目录
-
- 热门文章推荐
- 摘要
- [1. 引言 - Skills 进阶开发的意义](#1. 引言 - Skills 进阶开发的意义)
-
- [1.1 为什么需要高级 Skills 开发?](#1.1 为什么需要高级 Skills 开发?)
- [1.2 Skills 系统的核心价值](#1.2 Skills 系统的核心价值)
- [2. SKILL.md 深度解析 - 结构、指令、变量](#2. SKILL.md 深度解析 - 结构、指令、变量)
- [3. 高级技能模式 - 多文件技能、外部依赖](#3. 高级技能模式 - 多文件技能、外部依赖)
-
- [3.1 多文件技能架构设计](#3.1 多文件技能架构设计)
- [3.2 外部依赖管理](#3.2 外部依赖管理)
- [3.3 安装器配置](#3.3 安装器配置)
- [4. 技能配置管理 - skills.yaml 配置](#4. 技能配置管理 - skills.yaml 配置)
-
- [4.1 配置文件结构](#4.1 配置文件结构)
- [4.2 配置优先级与覆盖规则](#4.2 配置优先级与覆盖规则)
- [4.3 环境变量注入机制](#4.3 环境变量注入机制)
- [4.4 沙箱环境中的配置处理](#4.4 沙箱环境中的配置处理)
- [5. 技能调试技巧 - 日志、测试、错误处理](#5. 技能调试技巧 - 日志、测试、错误处理)
-
- [5.1 调试模式启用](#5.1 调试模式启用)
- [5.2 技能测试策略](#5.2 技能测试策略)
- [5.3 错误处理最佳实践](#5.3 错误处理最佳实践)
- [5.4 日志记录规范](#5.4 日志记录规范)
- [6. 实战案例 - 开发一个完整的复杂技能](#6. 实战案例 - 开发一个完整的复杂技能)
- [7. 总结](#7. 总结)
- [8. 参考资料](#8. 参考资料)
热门文章推荐
OpenClaw 浏览器自动化实战
OpenClaw 多模型配置与切换详解
摘要
OpenClaw Skills 是扩展 AI 智能体能力的核心机制,通过声明式的 SKILL.md 文件定义智能体的行为模式和工具使用方式。本文深入探讨 Skills 的高级开发技术,包括多文件技能架构设计、外部依赖管理、门控过滤机制、配置注入策略以及调试最佳实践。文章通过详细的代码示例和架构图,展示如何构建生产级别的复杂技能,帮助开发者掌握从简单技能到企业级技能系统的进阶之路。无论是构建个人效率工具还是团队协作平台,本文都将为读者提供全面的技术指导和实战经验。🎯
1. 引言 - Skills 进阶开发的意义
1.1 为什么需要高级 Skills 开发?
在 AI 智能体快速发展的今天,简单的提示词工程已经无法满足复杂业务场景的需求。OpenClaw Skills 系统提供了一套完整的扩展机制,让开发者能够:
- 封装复杂逻辑:将多步骤操作封装为可复用的技能模块
- 管理外部依赖:优雅地处理 API 密钥、二进制工具、环境变量等资源
- 实现条件加载:根据运行环境动态启用或禁用特定功能
- 构建可维护系统:通过模块化设计提升代码质量和团队协作效率
1.2 Skills 系统的核心价值
OpenClaw Skills 采用 AgentSkills 兼容规范,这意味着:
Skills 系统
标准化接口
可移植性
生态共享
SKILL.md 规范
YAML Frontmatter
Markdown 指令
跨平台兼容
版本管理
依赖隔离
ClawHub 市场
社区贡献
最佳实践
Skills 的核心价值在于将能力定义 与能力实现分离,让 AI 智能体能够像人类学习新技能一样,通过"阅读说明书"来掌握新工具的使用方法。这种设计理念使得技能可以独立开发、测试、分发和更新,极大地提升了 AI 应用的可扩展性。🚀
2. SKILL.md 深度解析 - 结构、指令、变量
2.1 SKILL.md 完整结构剖析
SKILL.md 是每个技能的核心定义文件,由 YAML frontmatter 和 Markdown 正文两部分组成。一个完整的 SKILL.md 结构如下:
markdown
---
name: skill-name
description: 简洁描述技能功能
homepage: https://example.com
user-invocable: true
disable-model-invocation: false
command-dispatch: tool
command-tool: custom-tool-name
command-arg-mode: raw
metadata:
{
"openclaw": {
"requires": { "bins": ["required-cli"], "env": ["API_KEY"], "config": ["feature.enabled"] },
"primaryEnv": "API_KEY",
"os": ["darwin", "linux"],
"emoji": "🔧",
"install": [...]
