线程池是什么?
用来维持和管理固定数量线程的池化结构。
线程池是一种基于"池化"思想来管理和复用线程的机制。它预先创建一组线程并放入"池子"中。当有任务到来时,从池中获取一个空闲线程来执行;任务完成后,该线程不会销毁,而是返回池中等待下一个任务。
代码;wait/多线程
什么是池化结构?
池化结构是一种设计模式,用来维护有限数量的资源池。当需要使用资源时,从池中获取;使用完毕后,归还给池而不是直接销毁。
为什么要固定线程数量?
系统的资源是有限的,若线程数数量持续增加,并不能带来性能的提升,反而会带来负担。
线程数量应该是多少?
从任务类型出发+cpu核心数。
经验公式:
- CPU密集型:CPU核心数 大部分时间都在计算,很少阻塞
- io密集型(网络以及磁盘io):2*CPU核心数+2 大量时间都是在等待
因为CPU密集型 是在用户态运行,
io密集型需要内核态 和 用户态之间相切换,但切换时间会比较久,就利用这段时间去运行其他线程,所以可以多开线程。
操作系统分为 内核态 以及 用户态。
用户态:运行普通应用程序代码的地方,权限低,不能直接碰硬件和核心资源。
内核态:运行操作系统内核代码的地方,权限高,可以操作硬件、管理内存、调度进程等。
对于网络io的操作来说,
用户态不直接接触网卡、协议栈等,只负责发号施令和处理数据;
内核态负责具体的执行和直接操作底层硬件。
为什么要使用线程池?
使用线程池主要是为了解决频繁创建和销毁线程所带来的性能开销 问题,以及资源管理的问题。
线程池是怎么工作的?
采用生产消费模型。
生产者:提交任务中的线程。
消费者:线程池中的工作线程。
缓冲区:任务队列。
在生产者-消费者模型中,线程池主要包含三个角色:
- 任务队列 :一个阻塞队列。当工作线程忙不过来时,生产者提交的任务就在这里排队。
- 工作线程集合 :一组已经创建好的线程(
Worker对象)。它们始终运行着,不断尝试从队列中取任务。 - 线程池管理器:负责控制线程的创建、销毁、以及决定任务该入队还是该新建线程。
提交任务
从队列取任务
执行任务
队列满/无空闲线程
生产者(任务提交方)
任务队列(缓冲区)
线程池(消费者组)
任务执行逻辑
拒绝策略
| 生产者 - 消费者角色 | 线程池组件 | 核心行为 |
|---|---|---|
| 生产者 | 提交任务的业务线程 | 调用 execute()/submit() 生产任务 |
| 缓冲区 | 阻塞队列(如 ArrayBlockingQueue) | 存储待执行任务,削峰填谷 |
| 消费者 | 线程池中的工作线程 | 循环从队列取任务、执行任务 |
| 兜底策略 | 拒绝策略(如 CallerRuns) | 缓冲区满时处理超额任务 |
实现了一个轻量级的线程池,基于 POSIX 线程(pthread)实现,核心功能是管理一组工作线程,接收并异步执行任务。
进程与线程
进程就是运行中的程序。进程是一个程序的实例。
线程就是进程中的进程。
线程的数量取决于CPU的核心数。
临界区
临界区指的是:在多线程 / 多进程程序中,访问共享资源(变量、数据结构、文件、设备等)的那段代码。
这段代码的特殊之处在于:
多个执行流(线程或进程)可能同时进入;
如果同时操作共享资源,就可能产生数据竞争,导致结果不确定、数据损坏等问题。
因此,临界区必须被互斥地执行------同一时刻最多只有一个线程/进程在里面运行。
什么是自旋锁?什么是互斥锁?
自旋锁是一种忙等待(busy-waiting)的锁。线程尝试获取锁时,如果锁已被占用,它不会进入睡眠状态,而是不断循环检查锁是否释放,直到成功获取为止。
适用于 临界区代码执行时间短(只有几条指令),系统调用次数频繁但竞争不激烈的情况。
互斥锁是一种阻塞式锁。线程尝试获取锁时,如果锁已被占用,它会进入睡眠状态,让出 CPU,直到锁可用时被唤醒。
适用于 临界区代码执行时间长;锁竞争激烈,可能导致长时间自旋的情况。
条件变量
条件变量必须配合互斥锁使用。
条件变量的核心作用是:让线程在某个"条件不满足"时阻塞等待,并在条件可能被满足时被唤醒。它本身并不负责保护共享数据,所以必须和互斥锁配合使用。因为条件本身依赖共享数据,需要互斥保护。条件通常是共享数据的布尔表达式,比如队列是否为空,任务是否完成。
原子操作 与 锁
原子操作:在硬件层面保证某一小段指令不被打断,中间不会有线程切换进来,不需要加锁。
锁:在软件层面通过互斥的机制,让一段代码(临界区)一次只允许一个线程执行。
在生产者-消费者模型中,线程池主要包含三个角色:
- 任务队列 :一个阻塞队列。当工作线程忙不过来时,生产者提交的任务就在这里排队。
- 工作线程集合 :一组已经创建好的线程(
Worker对象)。它们始终运行着,不断尝试从队列中取任务。 - 线程池管理器:负责控制线程的创建、销毁、以及决定任务该入队还是该新建线程。
任务队列
任务队列需要 一个任务队列的结构体,并且单个任务也要对应一个结构体。
那么就需要以下函数
- 创建任务队列并初始化函数
- 销毁任务队列函数
- 添加任务的函数
- 取出任务的函数(分为阻塞状态下 和 非阻塞状态下)
- 将队列设置成非阻塞模式的函数
为什么单独写一个设置非阻塞模式的函数?而没有再写一个设置为阻塞模式的函数呢?
