InternVL基于互联网开源数据采集了6B数据,经过滤后一阶段用了5B数据,二阶段用了1B数据。SFT阶段,用了4M数据(二阶段的0.4%)。InternVL1.5与上一版本相比,扩大了训练数据集的纳入范围(尤其是关于ORC任务,进行了细粒度的划分),并且设计了**翻译流程,**补充中文语料训练数据的不足,同时针对测试任务针对性设计了SFT数据。
InternVL2基于1.5版本的数据集,二次进行扩充,同时构建了包含医疗领域的二阶段高质量训练数据。
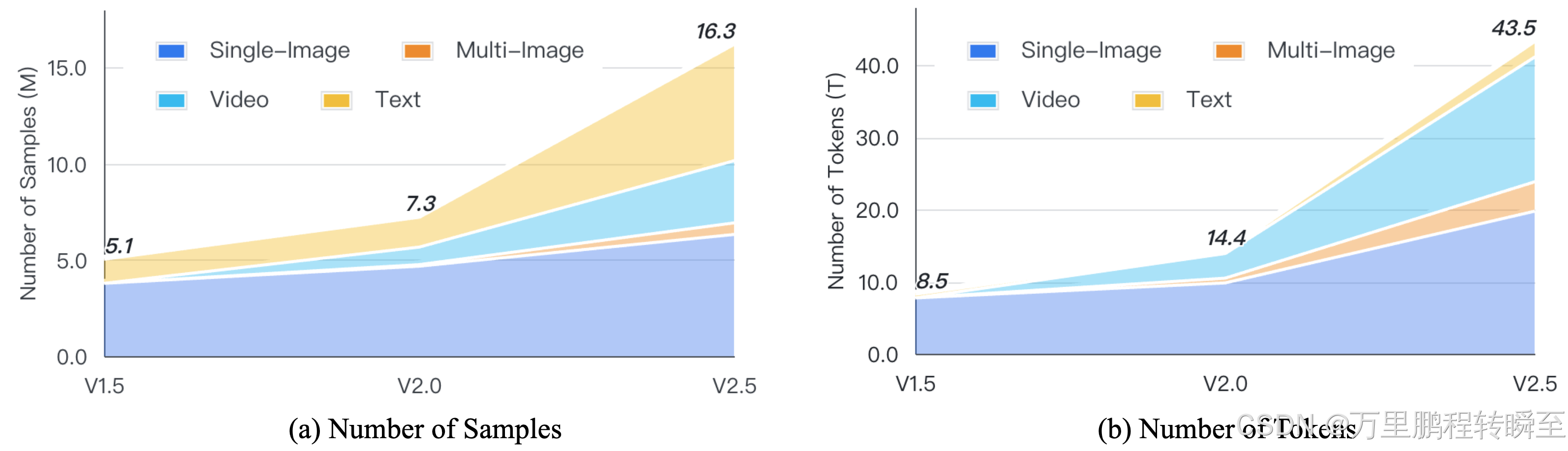
InternVL2.5 引入了有条件地应用JPEG 压缩,图像分块控制, 在总体的训练数据规模上,比v2模型多了近一倍,同时由于tille数量的变化,训练视觉token数提升的比例变得更大了。并提出了异常数据过滤.
