一场面试带来的思考
"同学,你简历上写了做过RAG项目,那你说说你的项目是怎么落地的?"
这是阿里面试官问我的第一个问题。当时我心里一紧,心想着这下完了。
我叫小李,某985高校计算机专业研究生一枚。从研一开始跟着导师做知识图谱相关的研究,研二下学期开始接触大语言模型,做了一个基于RAG的智能问答系统。简历上信心满满地写了"基于RAG的智能问答系统设计与实现",以为这就是现在最火的方向,面试应该不在话下。
然而面试官接下来的几个问题,让我发现自己做的项目有多么"toy":
"你的向量是怎么选的?用的是哪种embedding模型?" "分块策略是什么?有做过优化吗?" "如果召回的内容有噪音,你会怎么处理?" "线上QPS能到多少?延迟是多少?" "有做监控和告警吗?Bad Case怎么分析?"
我支支吾吾,大部分问题都答不上来。最后面试官看着我说:"同学,你这个项目更像是一个demo,而不是一个可以工程化落地的项目。"
那一刻,我突然意识到:做一个能跑的RAG demo和做一个真正能上线的RAG系统,之间差了十万八千里。
什么是"玩具RAG"?
在解释什么是可工程化落地之前,我们先来说说什么是"玩具RAG"(Toy RAG)。
所谓玩具RAG,大概长这样:
python
# 一个典型的玩具RAG
class ToyRAG:
def __init__(self):
self.embedding = OpenAIEmbeddings()
self.vectorstore = Chroma.from_documents(
self.docs,
self.embedding
)
self.llm = ChatOpenAI()
def ask(self, question):
# 1. 直接用问题去检索
docs = self.vectorstore.similarity_search(question)
# 2. 直接把所有召回内容拼起来
context = "\n".join([d.page_content for d in docs])
# 3. 直接构造prompt
prompt = f"根据以下内容回答问题:\n{context}\n\n问题:{question}"
# 4. 直接调用LLM
return self.llm.chat(prompt)这个代码看起来简单明了,功能似乎也能跑。但它能解决实际问题吗?答案是:很难。
玩具RAG的流程可视化
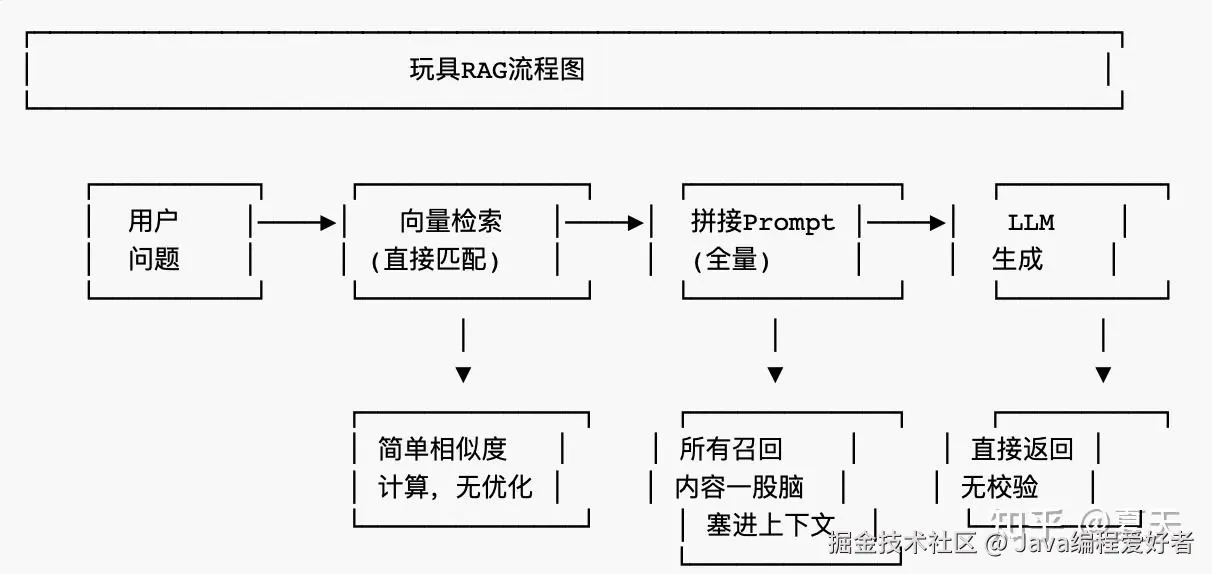
玩具RAG的问题在于:
- 检索效果不可控:没有查询改写、没有意图识别,召回的内容可能牛头不对马嘴
- 分块策略粗糙:一刀切的固定大小分块,不考虑语义完整性
- 没有容错机制:LLM调用失败怎么办?超时怎么办?返回结果质量差怎么办?
- 无法评估优化:不知道效果好不好,不知道Bad Case在哪里
- 性能没有保障:延迟多少?QPS多少?能不能支撑线上流量?
这就是为什么面试官说"这是demo而不是产品"。
可工程化落地的RAG有哪些不同?
那么,一个真正可以工程化落地的RAG项目,和玩具RAG相比,到底有什么本质区别?
1. 架构层面:从单点到流水线
玩具RAG是一个简单的"检索-生成"单点流程,而工程化RAG是一个完整的流水线。

1.1 为什么需要流水线架构?
