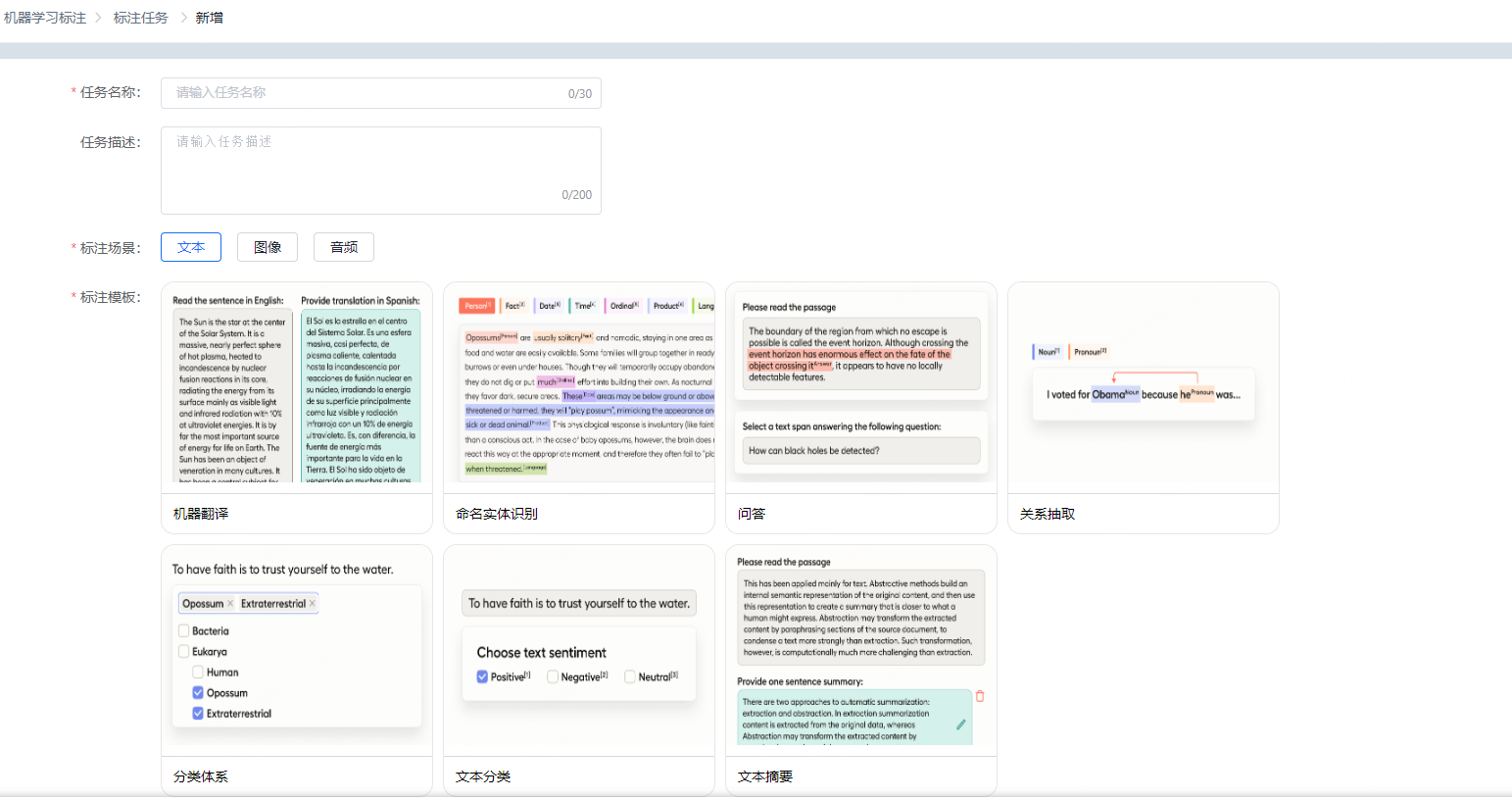
天纪标注平台TLP介绍
天纪数据标注平台,支持大模型、传统机器学习数据集标的注,包含图像、文本、视频、音频等多种数据类型的标注。内置丰富的标注模版,并提供大模型自动化标注功能,帮助用户更好的完成标注工作。
大模型数据标注介绍
数据标注是机器学习和人工智能领域中构建高质量训练数据的核心环节,尤其对大模型而言,标注数据的质量直接影响模型的性能和泛化能力。数据标注是指为原始数据添加结构化标签或注释的过程。例如:
-
文本标注:为句子添加情感标签(如"正面""负面")、实体识别(如人名、地点)或意图分类(如"查询天气")。
-
图像标注:通过框选、分割或分类标注目标物体(如行人、车辆)、场景(如"公园""街道")或关键点(如人脸关键点)。
-
音频标注:为语音数据标注关键词、语种或情感。
-
视频标注:结合时间戳和空间位置,标注动态目标的轨迹或行为(如"奔跑""摔倒")。
大模型通常需要海量标注数据来学习复杂模式,因此标注的规模和多样性至关重要。
大模型对数据标注的特殊需求
-
数据规模:大模型(如GPT、DeepSeek)依赖数十亿级标注数据,需高效标注工具和众包协作。
-
数据质量:标注需高度准确,避免噪声干扰模型学习。例如,文本标注中的歧义或图像标注中的边界偏差可能导致模型错误。
-
数据多样性:覆盖多场景、多语言、多领域,以增强模型的泛化能力。
-
