1、知道多少种测试用例设计方法
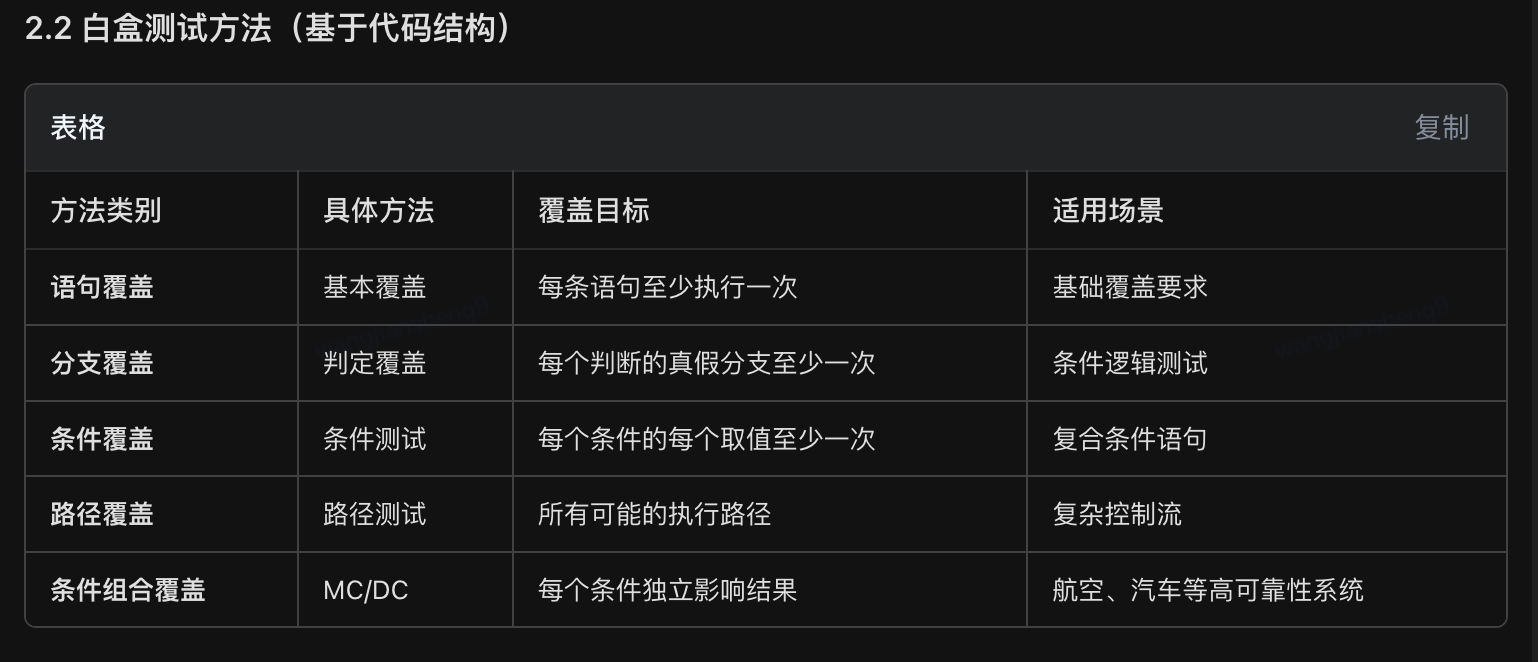
测试用例设计方法主要分为黑盒测试 、白盒测试 和灰盒测试 三大类,具体方法超过20种,以下是系统化分类与详解。
python
黑盒方法关注功能正确性
白盒方法关注代码质量
灰盒方法关注集成与交互
现代方法关注自动化与智能化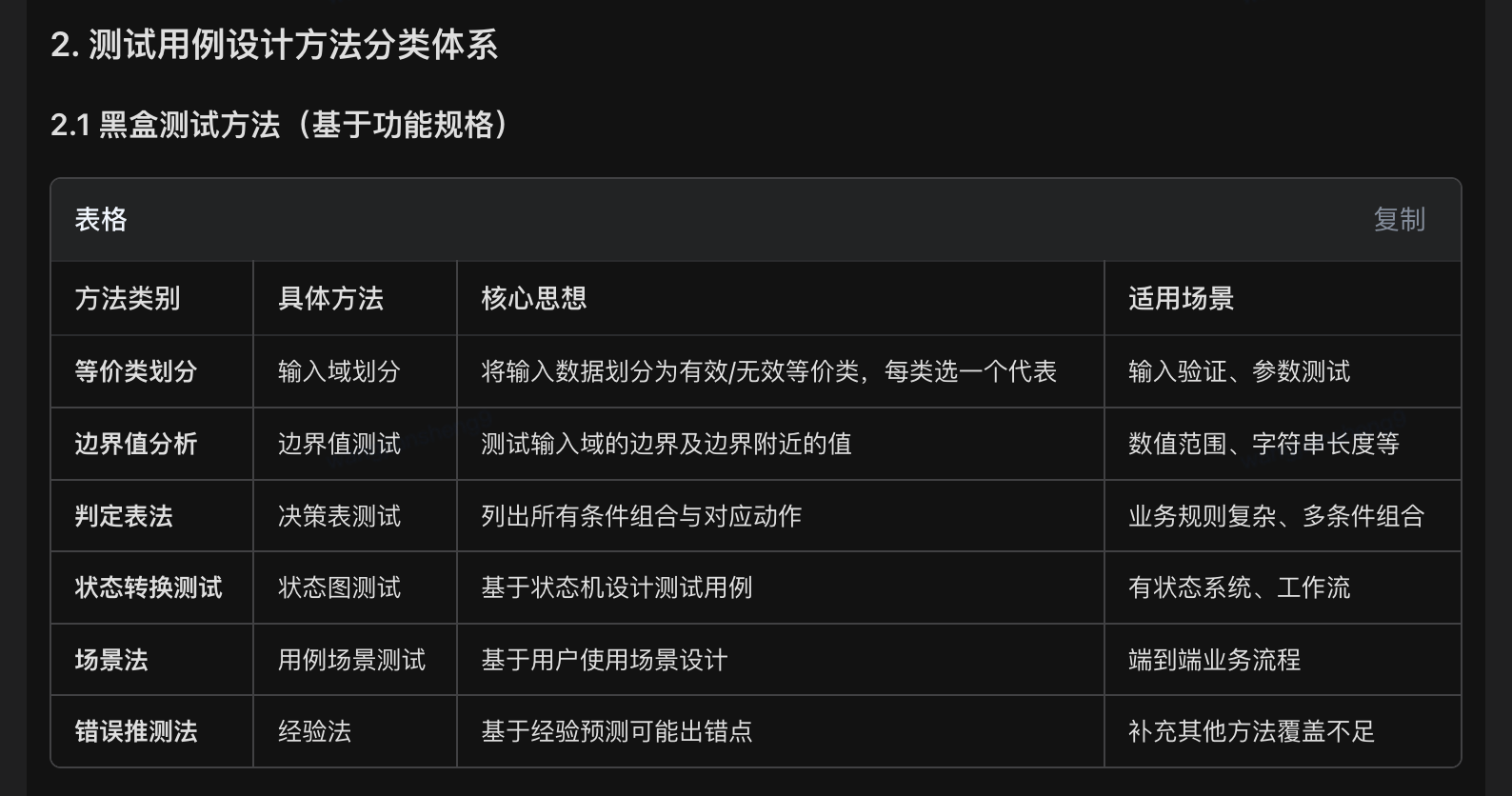

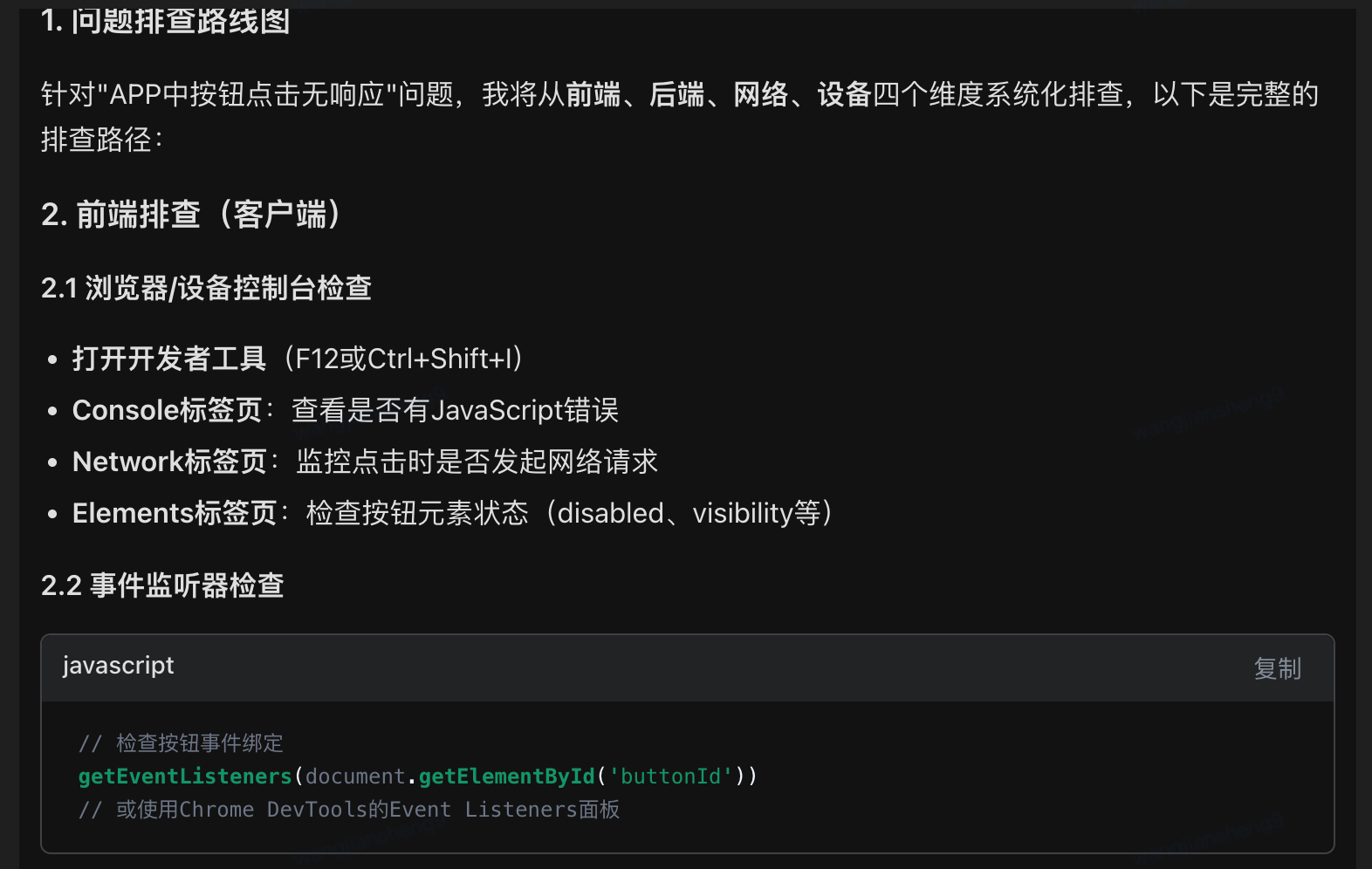
2、APP中按钮点击无响应,如何排查



3. 整个测试组大概多少人
python
我们部门一共32人,分布在6条业务线里面,每条业务线里有对个产品,平均每组4~6个人。4. 5个测试对应开发有多少人
python
研发测试比,1:3~45. 5个测试做一个项目是怎么划分工作的,是否按照模块分工
python
同一产品会按模块分工,比如准入域模块、交易域模块。有对应的主要测试负责人6. 金融系统项目测试这块有什么关注的质量指标的要求
python
1、页面性能:web页面性能优化中lcp指标目标80%,目前75%
1)不能达标的原因:依赖第三方sdkjs,sdk操作页面dom;LCP无法在1.8s以内(财富前端:孙奇)
2)接口比较多,可能需要改逻辑,涉及服务端和产品
