前言

RAG(Retrieval-Augmented Generation) 是当前大语言 模型 应用中最重要的技术范式之一。它通过将外部知识库与 LLM 相结合,有效解决了大模型的幻觉问题,并使其能够回答领域特定的问题。
本文将详细介绍如何基于 Milvus/Zilliz Cloud 构建一套完整的企业级 RAG 问答系统,涵盖以下核心模块:
bash
┌─────────────────────────────────────────────────────────────┐
│ RAG Pipeline 架构 │
├─────────────────────────────────────────────────────────────┤
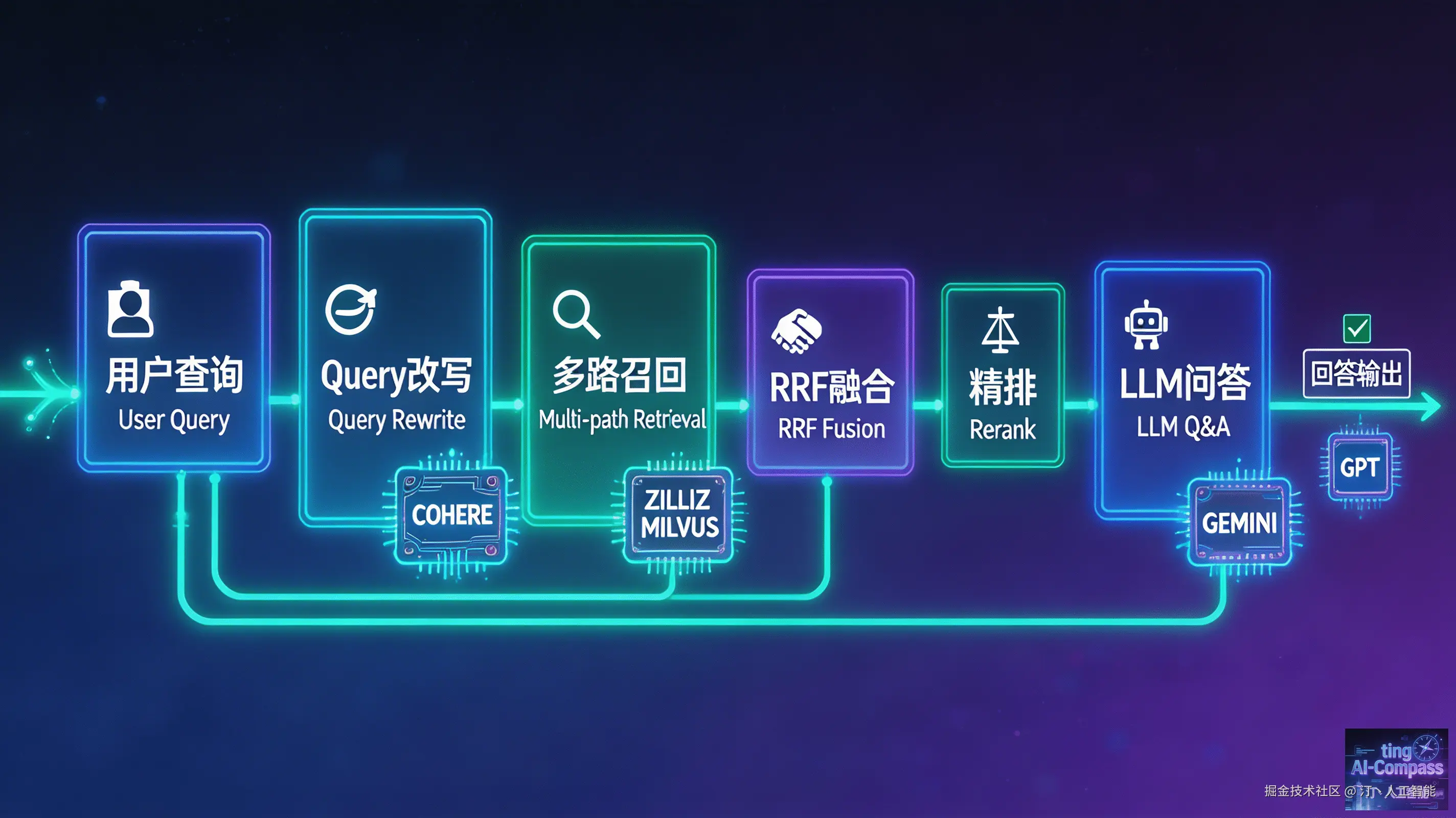
│ 用户查询 → Query改写 → 多路召回 → RRF融合 → 精排 → LLM问答 │
│ (Gemini) (Dense+BM25) (Cohere) (GPT) │
└─────────────────────────────────────────────────────────────┘一、系统架构概览
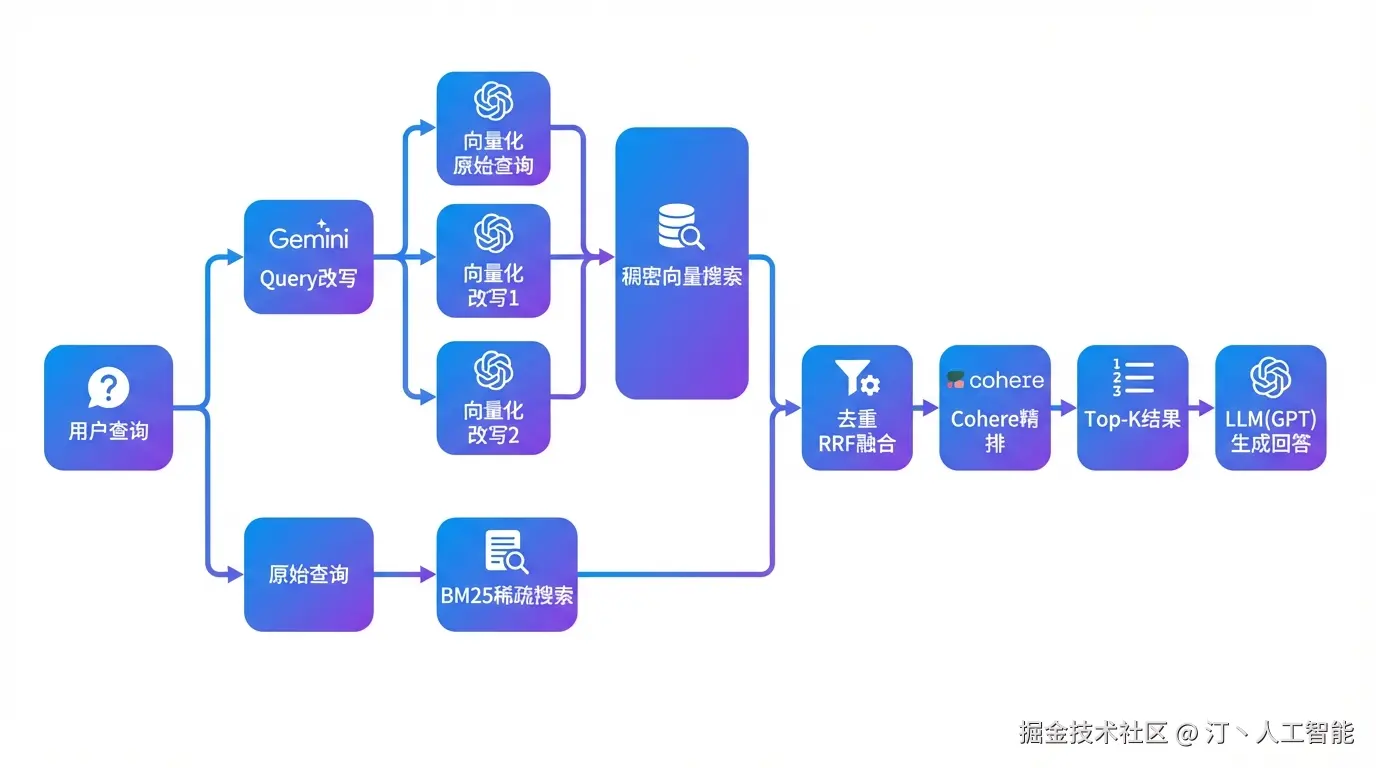
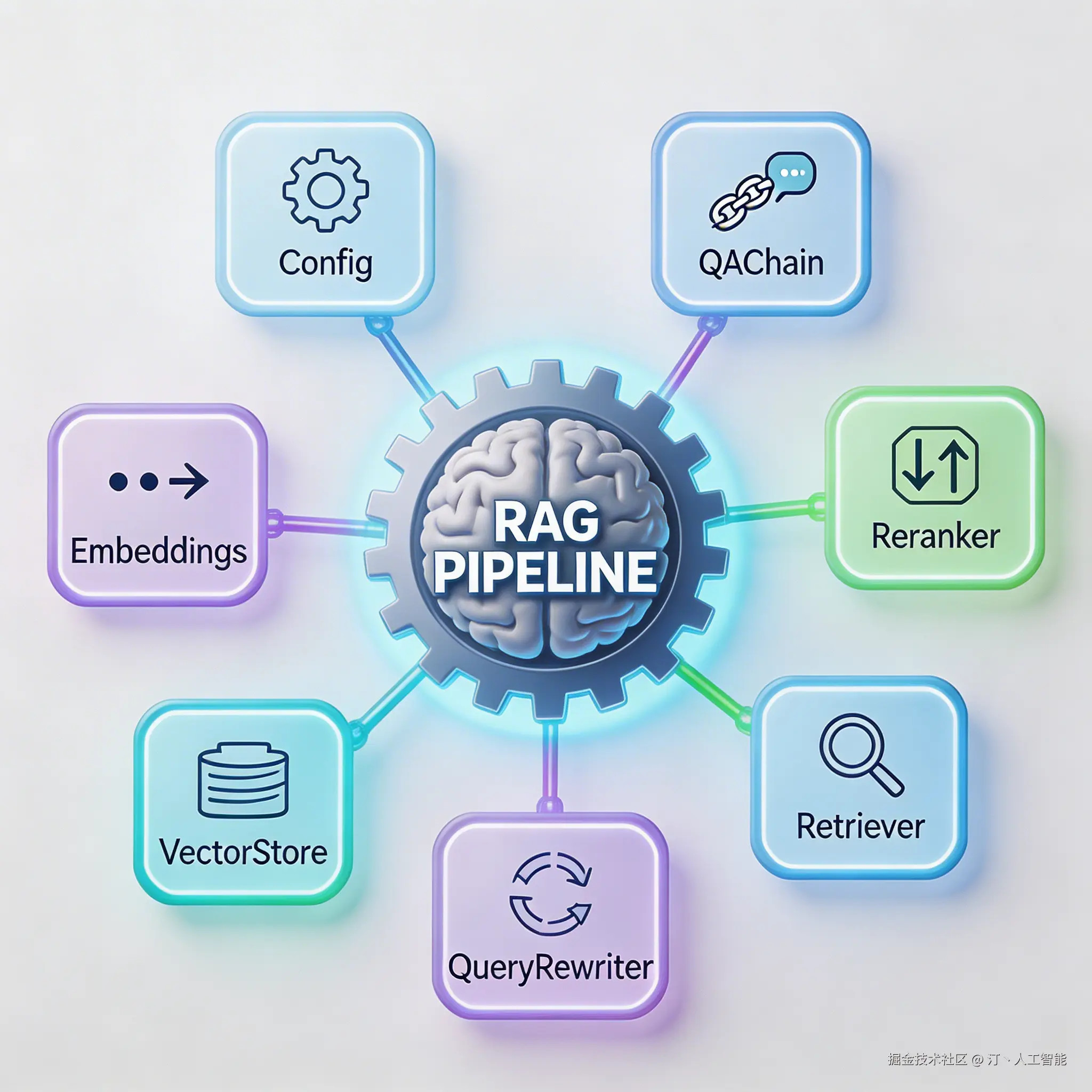
整个系统采用模块化设计,包含 7 个核心组件:
| 模块 | 功能 | 技术选型 |
|---|---|---|
| Config | 配置管理 | 环境变量 + 配置文件 |
| Embeddings | 文本向量化 | OpenAI text-embedding-ada-002 |
| VectorStore | 向量存储与检索 | Milvus/Zilliz Cloud |
| QueryRewriter | 查询改写 | Gemini-2.0-flash |
| Retriever | 混合检索 | Dense + BM25 + RRF |
| Reranker | 精排 | Cohere rerank-multilingual-v3.0 |
| QAChain | 问答生成 | GPT-4/GPT-5 |
二、配置管理模块(Config)
配置模块采用单例模式管理所有 API 密钥和系统参数,支持环境变量覆盖和运行时动态更新。
2.1 核心配置项
bash
# config.py - 核心配置结构
# =============================================================================
# 向量数据库配置
ZILLIZ_ENDPOINT = os.getenv("ZILLIZ_ENDPOINT", "https://xxx.zillizcloud.com")
ZILLIZ_API_KEY = os.getenv("ZILLIZ_API_KEY", "your_api_key")
# Embedding 模型配置
EMBEDDING_MODEL = "text-embedding-ada-002" # OpenAI embedding 模型
EMBEDDING_DIM = 1536 # ada-002 输出维度
# 检索配置
TOP_K_RETRIEVE = 50 # 多路召回后 RRF 融合取 top 50
TOP_K_RERANK = 10 # Cohere 精排后取 top 10
# Collection 配置
COLLECTION_NAME = "ai_knowledge_base"
MAX_TEXT_LENGTH = 65535 # VARCHAR 最大长度2.2 动态配置更新
bash
def update_config(**kwargs) -> None:
"""
动态更新配置项,支持运行时修改
使用示例:
update_config(
zilliz_endpoint="https://new-endpoint.zillizcloud.com",
top_k_retrieve=100
)
"""
config_map = {
"zilliz_endpoint": "ZILLIZ_ENDPOINT",
"top_k_retrieve": "TOP_K_RETRIEVE",
# ... 其他配置映射
}
for key, value in kwargs.items():
if key in config_map:
globals()[config_map[key]] = value设计要点:
- 使用
os.getenv()支持环境变量覆盖,便于容器化部署 - 配置与代码分离,不同环境使用不同配置
- 支持运行时动态更新,无需重启服务
三、文本向量化模块(Embeddings)
Embedding 是 RAG 系统的基石,负责将文本转换为高维向量表示。
3.1 模块设计
bash
class OpenAIEmbeddings:
"""
OpenAI text-embedding-ada-002 封装类
特性:
- 单条/批量文本 embedding
- 自动处理 API 调用和错误
- 支持自定义 base_url(代理服务)
"""
def __init__(
self,
api_key: Optional[str] = None,
base_url: Optional[str] = None,
model: str = "text-embedding-ada-002"
):
self.client = openai.OpenAI(
api_key=api_key or OPENAI_API_KEY,
base_url=base_url or OPENAI_BASE_URL
)
self.model = model3.2 核心方法实现
单条文本 Embedding:
bash
def embed_query(self, text: str) -> List[float]:
"""
为单条查询文本生成 embedding 向量
Returns:
List[float]: 1536 维向量
"""
if not text or not text.strip():
raise ValueError("输入文本不能为空")
response = self.client.embeddings.create(
model=self.model,
input=text.strip()
)
return response.data[0].embedding # 返回 1536 维向量批量文本 Embedding(分批处理):
bash
def embed_documents_batch(
self,
texts: List[str],
batch_size: int = 100
) -> List[List[float]]:
"""
分批处理大量文档的 embedding
避免单次 API 调用超时
"""
all_embeddings = []
for i in range(0, len(texts), batch_size):
batch = texts[i:i + batch_size]
logging.info(f"处理批次: {i + 1}-{min(i + batch_size, len(texts))}")
response = self.client.embeddings.create(
model=self.model,
input=batch
)
batch_embeddings = [item.embedding for item in response.data]
all_embeddings.extend(batch_embeddings)
return all_embeddings关键技术点:
