作者:路锦(小蘭)
概述
在移动互联网时代,网络请求性能已成为影响用户体验的关键因素。据统计,转化率会随着页面加载时间增加大幅下降,而移动应用中最常遇到的用户投诉都与"加载慢"、"卡顿"等网络性能问题相关。然而,移动端网络环境的复杂性远超 Web 端:
网络环境多样化
- WiFi、4G/5G、3G、2G 等多种网络制式共存;
- 信号强弱变化、网络切换频繁;
- 不同地域、运营商的网络质量差异巨大。
设备碎片化严重
- Android 设备品牌、型号众多;
- 系统版本从 Android 5.0 到最新版本跨度大;
- 设备性能参差不齐,影响网络处理能力。
问题排查困难
- 缺乏可见性:传统监控只能看到请求成功/失败和总耗时,无法了解具体耗在哪个环节;
- 难以复现:用户反馈"很慢",但开发环境下往往无法复现;
- 缺少量化依据:凭感觉优化,无法评估优化效果;
- 端到端追踪缺失:客户端日志缺失,与服务端监控割裂,无法形成完整链路。
为了解决上述痛点,我们需要将网络请求的"黑盒"变成"透明盒",清晰地看到每个环节的耗时。阿里云 CMS 2.0 的实时应用监控服务(RUM)Android SDK 提供了移动端网络性能监控能力。接下来,我们将详细介绍 RUM SDK 采集的资源指标数据模型,帮助你理解每个指标的含义和计算方式。
资源指标数据说明
要让每个网络请求的各个阶段都清晰可见、可量化,首先需要建立一套标准化的数据模型。阿里云 RUM 采用 Resource 事件作为网络请求监控的核心数据模型。
Resource 事件是专门针对网络请求设计的标准化事件类型,它基于 HTTP 协议和 W3C Performance Timing API 标准制定,确保了数据采集的准确性和可对比性。由于 Performance API 在不同平台环境(Web、iOS、Android、HarmonyOS)下存在实现差异,RUM 针对这些差异进行了修正和对齐,使得无论是Web端还是移动端,开发者都能看到口径一致的性能数据,方便跨平台性能对比和问题排查。