3)小程序唤起页
2、后端接口响应时间:40ms7. 离职的原因是什么
python
一方面是架构调整,分配到了新的部门,
想想,在京东也5年了,索性就直接出来挑战一些不一样的东西
获得更多的成长8. 现在找新的工作岗位,比较关注哪些方面
python
1、工作能力适配,
2、有新的挑战,能获得更多的成长9. 针对给定的APP小需求,讲述用例设计的主要思路
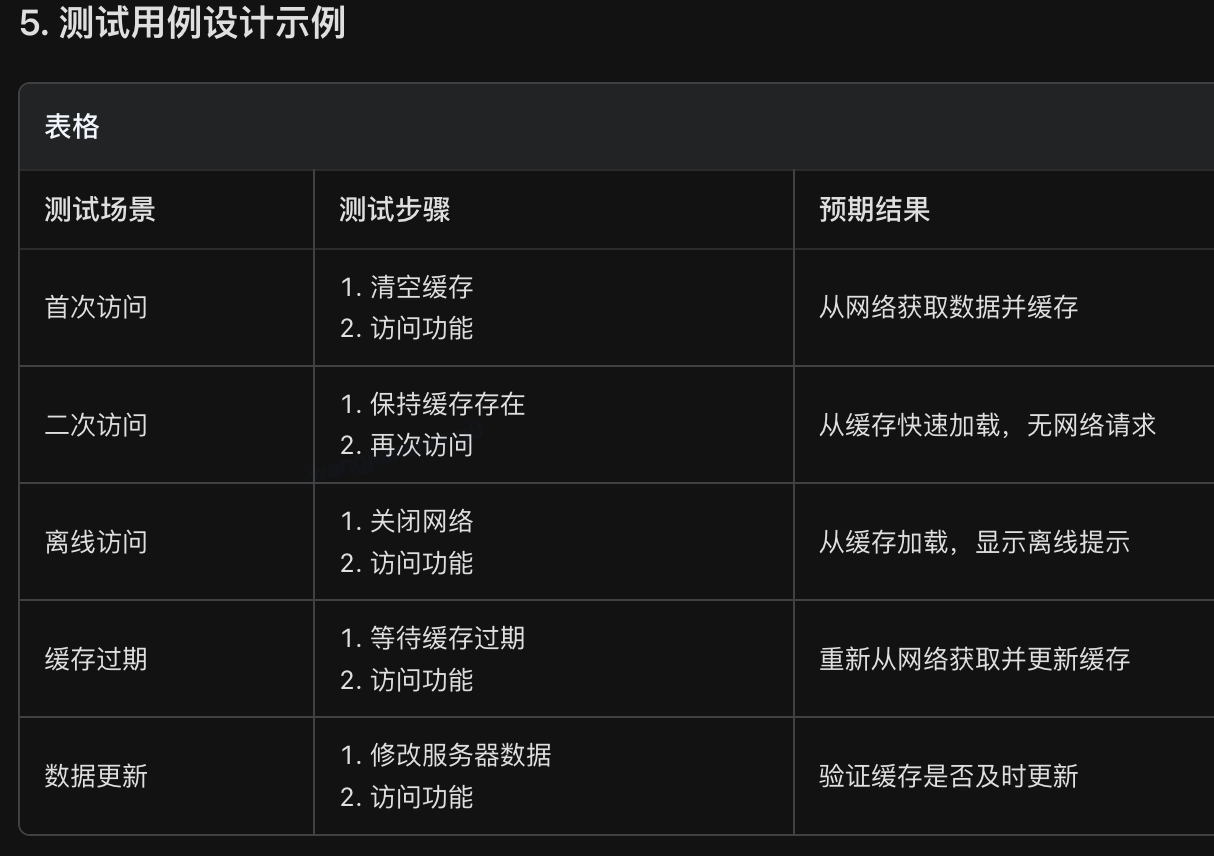
10. 如何理解需求中从本地缓存提取相关内容的这句话
python
从设备本地的存储中获取已缓存的数据,而不是每次都从远程服务器请求。
这是一种性能优化和用户体验提升的技术方案。
对于测试设计时:
1、缓存策略:何时缓存、缓存多久、缓存什么
2、数据一致性:如何保证缓存与服务器数据同步
3、用户体验:缓存状态的可视化反馈(如"离线模式"提示)
4、安全考虑:敏感数据是否适合缓存、加密存储11. 怎么去验证需求中从本地缓存提取的功能确实实现了
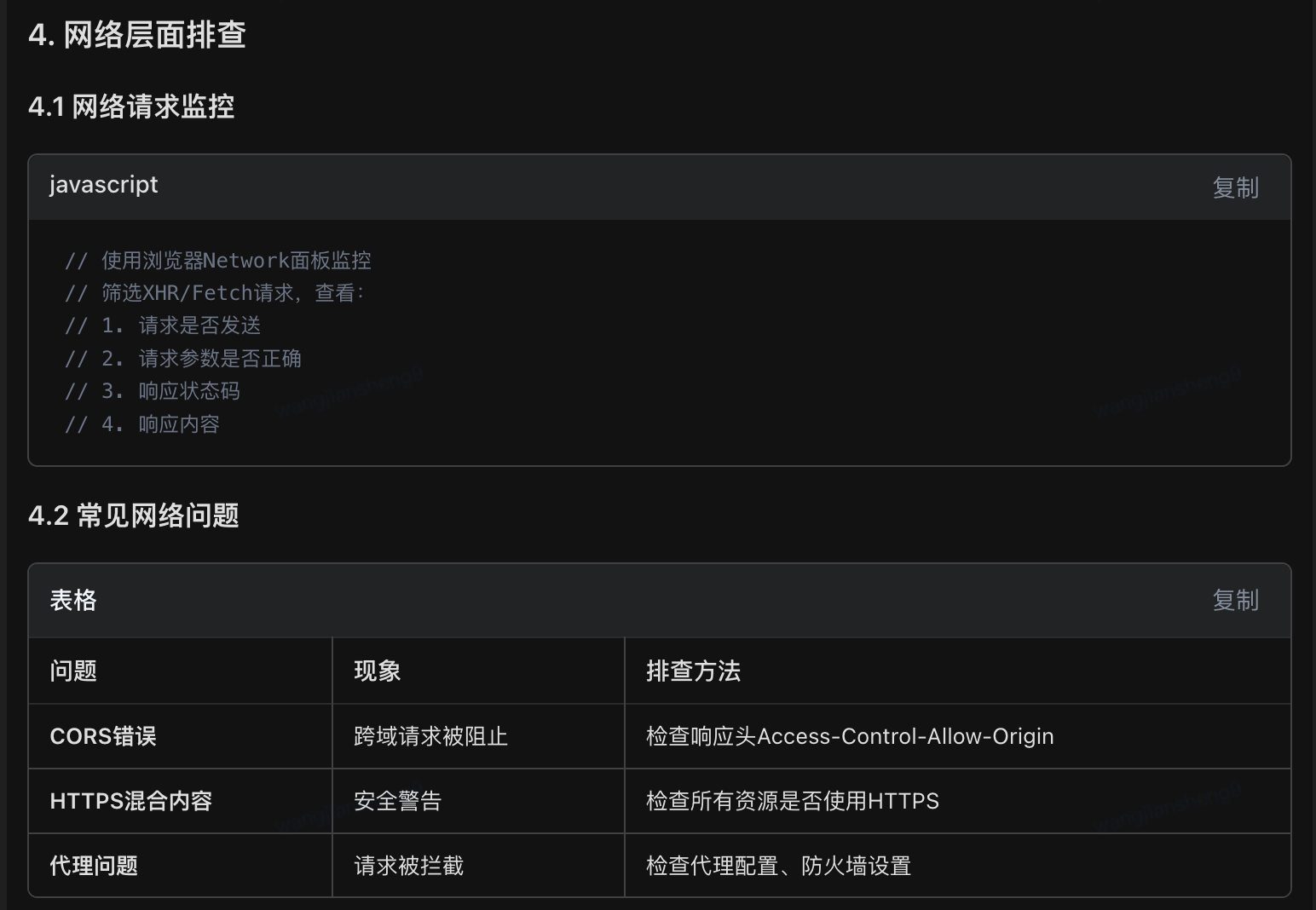
12. 登录天数位置无展示时,怎么排查哪个环节出现了问题
python
1. 问题现象确认
确认问题范围:是所有用户都无展示,还是特定用户/设备?
复现条件:在什么网络环境、什么操作步骤下出现?