}
}
---
# 技能标题
详细的技能使用说明...2.2 Frontmatter 字段详解
下表列出了所有可用的 frontmatter 字段及其用途:
| 字段 | 类型 | 默认值 | 说明 |
|---|---|---|---|
name |
string | 必填 | 技能唯一标识符,建议使用 kebab-case 命名 |
description |
string | 必填 | 技能功能描述,用于智能体匹配和用户展示 |
homepage |
string | 可选 | 技能主页 URL,在 macOS UI 中显示 |
user-invocable |
boolean | true | 是否作为用户斜杠命令暴露 |
disable-model-invocation |
boolean | false | 是否从模型提示词中排除 |
command-dispatch |
string | 可选 | 设置为 tool 时斜杠命令直接调度到工具 |
command-tool |
string | 可选 | 工具调度时的目标工具名称 |
command-arg-mode |
string | raw | 参数传递模式 |
metadata |
object | 可选 | OpenClaw 特定配置,必须是单行 JSON |
2.3 高级指令编写技巧
SKILL.md 的正文部分是给 AI 智能体的"操作手册"。编写高质量指令的关键原则:
原则一:明确触发条件
markdown
# 天气查询技能
当用户询问以下内容时激活此技能:
- 当前天气情况
- 未来几天的天气预报
- 特定城市的气温、降水等气象信息
不要在以下情况使用此技能:
- 历史天气数据查询
- 极端天气预警(请使用 weather-alert 技能)原则二:提供具体操作步骤
markdown
## 使用步骤
1. 首先确认用户询问的城市名称
2. 如果城市名称不明确,主动询问用户
3. 使用 weather-api 工具获取天气数据
4. 将数据格式化为用户友好的文本输出
5. 如果 API 返回错误,提供备用的 wttr.in 方案原则三:使用变量占位符
SKILL.md 支持特殊的变量占位符,最常用的是 {baseDir}:
markdown
## 资源文件
此技能依赖以下资源文件:
- 配置模板:{baseDir}/templates/config.yaml
- 示例数据:{baseDir}/examples/sample.json
在执行时,请使用 `{baseDir}` 变量引用技能目录路径。2.4 Metadata 高级配置
metadata.openclaw 对象提供了强大的门控和配置能力:
metadata.openclaw
门控条件
环境配置
安装器
UI 配置
requires.bins
requires.env
requires.config
requires.anyBins
os
always
primaryEnv
skillKey
brew 安装器
node 安装器
go 安装器
download 安装器
emoji
homepage
3. 高级技能模式 - 多文件技能、外部依赖
3.1 多文件技能架构设计
对于复杂技能,单一 SKILL.md 文件往往难以维护。OpenClaw 支持多文件技能架构,允许将功能拆分为多个模块:
my-complex-skill/
├── SKILL.md # 主入口文件
├── lib/
│ ├── helpers.py # 辅助函数库
│ ├── api_client.py # API 客户端封装
│ └── validators.py # 输入验证器
├── templates/
│ ├── report.md # 报告模板
│ └── email.html # 邮件模板
├── config/
│ └── defaults.yaml # 默认配置
├── examples/
│ └── sample.json # 示例数据
└── tests/
└── test_helpers.py # 单元测试在 SKILL.md 中引用这些文件:
markdown
---
name: my-complex-skill
description: 一个复杂的多文件技能示例
metadata:
{
"openclaw": {
"requires": { "bins": ["python3"], "env": ["MY_API_KEY"] }
}
}
---
# 复杂技能使用指南
## 文件结构
此技能包含以下模块:
- **lib/helpers.py**: 通用辅助函数,使用 `{baseDir}/lib/helpers.py` 引用
- **lib/api_client.py**: API 客户端,处理认证和请求
- **templates/**: 输出模板目录
## 执行流程
1. 加载配置:`python3 {baseDir}/lib/helpers.py --config {baseDir}/config/defaults.yaml`
2. 调用 API:`python3 {baseDir}/lib/api_client.py --key $MY_API_KEY`
3. 生成报告:使用 `{baseDir}/templates/report.md` 模板3.2 外部依赖管理
OpenClaw Skills 可以声明对二进制工具、环境变量和配置项的依赖:
二进制依赖 (bins)
markdown
---
metadata:
{
"openclaw": {
"requires": { "bins": ["ffmpeg", "ffprobe"] }
}
}
---当技能被加载时,OpenClaw 会检查 ffmpeg 和 ffprobe 是否存在于系统 PATH 中。如果不存在,该技能将被过滤掉。
环境变量依赖 (env)
markdown
---
metadata:
{
"openclaw": {
"requires": { "env": ["OPENAI_API_KEY", "ANTHROPIC_API_KEY"] }
}
}
---环境变量可以通过两种方式提供:
- 系统环境变量(export OPENAI_API_KEY=xxx)
- 配置文件注入(skills.entries..env)
配置依赖 (config)
markdown
---
metadata:
{
"openclaw": {
"requires": { "config": ["browser.enabled", "sandbox.enabled"] }
}
}
---这要求 ~/.openclaw/openclaw.json 中对应的配置项为真值。
3.3 安装器配置
