Cao Thien Tan 1,2,3^{1,2,3}1,2,3 Trang Phan Thi Thu 3,5^{3,5}3,5 Duc Nghiem Do 6^{6}6 Ho Ngoc Anh 5^{5}5
Hanyang Zhuang 4,∗^{4,*}4,∗ Duc Dung Nguyen 2,∗^{2,*}2,∗
1^{1}1Ho Chi Minh City Open University(胡志明市开放大学)
2^{2}2AI Tech Lab, Ho Chi Minh City University of Technology(胡志明市理工大学 AI 技术实验室)
3^{3}3Code Mely AI Research Team
4^{4}4Global College, Shanghai Jiao Tong University(上海交通大学全球学院)
5^{5}5Ha Noi University of Science and Technology(河内科技大学)
6^{6}6University of Manitoba(曼尼托巴大学)
caothientan2001@gmail.com, zhuanghany11@sjtu.edu.cn, nddung@hcmut.edu.vn
代码:https://github.com/hokiyoshi/UCAN
摘要
混合 CNN-Transformer 架构在图像超分辨率方面取得了强大的结果,但缩放注意力窗口或卷积核会显著增加计算成本,限制了其在资源受限设备上的部署。我们提出了 UCAN,这是一种轻量级网络,它统一了卷积和注意力以有效地扩展有效感受野。UCAN 结合了基于窗口的空间注意力与 Hedgehog 注意力机制,以建模局部纹理和长程依赖关系,并引入了基于蒸馏的大核模块,以在不增加 heavy 计算的情况下保留高频结构。此外,我们采用跨层参数共享来进一步降低复杂度。在 Manga109 (4×4\times4×) 上,UCAN-L 仅以 48.448.448.4G MACs 实现了 31.6331.6331.63 dB PSNR,超越了最近的轻量级模型。在 BSDS100 上,UCAN 达到了 27.7927.7927.79 dB,优于模型显著更大的方法。大量实验表明,UCAN 在准确性、效率和可扩展性之间取得了卓越的平衡,使其非常适合实际的高分辨率图像恢复。
1. 引言
单图像超分辨率 (SR) 旨在从退化的低分辨率 (LR) 输入重建高分辨率 (HR) 图像,代表了底层视觉中一个长期存在但不断演变的挑战。由于其广泛的实际应用以及对 SR 解决方案准确性和效率日益增长的需求,该任务在计算机视觉社区中获得了持续的关注。最近的进展见证了轻量级 SR 模型的出现,越来越强调通过扩展有效感受野来增强性能。虽然基于 Transformer 的架构在这方面展示了强大的能力,但最近的研究调查了通过新架构或技术扩展感受野的替代策略,这些策略具有更低的计算复杂度和更少的参数。
轻量级超分辨率的最新进展主要集中在扩大有效感受野以捕捉更广泛的上下文信息并恢复高频细节。虽然这种扩展至关重要,但现有方法仍然有限。基于卷积的架构有效地建模了局部依赖关系,但许多引入全局注意力的努力,如 Grid Attention 33、Mamba 8, 29 和 Adaptive Token Dictionary 38,仍然难以高效地捕捉全局上下文。线性注意力 1 提供了一个有希望的替代方案,但其潜力受到有限特征多样性的约束,这削弱了表示能力。此外,效率与性能之间的权衡仍然存在;虽然最近的模型实现了更少的参数计数,但它们往往牺牲了表示丰富性。联合注意力机制和蒸馏策略 26 进一步同质化了层和通道间的特征图,减少了特征多样性,最终阻碍了重建质量。
我们引入了统一卷积注意力网络 (UCAN),这是一种轻量级超分辨率架构,它在扩展有效感受野的同时保留了丰富的特征表示。高性能模块 (High Performance Block) 结合了 Flash Attention 以避免计算完整的注意力矩阵,允许高效的 32×3232 \times 3232×32 窗口,并实现比传统注意力显著更低的延迟。为了捕捉精细的局部结构、长程依赖关系和通道关系,我们设计了一种混合注意力机制,其中窗口注意力有效地建模局部模式,而双重融合层 (Dual Fusion Layer) 是 Hedgehog 注意力的优化实现,解决了线性注意力和通道注意力中通常观察到的秩缺陷问题。此外,采用参数共享来降低计算成本,同时保持强大的性能。大核蒸馏模块进一步增强了网络以最小的参数开销复现复杂纹理和层次结构的能力。在标准基准测试中,UCAN 提供了更高的视觉保真度,同时保持了延迟和计算效率之间的有利平衡。
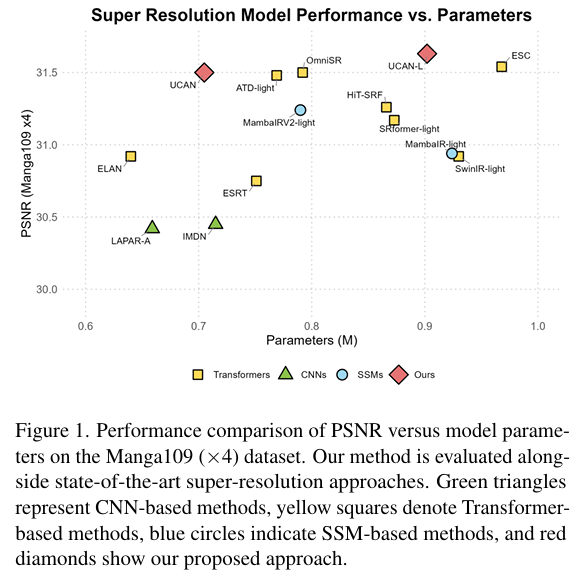
基于上述组件,UCAN 展示了轻量级设计和表达能力之间的强烈平衡。如图 1 所示,UCAN 实现了具有竞争力的性能,在参数计数和重建准确性之间取得了有利的权衡。在 2×2\times2× 放大的标准基准测试中,UCAN 在 Urban100 上超越 OmniSR 模型 0.120.120.12 dB,在 Set5 上超越 0.170.170.17 dB,同时使用了少 11%11\%11% 的参数和少 24%24\%24% 的 FLOPs。对于 Manga109 上的 4×4\times4× 放大,较大变体 UCAN-L 比 MambaIRV2 高出 0.390.390.39 dB,实现了高达 36%36\%36% 的更低计算成本。这些一致的改进突出了我们统一的卷积注意力框架在实现高保真图像重建方面的有效性和效率。
总之,我们的贡献如下:
- 我们引入了 Hedgehog 注意力,这是一种新颖的注意力机制,通过增强特征的秩来增强线性注意力中的特征多样性。该设计允许模型捕捉更丰富和更具表达力的特征。
- 我们提出了 UCAN,这是一个统一且高效的模型,捕捉多个感受野上的局部和全局依赖关系。UCAN 采用 Flash Attention 进行大窗口注意力以提高计算效率,采用 Hedgehog 注意力在有限资源下以强鲁棒性建模全局信息,并采用多核卷积提取必要的局部特征。
- 我们设计了一种 半共享和蒸馏架构,平衡了参数共享与任务特定的专业化。实验结果表明,该架构允许 UCAN 在显著减少参数数量和计算成本的同时实现强大的性能。
2. 相关工作
卷积方法。 早期的基于深度学习的 SR 方法 4, 5 采用堆叠卷积进行局部特征提取,但遭受过度参数化的困扰。权重共享策略 13, 14, 32 降低了复杂度,但输入独立的共享往往降低了性能。后来的架构提高了 CNN 表达能力:EDSR 20 使用深度残差块,RDN 43 使用密集特征重用,RCAN 42 使用通道注意力。尽管取得了这些进展,卷积仍然局限于局部感受野,这促使探索建模长程依赖关系的架构。
注意力方法对比分析。 视觉 Transformer 最近在图像超分辨率领域获得了关注,继其在通用计算机视觉任务 6, 27 取得成功之后。代表性方法包括 SwinIR 22,它调整了 shifted-window 策略用于图像恢复;ESRT 23,它将轻量级 CNN 与 Transformer 块结合以提高效率;以及 ELAN 40,它通过共享自注意力和统一查询 - 键参数 36 降低成本。
尽管取得了这些进展,当代 Transformer 架构仍然遭受有效感受野有限的困扰,限制了全局上下文建模和计算效率。为了解决这个问题,Omni-SR 33 引入了网格注意力以扩大空间观察,而 MambaIRv2 8 将 Swin Transformer 与状态空间模型结合以增强全图像信息捕捉。基于这些想法,我们的方法集成了 Swin Transformer 与改进的线性 Transformer,通过扩展感受野同时保持效率来实现 superior 性能。
大感受野注意力机制。 Transformer 的计算成本驱动了研究基于 CNN 的替代方案,这些方案使用大核和像素级注意力来近似 Transformer 性能 30, 34, 35。然而,这些方法往往无法捕捉自注意力丰富的表示,或者因多方向扫描等复杂架构而产生内存开销。最近的工作通过 CUDA 优化 16、不对称卷积 31、空洞卷积 16 和蒸馏技术 17 解决了 CNN 核扩展问题。基于这些进展,我们提出了大核蒸馏 (Large Kernel Distillation),它将空洞卷积与知识蒸馏相结合,以实现大感受野同时保持计算效率。
3. proposed 方法
在本节中,我们首先分析线性 Transformer 和 Softmax 注意力,然后详细描述所提出的网络。
3.1. 桥接 Softmax 和线性注意力
