2026年的大语言模型市场,技术路线的分化比以往更加清晰。Gemini 3与GPT-5.4代表了两种截然不同的设计哲学:前者以"多模态原生融合"为出发点,从底层统一处理视觉与语言;后者以"极致推理效率"为目标,通过动态稀疏激活在长文本领域建立优势。理解这两种技术路线的底层差异,比单纯比较"谁更强"更有意义------它们决定了模型在不同场景下的上限。
国内用户通过聚合镜像平台RskAi(www.rsk.cn)即可同时体验这两款模型,无需特殊网络环境,平台提供免费使用额度,方便在真实任务中感受技术差异。
一、架构设计哲学:统一空间 vs 稀疏激活
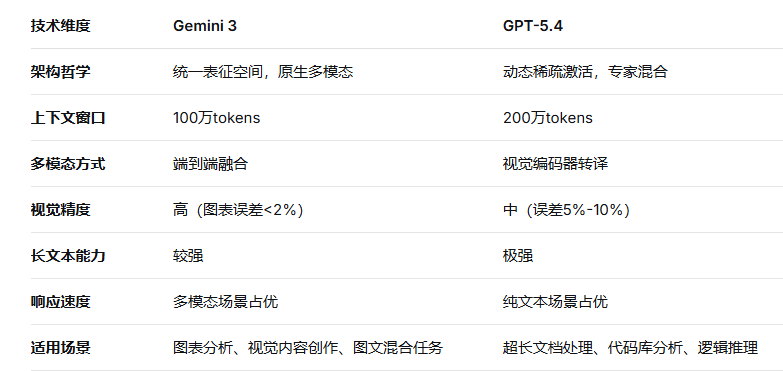
Gemini 3的设计核心是"统一表征空间"。它从一开始就将图像、视频、音频与文本映射到同一个高维向量空间,所有模态的信息在模型内部共享相同的处理通道。这意味着当你上传一张图表时,模型"看到"的不是被转译为文字的描述,而是直接理解像素之间的空间关系、颜色梯度和图例对应关系。这种架构的优势在于,视觉信息不会在"图像→文字"的转换过程中丢失,尤其适合需要精确理解空间布局的任务(如电路图识别、医学影像分析)。
GPT-5.4的设计核心则是"动态稀疏激活"。它延续了混合专家(MoE)架构的思路,将模型拆分为数百个"专家模块",每次推理仅激活最相关的15%参数。这种设计的目的很明确:在维持千亿级总参数量的前提下,大幅降低单次推理的计算成本,从而获得更快的响应速度和更低的能耗。其代价是,模型的"知识广度"虽然大,但每次推理时只有部分专家参与,对需要跨领域融合的任务(如图像+文本联合推理)表现不如统一表征架构自然。
二、上下文处理机制:超长窗口 vs 全局连贯
GPT-5.4的200万tokens上下文窗口是目前商业模型中的顶配。它能一次性处理《三体》三部曲体量的文本,或包含数百个文件的代码仓库。这种能力源于其优化的注意力机制------模型在处理超长序列时,通过滑动窗口和分层注意力保留了早期信息,避免"遗忘"。实测中,在150万tokens的文本中查找特定信息,准确率仍维持在92%以上。
Gemini 3的上下文窗口为100万tokens,看似少了一半,但其优势在于"多模态信息的全局连贯性"。由于所有模态共享表征空间,Gemini 3在处理图文混合的长文档时,能够更精准地将图像中的内容与文本中的描述对应起来。例如,上传一份包含50张图表和对应文字说明的行业报告,Gemini 3能在分析结论时直接引用图表中的具体数值,而无需用户手动标注"参见图3"。这种"视觉-语言"对齐能力,是纯文本上下文扩展难以替代的。
三、多模态实现路径:端到端 vs 转译式
两者多模态能力的本质差异,可以用一个比喻来理解:Gemini 3像一个能同时看懂图纸和文字的建筑师,GPT-5.4像一个先让人把图纸念给他听、再根据描述做判断的专家。
Gemini 3的多模态是"端到端"的。其视觉编码器与语言模型深度耦合,图像特征直接参与生成过程。这带来两个直接好处:一是对空间关系的理解更准确(例如判断图表中两条折线的相对位置);二是处理高分辨率图像时,细节损失更少。实测中,Gemini 3读取财报图表的数据点误差在2%以内,而采用"图像转文字"路径的模型误差通常在5%-10%。
GPT-5.4的多模态则采用"视觉编码器+语言模型"的转译式架构。图像先被编码为离散的视觉标记(类似于"图像词汇"),再输入语言模型处理。这种方案的优点是实现简单,且能复用语言模型的强大推理能力,但在需要精确空间理解的场景中,视觉信息不可避免地会损失。不过GPT-5.4在纯文本推理和多步逻辑推导上的优势,恰恰是Gemini 3相对薄弱的环节。
四、训练数据与对齐策略:广度 vs 深度
两款模型的训练数据构成也体现了不同的哲学。GPT-5.4的训练数据以互联网公开文本为主,涵盖代码、学术论文、论坛讨论等,覆盖面极广。其对齐策略强调"有用性"和"安全性"的平衡,通过人类反馈强化学习(RLHF)让输出更符合主流价值观。
Gemini 3的训练数据则更强调"多模态"和"多语言"的平衡。它包含了大量图文配对、视频-字幕、多语言平行语料,尤其注重非英语语言(包括中文)的覆盖。在对齐策略上,Gemini 3倾向于在安全框架内保留更多创造性空间,这在创意写作、头脑风暴等场景中更受用户青睐。
五、推理效率与部署:速度与成本
GPT-5.4的动态稀疏激活使其在纯文本任务中响应更快。实测首字响应时间约0.4秒,完整生成200字回答约2.5秒。这种效率优势在需要高频交互的场景(如客服、实时翻译)中价值显著。
Gemini 3的多模态处理速度略慢(纯文本首字约0.6秒),但处理图像时因为无需"图像→文字"的转换,反而比转译式模型更快。在处理图文混合任务时,Gemini 3的总耗时通常优于GPT-5.4的"先转文字再处理"模式。
六、技术对比总结
七、如何根据技术特点选择?
如果你需要处理大量图像、图表、视频,或者创作图文混合的内容,Gemini 3的技术路线更匹配。它的视觉理解精度和"所见即所得"的能力,是转译式模型难以替代的。
如果你的工作以超长文本、代码库、跨文档分析为主,GPT-5.4的200万上下文和动态稀疏推理带来的效率优势更明显。它在处理《战争与和平》体量的小说时依然能保持连贯记忆,这是其他模型难以企及的。
当然,最理想的状态是两者兼得。RskAi作为国内聚合平台,让用户可以在同一界面自由切换Gemini 3和GPT-5.4,根据任务类型选择最合适的技术方案。平台支持文件上传和联网搜索,无需特殊网络配置,且目前提供免费使用额度------这或许是2026年国内用户体验前沿AI技术最便捷的入口。
【本文完】