - 97 %的准确率。 对于DVM汽车数据集,由于有280 +个类别,我们报告了top - 1的准确率。结果报告为在微调过程中对5种不同的种子设置计算的平均值和标准差。两种心脏任务均从单个预训练模型中进行评估。完整的实验细节,包括基线模型的设置,可在补充材料中找到。
多模态预训练改进了单模态预测
我们的主要结果展示了我们的多模态预训练框架的优势,见表1。所有显示的结果仅使用图像作为输入,因为这是临床相关的任务。使用表格输入的结果在补充材料中显示。我们的多模态预训练模型在所有三个任务和两个微调策略上都明显优于所有其他模型。Sim CLR总体上优于其他所有对比策略,这表明我们的多模态策略是基于Sim CLR的。在心脏任务上,当冻结编码器时,多模态模型取得了最好的效果。我们假设这是由于微调过程中对成像模态的过拟合造成的。 我们怀疑当在微调过程中提供仅成像的信号时,编码器丢弃了从表格数据中学习到的特征。当从DVM数据集的图像中预测汽车模型时,我们的多模态模型在冻结的线性探测过程中表现出比其他预训练策略更大的优势。这表明,对于类似DVM汽车的同质数据集,增加一个额外的区分信号(如表格数据)可以更好地将学习到的特征对齐到下游的目标类。
多模态预训练在低数据条件下是有益的
当调查标签频率非常低的罕见医疗条件时,当可用的阳性样本很少时,模型必须执行。为了测试学习到的编码器在这种低数据状态下的性能,我们将微调后的训练数据集采样到其原始大小的10 %和1 %,并且每个子集都包含在每个超集内。由于正类的频率较低,这导致心肌梗死的平衡训练集大小为200 ( 10 % )和20 ( 1 % ),CAD的平衡训练集大小为400 ( 10 % )和40 ( 1 % )。测试集和验证集保持与全数据格式相同。结果的图形表示如图2所示。 我们发现,在低数据条件下,我们的多模态框架通常比全数据条件下的仅成像对比方法表现出更大的优势。这表明当以罕见疾病为目标时,需要较少的微调样本以达到相同的性能和更高的效用的改进表示。我们再次看到,我们的多模态冻结编码器始终优于我们的可训练编码器。我们以Sim CLR作为最强的对比预训练策略。与所有预训练策略的比较可以在补充材料中找到。
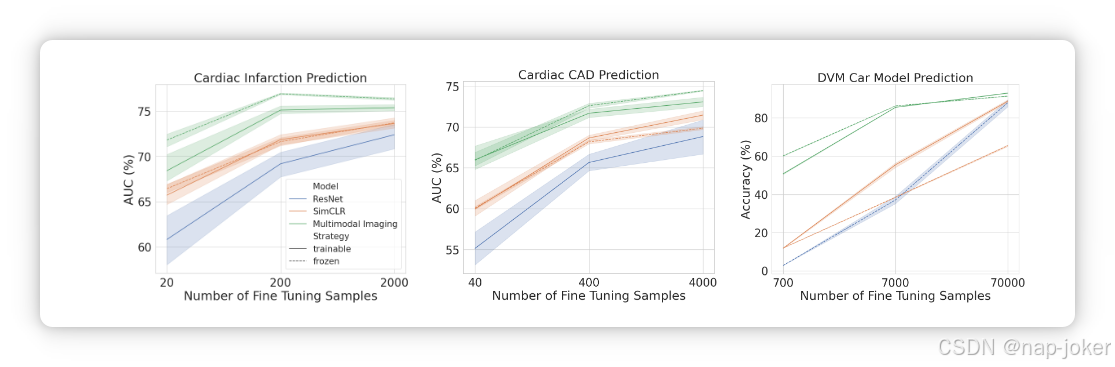
图2。不同微调训练样本数的成像模型性能。阴影区域表示95 %的置信区间。使用图像和表格数据的预训练在所有数据量下都很出色,并且非常适合在只有几十或几百个标签可用的情况下进行罕见病识别。
