MOVA MOSS Video and Audio同步视频-音频设计分析
1. 仓库概览
MOVA (MOSS Video and Audio) 是一个开源的基础模型,专为同步视频-音频生成而设计,旨在打破开源视频生成的"沉默时代"。
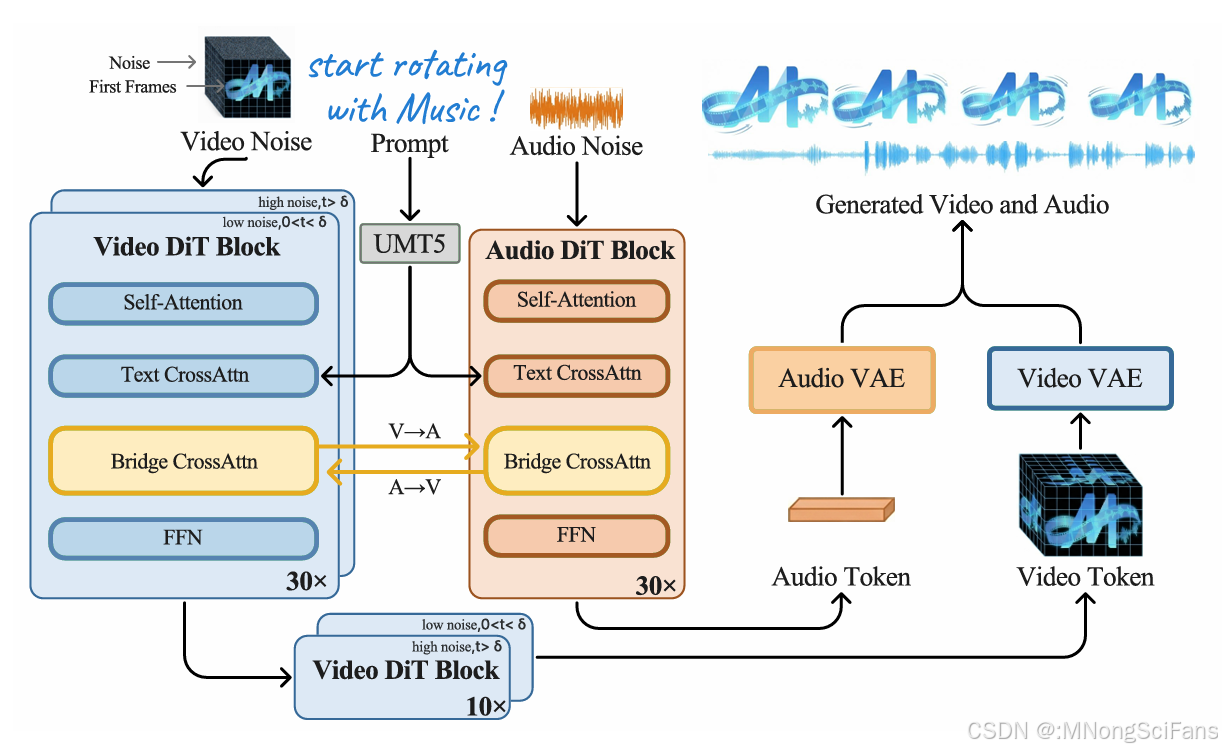 MOVA模型结构概览。MOVA 通过一个 26 亿参数的双向桥接模块,将一个 14 亿参数的视频 DiT 主干和一个 13 亿参数的音频 DiT 主干连接起来。
MOVA模型结构概览。MOVA 通过一个 26 亿参数的双向桥接模块,将一个 14 亿参数的视频 DiT 主干和一个 13 亿参数的音频 DiT 主干连接起来。
主要功能/亮点:
- 原生双模态生成:在单次推理中同时生成高保真视频和同步音频,消除级联错误积累
- 精确的口型同步与音效:在多语言口型同步和环境感知音效方面达到最先进水平
- 全开源:发布模型权重、推理代码、训练管道和LoRA微调脚本
- 非对称双塔架构:利用预训练的视频和音频塔,通过双向交叉注意力机制实现丰富的模态交互
典型应用场景:
- 单人/多人语音视频生成
- 不同场景的视频-音频同步生成
- 通过API和ComfyUI集成到其他系统
2. 目录结构
MOVA项目采用模块化设计,清晰地分离了核心模型、数据处理、训练和推理等组件。项目结构组织合理,便于扩展和维护。
text
d:\MyDrivers\update\MOVA-main/
├── assets/ # 示例资源文件
├── configs/ # 配置文件
│ └── training/ # 训练配置
├── mova/ # 核心代码
│ ├── datasets/ # 数据集相关代码
│ ├── diffusion/ # 扩散模型相关代码
│ │ ├── models/ # 模型定义
│ │ ├── pipelines/ # 推理管道
│ │ └── schedulers/ # 调度器
│ ├── distributed/ # 分布式训练相关
│ ├── engine/ # 训练引擎
│ └── utils/ # 工具函数
├── scripts/ # 脚本文件
│ ├── training_scripts/ # 训练脚本
│ └── inference_*.py # 推理脚本
├── workflow/ # 工作流相关代码
├── README.md # 项目说明
└── pyproject.toml # 项目配置- mova/diffusion/:包含扩散模型的核心实现,包括视频和音频的扩散模型、推理管道和调度器。
- mova/engine/:包含训练相关的代码,包括优化器和训练器。
- mova/datasets/:包含数据集处理和转换相关的代码。
- scripts/:包含推理和训练的脚本文件。
- workflow/:包含AI辅助视频生成工作流的代码。
3. 系统架构与主流程
MOVA采用非对称双塔架构,通过双向交叉注意力机制实现视频和音频的同步生成。系统架构设计如下:
核心架构组件
-
输入处理层:
- 文本编码器 (UMT5EncoderModel):处理文本提示
- 视频处理器:处理输入参考图像
-
扩散模型层:
- 视频DiT (WanModel):两个版本,用于不同噪声水平
- 音频DiT (WanAudioModel):处理音频生成
- 双塔条件桥接器 (DualTowerConditionalBridge):实现视频和音频的双向交互
-
解码层:
- 视频VAE (AutoencoderKLWan):将视频潜在表示解码为实际视频
- 音频VAE (DAC):将音频潜在表示解码为实际音频
主要工作流程
-
输入准备:
- 处理文本提示,生成文本嵌入
- 处理参考图像,生成视频条件
- 初始化视频和音频潜在变量
-
扩散过程:
- 在多个时间步上进行去噪
- 视频和音频通过双塔桥接器进行双向交互
- 在低噪声阶段切换到第二个视频DiT
-
解码过程:
- 视频VAE解码视频潜在表示
- 音频VAE解码音频潜在表示
-
输出:
- 生成同步的视频和音频
解码层
扩散模型层
输入层
文本提示
文本编码器
参考图像
视频处理器
文本嵌入
视频条件
视频DiT
音频DiT
双塔条件桥接器
视频VAE解码
音频VAE解码
生成视频
生成音频
同步视频-音频输出