InternVL3主要描述**将语言预训练与多模态对齐训练整合于同一预训练阶段,**混合输入多模态数据(图文、视频文本等)与大规模纯文本语料实现联合优化,同步学习语言与多模态能力。
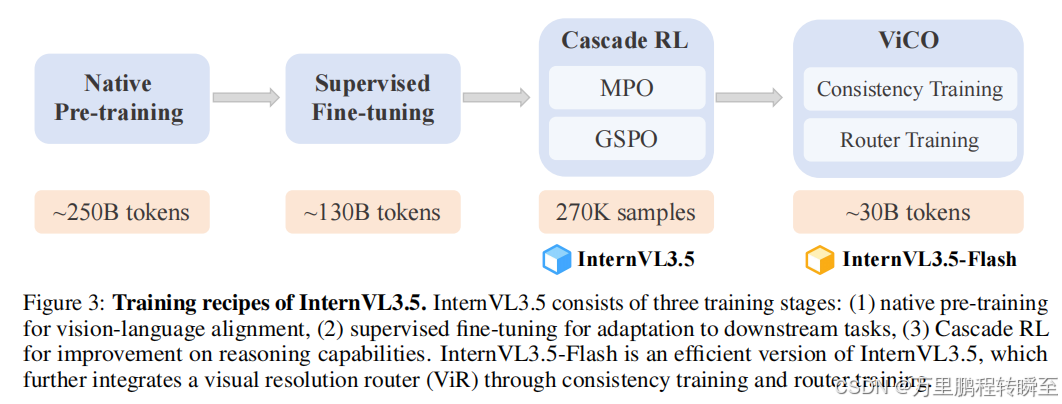
InternVL3.5仅训练了1160M 样本(250B token,仅约 InternVL1的1/5),但是在SFT阶段用了约600M样本。
InternVL
公开时间:2024年1月15日
仅介绍了其基于模型架构与训练步骤,只说明数据均来自开源环境,经过筛选后保留合格数据,并未详细介绍数据处理流程。具体使用的数据集来源可以查看论文附录:https://arxiv.org/pdf/2312.14238
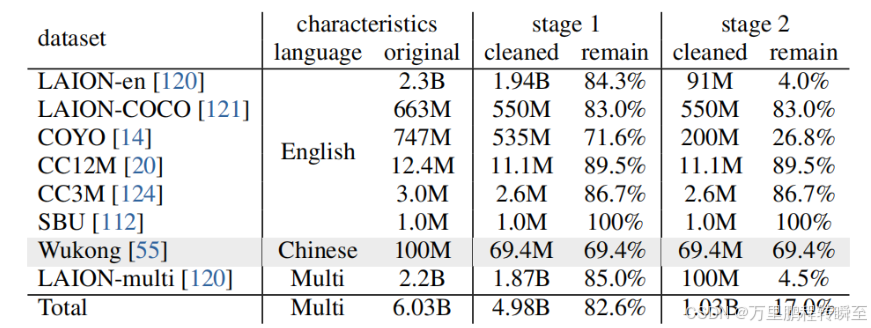
整体可以看到用了5B 图文多模态数据集, 一条图文对:问题 + 回答 ≈ 200~500 token, 取中间保守值:1 条 ≈ 300 token, 5B 条样本 ≈ 5B × 300 = 1500B token
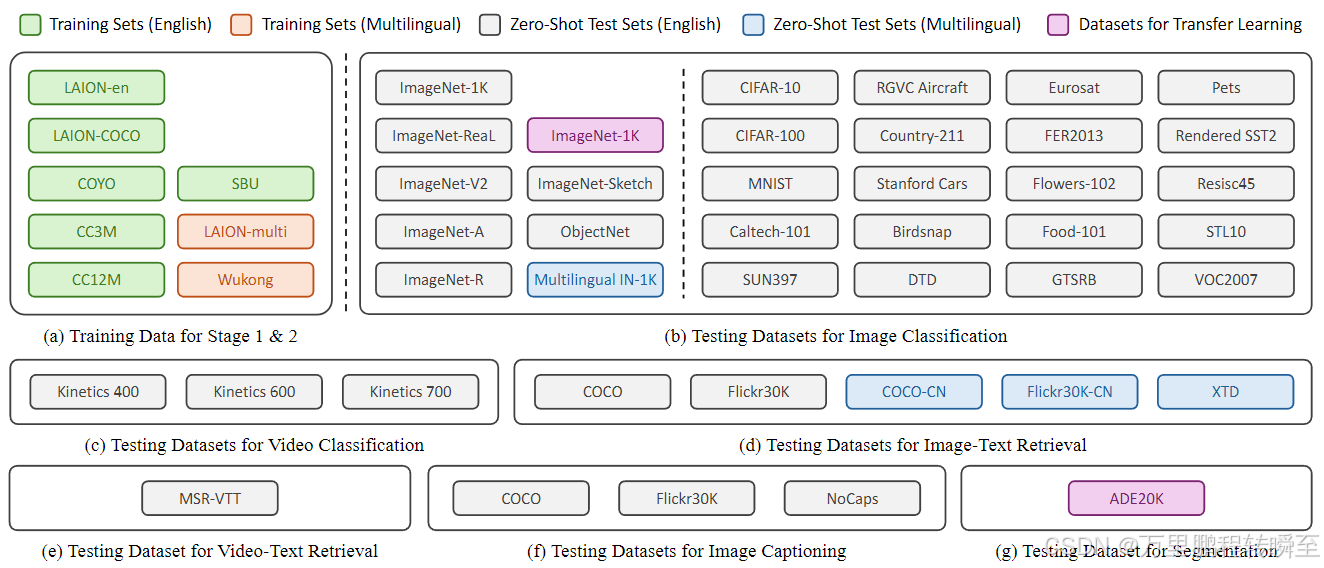
训练与测试时具体数据集划分。
InternVL1.5
Pre-training Dataset.
