作者:珞雪
引言:生成式 AI 时代的推理加速挑战
在当今人工智能快速发展的时代,图像和视频生成技术已从科研前沿走向实际应用。从创意产业的广告制作、内容生成,到工业设计的可视化,再到医学影像辅助诊断和虚拟内容制作,扩散模型(Diffusion Model)正在为各个行业创造前所未有的价值。
然而,这种应用的广泛化也带来了新的挑战:随着模型规模的不断增大,推理时间随之增加,用户对生成速度的期待与硬件性能之间的矛盾日益凸显。同时,复杂的推理优化配置也为普通用户设置了较高的技术门槛,制约了这些强大技术的普及。
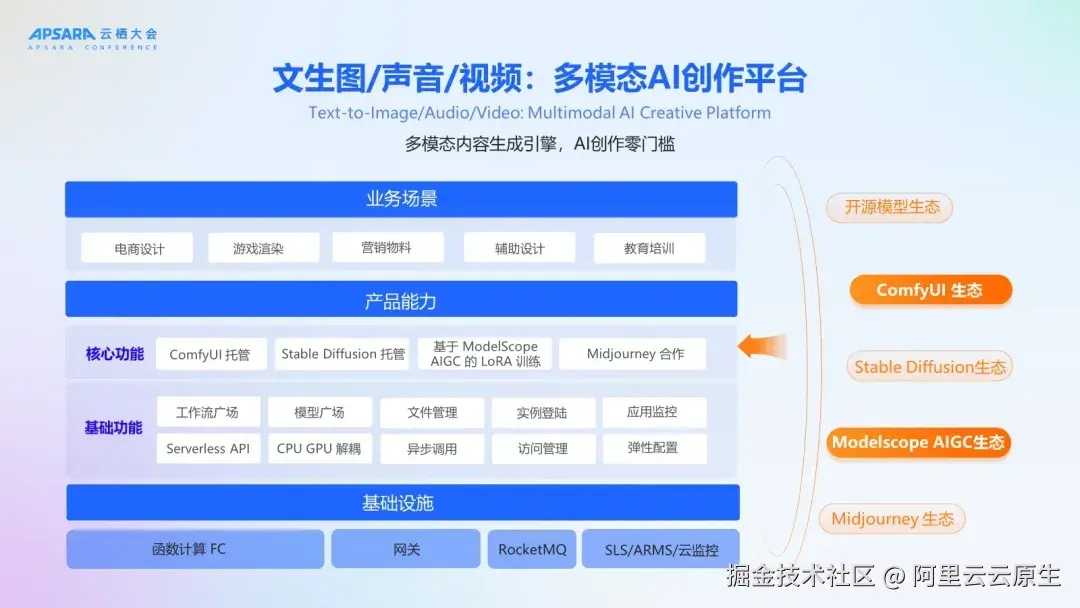
在 AI 生成领域,推理性能的提升直接决定用户体验的质量。FunArt 作为阿里云函数计算提供的一键托管 ComfyUI 应用平台 ,致力于为用户提供开箱即用的先进 DiT 推理引擎能力,持续提升图像/视频生成性能。此前,FunArt 已相继集成 Nunchaku 和 DeepGPU 两款 DiT 推理引擎,让用户无需繁琐配置即可享受加速推理的红利。
现在,FunArt 再次集成新引擎------VisionPlaid。VisionPlaid 是阿里云基础软件团队推出的一款专为视觉扩散模型(Diffusion Model)设计的高性能推理加速框架,深度整合前沿技术,提供对 ComfyUI 的原生支持,为多款模型提供极致的推理体验。
技术演进:从 Nunchaku 到 VisionPlaid
FunArt 在推理加速领域的演进历程反映了一个重要理念:单一的加速方案无法满足所有场景需求,只有不断集成最新技术,才能为用户提供真正的极致体验。
FunArt 的优势
FunArt 是阿里云函数计算提供的一键托管 ComfyUI 应用平台,提供从项目开发到 API 调用的全生命周期管理能力。