标注一致性:通过标准化标注指南和审核机制,确保不同标注者对同一任务的标注结果一致。
数据标注是大模型训练的基石,其核心目标是为模型提供结构化、高质量的训练数据。随着自动化工具和众包平台的发展,数据标注效率显著提升,但仍需结合人工审核确保最终质量。未来,随着自监督学习和小样本学习技术的进步,标注需求可能向更高效、半自动化的方向演进。
机器学习注介绍
机器学习标注(Data Annotation)是为原始数据添加标签或元数据的过程,堪称监督学习模型训练的"燃料"。通过对图像、文本、音频等非结构化数据进行分类、框选、转录或语义标记,赋予机器可理解的信号,使其能从数据中学习规律并进行预测。
主流标注类型涵盖:
-
图像标注:包括 2D/3D 框选、语义分割、关键点标记,是自动驾驶、安防监控的基石。
-
文本标注:涉及实体识别、情感分析、意图分类,支撑搜索引擎与智能客服。
-
语音标注:如语音转写、说话人分离,赋能智能助手与语音交互。
标注质量直接决定模型上限,"垃圾进,垃圾出"是行业铁律。当前主要采用"人工 + 平台"模式,面临成本高、隐私保护及标准统一等挑战。
AI标注
AI 自动化标注(Auto-labeling)是利用算法模型辅助或自动生成数据标签的技术,旨在突破传统人工标注的效率瓶颈。其核心模式是"人机协同"(Human-in-the-loop),即模型预标、人工校验,而非完全取代人工。
关键技术路径包括:
-