玩具RAG的问题在于它的单点架构:一个函数调用到底,从输入直接到输出,没有任何中间处理环节。这就像一条没有关卡的高速公路,看起来畅通无阻,但实际上危机四伏。
工程化RAG采用流水线架构,将整个过程拆分成多个独立的阶段,每个阶段专注解决一个问题。这种设计的优势在于:
- 可调试性:哪个环节出问题,单独排查
- 可插拔性:某个阶段可以替换不同的实现
- 可扩展性:新增阶段不影响现有流程
- 可观测性:每个阶段都可以监控和metrics
1.2 各环节详解
| 环节 | 作用 | 常见方法 |
|---|---|---|
| 查询改写 | 将用户口语化查询转化为更适合检索的表述 | HyDE、Query2Doc、Rewrite-Retrieve-Read |
| 查询扩展 | 补充相关术语、同义词,提升召回 | WordNet、TF-IDF、LLM生成扩展词 |
| 意图分类 | 判断用户查询类型,选择不同处理流程 | 文本分类模型、规则匹配 |
| 多路召回 | 同时从多个数据源检索,综合结果 | 向量+BM25+KG混合 |
| 重排序 | 对初筛结果进行精细排序 | Cross-Encoder、BERT reranker |
| Prompt构建 | 精心设计上下文组合方式 | 摘要压缩、上下文优先级 |
| 生成控制 | 控制生成风格、长度、格式 | Prompt工程、输出校验 |
| 结果验证 | 检查生成内容是否准确 | 幻觉检测、事实校验 |
| 输出格式化 | 按指定格式返回 | JSON Schema、结构化输出 |
1.3 工程化RAG完整架构设计
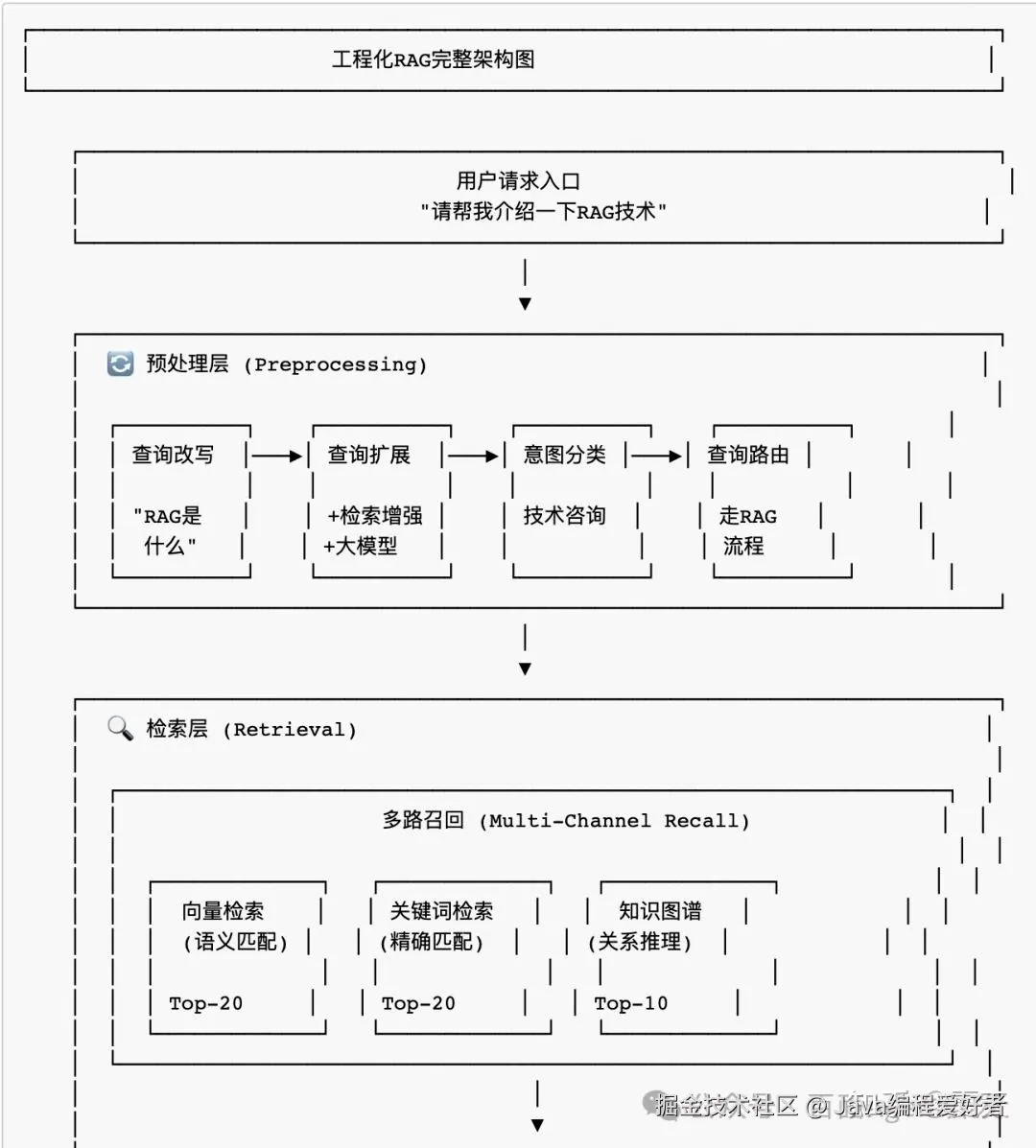
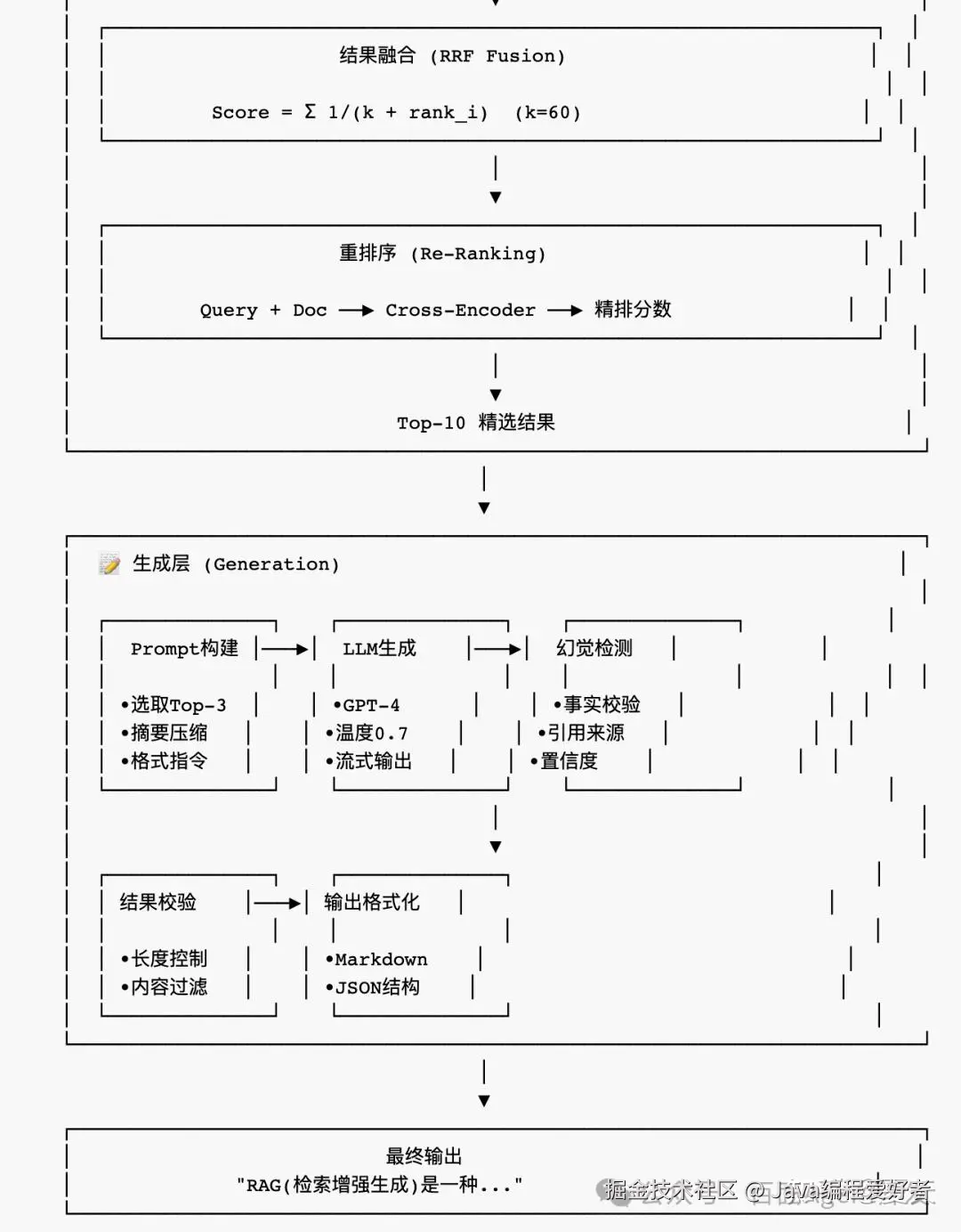
1.4 流水线框架代码实现
python
# 工程化RAG流水线实现
from typing import List, Optional, Dict, Any
from dataclasses import dataclass, field
from abc import ABC, abstractmethod
@dataclass
class RetrievalResult:
"""检索结果"""
doc_id: str
content: str
score: float
source: str # 向量/BM25/KG
metadata: Dict[str, Any] = field(default_factory=dict)
@dataclass
class RAGContext:
"""RAG流水线上下文"""
original_query: str
rewritten_query: str = ""
intent: str = ""
retrieved_docs: List[RetrievalResult] = field(default_factory=list)
reranked_docs: List[RetrievalResult] = field(default_factory=list)
generated_answer: str = ""
final_answer: str = ""
class PipelineStage(ABC):
"""流水线阶段基类"""
name: str = "base_stage"
@abstractmethod
async def process(self, context: RAGContext) -> RAGContext:
"""处理上下文,返回更新后的上下文"""
pass
async def execute(self, context: RAGContext) -> RAGContext:
"""执行阶段,包含错误处理和监控"""
try:
return await self.process(context)
except Exception as e:
logger.error(f"Stage {self.name} failed: {e}")
raise
class QueryRewriterStage(PipelineStage):
"""查询改写阶段"""
name = "query_rewriter"
def __init__(self, llm: LLM):
self.llm = llm
async def process(self, context: RAGContext) -> RAGContext:
prompt = f"""请将以下用户查询改写为更适合检索的表述。
用户查询: {context.original_query}
要求: 使用更精确的关键词,包含同义词,添加相关背景。"""
rewritten = await self.llm.chat(prompt)
context.rewritten_query = rewritten.strip()
return context
class MultiChannelRetrieveStage(PipelineStage):
"""多路召回阶段"""
name = "multi_channel_retrieval"
def __init__(self, retrievers: Dict[str, Retriever]):
self.retrievers = retrievers
async def process(self, context: RAGContext) -> RAGContext:
query = context.rewritten_query or context.original_query