对于需要安装外部工具的技能,可以配置自动安装器:
markdown
---
name: gemini
description: Use Gemini CLI for coding assistance
metadata:
{
"openclaw": {
"requires": { "bins": ["gemini"] },
"install": [
{
"id": "brew",
"kind": "brew",
"formula": "gemini-cli",
"bins": ["gemini"],
"label": "Install Gemini CLI (brew)"
},
{
"id": "npm",
"kind": "node",
"package": "@google/gemini-cli",
"bins": ["gemini"],
"label": "Install Gemini CLI (npm)"
}
]
}
}
---安装器类型及配置如下表所示:
| 安装器类型 | 必填字段 | 可选字段 | 说明 |
|---|---|---|---|
brew |
formula |
bins, label |
Homebrew 包管理器 |
node |
package |
bins, label |
npm/pnpm/yarn/bun |
go |
package |
bins, label |
Go 模块 |
download |
url |
archive, extract, targetDir |
直接下载 |
4. 技能配置管理 - skills.yaml 配置
4.1 配置文件结构
OpenClaw 的主配置文件位于 ~/.openclaw/openclaw.json,所有 Skills 相关配置都在 skills 键下:
json5
{
skills: {
// 内置技能白名单
allowBundled: ["gemini", "peekaboo"],
// 加载配置
load: {
extraDirs: ["~/Projects/my-skills"],
watch: true,
watchDebounceMs: 250,
},
// 安装配置
install: {
preferBrew: true,
nodeManager: "npm",
},
// 单技能配置
entries: {
"my-api-skill": {
enabled: true,
apiKey: "sk-xxxxx",
env: {
MY_API_KEY: "sk-xxxxx",
DEBUG: "true",
},
config: {
endpoint: "https://api.example.com",
timeout: 30000,
},
},
},
},
}4.2 配置优先级与覆盖规则
enabled: false
enabled: true 或未设置
不存在
存在
缺少环境变量
是
否
存在
配置项为真
配置项为假
技能配置加载
技能是否启用?
跳过该技能
检查门控条件
bins 检查
技能不可用
env 检查
配置文件是否提供?
注入环境变量
config 检查
技能可用
加入技能快照
4.3 环境变量注入机制
当智能体运行开始时,OpenClaw 会执行以下环境变量注入流程:
python
# 伪代码示例:环境变量注入逻辑
def inject_skill_environment(skill_name, config):
"""为技能注入环境变量"""
skill_config = config.skills.entries.get(skill_name, {})
# 1. 注入 env 字段中的所有变量
for key, value in skill_config.get('env', {}).items():
if key not in os.environ: # 只在未设置时注入
os.environ[key] = value
# 2. 如果定义了 primaryEnv,注入 apiKey
primary_env = skill_metadata.get('primaryEnv')
if primary_env and 'apiKey' in skill_config:
if primary_env not in os.environ:
os.environ[primary_env] = skill_config['apiKey']
# 3. 运行结束后恢复原始环境
# (由 OpenClaw 运行时自动处理)这段代码展示了环境变量注入的核心逻辑。关键点在于:
- 非覆盖原则:已存在的环境变量不会被覆盖
- 作用域限定:注入仅在智能体运行期间有效
- 安全隔离:敏感信息不会泄露到提示词或日志中
4.4 沙箱环境中的配置处理
当智能体运行在沙箱(Docker)环境中时,配置处理有所不同:
json5
// 沙箱环境配置示例
{
agents: {
defaults: {
sandbox: {
docker: {
env: {
MY_API_KEY: "sk-xxxxx", // 直接注入到容器
DEBUG: "true",
},
},
},
},
},
}重要提示 :沙箱容器不会继承宿主机的环境变量,必须通过 docker.env 显式配置或使用自定义镜像。
5. 技能调试技巧 - 日志、测试、错误处理
5.1 调试模式启用
OpenClaw 提供了多种调试方式:
命令行调试
bash
# 启用详细日志
openclaw gateway start --verbose
# 测试特定技能
openclaw agent --message "测试我的技能" --skill my-skill
# 检查技能加载状态
openclaw skills list配置文件调试
json5
{
skills: {
load: {
watch: true, // 启用热重载
watchDebounceMs: 250,
},
},
logging: {
level: "debug",
},
}5.2 技能测试策略
为技能编写测试是保证质量的关键。以下是推荐的测试结构:
python
# tests/test_skill.py
import os
import json
import subprocess
from pathlib import Path
class TestMySkill:
"""技能测试套件"""
@classmethod
def setup_class(cls):
"""测试前准备"""
cls.skill_dir = Path(__file__).parent.parent
cls.skill_md = cls.skill_dir / "SKILL.md"