连接分析。 令 X∈RHW×CX \in \mathbb{R}^{HW \times C}X∈RHW×C 且 Q=XWQQ= XW_QQ=XWQ, K=XWKK= XW_KK=XWK, V=XWVV= XW_VV=XWV,其中 WQ,WK,WV∈RC×dW_Q, W_K, W_V \in \mathbb{R}^{C \times d}WQ,WK,WV∈RC×d。用 qi,ki,vi∈Rdq_i, k_i, v_i \in \mathbb{R}^dqi,ki,vi∈Rd 表示行。
标准 softmax 注意力描述为:
si=exp(qi⊤k1)∑j=1Nexp(qi⊤kj),...,exp(qi⊤kHW)∑j=1Nexp(qi⊤kj)⊤,oiS=si⊤V.(1) s_i=\left\\frac{\\exp(q_i\^\\top k_1)}{\\sum_{j=1}\^N \\exp(q_i\^\\top k_j)}, \\dots, \\frac{\\exp(q_i\^\\top k_{HW})}{\\sum_{j=1}\^N \\exp(q_i\^\\top k_j)}\\right^\top, \quad o_i^S = s_i^\top V. \quad (1) si=∑j=1Nexp(qi⊤kj)exp(qi⊤k1),...,∑j=1Nexp(qi⊤kj)exp(qi⊤kHW)⊤,oiS=si⊤V.(1)
然而,线性注意力用 ϕ(qi)⊤ϕ(kj)\phi(q_i)^\top \phi(k_j)ϕ(qi)⊤ϕ(kj) 替换 exp(qi⊤kj)\exp(q_i^\top k_j)exp(qi⊤kj),其中特征图 ϕ∈Rd→Rr\phi \in \mathbb{R}^{d \to \mathbb{R}^r}ϕ∈Rd→Rr:
oiL=∑j=1N(ϕ(qi)⊤ϕ(kj))vj∑j=1Nϕ(qi)⊤ϕ(kj)=ϕ(qi)⊤(∑j=1Nϕ(kj)vj⊤)ϕ(qi)⊤(∑j=1Nϕ(kj)).(2) o_i^L = \frac{\sum_{j=1}^N (\phi(q_i)^\top \phi(k_j)) v_j}{\sum_{j=1}^N \phi(q_i)^\top \phi(k_j)} = \frac{\phi(q_i)^\top (\sum_{j=1}^N \phi(k_j) v_j^\top)}{\phi(q_i)^\top (\sum_{j=1}^N \phi(k_j))}. \quad (2) oiL=∑j=1Nϕ(qi)⊤ϕ(kj)∑j=1N(ϕ(qi)⊤ϕ(kj))vj=ϕ(qi)⊤(∑j=1Nϕ(kj))ϕ(qi)⊤(∑j=1Nϕ(kj)vj⊤).(2)
两个聚合项 ∑jϕ(kj)vj⊤\sum_j \phi(k_j) v_j^\top∑jϕ(kj)vj⊤ 和 ∑jϕ(kj)\sum_j \phi(k_j)∑jϕ(kj) 可在 O(N)O(N)O(N) 中计算并用于所有查询,将每层复杂度从 O(N2)O(N^2)O(N2) 降低到 O(N)O(N)O(N)。
打破线性注意力中的低秩瓶颈。 先前的工作通过添加深度卷积或辅助高秩乘数来恢复输出矩阵的秩,但这并没有消除线性注意力固有的低秩趋势。秩崩溃迫使模型依赖少数依赖方向并减少表示多样性。
在线性时间内近似 softmax 需要一个特征图 ϕ\phiϕ 来复现 softmax 选择性。简单的选择如 ReLU 或 ELU+1 失败了,因为 ReLU 丢弃了负贡献,这些贡献可以在 softmax 下组合形成重要的正注意力,而 ELU+1 产生极端的相对变化,鼓励秩崩溃。详细分析见补充材料。
我们使用 Hedgehog 特征图 (HFM) 39。HFM 连接 mmm 个对称指数特征对:
ϕH(X)=exp(W⊤X+b1),...,exp(W⊤X+bm),exp(−W⊤X−b1),...,exp(−W⊤X−bm),(3) \phi_H(X)=\\exp(W\^\\top X+ b_1), \\dots, \\exp(W\^\\top X+ b_m), \\exp(-W\^\\top X - b_1), \\dots, \\exp(-W\^\\top X - b_m), \quad (3) ϕH(X)=exp(W⊤X+b1),...,exp(W⊤X+bm),exp(−W⊤X−b1),...,exp(−W⊤X−bm),(3)
其中 W∈RC×CW \in \mathbb{R}^{C \times C}W∈RC×C 是共享投影,{bi}i=1m\{b_i\}_{i=1}^m{bi}i=1m 是可学习偏置。
HFM 呈现出源于其核心设计的独特优势。其简单、可训练的 MLP 风格构造比 rigid、手工设计的特征图提供了更大的灵活性。通过促进低熵、尖峰状的注意力分布,HFM 还保持了细粒度、内容依赖的查找,同时增加了多样性。此外,其对称配对机制保留了来自正负预投影方向的信息,从而减轻了通常由整流引起的信息丢失。因此,HFM 能够直接抑制秩崩溃,消除了对外部秩恢复模块的需求。我们在图 2 中的实验结果表明,应用 HFM 的线性注意力模型恢复了高达 464646 的秩,超过了其他比较方法。

3.2. 整体架构
我们通过分层设计来解决感受野大小和效率之间的经典权衡,该设计遵循先前的工作 8, 17, 26, 38。首先,我们构建一个高效的注意力骨干网,以低成本产生大感受野。在此骨干网上,我们堆叠混合块,集成局部细节和全局上下文,最后我们将空间知识从大核块蒸馏到网络中,以便模型更好地保留精细结构和复杂细节。
低分辨率输入图像 ILR∈RH×W×3I_{LR} \in \mathbb{R}^{H \times W \times 3}ILR∈RH×W×3 首先通过 3×33 \times 33×3 卷积映射到浅层特征嵌入 F0F_0F0。这些浅层特征由核心编码器处理,该编码器由广域有效感受野组 (Broad Effective Receptive Field Group, BERFG) 单元组成,表示为 fBERFGf_{BERFG}fBERFG,以产生深层特征 FdfF_{df}Fdf。为了保留低频内容,我们将 FdfF_{df}Fdf 与 F0F_0F0 融合以获得 FfuseF_{fuse}Ffuse。融合特征然后通过重建模块(3×33 \times 33×3 卷积后跟像素洗牌 28)以产生最终的高分辨率图像 IHRI_{HR}IHR。核心编码器依赖于广域有效感受野组。该组顺序集成了用于局部上下文的高性能注意力、用于高效全局聚合的共享和接收混合注意力,以及用于空间细化的大核蒸馏。我们在以下子节中详细说明这些子模块。
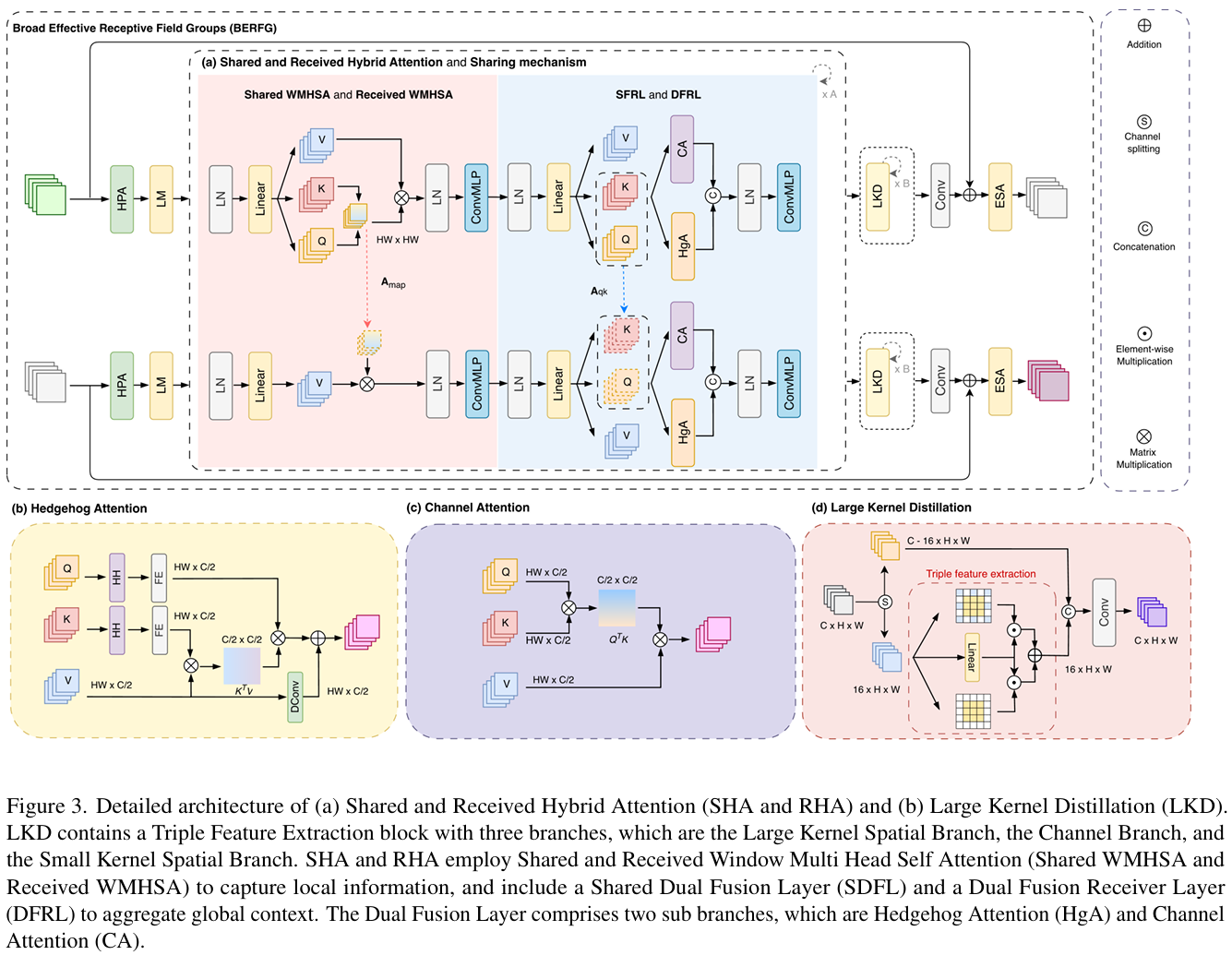
3.3. 广域有效感受野组 (BERFG)
为了优化深度注意力机制的计算成本,我们提出了广域有效感受野组 (BERFG),这是一个由共享块 (Sharing Block, SB) 和接收块 (Receiving Block, RB) 组成的两部分架构(图 3)。共享块首先处理输入特征 FinF_{in}Fin,并使用高性能注意力 (HPA) 和局部模块 (LM) 层 26 通过初始变换传递它们。结果然后进入一系列共享混合注意力 (fSHAf_{SHA}fSHA) 模块,执行完整的注意力计算。如公式 4 所示,这些模块关键地共享 Aqk(a)A^{(a)}{qk}Aqk(a) 和 Amap(a)A^{(a)}{map}Amap(a):
F2,a+1,Amap(a),Aqk(a)=fSHA(a)(F2,a)(4) F_{2,a+1}, A^{(a)}{map}, A^{(a)}{qk} = f^{(a)}{SHA}(F{2,a}) \quad (4) F2,a+1,Amap(a),Aqk(a)=fSHA(a)(F2,a)(4)
特征随后由大核蒸馏 (LKD) 层细化。最后,SB 输出 FSB_outF_{SB\out}FSB_out 通过在初始输入 FinF{in}Fin 的残差连接后应用增强空间注意力 (ESA) 模块 21 产生。
接收块以 FSB_outF_{SB\out}FSB_out 作为输入并镜像其结构。然而,它在接收混合注意力 (fRHAf{RHA}fRHA) 模块中引入了我们的核心优化。RB 不重新计算整个注意力机制,而是直接重用 SB 中对应第 aaa 个模块预计算的注意力组件 (Amap(a),Aqk(a)A^{(a)}{map}, A^{(a)}{qk}Amap(a),Aqk(a)):
F2,a+1′=fRHA(a)(F2,a′,Amap(a),Aqk(a))(5) F'{2,a+1} = f^{(a)}{RHA}(F'{2,a}, A^{(a)}{map}, A^{(a)}_{qk}) \quad (5) F2,a+1′=fRHA(a)(F2,a′,Amap(a),Aqk(a))(5)
架构以与 SB 相同的 LKD 和 ESA 层结束,以产生最终输出 FoutF_{out}Fout。这种半共享策略允许 BERFG 保持深度注意力的强大特征表示,同时显著降低计算负担。
