2025 ICLR
摘要
大型多模态模型(LMM)依靠 Transformer 解码器中文本词元和视觉词元之间的**注意力机制**来"看懂"图像。理想情况下,这类模型应当聚焦**与文本词元相关的关键视觉信息**。 然而,现有研究发现:大型多模态模型往往存在一种明显倾向------会持续对某些特定视觉词元分配很高的注意力权重,即便这些视觉词元与对应的文本内容无关。本文围绕这类无关视觉词元的形成原因展开探究,并分析其特征。研究表明,该现象源于模型部分隐藏状态维度被过度激活,与大语言模型中存在的**注意力沉底(attention sink)**现象相似。因此,我们将这一现象命名为**视觉注意力沉底(visual attention sink)**。 分析还发现:尽管这些无关的视觉沉底词元获得了很高的注意力权重,但剔除它们**并不会影响模型性能**。基于这一点,我们将分配到这类词元上的注意力视作冗余资源,重新调配注意力额度,增强模型对图像有效区域的聚焦能力。 为此,本文提出**视觉注意力重分配方法(Visual Attention Redistribution, VAR)**。该方法针对天然偏向视觉感知的**图像注意力头**进行注意力重整。VAR 可无缝适配各类大型多模态模型,在**无需额外训练、无需引入附加模型、不增加推理步骤**的前提下,普遍提升模型在通用图文任务、缓解视觉幻觉任务、纯视觉任务上的效果。 实验结果表明:VAR 通过调整模型内部的注意力分布,让大型多模态模型能够更高效地处理视觉信息,为增强多模态模型的综合能力提供了一条全新思路。
1 引言
大型多模态模型(LMM)正在不断拓展大语言模型的能力边界,使其能够处理各类多模态任务(Liu 等人,2024c;a;b;Li 等人,2023b;Bai 等人,2023)。具体而言,大型多模态模型依托**预训练视觉编码器**(Radford 等人,2021)处理图像数据,并利用大语言模型的 Transformer 解码器生成文本回复(OpenAI,2023;Touvron 等人,2023;Yang 等人,2024)。这种结构简洁且性能强大,能够高效提取图像中的视觉信息,广泛应用于视觉问答、图像描述、视觉推理等图文任务(Peng 等人,2023;Alayrac 等人,2022;Tsimpoukelli 等人,2021)。 为了将视觉信息融入文本生成过程,大型多模态模型依赖 Transformer 解码器中的**注意力机制**(Vaswani 等人,2017)。在处理多模态输入时,文本词元与视觉词元之间的注意力权重,决定了每个文本词元对对应视觉信息的关注程度。
例如,如图1左上角所示,当生成文本词元"鸟"时,模型会聚焦图像中与鸟相关的视觉词元。从直观角度来看,大型多模态模型理应只关注与文本词元相关的视觉词元。 但在实际推理中,模型的注意力并非全部投向有效视觉词元。如图1所示,模型会对**无关视觉词元**分配过高的注意力权重。该现象在各类大型多模态模型中普遍存在(Woo 等人,2024;An 等人,2024),且呈现固定规律:无论生成何种文本词元,无关视觉词元始终集中在固定位置(图1红框标注部分)。