def test_skill_md_exists(self):
"""测试 SKILL.md 文件存在"""
assert self.skill_md.exists(), "SKILL.md 文件不存在"
def test_skill_md_frontmatter(self):
"""测试 frontmatter 格式正确"""
content = self.skill_md.read_text()
assert content.startswith("---"), "缺少 YAML frontmatter"
# 解析 frontmatter
parts = content.split("---", 2)
frontmatter = yaml.safe_load(parts[1])
assert "name" in frontmatter, "缺少 name 字段"
assert "description" in frontmatter, "缺少 description 字段"
def test_skill_dependencies(self):
"""测试依赖是否满足"""
# 检查二进制依赖
required_bins = ["python3", "curl"]
for bin_name in required_bins:
result = subprocess.run(
["which", bin_name],
capture_output=True
)
assert result.returncode == 0, f"缺少二进制依赖: {bin_name}"
def test_skill_execution(self):
"""测试技能执行"""
# 模拟技能调用
result = subprocess.run(
["python3", f"{self.skill_dir}/lib/main.py", "--test"],
capture_output=True,
text=True
)
assert result.returncode == 0, f"执行失败: {result.stderr}"5.3 错误处理最佳实践
在 SKILL.md 中定义清晰的错误处理策略:
markdown
## 错误处理
### 常见错误及处理方式
1. **API 密钥无效**
- 错误信息:`Authentication failed`
- 处理方式:提示用户检查 API 密钥配置
- 备选方案:使用免费的公共 API
2. **网络连接失败**
- 错误信息:`Connection timeout`
- 处理方式:自动重试 3 次,每次间隔 2 秒
- 备选方案:使用本地缓存数据
3. **资源不存在**
- 错误信息:`Resource not found`
- 处理方式:提供相似资源列表供用户选择
### 错误恢复流程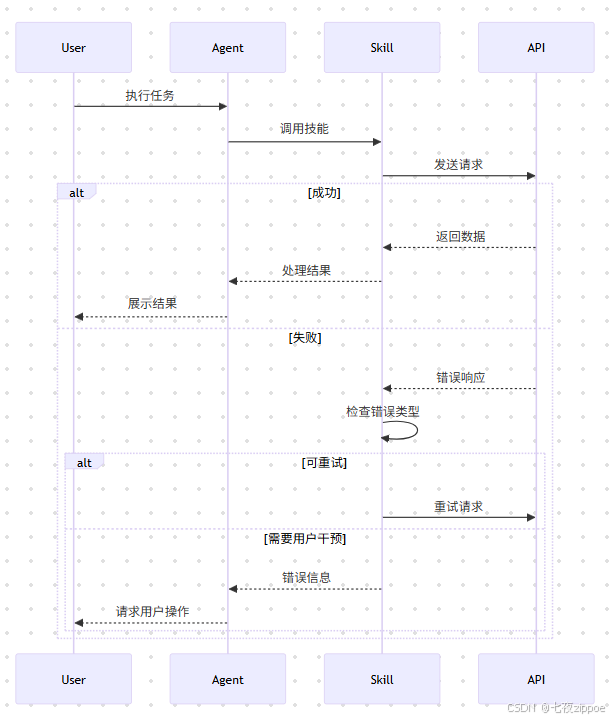
5.4 日志记录规范
为技能添加结构化日志:
python
# lib/logger.py
import logging
import json
from datetime import datetime
class SkillLogger:
"""技能专用日志记录器"""
def __init__(self, skill_name):
self.logger = logging.getLogger(skill_name)
self.skill_name = skill_name
def log(self, level, message, **kwargs):
"""结构化日志输出"""
log_entry = {
"timestamp": datetime.utcnow().isoformat(),
"skill": self.skill_name,
"level": level,
"message": message,
**kwargs
}
self.logger.log(
getattr(logging, level.upper()),
json.dumps(log_entry)
)
def info(self, message, **kwargs):
self.log("INFO", message, **kwargs)
def error(self, message, **kwargs):
self.log("ERROR", message, **kwargs)
def debug(self, message, **kwargs):
self.log("DEBUG", message, **kwargs)6. 实战案例 - 开发一个完整的复杂技能
6.1 需求分析
让我们开发一个"智能代码审查"技能,功能包括:
- 分析代码质量
- 检测安全漏洞
- 生成改进建议
- 输出结构化报告
6.2 技能目录结构
code-reviewer/
├── SKILL.md
├── lib/
│ ├── __init__.py
│ ├── analyzer.py # 代码分析核心
│ ├── security.py # 安全检查模块
│ ├── reporter.py # 报告生成器
│ └── logger.py # 日志模块
├── templates/
│ ├── report.md.j2 # Markdown 报告模板
│ └── report.html.j2 # HTML 报告模板
├── config/
│ └── rules.yaml # 检查规则配置
├── examples/
│ └── sample.py # 示例代码
└── tests/
├── test_analyzer.py
└── test_security.py6.3 SKILL.md 完整实现
markdown
---
name: code-reviewer
description: 智能代码审查技能,支持质量分析、安全检测和改进建议生成
homepage: https://github.com/example/code-reviewer
user-invocable: true
metadata:
{
"openclaw": {
"requires": {
"bins": ["python3"],
"env": ["OPENAI_API_KEY"],
"anyBins": ["git", "hg"]
},
"primaryEnv": "OPENAI_API_KEY",
"emoji": "🔍",
"os": ["darwin", "linux"],
"install": [
{
"id": "pip",
"kind": "download",
"url": "https://example.com/code-reviewer.tar.gz",