3.4. 高性能注意力
先前的工作 17 表明,扩大感受野改善了信息聚合。因此,我们提出了一个 HPA 模块来优化所学信息,描述为:
Fmlp=fConvMLP(fLN(X)),F1=fFWA(fLN(Fmlp))(6) F_{mlp}= f_{ConvMLP}(f_{LN}(X)), \quad F_1= f_{FWA}(f_{LN}(F_{mlp})) \quad (6) Fmlp=fConvMLP(fLN(X)),F1=fFWA(fLN(Fmlp))(6)
其中 LN 是归一化层,ConvMLP 是核大小为 777 的多层感知机,Flash Attention 用于大窗口注意力。我们首先应用 ConvMLP 来捕捉局部上下文,而不依赖显式的 QKV 投影。为了在更大的空间区域上高效聚合信息,我们结合了窗口大小为 32×3232 \times 3232×32 的窗口注意力。然而,大窗口上的标准自注意力由于二次内存和运行时复杂度而计算昂贵。为了解决这个问题,我们采用 Flash Attention,它 enables 精确的注意力计算,具有显著更低的内存使用和更快的执行速度,使得大窗口自注意力可行。尽管如此,有效感受野仍然受限。为了克服这一点,我们引入了一个混合模块,如下详述。
3.5. 共享和接收混合注意力
我们工作的核心概念是在保持高性能和轻量级设计之间平衡的同时扩展模型有效感受野。为了实现这一点,我们提出了一个有两个主要支柱的解决方案。首先,我们引入了一种半共享机制, dramatically 减少了计算开销而不牺牲表示能力。其次,我们设计了一个混合注意力模块,有效地捕捉局部、全局和通道信息。Together,这两项创新允许我们的模型捕捉更多信息,同时保持快速和高效。架构细节如图 3 所示。
半共享机制。 为了实现轻量级但高性能的设计,我们在混合注意力 (HA) 模块对中引入了一种半共享机制。如图 3a 所示,SHA 由共享窗口多头注意力 (Shared WMHA) 和共享双重融合层 (SDFL) 组成,而 RHA 由接收窗口多头注意力 (Received WMHA) 和双重融合接收层 (DFRL) 组成。在此设计中,来自 Shared WMHA 的注意力图与 Received WMHA 共享,减少了冗余计算。与推导图为 Softmax(QKT)\text{Softmax}(QK^T)Softmax(QKT) 的标准 Softmax 注意力不同,双重融合层将其计算为 ϕ(Q)ϕ(K)T\phi(Q)\phi(K)^Tϕ(Q)ϕ(K)T。在此层内,具有 QQQ 和 KKK 的动态特征图在每一层独立重新计算。这种动态重新计算刷新了特征表示,同时保持了效率。总体而言,半共享机制平衡了表示更新和计算成本,这一权衡由我们的消融研究验证。
局部空间模块。 遵循先前的研究 18,我们采用基于窗口的多头自注意力 (WMSA) 来提取精细局部纹理(图 3)。该设计强调每个像素的直接邻域,允许高保真局部恢复。
全局和通道模块。 我们双重融合层的目标是高效聚合全局空间和通道信息。首先,Q,K,V∈RHW×C/2Q, K, V \in \mathbb{R}^{HW \times C/2}Q,K,V∈RHW×C/2 根据输入 token X∈RHW×CX \in \mathbb{R}^{HW \times C}X∈RHW×C 计算:
Q=WQX;K=WKX;V=WVX;(7) Q= W_Q X; \quad K= W_K X; \quad V= W_V X; \quad (7) Q=WQX;K=WKX;V=WVX;(7)
其中 WQ,WKW_Q, W_KWQ,WK 和 WVW_VWV 是投影矩阵。为了减少冗余和计算,我们从维度 CCC 投影到 C/2C/2C/2,这将特征通道减半并减轻了模型负担,而不牺牲关键信息。张量然后被送入空间、全局和通道分支。
对于空间分支,我们引入了图 3b 中描绘的 Hedgehog 注意力 (HgA)。我们还将轻量级深度卷积集成到计算过程中,可以公式化为:
Fsb=(ϕ(Q))(ϕ(K))TV+WdV,(8) F_{sb}=(\phi(Q))(\phi(K))^T V+ W_d V, \quad (8) Fsb=(ϕ(Q))(ϕ(K))TV+WdV,(8)
其中 WdW_dWd 表示深度卷积,ϕ\phiϕ 是 HFM。我们将空间分支输出表示为 FspF_{sp}Fsp。HFM 学习多尺度特征交互,并增强模型捕捉复杂空间依赖关系的能力。
此外,我们使用傅里叶特征图 11 通过告知图像中的像素相对位置来提升空间注意力性能。包括深度卷积以捕捉局部结构并补充全局注意力。
对于通道分支,CA 机制中的自注意力机制沿通道维度执行,如图 3c 所示。遵循先前的通道注意力设计,我们计算通道注意力为:
Fcb=softmax(QTK)V,(9) F_{cb}= \text{softmax}(Q^T K)V, \quad (9) Fcb=softmax(QTK)V,(9)
其中 FcbF_{cb}Fcb 是通道分支的输出。
最后,FsbF_{sb}Fsb 和 FcbF_{cb}Fcb 被连接以获得最终输出。就计算复杂度而言,全局空间分支和通道分支在空间分辨率上都具有线性复杂度。更具体地说,全局空间分支和通道分支所需的乘加操作数量为:
ODFL=2C2HW⏟channel branch+(6HWC2D+9HWC)⏟spatial branch.(10) O_{DFL}= \underbrace{2C^2 HW}{\text{channel branch}} + \underbrace{(6 HW \frac{C^2}{D} + 9 HW C)}{\text{spatial branch}}. \quad (10) ODFL=channel branch 2C2HW+spatial branch (6HWDC2+9HWC).(10)
其中 DDD 表示头数,通道分支的复杂度用蓝色书写,空间分支用红色书写。这表明我们的双重融合层在空间分辨率上实现了线性复杂度,同时保持了高效率。
3.6. 大核蒸馏
为了进一步细化特征,重点关注广泛的空间依赖关系,我们结合了一个大核蒸馏模块(图 3d)。我们将计算蒸馏到信息量最大的通道上,同时通过轻量级旁路保留全部内容。我们将通道分裂为细粒度子集 Ffg∈RH×W×CfgF_{fg} \in \mathbb{R}^{H \times W \times C_{fg}}Ffg∈RH×W×Cfg 和粗粒度子集 Fcg∈RH×W×(C−Cfg)F_{cg} \in \mathbb{R}^{H \times W \times (C-C_{fg})}Fcg∈RH×W×(C−Cfg),其中 Cfg=max(C/4,16)C_{fg}= \max(C/4, 16)Cfg=max(C/4,16):
Ffg,Fcg=Split(X),Fb+1=Concat(fTFE(Ffg),Fcg).(11) F_{fg}, F_{cg}= \text{Split}(X), \quad F_{b+1}= \text{Concat}(f_{TFE}(F_{fg}), F_{cg}). \quad (11) Ffg,Fcg=Split(X),Fb+1=Concat(fTFE(Ffg),Fcg).(11)
三重特征提取 (TFE) 模块由三个并行分支组成。通道注意力分支提取通道信息,具有 1×1→3×3→1×11 \times 1 \to 3 \times 3 \to 1 \times 11×1→3×3→1×1 瓶颈的局部分支捕捉细粒度细节,层次大核分支使用深度和空洞可分离卷积建模长程上下文。该设计通过将 heavy 计算限制在 CfgC_{fg}Cfg 通道上来实现高效率,从而按比例减少计算。同时,大核路径使用空洞和深度因子分解有效地扩展感受野。完整的架构细节、复杂度和有效感受野分析在补充材料中。
4. 实验
为了验证我们提出的 UCAN 模型,本节展示了其在 SR 任务上的性能。评估是在五个不同的测试集上进行的。我们将描述实验中使用的 methodologies 和数据集,并提出一系列消融研究以确认每个提出模块的重要性。
4.1. 经典图像超分辨率
为了评估我们在传统超分辨率任务上提出的架构,我们利用了五个标准基准数据集 (Set5 2, Set14 37, BSDS100 24, Urban100 12, Manga109 25),并使用基于缩放因子边界裁剪和 YCbCr 颜色空间转换后在亮度通道上计算的 PSNR 和 SSIM 指标评估性能。性能分析涉及重建 HD 图像 (1280×7201280 \times 7201280×720),而计算效率使用 fvcore 库通过乘累加操作 (MACs) 测量。我们展示了两个模型变体:UCAN,专为参数效率设计;UCAN-L,优化以最大化 PSNR 和 SSIM 性能。
4.2. 训练配置
