通用机器人预示着这样一个未来:家庭辅助将更加普及,居家养老也能得到可靠、智能的支持。这些机器人将使人类能够以变革性的新方式塑造并与物理世界互动。这场转变的核心是大型行为模型(LBM)------一种具身人工智能系统,它接收机器人的传感器数据并输出动作。LBM 在大型、多样化的操作数据集上进行预训练,是实现稳健通用机器人智能的关键。
然而,尽管 LBM 越来越受欢迎,我们对其当前的实际能力仍缺乏了解。这种不确定性源于在现实世界机器人学中进行严谨大规模评估的困难。因此,算法和数据集设计的进展往往更多是依靠直觉而非证据指导,这阻碍了进步。我们的工作旨在改变这一现状。
安装自行车刹车盘。
(配图说明:安装自行车刹车盘;取芯和切苹果)
结果亮点
我们使用近 1700 小时 的机器人数据训练了一系列基于扩散的 LBM,进行了 1800 次真实世界评估 推演和超过 47000 次模拟推演,以严格研究它们的能力。
发现:轻量级 LBM
-
相比于从零开始训练的策略,能持续提供性能改进;
-
在具有挑战性的环境中,能够用 3-5 倍更少的数据 学习新任务,并对多种环境因素具有鲁棒性;
-
随着预训练数据的增加,性能持续改进。