"archive": "tar.gz",
"bins": ["code-reviewer"]
}
]
}
}
---
# 智能代码审查技能 🔍
## 功能概述
此技能为代码提供全面的智能审查服务,包括:
- **代码质量分析**:检测代码异味、复杂度问题、重复代码
- **安全漏洞扫描**:识别常见安全漏洞如 SQL 注入、XSS 等
- **改进建议生成**:基于最佳实践提供具体的代码改进建议
- **多格式报告输出**:支持 Markdown 和 HTML 格式的审查报告
## 触发条件
当用户请求以下操作时,激活此技能:
- "审查这段代码"
- "检查代码质量"
- "分析代码安全性"
- "生成代码审查报告"
## 使用方式
### 1. 审查文件
请审查文件 src/main.py
### 2. 审查目录
请审查 src/ 目录下的所有 Python 文件
### 3. 审查 Git 变更
请审查最近一次提交的代码变更
## 执行流程
1. **输入验证**:确认目标路径或 Git 引用有效
2. **代码收集**:读取目标代码文件或 Git diff
3. **静态分析**:运行本地静态分析工具
4. **AI 增强**:使用 LLM 进行深度分析
5. **报告生成**:整合结果并生成报告
## 资源引用
- 分析脚本:`{baseDir}/lib/analyzer.py`
- 安全规则:`{baseDir}/config/rules.yaml`
- 报告模板:`{baseDir}/templates/report.md.j2`
## 错误处理
| 错误类型 | 处理方式 |
|---------|---------|
| 文件不存在 | 提示用户检查路径 |
| 不支持的文件类型 | 跳过并记录警告 |
| API 限流 | 等待后重试,最多 3 次 |
| 内存不足 | 分批处理大文件 |
## 配置选项
用户可在 `~/.openclaw/openclaw.json` 中配置:
{
"skills": {
"entries": {
"code-reviewer": {
"config": {
"maxFileSize": 1048576,
"excludePatterns": ["*.min.js", "vendor/*"],
"severity": "medium"
}
}
}
}
}6.4 核心代码实现
以下是代码分析器的核心实现:
python
# lib/analyzer.py
"""
代码分析核心模块
负责执行静态代码分析并收集质量指标
"""
import os
import ast
import json
import subprocess
from pathlib import Path
from dataclasses import dataclass, asdict
from typing import List, Dict, Optional, Set
from concurrent.futures import ThreadPoolExecutor
from .logger import SkillLogger
logger = SkillLogger("code-reviewer")
@dataclass
class CodeIssue:
"""代码问题数据结构"""
file_path: str
line_number: int
column: int
severity: str # critical, high, medium, low, info
category: str # security, quality, style, complexity
message: str
suggestion: str
rule_id: str
@dataclass
class AnalysisResult:
"""分析结果数据结构"""
files_analyzed: int
total_issues: int
issues_by_severity: Dict[str, int]
issues_by_category: Dict[str, int]
issues: List[CodeIssue]
metrics: Dict[str, any]
class CodeAnalyzer:
"""
代码分析器主类
支持多种编程语言的静态分析,包括:
- Python (pylint, bandit)
- JavaScript (eslint)
- Go (golint, go vet)
"""
SUPPORTED_EXTENSIONS = {
'.py': 'python',
'.js': 'javascript',
'.ts': 'typescript',
'.go': 'go',
'.java': 'java',
}
def __init__(self, config: Optional[Dict] = None):
"""初始化分析器"""
self.config = config or {}
self.max_file_size = self.config.get('maxFileSize', 1048576)
self.exclude_patterns = self.config.get('excludePatterns', [])
self.min_severity = self.config.get('severity', 'low')
logger.info("CodeAnalyzer initialized", config=self.config)
def analyze_path(self, path: str) -> AnalysisResult:
"""
分析指定路径下的所有代码文件
Args:
path: 文件或目录路径
Returns:
AnalysisResult: 包含所有分析结果的对象
"""
path = Path(path)
if not path.exists():
raise FileNotFoundError(f"路径不存在: {path}")
# 收集所有待分析文件
files = self._collect_files(path)
logger.info(f"Collected {len(files)} files for analysis")
# 并行分析文件
with ThreadPoolExecutor(max_workers=4) as executor:
results = list(executor.map(self._analyze_file, files))
# 合并结果
return self._merge_results(results)