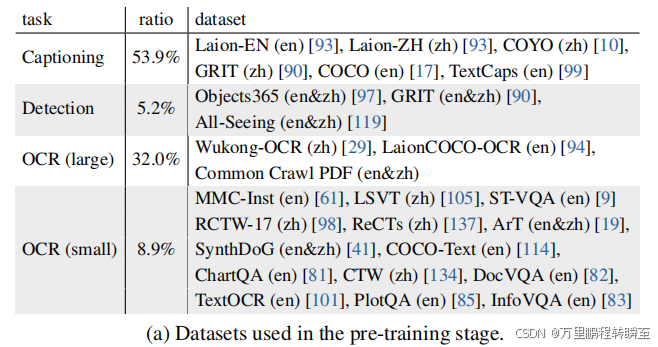
Fine-tuning Dataset.
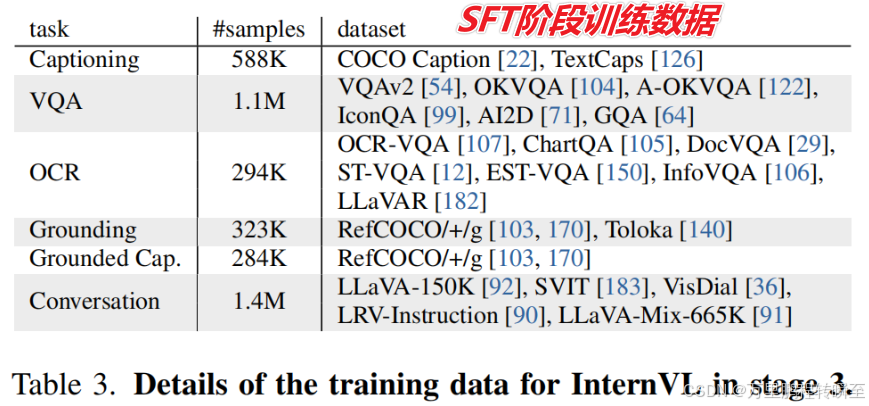
在微调阶段,精心选择数据集,以提高在各种多模态任务中的模型性能。表1b总结了本阶段使用的数据集。在表1中,已经为每个数据集进行了语言注释。对于最初是英文的数据集,作为"zh"的注释表示我们已经使用翻译pipeline将其翻译成中文。例如,COYO 10和GRIT 90最初是英语数据集,已经将它们翻译成了中文。
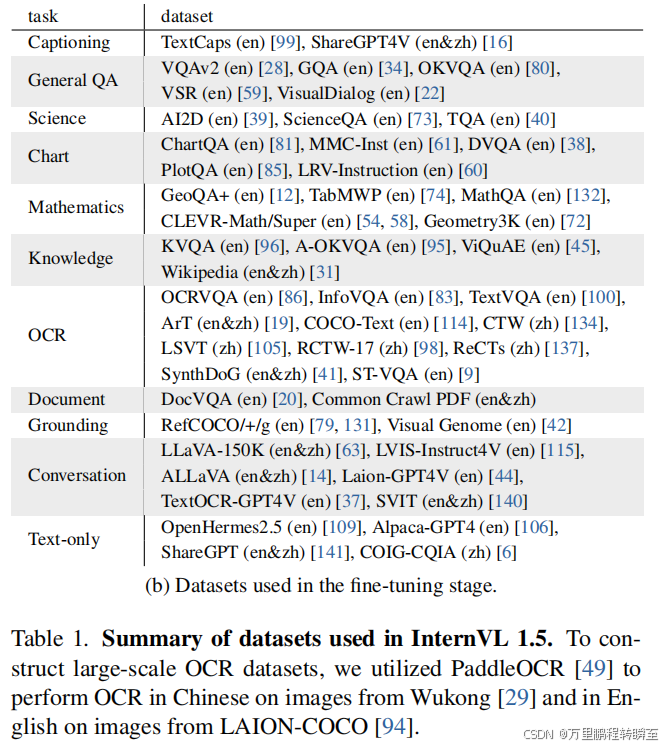
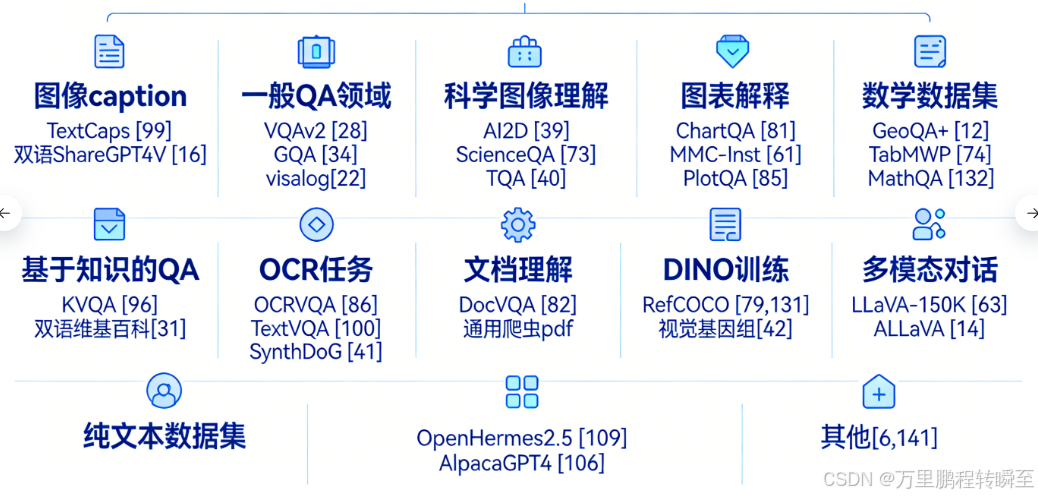
总之,这些数据集一起为微调建立了丰富和多样的基础,这增强了我们的模型处理广泛的多模态任务的能力,并确保其为实际应用做好了准备。
Data Translation Pipeline
**为了增强模型的多语言功能, 实现了一个翻译流程。**该pipeline利用最先进的开源LLMs 4,11,130或GPT-3.5将英语数据集转换为另一种语言(如中文),从而保持双语标签的一致性和精度。此外,它可以通过调整语言提示符,很容易地扩展到包含更多的语言,而不依赖于手动注释过程。

InternVL2