一键部署,开箱即用
- 一键部署:一键拉起图像生成项目,分钟级完成端到端环境搭建。
- 开箱即用:自动分配 Serverless GPU 算力与存储资源,预装开箱即用的 ComfyUI 环境,全程无需手动安装依赖。
提供项目开发到 API 调用的全生命周期管理
- 简单易上手的项目开发,项目开发阶段拉齐本地出图体验,可便捷地下载模型,安装插件,调试提示词与流程,快速出图。
- 弹性高可用的 API 调用:API 调用阶段充分发挥 Serverless 优势,弹性高可用,自动扩缩容。
- 一站式发布:项目开发阶段调试通过的流程可直接发布为弹性高可用的 API。
国内网络加速,减少等待
- 模型预缓存:缓存 50+ 常用模型,提升模型下载速度。
- 使用国内 Github 源站加速插件下载,避免跨境访问连接超时。
- 使用阿里云 PyPI 源,提升依赖安装速度。
灵活开放
- 自定义模型上传:支持上传自定义模型,即时生效。
- 自定义插件扩展:可通过文件管理或实例登录上传自定义插件,适配个性化需求。
资源独享,安全无忧
- 独立的运行环境:项目独占 GPU 资源,避免资源争抢带来的性能波动。
- 隔离的资源存储:模型与生成内容均存储在用户的 NAS 中,保证数据安全。
Serverless 算力,弹性扩展,按需付费
- 自动弹性伸缩:Serverless 算力在突发流量时可自动扩容,轻松应对波峰流量。
- 算力按需计费:算力按需计费,无请求时可自动释放计算资源,随起随停,浅休眠(原闲置)成本低。
企业级可靠性保障
- 服务高可用:算力多可用区容灾部署,单点故障可自动迁移恢复。
VisionPlaid 技术概览:推理加速的新方向