def _collect_files(self, path: Path) -> List[Path]:
"""收集所有待分析的代码文件"""
files = []
if path.is_file():
if self._should_analyze(path):
files.append(path)
else:
for ext, lang in self.SUPPORTED_EXTENSIONS.items():
files.extend(
f for f in path.rglob(f'*{ext}')
if self._should_analyze(f)
)
return files
def _should_analyze(self, file_path: Path) -> bool:
"""判断文件是否应该被分析"""
# 检查文件大小
if file_path.stat().st_size > self.max_file_size:
logger.debug(f"Skipping large file: {file_path}")
return False
# 检查排除模式
file_str = str(file_path)
for pattern in self.exclude_patterns:
if pattern in file_str:
logger.debug(f"Skipping excluded file: {file_path}")
return False
# 检查文件扩展名
return file_path.suffix in self.SUPPORTED_EXTENSIONS
def _analyze_file(self, file_path: Path) -> List[CodeIssue]:
"""分析单个文件"""
language = self.SUPPORTED_EXTENSIONS[file_path.suffix]
logger.debug(f"Analyzing {file_path} as {language}")
issues = []
# 根据语言选择分析器
if language == 'python':
issues.extend(self._analyze_python(file_path))
elif language in ('javascript', 'typescript'):
issues.extend(self._analyze_javascript(file_path))
elif language == 'go':
issues.extend(self._analyze_go(file_path))
return issues
def _analyze_python(self, file_path: Path) -> List[CodeIssue]:
"""Python 代码分析"""
issues = []
try:
# AST 分析
with open(file_path, 'r', encoding='utf-8') as f:
source = f.read()
tree = ast.parse(source)
# 检测复杂度问题
for node in ast.walk(tree):
if isinstance(node, (ast.FunctionDef, ast.AsyncFunctionDef)):
complexity = self._calculate_complexity(node)
if complexity > 10:
issues.append(CodeIssue(
file_path=str(file_path),
line_number=node.lineno,
column=node.col_offset,
severity='medium',
category='complexity',
message=f'函数复杂度过高 ({complexity})',
suggestion='考虑将函数拆分为更小的函数',
rule_id='PY001'
))
# 运行 bandit 安全检查
issues.extend(self._run_bandit(file_path))
except SyntaxError as e:
issues.append(CodeIssue(
file_path=str(file_path),
line_number=e.lineno or 0,
column=e.offset or 0,
severity='critical',
category='quality',
message=f'语法错误: {e.msg}',
suggestion='修复语法错误后重新分析',
rule_id='PY000'
))
return issues
def _calculate_complexity(self, node: ast.AST) -> int:
"""计算圈复杂度"""
complexity = 1
for child in ast.walk(node):
if isinstance(child, (ast.If, ast.While, ast.For, ast.ExceptHandler)):
complexity += 1
elif isinstance(child, ast.BoolOp):
complexity += len(child.values) - 1
return complexity
def _run_bandit(self, file_path: Path) -> List[CodeIssue]:
"""运行 bandit 安全检查"""
issues = []
try:
result = subprocess.run(
['bandit', '-f', 'json', str(file_path)],
capture_output=True,
text=True,
timeout=30
)
if result.returncode != 0 and result.stdout:
data = json.loads(result.stdout)
for item in data.get('results', []):
issues.append(CodeIssue(
file_path=str(file_path),
line_number=item.get('line_number', 0),
column=0,
severity=self._map_bandit_severity(item.get('issue_severity')),
category='security',
message=item.get('issue_text', ''),