因为队列在初始化时默认为阻塞模式,所以需要一个设置为非阻塞模式的函数。
又因为设置为非阻塞模式是一种控制行为,而这个行为在实际操作中通常是一次性的操作,而不需要频繁的切换。并且没有从非阻塞转到阻塞模式的场景。所以只需要一个设置为非阻塞模式的函数即可。
为什么取出任务的函数要分为在阻塞状态下 和 非阻塞状态下两个函数?
因为任务队列又这两种不同的模式,所以需要不同的取出任务的策略。
非阻塞模式下取出任务:直接取出任务,不会等待,若为空,直接返回NULL。使用自旋锁。
阻塞状态下取出任务:阻塞等待有任务可以取出,若队列为空,则一直等待直到有新任务到来。使用互斥锁加条件变量。
在阻塞状态下获取任务的时候,容易有虚假唤醒的情况。
虚假唤醒就是一个线程在没有被告知唤醒的情况下,从休眠状态中意外的苏醒了。
如何避免这种问题?
始终用while循环检查条件,而不用if。
在线程调用wait或其他类似条件变量等待机制 被唤醒后,用while继续检查是否满足条件。
// 资源的创建 使用 回滚式编程
// 业务逻辑 使用 防御式编程
什么是回滚式编程?什么是防御性编程?为什么创建资源要用回滚式,业务逻辑要用防御式?
回滚式编程,核心是:在创建多个资源时,如果后续任何一个资源创建失败,就要将之前已经成功创建的资源全部释放(回滚),以保证系统状态的一致性。
如果构造失败,就要撤销之前所有已完成的构造,保证不留垃圾、不泄露资源。
资源创建复杂、易失败、易泄漏 → 必须用回滚式编程保证安全。
防御式编程,核心是:不信任任何外部输入、内部状态或运行时环境,总是假设可能出现异常情况,并对代码进行额外的检查、保护与容错。
永远不要相信数据是正确的、状态是稳定的、调用是安全的,必须进行验证、判断、保护。
业务逻辑复杂、易受外部影响、易出错 → 必须用防御式编程提高鲁棒性。
任务队列结构体
// 单个任务 结构体
typedef struct task_s {
void *next; // 链接下一个任务
handler_pt func; // 任务以什么样的方式执行,具体的函数指针
void *arg; // 上下文 需要传递给函数的参数 在堆上分配,维护
} task_t;
// 任务队列结构体
typedef struct task_queue_s {
void *head;
void **tail;
int block; // 是否阻塞 1:阻塞 0:非阻塞
spinlock_t lock; // 自旋锁
pthread_mutex_t mutex; // 互斥锁
pthread_cond_t cond; // 条件变量 配合互斥锁使用
} task_queue_t;任务队列的创建
- 分配任务队列内存
- 初始化互斥锁
- 初始化条件变量
- 初始化自旋锁
- 设置队列初始状态(head = NULL, tail = &head, block = 1)
返回值:成功返回队列指针,失败返回NULL
一旦初始化失败,就会逐一释放申请的内存,或者销毁相关的变量。
// static inline: 表示该函数仅在当前源文件可见,
// 且建议编译器内联,适合高频调用的短小函数,比如任务消费逻辑。
static task_queue_t *
__taskqueue_create() {
int ret;
task_queue_t *queue = (task_queue_t *)malloc(sizeof(task_queue_t));
if (queue) {
ret = pthread_mutex_init(&queue->mutex, NULL);
if (ret == 0) {
ret = pthread_cond_init(&queue->cond, NULL);
if (ret == 0) {
spinlock_init(&queue->lock);
queue->head = NULL;
queue->tail = &queue->head;
queue->block = 1;
return queue;
}
pthread_mutex_destroy(&queue->mutex);
}
free(queue);
}
return NULL;
}将队列设置为非阻塞模式
pthread_mutex_t mutex; 是互斥锁变量。
pthread_mutex_lock(&queue->mutex);只能锁住mutex这个互斥锁变量。它本身不绑定或者保护任何特定的变量。
int block; // 是否阻塞 1:阻塞 0:非阻塞
queue->block 只是一个普通变量,它不会被互斥锁自动保护,并且它本身也没有任何内置的线程安全机制。
如果其他线程想直接访问这个变量,也是可以直接访问修改的。
那么这里的互斥锁保护了什么呢?
这里有一个 约定俗成的规则,当修改queue->block条件变量的时候,必须先通过pthread_mutex_lock(&queue->mutex);对mutex进行加锁。这样就可以做到线程安全。
需要说明的是直接访问修改queue->block也是可以的,但线程不安全,所以要先加锁。
pthread_cond_broadcast(&queue->cond);
pthread_cond_t cond; // 条件变量 配合互斥锁使用
cond是一个 pthread_cond_t类型的条件变量,通常与一个互斥锁(pthread_mutex_t)配合使用,用于线程间同步。
唤醒所有正在等待该条件变量 cond的线程。
这表示:
"如果队列是空的,而且我是阻塞模式(block == 1),那我就挂起(进入睡眠),等待其他线程添加任务并唤醒我。"
但你现在调用了 __nonblock(),意味着:
"线程池要进入非阻塞模式了,或者要关闭了,所有还在等待任务的线程,不要再等了,应该立刻检查状态并做出响应。"
static void
__nonblock(task_queue_t *queue) {
pthread_mutex_lock(&queue->mutex);
queue->block = 0;
pthread_mutex_unlock(&queue->mutex);
pthread_cond_broadcast(&queue->cond);
}向队列中添加新任务
采用的是尾插法。
task:指向一个任务结构体的指针,这个任务将被插入队列尾部等待执行。
// 单个任务 结构体
typedef struct task_s {
void *next; // 链接下一个任务
handler_pt func; // 任务以什么样的方式执行,具体的函数指针
void *arg; // 上下文 在堆上分配,维护
} task_t;
// 任务队列结构体
typedef struct task_queue_s {
void *head;
void **tail;
int block; // 是否阻塞 1:阻塞 0:非阻塞
spinlock_t lock; // 自旋锁
pthread_mutex_t mutex; // 互斥锁
pthread_cond_t cond; // 条件变量 配合互斥锁使用
} task_queue_t;二级指针void **tail;
task_t结构体中第一个元素void *next;
这里tail为什么是二级指针呢?
