大家好,我是独孤风。
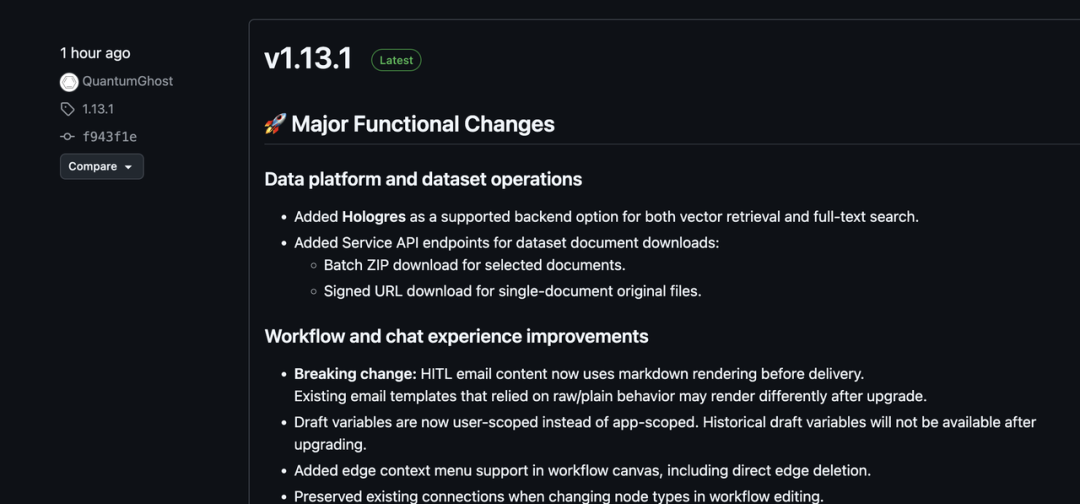
距离Dify上次发布Skills预告版本已经过去了一个月。在上篇文章中,我们深度剖析了 Dify 如何通过 HITL(人工干预)节点完成了从"概率"到"确定性"的底层进化。如果说 v1.13.0 是一场大刀阔斧的架构手术,那么刚刚发布的 v1.13.1,则是手术后最为关键的"消炎与加固"。
作为大数据工程师,我深知:功能的堆砌只能赢得眼球,而对边界 Bug 的极致修复和架构性能的调优,才能赢得企业生产环境的入场券。
今天,我们就来扒一扒这个以修复为主的版本中,隐藏了哪些硬核的工程改进。
一、 大数据版图扩张:Hologres 正式入局
在这个补丁版本中,Dify 悄悄塞进了一个重磅的存储支持:Hologres。
对于做大数据的同学来说,Hologres 并不陌生。它是阿里系实时数仓的标杆,支持海量数据的实时写入与查询。
-
向量与全文的双重加持:此次 v1.13.1 让 Hologres 同时也支持了向量检索(Vector Retrieval)和全文搜索(Full-text Search)。
-
工程意义:这意味着如果你已经在阿里云生态内,你可以直接复用现有的实时数仓能力,无需额外维护一套专门的向量数据库(如 Milvus 或 Weaviate),极大地降低了 RAG 链路的数据孤岛感和维护成本。
二、 数据的"管"与"用":数据集 API 的闭环
很多团队在落地 AI 应用时,最头疼的是数据集的导出与审计。v1.13.1 增强了 Service API 的端点功能:
-
批量导出(Batch ZIP):支持对选定文档进行一键打包下载。
-
带签名下载(Signed URL):针对单文档原始文件,提供了带有时效性的签名 URL。
从工程角度看,这解决了企业在数据归档、二次审计、以及跨系统分发时的安全性与便捷性问题。数据不再是只进不出的黑盒。
三、 填坑与重构:那些你必须警惕的"破坏性改动"
既然是"加固"版,Dify 团队对 1.13.0 重构后暴露出的问题进行了快速闪击。
-
草稿变量的"用户隔离": 这是一个 Breaking Change。草稿变量(Draft variables)现在改为 User-scoped(用户作用域)。升级后,以前那种"应用级"的共享草稿变量将不可见。这虽然带来了一点迁移成本,但彻底解决了多人在同一个 App 下协作时变量冲突的乱象。
-
执行引擎的"精准排水": 1.13.0 引入了 Celery 异步队列。在 1.13.1 中,新增了一个专用队列:dataset_summary。 运维重点:如果你发现升级后数据集摘要生成慢,一定要检查 Worker 是否订阅了这个新队列。这体现了 Dify 团队对"LLM 重型任务"与"轻量逻辑任务"进行物理隔离的思路。
四、 安全防线:不仅仅是 SQL 注入
在企业级交付中,安全永远是 0 前面的那个 1。
-
SQL 参数化:修复了向量库查询路径中的注入风险。
-
SMTP 头注入防护:针对 HITL 邮件发送,对内容进行了严格的脱敏(Strip CR/LF)。 这些修补虽然在 UI 上看不出来,但却是防止"内鬼"利用提示词或输入框进行系统穿透的关键屏障。
五、 稳定升级三部曲
虽然 1.13.1 是小版本,但由于涉及数据库迁移和队列变更,请务必执行以下标准操作:
-
快照备份:
-
Bash
go
tar -cvf volumes-$(date +%s).tgz volumes-
配置核查: 确保环境变量中新增了 REDIS_MAX_CONNECTIONS 的定义,并检查 EVENT_BUS_* 设置(旧版 PUBSUB_* 已弃用)。
-
灰度重启: 使用 --profile postgresql 模式确保插件数据库的连接稳定性:
-
Bash
go
docker compose --profile postgresql up -d结语:向"无感交付"更近一步
从 1.13.0 的架构跨越,到 1.13.1 的细节打磨,我看到的是一个国产开源框架在"好用"和"能用"之间的坚定平衡。
过去,我们常说 AI 落地难,难在模型不可控;现在,Dify 正在通过一套工业级的工程框架,把模型关进"确定性"的笼子里。1.14带Skills版本也即将发布,让我们拭目以待!
未来 10 年,我们将见证从"数据驱动"向"智能驱动"的全面跃迁。而这一切的起点,就在于你对每一行配置、每一个 Bug 的严谨对待。
加入「大数据流动」,和我们一起为未来 10 年埋下种子。
我是独孤风。
关注「大数据流动」,我们下期见。