VisionPlaid 的出现标志着推理加速技术的一个重要突破。与传统的加速方案相比,VisionPlaid 采取了全新的技术路线,既保证了与现有生态(ComfyUI)的无缝兼容,又通过创新的算法和架构实现了显著的性能提升。这种"兼容性与性能并重"的设计思想,正是 VisionPlaid 能够快速被 FunArt 采纳的原因。
VisionPlaid 的优势
1. 行业领先的 ComfyUI 并行化加速 (SP)
- 超越简单的显存节省 :不同于
comfyui-multigpu等仅通过分布式 Offload 来节省内存的项目,VisionPlaid 实现了真正的序列并行(Sequence Parallelism, SP)加速。我们不仅能让你跑起来大模型,更能通过多卡协同计算,显著缩短单图/单视频的生成时间。 - SOTA E2E 速度 :VisionPlaid 支持在并行模式下同时开启
Async Offload,并将并行加速与4-bit 量化完美结合(Insane!)。这种组合拳让单张大图或长视频的端到端(E2E)生成速度直达硬件极限。
2. 极致的原生 ComfyUI 兼容性
- 生态无缝衔接 :ComfyUI 是目前最受欢迎的视觉工作流框架,使普通用户也能在消费级显卡上搭建自定义风格和组件。VisionPlaid 坚持原生兼容路线:
- 直接支持社区权重 :无需像
SGL-Diffusion那样用后端服务接管,直接复用社区生态。 - 全组件兼容 :区别于
xDiT等独立框架,VisionPlaid 融入原生态工作流,你可以继续使用你喜爱的各种自定义节点和插件。
3. 智能内存管理与异步 Offload
- 突破显存物理上限 :在 ComfyUI 原有的内存管理基础上,我们提供了更深层的智能异步加载/卸载(Async Load/Unload) 能力。在推理进行的同时,后台异步准备下一阶段权重,理论上支持运行远超物理显存容量的超大规模模型。