假定tail_1是一级尾指针,tail_2是二级尾指针。
task_t task;
tail_1 = &task;
tail_2 = &task;
那么这两个指针变量有什么区别呢?
#include <stdio.h>
struct task_ {
void *next;
int data;
};
int main() {
struct task_ t1;
t1.next = NULL;
t1.data = 200;
struct task_ task;
task.next = &t1;
task.data = 200;
struct task_ * tail_1 ;
struct task_ ** tail_2 ;
tail_1 = &task;
tail_2 = &task;
printf("task: %p\n", task); // task实例
printf("&task: %p\n", &task); // task自身的地址
printf("task.next: %p\n", task.next); //task.next所指向内存的起始地址
printf("&task.next: %p\n", &task.next); //task.next自身的地址
printf("&t1: %p\n", &t1); //t1的起始地址
printf("tail_1: %p\n", tail_1); //tail_1所指向内存的起始地址
printf("*tail_1: %p\n", *tail_1); //tail_1所指向内存的起始地址
printf("&tail_1: %p\n", &tail_1); //tail_1自身的地址
printf("tail_1->next: %p\n", tail_1->next); //tail_1->next所指向内存的起始地址
printf("&tail_1->next: %p\n", &tail_1->next); //tail_1->next自身的地址
printf("tail_2: %p\n", tail_2); //tail_2所指向内存的起始地址
printf("*tail_2: %p\n", *tail_2); //tail_2所指向内存的起始地址
printf("&tail_2: %p\n", &tail_2); //tail_2自身的地址
return 0;
}
task: 000000000062FDE0
&task: 000000000062FE00
task.next: 000000000062FE10
&task.next: 000000000062FE00
&t1: 000000000062FE10
tail_1: 000000000062FE00
*tail_1: 000000000062FDE0
&tail_1: 000000000062FDF8
tail_1->next: 000000000062FE10
&tail_1->next: 000000000062FE00
tail_2: 000000000062FE00
*tail_2: 000000000062FE10
&tail_2: 000000000062FDF0可以看到
task = *tail_1 = DE0
&task = &task.next = tail_1 = &(tail_1->next) = tail_2 = E00
task.next = &t1 = tail_1->next = *tail_2 = E10
&tail_1 = DF8
&tail_2 = DF0我们知道指针是用来存储地址的,而且指针本身所占的内存是固定的,8个字节。
tail_1指向的是task这个结构体,tail_1本身占用8个字节,tail_1指向的这个结构体task占用24个字节(见上面结构体代码)。
tail_2是二级指针,它本身占用8个字节,并且它所指向的内存也是占用8个字节。
tail_2=&task;那么tail_2就是指向的task的前8个字节的内存(也就是 void *next元素),这个元素是用来连接下一个task_t结构体的。**结构体的地址 和 结构体中第一个元素的地址 是一致的。**所以 tail_2 = &(tail_1->next) = tail_1
如果在插入时使用tail_1一级指针,那么就会出现 tail_1->next 这个表达式。就间接的固定了传给函数的task参数的元素里必须有一个名字是next的元素。
如果使用tail_2二级指针,就可以直接用tail_2,而不需要写出来具体的链接指针,但这里必须保证 传给函数的task参数的第一个元素必须是用来链接下一个结构体的指针,名字可以随便起,但位置必须是第一位。
也就是说&(tail_1->next) 和 tail_2是等价的。而tail_2更具通用性,但要求传入的结构体的第一位元素必须是链接下一个结构体的指针。
代码中的处理是 void ** link = (void**)task
也就相当于 link 指向了 task的第一个元素的地址,即next元素的地址。
tail 永远指向最后一个节点的 next 指针的地址
typedef struct task_queue_s {
void *head; // 一级指针
void **tail; // 二级指针
int block;
spinlock_t lock;
pthread_mutex_t mutex;
pthread_cond_t cond;
} task_queue_t;
static inline void
__add_task(task_queue_t *queue, void *task) {
// 不限定任务类型,只要该任务的结构起始内存是一个用于链接下一个节点的指针
// 一级指针转为二级指针
void **link = (void**)task; // link 指向 task 的 next 字段
// 即 *link = task->next link=&(task->next)
*link = NULL;
spinlock_lock(&queue->lock);
*queue->tail = link; // 将当前尾节点的 next 指向新任务
queue->tail = link; // 更新尾指针
spinlock_unlock(&queue->lock);
pthread_cond_signal(&queue->cond);
}假设queue的最后一个元素是 tail_t
queue->tail 是二级指针,本身占用8B内存,指向的内存也是8B。
queue->tail_t->next 是一个一级指针。
queue->tail = &(queue->tail_t->next);
而不是 queue->tail = queue->tail_t->next;
尾插法(一级指针,插入元素task):
queue->tail_t->next = task; // 最后一个元素的next指向task元素
queue->tail_t = task; // 更新最后一个元素,更新为task元素
#include <stdio.h>
struct task_ {
void *next;
int data;
};
int main() {
struct task_ t1, t2;
t1.next = &t2; // t1.next 指向 t2
t1.data = 100;
t2.next = NULL;
t2.data = 200;
struct task_ *task = &t1;
printf("t1 的地址: %p\n", t1);
printf("&t1 的地址: %p\n", &(t1));
printf("task 变量的地址: %p\n", task);
printf("&task 变量的地址: %p\n", &(task));
printf("task->next 的地址: %p\n", task->next);