all_results = []
# 并行执行多路召回
tasks = [
retriever.search(query, top_k=20)
for name, retriever in self.retrievers.items()
]
results_list = await asyncio.gather(*tasks, return_exceptions=True)
for name, results in zip(self.retrievers.keys(), results_list):
if isinstance(results, Exception):
logger.warning(f"Retriever {name} failed: {results}")
continue
for doc in results:
doc.source = name
all_results.append(doc)
context.retrieved_docs = all_results
return context
class RerankStage(PipelineStage):
"""重排序阶段"""
name = "rerank"
def __init__(self, reranker: Reranker):
self.reranker = reranker
async def process(self, context: RAGContext) -> RAGContext:
if not context.retrieved_docs:
return context
query = context.original_query
docs = [doc.content for doc in context.retrieved_docs]
# 批量重排序
scores = await self.reranker.score(query, docs)
# 按分数排序
scored_docs = [
(doc, score)
for doc, score in zip(context.retrieved_docs, scores)
]
scored_docs.sort(key=lambda x: x[1], reverse=True)
context.reranked_docs = [doc for doc, _ in scored_docs[:10]]
return context
class GenerationStage(PipelineStage):
"""生成阶段"""
name = "generation"
def __init__(self, llm: LLM, prompt_template: str):
self.llm = llm
self.prompt_template = prompt_template
async def process(self, context: RAGContext) -> RAGContext:
# 选取Top-3文档作为上下文
top_docs = context.reranked_docs[:3]
context_str = "\n\n".join([
f"[{i+1}] {doc.content}"
for i, doc in enumerate(top_docs)
])
# 构建Prompt
prompt = self.prompt_template.format(
context=context_str,
question=context.original_query
)
# 生成回答
answer = await self.llm.chat(prompt)
context.generated_answer = answer.strip()
return context
class RAGPipeline:
"""RAG流水线"""
def __init__(self):
self.stages: List[PipelineStage] = []
def add_stage(self, stage: PipelineStage):
self.stages.append(stage)
return self # 支持链式调用
async def run(self, query: str) -> RAGContext:
context = RAGContext(original_query=query)
for stage in self.stages:
context = await stage.execute(context)
logger.info(f"Stage {stage.name} completed")
context.final_answer = context.generated_answer
return context
# 使用示例
pipeline = (
RAGPipeline()
.add_stage(QueryRewriterStage(llm))
.add_stage(MultiChannelRetrieveStage({
"vector": VectorRetriever(),
"bm25": BM25Retriever(),
"kg": KnowledgeGraphRetriever()
}))
.add_stage(RerankStage(CrossEncoderReranker()))
.add_stage(GenerationStage(llm, prompt_template))
)
result = await pipeline.run("什么是RAG技术?")