展示位置:具体是哪个页面/模块的登录天数显示异常?
2. 前端排查路径
2.1 数据获取层面
接口调用检查:确认登录天数接口是否正常调用
响应数据验证:检查接口返回的登录天数数据是否存在、格式是否正确
空值处理逻辑:前端对空值/异常值的处理是否合理
2.2 渲染逻辑层面
条件渲染判断:检查前端展示条件判断逻辑
数据绑定验证:确认数据是否正确绑定到UI组件
样式显示问题:排查CSS/样式是否导致内容被隐藏
3. 后端排查路径
3.1 数据计算逻辑
登录天数计算:验证后端登录天数计算算法是否正确
数据存储检查:确认用户登录记录是否正常存储
缓存机制:检查缓存数据是否过期或异常
3.2 接口服务层面
接口响应状态:确认接口返回状态码和响应体
权限验证:检查用户权限是否影响数据展示
业务规则:验证是否有业务规则限制展示
4. 数据流追踪
4.1 端到端追踪
日志分析:查看前后端相关日志,定位异常时间点
链路追踪:通过TraceID追踪完整请求链路
数据库查询:直接查询数据库验证原始数据
4.2 环境因素
版本兼容性:检查客户端版本与服务器版本兼容性
配置检查:验证相关功能开关配置是否正确
AB测试:确认是否在AB测试分组中
5. 快速定位建议
优先检查接口响应:使用工具直接调用登录天数接口,确认数据是否存在
查看控制台日志:前端控制台是否有错误信息