4. 极简的架构易用性
- 一键替换,无感加速 :在工作流中支持并行,只需要替换一个节点(KSampler) 即可完成。
- 智能 Worker 管理 :VisionPlaid 能够智能管理 GPU 资源的分配与回收。当你切换 GPU 数量时,系统会自动销毁并重建 Worker,无需重启 ComfyUI 即可即时生效。
VisionPlaid 核心特性
VisionPlaid 通过软硬件协同优化,在保持模型精度的前提下突破推理性能瓶颈。
并行与通信
- SP 通信计算重叠 :利用序列并行(Sequence Parallelism)隐藏通信延迟,实现计算与通信高效并发。
- 量化通信 :采用低位宽通信协议,大幅缓解多卡/多节点间的带宽压力。
精度与量化
- 下一代量化支持 :原生支持
Int4与NVFP4,在极致压缩显存的同时确保生成质量。 - 4-Step 蒸馏兼容 :完美适配少步数模型,支持秒级极速图像/视频生成。
架构与算子
- ComfyUI 原生加速 :深度集成工作流,支持节点级并行推理。
- 全能 Attention 后端 :支持
SageAttention、FlashAttention及SDPA无重启自由切换。 - 异步 Offload 机制 :动态加载/卸载权重,利用计算流水掩盖 IO 延迟,支持远超显存容量的超大模型推理。
- 算子深度加速 :整合
torch.compile与自定义融合算子,榨干硬件性能。
VisionPlaid横向评测 (Benchmarks)
在与当前业界 SOTA 项目的横向对比中,VisionPlaid 在 Transformer 单步时间和端到端延迟上均展现了显著优势。
视频生成
