一.JVM(Java虚拟机)
**java虚拟机:**仿造操作系统进行的设计,真正的操作系统对于进程的地址空间进行了分区域的设计
JVM也就仿造操作系统进行了分区域的设计。
二.JVM(Java虚拟机)创造过程和内存区域划分
1.JVM创造过程
1)编译阶段(javac进程)
.java会由javac进程编译成.class文件,javac进程也会创造一个临时JVM实例(用完就销毁)来进行编译(可以在编译阶段就知道错误,不然会在运行时才知道)
2)运行阶段(java进程)
这时会创造一个新的操作系统进程,该进程的入口是JVM的C++启动代码,之后创造JVM实例(java虚拟机)
2.JVM内存划分
主要4个核心区域
1)程序计数器(线程私有)
**作用:**记录当前指针执行到哪里了
2)方法区(jdk8叫做元数据区)(线程共享)
保存类加载好的数据,即通过类加载器加载.class文件。
3)堆(线程共享)
保存通过new出来的对象,如Text t =new Text(),t引用如果是局部变量就在栈中,如果是成员变量就在堆区,如果是静态成员变量就在元数据区,t引用指向的对象在堆区
4)栈(线程私有)
每个 Java 方法被调用时,会在 Java 虚拟机栈 中创建一个栈帧,用于存储局部变量表、操作数栈、动态链接、方法出口等信息。
但有些方法被标记为 native (如 Thread.sleep() ),表示它们由底层语言(通常是 C/C++)实现。
当 Java 代码调用一个 native 方法时,JVM 不会在 Java 虚拟机栈中为该 native 方法创建栈帧 ,而是切换到 本地方法栈 ,在该栈中为 native 方法创建栈帧(遵循 C 调用约定)。
native 方法执行期间,程序计数器仍会记录执行位置(但可能指向 native 代码地址)。执行完成后,结果被返回,本地方法栈的对应栈帧弹出,控制权交还给 Java 虚拟机栈中原来的调用者栈帧,继续执行后续的 Java 代码。