我们的模型使用 161616 的批量大小训练,输入图像随机裁剪到 64×6464 \times 6464×64 像素,并通过随机旋转和水平翻转操作增强。优化采用 Adam 优化器 (β1=0.9,β2=0.99\beta_1 = 0.9, \beta_2 = 0.99β1=0.9,β2=0.99) 以最小化 L1L_1L1 重建损失、LDLL_{DL}LDL 损失 19 和小波损失 15,遵循既定的超分辨率实践。对于 ×2\times 2×2 缩放因子,我们从 scratch 训练 800,000800,000800,000 次迭代,初始学习率为 5×10−45 \times 10^{-4}5×10−4,在里程碑 300K,500K,650K,700K,750K300\\text{K}, 500\\text{K}, 650\\text{K}, 700\\text{K}, 750\\text{K}300K,500K,650K,700K,750K 应用逐步减半衰减。更高放大倍数 (×3\times 3×3 和 ×4\times 4×4) 利用迁移学习,通过微调预训练的 ×2\times 2×2 模型 400,000400,000400,000 次迭代,保持相同的初始学习率,并在 200K,320K,360K,380K200\\text{K}, 320\\text{K}, 360\\text{K}, 380\\text{K}200K,320K,360K,380K 次迭代衰减。所有实验均在 2 块 RTX 3090 GPU 上的 PyTorch 中实现。
4.3. 与最先进方法基准测试
在本节中,我们通过将 UCAN、UCAN-L 模型与最先进 (SOTA) 方法进行比较来评估其有效性,包括基于 CNN 的、轻量级 Transformer -based 和基于 SSM 的超分辨率 (SR) 方法。我们展示了定量和定性结果,强调与先前 SR 模型的比较,如 SwinIR-light 18, ELAN 40, OmniSR 33, SRformer-light 44, ATD-light 38, HiT-SRF 41, ASID-D8 26, MambaIR-light 10, MambaIRV2-light 8, RDN 43, RCAN 42 和 ESC。

我们与 prior state-of-the-art 轻量级 SR 方法进行了全面比较,视觉结果见图 4,定量指标见表 1。我们的基础模型 UCAN 展示了卓越的效率。例如,在 Manga109 (×4\times 4×4) 数据集上,它比 MambaIRV2 实现了显著的 0.260.260.26 dB PSNR 改进,同时需要少 11%11\%11% 的参数。同样,与 ASID-D8 相比,UCAN 在评估集上提供了 superior 性能,尽管参数少 6%6\%6% 且 MACs 低 23%23\%23%。
较大变体 UCAN-L 进一步巩固了我们的领先地位。尽管参数比强大的 ESC 模型少 7%7\%7%,UCAN-L 在五个基准数据集中的四个上优于它。这在 Manga109 (×2\times 2×2) 上尤为明显,我们的模型实现了近 0.10.10.1 dB 的显著增益。这些结果共同强调了 UCAN 的设计作为现代图像超分辨率的 robust、强大且资源高效的解决方案。
表 1. 与最先进方法的轻量级图像超分辨率定量比较。最佳和次佳结果分别用粗体和下划线显示。
| 方法 | 缩放 | #参数 | MACs | Set5 (PSNR / SSIM) | Set14 (PSNR / SSIM) | BSDS100 (PSNR / SSIM) | Urban100 (PSNR / SSIM) | Manga109 (PSNR / SSIM) |
|---|---|---|---|---|---|---|---|---|
| MambaIR-light 10 | 2×2\times2× | 905905905K | 334.2334.2334.2G | 38.1338.1338.13 / 0.96100.96100.9610 | 33.9533.9533.95 / 0.92080.92080.9208 | 32.3132.3132.31 / 0.90130.90130.9013 | 32.8532.8532.85 / 0.93490.93490.9349 | 39.2039.2039.20 / 0.97820.97820.9782 |
| OmniSR 33 | 2×2\times2× | 772772772K | 194.5194.5194.5G | 38.2238.2238.22 / 0.96130.96130.9613 | 33.9833.9833.98 / 0.92100.92100.9210 | 32.3632.3632.36 / 0.90200.90200.9020 | 33.0533.0533.05 / 0.93630.93630.9363 | 39.2839.2839.28 / 0.97840.97840.9784 |
| SRFormer-light 44 | 2×2\times2× | 853853853K | 236.3236.3236.3G | 38.2338.2338.23 / 0.96130.96130.9613 | 33.9433.9433.94 / 0.92090.92090.9209 | 32.3632.3632.36 / 0.90190.90190.9019 | 32.9132.9132.91 / 0.93530.93530.9353 | 39.2839.2839.28 / 0.97850.97850.9785 |
| ATD-light 38 | 2×2\times2× | 753753753K | 380.0380.0380.0G | 38.2938.2938.29 / 0.96160.96160.9616 | 34.1034.1034.10 / 0.92170.92170.9217 | 32.3932.3932.39 / 0.90230.90230.9023 | 33.2733.2733.27 / 0.93750.93750.9375 | 39.5239.5239.52 / 0.97890.97890.9789 |
| HiT-SRF 41 | 2×2\times2× | 847847847K | 226.5226.5226.5G | 38.2638.2638.26 / 0.96150.96150.9615 | 34.0134.0134.01 / 0.92140.92140.9214 | 32.3732.3732.37 / 0.90230.90230.9023 | 33.1333.1333.13 / 0.93720.93720.9372 | 39.4739.4739.47 / 0.97870.97870.9787 |
| ASID-D8 26 | 2×2\times2× | 732732732K | 190.5190.5190.5G | 38.3238.3238.32 / 0.96180.96180.9618 | 34.2434.2434.24 / 0.92320.92320.9232 | 32.4032.4032.40 / 0.90280.90280.9028 | 33.3533.3533.35 / 0.93870.93870.9387 | -- |
| MambaIRV2-light 9 | 2×2\times2× | 774774774K | 286.3286.3286.3G | 38.2638.2638.26 / 0.96150.96150.9615 | 34.0934.0934.09 / 0.92210.92210.9221 | 32.3632.3632.36 / 0.90190.90190.9019 | 33.2633.2633.26 / 0.93780.93780.9378 | 39.3539.3539.35 / 0.97850.97850.9785 |
| RDN 43 | 2×2\times2× | 221232212322123K | 5096.25096.25096.2G | 38.2438.2438.24 / 0.96140.96140.9614 | 34.0134.0134.01 / 0.92120.92120.9212 | 32.3432.3432.34 / 0.90170.90170.9017 | 32.8932.8932.89 / 0.93530.93530.9353 | 39.1839.1839.18 / 0.97800.97800.9780 |