printf("&task->next 的地址: %p\n", &(task->next));
printf("t2 的地址: %p\n", t2);
printf("&t2 的地址: %p\n", &(t2));
void ** link = (void **)task;
printf("link的地址: %p\n", link);
printf("*link的地址: %p\n", *link);
return 0;
}
t1 的地址: 000000000062FDD0
&t1 的地址: 000000000062FE00
task 变量的地址: 000000000062FE00
&task 变量的地址: 000000000062FDE8
task->next 的地址: 000000000062FDF0
&task->next 的地址: 000000000062FE00
t2 的地址: 000000000062FDD0
&t2 的地址: 000000000062FDF0
link的地址: 000000000062FE00
*link的地址: 000000000062FDF0可以看出
t1 ≠ &t1 t1是结构体的实体,&ti是结构体t1的起始地址
task ≠ &task task是task所执行的内存起始地址,&task是task变量自身的起始地址
&t1 = task = &task->next =link
task指向的是t1,所以task等于t1的地址;
task结构体的首个元素是next,所以&task->next 等于 task;
link是二级指针,指向的是task->next,所以link 等于 &task->next;
&t1和task是一级指针
&task->next 和 link 是二级指针
所以*link = task->next。
想不明白的时候,就写一个小代码的实例,便于理解。
从上面的实例可以看出,
task = &task->next =link ------等式1
*link = task->next
尾插法(一级指针,插入元素task):
queue->tail_t->next = task; -------代码1
// 最后一个元素的next指向task元素
queue->tail_t = task; -------代码2
// 更新最后一个元素,更新为task元素
尾插法(二级指针,插入元素task):
queue->tail 是二级指针
queue->tail 等于 &(queue->tail_t->next) 等于 queue->tail_t ------等式2
*queue->tail 等于 queue->tail_t->next ------等式3
根据等式1和等式3可以将代码1改写为 *queue->tail = link;
根据等式1和等式2可以将代码2改写为queue->tail = link;
pthread_cond_signal(&queue->cond);
唤醒一个(至少一个)正在等待该条件变量 cond的线程。
和pthread_cond_broadcast(&queue->cond);有什么区别呢?
pthread_cond_signal(&cond) :唤醒一个 (至少一个,通常是其中一个)正在等待该条件变量的线程。适用于你认为只需要一个线程来处理当前情况就够了。
pthread_cond_broadcast(&cond) :唤醒所有 正在等待该条件变量的线程。适用于你认为所有等待线程都应该醒来检查条件。
为什么在添加任务时使用pthread_cond_signal,而在切换阻塞模式时使用pthread_cond_broadcast?
添加任务时使用pthread_cond_signal
生产者:调用 __add_task(),向队列中添加任务;
消费者:工作线程调用 pthread_cond_wait(&queue->cond, &queue->mutex),在队列为空时阻塞等待新任务到来。
当你添加了一个新任务到队列中,意味着:现在队列中有任务了,你(工作线程)可以醒过来拿任务去执行了。 但注意,只需要唤醒一个工作线程就够了!
因为一个任务只需要一个线程去处理; 如果你唤醒了多个线程,它们会依次尝试获取锁,但只有一个能抢到任务,其他线程可能发现队列又空了,然后重新等待。 这样做不仅 效率更高(少唤醒线程),而且 避免了"惊群效应"。
切换阻塞模式时使用pthread_cond_broadcast
如果多个工作线程在队列为空时阻塞等待任务,切换阻塞模式后,所有正在傻等任务的工作线程,立刻停止等待,检查新的状态(比如 block == 0,或者要退出了),并做出响应(比如直接返回、退出线程等)。
唤醒所有正在等待的线程,让它们全部检查新的状态,该退出就退出,该返回就返回,该停止等待就停止等待。
static inline void
__add_task(task_queue_t *queue, void *task) {
// 不限定任务类型,只要该任务的结构起始内存是一个用于链接下一个节点的指针
void **link = (void**)task;
*link = NULL;
spinlock_lock(&queue->lock);
*queue->tail /* 等价于 queue->tail->next */ = link;// 添加元素
queue->tail = link; // 更新尾指针
spinlock_unlock(&queue->lock);
pthread_cond_signal(&queue->cond);
}从队列头部取出任务(非阻塞模式下)
从任务队列的头部(FIFO,先进先出)取出一个任务,用于执行。这是一个非阻塞的操作:如果队列为空,则直接返回 NULL;否则取出队首任务并返回。
- 使用自旋锁保护
- 如果队列为空,返回NULL
- 取出头部任务
- 更新head指针
- 如果队列变空,重置tail指针
返回值:成功返回任务指针,失败返回NULL
static inline void *
__pop_task(task_queue_t *queue) {
spinlock_lock(&queue->lock);
if (queue->head == NULL) { // 队列为空
spinlock_unlock(&queue->lock);
return NULL;
}
task_t *task;
task = queue->head;
void **link = (void**)task; // 借用头指针,取出元素 等价于 link = task->next
queue->head = *link; // 等价于 queue->head = task
if (queue->head == NULL) {
queue->tail = &queue->head;
}
spinlock_unlock(&queue->lock);
return task;
}获取任务 (阻塞模式)
如果取不出数据就加互斥锁,然后判断是否是非阻塞模式, 如果是就解锁并返回NULL。如果是阻塞模式就等待,等待结束后,然后去掉互斥锁,再进行while判断。
如果取得出数据,就退出while循环,然后返回取出的数据。
为什么要用while判断 取不取的出数据?用if也可以啊,再说里面还有一个等待函数呢。
while循环的意思:
只要我尝试从队列中取任务(__pop_task())返回了 NULL,说明当前没任务,我需要根据线程池的状态决定是等待,还是直接返回。
条件变量的等待可能存在 "虚假唤醒"(spurious wakeup),也就是说,线程可能在没有被真正唤醒(如收到信号)的情况下被操作系统唤醒。
所以,不能依赖单次唤醒就假定条件成立,必须用 while循环反复检查条件。
这里的虚假唤醒是指的pthread_cond_wait(&queue->cond, &queue->mutex);这条代码还是
task = __pop_task(queue)?