并未介绍数据处理过程,只介绍到是1.5版本的数据集扩展版

InternVL2.5
在 InternVL 2.0 和 2.5 中,训练数据的组织由几个关键参数控制,以优化训练期间数据集的平衡和分布。

数据配比
数据增强:有条件地应用JPEG 压缩:对图像数据集启用以增强稳健性,对视频数据集禁用以保持一致的帧质量。
最大图块数量:该参数控制每个数据集的最大图块数。例如,较高的值 (24-36) 用于多图像或高分辨率数据,较低的值 (6-12) 用于标准图像,1 用于视频。n_max
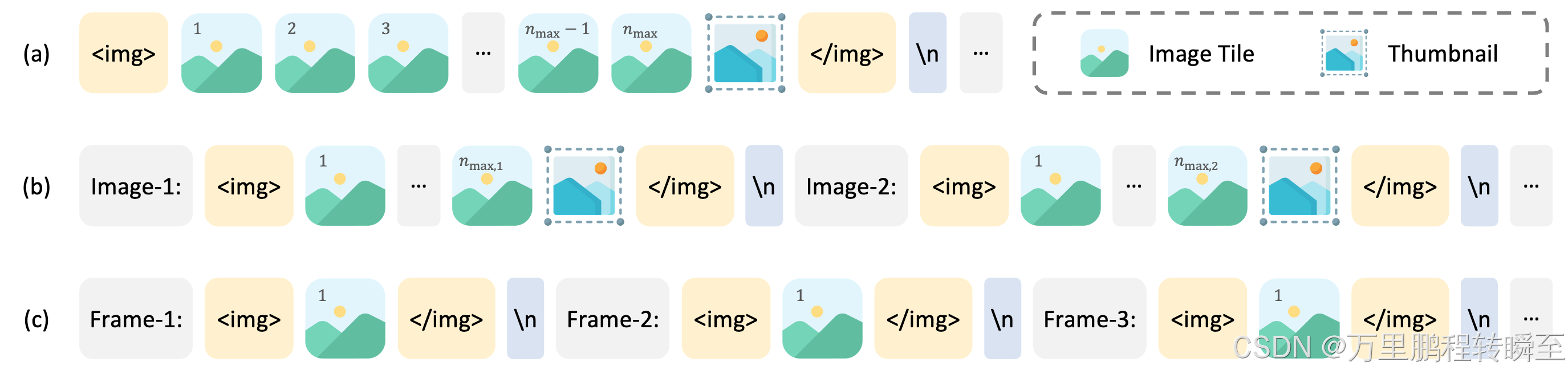
重复系数:重复因子调整数据集采样频率。低于 1 的值会降低数据集的权重,而高于 1 的值会增加数据集的权重。这可确保任务之间的均衡训练,并防止过拟合或欠拟合。
在总体的训练数据规模上,可以发现v2.5比v2模型多了近一倍,同时由于tille数量的变化,训练视觉token数提升的比例变得更大了。