suggestion=item.get('more_info', ''),
rule_id=item.get('test_id', '')
))
except Exception as e:
logger.error(f"Bandit analysis failed: {e}")
return issues
def _map_bandit_severity(self, severity: str) -> str:
"""映射 bandit 严重级别"""
mapping = {'HIGH': 'high', 'MEDIUM': 'medium', 'LOW': 'low'}
return mapping.get(severity, 'info')
def _analyze_javascript(self, file_path: Path) -> List[CodeIssue]:
"""JavaScript/TypeScript 代码分析"""
# 实现类似 Python 分析的逻辑
# 使用 eslint 进行检查
pass
def _analyze_go(self, file_path: Path) -> List[CodeIssue]:
"""Go 代码分析"""
# 使用 go vet 和 golint 进行检查
pass
def _merge_results(self, results: List[List[CodeIssue]]) -> AnalysisResult:
"""合并所有分析结果"""
all_issues = []
for file_issues in results:
all_issues.extend(file_issues)
# 统计问题分布
issues_by_severity = {}
issues_by_category = {}
for issue in all_issues:
issues_by_severity[issue.severity] = issues_by_severity.get(issue.severity, 0) + 1
issues_by_category[issue.category] = issues_by_category.get(issue.category, 0) + 1
return AnalysisResult(
files_analyzed=len(results),
total_issues=len(all_issues),
issues_by_severity=issues_by_severity,
issues_by_category=issues_by_category,
issues=all_issues,
metrics={
'avg_issues_per_file': len(all_issues) / max(len(results), 1)
}
)这段代码实现了一个完整的代码分析器,包含以下关键特性:
-
多语言支持 :通过
SUPPORTED_EXTENSIONS字典定义支持的编程语言,使用策略模式根据文件扩展名选择对应的分析器。 -
并行处理 :使用
ThreadPoolExecutor实现多线程并行分析,显著提升大规模代码库的分析效率。 -
复杂度计算:通过 AST 遍历计算函数的圈复杂度,当复杂度超过阈值时生成警告。
-
安全检查集成 :调用
bandit工具进行 Python 代码的安全漏洞扫描,将结果统一转换为CodeIssue对象。 -
灵活配置:支持通过配置文件自定义文件大小限制、排除模式和严重级别阈值。
6.5 报告生成器实现
python
# lib/reporter.py
"""
报告生成模块
负责将分析结果转换为可读的报告格式
"""
import os
from pathlib import Path
from datetime import datetime
from typing import Dict, List, Optional
from jinja2 import Environment, FileSystemLoader
from .analyzer import AnalysisResult, CodeIssue
from .logger import SkillLogger
logger = SkillLogger("code-reviewer")
class ReportGenerator:
"""
报告生成器
支持多种输出格式:
- Markdown (.md)
- HTML (.html)
- JSON (.json)
"""
def __init__(self, template_dir: Optional[str] = None):
"""
初始化报告生成器
Args:
template_dir: 模板目录路径,默认使用内置模板
"""
if template_dir:
self.template_dir = Path(template_dir)
else:
self.template_dir = Path(__file__).parent.parent / "templates"
self.env = Environment(
loader=FileSystemLoader(str(self.template_dir)),
autoescape=True
)
logger.info(f"ReportGenerator initialized with templates: {self.template_dir}")
def generate(self, result: AnalysisResult, output_format: str = "markdown") -> str:
"""
生成报告
Args:
result: 分析结果对象
output_format: 输出格式 (markdown, html, json)
Returns:
str: 格式化的报告内容
"""
logger.info(f"Generating {output_format} report")
if output_format == "markdown":
return self._generate_markdown(result)
elif output_format == "html":
return self._generate_html(result)
elif output_format == "json":
return self._generate_json(result)
else:
raise ValueError(f"不支持的输出格式: {output_format}")