4. 核心功能模块
4.1 双塔条件桥接器 (DualTowerConditionalBridge)
双塔条件桥接器是MOVA的核心创新,实现了视频和音频之间的双向交互。
功能:
- 控制视频和音频DiT之间的交互策略
- 实现跨模态注意力机制
- 支持跨模态RoPE (Rotary Position Embedding) 对齐
- 提供多种交互策略,如shallow_focus、distributed等
实现细节:
- 使用ConditionalCrossAttentionBlock实现跨模态注意力
- 支持每帧注意力池化 (PerFrameAttentionPooling)
- 实现双向条件控制,即音频→视频和视频→音频
关键代码:
python
# 双向条件控制
visual_conditioned = self.apply_conditional_control(
layer_idx=layer_idx,
direction="a2v",
primary_hidden_states=visual_hidden_states,
condition_hidden_states=audio_hidden_states,
x_freqs=x_freqs,
y_freqs=y_freqs,
condition_scale=a2v_condition_scale if a2v_condition_scale is not None else condition_scale,
video_grid_size=video_grid_size,
)
audio_conditioned = self.apply_conditional_control(
layer_idx=layer_idx,
direction="v2a",
primary_hidden_states=audio_hidden_states,
condition_hidden_states=visual_hidden_states,
x_freqs=y_freqs,
y_freqs=x_freqs,
condition_scale=v2a_condition_scale if v2a_condition_scale is not None else condition_scale,
video_grid_size=video_grid_size,
)4.2 扩散推理管道 (MOVA)
扩散推理管道是MOVA的主要推理接口,实现了从输入到输出的完整推理过程。
功能:
- 处理输入文本和图像
- 执行扩散过程
- 解码生成视频和音频
- 支持多种推理优化策略
实现细节:
- 使用两个视频DiT,在低噪声阶段切换
- 实现CFG (Classifier-Free Guidance) 增强生成质量
- 支持CPU offload和分层offload以减少VRAM使用
关键代码:
python
# 扩散步骤
for idx_step in tqdm(range(total_steps), disable=dist.get_rank() != 0):
timestep, audio_timestep = paired_timesteps[idx_step]
# 切换到低噪声DiT
if not switched and timestep.item() < boundary_timestep:
cur_visual_dit = self.video_dit_2
if remove_video_dit:
self.video_dit = None
gc.collect()
switched = True
# 推理单步
noise_pred_posi = self.inference_single_step(
visual_dit=cur_visual_dit,
visual_latents=latent_model_input,
audio_latents=audio_latents,
context=prompt_embeds,
timestep=timestep,
audio_timestep=audio_timestep,
video_fps=video_fps,
cp_mesh=cp_mesh,
)4.3 跨模态RoPE对齐
跨模态RoPE对齐是MOVA实现视频和音频同步的关键技术。
功能:
- 基于视频帧率和音频帧率对齐位置编码