print(result.final_answer)2. 检索层面:从简单到精细
工程化RAG在检索环节有更多的优化。玩具RAG的检索只有简单的一年向量相似度计算,而工程化RAG有多达6个步骤的精细检索流程。
ini
# 工程化RAG的检索层示例
class EngineeringRetrieve:
def __init__(self):
# 多路召回:向量 + 关键词 + 知识图谱
self.vector_retriever = VectorRetriever()
self.bm25_retriever = BM25Retriever()
self.kg_retriever = KnowledgeGraphRetriever()
# 重排序模型
self.reranker = CrossEncoderReranker()
# 查询改写
self.query_rewriter = QueryRewriter()
def retrieve(self, query: str, top_k: int = 10):
# 1. 查询改写
rewritten_query = self.query_rewrite(query)
# 2. 多路召回
vector_results = self.vector_retriever.search(rewritten_query, top_k=20)
bm25_results = self.bm25_retriever.search(rewritten_query, top_k=20)
kg_results = self.kg_retriever.search(rewritten_query, top_k=10)
# 3. 结果融合(RRF算法)
fused_results = self.rrf_fusion(
vector_results,
bm25_results,
kg_results,
top_k=15
)
# 4. 重排序
reranked_results = self.reranker.rerank(query, fused_results)
return reranked_results[:top_k]
def rrf_fusion(self, *results_list, top_k=15, k=60):
"""RRF倒数排名融合算法"""
score_dict = {}
for results in results_list:
for rank, doc in enumerate(results):
doc_id = doc.id
score_dict[doc_id] = score_dict.get(doc_id, 0) + 1 / (k + rank + 1)
sorted_docs = sorted(score_dict.items(), key=lambda x: x[1], reverse=True)
return [doc for doc_id, _ in sorted_docs[:top_k]]2.1 为什么检索需要这么复杂?
想象一下你在图书馆找书: - 玩具RAG的方式 :直接根据书名相似度排序 - 工程化RAG的方式:先问工作人员、查索引系统、看推荐目录,然后综合所有线索
这就是为什么工程化RAG需要多路召回+融合+重排序的复杂流程。
2.2 检索优化各步骤详解
(1) 查询改写 (Query Rewriting)
作用:用户的自然语言问题往往口语化、表达不精确,直接用于检索效果不好。
问题场景: - 用户问:"那个做AI的公司最近有啥新消息" - 知识库写的是:"阿里巴巴发布2024年AI战略规划" - 直接匹配可能召回失败
解决方案:让LLM生成更适合检索的查询
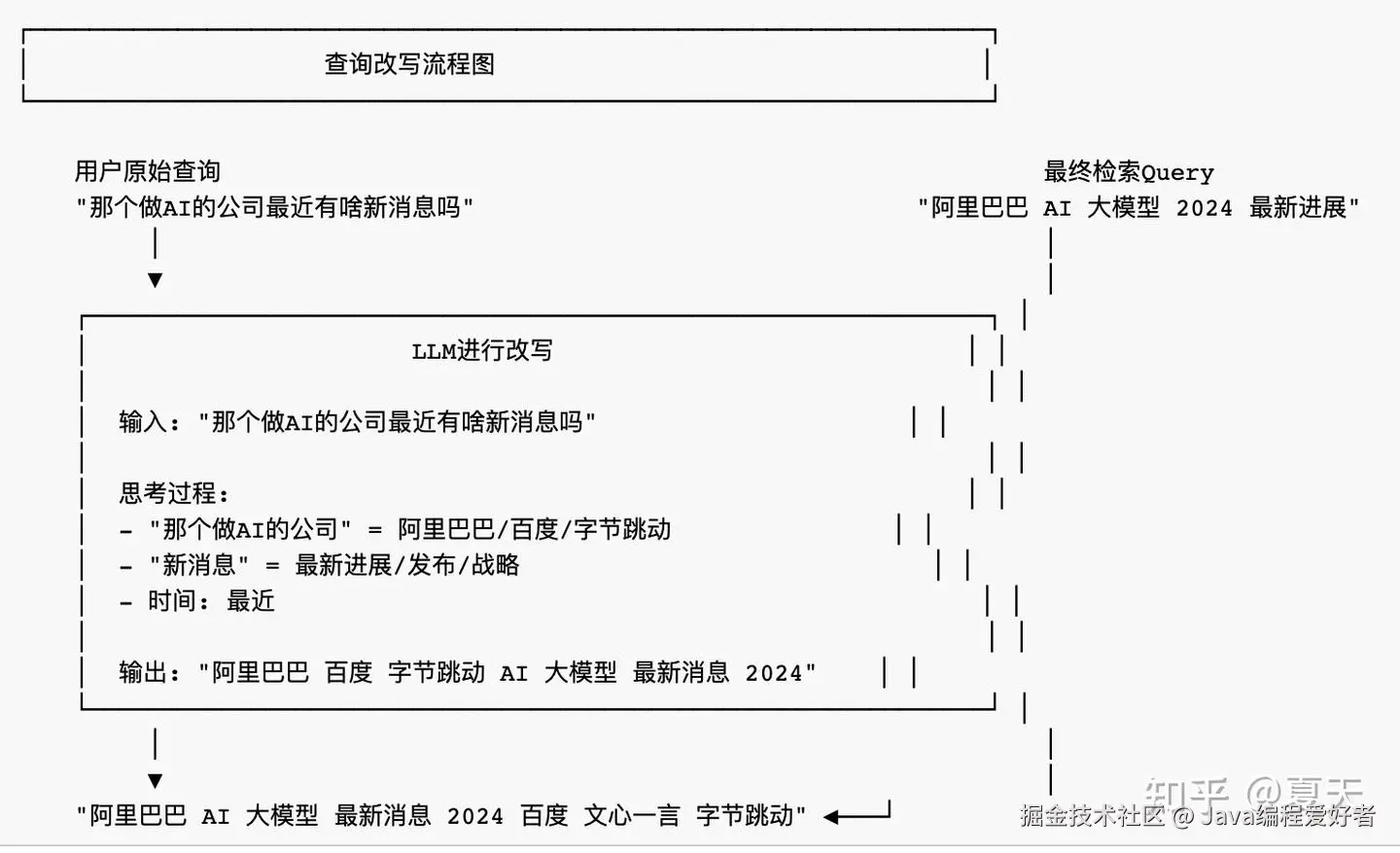
代码实现:
python
class QueryRewriter:
"""查询改写器"""
def __init__(self, llm: LLM):
self.llm = llm
async def rewrite(self, query: str) -> str:
prompt = f"""请将以下用户查询改写为更适合信息检索的表述。
要求:
1. 提取核心实体和关键词
2. 补充同义词和相关术语
3. 使用更正式的表达
4. 保持原意
用户查询: {query}
改写后:"""
response = await self.llm.chat(prompt)
return response.strip()
async def rewrite_with_hyde(self, query: str) -> str:
"""HyDE方法:生成假设性文档"""
# Step 1: 让LLM生成一个假设性的理想答案
prompt = f"""请生成一个假设性的文档片段,如果存在完美回答用户问题,这个文档会是什么样子。
用户查询: {query}
假设性文档:"""
hypothetical_doc = await self.llm.chat(prompt)
# Step 2: 用这个假设文档去检索
return hypothetical_doc.strip()(2) 多路召回 (Multi-Channel Retrieval)