pthread_cond_wait()可能会发生"虚假唤醒"!
就算是假唤醒,那while也会直接退出啊,这不和if一样吗?
当被唤醒后,while会 重新检查条件(比如队列是否真的非空),如果条件不满足(比如队列仍然为空),它会继续等待(说明我被假唤醒了,队列中并没有来数据,还是空的);而 if只会判断一次,虚假唤醒后,它不会重新检查条件,会错误地继续执行,可能导致严重问题!
int pthread_cond_wait(pthread_cond_t *cond, pthread_mutex_t *mutex);
cond:指向要等待的条件变量的指针(pthread_cond_t类型)。
mutex:指向与条件变量关联的互斥锁的指针(pthread_mutex_t类型)。
返回值:
成功:返回 0。
失败:返回非 0的错误码(如 EINVAL表示参数无效)。
内部工作流程:
- 释放互斥锁
- 阻塞等待
- 被唤醒后重新上锁
- 返回并检查条件
pthread_cond_wait等待,不应该先等待,等待结束后再加锁,然后进行操作吗?为什么要先加锁,再等待。如果多个线程都是先加锁然后再等待,那么当那个占用的线程处理完后,那个线程接手呢?这不就发生竞争了吗?
pthread_cond_wait(cond, mutex)的确要求你先加锁(持有 mutex),然后才能调用它;但它并不是"先等待,后加锁",而是:
它是一个原子操作,会先解锁 mutex,然后让线程进入等待(阻塞)状态,等待被唤醒;
当它被唤醒后,会 自动重新加锁 mutex,并返回到你的代码中,此时你已再次持有锁,可以安全地操作共享数据。
所以:你是在持有锁的情况下调用 pthread_cond_wait(),但它会在内部帮你安全地解锁并等待,唤醒后重新加锁。
pthread_cond_wait(&queue->cond, &queue->mutex);
调用函数后会做三件原子性(不可分割)的事:
-
解锁互斥锁
mutex(让其他线程可以访问共享数据) -
让当前线程进入休眠(阻塞状态),等待其他线程调用
pthread_cond_signal()或pthread_cond_broadcast()唤醒它 -
当被唤醒后,重新获取(加锁)该
mutex,并返回到pthread_cond_wait下一行的代码中
这里等待后就直接解锁了,什么都没有操作,为什么?
pthread_cond_wait(&queue->cond, &queue->mutex);
pthread_mutex_unlock(&queue->mutex);
如果在这里不释放锁,就直接循环那么再次调用 __pop_task 时,__pop_task 内部的自旋锁会被阻塞导致死锁!
并非什么 都没有操作,而是要解锁后再去while判断,是否可以取出数据。
// 获取任务 (阻塞模式)
static inline void *
__get_task(task_queue_t *queue) {
task_t *task;
// 虚假唤醒
while ((task = __pop_task(queue)) == NULL) {
pthread_mutex_lock(&queue->mutex);
if (queue->block == 0) {
pthread_mutex_unlock(&queue->mutex);
return NULL;
}
// 1. 先 unlock(&mtx)
// 2. 在 cond 休眠
// --- __add_task 时唤醒
// 3. 在 cond 唤醒
// 4. 加上 lock(&mtx);
pthread_cond_wait(&queue->cond, &queue->mutex);
pthread_mutex_unlock(&queue->mutex);
}
return task;
}销毁任务队列
-
清空任务队列中的所有剩余任务(逐个取出并释放内存)
-
销毁自旋锁(
spinlock_t) -
销毁 POSIX 条件变量(
pthread_cond_t) -
销毁 POSIX 互斥锁(
pthread_mutex_t) -
最后释放任务队列结构体本身占用的内存(
free(queue))// 销毁任务队列
static void
__taskqueue_destroy(task_queue_t *queue) {
task_t *task;
while ((task = __pop_task(queue))) {
free(task);
}
spinlock_destroy(&queue->lock);
pthread_cond_destroy(&queue->cond);
pthread_mutex_destroy(&queue->mutex);
free(queue);
}
线程管理
线程池管理器:负责控制线程的创建、销毁、以及决定任务该入队还是该新建线程。
线程池结构体
// 线程池结构体
struct thrdpool_s {
task_queue_t *task_queue; // 绑定的任务队列
atomic_int quit;// 退出标记,原子变量(线程安全)
int thrd_count; // 工作线程的数量,固定的数量,所以不用原子变量
pthread_t *threads; // 数组,存储所有工作线程的ID
};这个线程池结构体是每一个线程对应一个结构体吗?