目前,该现象的成因与作用尚不明确,这也构成了本文的研究动机。 本文深入探究无关视觉词元的内在特性与分布规律。研究发现:视觉注意力图中的无关词元,源于模型隐藏状态中部分维度的过度激活。该机制与大语言模型中的**注意力沉底(attention sink)**高度相似------模型会过度关注语义价值极低的词元(如起始符、句号、换行符等)(Xiao 等人,2023;Sun 等人,2024a)。这类无关视觉词元的特征是少数维度数值异常突出,且几乎不含图像有效语义,因此本文将其定义为**视觉沉底词元**。
实验同时证明:尽管模型分配了高额注意力,去除视觉沉底词元并不会降低模型生成质量。 基于上述结论,本文提出:分配给沉底词元的注意力可作为**冗余注意力资源**进行复用。现有研究表明,大型多模态模型普遍存在"重文本、轻图像"的问题,对图像的注意力投入不足(Chen 等人,2024;Liu 等人,2024d)。为此,我们将沉底词元的冗余注意力重新分配至图像区域。同时,考虑到不同注意力头各司其职(Zheng 等人,2024),本文根据视觉注意力沉底分布,筛选出专注视觉感知的**图像专属注意力头**。最终,提出**视觉注意力重分配方法(VAR)**,分为两步:筛选图像专属注意力头、在对应注意力头内重分配注意力,强化模型对图像的聚焦能力。
综上,本文揭示了无关视觉词元的本质规律,证明其与大语言模型的沉底词元一致,属于无效冗余资源。基于此提出 VAR 方法,回收沉底词元的注意力,提升模型对图像的关注度。实验表明,VAR 能够全面提升模型在通用图文任务、缓解视觉幻觉任务、纯视觉任务上的性能。该方法**无需额外训练、无需新增模型、不增加推理开销**,可直接适配各类大型多模态模型,有效解决图像注意力不足的痛点,也为理解多模态模型的注意力机制提供了全新视角。
2 相关工作
大型多模态模型中的视觉注意力 在大型多模态模型中,图文交互注意力是融合视觉信息的核心,模型对图像的关注程度通常由**视觉注意力图**表征(Aflalo 等人,2022;Stan 等人,2024)。但现有研究发现,大型多模态模型的视觉注意力存在诸多不合理现象:模型容易过度聚焦少量视觉词元(Woo 等人,2024;Arif 等人,2024),部分词元无论对应何种文本,都会获得高额注意力(An 等人,2024);同时,模型整体对视觉信息的关注力度普遍不足(Chen 等人,2024;Liu 等人,2024d)。 针对该问题,研究者提出**视觉对比解码**(Leng 等人,2024;Favero 等人,2024):对比有无图像输入的模型输出,引导模型依赖视觉信息。还有部分工作通过提升图像注意力权重,保证视觉信息被充分关注(Zhang 等人,2024b;Zhu 等人,2024)。 ### 大语言模型中的注意力沉底 注意力沉底是大语言模型中的经典现象:语义贫乏的词元(起始符、标点、换行符等)会被分配异常高的注意力权重(Xiao 等人,2023;Ferrando & Voita,2024)。