VisionPlaid 的性能优势不仅体现在原始数字上,更重要的是这些性能提升对实际应用的影响。在视频生成领域,与 Diffusers 相比 1.6 倍的单卡加速意味着生成一段视频的时间从 499 秒降至 308 秒,减少了 191 秒的等待时间------这对于需要快速迭代的创意工作者而言是巨大的生产力提升。在双卡配置下,2.5 倍的加速将时间进一步压缩到 200 秒,使得原本需要 8 分钟的任务降至 3 分钟,这在生产环境中可以显著提升吞吐量。
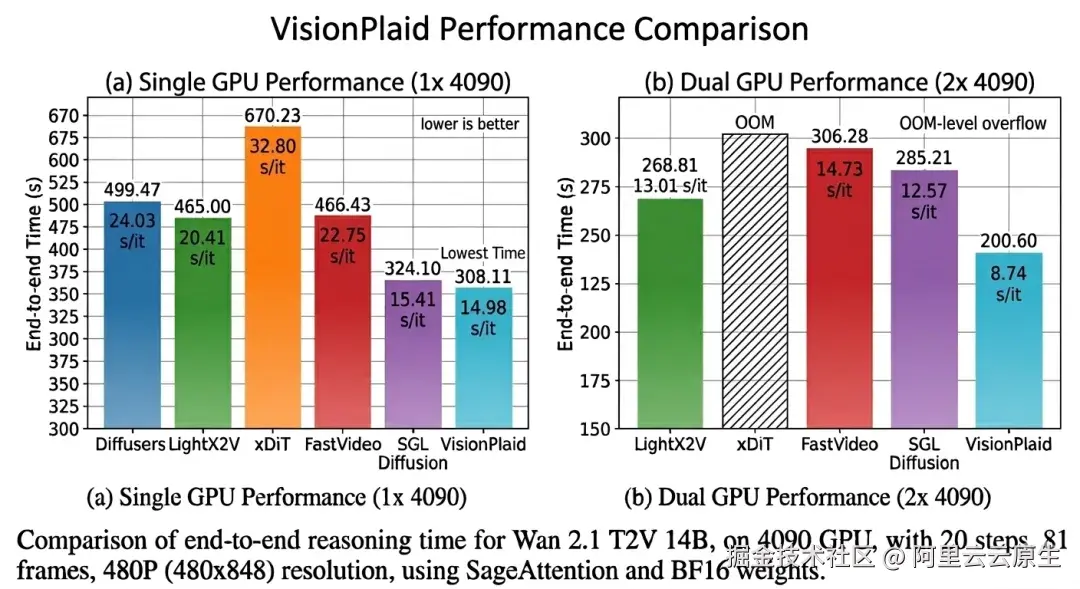
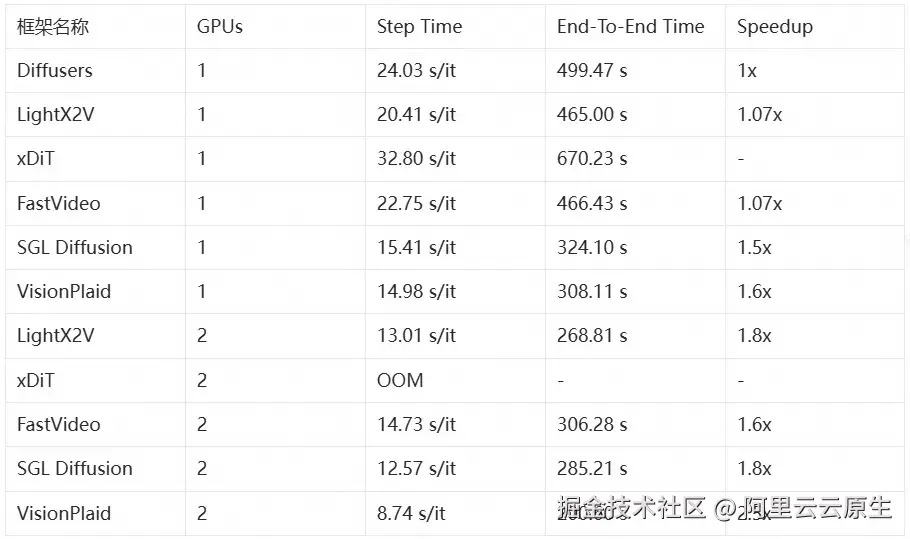
测试环境:Wan 2.1 T2V 14B,4090,20 steps,81 frames,480P (480x848),SageAttention,BF16
注:xDiT 未接入 SageAttention,因此省略 Speedup 信息;2 卡时疑似 cpu offload 和 parallel 冲突导致 OOM。
图片生成(bf16/fp8)
在图片生成领域,VisionPlaid 展现出了对不同精度配置的优异适应能力。即使在 fp8 低精度下仍能保持 1.10 倍的性能优势,说明 VisionPlaid 的优化不仅限于高精度场景,对于成本敏感的应用同样有效。在极端的 4-step 超快速生成配置下,VisionPlaid 能够在 3.51 秒内完成一张 1024x1024 图像的生成,这使得实时或近实时的交互式生成成为了可能。
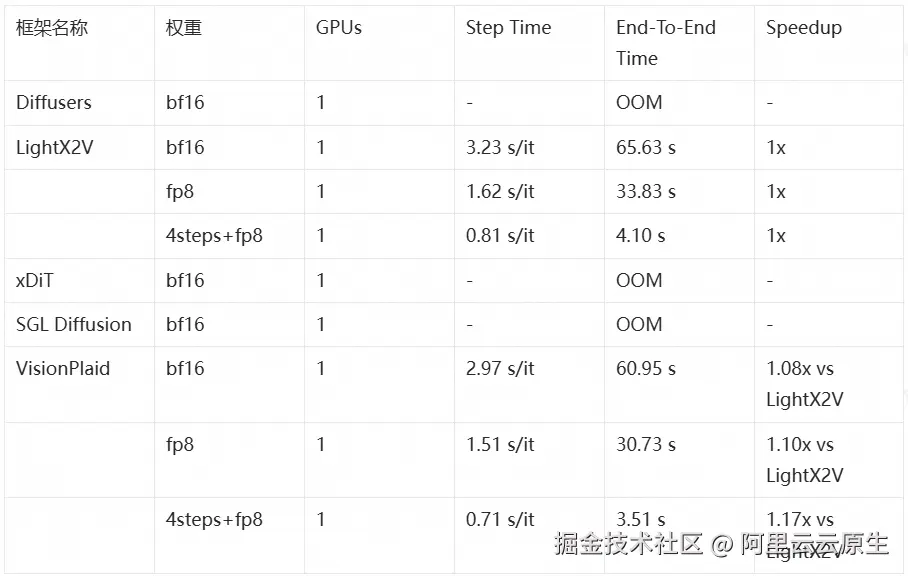
测试环境:Qwen-Image-2512,4090,20 steps or 4 steps,1024x1024,SageAttention
注:4-step 配置中使用了 CFG=1.0 的推荐配置;xDiT 和 SGLD 未支持 fp8。