形态特征提高了嵌入质量
为了探索为什么以多模态的方式训练会改进单模态编码器,我们分析了表格特征对改进嵌入的贡献。表格数据的一个独特之处在于它的每个输入节点都对应一个单一的特征。我们将特征分为两类,形态特征和非形态特征。形态特征与尺寸和形状有关,并且在图像中具有直接的相关性,例如心室的体积,重量或汽车长度。使用集成梯度,我们计算了每个特征在测试样本中的重要性。为了生成心脏嵌入,最重要的7个特征都是形态特征,尽管它们只代表了所有特征的五分之一。 此外,所有24个形态学特征都位于重要性排名的前半部分。这些结果见图3和补充材料。我们假设模型专注于形态学表格特征,因为这些特征在图像中具有直接的相关性。在两种模态中提取这些特征增加了投影嵌入相似性,并最小化了对比损失,如补充材料所示。
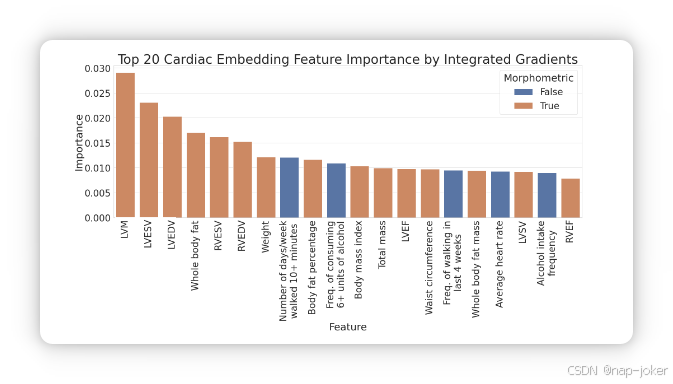
图3。使用集成梯度特征属性方法确定的计算嵌入的前20个最有影响的特征。形态特征为橙色,包含了20个最具影响力的特征中的15个。
这与Guided Grad Cam结果相印证,如图5所示,可以看出成像模型主要集中在左心室。根据积分梯度最重要的三个特征是左心室质量( LVM ),左心室收缩末期容积( LVESV )和左心室舒张末期容积。容积( LVEDV )。为了分析这些表格特征对下游性能的影响,我们只用形态特征和只用非形态特征训练了一次。我们观察到,形态特征对生成嵌入有非常大的影响。表2显示,尽管他们只贡献了46 .在117个特征中,有24个特征的重要性占总重要性的99 %,它们在CAD预测中的排除降低了性能,等同于非形态特征在梗死预测中的排除。总的来说,这表明多模态预训练过程对特征选择具有相当的鲁棒性,特别是当总特征集非常大且数据内部存在共线性时。
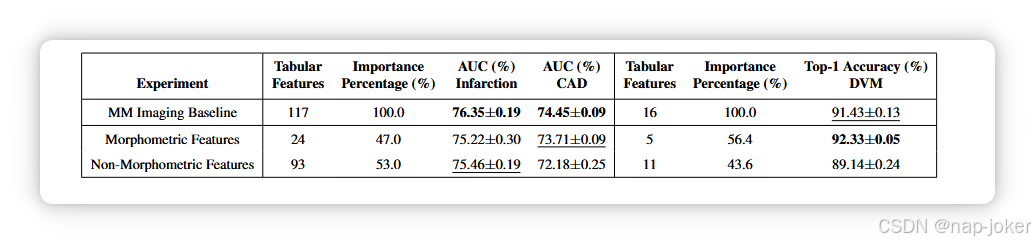
见表2。使用所有特征、仅有形态特征和没有形态特征预训练的多模态模型的冻结微调性能。尽管形态特征在心脏任务上的总重要性小于非形态特征,但它们的排斥会恶化或对下游表现产生同等影响。最好的得分方式是在粗体字体中,其次是在下划线中。
将标签作为Tatable特征追加BOOSTS监督的对比策略
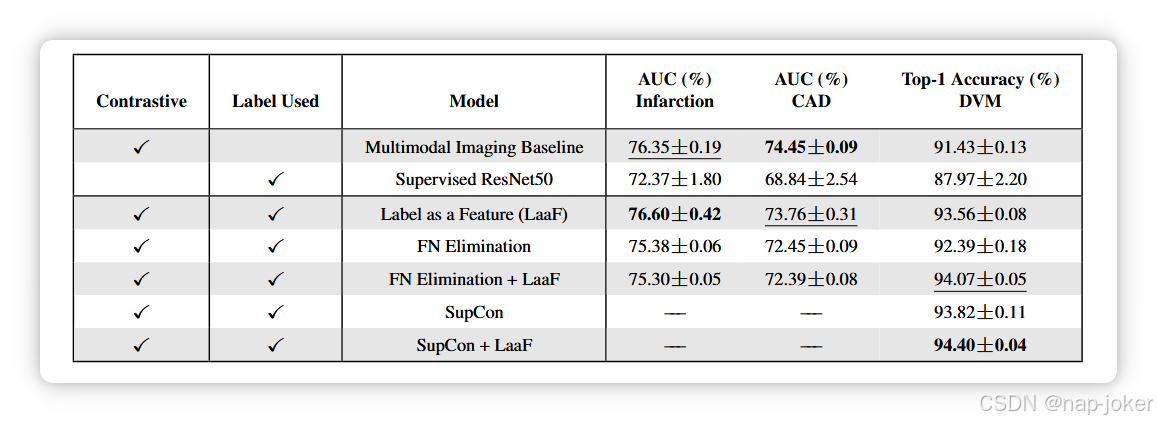