不是,一个线程池只有一个这样的结构体。
pthread_t *threads; // 数组,存储所有工作线程的ID
事例:
thrdpool_t *pool = thrdpool_create(4); // 创建一个线程池,包含4个工作线程
// 这里只有一个 pool 结构体,但里面有4个线程ID工作线程的主函数
它是线程池中每个工作线程的执行主体。负责从任务队列中获取任务并执行。
void *arg
任意类型的通用指针,此函数中指向thrdpool_t结构体的指针
task_t *task;和 void *ctx;:
定义了两个局部变量:
task: 用于存储从任务队列中获取的当前任务。
ctx: 用于存储任务的上下文参数,即传递给任务处理函数的实际数据。
while (atomic_load(&pool->quit) == 0)
使用原子操作读取 pool->quit的值。pool->quit是一个 atomic_int类型的变量,用于指示线程池是否应该退出。
如果为0,不退出,继续处理任务。如果不为0,退出。
if (!task) break;:
如果 __get_task返回 NULL,意味着当前没有可用的任务
free(task);:
释放之前通过 malloc分配的任务结构体 task的内存。
任务结构体 task_t在提交任务时通过 thrdpool_post函数动态分配,因此在任务被取出后,需要手动释放其内存,以避免内存泄漏。
func(ctx);:
调用任务处理函数 func,并将任务的上下文参数 ctx传递给它。
这是实际执行用户定义任务的地方。
task->func 就是 task任务所对应的 任务函数。
static void *
__thrdpool_worker(void *arg) {
thrdpool_t *pool = (thrdpool_t*) arg;
task_t *task;
void *ctx;
while (atomic_load(&pool->quit) == 0) {
task = (task_t*)__get_task(pool->task_queue);
if (!task) break;// 当前没有可用的任务
handler_pt func = task->func;
ctx = task->arg;
free(task);
func(ctx);
}
return NULL;
}终止所有的线程
终止线程池中的所有工作线程,并确保它们安全地退出。
atomic_store(&pool->quit, 1):
使用原子操作将线程池结构体中的 quit标志设置为 1。通知所有工作线程线程池即将终止。
当 quit的值为 1时,工作线程在检查到这个标志后,会停止获取新任务,并在完成当前任务(如果有的话)后退出。
__nonblock(pool->task_queue):
将任务队列设置为非阻塞模式。为了确保那些可能正在等待新任务的工作线程能够被唤醒,从而检测到线程池的终止信号。
pthread_join(pool->threadsi, NULL):
阻塞调用线程(通常是主线程或管理线程),直到指定的工作线程 (pool->threads[i]) 结束。当前线程结束后,主线程在继续执行。
通过调用 pthread_join,确保主线程等待每个工作线程完成其当前任务并安全退出。这避免了在有线程仍在运行时,线程池资源被提前释放或销毁,从而导致未定义行为或资源泄漏。
通过for循环,主线程会逐个等待每个工作线程的结束,确保所有线程都已经终止,线程池可以安全地进行后续的清理工作。
创建工作线程
申请一个线程属性对象attr,用来设置新创建线程的属性。
初始化此线程属性对象。(使用默认配置)
申请thrd_count线程数量的内存。
分别创建thrd_count数量的线程。
销毁attr线程属性对象。
如果创建数量是thrd_count,成功,返回0。
static int
__threads_create(thrdpool_t *pool, size_t thrd_count) {
pthread_attr_t attr;// 线程属性对象 attr,用于设置新创建线程的属性
int ret;
ret = pthread_attr_init(&attr);
if (ret == 0) {
pool->threads = (pthread_t *)malloc(sizeof(pthread_t) * thrd_count);
if (pool->threads) {
int i = 0;
for (; i < thrd_count; i++) {
if (pthread_create(&pool->threads[i], &attr, __thrdpool_worker, pool) != 0) {
break;
}
}
pool->thrd_count = i; // 创建中若有线程创建失败,i的值将小于参数thrd_count
pthread_attr_destroy(&attr);
if (i == thrd_count) //
return 0; // 成功
// 失败
__threads_terminate(pool);
free(pool->threads);
}
ret = -1;
}
return ret;
}对外API接口
提供给用户使用。
创建线程池
申请一个线程池结构体。
创建一个任务队列。
将线程池与任务队列建立连接。
初始化pool->quit线程池退出标记。
创建thrd_count个数量的线程。
创建成功,返回线程池。
thrdpool_t *
thrdpool_create(int thrd_count) {
thrdpool_t *pool;
pool = (thrdpool_t*)malloc(sizeof(*pool));
if (pool) {
task_queue_t *queue = __taskqueue_create();
if (queue) {
pool->task_queue = queue;
atomic_init(&pool->quit, 0);
if (__threads_create(pool, thrd_count) == 0)
return pool;
__taskqueue_destroy(queue);
}
free(pool);
}
return NULL;
}向线程池中提交任务
检查线程池是否正在运行。
申请一个任务结构体。
设置任务结构体的 任务函数参数 以及 上下文参数。
添加到线程池的任务队列中。
int
thrdpool_post(thrdpool_t *pool, handler_pt func, void *arg) {
if (atomic_load(&pool->quit) == 1)
return -1;
task_t *task = (task_t*) malloc(sizeof(task_t));
if (!task) return -1;
task->func = func;
task->arg = arg;
__add_task(pool->task_queue, task);
return 0;
}终止线程池(非阻塞)
该函数用于通知线程池中的所有工作线程停止处理任务并退出,而不会等待这些线程实际完成退出的过程。
设置退出标记。
设置任务队列为非阻塞模式。
每个工作线程在主循环中不断检查 atomic_load(&pool->quit)的值。
一旦检测到 quit为 1,工作线程将停止从任务队列中获取新任务,并在完成当前任务(如果有)后退出循环,最终终止线程。
该终止过程是非阻塞的 ,即 thrdpool_terminate函数本身不会等待所有工作线程实际完成退出。它只是发送了终止信号并调整了任务队列的行为。
为什么不能直接调用 __threads_terminate?