视觉 Transformer 中的背景无效词元也存在同类现象(Darcet 等人,2023),说明注意力沉底是跨模态的共性问题。 沉底词元虽然占用大量注意力,但对模型预测几乎无贡献(Kobayashi 等人,2020;Bondarenko 等人,2023)。研究证实,注意力沉底源于沉底词元隐藏状态部分维度的过度激活(Sun 等人,2024a;Cancedda,2024)。Gu 等人(2024)进一步分析了注意力沉底的诱因;Yu 等人(2024)通过校正特定注意力头的沉底权重,提升了大语言模型的生成精度。本文将注意力沉底概念拓展至多模态领域,首次提出大型多模态模型中的**视觉注意力沉底**。
3 准备知识 (Preliminaries)
多模态大模型(LMMs)通常由视觉编码器(Visual Encoder) 、**投影层(Projector)和大语言模型(LLM)**组成。视觉编码器和投影层负责从图像中提取视觉特征,并将其投影为与文本对齐的表示形式。
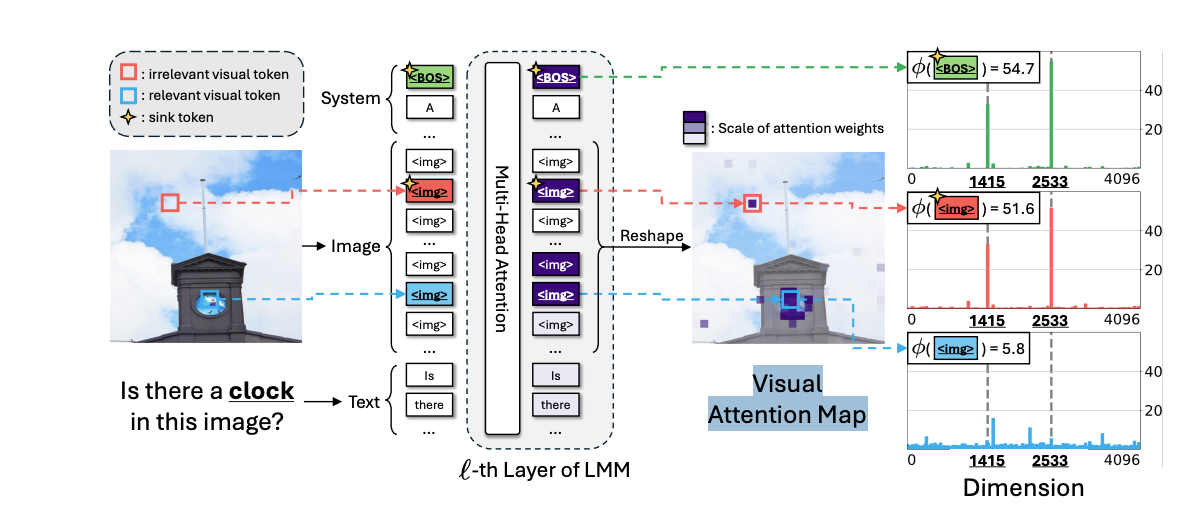 图 2 展示了大语言模型(LMM)的典型架构以及对**视觉注意力汇聚(Visual Attention Sink)现象的调查。大模型接收图像和文本作为输入。在 Transformer 解码器中,每个文本 Token 通过注意力机制与视觉 Token 进行交互。我们可以将这种交互以注意力图(Attention Map)**的形式进行可视化。
图 2 展示了大语言模型(LMM)的典型架构以及对**视觉注意力汇聚(Visual Attention Sink)现象的调查。大模型接收图像和文本作为输入。在 Transformer 解码器中,每个文本 Token 通过注意力机制与视觉 Token 进行交互。我们可以将这种交互以注意力图(Attention Map)**的形式进行可视化。
我们发现,注意力图中那些无关的视觉 Token(图中红色框标记)在隐藏层状态(Hidden States)的特定维度上具有极大的激活值;而相关的视觉 Token(图中蓝色框标记)则没有这种现象。语言模型中众所周知的汇聚 Token(例如 'BOS',即起始符)在隐藏层状态中也表现出完全相同的模式。
如图 2 左侧所示,大语言模型接收三类输入:(1) 系统指令 ,(2) 来自图像的视觉特征 ,以及 (3) 包含用户查询和前文语境的文本 。随后,模型以自回归的方式生成响应。在本文中,我们将输入到大语言模型的离散输入及其内部的嵌入(embeddings)统称为 Token。
设系统 Token、视觉 Token 和文本 Token 的索引分别表示为 ,它们是所有输入 Token 索引集合 I 的子集。输入数据通过 L 个 Transformer 块进行处理,每个块由**多头注意力机制(MHA)和前馈网络(FFN)**组成:
其中,是第
层中第 i 个 Token 的输入,而
分别是 MHA 和 FFN 的输出。
现在我们重点关注 MHA,它实现了不同 Token 之间的交互。参考 Elhage 等人 (2021) 的研究,单个输入 与之前的 Token 序列