三.JVM类加载
1.JVM类加载的过程
a)加载
找到.class文件,根据类的全限定名(如java.lang.String),打开文件,读取文件中的内容到内存中
还会在堆中创建一个java.lang.Class对象
b)验证
校验.class文件是否是合法的
c)准备
给**类变量(static 变量)**在方法区申请内存空间(是全0的空间)
d)解析
将常量池中的符号引用 (字面量形式)替换为直接引用(如内存地址、偏移量)。
e)初始化
针对类对象的初始化,对类对象的各种属性进行初始化,如果有父类,父类优先初始化
2.JVM类加载的双亲委派模型
JVM默认提供了三种类加载器
BootstrapClassLoder(爷,java标准库)-----ExtensionClassLoder(爹,java扩展库的目录)----
ApplicationClassLoder(子,java的第三方库/当前项目)
注意:这里是没有继承关系的,而是通过类似于parent这样的引用指向的
过程:
通过全限定类名,找.class文件的时候,先会从ApplicationClassLoder加载器开始,然后把类加载的任务委托给父亲ExtensionClassLoder加载器,但该加载器不会立即执行任务,也是将该任务委派给父亲BootstrapClassLoder加载器,但BootstrapClassLoder加载器没有父亲了,只能自己进行类加载了,根据类名从标准库开始找与之对应的.class文件,如果没找到就把任务交给孩子继续一样的过程,当没有孩子时还没找到就会抛出异常
四.垃圾回收
现在Java垃圾回收最主流的方案为GC
GC工作过程:
1.找到垃圾
有俩种方案,分别为引用计数和可达性分析
1)引用计数
每次new一个对象时,都会搭配上一个很小的内存来来保存一个整数,这个整数代表有多少个引用指向该对象,如果该数为0,就说明没有对象引用它了,该对象就是垃圾。