对比正常用户:对比正常展示用户与异常用户的差异点
检查最近变更:回顾近期是否有相关代码/配置变更13. 应用使用过程中闪退了,怎么去定位和反馈
python
1. 问题现象收集
1.1 基本信息记录
设备信息:手机型号、操作系统版本、系统版本号
应用信息:应用名称、版本号、安装来源
网络环境:Wi-Fi/移动网络、网络状态
时间信息:闪退发生的具体时间点
1.2 操作场景还原
操作路径:闪退前进行的操作步骤
触发条件:是否特定操作、特定页面、特定数据状态下发生
复现频率:是否每次都能复现,还是偶发性问题
2. 问题定位方法
2.1 用户端自查
查看日志:检查应用内是否有错误提示或日志记录
重启测试:重启应用后是否仍会闪退
清理缓存:清理应用缓存后重新测试
2.2 技术排查路径
崩溃日志收集:获取设备上的崩溃日志文件
堆栈信息分析:分析崩溃时的调用栈信息
内存监控:检查是否存在内存泄漏或OOM问题
3. 反馈信息整理
3.1 必备信息
问题描述:清晰描述闪退现象和发生场景
复现步骤:详细的操作步骤说明
设备信息:完整的设备型号和系统版本
应用版本:当前使用的应用版本号
3.2 辅助信息
截图/录屏:如有条件,提供闪退瞬间的截图或录屏
日志文件:提供相关的崩溃日志文件
网络状态:当时的网络环境信息14、自动化测试中,A请求的返回值作为B请求的入参,该如何实现?