的交互方式如下:
其中, 是输出投影矩阵,
分别是查询(Query)和键(Key)的投影矩阵。
是从
到
的注意力权重 (满足
)。公式 (2) 表明,注意力权重
可以解释为 LMM 在处理
时对
的关注程度。
由于我们研究的是文本 Token 如何与视觉 Token 交互以生成响应,因此我们重点关注从视觉到文本 Token 的注意力权重 ,即 ,并以**视觉注意力图(Visual Attention Map)**的形式对其进行考察。
4 视觉注意力沉底
在大型多模态模型(LMM)中,为了生成融合视觉信息的回答,文本词元依靠 Transformer 解码器中的**注意力机制**来"观察"图像。由视觉词元(键)指向文本词元(查询)的注意力,表示该文本词元对对应视觉信息的关注程度。 基于这一定义,可以通过**视觉注意力图**分析从视觉词元到文本词元的注意力权重,直观反映多模态模型中文本词元与视觉词元之间的交互关系。图1展示了指定文本词元与视觉词元之间的视觉注意力分布。理想情况下,模型应当仅关注与文本词元相关的视觉词元。 但已有研究发现(Woo 等人,2024;An 等人,2024),模型同时会关注一部分**无关视觉词元**。例如,如图1右上方所示,在生成词元"香蕉"时,模型仍对与香蕉无关的视觉词元(红框)分配了很高的注意力权重。并且,无论生成何种文本词元,这些无关视觉词元始终出现在固定位置。这一稳定规律说明:无关视觉词元的出现源于其固有的内在特性。本文重点探究这类无关视觉词元的形成机理,以及它们在多模态模型中的作用。 后续实验表明,视觉注意力图中的无关视觉词元,来源于**隐藏状态中部分维度的过度激活**。该现象与大语言模型中的**注意力沉底**高度相似(Xiao 等人,2023;Sun 等人,2024a)------模型会对语义含量极低的词元(如起始符 BOS)分配异常高的注意力。因此,本文将该现象命名为**视觉注意力沉底**,并进一步分析其特征。
4.1 探究无关视觉 Token 的属性
我们将视觉注意力图中具有高注意权重的视觉 Token 分为两类:无关视觉 Token (Irrelevant visual tokens)和相关视觉 Token(Relevant visual tokens)。无关视觉 Token 指的是与对应文本 Token 无关的视觉 Token。相比之下,相关视觉 Token 则是指与对应文本 Token 相关的视觉 Token。图 2 分别用红色和蓝色方框展示了无关和相关视觉 Token 的示例。
如何区分无关视觉 Token? 我们的研究重点在于,无论文本 Token 为何,无关视觉 Token 总是持续出现在固定的位置。如图 1 左下角所示,无论文本 Token 是"刀"还是"杯子",模型始终关注相同的无关视觉 Token。这一观察表明,无关视觉 Token 的出现并非由于文本 Token 的驱动,而是其自身固有属性的结果。因此,我们检查了无关 Token 的隐藏层状态(Hidden States),以探究其独特的属性。图 2 右侧显示了无关视觉 Token(红色)、相关视觉 Token(蓝色)以及"BOS" Token(绿色)的隐藏层状态。
