一、前言
哈喽大家好,我是「老周聊架构」主理人老周,周末参加了Data For AI的活动,本来那天有龙虾的活动,想了几秒:我毅然还是选择了Data For AI的活动。为啥呢?"AI的燃料是数据,数据的燃料是元数据。" 如何?这个理由充分不,哈哈哈哈,我们话不多说直接进入正题。
二、AI Agent 时代的数据控制:从「什么时候我们才可以用OpenClaw来做数据管理?」谈起
第一个上场分享的是Datastrato创始人堵俊平老师,从ChatGPT引爆AI圈后,从LLM到RAG再到Agent再到今年的OpenClaw,大模型走到了今天这个时间点,不仅仅是能回答问题,而且是能去帮用户主动的解决问题,这是Agent跟之前的范式核心的变化之一。

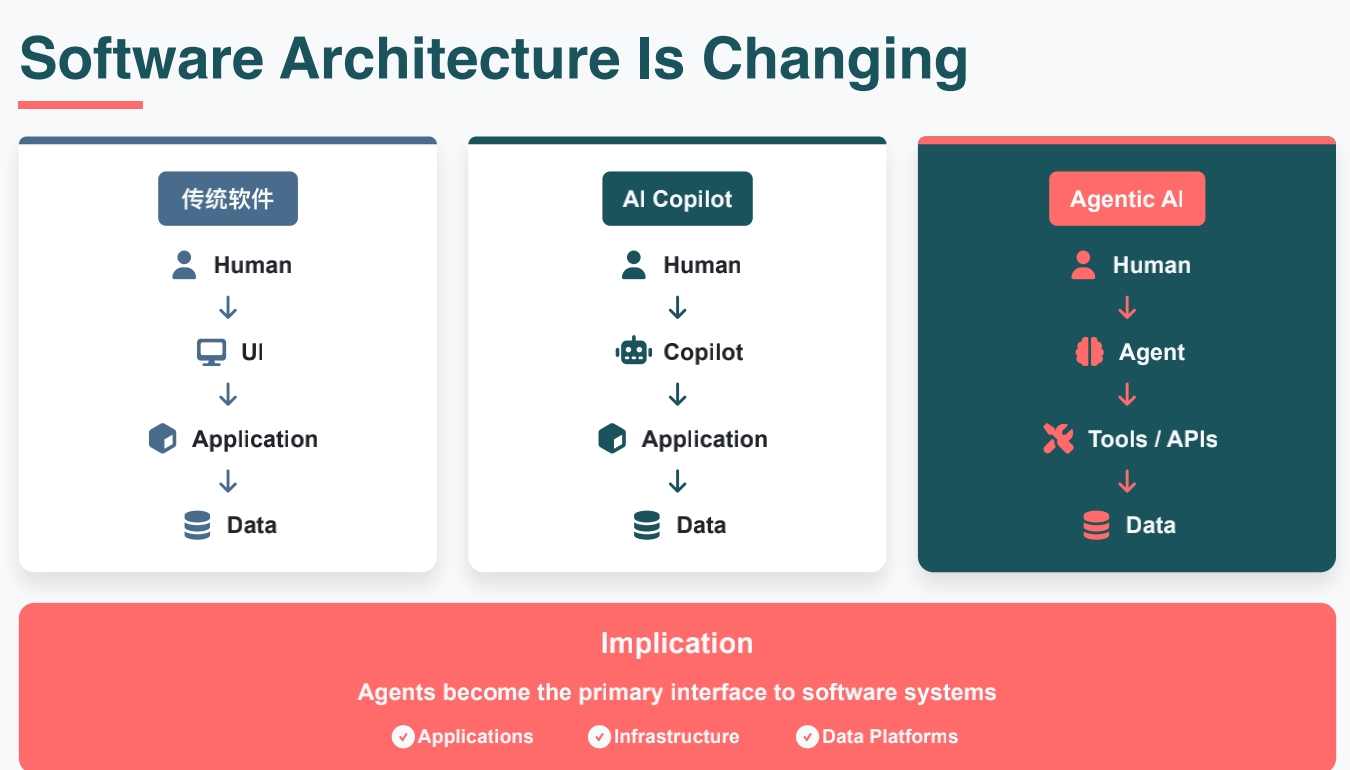
软件架构正经历从传统的"以界面为中心"到"以智能体(Agent)为中心"的深刻变革。这一过程可以划分为三个关键阶段:
- 传统软件阶段(UI-Centric): 这是典型的"命令-响应"模式。人类用户通过图形界面(UI)直接操作系统。架构的核心在于如何高效地将用户指令转化为后端应用的逻辑处理,UI 是唯一的沟通媒介。
- AI Copilot 阶段(Assisted interaction): 随着 AI 的介入,软件进入了"辅助驾驶"时代。Copilot 作为一个中间层嵌入到人与应用之间,帮助用户生成代码、撰写文档或优化查询。此时,AI 主要起到降本增效的作用,但交互的主动权和流程的串联依然掌握在人类手中。
- Agentic AI 阶段(Agent-Centric): 这是架构最本质的跃迁。Agent 正在取代 UI 成为软件系统的首要接口。 在这种模式下,人类只需提供目标(Goal),Agent 则自主进行任务拆解,通过调用各种工具和 API 独立完成任务并与数据交互。
上面说完软件架构的变化,下面说下数据架构的五大核心转向:
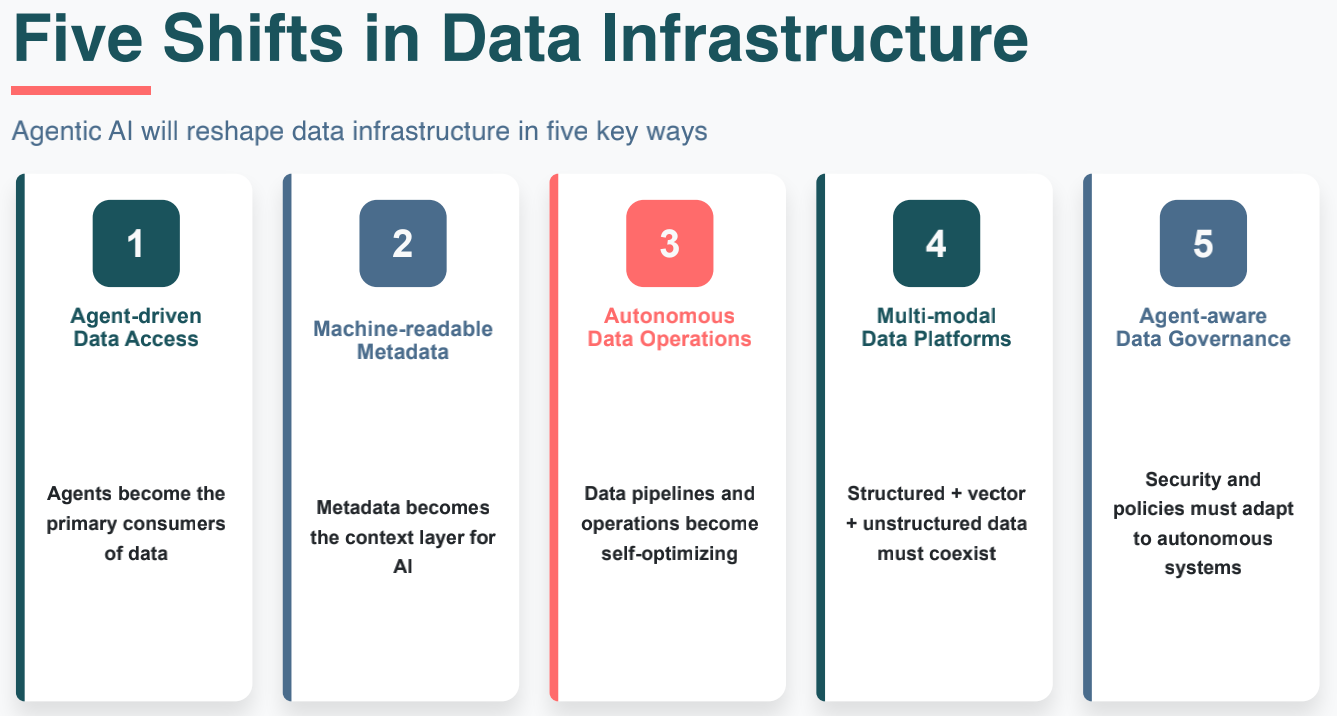
- 从"人看"转为"代理看"(Agent-driven Data Access): 过去的数据架构旨在为人类提供报表和可视化,而未来,Agent 将成为数据的第一消费群体。这意味着数据访问不再仅仅是 SQL 查询,而是需要支持自然语言检索和语义化的接口,以适应 Agent 的自主调度。
- 元数据的语义化升级(Machine-readable Metadata): 元数据不再只是数据库的字典,而是演变为 AI 的上下文图谱(Context Layer)。架构需要提供具备极强机器可读性的元数据,帮助 Agent 快速理解数据背后的业务逻辑、血缘关系及质量可靠性。
- 自动化运维的闭环(Autonomous Data Operations): 数据管线(Data Pipeline)正从"手动配置"转向"自愈优化"。通过集成 AI 能力,系统能够根据负载、成本和数据新鲜度自主调整任务编排,实现链路的自适应优化,大幅降低工程负担。
- 全模态底座的融合(Multi-modal Data Platforms): 结构化数据、向量数据与非结构化数据的界限彻底模糊。新一代架构必须支持多种数据形态在同一平台共生,让 Agent 能够在一个统一的逻辑视图下,无缝跨越表格、音视频与文档进行关联推理。
- 治理模式的智能转型(Agent-aware Data Governance): 当系统由 Agent 主导时,安全、合规和隐私政策必须具备代理感知能力。治理不再是事后的审计,而是实时的、面向自主系统的动态策略控制,以应对 Agent 在执行复杂长链任务时可能带来的风险。
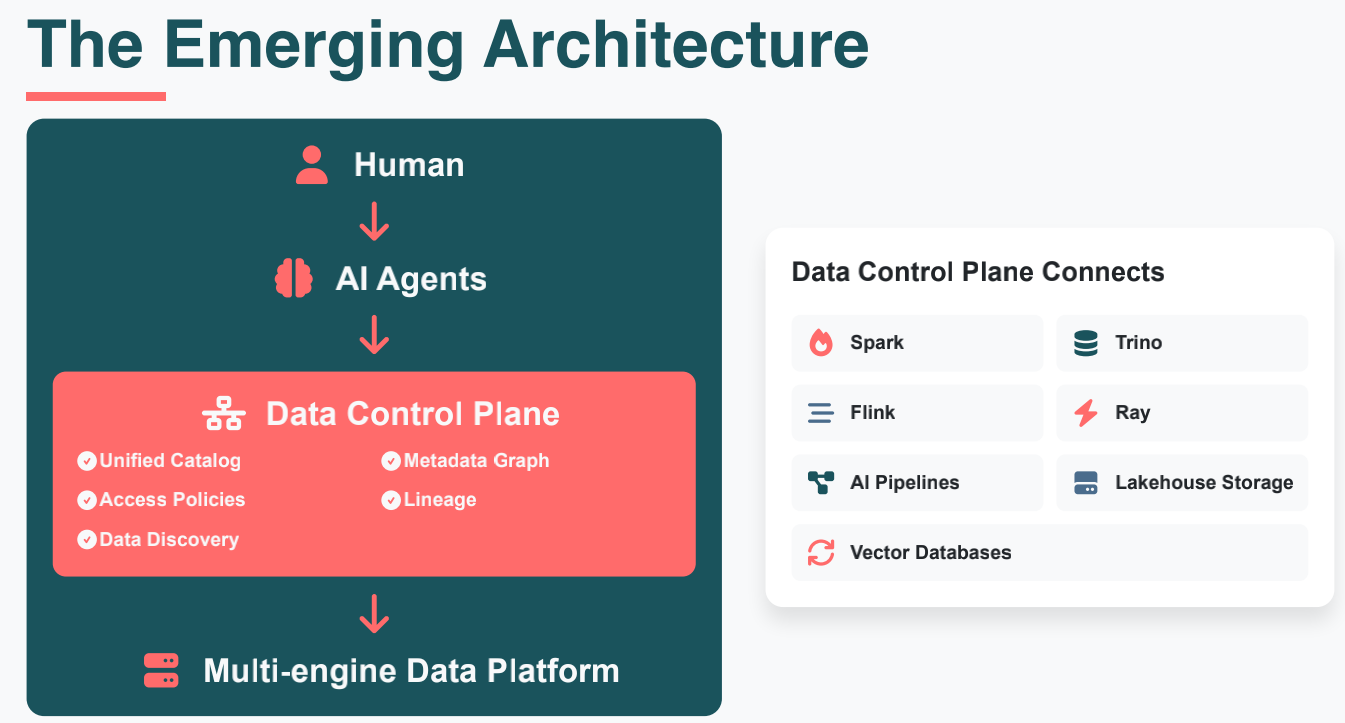
随着 AI Agents 成为人类与数据交互的主要入口,架构重心正在向数据控制平面转移。这一架构不再要求 Agent 直接面对底层繁琐的计算引擎,而是通过一个高度抽象、语义化的中枢进行调度:
- 中枢化治理: 数据控制平面集成了统一目录(Unified Catalog)、元数据图谱(Metadata Graph)以及血缘追踪(Lineage)。它为 Agent 提供了清晰的"数据导航",确保 AI 能够精准发现数据、理解业务逻辑并遵循统一的安全访问策略。