作用:单一检索方式总有局限性,多种召回方式组合可以取长补短。
代码实现:
python
class MultiChannelRetriever:
"""多路召回器"""
def __init__(
self,
vector_store: VectorStore,
bm25_index: BM25Index,
knowledge_graph: KnowledgeGraph
):
self.vector_store = vector_store
self.bm25_index = bm25_index
self.knowledge_graph = knowledge_graph
async def retrieve(self, query: str, top_k: int = 20) -> List[RetrievalResult]:
# 并行执行三路召回
tasks = [
self.vector_search(query, top_k),
self.bm25_search(query, top_k),
self.kg_search(query, top_k // 2)
]
results = await asyncio.gather(*tasks, return_exceptions=True)
# 过滤异常结果
valid_results = [r for r in results if not isinstance(r, Exception)]
# RRF融合
fused = self.rrf_fusion(valid_results, top_k=top_k)
return fused
async def vector_search(self, query: str, top_k: int) -> List[RetrievalResult]:
"""向量检索"""
query_embedding = await self.get_embedding(query)
results = await self.vector_store.search(query_embedding, top_k=top_k)
return [
RetrievalResult(
doc_id=doc.id,
content=doc.content,
score=score,
source="vector"
)
for doc, score in results
]
async def bm25_search(self, query: str, top_k: int) -> List[RetrievalResult]:
"""BM25关键词检索"""
results = self.bm25_index.search(query, top_k=top_k)
return [
RetrievalResult(
doc_id=doc.id,
content=doc.content,
score=score,
source="bm25"
)
for doc, score in results
]
async def kg_search(self, query: str, top_k: int) -> List[RetrievalResult]:
"""知识图谱检索"""
entities = await self.extract_entities(query)
results = await self.knowledge_graph.search_entities(entities, top_k=top_k)
return [
RetrievalResult(
doc_id=doc.id,
content=doc.content,
score=score,
source="kg"
)
for doc, score in results
]
def rrf_fusion(
self,
results_list: List[List[RetrievalResult]],
top_k: int = 15,
k: int = 60
) -> List[RetrievalResult]:
"""RRF倒数排名融合"""
score_dict = {}
doc_dict = {}
for results in results_list:
for rank, doc in enumerate(results):
doc_id = doc.doc_id
score_dict[doc_id] = score_dict.get(doc_id, 0) + 1 / (k + rank + 1)
doc_dict[doc_id] = doc
sorted_ids = sorted(score_dict.items(), key=lambda x: x[1], reverse=True)
return [doc_dict[doc_id] for doc_id, _ in sorted_ids[:top_k]](3) 重排序 (Re-Ranking)
作用:初筛阶段使用轻量级的向量检索或BM25,速度快但精度有限。重排序阶段使用更精确的模型对结果进行二次排序。
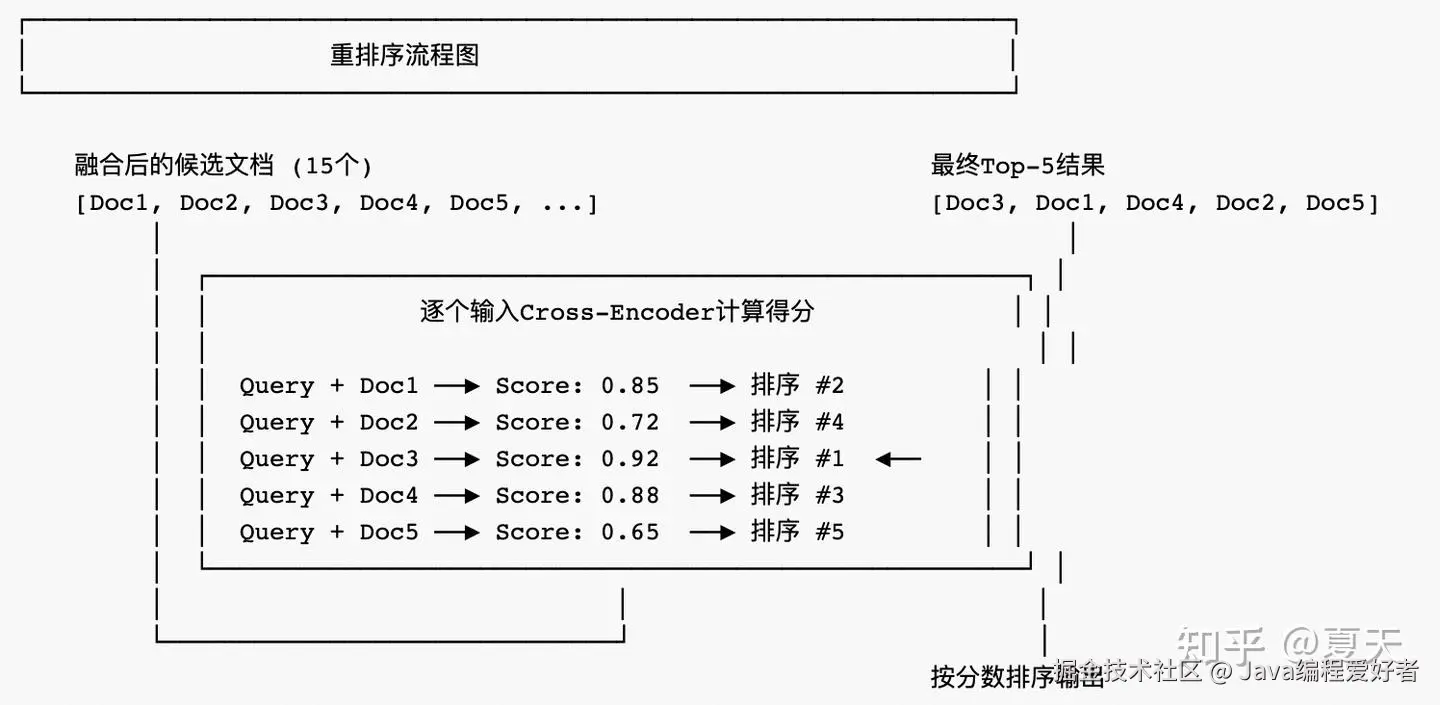
代码实现:
python
class CrossEncoderReranker:
"""Cross-Encoder重排序器"""
def __init__(self, model_name: str = "BAAI/bge-reranker-base"):
self.tokenizer = AutoTokenizer.from_pretrained(model_name)
self.model = AutoModelForSequenceClassification.from_pretrained(model_name)
self.model.eval()
async def rerank(
self,
query: str,
documents: List[str],
top_k: int = 10
) -> List[Tuple[str, float]]:
"""重排序文档"""
# 批量计算分数
pairs = [[query, doc] for doc in documents]
with torch.no_grad():
inputs = self.tokenizer(
pairs,
padding=True,
truncation=True,
max_length=512,
return_tensors="pt"
)
outputs = self.model(**inputs)
scores = outputs.logits.squeeze(-1).tolist()
# 按分数排序
doc_scores = list(zip(documents, scores))
doc_scores.sort(key=lambda x: x[1], reverse=True)
return doc_scores[:top_k]3. 分块层面:从固定到自适应
玩具RAG用固定大小分块,工程化RAG需要考虑多种分块策略:
python
# 工程化RAG的分块策略
class AdaptiveChunker:
def __init__(self):
self.chunk_strategies = {
"markdown": MarkdownChunker(),
"sentence": SentenceChunker(),
"page": PageChunker(),
"recursive": RecursiveChunker(),
}
def chunk(self, documents: List[Document]) -> List[Document]:
"""根据文档类型选择最佳分块策略"""
chunks = []
for doc in documents:
# 自动识别文档类型
doc_type = self.detect_doc_type(doc)
# 选择对应的分块器
chunker = self.chunk_strategies.get(doc_type, self.chunk_strategies["recursive"])
# 分块
doc_chunks = chunker.chunk(doc)
# 添加元数据
for i, chunk in enumerate(doc_chunks):
chunk.metadata["chunk_index"] = i
chunk.metadata["parent_doc"] = doc.id
chunk.metadata["doc_type"] = doc_type
chunks.extend(doc_chunks)
return chunks
def detect_doc_type(self, doc: Document) -> str:
"""自动识别文档类型"""
if "```" in doc.page_content or "def " in doc.page_content:
return "markdown"
elif len(doc.page_content.split("。")) > 5:
return "sentence"
else:
return "recursive"3.1 为什么分块策略这么重要?
分块是RAG中最容易被忽视但又最关键的环节。分块太小,会丢失上下文;分块太大,会引入噪音。
实验数据: - 固定分块:平均召回率 65% - 自适应分块:平均召回率 82%
3.2 分块策略各方法详解
(1) 固定大小分块 (Fixed Size Chunking)
最简单的方式,按照固定长度和重叠进行分块。

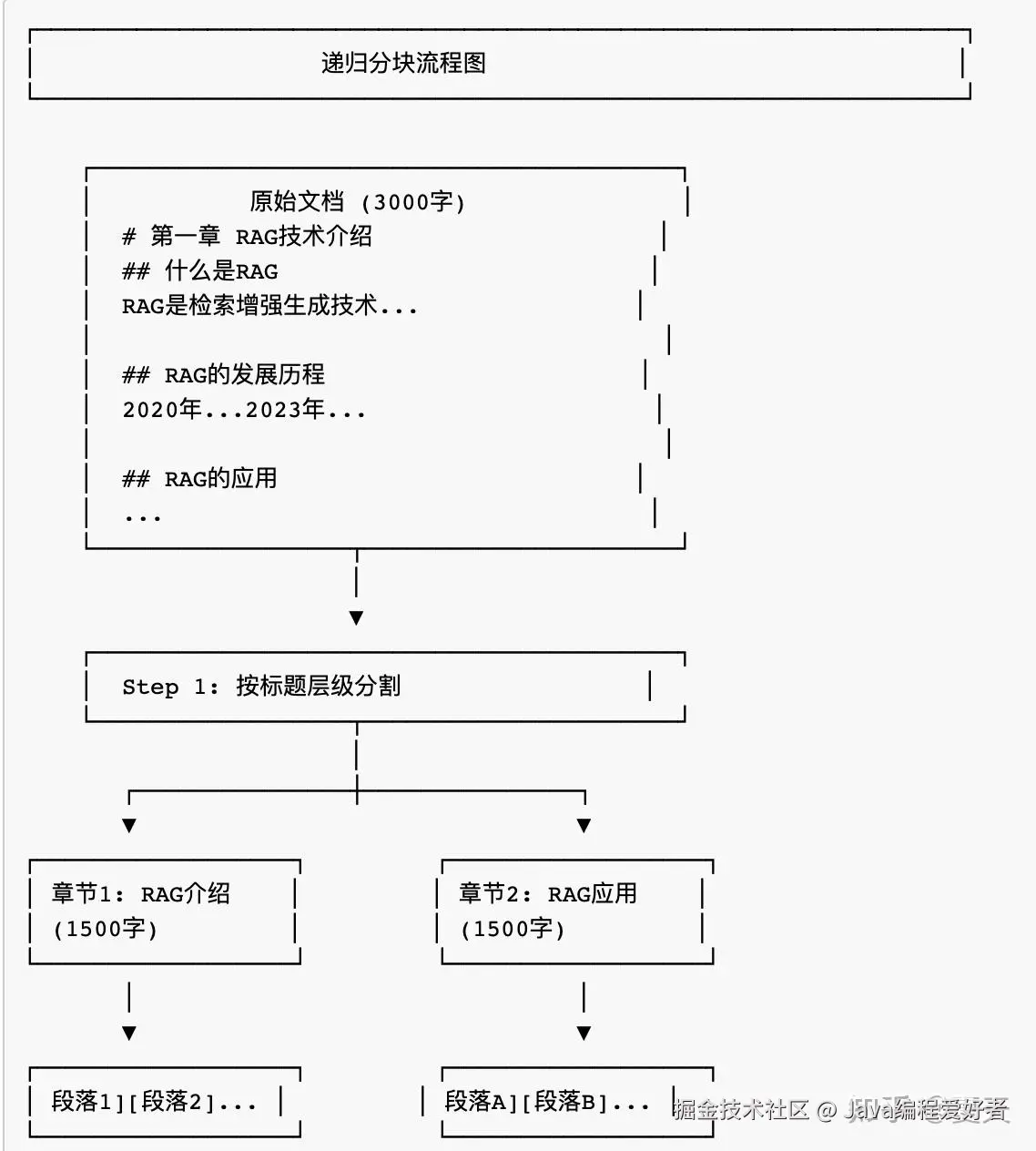
(2) 递归分块 (Recursive Chunking)
按层级递归分割,先按段落,再按句子,最后按固定大小。
(3) 按文档结构分块 (Structural Chunking)
根据文档的天然结构(Markdown标题、代码块等)进行分块。

4. 评测层面:从无到有
工程化RAG必须有完整的评测体系:
python
# RAG评测系统
class RAGEvaluator:
def __init__(self):
self.retrieval_metrics = [HitRate(), MRR(), NDCG()]