text-embedding-ada-002输出 1536 维向量- 批量处理时建议每批 100 条,避免超时
- 支持 LiteLLM 等代理服务,统一管理多模型调用
四、向量存储模块(VectorStore)
这是整个系统的核心存储层,基于 Milvus/Zilliz Cloud 实现。
4.1 Collection Schema 设计
bash
def create_collection(self, drop_if_exists: bool = False) -> None:
"""
创建支持混合搜索的 Collection
Schema 设计:
- id: INT64 主键(自动生成)
- text: VARCHAR 原文内容
- dense_vector: FLOAT_VECTOR(1536) 稠密向量
- sparse_vector: SPARSE_FLOAT_VECTOR BM25 稀疏向量(自动生成)
"""
schema = self.client.create_schema(auto_id=True)
# 主键字段
schema.add_field(
field_name="id",
datatype=DataType.INT64,
is_primary=True,
auto_id=True
)
# 文本字段 - 启用中文分析器,用于 BM25
schema.add_field(
field_name="text",
datatype=DataType.VARCHAR,
max_length=MAX_TEXT_LENGTH,
enable_analyzer=True,
analyzer_params={"type": "chinese"}, # 中文分词
enable_match=True
)
# 稠密向量字段
schema.add_field(
field_name="dense_vector",
datatype=DataType.FLOAT_VECTOR,
dim=EMBEDDING_DIM # 1536
)
# 稀疏向量字段(BM25 自动生成)
schema.add_field(
field_name="sparse_vector",
datatype=DataType.SPARSE_FLOAT_VECTOR
)4.2 BM25 函数配置
Milvus 2.4+ 支持内置 BM25 函数,自动从文本生成稀疏向量:
bash
# 添加 BM25 函数:自动从 text 生成 sparse_vector
bm25_function = Function(
name="bm25_function",
function_type=FunctionType.BM25,
input_field_names=["text"], # 输入字段
output_field_names=["sparse_vector"] # 输出字段
)
schema.add_function(bm25_function)4.3 索引配置
bash
index_params = self.client.prepare_index_params()
# 稠密向量索引 - IVF_FLAT + COSINE 相似度
index_params.add_index(
field_name="dense_vector",
index_type="IVF_FLAT",
metric_type="COSINE",
params={"nlist": 128} # 聚类数量
)
# 稀疏向量索引 - SPARSE_INVERTED_INDEX + BM25
index_params.add_index(
field_name="sparse_vector",
index_type="SPARSE_INVERTED_INDEX",
metric_type="BM25",