- 多引擎协同(Multi-engine Data Platform): 该架构解耦了控制与执行。控制平面向下连接着由 Spark、Flink、Trino、Ray 等组成的计算集群,以及湖仓存储(Lakehouse)和向量数据库(Vector Databases)。
- AI 管道的融合: 传统的 ETL 正在进化为 AI Pipelines。数据不再仅仅是静态的存储,而是通过控制平面的动态编排,实时流向 Agent 进行推理或处理。
老周看了很多组件,很多组件都是慢慢在向这一方向在演进。
这种设计彻底解决了 Agent 在面对海量、异构数据源时的"迷茫"问题。它将复杂的基础设施逻辑封装在控制平面之下,让 Agent 能够专注在目标达成上,实现了逻辑上统一视图,物理上分布式执行的终极形态。
三、TBDS:AI时代的多模态数据湖基础设施
接下来由腾讯云TBDS技术负责人张帅老师带来的分享,有点像字节的LAS,反正都是数据湖的基础设施。
腾讯⼤数据套件 TBDS(Tencent Big Data Suite) 是腾讯云⾯向企业级场景的⼀站式⼤数据平台,集成存储、计算、治理与 AI 能⼒,提供从数据接⼊、湖仓存储(HDFS/Iceberg/Lance)、多引擎计算(Spark/Flink/Presto/StarRocks)到元数据管理(MetaService)、数据⾎缘与权限治理的全链路⼤数据解决⽅
案,⽀持私有化部署、国产化芯⽚适配及⾦融/能源/互联⽹等⾏业场景落地。
传统数据湖在⾯对⼤规模多模态数据时,⾯临存储、计算、管理和治理上的诸多挑战。

TBDS 深度集成 Lance:实现多模态数据⾼效存储
当我看到腾讯也深度集成Lance的时候,我才反应过来,我之前以为是字节的产品,因为之前字节的数据湖分享的时候经常出现Lance。那老周这里就简单先介绍下Lance吧:
Lance 是由 LanceDB 这家初创公司开发并开源的。它的创始人包括 Chang She(曾是 Pandas 的核心作者之一)等。它被定义为一种专门为 AI 和多模态数据设计的现代列式数据格式。
Lance格式 为AI时代存储⽽⽣,使⽤存算分离架构,更易维护,在海量数据下有较⼤成本优势。

上面说完存储,我们下面说下计算:
TBDS集成增强Ray:多模态数据⾼效流转&AI计算资源弹性管理

除了上面的特性以外,⽀持混合调度多个k8s集群的CPU/GPU异构资源, ⽀持客户在AI时代的计算需求。
TBDS协同开发Gravitino: ⼀站式管理异构数据源
Gravitino:多模态数据资产的统⼀管理
从⽂件⽬录到 REST 接⼝,不同lance表元数据管理⽅案在集中管理、权限控制和扩展性上差距显著。

TBDS-Lakekeeper:完整 AI 数据湖治理⽅案
-
自动化索引与智能化治理
通过无人值守的 IVF/HNSW 向量索引 构建与实时统计,系统能自动评估索引健康度并确保持续覆盖。同时,结合策略驱动的表优化治理,通过自动清理旧版本与小文件合并,显著释放存储空间并降低检索 I/O 开销。
-
高性能分布式架构
方案深度集成 Ray 集群分布式计算,支持多模态数据的并行读写与超大规模索引构建,配合常驻的 Lance 检索服务,极大提升了系统的吞吐量,且不占用客户端计算资源。
-
统一存储与加速
底层依托 TBDS-FS 统一存储,利用分布式缓存能力加速数据检索。它成功屏蔽了 HDFS、S3 等异构存储系统的复杂性,通过统一命名空间将多个存储后端挂载到同一逻辑视图,实现了存储资源的极致解耦与高效访问。
TBDS全新⼀代AI湖仓产品架构
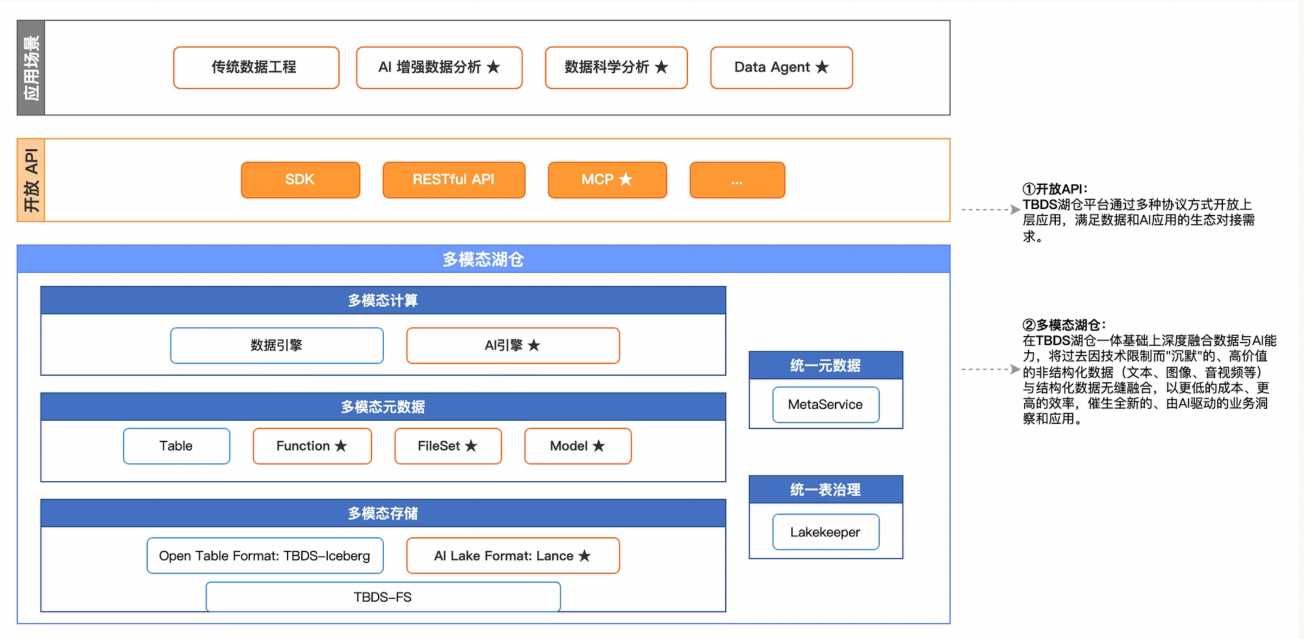
我们从三个维度来看:
- 核心底座:多模态湖仓(Multimodal Lakehouse)
- 多模态存储:底层基于 TBDS-FS,向上支撑 Iceberg(处理表格式数据)和 Lance(专为 AI 向量和非结构化数据优化的格式)。这种"双格式"设计确保了传统工程与 AI 检索的高效并行。