无关视觉 Token 在特定维度上具有极高的激活值。 我们观察到,无关视觉 Token 的隐藏状态在特定维度上表现出巨大的激活,而相关视觉 Token 则没有。此外,在无关视觉 Token 中高度激活的维度与"BOS" Token 的激活维度完全一致,而"BOS"被认为是语言模型中典型的汇聚(Sink)Token(Sun 等人,2024a)。这一观察表明,无关视觉 Token 与注意力汇聚(Attention Sink)密切相关。
汇聚维度(Sink Dimensions)的形式化定义 为了进一步扩展和规范这一观察,我们检查了 Token 隐藏状态中特定维度(称为汇聚维度 D_{sink})的巨量激活值。D_{sink} 是由 LMM 的基础语言模型决定的固定维度集合。例如,作为 LLaVA-1.5-7B(Liu 等人,2024a)基础语言模型的 LLaMA2(Touvron 等人,2023),其 。我们在附录 A.1 中验证了 LMM 中的汇聚维度与基础语言模型中的一致,并使用了 Sun 等人(2024a)报告的汇聚维度。
给定一个 Token 的隐藏状态 x \\in \\mathbb{R}\^D,我们定义其汇聚维度值 \\phi(x) 如下:
其中 x\[d\] 是隐藏状态的第 d 个维度。为了稳定性,隐藏状态经过了维度的均方根(RMS)归一化,且我们只考虑汇聚维度中的最大值。如图 2 最右侧所示,无关视觉 Token(红色)的汇聚维度值显著高于相关视觉 Token(蓝色)。
利用汇聚维度值分离 Token 汇聚维度值可以将无关视觉 Token 与相关视觉 Token 区分开来。我们引入汇聚维度值来识别这两者。对于视觉 Token,我们在图 3(a) 中绘制了汇聚维度值与对应注意力权重的成对数值关系。详细的实验设置见附录 D.3。具有高注意力权重的视觉 Token 在汇聚维度值的分布上明显分为两组:一组具有较低的汇聚维度值,另一组具有较高的汇聚维度值。基于此分析,我们现在将具有高汇聚维度值的视觉 Token 定义为视觉汇聚 Token(Visual Sink Tokens) ,并指出它们与语言模型中的注意力汇聚紧密相关。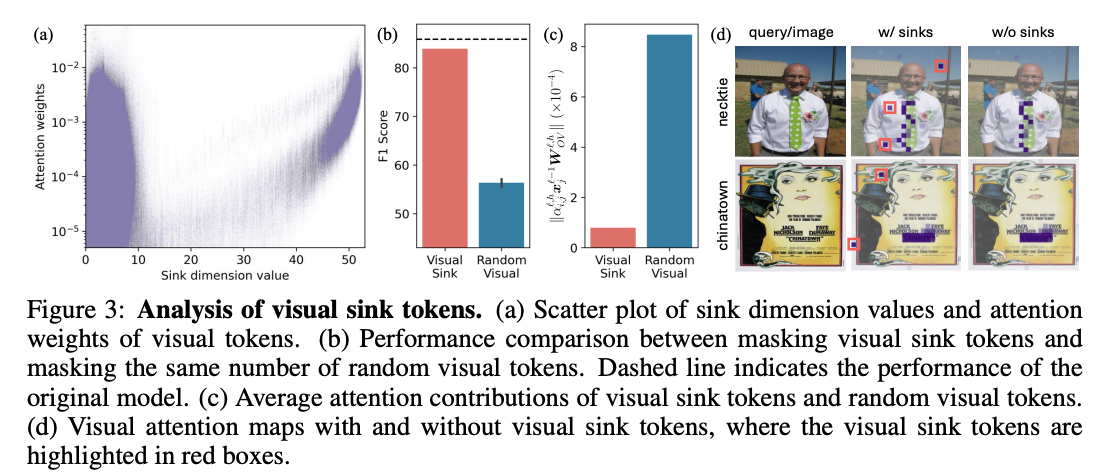
具体而言,我们设定一个阈值 \\tau 来划分图 3(a) 中的分布,并将汇聚 Token 的索引定义为 ,其中
是第 \\ell 层中第 j 个 Token 的输入隐藏状态。在随后的分析中,我们设定 \\tau = 20。我们注意到,I_q\^\\ell 的定义涵盖了所有汇聚 Token 的索引,包括视觉和文本 Token。我们将视觉汇聚 Token 表示为
,其中 I_{vis} 是视觉 Token 索引的集合。为方便起见,我们将其他视觉 Token 称为视觉非汇聚 Token(Visual Non-sink Tokens) ,并表示为