- 确保视频和音频在时间维度上的同步
实现细节:
- 构建对齐的RoPE (cos, sin) 对
- 考虑第一帧的时间偏移
- 支持不同帧率的视频和音频
关键代码:
python
def build_aligned_freqs(self, video_fps, grid_size, audio_steps, device=None, dtype=None):
"""
基于视频帧率、视频网格大小和音频序列长度构建对齐的RoPE
"""
f_v, h, w = grid_size
L_v = f_v * h * w
L_a = int(audio_steps)
# 音频位置
audio_pos = torch.arange(L_a, device=device, dtype=torch.float32).unsqueeze(0)
# 视频位置:将视频帧对齐到音频步长单位
if self.apply_first_frame_bias_in_rope:
# 考虑"第一帧持续1/video_fps"的偏差
video_effective_fps = float(video_fps) / 4.0
if f_v > 0:
t_starts = torch.zeros((f_v,), device=device, dtype=torch.float32)
if f_v > 1:
t_starts[1:] = (1.0 / float(video_fps)) + torch.arange(f_v - 1, device=device, dtype=torch.float32) * (1.0 / video_effective_fps)
else:
t_starts = torch.zeros((0,), device=device, dtype=torch.float32)
# 转换为音频步长单位
video_pos_per_frame = t_starts * float(self.audio_fps)
else:
# 无第一帧偏差:均匀对齐
scale = float(self.audio_fps) / float(video_fps / 4.0)
video_pos_per_frame = torch.arange(f_v, device=device, dtype=torch.float32) * scale
# 展平为f*h*w;同一帧内的令牌共享相同的时间位置
video_pos = video_pos_per_frame.repeat_interleave(h * w).unsqueeze(0)
# 构建RoPE
dummy_v = torch.zeros((1, L_v, self.head_dim), device=device, dtype=dtype)
dummy_a = torch.zeros((1, L_a, self.head_dim), device=device, dtype=dtype)
cos_v, sin_v = self.rotary(dummy_v, position_ids=video_pos)
cos_a, sin_a = self.rotary(dummy_a, position_ids=audio_pos)
return (cos_v, sin_v), (cos_a, sin_a)4.4 LoRA微调
MOVA支持LoRA微调,允许用户在有限资源下对模型进行定制。
功能:
- 支持低资源LoRA微调(单GPU)
- 支持Accelerate LoRA微调
- 支持Accelerate + FSDP LoRA微调(多GPU)
实现细节:
- 提供多种LoRA配置选项
- 支持不同的优化器和调度器设置
- 提供详细的资源使用参考
关键配置:
- 低资源LoRA:
configs/training/mova_train_low_resource.py - Accelerate LoRA:
configs/training/mova_train_accelerate.py - Accelerate + FSDP LoRA:
configs/training/mova_train_accelerate_8gpu.py
5. 核心 API/类/函数
5.1 MOVA 类
功能:MOVA的主要推理类,实现完整的视频-音频生成流程。
关键参数:
video_vae:视频VAE模型audio_vae:音频VAE模型text_encoder:文本编码器tokenizer:文本分词器scheduler:扩散调度器video_dit:视频DiT模型video_dit_2:低噪声视频DiT模型audio_dit:音频DiT模型dual_tower_bridge:双塔条件桥接器
主要方法:
__call__:执行完整的推理过程inference_single_step:执行单步扩散推理forward_dual_tower_dit:执行双塔DiT的前向传播
使用示例:
python
# 生成视频-音频
video, audio = mova_pipeline(
prompt="A man speaks in a formal indoor setting",
image=reference_image,
height=352,
width=640,
num_frames=193,
video_fps=24.0,
num_inference_steps=50,
cfg_scale=5.0,
)5.2 DualTowerConditionalBridge 类
功能:实现视频和音频DiT之间的双向条件控制。
关键参数:
visual_layers:视频DiT的层数audio_layers:音频DiT的层数visual_hidden_dim:视频DiT的隐藏维度audio_hidden_dim:音频DiT的隐藏维度interaction_strategy:交互策略apply_cross_rope:是否应用跨模态RoPE
主要方法:
forward:执行双向条件控制build_aligned_freqs:构建对齐的RoPEshould_interact:检查指定层是否应该交互
使用示例:
python
# 双向条件控制
visual_conditioned, audio_conditioned = dual_tower_bridge(
layer_idx=layer_idx,
visual_hidden_states=visual_x,
audio_hidden_states=audio_x,
x_freqs=visual_rope_cos_sin,
y_freqs=audio_rope_cos_sin,
video_grid_size=grid_size,
)5.3 CrossModalInteractionController 类
功能:控制视频和音频塔之间的交互策略。
关键参数:
visual_layers:视频DiT的层数audio_layers:音频DiT的层数
主要方法:
get_interaction_layers:获取交互层映射should_interact:检查指定层是否应该交互
使用示例:
python
# 获取交互策略
controller = CrossModalInteractionController(visual_layers=30, audio_layers=30)
interaction_mapping = controller.get_interaction_layers(strategy="shallow_focus")5.4 PerFrameAttentionPooling 类
功能:对视频帧进行注意力池化,生成每帧的表示。
关键参数:
dim:输入维度num_heads:注意力头数
主要方法:
forward:执行注意力池化
使用示例:
python
# 每帧注意力池化
pooled = per_frame_pooling(x, grid_size=(T, H, W))5.5 推理脚本函数
功能:提供命令行接口,用于生成视频-音频。
关键参数:
ckpt_path:模型 checkpoint 路径prompt:文本提示ref_path:参考图像路径output_path:输出路径height/width:视频高度/宽度num_frames:视频帧数video_fps:视频帧率
使用示例:
bash
python scripts/inference_single.py \
--ckpt_path /path/to/MOVA-360p/ \
--prompt "A man speaks in a formal indoor setting" \
--ref_path "./assets/single_person.jpg" \