| RCAN 42 | 2×2\times2× | 154451544515445K | 3529.73529.73529.7G | 38.2738.2738.27 / 0.96140.96140.9614 | 34.1234.1234.12 / 0.92160.92160.9216 | 32.4132.4132.41 / 0.90270.90270.9027 | 33.3433.3433.34 / 0.93840.93840.9384 | 39.4439.4439.44 / 0.97860.97860.9786 |
| ESC 26 | 2×2\times2× | 947947947K | 592.0592.0592.0G | 38.3538.3538.35 / 0.96190.96190.9619 | 34.1134.1134.11 / 0.92230.92230.9223 | 32.4132.4132.41 / 0.90270.90270.9027 | 33.4633.4633.46 / 0.93950.93950.9395 | 39.5439.5439.54 / 0.97900.97900.9790 |
| UCAN (Ours) | 2×2\times2× | 689689689K | 146.3146.3146.3G | 38.3438.3438.34 / 0.96180.96180.9618 | 34.2734.2734.27 / 0.92420.92420.9242 | 32.3932.3932.39 / 0.90250.90250.9025 | 33.2233.2233.22 / 0.93790.93790.9379 | 39.5439.5439.54 / 0.97900.97900.9790 |
| UCAN-L (Ours) | 2×2\times2× | 886886886K | 182.4182.4182.4G | 38.3738.3738.37 / 0.96190.96190.9619 | 34.1934.1934.19 / 0.92240.92240.9224 | 32.4432.4432.44 / 0.90310.90310.9031 | 33.3933.3933.39 / 0.93930.93930.9393 | 39.6639.6639.66 / 0.97890.97890.9789 |
| MambaIR-light 10 | 3×3\times3× | 913913913K | 148.5148.5148.5G | 34.6334.6334.63 / 0.92880.92880.9288 | 30.5430.5430.54 / 0.84590.84590.8459 | 29.2329.2329.23 / 0.80840.80840.8084 | 28.7028.7028.70 / 0.86310.86310.8631 | 34.1234.1234.12 / 0.94790.94790.9479 |
| OmniSR 33 | 3×3\times3× | 780780780K | 88.488.488.4G | 34.7034.7034.70 / 0.92940.92940.9294 | 30.5730.5730.57 / 0.84690.84690.8469 | 29.2829.2829.28 / 0.80940.80940.8094 | 28.8428.8428.84 / 0.86560.86560.8656 | 34.2234.2234.22 / 0.94870.94870.9487 |
| SRformer-light 44 | 3×3\times3× | 861861861K | 105.4105.4105.4G | 34.6734.6734.67 / 0.92960.92960.9296 | 30.5730.5730.57 / 0.84690.84690.8469 | 29.2629.2629.26 / 0.80990.80990.8099 | 28.8128.8128.81 / 0.86550.86550.8655 | 34.1934.1934.19 / 0.94890.94890.9489 |
| ATD-light 38 | 3×3\times3× | 760760760K | 168.0168.0168.0G | 34.7434.7434.74 / 0.93000.93000.9300 | 30.6830.6830.68 / 0.84850.84850.8485 | 29.3229.3229.32 / 0.81090.81090.8109 | 29.1729.1729.17 / 0.87090.87090.8709 | 34.6034.6034.60 / 0.95060.95060.9506 |
| HiT-SRF 41 | 3×3\times3× | 855855855K | 101.6101.6101.6G | 34.7534.7534.75 / 0.93000.93000.9300 | 30.6130.6130.61 / 0.84750.84750.8475 | 29.2929.2929.29 / 0.81060.81060.8106 | 28.9928.9928.99 / 0.86870.86870.8687 | 34.5334.5334.53 / 0.95020.95020.9502 |
| ASID-D8 26 | 3×3\times3× | 739739739K | 86.486.486.4G | 34.8434.8434.84 / 0.93070.93070.9307 | 30.6630.6630.66 / 0.84910.84910.8491 | 29.3229.3229.32 / 0.81190.81190.8119 | 29.0829.0829.08 / 0.87060.87060.8706 | -- |
| MambaIRV2-light 9 | 3×3\times3× | 781781781K | 126.7126.7126.7G | 34.7134.7134.71 / 0.92980.92980.9298 | 30.6830.6830.68 / 0.84830.84830.8483 | 29.2629.2629.26 / 0.80980.80980.8098 | 29.0129.0129.01 / 0.86890.86890.8689 | 34.4134.4134.41 / 0.94970.94970.9497 |
| RDN 43 | 3×3\times3× | 223082230822308K | 2281.22281.22281.2G | 34.7134.7134.71 / 0.92960.92960.9296 | 30.5730.5730.57 / 0.84680.84680.8468 | 29.2629.2629.26 / 0.80930.80930.8093 | 28.8028.8028.80 / 0.86530.86530.8653 | 34.1334.1334.13 / 0.94840.94840.9484 |
| RCAN 42 | 3×3\times3× | 156291562915629K | 1586.11586.11586.1G | 34.7434.7434.74 / 0.92990.92990.9299 | 30.6530.6530.65 / 0.84820.84820.8482 | 29.3229.3229.32 / 0.81110.81110.8111 | 29.0929.0929.09 / 0.87020.87020.8702 | 34.4434.4434.44 / 0.94990.94990.9499 |
| ESC 26 | 3×3\times3× | 955955955K | 267.6267.6267.6G | 34.8434.8434.84 / 0.93080.93080.9308 | 30.7430.7430.74 / 0.84930.84930.8493 | 29.3429.3429.34 / 0.81180.81180.8118 | 29.2829.2829.28 / 0.87390.87390.8739 | 34.6634.6634.66 / 0.95120.95120.9512 |
| UCAN (Ours) | 3×3\times3× | 696696696K | 64.664.664.6G | 34.8334.8334.83 / 0.93080.93080.9308 | 30.7230.7230.72 / 0.84930.84930.8493 | 29.3229.3229.32 / 0.81210.81210.8121 | 29.1529.1529.15 / 0.87120.87120.8712 | 34.6234.6234.62 / 0.95080.95080.9508 |