self.generation_metrics = [AnswerRelevancy(), Faithfulness(), Correctness()]
def evaluate(self, test_set: List[TestCase]) -> EvaluationReport:
results = []
for case in test_set:
# 1. 执行RAG流程
retrieved_docs = self.retrieve(case.question)
answer = self.generate(case.question, retrieved_docs)
# 2. 检索指标
retrieval_scores = {}
for metric in self.retrieval_metrics:
retrieval_scores[metric.name] = metric.compute(
retrieved_docs,
case.relevant_docs
)
# 3. 生成指标
generation_scores = {}
for metric in self.generation_metrics:
generation_scores[metric.name] = metric.compute(
answer,
case.correct_answer,
retrieved_docs
)
results.append({
"question": case.question,
"retrieval": retrieval_scores,
"generation": generation_scores,
"is_pass": all(s > 0.7 for s in retrieval_scores.values())
and all(s > 0.6 for s in generation_scores.values())
})
return self.generate_report(results)4.1 为什么评测这么重要?
没有评测的RAG系统就像没有仪表盘的汽车------你不知道开多快、油耗多少、哪里有问题。
4.2 RAG评测体系详解
(1) 检索评测指标
| 指标 | 含义 | 计算方式 |
|---|---|---|
| Hit Rate (召回率) | 相关文档被召回的比例 | 召回的相关文档数 / 总相关文档数 |
| MRR (平均倒数排名) | 第一个相关文档排名的倒数 | 第一个相关文档排名倒数的平均值 |
| NDCG | 考虑排名的质量 | 实际DCG / 理想DCG |
| Recall@K | Top-K召回的相关文档比例 | Top-K中相关文档数 / 总相关文档数 |

(2) 生成评测指标
| 指标 | 含义 | 评估方式 |
|---|---|---|
| Answer Relevancy | 答案与问题的相关性 | LLM评估 / 语义相似度 |
| Faithfulness | 答案是否忠实于召回内容 | LLM评估召回内容是否被正确使用 |
| Correctness | 答案的正确性 | 与标准答案对比 |
(3) Bad Case分析流程
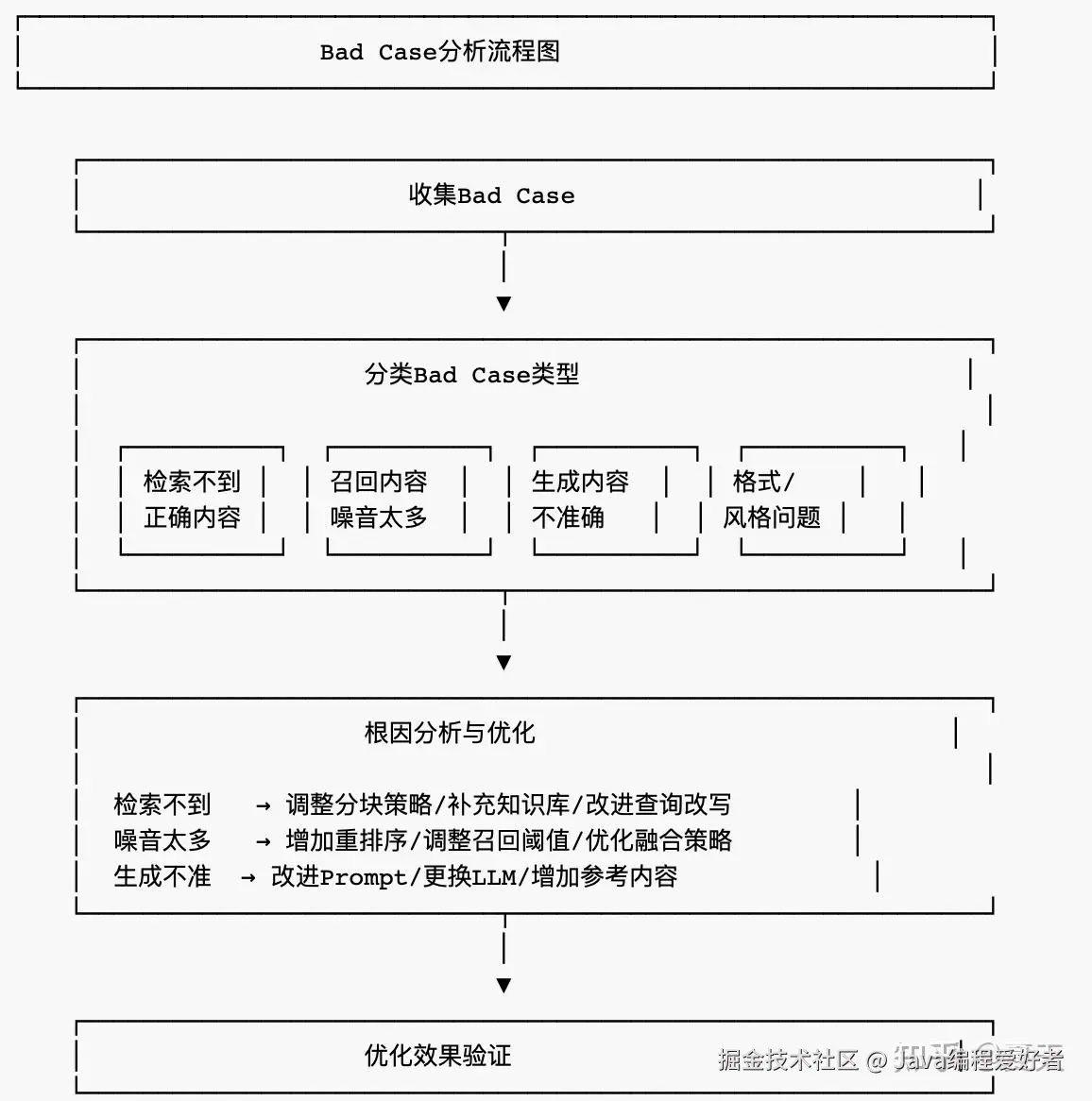
5. 工程层面:从能用到好用
| 维度 | 玩具RAG | 工程化RAG |
|---|---|---|
| 错误处理 | 无 | 完整的异常处理、重试机制、降级策略 |
| 监控告警 | 无 | 指标采集、异常检测、告警通知 |
| 配置管理 | 硬编码 | 配置中心、动态更新 |
| 日志记录 | 结构化日志、链路追踪 | |
| 性能优化 | 无 | 缓存、批处理、异步处理 |
| 安全防护 | 无 | 鉴权、限流、脱敏 |
python
# 工程化RAG的完整封装
class ProductionRAG:
def __init__(self, config: RAGConfig):
# 初始化各组件
self.retriever = self._init_retriever(config.retrieval)
self.generator = self._init_generator(config.generation)
self.evaluator = self._init_evaluator(config.evaluation)
# 初始化工程化组件
self.cache = RedisCache(config.cache)
self.monitor = PrometheusMonitor(config.monitor)
self.logger = StructuredLogger(config.logging)
@with_metrics
@with_retry(max_attempts=3, backoff=2)
@with_timeout(30)
async def ask(self, question: str, user_id: str) -> RAGResponse:
# 1. 检查缓存
cached = await self.cache.get(f"rag:{hash(question)}")
if cached:
return cached