--output_path "./data/samples/single_person.mp4" \
--height 352 \
--width 640 \
--num_frames 193 \
--video_fps 24.06. 技术栈与依赖
| 类别 | 技术/库 | 用途 | 来源 |
|---|---|---|---|
| 核心框架 | PyTorch | 深度学习框架 | pyproject.toml |
| 扩散模型 | Diffusers | 扩散模型库 | mova/diffusion/pipelines/pipeline_mova.py |
| 文本处理 | Transformers (T5) | 文本编码 | mova/diffusion/pipelines/pipeline_mova.py |
| 视频处理 | VideoProcessor | 视频预处理 | mova/diffusion/pipelines/pipeline_mova.py |
| 音频处理 | DAC | 音频VAE | mova/diffusion/models/dac_vae.py |
| 分布式训练 | Accelerate, FSDP | 分布式训练 | configs/training/accelerate/ |
| 推理优化 | SGLang | 高吞吐量推理 | workflow/launch_sglang_server.sh |
| 模型压缩 | LoRA | 参数高效微调 | mova/engine/trainer/ |
| 可视化 | Streamlit | 交互式工作流 | workflow/launch_streamlit.sh |
7. 关键模块与典型用例
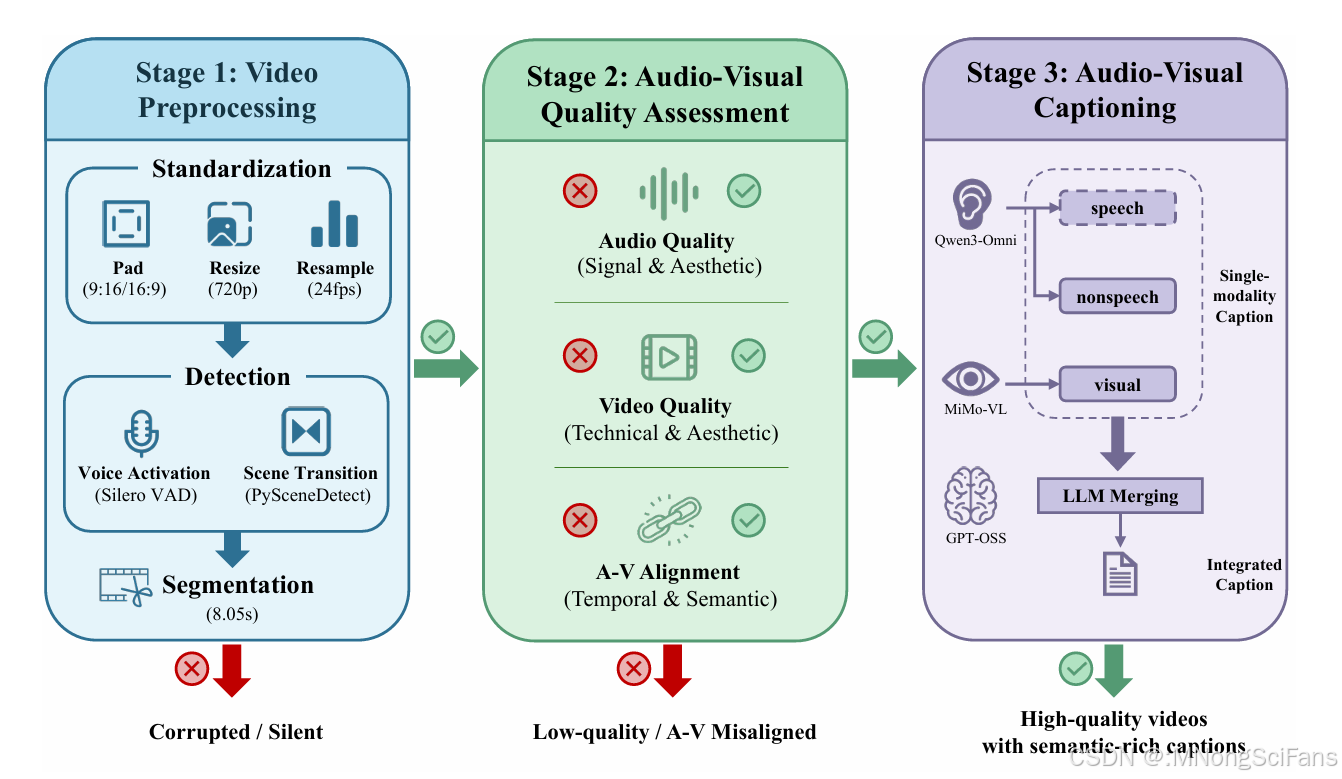 MOVA数据整理概览。我们的数据管道包括三个阶段。在第一阶段,我们将原始数据预处理为固定长度的片段,分辨率为720p,帧率为24fps,时长为8.05秒。在第二阶段,我们根据音频质量、视频质量以及音视频对齐情况对这些片段进行筛选,以获取高质量、同步的片段。在第三阶段,我们分别利用Qwen3-Omni和MiMo-VL对视频中的音频和视觉信息进行标注,最后使用GPT-OSS合并这些单模态字幕。通过我们的数据管道,我们已成功整理出高质量的音视频内容及其对应的语义丰富的字幕。
MOVA数据整理概览。我们的数据管道包括三个阶段。在第一阶段,我们将原始数据预处理为固定长度的片段,分辨率为720p,帧率为24fps,时长为8.05秒。在第二阶段,我们根据音频质量、视频质量以及音视频对齐情况对这些片段进行筛选,以获取高质量、同步的片段。在第三阶段,我们分别利用Qwen3-Omni和MiMo-VL对视频中的音频和视觉信息进行标注,最后使用GPT-OSS合并这些单模态字幕。通过我们的数据管道,我们已成功整理出高质量的音视频内容及其对应的语义丰富的字幕。
7.1 单人语音视频生成
功能说明:生成单人说话的视频-音频,包含精确的口型同步。
配置与依赖:
- 模型:MOVA-360p 或 MOVA-720p
- 硬件:至少12GB VRAM(使用分层offload)
使用示例:
bash
export CP_SIZE=1
export CKPT_PATH=/path/to/MOVA-360p/
torchrun \
--nproc_per_node=$CP_SIZE \
scripts/inference_single.py \
--ckpt_path $CKPT_PATH \
--cp_size $CP_SIZE \
--height 352 \
--width 640 \
--prompt "A man in a blue blazer and glasses speaks in a formal indoor setting, framed by wooden furniture and a filled bookshelf. Quiet room acoustics underscore his measured tone as he delivers his remarks. At one point, he says, \"I would also say that this election in Germany wasn't surprising.\"" \