| UCAN-L (Ours) | 3×3\times3× | 893893893K | 81.381.381.3G | 34.8134.8134.81 / 0.93110.93110.9311 | 30.7530.7530.75 / 0.85000.85000.8500 | 29.3429.3429.34 / 0.81270.81270.8127 | 29.2929.2929.29 / 0.87380.87380.8738 | 34.7934.7934.79 / 0.95160.95160.9516 |
| MambaIR-light 10 | 4×4\times4× | 924924924K | 84.684.684.6G | 32.4232.4232.42 / 0.89770.89770.8977 | 28.7428.7428.74 / 0.78470.78470.7847 | 27.6827.6827.68 / 0.74000.74000.7400 | 26.5226.5226.52 / 0.79830.79830.7983 | 30.9430.9430.94 / 0.91350.91350.9135 |
| OmniSR 33 | 4×4\times4× | 792792792K | 50.950.950.9G | 32.4932.4932.49 / 0.89880.89880.8988 | 28.7828.7828.78 / 0.78590.78590.7859 | 27.7127.7127.71 / 0.74150.74150.7415 | 26.6426.6426.64 / 0.80180.80180.8018 | 31.0231.0231.02 / 0.91510.91510.9151 |
| SRformer-light 44 | 4×4\times4× | 873873873K | 62.862.862.8G | 32.5132.5132.51 / 0.89880.89880.8988 | 28.8228.8228.82 / 0.78720.78720.7872 | 27.7327.7327.73 / 0.74220.74220.7422 | 26.6726.6726.67 / 0.80320.80320.8032 | 31.1731.1731.17 / 0.91650.91650.9165 |
| ATD-light 38 | 4×4\times4× | 769769769K | 100.1100.1100.1G | 32.6332.6332.63 / 0.89980.89980.8998 | 28.8928.8928.89 / 0.78860.78860.7886 | 27.7927.7927.79 / 0.74400.74400.7440 | 26.9726.9726.97 / 0.81070.81070.8107 | 31.4831.4831.48 / 0.91980.91980.9198 |
| HiT-SRF 41 | 4×4\times4× | 866866866K | 58.058.058.0G | 32.5532.5532.55 / 0.89990.89990.8999 | 28.8728.8728.87 / 0.78800.78800.7880 | 27.7527.7527.75 / 0.74320.74320.7432 | 26.8026.8026.80 / 0.80690.80690.8069 | 31.2631.2631.26 / 0.91710.91710.9171 |
| ASID-D8 26 | 4×4\times4× | 748748748K | 49.649.649.6G | 32.5732.5732.57 / 0.89900.89900.8990 | 28.8928.8928.89 / 0.78980.78980.7898 | 27.7827.7827.78 / 0.74490.74490.7449 | 26.8926.8926.89 / 0.80960.80960.8096 | -- |
| MambaIRV2-light 9 | 4×4\times4× | 790790790K | 75.675.675.6G | 32.5132.5132.51 / 0.89920.89920.8992 | 28.8428.8428.84 / 0.78780.78780.7878 | 27.7527.7527.75 / 0.74260.74260.7426 | 26.8226.8226.82 / 0.80790.80790.8079 | 31.2431.2431.24 / 0.91820.91820.9182 |
| RDN 43 | 4×4\times4× | 222712227122271K | 1309.21309.21309.2G | 32.4732.4732.47 / 0.89900.89900.8990 | 28.8128.8128.81 / 0.78710.78710.7871 | 27.7227.7227.72 / 0.74190.74190.7419 | 26.6126.6126.61 / 0.80280.80280.8028 | 31.0031.0031.00 / 0.91510.91510.9151 |
| RCAN 42 | 4×4\times4× | 155921559215592K | 917.6917.6917.6G | 32.6332.6332.63 / 0.90020.90020.9002 | 28.8728.8728.87 / 0.78890.78890.7889 | 27.7727.7727.77 / 0.74360.74360.7436 | 26.8226.8226.82 / 0.80870.80870.8087 | 31.2231.2231.22 / 0.91730.91730.9173 |
| ESC 26 | 4×4\times4× | 968968968K | 149.2149.2149.2G | 32.6832.6832.68 / 0.90110.90110.9011 | 28.9328.9328.93 / 0.79020.79020.7902 | 27.8027.8027.80 / 0.74470.74470.7447 | 27.0727.0727.07 / 0.81440.81440.8144 | 31.5431.5431.54 / 0.92070.92070.9207 |
| UCAN (Ours) | 4×4\times4× | 705705705K | 38.138.138.1G | 32.6532.6532.65 / 0.90100.90100.9010 | 28.9528.9528.95 / 0.78990.78990.7899 | 27.7927.7927.79 / 0.74540.74540.7454 | 26.8926.8926.89 / 0.80970.80970.8097 | 31.5031.5031.50 / 0.92000.92000.9200 |
| UCAN-L (Ours) | 4×4\times4× | 902902902K | 48.448.448.4G | 32.6832.6832.68 / 0.90150.90150.9015 | 28.9928.9928.99 / 0.79170.79170.7917 | 27.8027.8027.80 / 0.74590.74590.7459 | 27.0627.0627.06 / 0.81340.81340.8134 | 31.6331.6331.63 / 0.92120.92120.9212 |
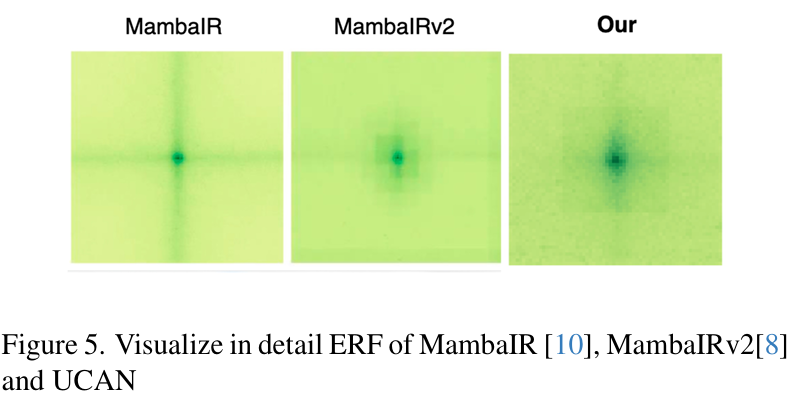
4.4. 有效感受野比较
我们在图 5 中展示了全面的 ERF 分析,将我们提出的 UCAN 模型与其他利用全局空间信息的模型进行比较。ERF 图像显示,UCAN 表现出比现有方法显著更暗和更扩展的影响区域。这种改进的感受野覆盖表明,我们的模型有效地从输入中捕捉更广泛的上下文信息,导致 superior 特征表示,并最终实现更好的图像重建性能。
4.5. 局部归因图
为了评估 UCAN 的信息聚合性能,我们利用局部归因图 (LAM) 7。LAM 是一种旨在识别输入图像中哪些像素最强烈地影响最终 SR 输出的技术。这些区域被称为信息区域,其大小对应于模型聚合信息的能力。如图 6 所示,我们将 LAM 方法应用于 SRFormer 44、ATD 38、HiT-SRF 41 和 UCAN,以比较它们各自相同目标区域的信息区域。SRFormer 操作具有小的固定窗口,产生局部受限的信息区域,从而限制了其捕捉长程依赖关系的能力。虽然 ATD 和 UCAN 通过全局注意力机制扩展了这些信息域,但我们的模型展示了 superior 信息聚合能力。因此,我们的方法可以利用显著更广泛上下文的信息,包括图像中的重复模式和相似结构,导致增强的超分辨率性能。