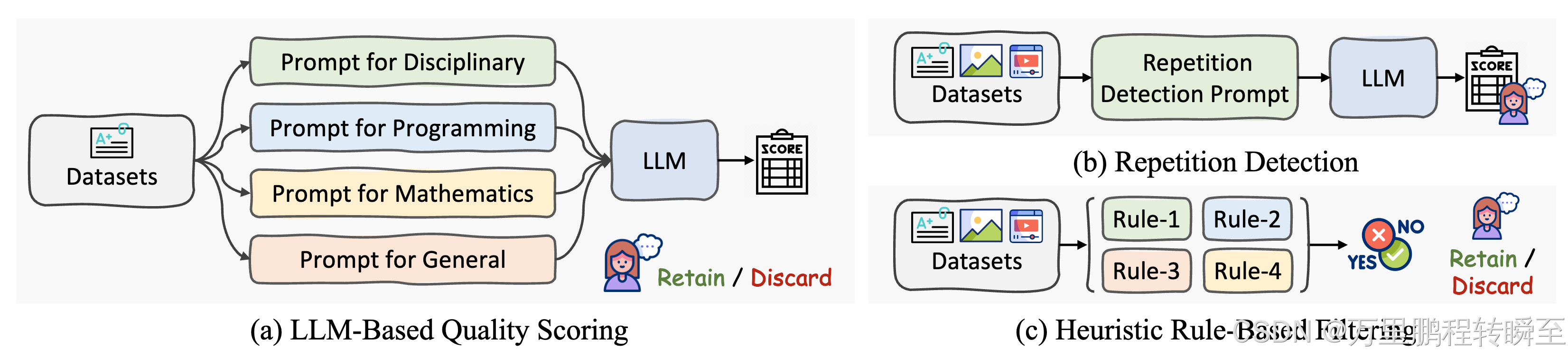
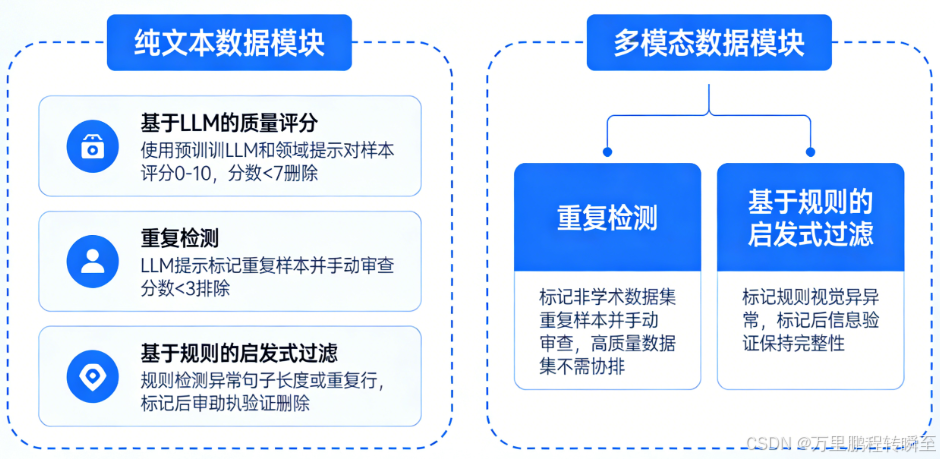
异常数据过滤
作者发现 LLM 对数据噪声高度敏感,即使是很小的异常(如异常值【文本或图片】或重复数据)也会在推理过程中引起异常行为。事实证明,重复生成,尤其是在长格式或 CoT 推理任务中,特别有害。

为了应对这一挑战并支持未来的研究,作者设计了一种高效的数据过滤管道来去除低质量的样本。
InternVL3
https://hpg123.blog.csdn.net/article/details/156064158
仅介绍了其基于原生多模态预训练,将语言预训练与多模态对齐训练整合于同一预训练阶段, 混合输入多模态数据(图文、视频文本等)与大规模纯文本语料实现联合优化,同步学习语言与多模态能力,无需额外桥接模块或跨模型对齐流程即可高效处理跨模态任务。未透露数据处理流程。
InternVL3.5
数据:
- 总计约 1160M 样本(250B token),纯文本 : 多模态 ≈ 1:2.5。
- 覆盖图像描述、OCR、图表理解、医学等多领域。
- 最大序列长度为 32K。