--ref_path "./assets/single_person.jpg" \
--output_path "./data/samples/single_person.mp4" \
--seed 42 \
--offload cpu7.2 多人语音视频生成
功能说明:生成多人对话的视频-音频,包含多人的口型同步。
配置与依赖:
- 模型:MOVA-360p 或 MOVA-720p
- 硬件:至少12GB VRAM(使用分层offload)
使用示例:
bash
export CP_SIZE=1
export CKPT_PATH=/path/to/MOVA-360p/
torchrun \
--nproc_per_node=$CP_SIZE \
scripts/inference_single.py \
--ckpt_path $CKPT_PATH \
--cp_size $CP_SIZE \
--height 352 \
--width 640 \
--prompt "The scene shows a man and a child walking together through a park, surrounded by open greenery and a calm, everyday atmosphere. As they stroll side by side, the man turns his head toward the child and asks with mild curiosity, in English, \"What do you want to do when you grow up?\" The boy answers with clear confidence, saying, \"A bond trader. That's what Don does, and he took me to his office.\" The man lets out a soft chuckle, then responds warmly, \"It's a good profession.\" as their walk continues at an unhurried pace, the conversation settling into a quiet, reflective moment." \
--ref_path "./assets/multi_person.png" \
--output_path "./data/samples/multi_person.mp4" \
--seed 42 \
--offload cpu7.3 LoRA微调
功能说明:使用LoRA对MOVA进行参数高效微调,适应特定领域或风格。
配置与依赖:
- 环境:安装训练依赖
pip install -e ".[train]" - 数据:准备视频+音频数据集
- 配置:选择合适的训练配置文件
使用示例:
bash
# 低资源LoRA微调(单GPU)
bash scripts/training_scripts/example/low_resource_train.sh
# Accelerate LoRA微调(1 GPU)
bash scripts/training_scripts/example/accelerate_train.sh
# Accelerate + FSDP LoRA微调(8 GPUs)
bash scripts/training_scripts/example/accelerate_train_8gpu.sh8. 配置、部署与开发
8.1 环境配置
基础环境:
- Python 3.13
- PyTorch
- 相关依赖:
pip install -e .
训练环境:
- 额外依赖:
pip install -e ".[train]" - 包含 torchcodec 和 bitsandbytes
8.2 模型下载
| 模型 | 下载链接 | 说明 |
|---|---|---|
| MOVA-360p | Huggingface | 支持 TI2VA |
| MOVA-720p | Huggingface | 支持 TI2VA |
下载命令:
bash