python
在于正确提取数据、合理存储变量、确保时序正确
python
1. 基于测试框架的变量传递
1.1 Postman/Newman方案
使用变量存储:在A请求响应后,通过pm.test()提取关键数据并赋值给环境变量
变量引用:在B请求中通过{{variable_name}}引用该变量
示例代码:
"javascript
复制
// A请求的Tests脚本中
pm.test("提取ID", function () {
const response = pm.response.json();
pm.environment.set("extracted_id", response.id);
});
// B请求的URL或Body中引用
// URL: https://api.example.com/items/{{extracted_id}}
1.2 JMeter方案
使用JSON Extractor:在A请求后添加JSON Extractor提取器
变量传递:提取的值自动存储为JMeter变量
引用方式:在B请求中使用${variable_name}引用
2. 基于编程语言的实现
2.1 Python + Requests方案
python
复制
import requests
# 执行A请求
response_a = requests.get('https://api.example.com/endpointA')
data_a = response_a.json()
item_id = data_a['id']
# 使用A请求结果作为B请求参数
response_b = requests.post('https://api.example.com/endpointB',
json={'id': item_id, 'other_param': 'value'})
2.2 Java + RestAssured方案
java
复制
// 执行A请求并提取值
String itemId = given()
.when()
.get("/endpointA")
.then()
.extract()
.path("id");
// 使用提取的值执行B请求
given()
.body(Map.of("id", itemId, "param", "value"))
.when()