- 多模态元数据:除了传统的 Table 级管理,还引入了对 Function(函数)、FileSet(文件集) 和 Model(模型) 的统一元数据治理,实现了"万物皆可索引"。
- 多模态计算:内置数据引擎与 AI 引擎。AI 引擎的加入意味着数据不再只是被动的存储,而是可以直接进行模型推理和向量转化。
- 治理与服务:统一元数据与表治理
- MetaService:提供统一元数据服务,确保数据在不同引擎间的一致性。
- Lakekeeper:负责统一表治理,通过自动化的索引构建与空间优化,降低了维护大规模 AI 数据集的复杂度。
- 开放生态与应用场景
- 开放 API:除了 SDK 和 RESTful API,特别亮眼的是支持 MCP (Model Context Protocol),这标志着该架构能够原生适配主流的大模型生态,让数据更易于被 Agent 调用。
- 全场景覆盖:从传统的 BI/数据工程,到 Data Agent 和 AI 增强分析,体现了"数智化"转型的最终落地。
基于AI数据湖的知识库构建
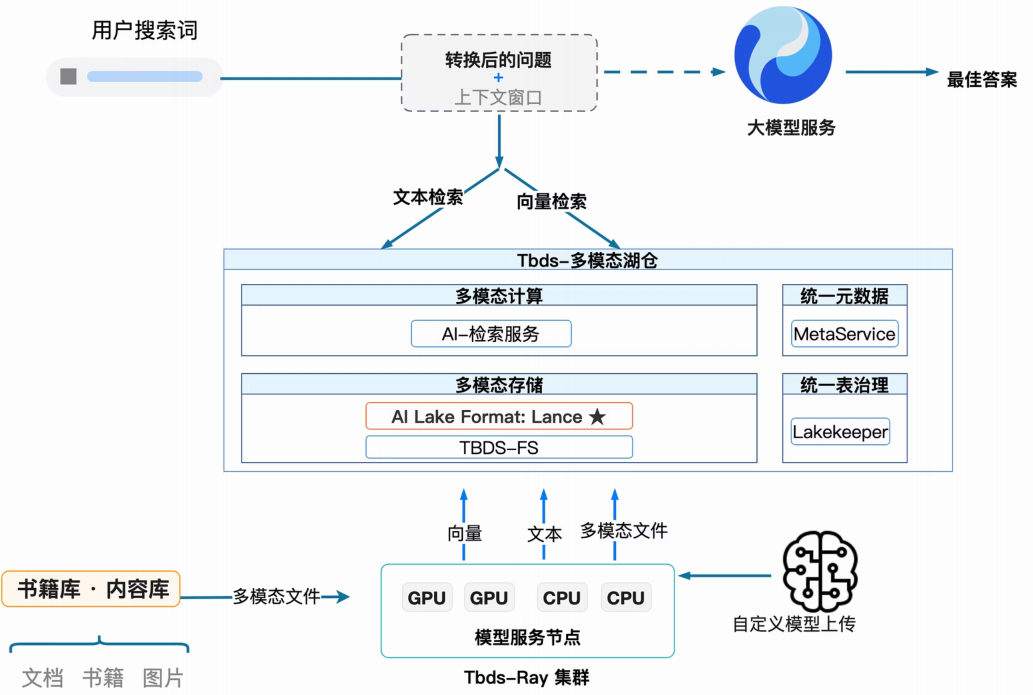
- 数据生产与预处理(底部:Tbds-Ray 集群)
- 多模态注入:来自书籍库、内容库的文档、书籍、图片等原始文件进入系统。
- 分布式计算:利用 Tbds-Ray 集群 的强大算力,通过 GPU 和 CPU 节点协同,完成数据的特征提取(Embedding)。
- 多模态产出:将原始文件转化为向量、文本和多模态文件,为后续的精准检索打下基础。
- 多模态存储与管理(中部:Tbds-多模态湖仓)
- 核心存储层:依托 TBDS-FS,采用专为 AI 优化的 Lance 格式。这种格式的优势在于能够同时兼顾高性能的向量检索和传统的文本检索。
- 计算与治理:AI-检索服务 直接驻留在湖仓之上,减少了数据搬运。配合 MetaService(统一元数据)和 Lakekeeper(统一表治理),确保了海量 AI 数据的高可靠性和一致性。
- 应用交互与检索增强(顶部:大模型服务)
- 意图理解:用户搜索词并非直接丢给模型,而是经过"转换后的问题 + 上下文窗口"的预处理,使搜索更具语义针对性。
- 双路检索:系统同时发起文本检索和向量检索。文本检索保证关键词的精确匹配,向量检索负责理解语义深度。
- RAG 闭环:检索到的知识块作为背景补充给大模型服务,由模型生成最终的"最佳答案",从而有效解决了大模型的幻觉问题。
四、Gravitino&Curvine在OPPO多模态数据湖应⽤实践
接下来是来自OPPO⼤数据架构负责⼈David分享的《Gravitino&Curvine在OPPO多模态数据湖应⽤实践》,上面就有老师分享过Gravitino,现在Gravitino又出现了,看来Gravitino在元数据这块已经深入各个大厂的青睐了。
这里的Curvine可能大家不怎么熟悉,老周这里大概介绍下,Curvine是由OPPO开源的一款分布式缓存组件。
Curvine is a high-performance, concurrent distributed cache system written in Rust, designed for low-latency and high-throughput workloads.
Name Origin The name "Curvine" is derived from the concatenation of the words "Curvature" and "Engine". It refers to an accelerator for spacecraft in the science fiction novel The Three-Body Problem, symbolizing extremely high performance.
Curvine 是一个用 Rust 编写的高性能并发分布式缓存系统,专为低延迟和高吞吐量工作负载而设计。
名称由来:Curvine 的名称源自"曲率"(Curvature)和"引擎"(Engine)两个词的组合。它指的是科幻小说《三体》中用于航天器的加速器,象征着极高的性能。