图片生成(int4/4steps+int4)
最为值得关注的是 int4 超低精度配置下的性能表现。VisionPlaid + SageAttention 在单卡上达到了 2.0 倍的加速,在双卡上甚至能达到 2.7 倍,这意味着用户可以在消费级显卡上实现图片和视频的实时或准实时生成,同时显著降低推理成本。这对于没有高端 GPU 资源的开发者和企业而言,具有重要的实际意义,使其能够以更低的投入成本部署和运营 AI 生成应用。
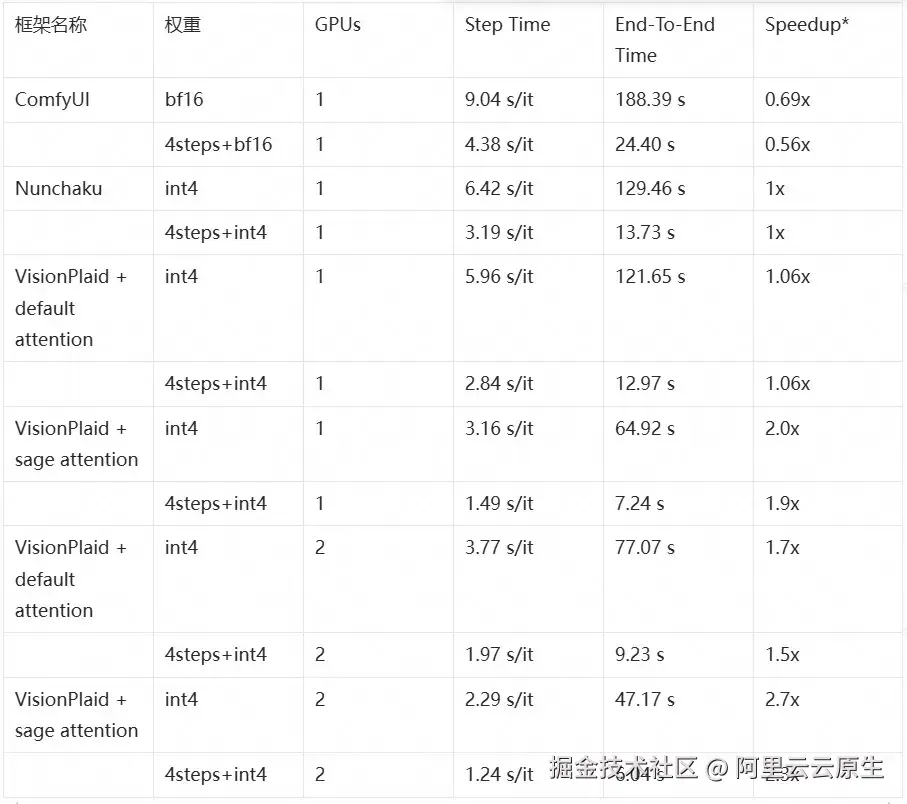
测试环境:Qwen-Image-Edit-2509,4090,20 steps or 4 steps,1440x1920,ComfyUI 默认启动参数
注:4-step 配置中使用了 CFG=1.0 的推荐配置; Speedup 分别以 Nunchaku 的两个结果为基准,即 int4 以 int4 为基准,4steps+int4 以 4steps+int4 为基准;** VisionPlaid 的一个优势在于默认可以无重启切换 SageAttention,适合一些长期运行,workload 不固定的 ComfyUI 服务(比如阿里云 FC),这个配置利用了这一点。*
在 FunArt 中使用 VisionPlaid
FunArt 对 VisionPlaid 做了深度集成,包括:
- 集成 VisionPlaid
- 提供 VisionPlaid 示例工作流
- 提供示例工作流所需模型数据
- 集成示例工作流所需依赖包
用户可以以开箱即用的方式使用 VisionPlaid。当前还处于邀测阶段,请加入客户钉群:32245557,添加 VisionPlaid 白名单。
创建FunArt项目