params={"drop_ratio_build": 0.2} # 构建时丢弃低频词比例
)4.4 混合搜索(Hybrid Search)

核心创新点 :同时使用稠密向量(语义)和稀疏向量(关键词)进行检索,通过 RRF(Reciprocal Rank Fusion) 融合结果。
bash
def hybrid_search(
self,
query_vector: List[float],
query_text: str,
top_k: int = 50
) -> List[Dict[str, Any]]:
"""
混合搜索 = 稠密向量搜索 + BM25 稀疏向量搜索 + RRF 融合
"""
# 稠密向量搜索请求
dense_req = AnnSearchRequest(
data=[query_vector],
anns_field="dense_vector",
param={"metric_type": "COSINE", "params": {"nprobe": 10}},
limit=top_k
)
# BM25 稀疏向量搜索请求
sparse_req = AnnSearchRequest(
data=[query_text], # BM25 直接使用原始文本
anns_field="sparse_vector",
param={"metric_type": "BM25", "params": {}},
limit=top_k
)
# 执行混合搜索,使用 RRF 融合排序
results = self.client.hybrid_search(
collection_name=self.collection_name,
reqs=[dense_req, sparse_req],
ranker=RRFRanker(), # Reciprocal Rank Fusion
limit=top_k,
output_fields=["text"]
)
return self._parse_results(results)RRF 融合算法原理:
bash
RRF_score(d) = Σ 1 / (k + rank_i(d))
其中:
- d 为文档
- rank_i(d) 为文档 d 在第 i 路召回中的排名
- k 为常数(通常为 60)五、查询改写模块(QueryRewriter)
Query 改写是提升召回率的关键技术,通过生成语义相似但表达不同的查询变体。
5.1 改写 Prompt 设计
bash
REWRITE_PROMPT = """你是一个查询改写专家。请将用户的查询进行改写和扩展,生成多个语义相似但表达不同的查询变体。
要求:
1. 保持原始查询的核心语义
2. 使用不同的表达方式
3. 可以添加相关的同义词或近义词
4. 生成 2-3 个改写变体
用户查询: {query}
请以 JSON 格式返回,格式如下:
{{"queries": ["原始查询", "改写1", "改写2"]}}
只返回 JSON,不要有其他内容。"""5.2 改写实现
bash
class QueryRewriter:
def __init__(self, api_key: str, model: str = "gemini-2.0-flash"):
genai.configure(api_key=api_key)
self.model = genai.GenerativeModel(
model_name=model,
generation_config={
"temperature": 0.3, # 低温度保证稳定性
"top_p": 0.8,
"max_output_tokens": 500,
}
)
def rewrite(self, query: str, include_original: bool = True) -> List[str]:
"""
改写查询,生成多个查询变体
示例:
输入: "什么是机器学习?"