数据湖仓发展阶段
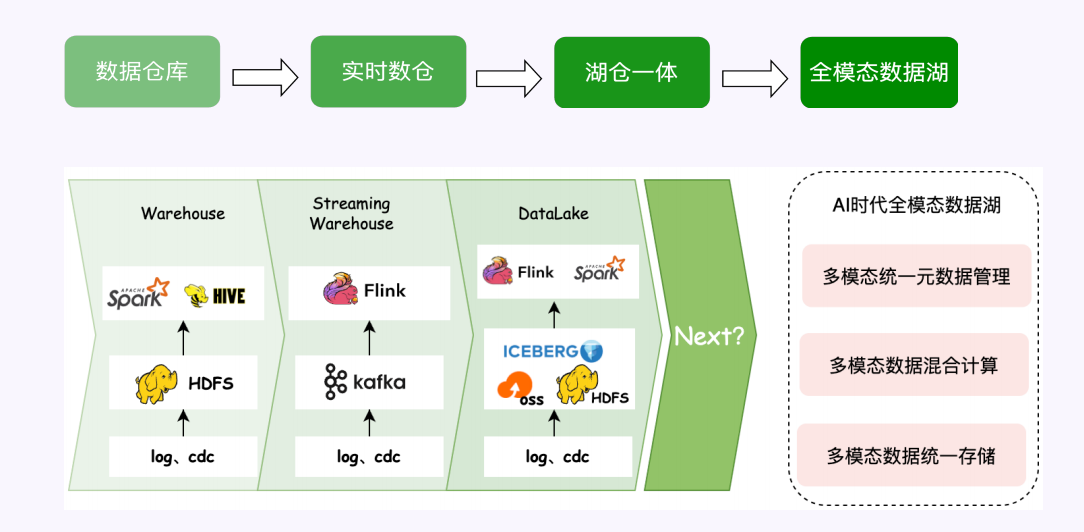
数据湖仓发展的发展基本上是这么一个方向,在AI时代必然是多模态的,无非抓住三个点:多模态数据怎么混合计算、怎么统一存储、怎么统一元数据管理。基本上是围绕这三个点进行的。
OPPO的多模态数据湖架构
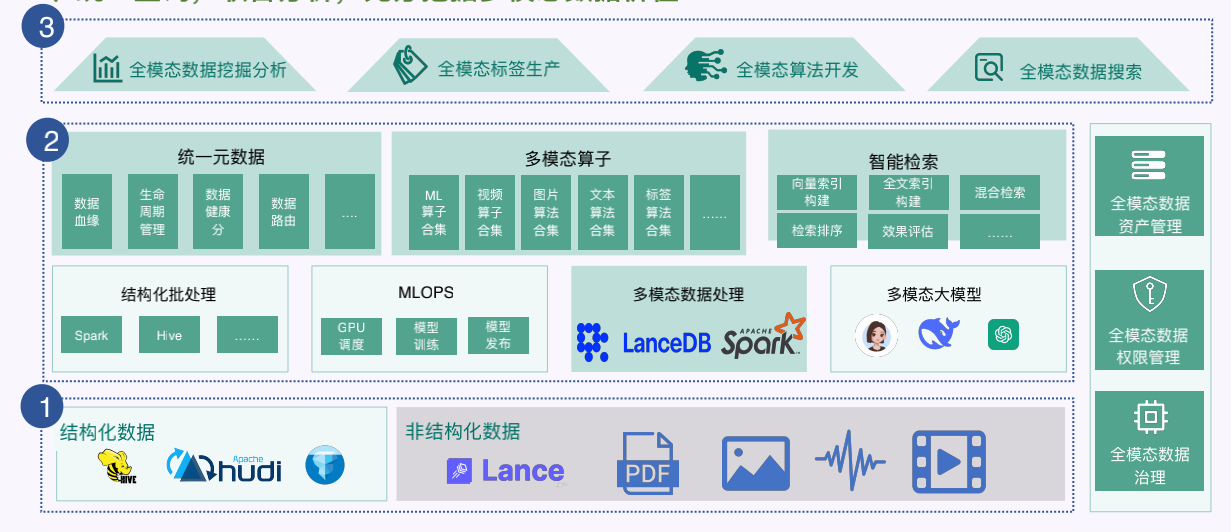
存储层:结构化与非结构化的融合 (L1)
- 结构化数据: 依赖传统的 Hive、Apache Hudi、Trino 等湖仓技术,处理关系型数据。
- 非结构化数据: 重点引入了 Lance 格式,专门针对 PDF、图片、音频、视频进行存储,为后续的向量化处理打下基础。
处理层:多模态算子与混合计算 (L2)
- 统一元数据与治理: 涵盖血缘分析、生命周期管理和健康分,确保数据的合规与质量。
- 多模态算子引擎: 包含针对文本、图像、视频、标签的各类算法合集,将原始数据转化为特征。
- 计算框架: 利用 Spark 进行大规模批处理,结合 LanceDB 进行高效的向量化存储与计算,并配备了完整的 MLOps(模型训练/发布)和 GPU 调度能力。
检索层:从关键词到语义搜索 (L2 右侧)
- 不仅支持传统的全文索引,还构建了基于向量的索引。
- 通过混合检索(Hybrid Search)、检索重排序(Reranking)和效果评估,提升了非结构化数据的查找精准度,这是实现 RAG(检索增强生成)的关键。
应用与管控层 (L3 及右侧)
- 上层应用: 最终通过全模态数据挖掘、算法开发和搜索,直接赋能业务。
- 纵向管控: 右侧的三个垂直模块(资产管理、权限管理、数据治理)贯穿始终,确保全模态数据在开发利用过程中的安全与规范。
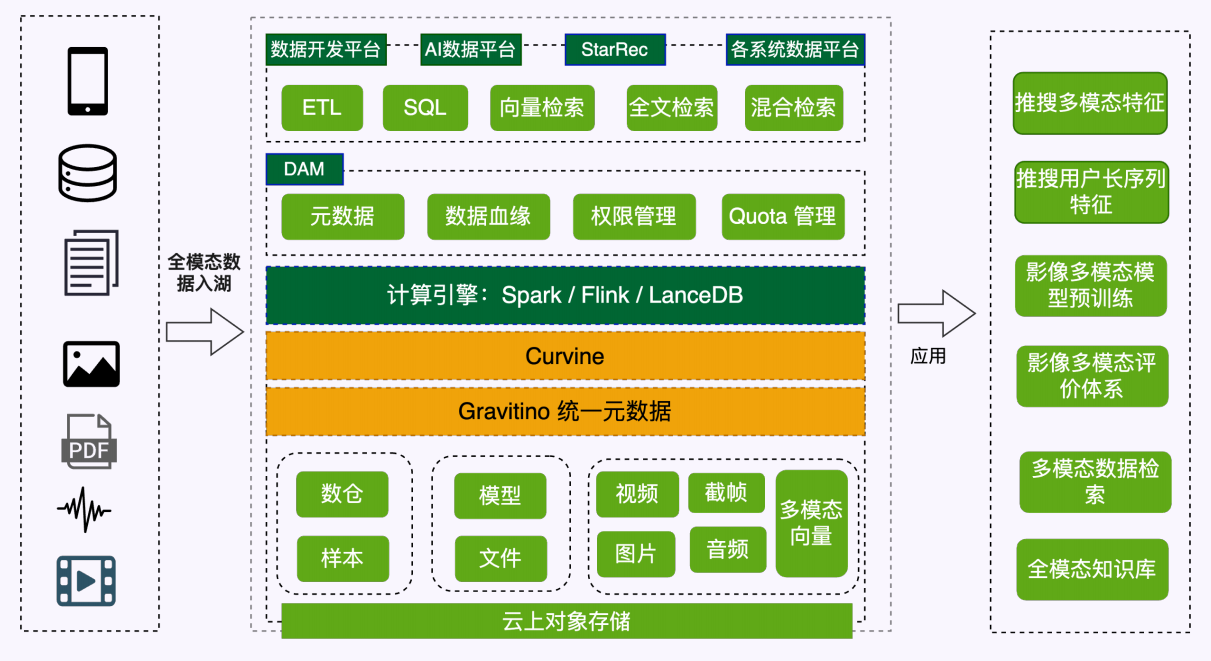
其实技术架构基本大差不差,老周这里说下和以前不一样的地方:AI 原生设计,相比传统架构,它通过 Gravitino + LanceDB 的组合,将"向量数据"提升到了与"关系型数据"同等的战略地位。
Gravitino统⼀全模态元数据
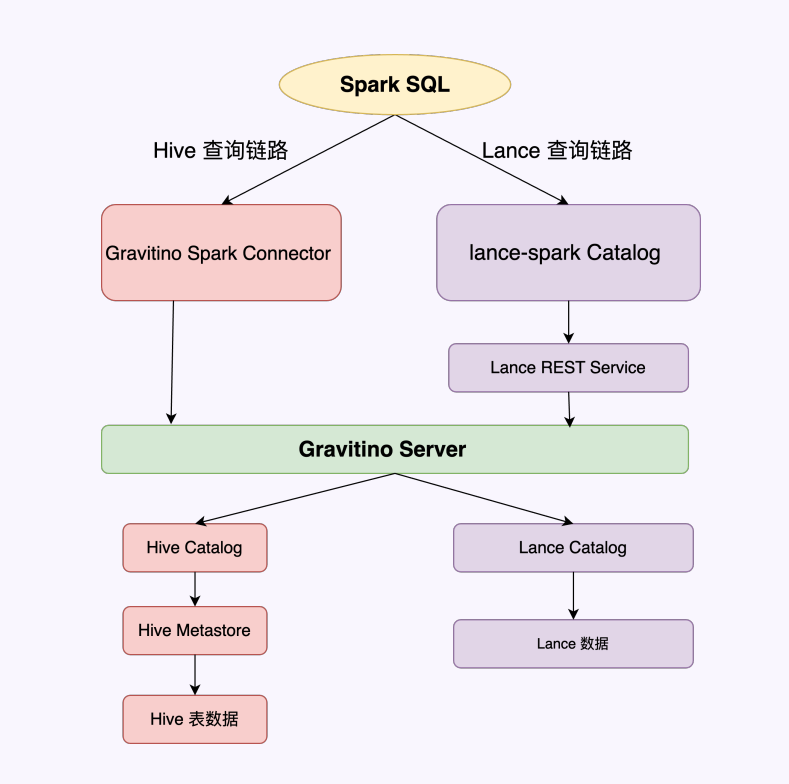
上图展示了 Spark SQL 如何通过 Gravitino 同时调度两种截然不同的数据底座:
核心技术架构:双链路打通
- Hive 查询链路(左侧红线): 通过 Gravitino Spark Connector 访问传统的 Hive Metastore,获取结构化表数据。
- Lance 查询链路(右侧紫线): 通过 lance-spark Catalog 走 Lance REST Service,对接 Gravitino Server 来管理非结构化或向量化的 Lance 数据。
- 核心中枢: Gravitino Server 充当了统一的控制面,向下挂载不同的 Catalog(Hive Catalog 和 Lance Catalog),向上对接计算引擎。
三大能力成果
- 统一元数据: 将 Hive 和 Lance 两套完全不同的存储格式归于同一套目录体系下,解决了多模态数据与传统数仓数据"各管各"的痛点。
- 联邦查询: 用户只需写一条 SQL,即可实现 Hive 表与 Lance 表的 跨表 JOIN。例如:将用户行为表(Hive)与用户的多模态特征向量(Lance)直接进行关联分析。
- 标准化对接: 无论是传统的 Connector 还是新兴的 lance-spark,均实现了对 Gravitino 的标准化对接。
一句话总结:Gravitino 屏蔽了底层存储的差异性,通过构建统一的元数据层,让 Spark 具备了同时处理大数据分析(Big Data)与 AI 多模态数据(AI Data)的联邦计算能力。
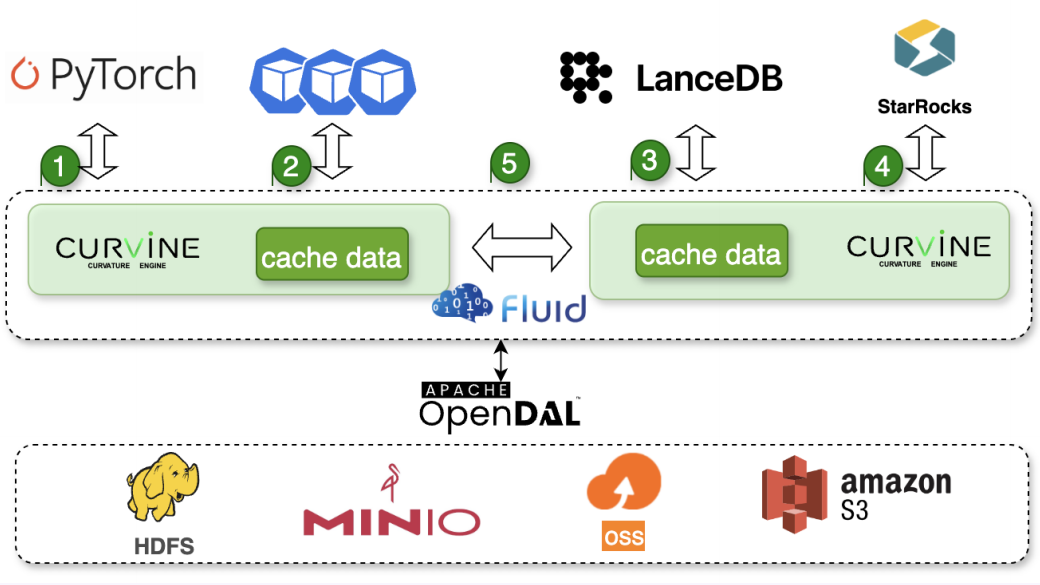
我们再来看下Curvine在哪个位置,很明显在计算和存储之间。
那如何让Curvine加速多模态数据读写呢?