__threads_terminate
非阻塞的终止方式。不清理资源,仅通知。
thrdpool_terminate
阻塞的终止方式,等待线程结束,再清理资源(join线程)
void
thrdpool_terminate(thrdpool_t * pool) {
atomic_store(&pool->quit, 1);
__nonblock(pool->task_queue);
}等待线程池完成并清理资源
对线程池中的每个线程都进行join。(确保主线程(或调用者)等待线程池中的所有工作线程完成它们的任务并退出。)
销毁任务队列。
释放线程池。
void
thrdpool_waitdone(thrdpool_t *pool) {
int i;
for (i=0; i<pool->thrd_count; i++) {
pthread_join(pool->threads[i], NULL);
}
__taskqueue_destroy(pool->task_queue);
free(pool->threads);
free(pool);
}三个函数的区别
static void __threads_terminate(thrdpool_t * pool);
void thrdpool_terminate(thrdpool_t * pool);
void thrdpool_waitdone(thrdpool_t *pool) ;
__threads_terminate():只阻塞等待所有线程结束。只用于内部,创建线程失败的错误处理。
thrdpool_waitdone():阻塞等待所有线程结束,然后清理线程资源。可供用户调用。
thrdpool_terminate(): 只发送终止信号,不等待,非阻塞,立即返回。可供用户调用。
// 用户代码的正确用法
thrdpool_t *pool = thrdpool_create(4);
// 提交一些任务...
thrdpool_post(pool, task1, NULL);
thrdpool_post(pool, task2, NULL);
// 方案A:优雅终止(先发信号,后等待)
thrdpool_terminate(pool); // 立即返回,线程们开始退出
// 这里可以做其他事情...
thrdpool_waitdone(pool); // 阻塞等待线程结束并清理
// 方案B:直接等待(如果不需要提前发信号)
thrdpool_waitdone(pool); // 会先等待所有任务完成再清理
// 注意:waitdone内部不会发终止信号!怎么实现把任务安排给不同的线程呢?
每个线程分配的线程函数都是一样的。
pthread_create(&pool->threadsi, &attr, __thrdpool_worker, pool)
所有线程都在运行__thrdpool_worker函数。
没有显示的分配,而是通过共享队列和线程竞争的方式自动实现。
总结就是 谁抢到是谁的。
编译流程
对于thrd_pool.c文件
gcc thrd_pool.c -c -fPIC-c- 只编译不链接,生成目标文件(.o文件)-fPIC- Position Independent Code(位置无关代码)
执行结果: 生成 thrd_pool.o 目标文件
gcc -shared thrd_pool.o -o libthrd_pool.so -I./ -L./ -lpthread-shared- 生成共享库(.so文件,类似于Windows的.dll)thrd_pool.o- 输入的目标文件-o libthrd_pool.so- 输出文件名-I./- 包含头文件路径(当前目录)-L./- 库文件搜索路径(当前目录)-lpthread- 链接pthread库(POSIX线程库)
执行结果: 生成 libthrd_pool.so 动态链接库
测试文件main.c
# 编译 main.c 并链接 libthrd_pool.so
gcc main.c -o main -L./ -lthrd_pool -lpthread -I./
# 需要设置库路径,让系统能找到共享库
export LD_LIBRARY_PATH=./:$LD_LIBRARY_PATH
./main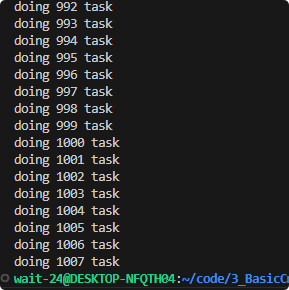
这里为什么不是到1000结束,而是1007结束?