模型预标注:利用已有模型生成初始标签,人工仅需修正错误,效率可提升数倍。
-
主动学习:算法自动筛选不确定性高、信息量大的样本供人工标注,避免无效劳动。
-
大模型赋能:借助 LLM 或 CV 基础模型的泛化能力,实现少样本甚至零样本标注,降低冷启动门槛。
优势在于大幅降低资金与时间成本,加速模型迭代闭环,尤其适合海量数据场景。但自动化并非万能,错误标签可能导致模型性能下降(误差传播),复杂场景及长尾数据仍需人工把关以确保精度
标注审核
标注审核(Annotation Review)是数据生产流程中的核心质检环节,旨在确保标注数据的准确性、一致性与合规性。作为模型训练前的"最后一道防线",其质量直接决定 AI 系统的上限,遵循"垃圾进,垃圾出"原则。
常见审核机制包括:
-
抽样复检:质检员随机抽查标注结果,计算准确率。
-
多人一致性:同一任务多人独立完成,通过交集验证可靠性。
-
自动化校验:利用脚本或规则引擎检查格式、逻辑冲突及异常值。
-
专家仲裁:针对疑难或争议样本,由资深专家进行最终判定。
审核面临的主要挑战在于主观性任务(如情感分析、语义理解)的标准统一,以及成本与效率的平衡。通常审核成本可占项目总预算的 30% 以上。若审核不严,错误标签将导致模型偏差甚至伦理风险。
未来趋势是"以模审数",利用 AI 模型辅助人工审核,自动识别低置信度数据,聚焦高风险样本。同时,建立行业通用的质检标准与合规体系,将是保障 AI 落地可靠性的关键。构建标准化、智能化的质检闭环,是实现高质量数据供给的必由之路。