hf download OpenMOSS-Team/MOVA-360p --local-dir /path/to/MOVA-360p
hf download OpenMOSS-Team/MOVA-720p --local-dir /path/to/MOVA-720p8.3 部署选项
本地部署:
- 使用推理脚本直接运行
- 支持CPU offload和分层offload以减少VRAM使用
SGLang部署:
- 支持高吞吐量推理
- 提供命令行生成和在线服务
API访问:
- 可通过 studio.mosi.cn 申请API密钥
- 提供RESTful API接口
ComfyUI集成:
- 通过 comfyui-mova 插件集成到ComfyUI
- 支持I2VA和T2VA工作流
8.4 开发流程
- 环境设置:安装依赖
- 模型下载:下载预训练模型
- 推理测试:使用示例脚本生成视频-音频
- 数据准备:准备自定义数据集
- LoRA微调:使用合适的配置进行微调
- 评估:使用Verse-Bench和人类评估进行评估
9. 监控与维护
9.1 推理性能监控
资源使用:
- VRAM使用:根据offload策略不同,VRAM使用在12GB-48GB之间
- Host RAM使用:在66GB-76GB之间
- 推理时间:根据硬件不同,生成8秒360p视频的时间在9秒-42秒之间
性能基准:
| Offload策略 | VRAM (GB) | Host RAM (GB) | 硬件 | 步时间 (s) |
|---|---|---|---|---|
| 组件级offload | 48 | 66.7 | RTX 4090 | 37.5 |
| 组件级offload | 48 | 66.7 | H100 | 9.0 |
| 分层offload | 12 | 76.7 | RTX 4090 | 42.3 |
| 分层offload | 12 | 76.7 | H100 | 22.8 |
9.2 训练资源监控
资源使用:
- 低资源LoRA:≈18GB VRAM,≈80GB Host RAM
- Accelerate LoRA:≈100GB VRAM,≥128GB Host RAM
- Accelerate + FSDP LoRA:≈50GB VRAM/ GPU,≥128GB Host RAM
训练速度:
| 模式 | 硬件 | 步时间 (s) |
|---|---|---|
| 低资源LoRA(单GPU) | RTX 4090 | 600 |
| Accelerate + FSDP LoRA(8 GPUs) | H100 | 22.2 |
9.3 常见问题与解决方案
| 问题 | 可能原因 | 解决方案 |
|---|---|---|
| VRAM不足 | 模型和中间激活占用过多VRAM | 使用 --offload cpu 或 --offload group |
| Host RAM不足 | 模型和中间激活占用过多Host RAM | 使用 --remove_video_dit 减少Host RAM使用 |
| 推理速度慢 | 硬件限制或offload策略 | 使用更强大的GPU或调整offload策略 |
| 口型同步不准确 | 文本提示不够详细或模型未针对特定语言优化 | 提供更详细的文本提示,包含明确的对话内容 |
10. 总结与亮点回顾
MOVA是一个突破性的开源视频-音频同步生成模型,通过非对称双塔架构和双向交叉注意力机制,实现了高质量的视频和音频同步生成。
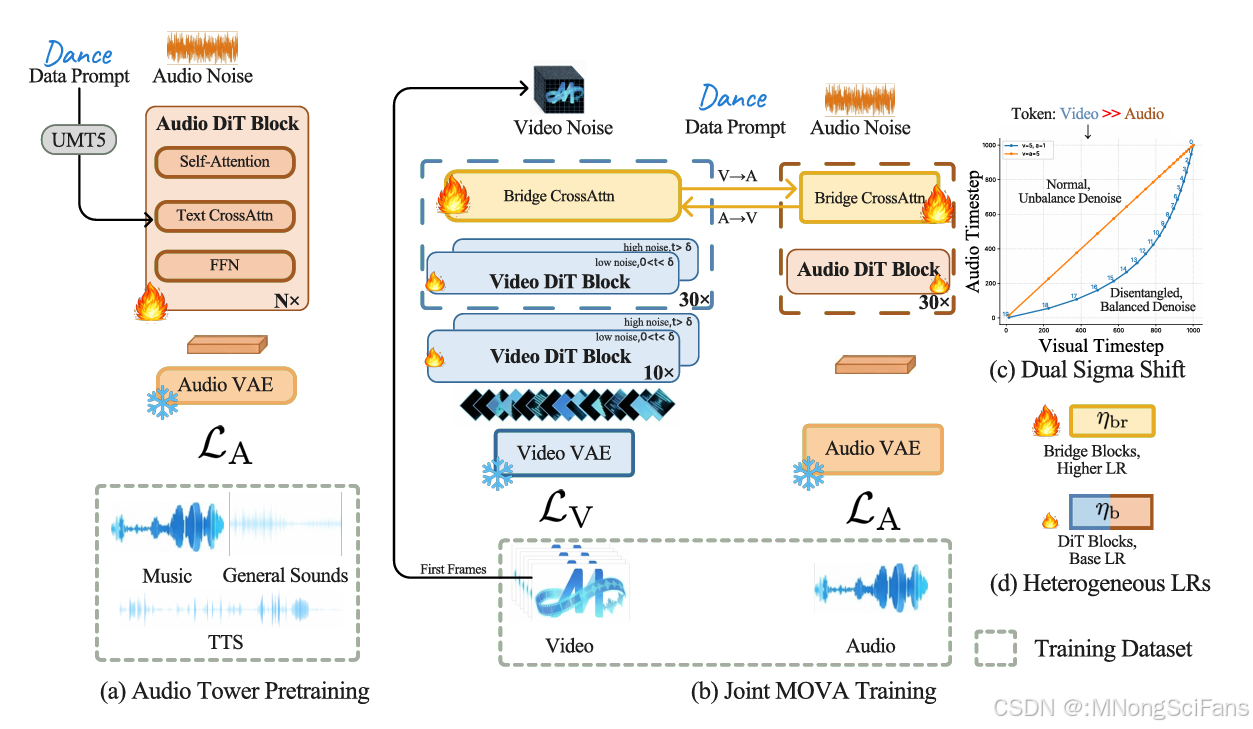 MOVA训练流程概览。 (a) 音频塔预训练:我们使用 Wan2.1 风格架构在音乐、通用声音和 TTS 数据上训练一个 13 亿参数的文本到音频模型。在此阶段,音频 VAE 保持冻结。 (b) 同步联合训练:视频塔(A14B,蓝色)和音频塔(1.3B,橙色)通过双向桥接跨注意力模块连接。 © 视频和音频时间步独立采样,使每种模态都可以遵循其自己的噪声计划。 (d) 桥接模块使用比骨干 DiT 模块更高的学习率(𝜂br = 2 × 10−5,骨干 𝜂b = 1 × 10−5)来加速跨模态对齐,同时保留预训练先验。在整个训练过程中,两个 VAE 都保持冻结。