。虽然视觉汇聚 Token I_{q,vis}\^\\ell 的定义也包含了如图 3(a) 所示的低注意力权重 Token,但由于它们的注意力权重较低,对模型的贡献极小。因此,我们在随后的分析中可以忽略它们。
4.2 分析视觉沉底词元的特征
接下来,我们分析视觉沉底词元的特征。具体而言,通过实验验证:视觉沉底词元与大语言模型中的沉底词元具有相似性质。已有研究表明,语言模型中的沉底词元几乎不会影响模型输出结果(Kobayashi 等人,2020;Bondarenko 等人,2023;Yu 等人,2024;Gu 等人,2024)。 本文从两个角度验证视觉沉底词元是否同样对模型输出无贡献:
(1)屏蔽视觉沉底词元,测试模型性能变化;
(2)量化视觉沉底词元对残差链路的机理贡献。
**词元屏蔽实验** 为评估视觉沉底词元对模型输出的影响,我们屏蔽从视觉沉底词元流向文本词元的注意力,使模型无法接收来自视觉沉底词元的任何信息。如图3(b)所示,屏蔽视觉沉底词元后,模型性能几乎没有下降;而随机屏蔽同等数量的普通视觉词元,会导致性能显著衰减。这证明:视觉沉底词元对模型生成结果几乎没有贡献。
**贡献度分析** 我们进一步分析视觉沉底词元在残差链路中的内在贡献。实验计算视觉沉底词元对文本词元残差链路的注意力贡献值,计算公式为 (其中 i 为文本词元、j 为视觉词元,推导见公式2)。如图3(c)所示,相比于普通视觉词元,视觉沉底词元对残差链路的注意力贡献显著更低。同时,如图3(d)所示,基于定义筛选出的视觉沉底词元,可以精准过滤无关视觉信息。
**关于视觉注意力沉底的拓展讨论** 为深入探究视觉注意力沉底现象,附录 A.2 补充了更多实验与特征分析,核心结论如下:
(1)视觉沉底词元大多分布在信息量较低的图像背景区域,与视觉 Transformer 的研究结论一致(Darcet 等人,2023)。同时,语言模型的沉底词元也属于低语义词元(逗号、换行符等)(Ferrando & Voita,2024;Yu 等人,2024),二者规律高度吻合。
(2)视觉沉底词元与文本沉底词元,会在**同一特征维度 D_{\\text{sink}}** 产生高强度激活。这说明:视觉沉底与文本沉底同源,底层机理继承自基础大语言模型。 综上,低语义的视觉词元会被多模态模型判定为视觉沉底词元,行为特征与语言模型一致。关于训练过程中模型如何识别沉底词元,将作为后续研究方向。
4.3 视觉注意力沉底中的冗余注意力:是否可以复用?
实验证明:视觉沉底词元虽然占用高额注意力权重,但对模型输出毫无贡献。由此启发我们:分配给沉底词元的注意力属于**闲置资源**,可作为"注意力配额"进行回收复用。 现有研究指出:多模态模型普遍存在"重文本、轻图像"的问题,对图像的注意力投入不足,导致图文任务效果受限(Chen 等人,2024;Liu 等人,2024d)。利用回收的注意力配额补充图像注意力,即可缓解该问题。 此外,视觉沉底词元还可用于判别有效图像区域。视觉沉底词元仅有高注意力、无匹配语义;反之,**非沉底视觉词元**更贴近图像真实有效内容。因此,可根据词元的注意力分布,筛选出天然聚焦图像的专属注意力头,相关方法将在下一节展开。