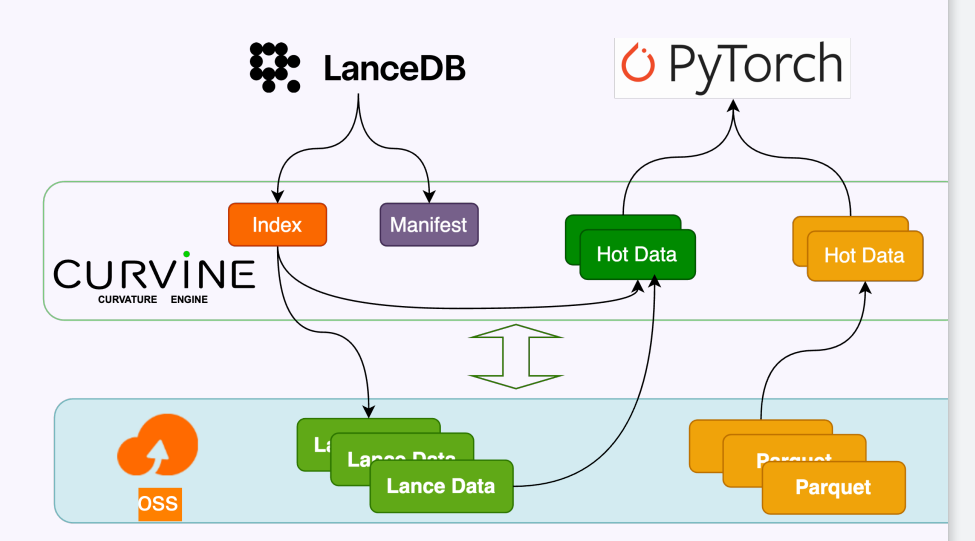
Curvine通过在底层对象存储(OSS)与上层计算框架(如 LanceDB 和 PyTorch)之间构建智能缓存层,显著消除了 AI 场景下的 I/O 瓶颈。它不仅通过缓存索引(Index)和元数据(Manifest)实现毫秒级的快速检索响应,还支持对频繁访问的图片、视频等热表数据进行预热,确保数据能够以"近计算端"的速度供给计算节点。此外,Curvine 还针对模型训练中的 Checkpoint 写入进行了专项加速,通过异步刷盘与分布式协同,保障了超大规模多模态数据在湖仓架构中的读写稳定性与高效流转。
五、AI 原⽣元数据平台的能⼒与实践:Apache Gravitino
AI Agent在访问数据方面面临的挑战
过去,数据治理的重心在于打破物理孤岛,即通过 ETL 手段将离散数据汇聚到数仓或数据湖,解决的是人查数据、看报表、做决策的需求。
而当下,数据的生产与消费主体正从'人'转向'模型与 Agent'。数据不再仅仅为了应用呈现,而是成为了模型燃料:一是为了模型微调与预训练,提供高质量的行业知识;二是为了嵌入 RAG 与 Agent 流程,通过实时索引与语义检索,将海量数据转化为直接解决业务问题的行动能力。这种转变要求我们从简单的'数据汇聚'走向深度语义对齐。
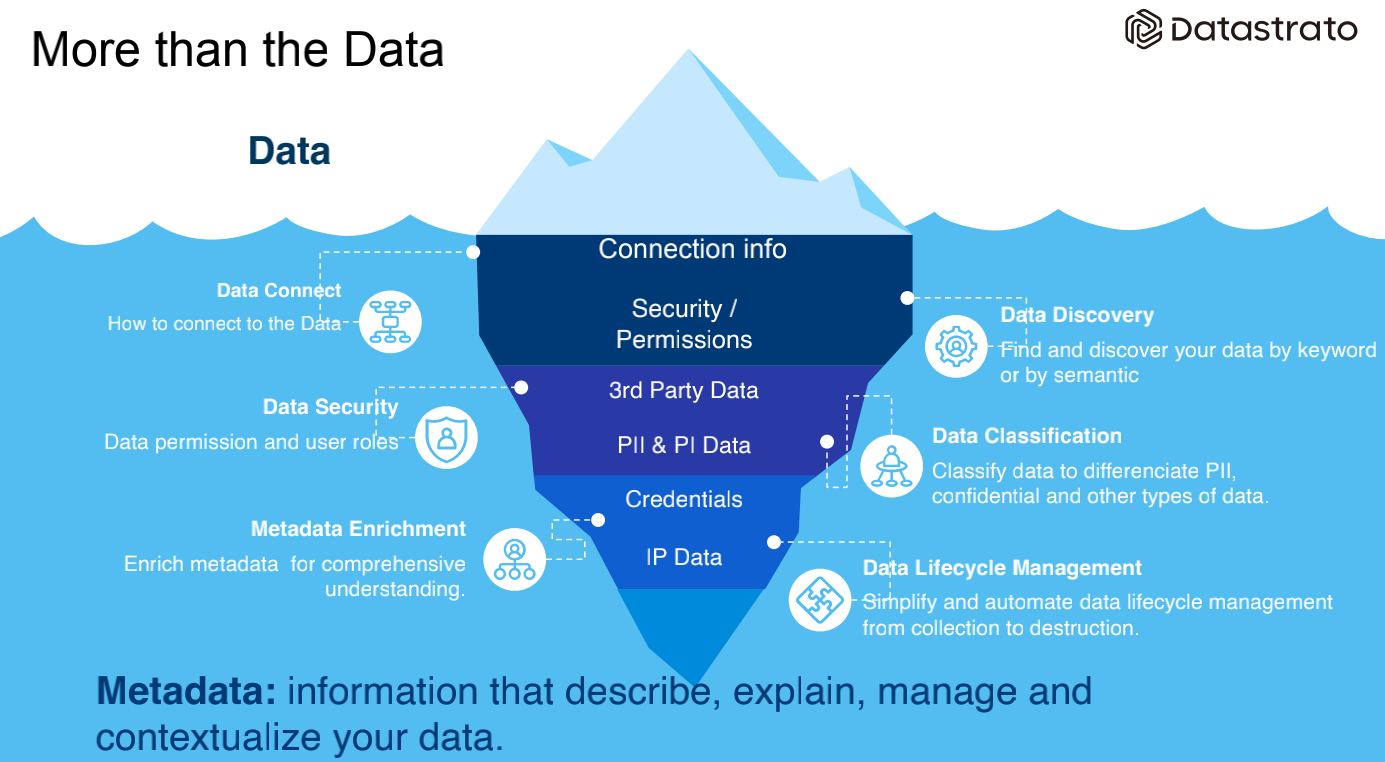
我们经常往往会说需要哪些数据,但最容易忽略的是冰山水面底下的元数据,这些元数据其实是这些数据的基座。
这里千呼万唤始出来,Gravitino作为元数据组件开源了出来,打破数据孤岛且为应用提供可靠的方式来获取这些数据。作为面向AI+Data的数据目录产品,应该低代价、低成本、同时满足合规要求把这些数据管理在一起。
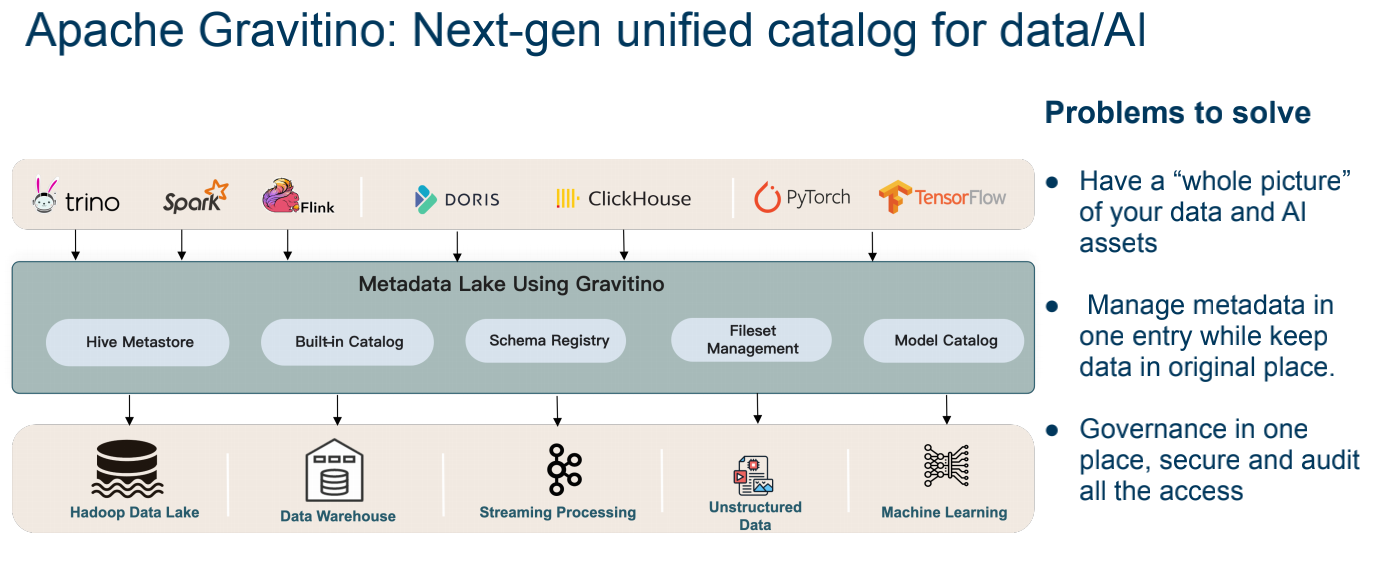
上层(计算与消费): 涵盖了大数据引擎(Trino、Spark、Flink)、OLAP 数据库(Doris、ClickHouse)以及 AI 框架(PyTorch、TensorFlow)。这意味着无论你是写 SQL 的开发者,还是训练模型的 AI 工程师,都通过同一个入口对接数据。
中层(Gravitino 统一元数据层): 这是核心。它通过 Built-in Catalog 兼容了多种元数据标准,包括:
- Hive Metastore: 兼容传统数仓表。
- Fileset Management: 管理非结构化文件(图片、视频、PDF)。
- Model Catalog: 专门管理 AI 模型资产。
底层(多源存储): 对接 Hadoop 数据湖、传统数仓、流式数据处理系统、非结构化存储以及机器学习专用存储。
Apache Gravitino Architecture
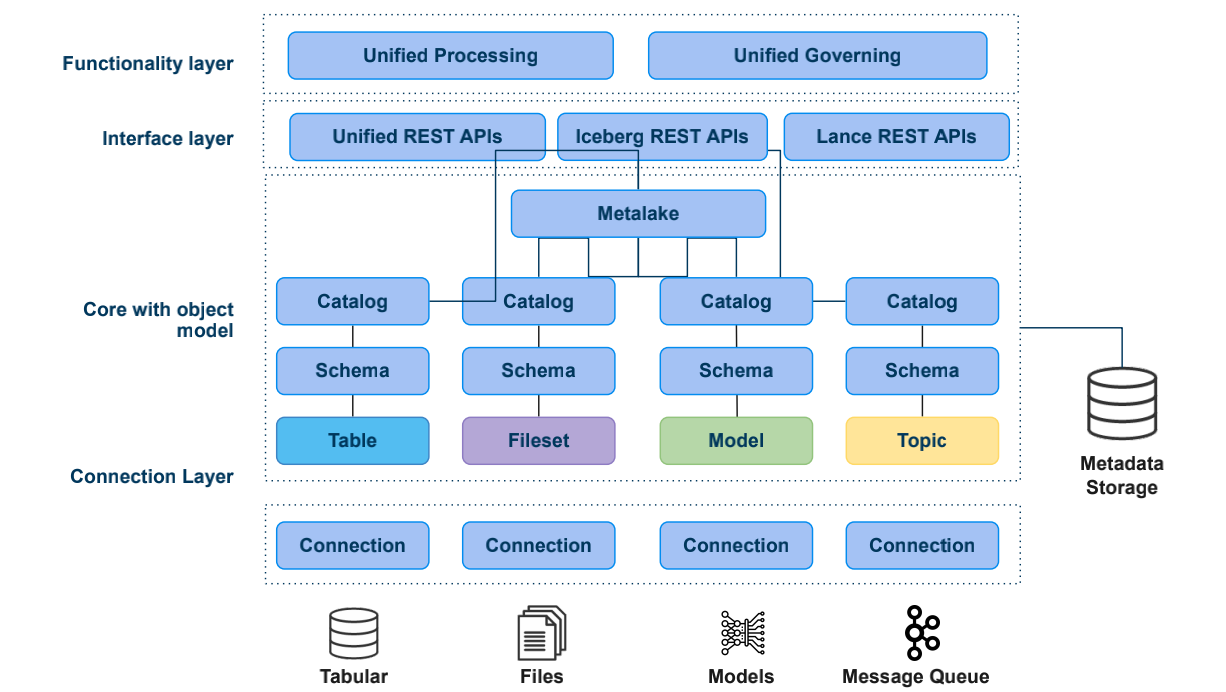
连接层 (Connection Layer):协议适配
这是最底层,负责与各种具体的存储实体建立物理连接。
- 它通过 Connection 对象屏蔽了不同底层存储(如 S3、HDFS、MySQL、Kafka 等)的协议差异。
- 涵盖四类核心资源: 表格(Tabular)、文件(Files)、模型(Models)以及消息队列(Message Queue)。
对象模型核心 (Core with Object Model):多级分层抽象
这是 Gravitino 最核心的逻辑设计,采用了一种类似多租户目录的层级结构:
- Metalake (元数据湖): 最高的逻辑单元,通常对应一个企业或一个独立的数据环境。
- Catalog (目录): 对应特定的数据源类型(如 Hive Catalog, Iceberg Catalog, Kafka Catalog)。
- Schema (架构/数据库): 逻辑分组,类似于传统数据库的 Database。
- 核心实体 (Entity): 这是 Gravitino 的精髓,它将所有资源抽象为四种标准化的实体(Table: 结构化数据。Fileset: 非结构化文件集。Model: AI 模型资产。Topic: 实时流数据。)
- Metadata Storage: 所有的这些层级关系、权限信息和属性都被记录在独立的元数据库中。
接口层 (Interface Layer):标准化通路
Gravitino 并没有发明一套完全封闭的协议,而是选择拥抱开放标准:
- Unified REST APIs: 提供 Gravitino 原生的管理接口。
- Iceberg / Lance REST APIs: 这一点非常关键。它通过实现这些开放协议的 Server 端,让现有的客户端(如 Spark、Flink、Trino)可以无缝、零代码修改地直接访问 Gravitino 管理的数据。
功能层 (Functionality Layer):价值转化
在这一层,统一后的元数据转化为实际的生产力:
- Unified Processing: 因为元数据统一了,所以可以做跨数据源的联合计算(如 SQL 关联 Fileset 元数据)。
- Unified Governing: 在这一层实现全局的 RBAC(基于角色的访问控制)、数据血缘以及安全审计。
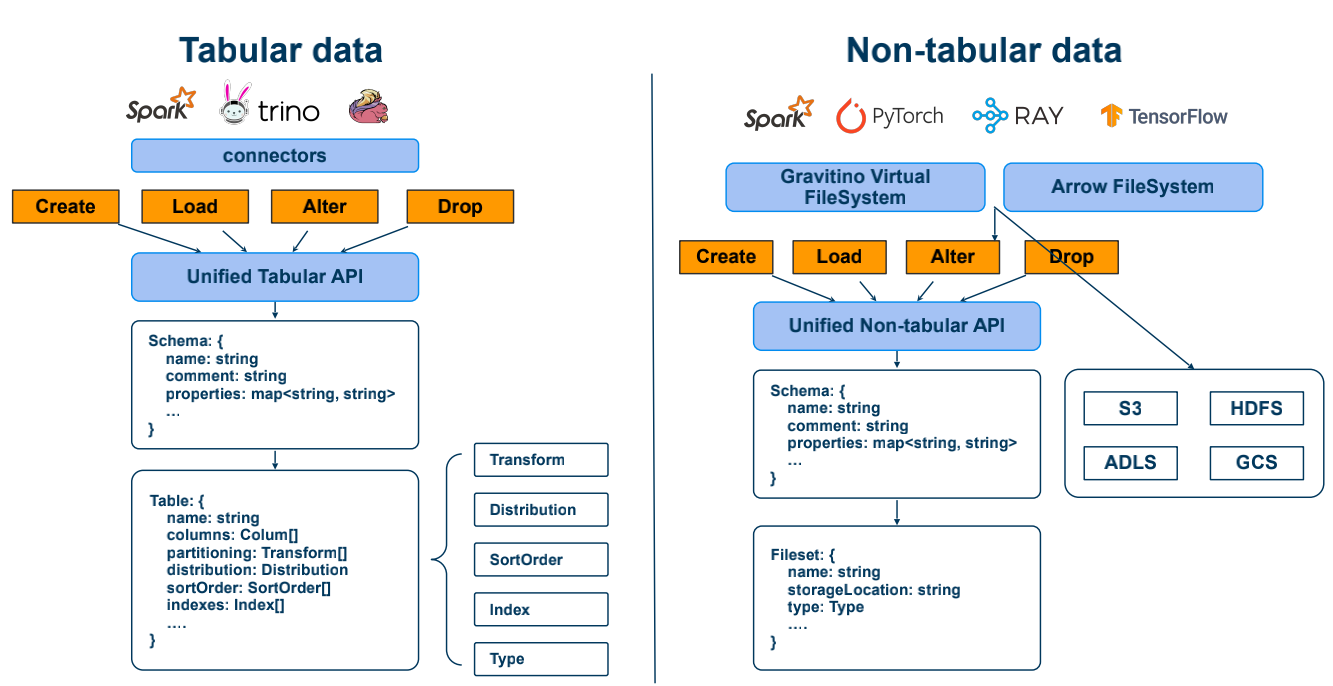
上图揭示了 Gravitino 如何通过统一的设计哲学,消除结构化与非结构化数据之间的管理鸿沟。它将传统的表格数据与现代 AI 所需的非结构化文件,共同抽象为一套标准化的 API 操作与多层级元数据模型(Schema/Table/Fileset),使开发者既能像管理数据库表一样精细化治理文件资源,又能通过虚拟文件系统(GVFS)让 PyTorch、Ray 等 AI 框架实现对底层异构存储的无感访问。这种设计不仅保障了跨计算引擎的一致性,更通过"位置透明"的Fileset抽象,为模型训练与 Agent 检索提供了规范化、资产化的知识获取路径,真正实现了大数据分析与 AI 数据处理的逻辑归一。
六、ScopeDB 云上实时数据分析
最后一个出场分享的是tison,tison是Apache软件基金会的现任董事,中国区只有一位,我看了下我关注的几个Apache项目,群里也都有tison老师的身影。
Rigid Schema vs. Schemaless
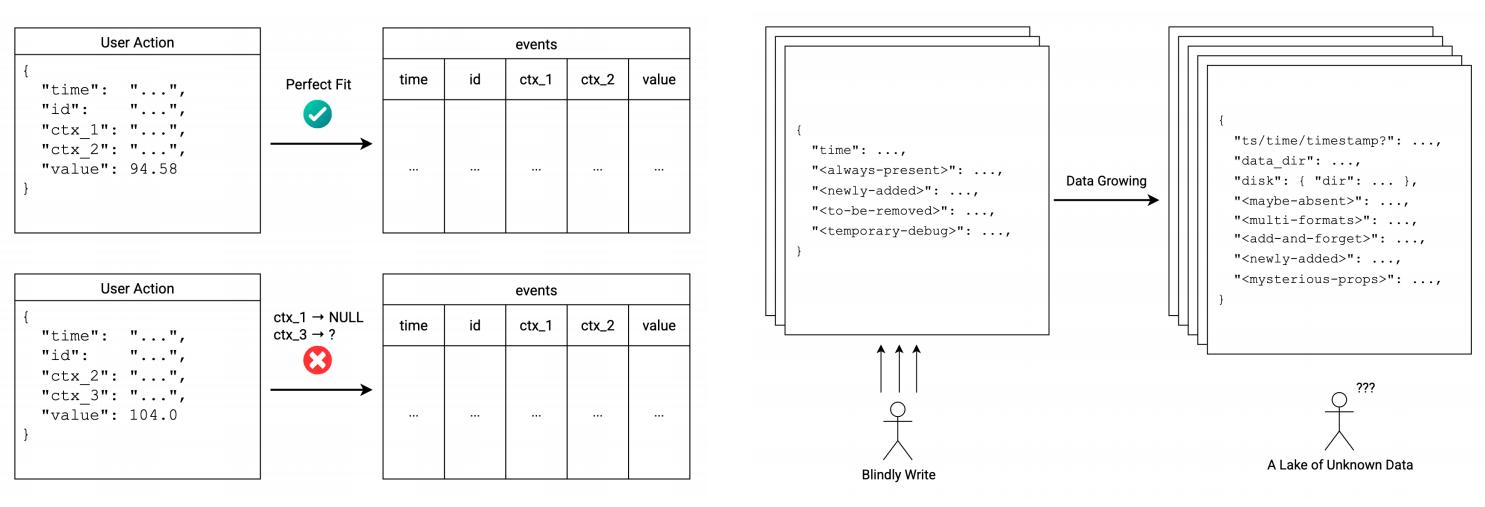
上图对比了"刚性模式"(Rigid Schema)与"无模式"(Schemaless)在数据存储中的根本差异:左侧展示了传统关系型数据库在处理结构化数据时,虽然对符合定义的完美数据(Perfect Fit)表现出色,但在遇到字段缺失或新增字段(如 ctx_3)时会产生兼容性冲突(NULL值或无法映射);而右侧则描述了无模式架构(常见于数据湖或NoSQL),它虽然允许通过"盲写"(Blindly Write)灵活接纳各种变化、新增或临时性的数据结构,但随之而来的代价是数据结构在不断增长中变得混乱且难以维护,最终演变成一个难以治理的"未知数据湖",也就是tison说的数据下水沟。