输出: [
"什么是机器学习?", # 原始查询
"机器学习的定义是什么", # 改写1
"如何理解机器学习这个概念" # 改写2
]
"""
prompt = REWRITE_PROMPT.format(query=query)
response = self.model.generate_content(prompt)
# 解析 JSON 响应
result = json.loads(response.text.strip())
queries = result.get("queries", [])
# 确保原始查询在第一位
if include_original and query not in queries:
queries.insert(0, query)
return queries设计要点:
- 使用 Gemini-2.0-flash,速度快、成本低
- 低温度 (0.3) 保证输出稳定性
- 原始查询始终保留,确保不丢失关键信息
六、混合检索模块(HybridRetriever)
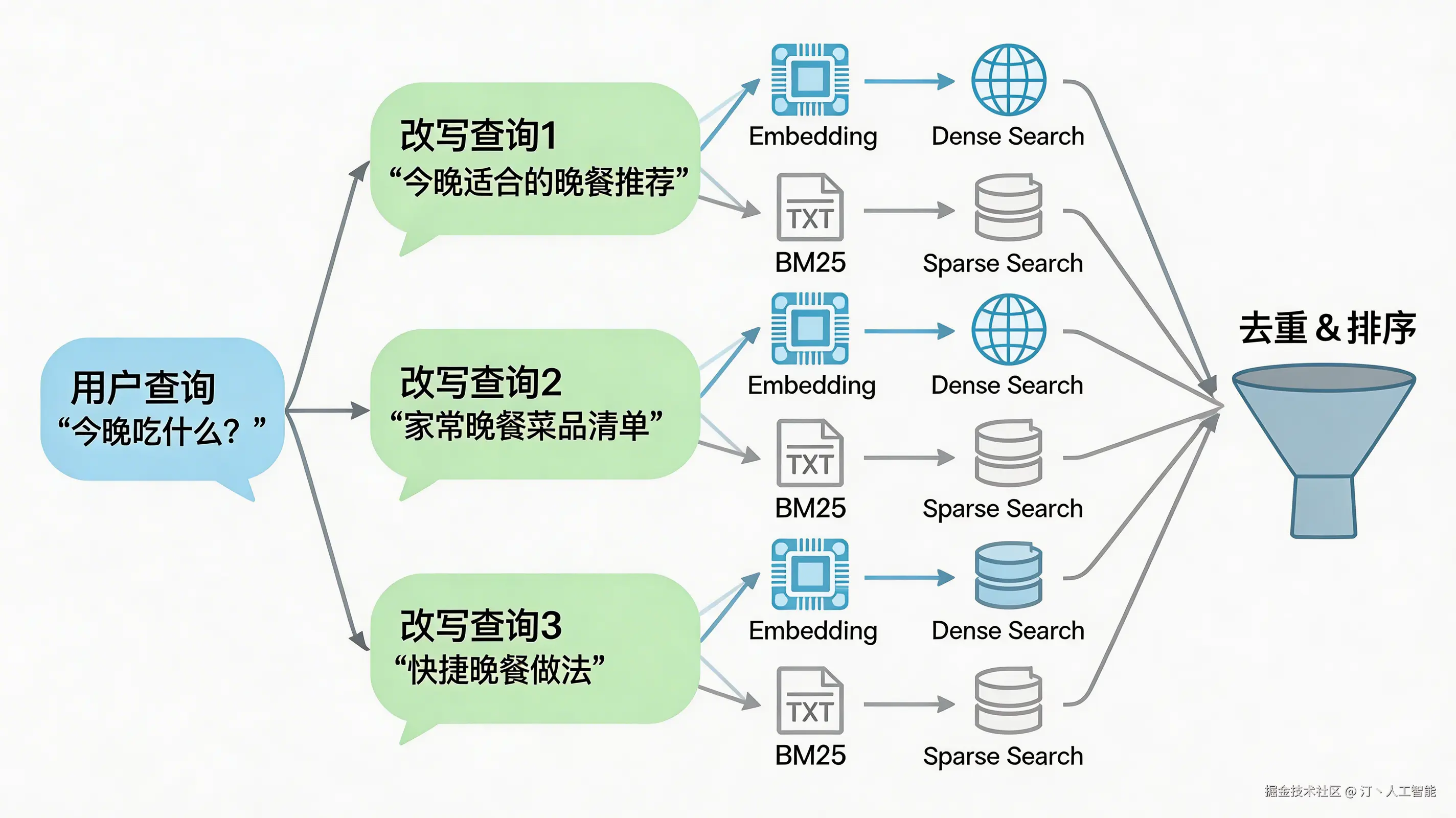
整合 Embedding、VectorStore、QueryRewriter,实现完整的检索流程。
6.1 检索流程
bash
用户查询 ──┬── Query改写 ──┬── 原始查询 ──┬── Embedding ── Dense搜索 ──┐
│ │ │ │
│ ├── 改写1 ────┼── Embedding ── Dense搜索 ──┼── 去重 ── 按分数排序 ── Top-K
│ │ │ │
│ └── 改写2 ────┴── Embedding ── Dense搜索 ──┤
│ │
└── 原始查询 ────────────────────────────── BM25搜索 ────┘6.2 核心实现
bash
class HybridRetriever:
def retrieve(
self,
query: str,
top_k: int = 50,
use_rewrite: bool = False
) -> List[Dict[str, Any]]:
"""
执行混合检索
流程:
1. (可选) Query 改写
2. 生成 query embedding
3. 执行混合搜索(向量 + BM25)
4. RRF 融合 + 去重排序
"""
# 1. Query 改写(可选)
queries_to_search = [query]
if use_rewrite and self.query_rewriter:
queries_to_search = self.query_rewriter.rewrite(query)
# 2. 收集所有检索结果(去重)
all_results = {} # key: doc_id, value: result
for q in queries_to_search:
# 生成 query embedding
query_vector = self.embeddings.embed_query(q)
# 执行混合搜索(Dense + BM25 + RRF)
results = self.vector_store.hybrid_search(
query_vector=query_vector,
query_text=q,
top_k=top_k
)
# 合并结果(保留最高分数)
for r in results:
doc_id = r["id"]
if doc_id not in all_results:
all_results[doc_id] = r
elif r["distance"] > all_results[doc_id]["distance"]:
all_results[doc_id] = r
# 3. 按分数排序,取 top_k
sorted_results = sorted(
all_results.values(),
key=lambda x: x["distance"],
reverse=True
)[:top_k]
return sorted_results七、精排模块(Reranker)
召回阶段追求高召回率,但结果相关性参差不齐。精排模块使用 Cohere rerank 对结果进行二次排序。
7.1 为什么需要精排?