表3。在对比预训练过程中融入标签时的冻结评估。我们的标签特征( Label as a Feature,Laaf )策略无论是单独使用还是结合使用,都一致优于有监督的对比学习( SupCon )和假阴性消除( FN Elimination )。最好的得分方式是在粗体字体中,其次是在下划线中。我们的方法突出了灰色。破折号表示收敛失败。
我们引入了一种新的监督对比学习形式,将真实标签作为表格特征( Laa F )。我们通过将该方法与全标签信息的监督对比学习和全标签信息的假阴性消除进行比较,来测试该方法的有效性。表3的结果表明,Laa F策略优于或优于这两种策略。在心脏二分类任务上存在着尖锐的类别不平衡问题。97 %的受试者为心肌梗死阴性,导致假阴性消除,在计算对比损失之前去除每批次的大部分。这导致了在训练过程中批大小急剧减少时更差的表示。 由于对比学习,特别是Sim CLR对批次大小敏感 13 ,这会降低下游性能。有监督的对比学习由于在预训练期间没有收敛而表现得更差。再次,由于类别不平衡,有监督的对比损失函数会导致退化解,因为大约97 %的批次被投影到单个嵌入中。类似的行为在CAD预测任务中被观察到,其中94 %的样本处于负类。在心脏任务上,Laa F的表现优于假阴性消除和有监督的对比学习,但在成像基线上没有实质性的提高。 我们将这归因于心脏设置包含了120个特征,这降低了任何一个特征的重要性。此外,如上所述,不平衡二分类是有监督对比学习的一个困难任务。在预训练过程中增加真实标签的重要性,并将有监督的对比学习适应于二进制情况,将留给未来的工作。在DVM任务上,我们有286个类,这个趋势遵循了既定的文献。假阴性消除在基线上有所改进,而有监督的对比学习在假阴性消除上有所改进 15 。我们的方法本身,在不修改损失函数的情况下,超越了假阴性消除,接近有监督的对比学习。 正如预期的那样,当更多的类存在时,如 15 所示,标签具有更高的影响。重要的是,添加标签作为表格特征还可以与假阴性消除和有监督的对比学习相结合。这突出了我们方法的灵活性,因为它可以与任何有监督的对比策略一起使用。通过LaaF,我们对这两种损失都进行了改进,并在DVM汽车模型预测任务上取得了最好的成绩。该效应在低数据区也同样显著,如补充材料所示。
讨论和总结
在这项工作中,我们提出了第一个结合表格和成像数据的对比框架。我们的贡献来自于生物数据库中丰富的临床数据集,这些数据集包含了参与者的病史、生活方式和生理测量的大量信息,并与医学图像相结合。然而,由于时间和预算的限制,在临床环境中收集这些详细的表格数据是不可行的。我们的解决方案在表格和成像数据的大型数据集上进行预训练,以提高仅使用图像作为输入的推理过程中的性能。