.post("/endpointB");15、自动化测试中调用插入数据接口,如何避免数据库数据重复插入导致的混乱?
python
1、优先选择唯一标识符方案:结合业务特点选择最合适的唯一性保障方式
2、建立数据清理机制:确保测试环境数据整洁
3、考虑测试并行化需求:设计支持并行测试的数据策略
4、文档化数据管理流程:明确测试数据的创建、使用、清理规范
1. 数据唯一性保障策略
1.1 使用唯一标识符
业务唯一键:利用业务逻辑中的唯一字段(如订单号、手机号、邮箱等)
时间戳+随机数:生成具有时间戳和随机数的唯一标识
UUID/GUID:使用系统生成的全局唯一标识符
1.2 数据清理机制
测试前清理:在测试开始前清空相关测试数据
事务回滚:使用数据库事务,测试结束后回滚
临时表隔离:创建临时表存放测试数据,测试后删除
2. 测试框架层面的解决方案
2.1 数据生成策略
动态数据生成:每次测试生成新的唯一数据
数据工厂模式:封装数据创建逻辑,确保唯一性
数据依赖管理:建立数据依赖关系,避免重复创建
2.2 测试执行控制
测试隔离:每个测试用例独立运行,互不干扰
数据生命周期管理:明确测试数据的创建、使用、清理流程
3. 数据库层面的解决方案
3.1 约束机制
唯一索引/约束:在数据库层面设置唯一性约束
幂等性设计:接口设计支持重复调用不产生副作用
3.2 数据清理策略
自动清理任务:定时清理测试环境数据
标记删除:为测试数据添加标记,测试后批量清理
4. 最佳实践建议
4.1 测试数据管理
数据预置:测试前预置基础数据,测试中只操作增量数据
数据复用策略:合理复用数据,避免重复创建
数据版本控制:对测试数据进行版本管理
4.2 测试执行优化
并行测试支持:确保并行测试时数据不冲突
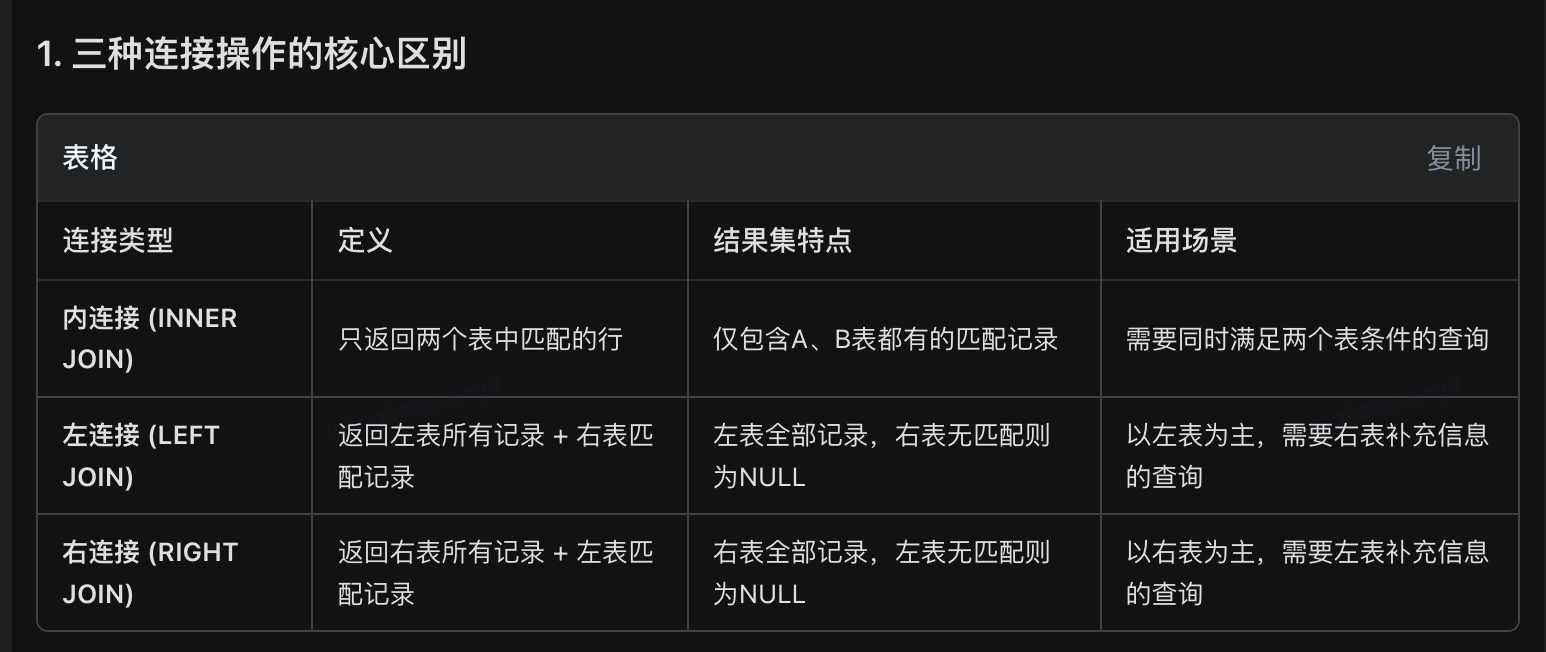
失败重试机制:处理因数据冲突导致的测试失败16、左连接、右连接、内连接的结果有什么不同?请以A表3条数据、B表5条数据为例说明
内连接:只保留交集
- 左连接:保留左表全集--现代SQL开发中,左连接的使用更为普遍。
- 右连接:保留右表全集
17、A表直接连接B表(无连接关键字)相当于哪种连接?
python
A表直接连接B表(无连接关键字)相当于内连接(INNER JOIN)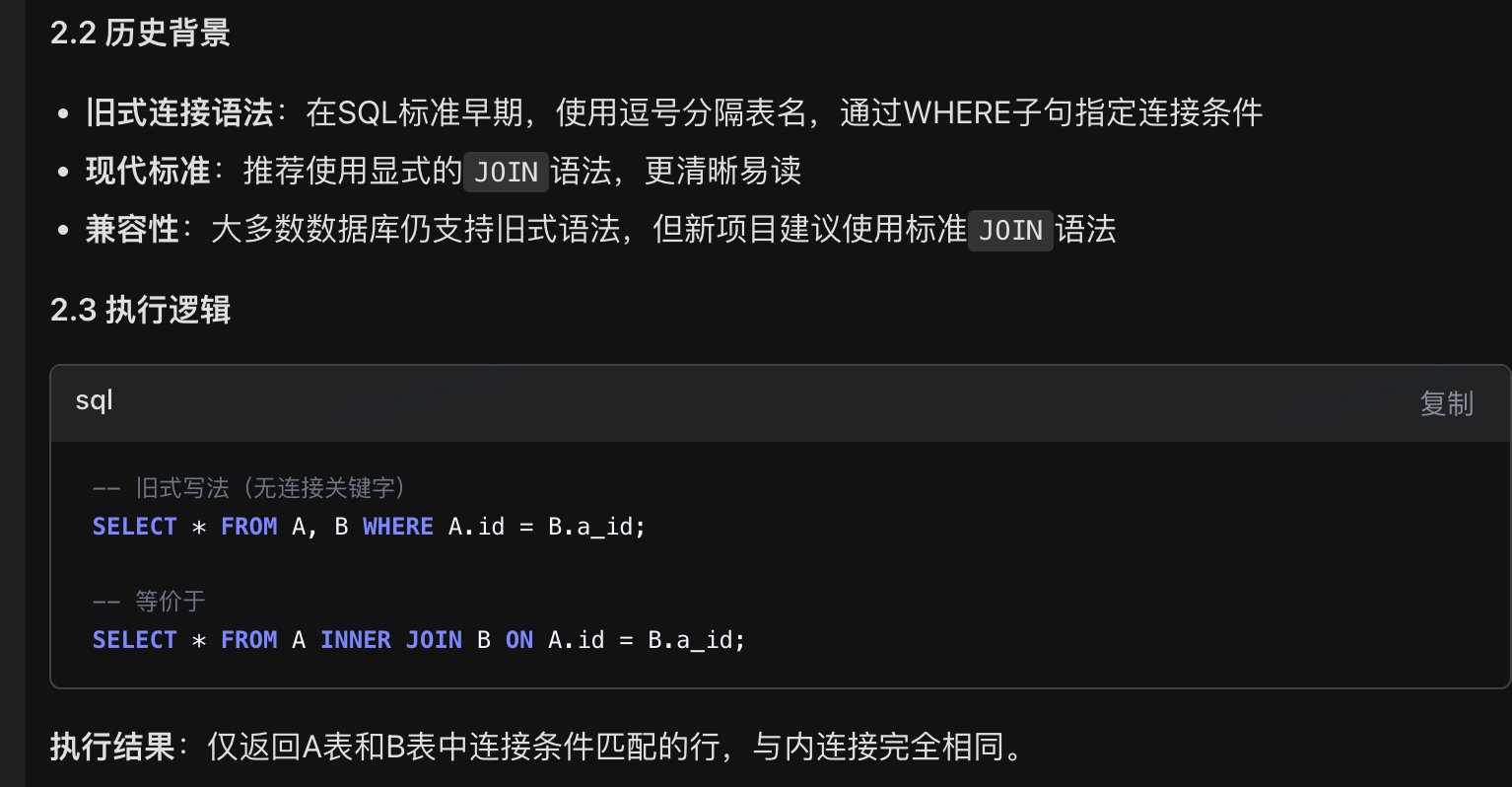
18、什么是主表和从表
python
主表和从表通常在同一数据库内.