| 阶段 | 目标 | 特点 |
|---|---|---|
| 召回(Retrieval) | 高召回率 | 快速、粗粒度 |
| 精排(Rerank) | 高精确率 | 慢速、细粒度 |
7.2 Cohere Rerank 实现
bash
class CohereReranker:
def __init__(self, api_key: str, model: str = "rerank-multilingual-v3.0"):
self.client = cohere.Client(api_key=api_key)
self.model = model
def rerank_with_ids(
self,
query: str,
documents: List[Dict[str, Any]],
top_k: int = 10
) -> List[Dict[str, Any]]:
"""
对带有 ID 的文档进行精排
Args:
documents: [{"id": 1, "text": "..."}, {"id": 2, "text": "..."}]
Returns:
精排后的文档列表,按相关性分数降序排列
"""
# 提取文本列表
texts = [doc.get("text", "") for doc in documents]
# 调用 Cohere rerank API
response = self.client.rerank(
query=query,
documents=texts,
model=self.model,
top_n=min(top_k, len(documents)),
return_documents=False
)
# 合并结果,保留原始 ID
final_results = []
for item in response.results:
original_doc = documents[item.index]
final_results.append({
"id": original_doc.get("id"),
"text": original_doc.get("text", ""),
"relevance_score": item.relevance_score
})
return final_results模型选择:
rerank-multilingual-v3.0:多语言支持,适合中英文混合场景- 单次最多处理 1000 条文档
八、问答生成模块(QAChain)
最终环节:将检索到的上下文与用户问题一起输入 LLM ,生成回答。
8.1 Prompt 设计
bash
QA_PROMPT_TEMPLATE = """你是一个专业的 AI 问答助手。请根据以下提供的参考资料回答用户的问题。
要求:
1. 基于参考资料回答,不要编造信息
2. 如果参考资料无法回答问题,请明确说明
3. 回答要简洁清晰,重点突出
4. 可以适当整合多个参考资料的信息
参考资料:
{contexts}
用户问题:{question}
请回答:"""8.2 上下文格式化
bash
def _format_contexts(self, contexts: List[str], max_length: int = 8000) -> str:
"""
格式化上下文列表,避免超出 token 限制
输出示例:
[1] 机器学习是人工智能的一个分支...
[2] 深度学习使用多层神经网络...
"""
formatted = []
total_length = 0
for i, ctx in enumerate(contexts, 1):
ctx_text = f"[{i}] {ctx.strip()}"
# 检查长度限制
if total_length + len(ctx_text) > max_length:
logging.warning(f"上下文超出长度限制,截断到 {i-1} 条")
break
formatted.append(ctx_text)
total_length += len(ctx_text)
return "\n\n".join(formatted)8.3 流式回答支持
bash
def stream_answer(
self,
question: str,
contexts: List[str],
max_tokens: int = 1024
):
"""
流式回答问题,提供更好的用户体验
"""
prompt = QA_PROMPT_TEMPLATE.format(
contexts=self._format_contexts(contexts),
question=question
)
response = self.client.chat.completions.create(
model=self.model,
messages=[
{"role": "system", "content": "你是一个专业的 AI 问答助手。"},
{"role": "user", "content": prompt}
],
max_tokens=max_tokens,
stream=True # 启用流式输出
)
for chunk in response:
if chunk.choices[0].delta.content:
yield chunk.choices[0].delta.content九、完整 Pipeline 整合
9.1 RAGPipeline 类
bash
class RAGPipeline:
"""完整的 RAG 问答系统,整合所有组件"""
def __init__(self, config: Optional[Dict[str, Any]] = None):
if config:
update_config(**config)
self.config = get_config()
self._init_components()
def _init_components(self):
"""初始化所有组件"""
# 1. Embedding
self.embeddings = OpenAIEmbeddings(...)