4.6. 注意力方案性能分析
表 2. 朴素自注意力、Flash Attention 3 和双重融合层 (DFL) 之间的延迟和参数比较
| 模块 | R64×64×64R_{64 \times 64 \times 64}R64×64×64 延迟 (ms) / #参数 | R128×128×64R_{128 \times 128 \times 64}R128×128×64 延迟 (ms) / #参数 |
|---|---|---|
| Attention | 596.53(1.5×)596.53 (1.5\times)596.53(1.5×) / 0.0330.0330.033M | 2576.75(1.0×)2576.75 (1.0\times)2576.75(1.0×) / 0.0820.0820.082M |
| Flash Attention | 190.50(4.7×)190.50 (4.7\times)190.50(4.7×) | 191.80(13.4×)191.80 (13.4\times)191.80(13.4×) |
| DFL | 903.47(1.0×)903.47 (1.0\times)903.47(1.0×) / 0.0140.0140.014M | 1294.83(2.0×)1294.83 (2.0\times)1294.83(2.0×) / 0.0140.0140.014M |
高效的长程交互对于高分辨率超分辨率至关重要,然而传统自注意力随着分辨率增长而 struggle 于快速增加的内存和延迟。UCAN 通过结合 Flash Attention(高效处理大窗口建模)与 DLF(以恒定复杂度聚合全局上下文)克服了这一限制。表 2 展示了在 A100 GPU 上 1000 张图像测量的 Native Self-Attention、Flash Attention 和 DFL 的延迟和参数计数比较。Flash Attention 在 128×128128 \times 128128×128 空间分辨率下实现了比 vanilla 注意力高达 13.4×13.4\times13.4× 的更快处理,展示了当内存约束收紧时的卓越可扩展性。在较小分辨率如 64×6464 \times 6464×64 下,DFL 显示略高的延迟,但在较大尺度下变得快约两倍,证实了其对于高分辨率重建的效率。其参数计数在分辨率间保持稳定,不像自注意力其成本随特征维度增长,表明 UCAN 的混合设计有效地平衡了局部效率和全局意识。
4.7. 消融研究
首先,我们在两种配置下检查了 HPA 块:完全移除和常规 16×1616 \times 1616×16 窗口。与 UCAN 相比,这两种变体都导致明显的性能下降,证实了我们的默认 32×3232 \times 3232×32 设置提供了最佳平衡。接下来,我们在 WMHA 块中将 8×88 \times 88×8 窗口与标准 16×1616 \times 1616×16 配置进行了比较。较小的窗口导致性能大幅下降,表明进一步减小窗口大小会损害特征聚合和整体准确性。然后我们变化核大小 (KS) 到 5×55 \times 55×5 和 47×4747 \times 4747×47 以确定其影响。5×55 \times 55×5 设置产生了较小的感受野,限制了上下文意识,而 47×4747 \times 4747×47 设置引入了过多的填充,降低了性能。在这两种情况下,由于基于蒸馏的架构,我们在包含高度详细纹理的 Urban100 上观察到 accuracy 显著下降。最后,我们评估了半共享机制与完全共享(即,参数计算一次并在层间重用)。半共享方法取得了更好的结果,证实了在层间刷新新信息对于保持表示多样性至关重要。
表 3. 消融研究。我们在 DIV2K 上训练所有模型 400400400K 次迭代,并在 Set5 和 Urban100 (×2\times 2×2) 上测试。最终结果显示在最后一行。
| 块 | 案例 | Set5 (PSNR / SSIM) | Urban100 (PSNR / SSIM) |
|---|---|---|---|
| 高性能注意力 (HPA) | w/o HPA | 38.2738.2738.27 / 0.96160.96160.9616 | 32.9032.9032.90 / 0.93460.93460.9346 |
| 窗口 16×1616 \times 1616×16 | 38.3238.3238.32 / 0.96170.96170.9617 | 33.0433.0433.04 / 0.93640.93640.9364 | |
| WMHA | WS 8×88 \times 88×8 | 38.3238.3238.32 / 0.96170.96170.9617 | 33.0233.0233.02 / 0.93610.93610.9361 |
| 双重融合层 (DFL) | 使用 ReLU | 38.3338.3338.33 / 0.96180.96180.9618 | 33.1633.1633.16 / 0.93740.93740.9374 |
| 使用 ELU+ 1 | 38.3338.3338.33 / 0.96180.96180.9618 | 33.1633.1633.16 / 0.93730.93730.9373 | |
| 大核蒸馏 (LKD) | KS=5×55 \times 55×5 | 38.3338.3338.33 / 0.96180.96180.9618 | 33.1233.1233.12 / 0.93690.93690.9369 |
| KS=47×4747 \times 4747×47 | 38.3438.3438.34 / 0.96180.96180.9618 | 33.1533.1533.15 / 0.93720.93720.9372 | |
| 共享 | 完全共享 | 38.2938.2938.29 / 0.96170.96170.9617 | 32.8932.8932.89 / 0.93500.93500.9350 |
| UCAN | Ours | 38.3438.3438.34 / 0.96180.96180.9618 | 33.2233.2233.22 / 0.93790.93790.9379 |
5. 结论
在本文中,我们提出了 UCAN,这是一种用于图像超分辨率的新颖且轻量级的网络,针对基于 Transformer 的模型的重大内存和计算需求。UCAN 战略性地扩展了感受野,具有增强的 Flash 和线性注意力,我们的实验表明这对性能至关重要。此外,我们引入了一种高效的参数共享方案以及基于蒸馏的大核卷积模块以确保效率。这种双重方法减少了计算负载,同时提高了重建质量。因此,UCAN 利用 Transformer 能力进行高保真图像重建,同时保持轻量级和实用性,为高效 SR 网络建立了有效的方向。
参考文献
1 Yuang Ai, Huaibo Huang, Tao Wu, Qihang Fan, and Ran He. Breaking complexity barriers: High-resolution image restoration with rank enhanced linear attention. arXiv preprint arXiv:2505.16157, 2025.
2 Marco Bevilacqua, Aline Roumy, Christine Guillemot, and Marie Line Alberi-Morel. Low-complexity single-image super-resolution based on nonnegative neighbor embedding. 2012.
3 Tri Dao, Dan Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. Flashattention: Fast and memory-efficient exact attention with io-awareness. Advances in neural information processing systems, 35:16344--16359, 2022.
4 Chao Dong, Chen Change Loy, Kaiming He, and Xiaoou Tang. Learning a deep convolutional network for image super-resolution. In Computer Vision--ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part IV 13, pages 184--199. Springer, 2014.