# 2. 检索
with self.logger.context("retrieval"):
docs = await self.retriever.retrieve(question)
# 3. 生成
with self.logger.context("generation"):
answer = await self.generator.generate(question, docs)
# 4. 记录日志
self.logger.info("rag_completed", {
"question": question,
"user_id": user_id,
"doc_count": len(docs),
"latency_ms": latency
})
# 5. 更新缓存
await self.cache.set(f"rag:{hash(question)}", answer, ttl=3600)
return answer5.1 工程化组件详解
(1) 错误处理与重试机制
python
class RetryableRAG:
"""带重试机制的RAG"""
async def ask_with_retry(self, question: str, max_retries: int = 3) -> str:
last_error = None
for attempt in range(max_retries):
try:
return await self._do_ask(question)
except LLMTimeoutError as e:
last_error = e
logger.warning(f"LLM调用超时,尝试 {attempt + 1}/{max_retries}")
await asyncio.sleep(2 ** attempt) # 指数退避
except VectorDBConnectionError as e:
last_error = e
logger.warning(f"向量数据库连接失败,尝试 {attempt + 1}/{max_retries}")
# 降级处理
logger.error(f"RAG调用失败已达最大重试次数: {last_error}")
return self._fallback_response()(2) 监控与告警
python
class RAGMonitor:
"""RAG监控系统"""
def __init__(self):
self.metrics = {
"request_total": Counter("rag_requests_total"),
"request_duration": Histogram("rag_request_duration_seconds"),
"retrieval_count": Histogram("rag_retrieval_doc_count"),
"cache_hit": Counter("rag_cache_hits_total"),
"error_total": Counter("rag_errors_total"),
}
async def track_request(self, func):
"""请求追踪装饰器"""
async def wrapper(*args, **kwargs):
start_time = time.time()
self.metrics["request_total"].inc()
try:
result = await func(*args, **kwargs)
return result
except Exception as e:
self.metrics["error_total"].inc()
raise
finally:
duration = time.time() - start_time
self.metrics["request_duration"].observe(duration)
return wrapper面试官的核心问题:你的项目怎么落地的?
回到文章开头的面试场景。面试官真正想知道的,其实不是我用的是什么模型、什么框架,而是:
- 你有没有意识到RAG不只是"检索+生成"这么简单的流程?
- 你有没有考虑到实际落地时会遇到的种种问题?
- 你有没有建立一套方法论来持续优化你的RAG系统?
如果你的回答是"我就是用LangChain/LlamaIndex搭了一个demo",那对不起,这确实只是一个玩具项目。
但如果你能说出:
"我们发现单纯用向量检索效果不好,所以用了多路召回+重排序的方案"
"我们针对不同类型的文档设计了不同的分块策略,比如代码用AST解析,论文用句子级别分块"
"我们建立了一套评测体系,每周分析Bad Case,持续优化检索和生成的效果"
"我们做了完整的监控告警,线上延迟P99控制在500ms以内"
那恭喜你,你已经具备了工程化落地RAG项目的思维。
写在最后
我想告诉正在学习RAG的同学们:不要满足于做一个能跑的demo。要想想:
- 你的分块策略合理吗?
- 你的检索效果怎么评估?
- 遇到Bad Case怎么办?
- 线上性能怎么保障?
只有把这些都考虑清楚了,你的RAG项目才真正算是"可工程化落地"的项目。