# 2. 向量库
self.vector_store = MilvusVectorStore(...)
# 3. Query 改写器(可选)
self.query_rewriter = QueryRewriter(...) if gemini_api_key else None
# 4. 混合检索器
self.retriever = HybridRetriever(...)
# 5. 精排器
self.reranker = CohereReranker(...)
# 6. 问答链
self.qa_chain = QAChain(...)9.2 构建索引
bash
def build_index(
self,
documents: List[Dict[str, str]],
drop_if_exists: bool = False
) -> Dict[str, Any]:
"""
构建向量索引
流程:
1. 创建 Collection
2. 批量生成 embeddings
3. 插入数据(BM25 稀疏向量自动生成)
"""
# 1. 创建 Collection
self.vector_store.create_collection(drop_if_exists=drop_if_exists)
# 2. 批量生成 embeddings
texts = [doc["text"] for doc in documents]
embeddings = self.embeddings.embed_documents_batch(texts)
# 3. 准备插入数据
insert_data = [
{"text": doc["text"], "dense_vector": embeddings[i]}
for i, doc in enumerate(documents)
]
# 4. 插入(sparse_vector 由 BM25 函数自动生成)
ids = self.vector_store.insert_documents(insert_data)
return {"success": True, "count": len(ids)}9.3 完整问答流程
bash
def query(
self,
question: str,
top_k_retrieve: int = 50,
top_k_rerank: int = 10,
use_rewrite: bool = True
) -> Dict[str, Any]:
"""
执行完整的 RAG 问答流程
流程:
1. Query 改写(可选)
2. 多路召回(Dense + BM25)
3. RRF 融合取 top_k_retrieve
4. Cohere 精排取 top_k_rerank
5. LLM 生成回答
"""
# 1. 混合检索
retrieval_results = self.retriever.retrieve(
query=question,
top_k=top_k_retrieve,
use_rewrite=use_rewrite
)
if not retrieval_results:
return {"answer": "抱歉,没有找到与您问题相关的信息。", ...}
# 2. Cohere 精排
rerank_results = self.reranker.rerank_with_ids(
query=question,
documents=retrieval_results,
top_k=top_k_rerank
)
# 3. 提取上下文
contexts = [r["text"] for r in rerank_results]
# 4. LLM 生成回答
answer = self.qa_chain.answer(
question=question,
contexts=contexts
)
return {
"answer": answer,
"question": question,
"contexts": contexts,
"retrieval_count": len(retrieval_results),
"rerank_count": len(rerank_results),
"rerank_scores": [r["relevance_score"] for r in rerank_results]
}十、使用示例
10.1 快速开始
bash
from mind.internal_tools.general.milvus import RAGPipeline
# 初始化 Pipeline
pipeline = RAGPipeline(config={
"zilliz_endpoint": "https://xxx.zillizcloud.com",
"zilliz_api_key": "your_api_key",
"gemini_api_key": "your_gemini_key", # 可选,用于 Query 改写
"cohere_api_key": "your_cohere_key",
})
# 构建索引
documents = [
{"text": "机器学习是人工智能的一个分支,它使计算机能够从数据中学习。"},
{"text": "深度学习是机器学习的子集,使用多层神经网络进行特征学习。"},
{"text": "RAG 是检索增强生成的缩写,结合了检索和生成两种技术。"},
]
pipeline.build_index(documents, drop_if_exists=True)
# 问答
result = pipeline.query("什么是深度学习?")
print(result["answer"])10.2 获取详细中间结果
bash
# 使用 query_with_details 获取完整的处理过程
result = pipeline.query_with_details(
question="RAG 技术有什么优势?",
use_rewrite=True
)
print("改写后的查询:", result["rewritten_queries"])
print("召回结果数:", len(result["retrieval_results"]))
print("精排结果数:", len(result["rerank_results"]))
print("最终回答:", result["answer"])十一、测试脚本与依赖关系
11.1 test.py 的问答流程依赖
test.py 的问答功能依赖 rag_pipeline.py ,而 rag_pipeline.py 作为编排层整合了 milvus 目录下的各个子模块。
11.2 依赖链结构
bash
test.py
└── RAGPipeline (rag_pipeline.py)
├── embeddings.py - OpenAIEmbeddings (向量化)
├── vector_store.py - MilvusVectorStore (向量库)
├── query_rewriter.py - QueryRewriter (Query改写,可选)
├── retriever.py - HybridRetriever (混合检索)
├── reranker.py - CohereReranker (精排)
└── qa_chain.py - QAChain (LLM问答)11.3 问答流程(rag_pipeline.py 的 query() 方法)
- Query 改写 (可选)-
query_rewriter.py - 混合检索 (向量 + BM25)-
retriever.py→ 内部调用vector_store.py+embeddings.py - RRF 融合
- Cohere 精排 -
reranker.py - LLM 生成回答 -
qa_chain.py
11.4 test.py 中的测试函数调用方式
| 测试函数 | 调用方式 | 说明 |
|---|---|---|
test_build_index() |
pipeline.build_index() |
完整流程 |
test_retrieval() |
pipeline.retriever.retrieve() |
直接访问子模块 |
test_rerank() |
pipeline.reranker.rerank() |
直接访问子模块 |
test_query() |
pipeline.query() |
完整问答流程 |
test_full_pipeline() |
pipeline.query_with_details() |
完整流程+中间结果 |
11.5 使用方式
bash
# 测试全部功能
python test.py
# 只测试索引构建
python test.py --test build
# 只测试召回
python test.py --test retrieval
# 只测试精排
python test.py --test rerank
# 只测试问答
python test.py --test query
# 指定配置
python test.py --zilliz-endpoint "https://xxx" --zilliz-key "xxx"11.6 测试结果
测试时间: 2026-01-06
11.6.1 索引构建测试 (build)
bash
============================================================
测试索引构建
============================================================
文档数量: 50
✅ 索引构建成功,插入 50 条文档
测试结果: ✅ 通过
关键日志:
- Collection 创建成功:
ai_knowledge_base - Embedding 批处理: 1-50/50
- 插入 50 条文档
11.6.2 检索测试 (retrieval)
bash
============================================================
测试检索功能
============================================================
问题: 什么是神经网络?它由哪些部分组成?