为了解决上述痛点,ScopeDB提出了一种新的数据存储模式------即时模式(Schema On The Fly)。
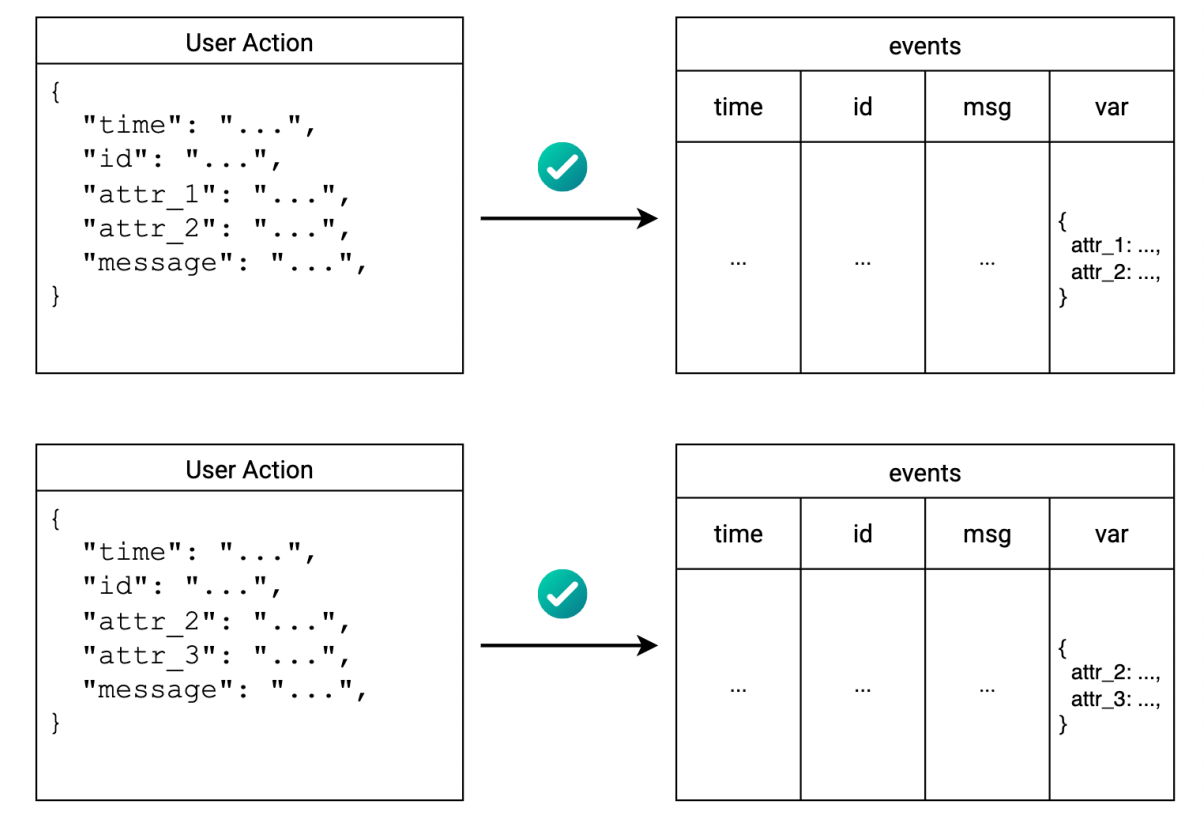
即时模式是一种解决数据结构多变性的有效策略,它不再强制要求所有写入数据遵循统一的严格列定义,而是通过将多变的属性或元数据打包进一个灵活的容器字段(如图中所示的 var 字段,通常采用 JSON 或键值对格式)来存入关系型或半结构化数据库。这种方法在处理如日志链路追踪、用户行为监测、A/B 测试参数或反欺诈特征等场景时极具优势,因为它允许系统在不变更底层物理存储模式的情况下,平滑地接纳不断演进的业务数据,从而在保持查询效率的同时兼顾了极高的灵活性与兼容性。
The Big Data Solution Is Not Cloud Native
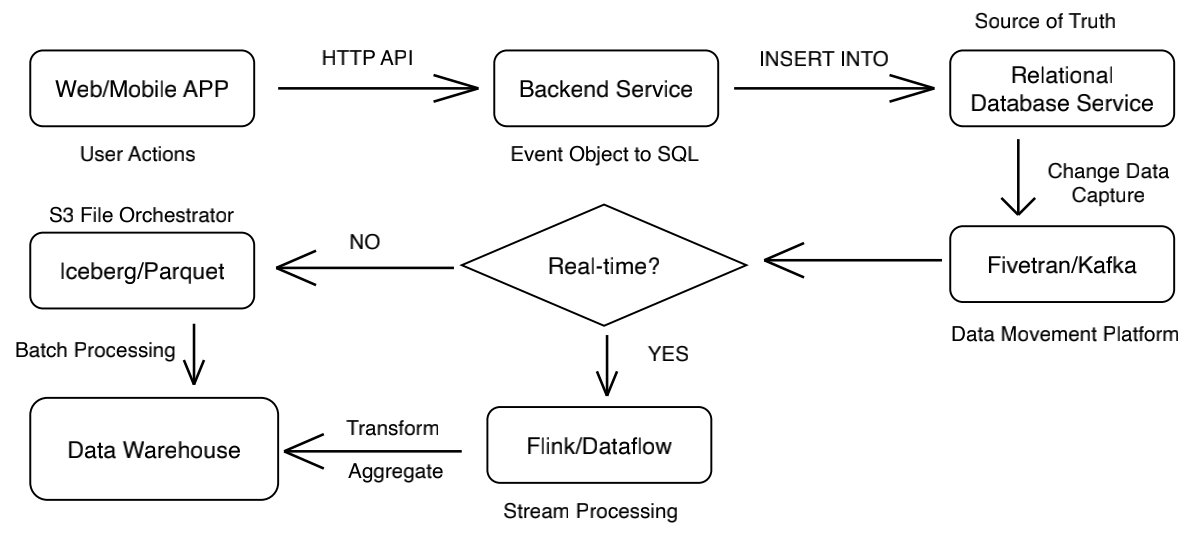
上面这张图典型的"非云原生"大数据架构的复杂性,其核心痛点在于数据并非直接从源头流入分析平台,而是必须先通过应用写入关系型数据库,再通过变更数据捕获(CDC)机制(如 Fivetran 或 Kafka)进行二次搬运,从而形成了繁琐的链路。这种架构不仅引入了额外的延迟和维护成本,还被迫根据"实时"与否的需求分叉出两条完全不同的技术栈:一条是依赖 S3 和批处理文件的冷数据路径,另一条则是依赖 Flink 或 Dataflow 等流处理引擎的热数据路径,这种割裂的架构模式 往往会导致数据一致性校验困难、基础设施资源冗余以及极高的运维复杂度,与追求敏捷、统一、直接数据接入的现代云原生架构理念背道而驰。
Language Integrated Cabel API
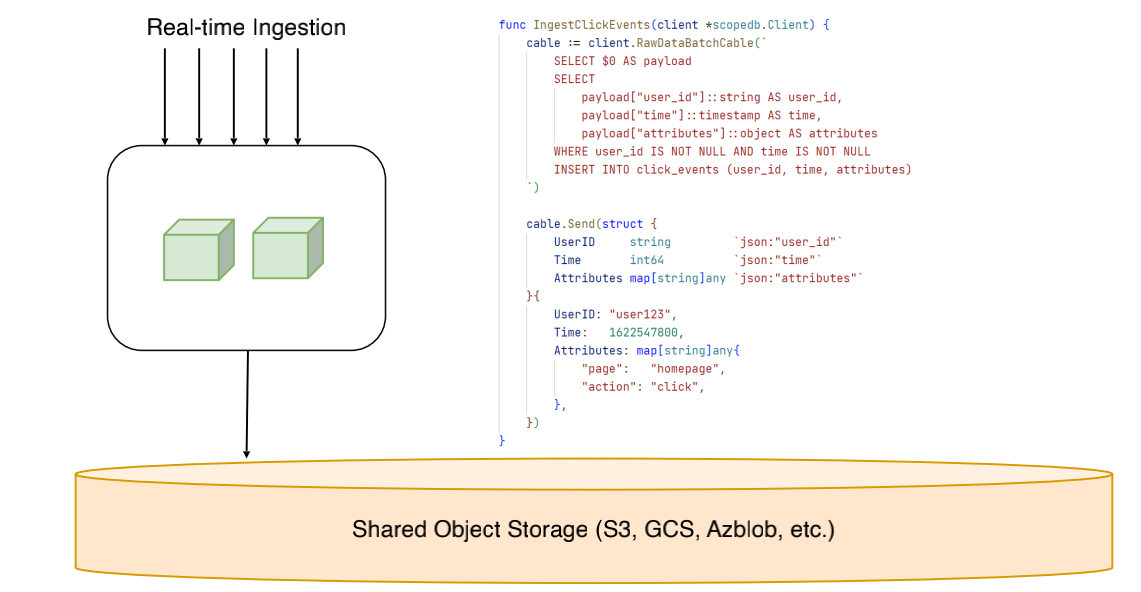
展示了 ScopeDB Language Integrated Cabel API 如何通过在应用程序代码中直接嵌入声明式逻辑来实现实时数据摄取,这种设计巧妙地将数据处理逻辑(如 SQL 选择、类型转换与过滤)与业务逻辑代码紧密绑定,从而省去了中间件(如 Kafka 或 Fivetran)的二次搬运环节。通过这种方式,开发者能够直接在代码中定义数据结构并执行实时写入操作,数据经过处理后直接进入共享对象存储(如 S3 或 GCS),不仅极大地简化了数据管道架构,还避免了传统数据迁移方案中常见的延迟和一致性问题,体现了云原生环境下"数据即代码"的简洁性。
但老周针对这种处理方式有不一样的想法:如果底层数据存储逻辑发生巨大变动,或者需要跨业务复用一套复杂的清洗规则时,代码的维护成本会急剧上升。在这种场景下,架构设计的关键在于权衡:如果是为了应对超大规模、极速写入的实时指标监控,这种"强绑定"可能是一种为了性能与效率而接受的必要之恶;但对于逻辑极其复杂且变动频繁的业务数据流,引入一层数据抽象层或配置中心(例如将转换规则定义为可动态更新的 Schema 定义文件而非硬编码在函数中)或许是平衡灵活性与耦合度的折中方案。
ScopeDB Architecture
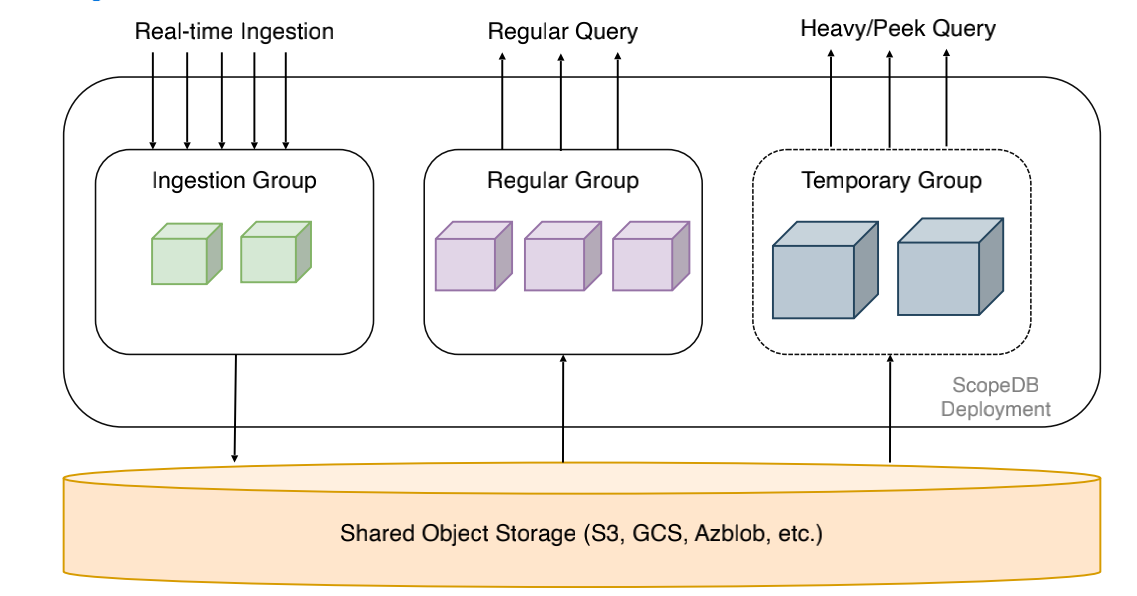