- 登录 FunArt 控制台(functionai.console.aliyun.com/funart/cn-h... ),在右上角切换您希望的地域;
-
切换到项目 tab,选择创建新项目;
-
在新打开的创建新项目页面。
- 第一步选择项目类型为 ComfyUI
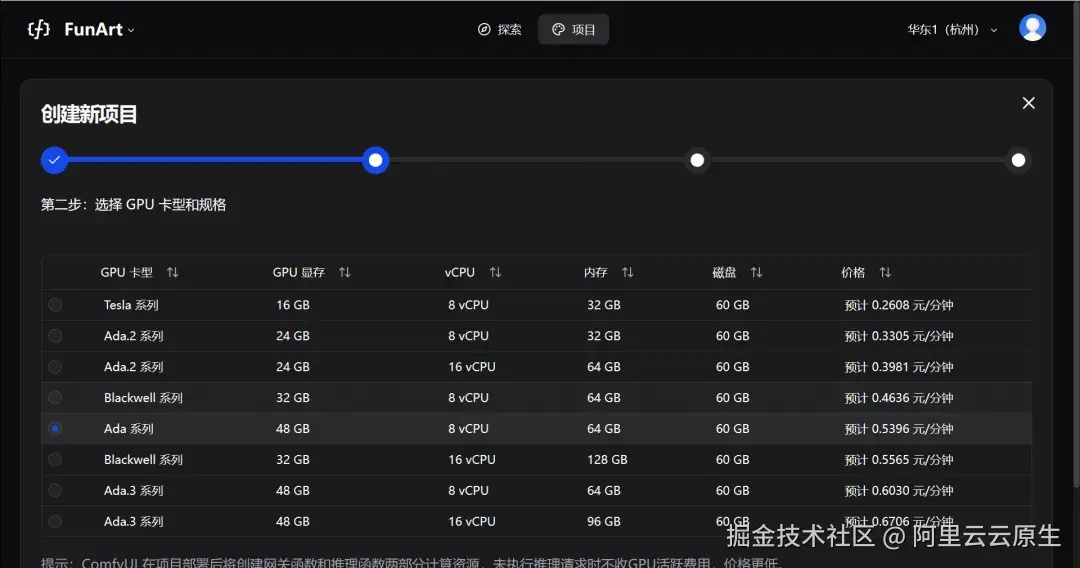
- 第二步选择 GPU 卡型和规格为 Ada.* 系列或者 Blackwell 系列
- 第三步配置其他项目属性 ,输入您希望的项目名称 ,选择您希望的地域 ,加速引擎 选择 VisionPlaid,其他保持默认配置即可
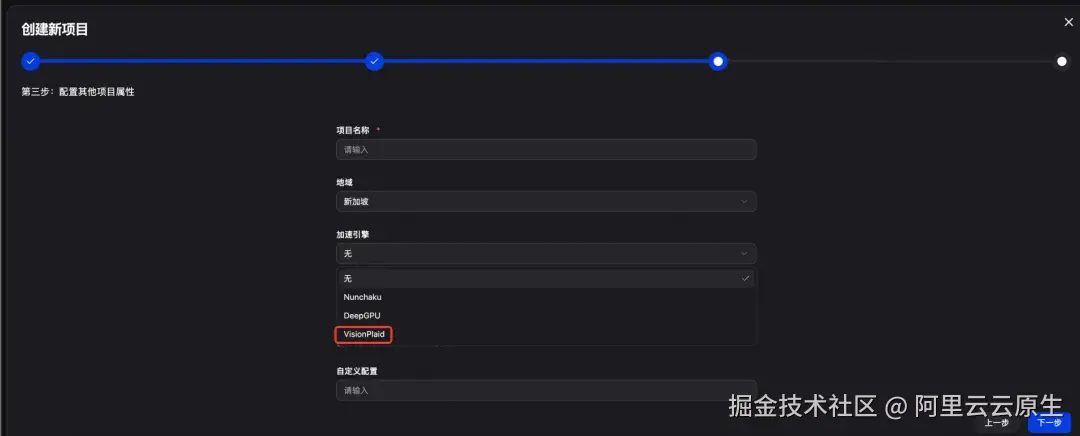
- 第四步在确认并完成创建 页面,点击确认部署,等待项目创建完成
运行示例工作流
- FunArt 项目创建完成后,在打开的项目页面里,选择项目开发/工作站/Workflows,可以看到 FunArt 已经内置了几个 VisionPlaid 示例工作流;
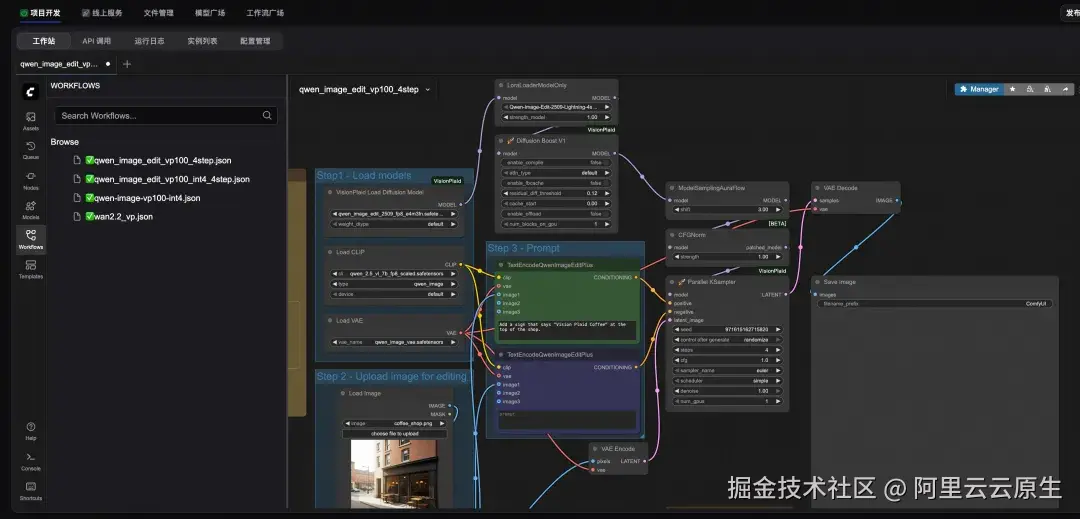
- 选择您想要运行的工作流,点击右上角的 Run 按钮,就可以开始运行推理了。
总结
VisionPlaid 通过序列并行加速、原生生态兼容和智能显存管理等创新技术,为用户带来了性能与易用性的完美结合。
无论是需要实时交互的应用场景,还是对生成质量有高要求的长流程任务,FunArt 结合 VisionPlaid 都提供了最优的解决方案。用户无需进行复杂的配置或优化,仅需几次点击就能启动一个高性能的 AI 生成服务,充分体现了 FunArt 的"开箱即用"。
了解更多:
FunArt 快速入门
help.aliyun.com/zh/function...
FunArt 自定义部署