优势:
事务一致性:支持跨表事务操作
性能优化:减少网络延迟,提高查询效率
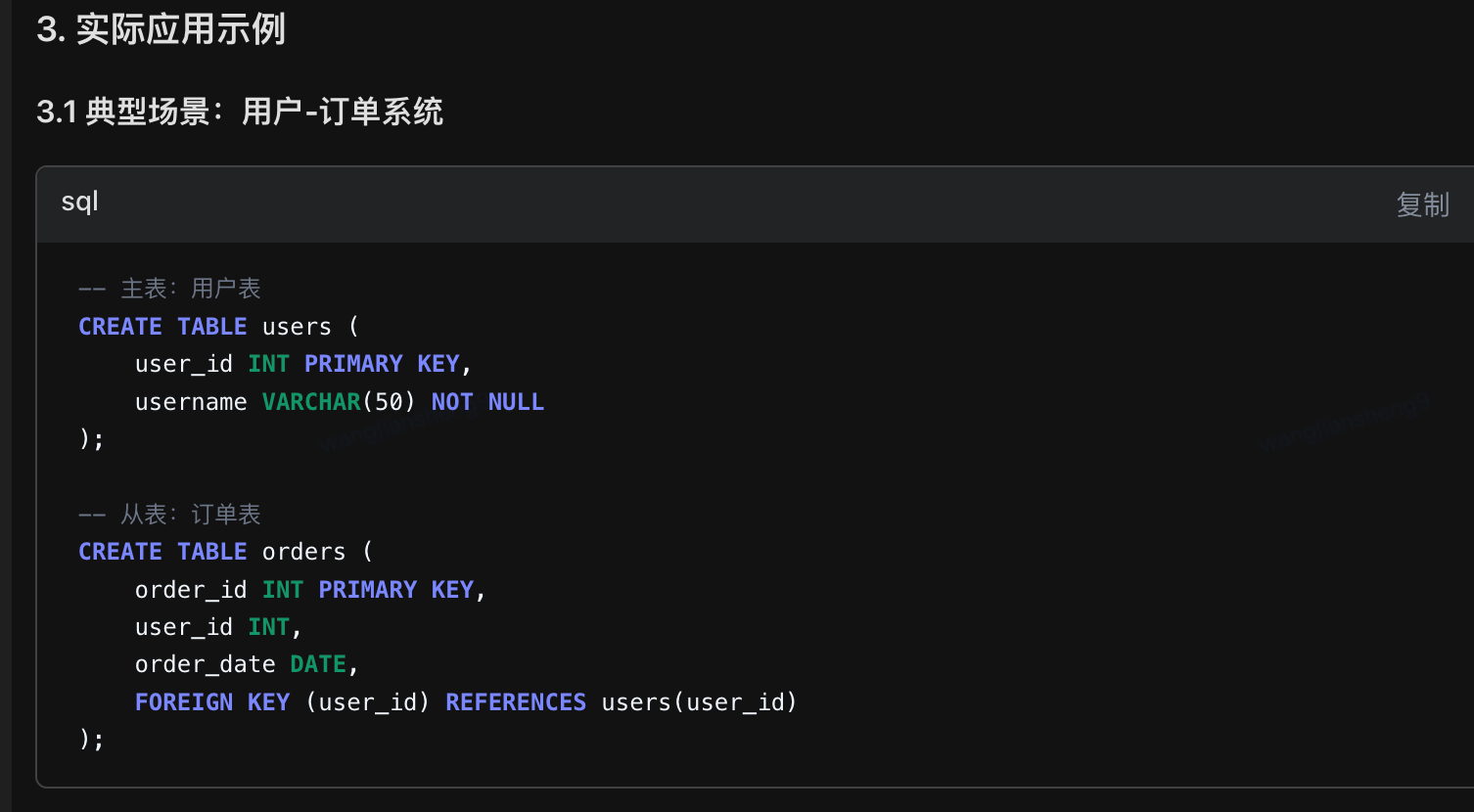

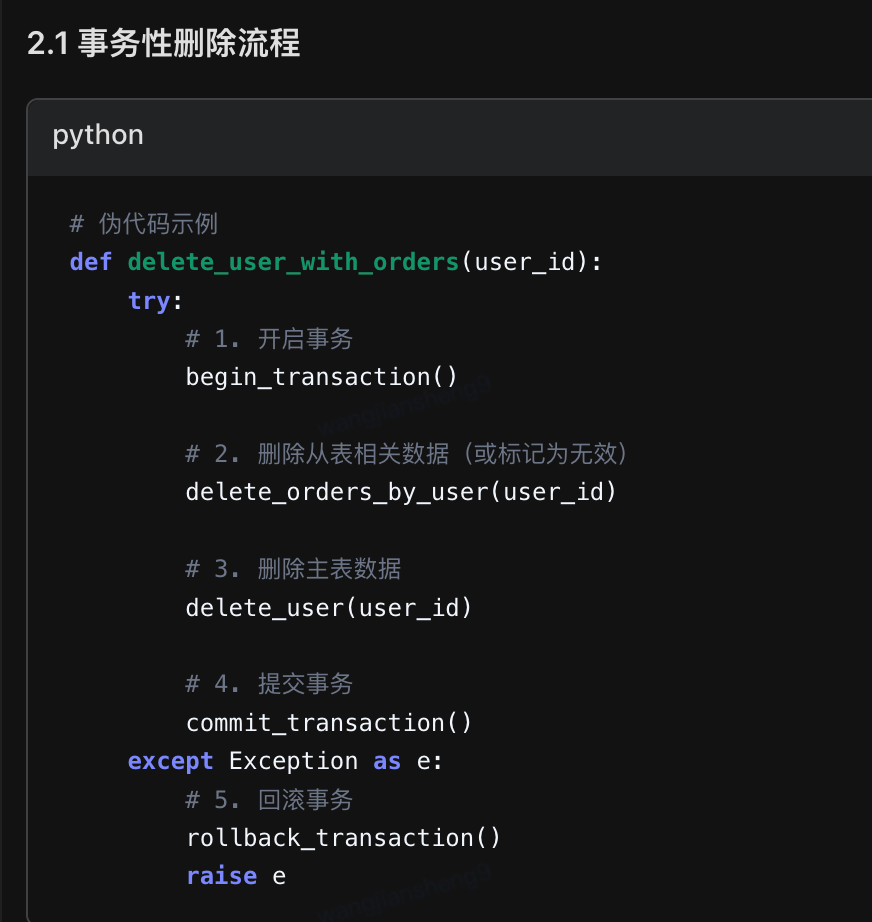
19、删除数据时,如何保证主表和从表的数据一致性
python
保持主从表数据一致性的核心在于提前规划删除策略,根据业务需求选择:
1、级联删除:完全依赖关系,数据同生共死
2、设为NULL:保留从表记录,解除关联
3、限制删除:需要人工处理关联数据
4、软删除(修改状态,非物理删除):保留历史记录,便于追溯
方案1:创建从表的时候,就要建立数据一致性机制
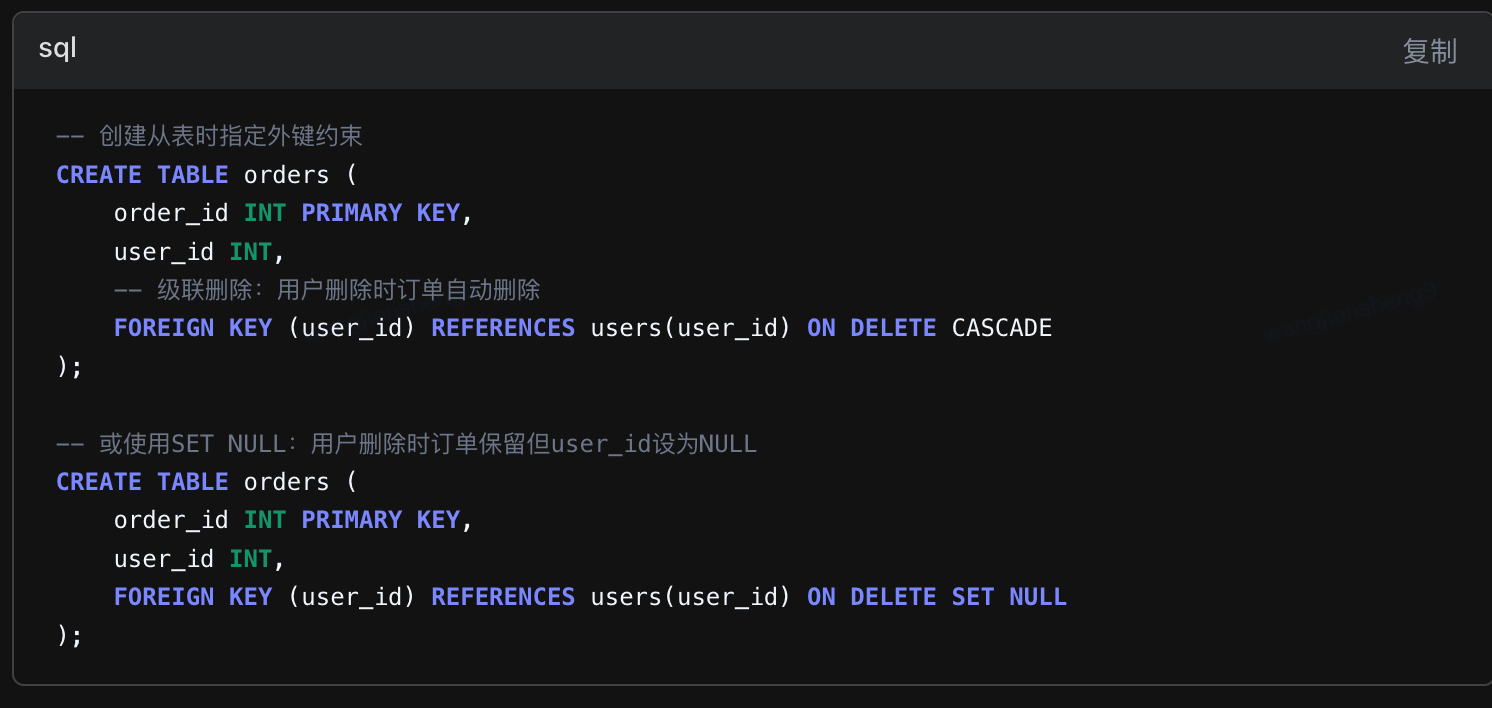
方案2:事务性删除