我们展示了我们的工具在从MRI进行心脏健康预测这一具有挑战性的任务上的实用性,战胜了所有的对比基线和全监督基线。 我们的方法还转化到自然图像领域,在广告数据的汽车模型预测任务上显示了它的优势。通过归因和消融实验,我们发现形态特征对于多模态学习过程具有非常重要的作用。我们假设这些与尺寸和形状相关的特征在图像中具有直接的相关性,从而有助于最小化多模态自监督损失。这表明,从图像中提取形态特征或从另一个来源收集形态特征,将其作为表格特征,改进了学习到的表示。最后,在使用表格数据时,我们提出了一种简单有效的新的监督对比学习方法。 简单地将目标标签添加为表格特征优于损失修正策略,如带有假阴性消除的对比学习和接近有监督的对比学习。该策略还可以与任何有监督的对比损失修改相结合,以达到最先进的结果,超过所有其他策略。
局限性在我们的研究中,我们检验了我们的框架只对分类任务的好处。未来的工作应该通过进一步的任务,如分割和回归,来测试框架的行为。我们假设,如果表格数据中包含形态学特征,例如待分割区域的大小,如果形态学特征是回归的,那么分割可以从该框架中受益。这项工作的另一个缺点是,我们只包括了来自英国Biobank人口数据集的白人受试者,因为其他种族在研究中的代表性严重不足,仅占总人口的5 %。冠状动脉梗死和CAD风险的显著种族差异已被反复发现 27、38、40 ,并可能导致错误的相关性被学习。未来的工作可以使用平衡数据集或探索在不平衡数据集上学习到的传播偏差,以识别和抵消任何学习到的偏差。
结论总之,我们的工作首次提出了一种在自监督对比学习中利用表格和成像数据的有效且简单的策略。我们的方法在临床环境中特别相关,我们希望在预训练过程中利用广泛的、多模态的生物样本库,并在实际中预测单峰。我们认为,表格数据是深度学习的一个未被充分研究和重视的数据来源,它易于收集且无处不在,因为任何数值或分类特征都可以表示。由于每个特征直接代表一个语义概念,因此它也具有很强的可解释性。我们希望,这将激发未来的工作,以发掘这一尚未开发的潜力。
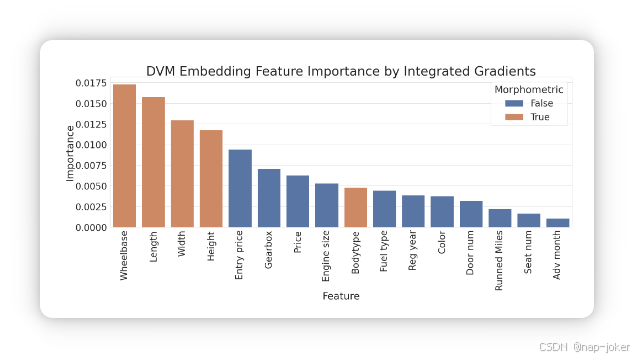
图4。使用综合梯度特征归属方法确定的特征对计算DVM嵌入的影响。形态特征是橙色的,包含了四个最重要的特征。
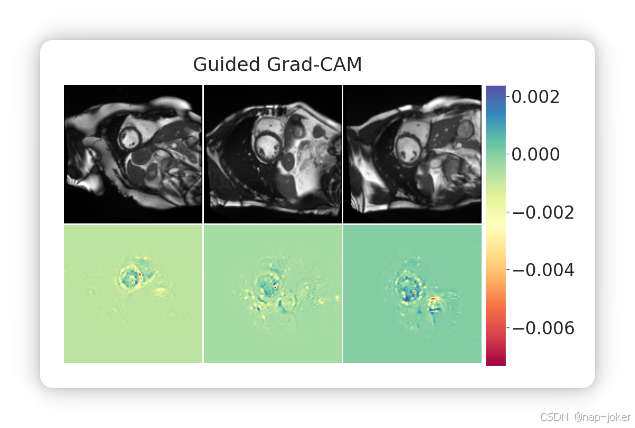
图5。在测试图像上预测CAD的引导Grad - CAM结果。最重要的特征以左心室为中心,与最重要的表格特征相匹配。