✅ 检索到 5 条结果
[1] 分数: 0.0328 | 内容: 神经网络是一种模仿人脑神经元结构的计算模型。它由多个层组成...
[2] 分数: 0.0320 | 内容: Transformer是一种基于自注意力机制的神经网络架构...
[3] 分数: 0.0312 | 内容: 深度学习是机器学习的一个子领域,使用多层神经网络...
问题: 机器学习有哪些主要类型?
✅ 检索到 5 条结果
[1] 分数: 0.0323 | 内容: 监督学习是机器学习中最常见的类型...
[2] 分数: 0.0164 | 内容: 机器学习是人工智能的一个分支...
[3] 分数: 0.0164 | 内容: 无监督学习处理没有标签的数据...
问题: 深度学习和传统机器学习有什么区别?
✅ 检索到 5 条结果
[1] 分数: 0.0328 | 内容: 深度学习是机器学习的一个子领域...
[2] 分数: 0.0318 | 内容: 机器学习是人工智能的一个分支...
[3] 分数: 0.0315 | 内容: 特征工程是从原始数据中创建、选择和转换特征...
测试结果: ✅ 通过分析: 混合检索(Dense + BM25 + RRF 融合)能够有效返回语义相关的文档。
11.6.3 精排测试 (rerank)
bash
============================================================
测试精排功能
============================================================
问题: 什么是深度学习?
待排序文档数: 10
✅ 精排成功,返回 3 条结果
[1] 分数: 0.9999 | 内容: 深度学习是机器学习的一个子领域,使用多层神经网络...
[2] 分数: 0.3996 | 内容: 过拟合是机器学习中的一个常见问题...
[3] 分数: 0.2843 | 内容: 神经网络是一种模仿人脑神经元结构的计算模型...
测试结果: ✅ 通过分析: Cohere rerank 模型能够精准识别最相关文档,第一条结果相关性分数高达 0.9999。
11.6.4 问答测试 (query)
bash
============================================================
测试完整问答流程
============================================================
问题: 什么是 RAG?它有什么作用?
----------------------------------------
✅ 问答成功
召回数: 50
精排后: 10
回答: RAG(检索增强生成,Retrieval-Augmented Generation)是一种结合**信息检索**和
**文本生成**的技术,用于增强大语言模型(LLM)的能力。
其基本工作流程包括:
1. 将用户查询转换为向量;
2. 从知识库中检索相关文档;
3. 将检索到的文档作为上下文输入给LLM;
4. LLM基于这些上下文生成回答。
问题: 如何解决模型过拟合问题?
----------------------------------------
✅ 问答成功
召回数: 50
精排后: 10
回答: 过拟合是指模型在训练数据上表现很好,但在新数据上效果很差。常见的解决方法包括:
1. **增加训练数据**:通过收集更多样本或使用**数据增强**
2. **使用正则化**:如 **L1/L2 正则化**
3. **使用 Dropout**:在训练过程中随机丢弃部分神经元
问题: Transformer 架构的核心是什么?
----------------------------------------
✅ 问答成功
召回数: 50
精排后: 10
回答: Transformer 架构的核心是**自注意力机制(Self-Attention)**。
它使模型在处理序列时能够同时关注序列中所有位置的信息,而不受距离限制,
从而高效捕捉全局依赖关系。
测试结果: ✅ 通过11.6.5 测试汇总
| 测试项 | 状态 | 说明 |
|---|---|---|
| 索引构建 (build) | ✅ 通过 | 成功插入 50 条文档 |
| 检索 (retrieval) | ✅ 通过 | 混合检索返回相关结果 |
| 精排 (rerank) | ✅ 通过 | Cohere 精排效果显著 |
| 问答 (query) | ✅ 通过 | 完整 RAG 流程正常 |
总体结果: ✅ 全部通过
11.7 总结
问答功能主要依赖 RAGPipeline ,它作为一个编排层 把各个子模块串联起来。但 test.py 中部分测试(如 test_retrieval、test_rerank)会直接访问 pipeline 暴露的子组件属性(pipeline.retriever、pipeline.reranker),用于单独测试各个环节。
完整代码和持续更新我整理在 GitHub :github.com/tingaicompa... ,这类工程化长文,我会继续更新在公众号「汀丶人工智能」。如果你想看更细的项目复盘、模板和答疑,可以再看看知识星球「 AI -Compass」。