MOVA训练流程概览。 (a) 音频塔预训练:我们使用 Wan2.1 风格架构在音乐、通用声音和 TTS 数据上训练一个 13 亿参数的文本到音频模型。在此阶段,音频 VAE 保持冻结。 (b) 同步联合训练:视频塔(A14B,蓝色)和音频塔(1.3B,橙色)通过双向桥接跨注意力模块连接。 © 视频和音频时间步独立采样,使每种模态都可以遵循其自己的噪声计划。 (d) 桥接模块使用比骨干 DiT 模块更高的学习率(𝜂br = 2 × 10−5,骨干 𝜂b = 1 × 10−5)来加速跨模态对齐,同时保留预训练先验。在整个训练过程中,两个 VAE 都保持冻结。
核心亮点
-
原生双模态生成:在单次推理中同时生成视频和音频,消除了级联错误积累,实现了完美的同步。
-
精确的口型同步与音效:通过跨模态RoPE对齐和双向条件控制,实现了精确的多语言口型同步和环境感知音效。
-
非对称双塔架构:利用预训练的视频和音频塔,通过双向交叉注意力机制实现了丰富的模态交互。
-
全开源:发布了模型权重、推理代码、训练管道和LoRA微调脚本,为开源社区提供了完整的视频-音频生成解决方案。
-
灵活的交互策略:提供了多种交互策略,如shallow_focus、distributed等,适应不同的生成需求。
-
高效的推理优化:支持多种推理优化策略,如CPU offload和分层offload,降低了硬件要求。
-
广泛的集成支持:支持SGLang、API访问和ComfyUI集成,方便在不同场景中使用。
-
强大的性能:在Verse-Bench和人类评估中表现优异,证明了其生成质量的先进性。
MOVA的出现标志着开源视频生成进入了"有声时代",为视频内容创作、虚拟人、教育培训等领域提供了新的可能性。随着模型的不断发展和社区的参与,MOVA有望在未来进一步提升生成质量和降低资源需求,成为视频-音频生成的标准工具。
MOVA与SEEDANCE 2.0对比表格
| 维度 | Seedance 2.0 | MOVA核心能力 |
|---|---|---|
| 音视频联合生成 | 未公开 | 320 亿(MoE,激活 180 亿) |
| 多语言唇形 | 支持 | 支持(中英文 SOTA) |
| 生成质量 | 商业级 | 学术级(持续优化中) |
| API 服务 | ✅ 即梦平台 | ❌ 暂无 |
| 本地部署 | ❌ 不支持 | ✅ 完全支持,多硬件适配 |
| 模型权重 | ❌ 闭源 | ✅ 开源 |
| 训练代码 | ❌ 闭源 | ✅ 开源 |
| 微调支持 | ❌ 不支持 | ✅ 支持 LoRA |
| 商用授权 | 按调用付费 | Apache License2.0(可商用) |
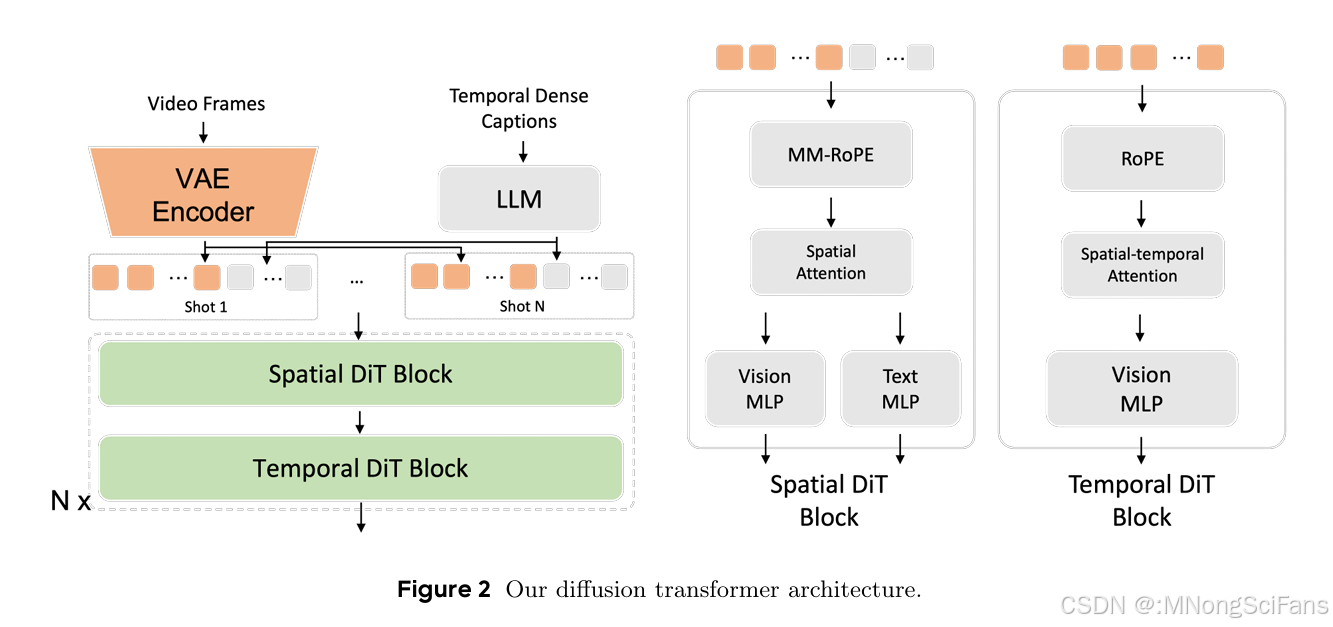
Seedance 1.0 扩散变换器架构
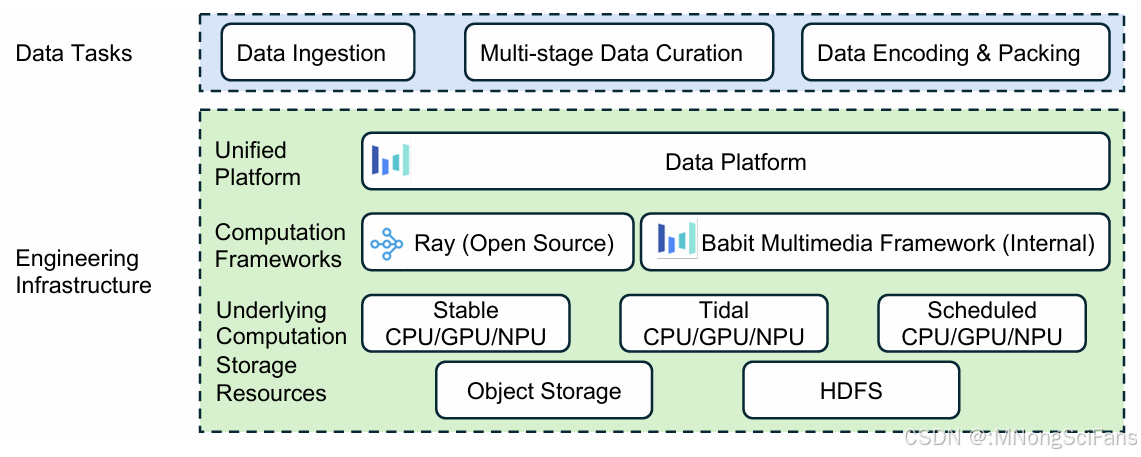
Seedance 1.0 视频数据处理管道,将异构的原始视频转换为精炼且特征丰富的训练数据集。工作流程包括三个主要阶段:(1) 面向多样性的 数据获取,用于从多种来源进行初步采集和合规性预筛选;(2) 多阶段数据整理,将原始数据精炼为视频片段;以及 (3) 离线数据打包,使用视频字幕和VAE编码生成用于模型训练的文本和VAE嵌入。
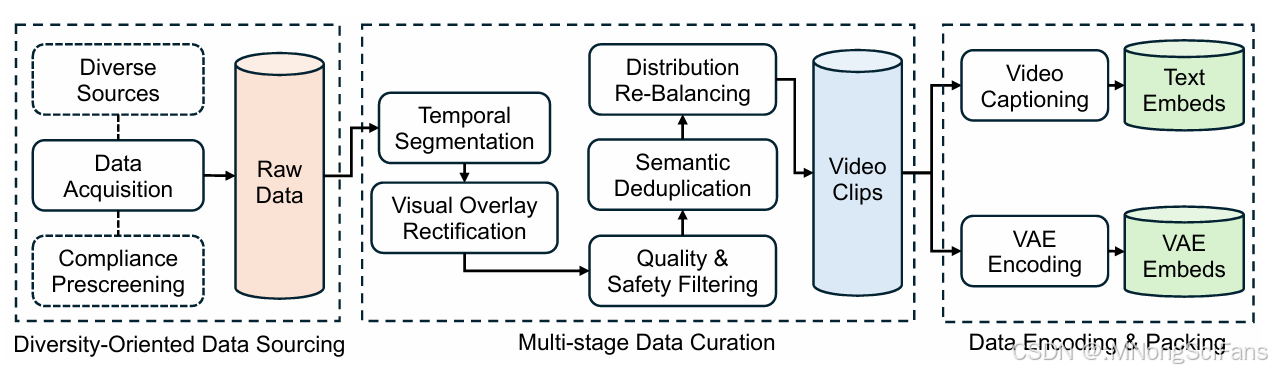
Seedance 1.0 用于数据处理的工程基础设施概述
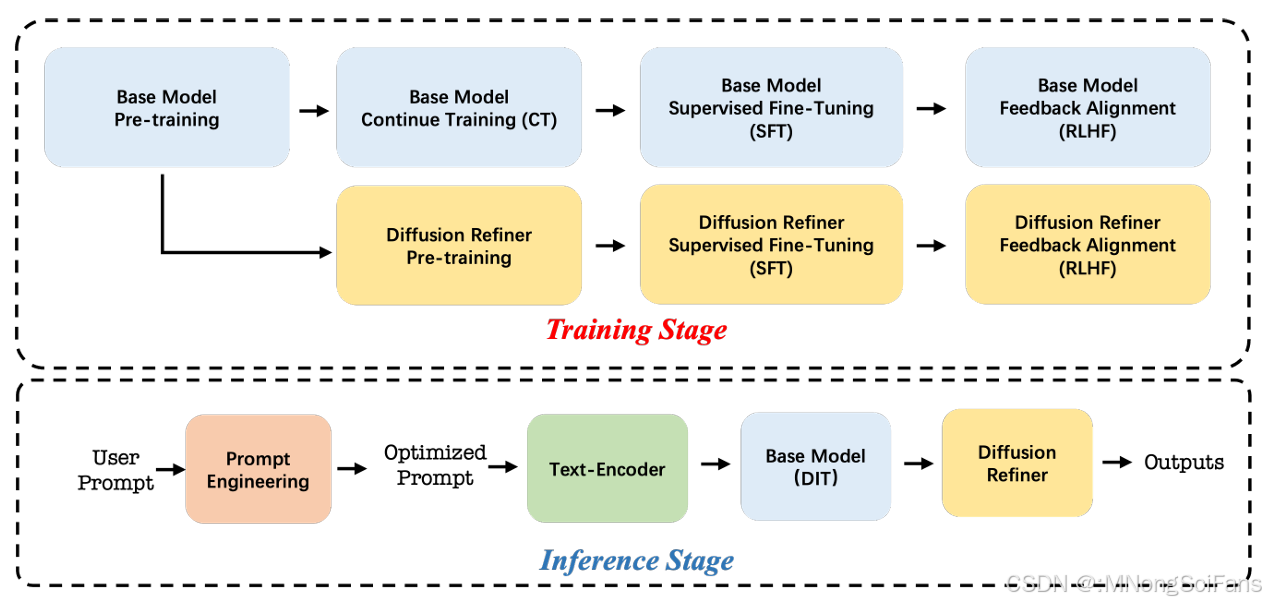
Seedance 1.0 训练和推理流程概览
参考链接
- 参考1:MOVA:TowardsScalable and Synchronized
Video--Audio Generation
SII-OpenMOSS Team arXiv:2602.08794 - 参考2:Seedance 1.0: Exploring the Boundaries of
Video Generation Models
ByteDance Seed arXiv:2506.09113 PDF - 参考3:MOVA GitHub
- 参考4:[什么?有人把 即梦Seedance2.0 开源了!(https://mp.weixin.qq.com/s/hHlfagoEzCzZWfv3Pm0gVA)
- 参考5:SEEDANCE平台
- 参考6:OpenMOSS HuggingFace模型