缺点:
(1) 内存消耗更多
(2)可能出现循环引用问题
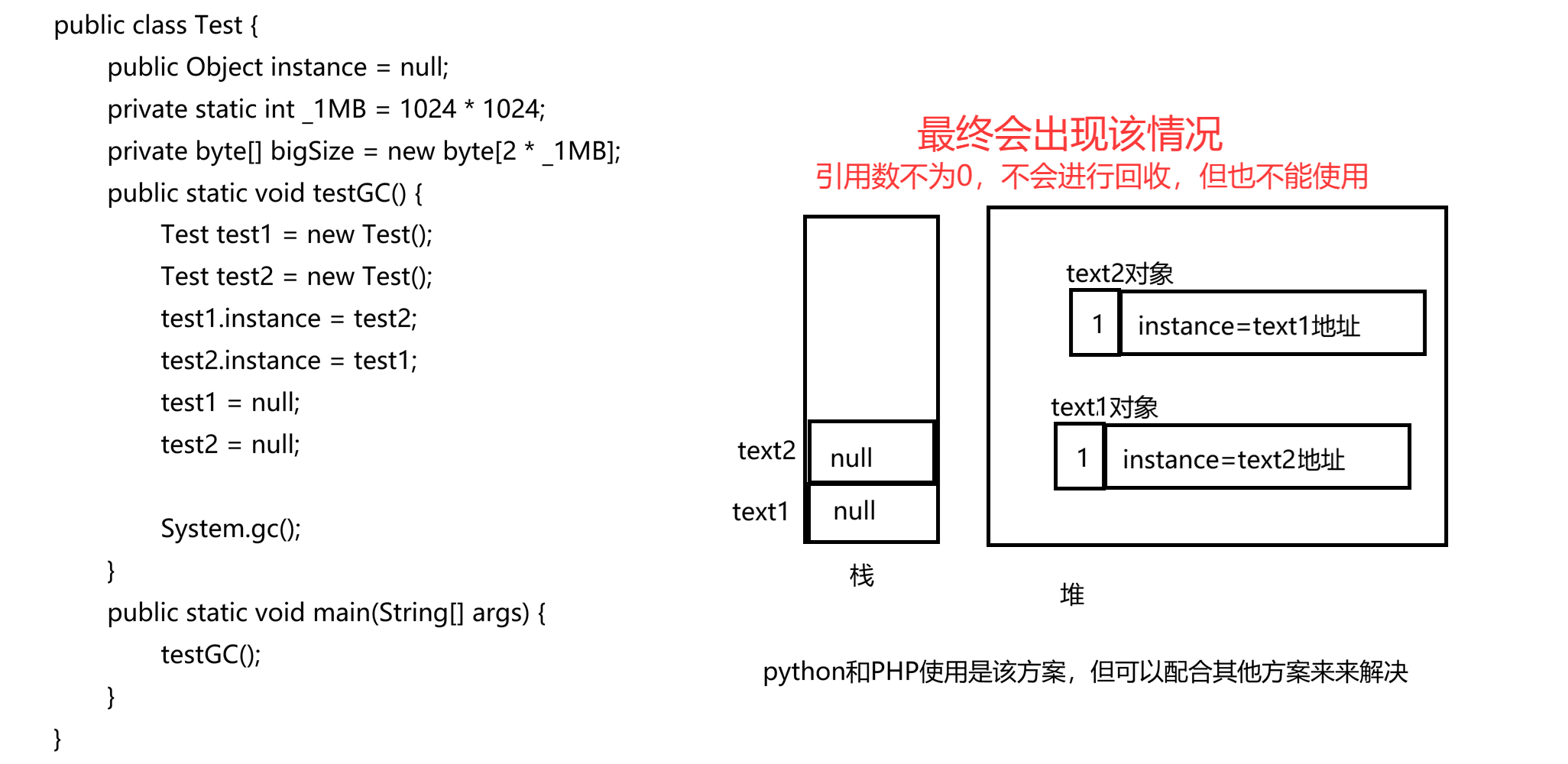
2)可达性分析(java使用该方案)
该方案是以时间换取空间,以代码的的一组特定对象集合---GCRoots(引用变量,比如局部变量,静态成员变量)作为起点,尽可能的进行遍历,每访问一个对象就把该对象标记为"可达",没访问到的对象就是"不可达"遍历完能遍历的所有对象后,JVM中一共有多少个对象,JVM自身是知道的,所以通过可达性分析就知道那些对象不可达,那些对象可达。
2.释放垃圾
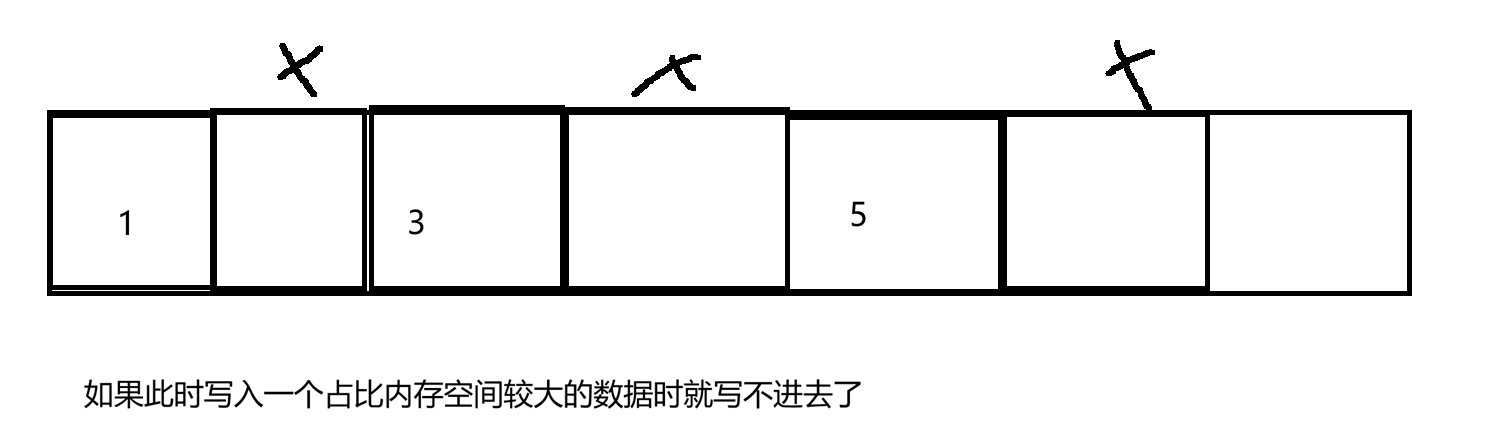
1)标记清除法
直接清除未标记的对象,但会出现内存碎片问题
2).复制算法
把内存分为俩半,一边存储数据,另一边空着,等GC回收时,使用标记清除法把垃圾回收,然后把没有回收的对象复制到空着的一边,下次回收后就复制回去。
**缺点:**一但复制对象比较多时,复制对象的开销会非常大,而且浪费了一半的空间
3).标记整理法
直接进行标记清除,然后把数据搬运到一块
**缺点:**搬运开销非常大
4).分代回收(java使用这个)
引入年龄机制,GC回收是周期性的,每隔一段时间进行一次GC,一个对象每经历一次GC,年龄就会加1,把区域划分成新生代(年龄较小值)和老年代俩快区域(年龄较大值)
由于老年代进行多次GC,大概率会存活很久,GC频率就可以降低,而新生代大部分不会经过一次GC,GC频率比较高。所以针对不同区域使用不同的方案。
新生代采用复制算法,把新生代区域分为俩个区域,分别为大伊甸区和多个小幸存区,一开始数据会存在伊甸区,然后进行一次GC后,就会存活来的对象通过复制到幸存区,下一次进行GC时,幸存区也会进行GC,然后把幸存的对象复制到另一个幸存区中,经过多次GC后,年龄达到一定值就会复制到老年代。
老年代采用标记整理法,因为存活来对象较少,搬运开销不是很大。