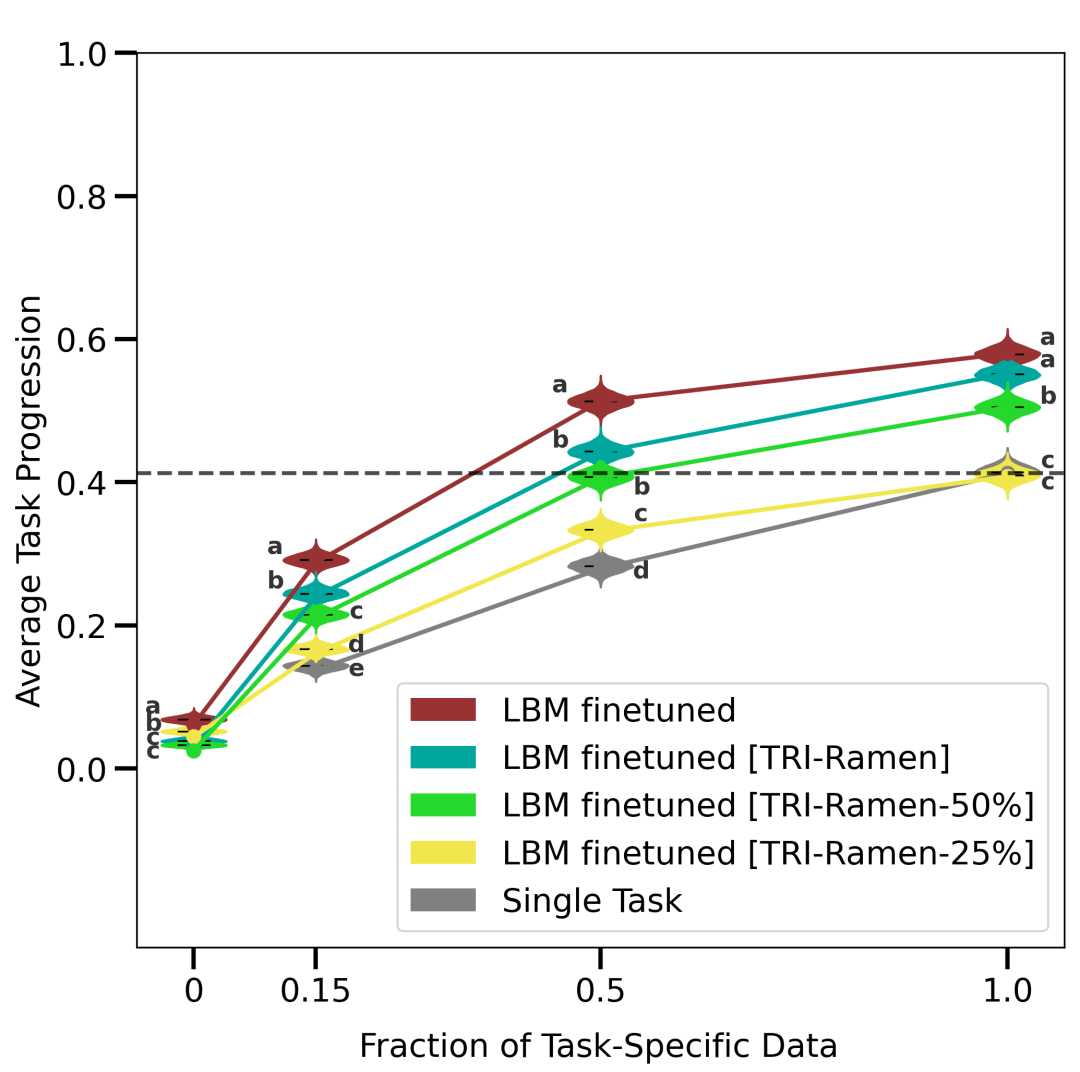
即使只有几百小时的多样化数据------每个行为只有几百个演示------性能也能显著提升。预训练的效果符合预期的规模规律。尽管目前尚未达到互联网规模的机器人数据量,但早在达到那个规模之前就已显示出巨大收益。这是一个令人期待的信号,有助于实现数据采集和性能提升的良性循环。
随着我们向预训练组合中添加更多数据和额外任务,LBM 的性能提升表现得十分平稳。
我们的评估套件包含若干新颖且极具挑战性的长视界现实任务。结果表明,尽管这些行为与预训练任务有很大区别,但在这些环境下经过微调的 LBM 仍能展现出更优的表现。
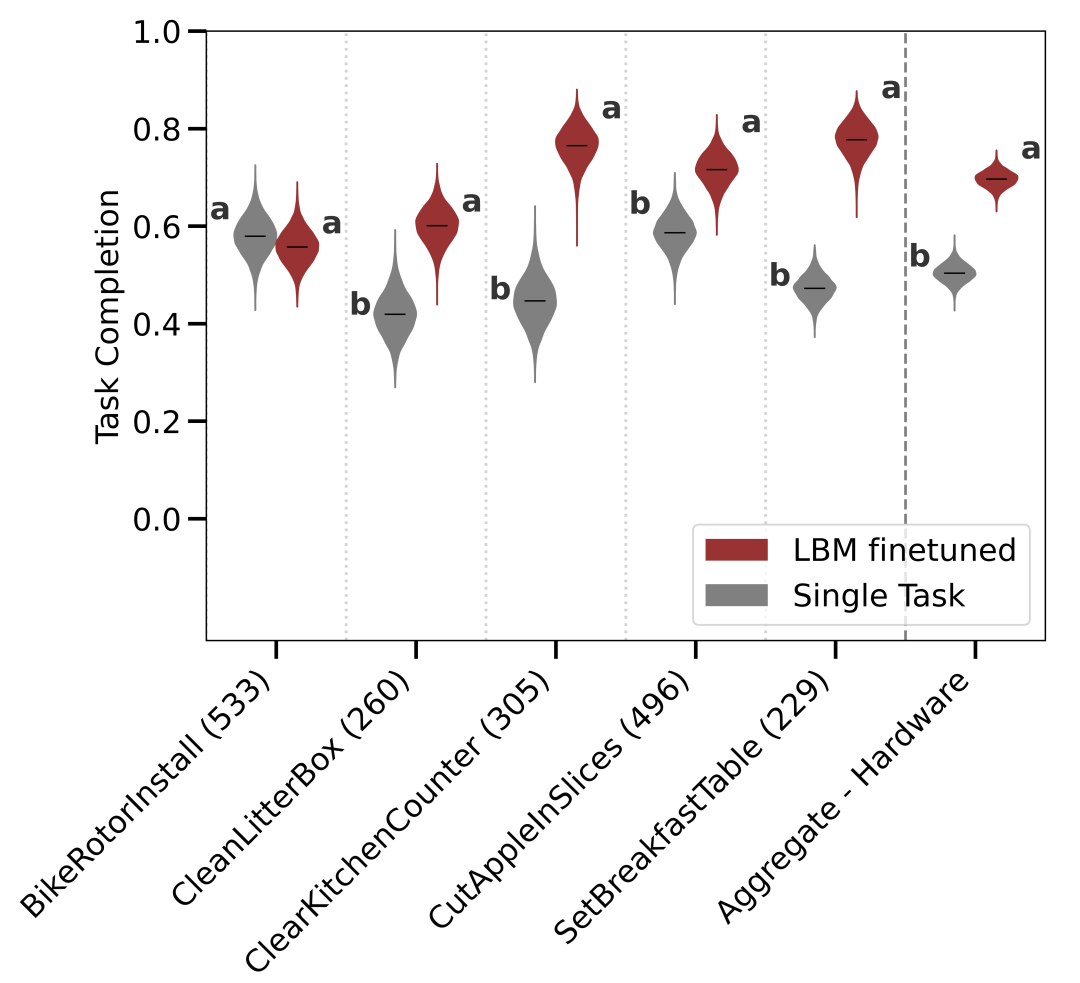
(配图说明:在新的长视界现实任务中取得进展。摆设早餐桌模型的并排对比:(左)单任务基线,(右)LBM。两个视频均为 1 倍速播放。)
LBM ------ 架构与数据
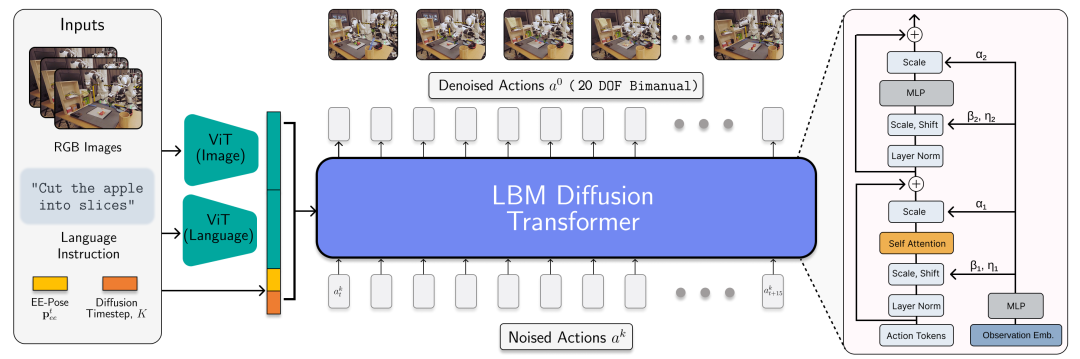
LBM 的架构实例化为一个扩散变压器,用于预测机器人的动作。
-
架构