AI 模型辅助人工审核(Model-Assisted Review)是将算法引入质检流程,通过"机审优先 + 人核兜底"模式提升数据质量与效率。其核心逻辑是利用模型预判数据质量,引导人工聚焦高风险样本。
主要技术手段包括:
-
置信度筛选:模型对标注结果打分,低置信度样本优先推送给人工复核,高置信度则免检或抽检。
-
异常检测:基于规则或无监督学习,识别偏离分布的异常标注(如框体过大、文本矛盾)。
-
交叉验证:使用不同模型对同一数据进行推理,结果不一致时触发人工仲裁。
该模式优势显著,大幅降低全量人工审核成本,将人力集中于难例(Hard Cases),提升整体质检吞吐量。同时,审核过程中产生的修正数据可反哺模型,形成"数据 - 模型"正向循环。
落地经验
机器学习标注的原始数据一般是非结构化的,所有平台需要存储用户上传的图片、word、pdf、音频等文件。在标注开始之前,原始数据需要进行清洗、转换和存储。
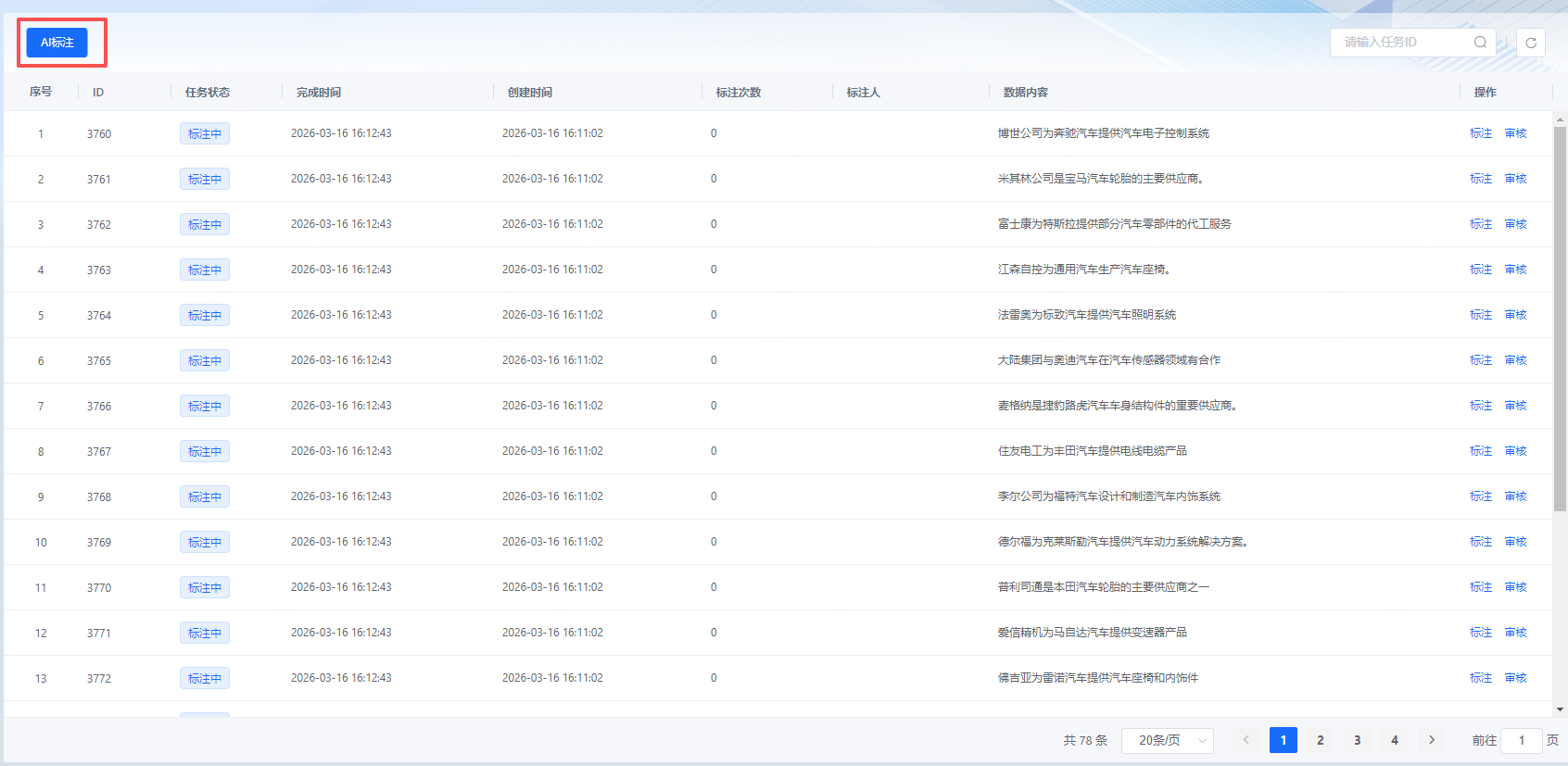
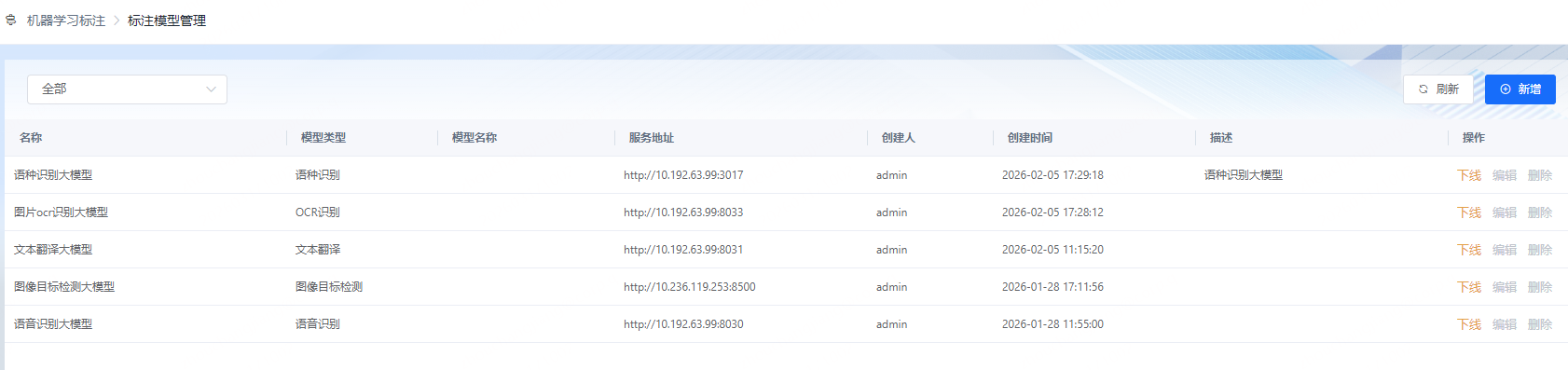
创建标注任务前,用户可先配置AI标注所用的模型(平台已有预置模型)。创建标注任务后,在标注任务页面,点击"AI标注",平台会自动将该任务下所有的数据自动进行标注,用户可手动停止标注过程,极大的提升了用户体验。