ScopeDB 如何通过计算与存储分离的架构,将不同类型的计算任务分配到专属的"工作组"中以实现资源隔离。系统明确划分了三个核心维度:负责实时写入的"摄取组"(Ingestion Group)、处理常规查询的"常规组"(Regular Group),以及针对复杂分析或大规模扫描任务的"临时组"(Temporary Group),所有这些算力节点都统一通过底层共享的对象存储(S3, GCS 等)进行数据交换。这种设计彻底摆脱了单体数据库中写入负载与复杂查询相互争抢内存和 CPU 资源的窘境,不仅确保了高并发实时入库的稳定性,还通过临时组实现了对大查询的弹性隔离,真正实现了分析负载与数据摄取负载的物理级解耦,从而在保障系统整体健壮性的同时,显著提升了资源调度的灵活性与利用率。
ScopeQL: A Fluent Query Language
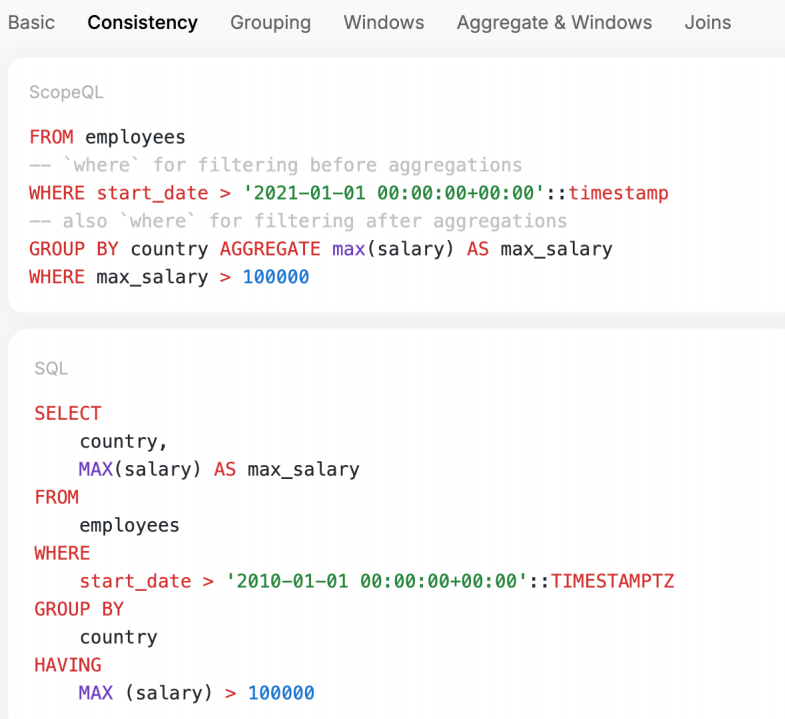
ScopeQL 的几个核心设计亮点包括:
- 读写路径统一: 这套语言不仅用于查询,也用于定义数据摄取时的处理逻辑,实现了"一套语义,两处使用"。
- 正交可组合性(Orthogonal Composability): 各个操作符(过滤、聚合、窗口函数)可以像搭积木一样自由组合,逻辑表达更加灵活。
- 原生表达式复用: 在 ScopeQL 中,你可以更自然地引用前一步生成的别名或计算结果,避免了在传统 SQL 中为了复用聚合结果而不得不写冗长子查询或 WITH 语句的尴尬。
- 关系代数基础: 尽管语法更"流畅(Fluent)",但其底层依然严谨地遵循关系代数,确保了优化的可行性和执行的确定性。
Fully Leverage Cloud Elasticity
- 瞬时弹性(Instant Elasticity): 当系统面临重负载(Heavy)或峰值(Peek)查询时,它可以秒级拉起临时的计算资源组,并在负载下降后自动释放(Scale-in)。由于数据本身存储在共享对象存储(如 S3 或 GCS)中,计算节点无需搬运数据即可直接读取,避免了漫长的数据迁移等待。
- 资源强隔离: 通过将不同类型的任务(如常规查询与重度分析)拆分到不同的计算资源组中,实现了"互不干扰",从根本上解决了传统单体集群中因为个别"大查询"拖垮整个系统(Noisy Neighbor)的问题。
- 可选的状态缓存: 虽然计算节点是无状态的,但系统支持可选的状态缓存(Stateful Caches),这在保持弹性的同时,能进一步加速对热点数据的访问速度,在灵活性与性能之间取得了巧妙平衡。
七、总结
一个下午的分享,老周也说说自己的一些想法。活动举办是在龙华,这也是我第一次去龙华参加活动,之前都是在南山,也是不一样的活动体验吧。
在 AI Agent 时代,数据领域正面临从"被动存储"向"主动即时决策"的范式转移,老周认为这也带来了诸多挑战:
- 多模态数据的深度整合能力:AI Agent 不仅需要处理传统的结构化数据,更需要实时理解并关联非结构化的日志、文档、图像甚至视频数据,这对系统的语义理解和多源数据融合提出了极高要求;
- 动态架构的自适应性:如 ScopeDB 所展示的,业务逻辑的快速迭代要求数据库具备极强的 schema 灵活性和索引自适应能力,否则 Agent 无法在面对不断变化的数据源时保持高效查询;
- 时延与计算效率的博弈:AI Agent 往往运行在以毫秒计的交互场景下,如何在处理海量数据流的同时通过物化索引或缓存来满足 Agent 的即时推理需求,是性能优化的关键;
- 上下文管理的复杂性:Agent 需要在海量历史数据中精准定位、提取并整合出最相关的上下文,这需要更智能的数据检索与索引机制。
好了,这次活动的全部内容都在这里了,期待下次的Data For AI活动再次来深圳,我们下期再见。