def _generate_markdown(self, result: AnalysisResult) -> str:
"""生成 Markdown 格式报告"""
template = self.env.get_template("report.md.j2")
# 按文件分组问题
issues_by_file: Dict[str, List[CodeIssue]] = {}
for issue in result.issues:
if issue.file_path not in issues_by_file:
issues_by_file[issue.file_path] = []
issues_by_file[issue.file_path].append(issue)
# 渲染模板
return template.render(
title="代码审查报告",
generated_at=datetime.now().strftime("%Y-%m-%d %H:%M:%S"),
result=result,
issues_by_file=issues_by_file,
severity_emoji={
"critical": "🔴",
"high": "🟠",
"medium": "🟡",
"low": "🔵",
"info": "⚪"
}
)
def _generate_html(self, result: AnalysisResult) -> str:
"""生成 HTML 格式报告"""
template = self.env.get_template("report.html.j2")
return template.render(
title="代码审查报告",
generated_at=datetime.now().strftime("%Y-%m-%d %H:%M:%S"),
result=result,
severity_colors={
"critical": "#dc2626",
"high": "#ea580c",
"medium": "#ca8a04",
"low": "#2563eb",
"info": "#6b7280"
}
)
def _generate_json(self, result: AnalysisResult) -> str:
"""生成 JSON 格式报告"""
import json
from dataclasses import asdict
report = {
"title": "代码审查报告",
"generated_at": datetime.now().isoformat(),
"summary": {
"files_analyzed": result.files_analyzed,
"total_issues": result.total_issues,
"issues_by_severity": result.issues_by_severity,
"issues_by_category": result.issues_by_category,
"metrics": result.metrics
},
"issues": [asdict(issue) for issue in result.issues]
}
return json.dumps(report, indent=2, ensure_ascii=False)
def save_report(self, result: AnalysisResult, output_path: str,
output_format: Optional[str] = None) -> str:
"""
生成并保存报告到文件
Args:
result: 分析结果
output_path: 输出文件路径
output_format: 输出格式,默认根据文件扩展名推断
Returns:
str: 保存的文件路径
"""
output_path = Path(output_path)
# 根据扩展名推断格式
if output_format is None:
ext = output_path.suffix.lower()
format_map = {
'.md': 'markdown',
'.markdown': 'markdown',
'.html': 'html',
'.htm': 'html',
'.json': 'json'
}
output_format = format_map.get(ext, 'markdown')
# 生成报告内容
content = self.generate(result, output_format)
# 确保输出目录存在
output_path.parent.mkdir(parents=True, exist_ok=True)
# 写入文件
output_path.write_text(content, encoding='utf-8')
logger.info(f"Report saved to: {output_path}")
return str(output_path)报告生成器模块展示了如何将分析结果转换为多种格式的报告。关键设计点包括:
-
模板引擎集成:使用 Jinja2 模板引擎实现内容与格式的分离,便于维护和定制。
-
多格式支持:统一接口支持 Markdown、HTML 和 JSON 三种格式,满足不同使用场景。
-
智能格式推断:根据输出文件扩展名自动选择合适的格式,简化调用方式。
-
文件分组聚合:将问题按文件分组展示,提高报告的可读性和实用性。
7. 总结
OpenClaw Skills 系统为 AI 智能体扩展提供了一个强大而灵活的框架。通过本文的深入探讨,我们掌握了以下核心知识点:
架构设计层面:Skills 采用三层加载机制(内置、托管、工作区),通过优先级规则实现灵活的覆盖和定制。门控过滤机制确保技能只在满足条件时加载,配置注入系统则提供了安全的环境变量管理能力。
开发实践层面:高质量的 SKILL.md 文件需要清晰的触发条件、详细的操作步骤和完善的错误处理。多文件技能架构适合复杂场景,通过模块化设计提升代码的可维护性和可测试性。
调试运维层面:结构化日志、单元测试和错误恢复流程是生产级技能的必备要素。沙箱环境中的配置处理需要特别注意环境变量的传递方式。
实战经验层面:通过代码审查技能的完整实现,我们看到了如何将理论知识应用于实际项目。从需求分析到目录结构设计,从核心代码实现到报告生成,每个环节都需要精心设计。
Skills 系统的设计哲学------"能力定义与能力实现分离"------为 AI 应用开发提供了新的思路。随着 AI 技术的不断发展,我们期待看到更多创新性的技能涌现,共同构建更加智能、更加实用的 AI 生态系统。🌟