:我们的 LBM 采用了多模态 ViT 视觉语言编码器,以及通过 AdaLN 编码观测条件的变压器去噪头。
-
输入与输出
:这些模型接收手腕和场景摄像机的图像、机器人本体感知和语言提示,并预测 16 个时间步(1.6 秒)的动作块。
数据来源 :我们通过 468 小时 的内部双手机器人遥操作数据、45 小时 模拟收集的遥操作数据、32 小时 通用操作接口(UMI)数据,以及大约 1150 小时 的公开网络数据进行训练。虽然模拟数据的比例较小,但将其包含在我们的预训练混合数据中,确保了我们可以针对相同的 LBM 检查点在模拟和现实环境中进行评估。
评估 ------ 模拟、真实机器人与严谨协议
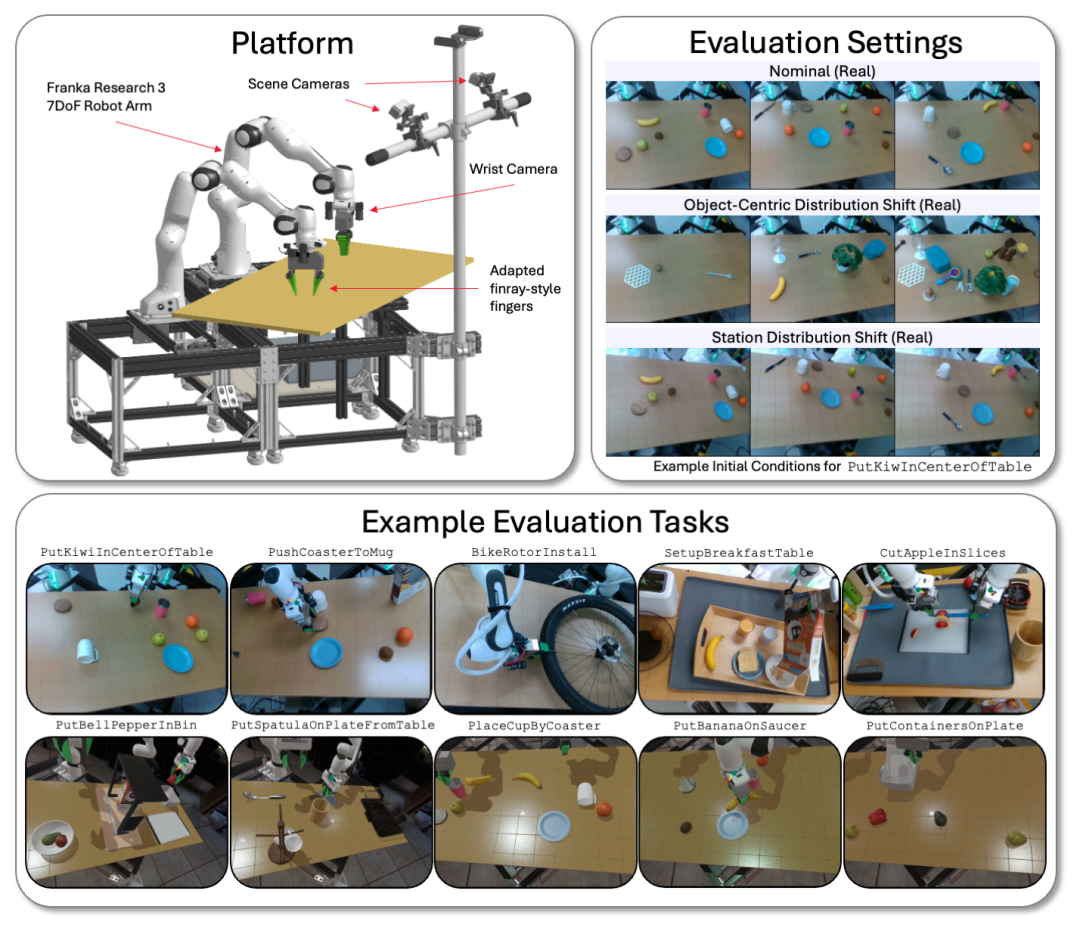
我们的 LBM 在配备了 Franka Panda FR3 机械臂的物理平台和 Drake 模拟双手工作站上进行评估,系统最多使用 六个摄像头------每只手腕各两个,以及两个静态场景摄像机。
我们在双手平台上评估 LBM 模型,涵盖了多种任务和环境条件,无论是模拟环境还是现实世界。我们对模型的评估包括已知任务(存在于预训练数据中)和未见任务(我们对预训练模型进行微调)。我们的评估套件包含:
-
16 个预训练中见过的模拟任务;
-
3 个预训练中见过的真实世界任务;
-
5 个此前未见过的长视界模拟任务;
-
5 个复杂且此前未见过的长视界现实任务。
每个模型通过 50 次真实任务 和 200 次模拟任务 的测试。这使我们的分析能够实现高度的统计严谨性,预训练模型已在 29 个任务中评估了 4200 次部署。
我们精心控制初始条件,使其在现实世界和模拟中保持一致,并在现实世界中进行盲测 A/B 测试,通过顺序假设检验框架计算统计显著性。
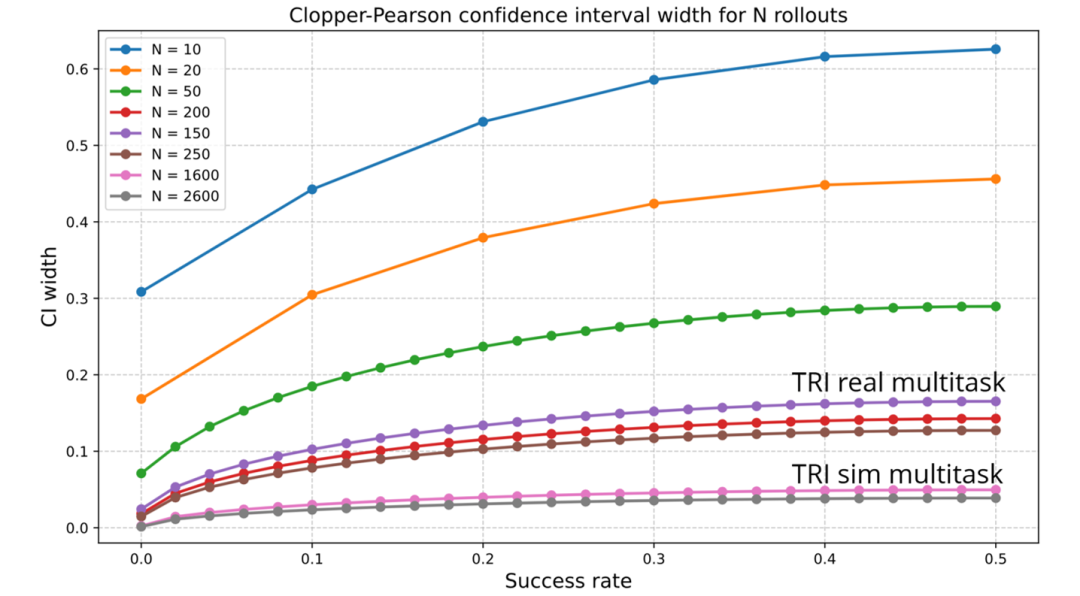
我们观察到的许多效应只有在样本量大于标准水平且进行谨慎统计检验的情况下才能测量,这在实证机器人领域并不常见。由于实验噪声,很容易产生使测量结果失真的变异,许多机器人论文可能因为统计功效不足而仅仅测量到了统计噪声。下图显示了根据推演次数变化的 Clopper-Pearson 置信区间大小。例如,对于 5 种行为,如果进行 50 次推演,最终的置信区间(CI)宽度通常为成功率的 20% 到 30%,这意味着除了最大的效应外,其他效应都无法被可靠地测量。
(配图说明:展示根据评估推演次数的函数来显示置信区间。)
总结
我们的主要结论之一是,随着预训练数据的增加,微调后的性能会平稳提升。在我们分析的数据规模上,未发现性能表现出现不连续或急剧的拐点;人工智能的扩展定律在机器人领域依然适用。
我们确实在未经微调的预训练 LBM 中观察到了好坏参半的结果。令人鼓舞的是,我们发现网络能够同时学习许多任务,但我们并未观察到未经微调的 LBM 能持续优于从头开始的单一任务训练。我们认为这部分原因在于语言对我们模型可控性的影响。在内部测试中,我们看到一些有希望的早期迹象表明更大的 VLA(视觉-语言-动作)原型机克服了部分难题,但要在更高语言容量的模型中严格研究这一效应,还需要更多工作。
我们的发现在很大程度上支持了近年来 LBM 风格机器人基础模型的流行趋势,并进一步证明了对多样化机器人数据进行大规模预训练是迈向更强大机器人能力的可行路径,尽管有几个需要注意的地方。值得注意的是,像数据归一化这样微妙的设计选择可能会对性能产生巨大影响,这种影响往往超过架构或算法的变更。因此,必须仔细隔离这些设计选择,以避免混淆性能变化的根本原因。