当 done 从999变成1000后:
- 这个线程先执行了
thrdpool_terminate() - 但此时其他线程可能已经在锁外面等待
- 在外面等待的线程,都会再执行一次函数然后才会终止
- 所以它们会继续执行,导致
done继续增加
在thrdpool_terminate之后,是哪一个操作在执行 等待中的线程执行完任务后,再退出。而不是直接退出,不进行等待。
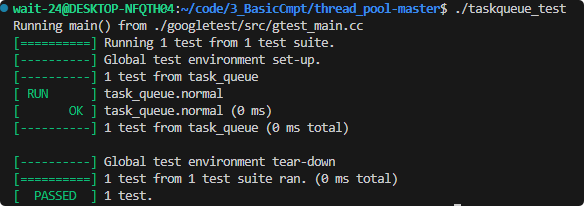
测试文件taskqueue_test.cc
g++ taskqueue_test.cc -o taskqueue_test -lgtest -lgtest_main -lpthread.cc是使用Google Test的测试文件后缀。
为什么没有 main函数?Google Test 框架提供了 main 函数,可以链接lgtest_main。
这样可以简化测试代码,自动注册和运行所有测试
// 测试1:从有到无
// - 添加10个任务
// - 取出10个任务
// - 验证取出了10个
// 测试2:从无到有再到无
// - 队列已空
// - 再添加10个任务
// - 再取出10个任务
// - 验证取出了10个
#include <pthread.h>
#include "spinlock.h"
#include <gtest/gtest.h>
/**
* author: mark
* QQ: 2548898954
* shell: g++ taskqueue_test.cc -o taskqueue_test -lgtest -lgtest_main -lpthread
*/
typedef void (*handler_pt)(void *);
typedef struct spinlock spinlock_t;
typedef struct task_s {
void *next;
handler_pt func;
void *arg;
} task_t;
typedef struct task_queue_s {
void *head;
void **tail;
int block;
spinlock_t lock;
pthread_mutex_t mutex;
pthread_cond_t cond;
} task_queue_t;
static task_queue_t *
__taskqueue_create() {
task_queue_t *queue = (task_queue_t*)malloc(sizeof(task_queue_t));
if (!queue) return NULL;
int ret;
ret = pthread_mutex_init(&queue->mutex, NULL);
if (ret == 0) {
ret = pthread_cond_init(&queue->cond, NULL);
if (ret == 0) {
spinlock_init(&queue->lock);
queue->head = NULL;
queue->tail = &queue->head;
queue->block = 0;
return queue;
}
pthread_cond_destroy(&queue->cond);
}
pthread_mutex_destroy(&queue->mutex);
return NULL;
}
static void
__nonblock(task_queue_t *queue) {
pthread_mutex_lock(&queue->mutex);
queue->block = 0;
pthread_mutex_unlock(&queue->mutex);
pthread_cond_broadcast(&queue->cond);
}
static inline void
__add_task(task_queue_t *queue, void *task) {
void **link = (void **)task;
*link = NULL;
spinlock_lock(&queue->lock);
*queue->tail = link;
queue->tail = link;
spinlock_unlock(&queue->lock);
pthread_cond_signal(&queue->cond);
}
static inline task_t *
__pop_task(task_queue_t *queue) {
spinlock_lock(&queue->lock);
if (queue->head == NULL) {
spinlock_unlock(&queue->lock);
return NULL;
}
task_t *task;
task = (task_t *)queue->head;
queue->head = task->next;
if (queue->head == NULL) {
queue->tail = &queue->head;
}
spinlock_unlock(&queue->lock);
return task;
}
static inline task_t *
__get_task(task_queue_t *queue) {
task_t *task;
while ((task = __pop_task(queue)) == NULL) {
pthread_mutex_lock(&queue->mutex);
if (queue->block == 0) {
pthread_mutex_unlock(&queue->mutex);
break;
}
pthread_cond_wait(&queue->cond, &queue->mutex);
pthread_mutex_unlock(&queue->mutex);
}
return task;
}
static void
__taskqueue_destroy(task_queue_t *queue) {
task_t *task;
while ((task = __pop_task(queue))) {
free(task);
}
pthread_cond_destroy(&queue->cond);
pthread_mutex_destroy(&queue->mutex);
spinlock_destroy(&queue->lock);
free(queue);
}
TEST(task_queue, normal) {
int i;
task_t *task;
task_queue_t * queue = __taskqueue_create();
for (i=0; i<10; i++) {
task_t *task = (task_t*)malloc(sizeof(*task));
__add_task(queue, task);
}
i = 0;
while (queue->head) {
task = __pop_task(queue);
free(task);
i++;
}
// 从有到无
ASSERT_TRUE(i==10);
// 从无到有
for (i=0; i<10; i++) {
task_t *task = (task_t*)malloc(sizeof(*task));
__add_task(queue, task);
}
i = 0;
while (queue->head) {
task = __pop_task(queue);
free(task);
i++;
}
ASSERT_TRUE(i==10);
}
thrdpool_test.cc
#include "thrd_pool.h"
#include <bits/types/time_t.h>
#include <chrono>
#include <cstddef>
#include <cstdint>
#include <atomic>
#include <thread>
#include <iostream>
#include <unistd.h>
/**
* author: mark
* QQ: 2548898954
* shell: g++ -Wl,-rpath=./ thrdpool_test.cc -o thrdpool_test -I./ -L./ -lthrd_pool -lpthread
*/
// 计算任务耗时
time_t GetTick() {
return std::chrono::duration_cast<std::chrono::milliseconds>(
std::chrono::steady_clock::now().time_since_epoch()
).count();
}
std::atomic<int64_t> g_count{0};// 原子计数器,记录已完成任务数
void JustTask(void *ctx) {
++g_count; // 原子递增,线程安全
}
constexpr int64_t n = 1000000;// 每个生产者提交100万个任务
void producer(thrdpool_t *pool) {
for(int64_t i=0; i < n; ++i) {
thrdpool_post(pool, JustTask, NULL);// 提交任务到线程池
}
}
void test_thrdpool(int nproducer, int nconsumer) {
auto pool = thrdpool_create(nconsumer);
for (int i=0; i<nproducer; ++i) {
std::thread(&producer, pool).detach(); // detach 让线程独立运行
}
time_t t1 = GetTick(); // 开始计时
// wait for all producer done
while (g_count.load() != n*nproducer) {
usleep(100000); // 睡眠100ms,避免忙等待
}
time_t t2 = GetTick();// 结束计时
// 起始时间 结束时间 used:耗时(ms) exec per sec:每秒处理任务数
// 5229182 5226480 used:2702 exec per sec:1.48038e+06
std::cout << t2 << " " << t1 << " " << "used:" << t2-t1 << " exec per sec:"
<< (double)g_count.load()*1000 / (t2-t1) << std::endl;
// 清理线程池
thrdpool_terminate(pool);
thrdpool_waitdone(pool);
}
int main() {
// test_thrdpool(1, 8);
test_thrdpool(4, 4); // 4个生产者,4个消费者
return 0;
}