5 Chao Dong, Yubin Deng, Chen Change Loy, and Xiaoou Tang. Compression artifacts reduction by a deep convolutional network. In Proceedings of the IEEE international conference on computer vision, pages 576--584, 2015.
6 Alexey Dosovitskiy. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929, 2020.
7 Jinjin Gu and Chao Dong. Interpreting super-resolution networks with local attribution maps. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9199--9208, 2021.
8 Hang Guo, Yong Guo, Yaohua Zha, Yulun Zhang, Wenbo Li, Tao Dai, Shu-Tao Xia, and Yawei Li. Mambairv2: Attentive state space restoration. arXiv preprint arXiv:2411.15269, 2024.
9 Hang Guo, Yong Guo, Yaohua Zha, Yulun Zhang, Wenbo Li, Tao Dai, Shu-Tao Xia, and Yawei Li. Mambairv2: Attentive state space restoration, 2024.
10 Hang Guo, Jinmin Li, Tao Dai, Zhihao Ouyang, Xudong Ren, and Shu-Tao Xia. Mambair: A simple baseline for image restoration with state-space model. In European Conference on Computer Vision, pages 222--241. Springer, 2025.
11 Ermo Hua, Che Jiang, Xingtai Lv, Kaiyan Zhang, Youbang Sun, Yuchen Fan, Xuekai Zhu, Biqing Qi, Ning Ding, and Bowen Zhou. Fourier position embedding: Enhancing attention's periodic extension for length generalization. arXiv preprint arXiv:2412.17739, 2024.
12 Jia-Bin Huang, Abhishek Singh, and Narendra Ahuja. Single image super-resolution from transformed self-exemplars. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 5197--5206, 2015.
13 Zheng Hui, Xiumei Wang, and Xinbo Gao. Fast and accurate single image super-resolution via information distillation network. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 723--731, 2018.
14 Jiwon Kim, Jung Kwon Lee, and Kyoung Mu Lee. Deeply-recursive convolutional network for image super-resolution. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 1637--1645, 2016.
15 Cansu Korkmaz and A Murat Tekalp. Training transformer models by wavelet losses improves quantitative and visual performance in single image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6661--6670, 2024.
16 Kin Wai Lau, Lai-Man Po, and Yasar Abbas Ur Rehman. Large separable kernel attention: Rethinking the large kernel attention design in cnn. Expert Systems with Applications, 236:121352, 2024.
17 Dongheon Lee, Seokju Yun, and Youngmin Ro. Emulating self-attention with convolution for efficient image super-resolution. arXiv preprint arXiv:2503.06671, 2025.
18 Jingyun Liang, Jiezhang Cao, Guolei Sun, Kai Zhang, Luc Van Gool, and Radu Timofte. Swinir: Image restoration using swin transformer. In Proceedings of the IEEE/CVF international conference on computer vision, pages 1833--1844, 2021.
19 Jie Liang, Hui Zeng, and Lei Zhang. Details or artifacts: A locally discriminative learning approach to realistic image super-resolution. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5657--5666, 2022.
20 Bee Lim, Sanghyun Son, Heewon Kim, Seungjun Nah, and Kyoung Mu Lee. Enhanced deep residual networks for single image super-resolution. In Proceedings of the IEEE conference on computer vision and pattern recognition workshops, pages 136--144, 2017.
21 Jie Liu, Wenjie Zhang, Yuting Tang, Jie Tang, and Gangshan Wu. Residual feature aggregation network for image super-resolution. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2359--2368, 2020.
22 Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF international conference on computer vision, pages 10012--10022, 2021.
23 Zhisheng Lu, Juncheng Li, Hong Liu, Chaoyan Huang, Linlin Zhang, and Tieyong Zeng. Transformer for single image super-resolution. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 457--466, 2022.
24 David Martin, Charless Fowlkes, Doron Tal, and Jitendra Malik. A database of human segmented natural images and its application to evaluating segmentation algorithms and measuring ecological statistics. In Proceedings eighth IEEE international conference on computer vision. ICCV 2001, pages 416--423. IEEE, 2001.
25 Yusuke Matsui, Kota Ito, Yuji Aramaki, Azuma Fujimoto, Toru Ogawa, Toshihiko Yamasaki, and Kiyoharu Aizawa. Sketch-based manga retrieval using manga109 dataset. Multimedia tools and applications, 76(20):21811--21838, 2017.
26 Karam Park, Jae Woong Soh, and Nam Ik Cho. Efficient attention-sharing information distillation transformer for lightweight single image super-resolution. In Proceedings of the AAAI Conference on Artificial Intelligence, pages 6416--6424, 2025.
27 René Ranftl, Alexey Bochkovskiy, and Vladlen Koltun. Vision transformers for dense prediction. In Proceedings of the IEEE/CVF international conference on computer vision, pages 12179--12188, 2021.
28 Wenzhe Shi, Jose Caballero, Ferenc Huszár, Johannes Totz, Andrew P Aitken, Rob Bishop, Daniel Rueckert, and Zehan Wang. Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 1874--1883, 2016.
29 Yuan Shi, Bin Xia, Xiaoyu Jin, Xing Wang, Tianyu Zhao, Xin Xia, Xuefeng Xiao, and Wenming Yang. Vmambair: Visual state space model for image restoration. arXiv preprint arXiv:2403.11423, 2024.
30 Long Sun, Jinshan Pan, and Jinhui Tang. Shufflemixer: An efficient convnet for image super-resolution. Advances in Neural Information Processing Systems, 35:17314--17326, 2022.
31 Christian Szegedy, Vincent Vanhoucke, Sergey Ioffe, Jon Shlens, and Zbigniew Wojna. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 2818--2826, 2016.
32 Ying Tai, Jian Yang, and Xiaoming Liu. Image super-resolution via deep recursive residual network. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 3147--3155, 2017.
33 Hang Wang, Xuanhong Chen, Bingbing Ni, Yutian Liu, and Jinfan Liu. Omni aggregation networks for lightweight image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22378--22387, 2023.
34 Gang Wu, Junjun Jiang, Junpeng Jiang, and Xianming Liu. Transforming image super-resolution: a convformer-based efficient approach. IEEE Transactions on Image Processing, 2024.
35 Chengxing Xie, Xiaoming Zhang, Linze Li, Haiteng Meng, Tianlin Zhang, Tianrui Li, and Xiaole Zhao. Large kernel distillation network for efficient single image super-resolution. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 1283--1292, 2023.
36 Syed Waqas Zamir, Aditya Arora, Salman Khan, Munawar Hayat, Fahad Shahbaz Khan, and Ming-Hsuan Yang. Restormer: Efficient transformer for high-resolution image restoration. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5728--5739, 2022.
37 Roman Zeyde, Michael Elad, and Matan Protter. On single image scale-up using sparse-representations. In International conference on curves and surfaces, pages 711--730. Springer, 2010.
38 Leheng Zhang, Yawei Li, Xingyu Zhou, Xiaorui Zhao, and Shuhang Gu. Transcending the limit of local window: Advanced super-resolution transformer with adaptive token dictionary. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2856--2865, 2024.
39 Michael Zhang, Kush Bhatia, Hermann Kumbong, and Christopher Ré. The hedgehog& the porcupine: Expressive linear attentions with softmax mimicry. arXiv preprint arXiv:2402.04347, 2024.
40 Xindong Zhang, Hui Zeng, Shi Guo, and Lei Zhang. Efficient long-range attention network for image super-resolution. In European conference on computer vision, pages 649--667. Springer, 2022.
41 Xiang Zhang, Yulun Zhang, and Fisher Yu. Hit-sr: Hierarchical transformer for efficient image super-resolution. In European Conference on Computer Vision, pages 483--500. Springer, 2024.
42 Yulun Zhang, Kunpeng Li, Kai Li, Lichen Wang, Bineng Zhong, and Yun Fu. Image super-resolution using very deep residual channel attention networks. In Proceedings of the European conference on computer vision (ECCV), pages 286--301, 2018.
43 Yulun Zhang, Yapeng Tian, Yu Kong, Bineng Zhong, and Yun Fu. Residual dense network for image super-resolution. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 2472--2481, 2018.
44 Yupeng Zhou, Zhen Li, Chun-Le Guo, Song Bai, Ming-Ming Cheng, and Qibin Hou. Srformer: Permuted self-attention for single image super-resolution. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 12780--12791, 2023.