5 视觉注意力重分配
结合第 4.3 节的分析,本章提出**视觉注意力重分配方法(Visual Attention Redistribution, VAR)**,用于增强大型多模态模型对图像的聚焦能力。该方法分为两步: (1)基于视觉注意力沉底筛选**图像专属注意力头**(见 5.1 节); (2)仅在选中的注意力头中,将沉底词元的注意力配额重新分配给有效非沉底视觉词元(见 5.2 节)。
VAR 的整体流程如图 5 所示。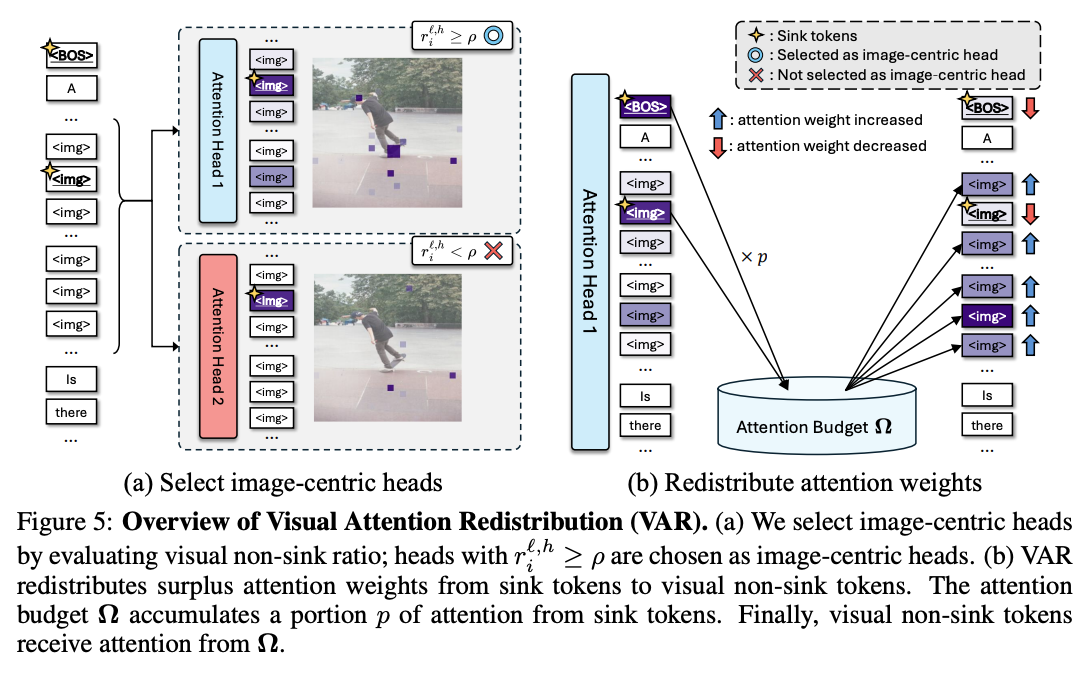
5.1 筛选图像专属注意力头
第 4 节指出,可以回收沉底词元的注意力,弥补模型对图像注意力不足的问题。但实验发现:如果对**所有注意力头**都进行重分配,模型性能会明显下降(见表 4)。 由于 Transformer 中每个注意力头各司其职(Deiseroth 等人,2023;Zhang 等人,2024a;Ge 等人,2024;Zheng 等人,2024),部分注意力头并不负责图文交互。因此,在重分配之前,需要先筛选出专门用于感知图像的**图像专属注意力头**。 本文利用**视觉注意力沉底**筛选图像专属注意力头: 首先,剔除对视觉词元总注意力小于 0.2 的注意力头(这类头基本不关注图像)。 其次,进一步结合视觉沉底特征筛选:有些头虽然对视觉词元总注意力很高,但大部分集中在无意义的沉底词元,并非真正关注有效图像内容。 根据第 4.3 节结论,**非沉底视觉词元所占注意力比例**,能够反映注意力头对有效视觉信息的关注程度。沿用第 3 节符号,定义**视觉非沉底占比**:
其中,表示全部视觉词元集合,
表示非沉底视觉词元集合。 若 r_{i}\^{\\ell,h} 越高,说明第 \\ell 层第 h 个注意力头越关注有效视觉信息。 **高非沉底占比 → 聚焦关键区域** 为验证该指标有效性,图 4 根据非沉底占比对注意力头排序并可视化: 非沉底占比高的头,更容易集中关注与文本相关的关键视觉区域; 非沉底占比低的头,注意力散乱、分布稀疏。 本文选取满足 r_{i}\^{\\ell,h}\\ge \\rho 的头作为图像专属注意力头,其中 \\rho 为超参数,用于控制筛选数量。筛选过程见图 5(a)。图像专属注意力头的更多特性见附录 A.3。
5.2 注意力权重重分配
筛选出图像专属注意力头后,仅在这些头内部,将沉底词元的注意力转移到非沉底视觉词元,流程见图 5(b)。 首先,提取沉底词元中比例为 p(0\\le p\\le1)的注意力,存入**注意力配额** \\Omega: 沉底词元新注意力: 收集冗余注意力:
下文省略层数和头数上标。 随后,将配额
按原有相对权重,加成分配给非沉底视觉词元。参考 Yu 等人(2024),更新后的非沉底词元注意力为:
该方式保证重分配后注意力总和仍为 1(\\sum\\limits_{j\\le i}\\alpha'_{i,j}=1),不破坏整体分布。 该重分配规则适用于所有文本词元,包括指令词元和生成词元。