接下来,我们将详细介绍 Resource 事件包含的属性字段和指标字段。
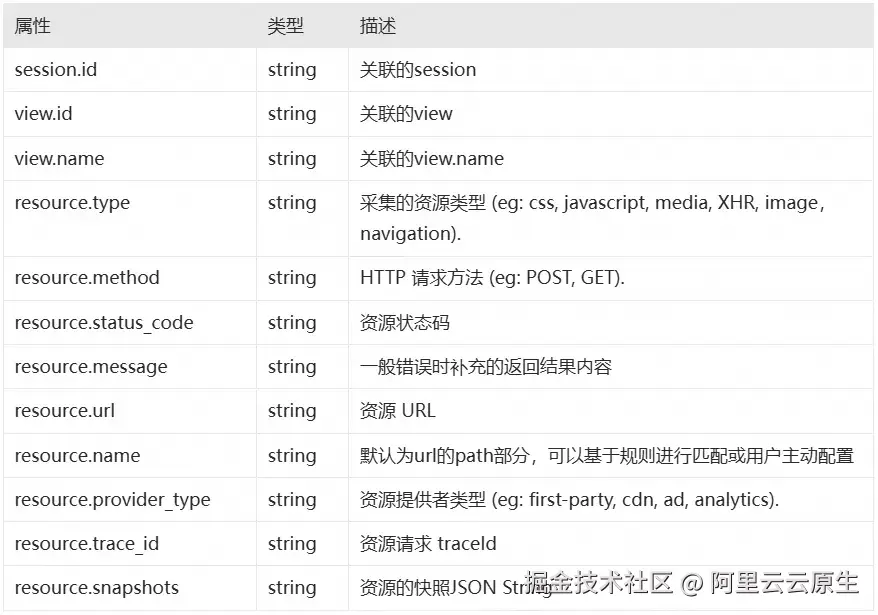
2.1 属性字段说明
Resource 事件包含丰富的属性字段,用于描述请求的上下文信息:
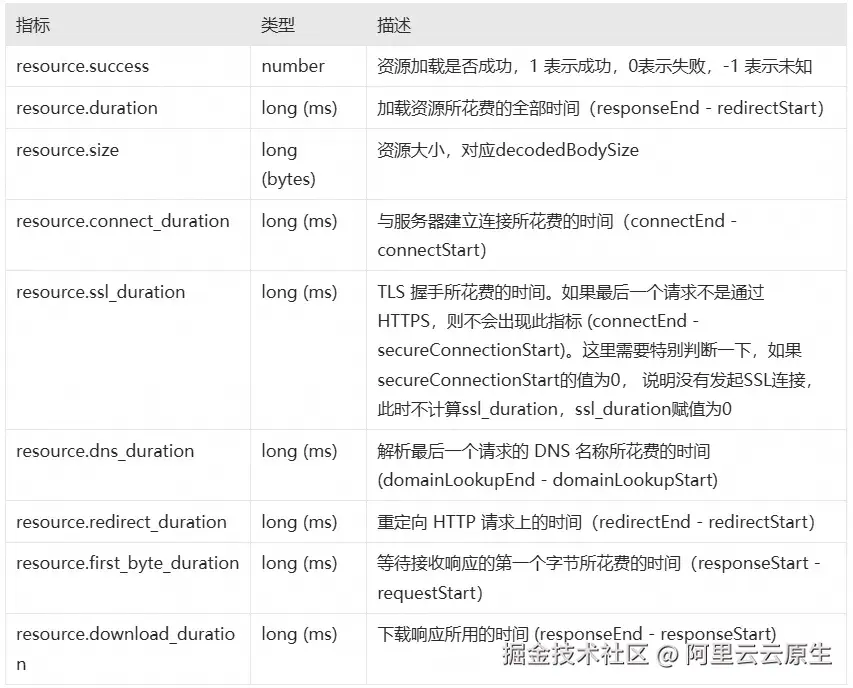
2.2 指标字段说明
除了属性字段,Resource 事件还包含了核心的性能指标,这部分数据是我们排查网络请求慢的核心数据。
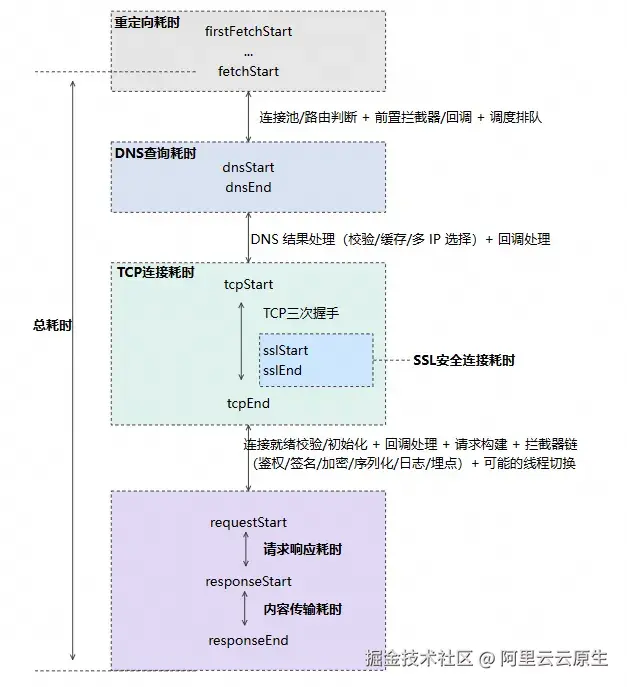
2.3 请求耗时阶段说明
一个完整的 HTTPS 请求通常包含以下关键阶段:
2.4 计算口径
了解了指标的定义,接下来我们深入了解 Android 端基于 OkHttp3 的具体计算实现。
2.4.1 OkHttp3 计算口径
下表展示了 Android 网络资源请求各阶段耗时计算口径,明确定义各个阶段的起止时间点和计算方法。
详细时间起始节点可在原始数据的 resource.timing_data 字段查看。
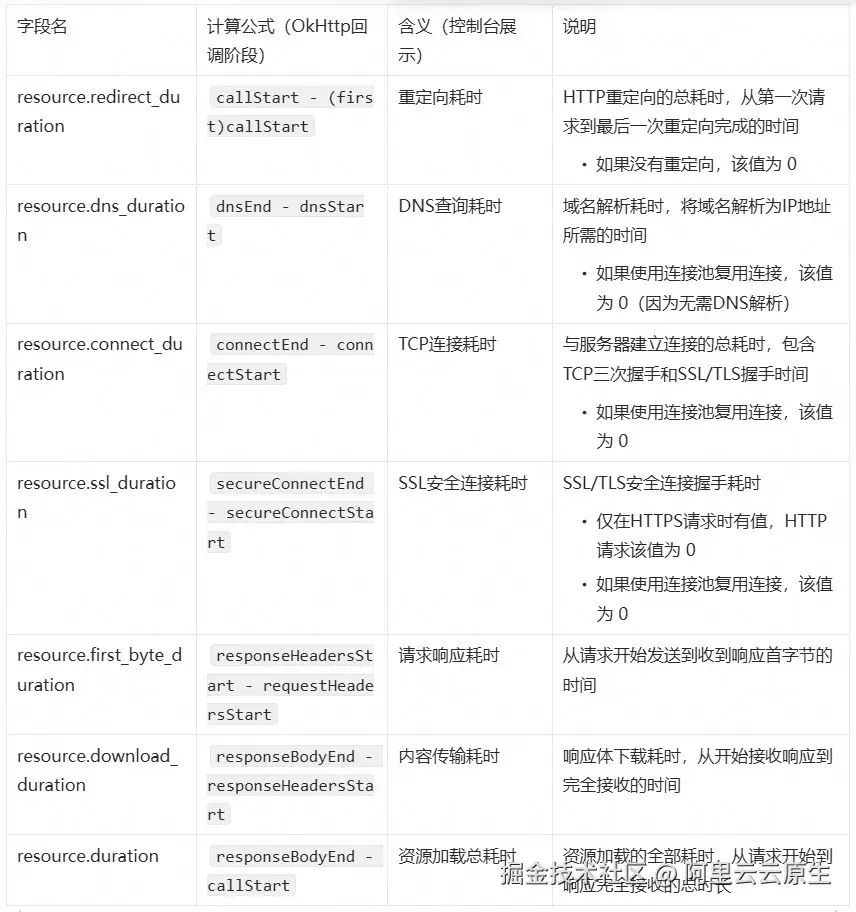
说明:控制台展示的"TCP 连接耗时"实际上包含了 SSL 握手时间。
2.4.2 连接复用识别
根据 RUM SDK 采集到的指标数据,我们可以识别连接是否复用,判断依据如下:
判断依据:
connectionAcquiredTime > 0:连接已获取;dnsStartTime <= 0:没有 DNS 解析回调;tcpStartTime <= 0:没有 TCP 连接回调。
连接复用时的特征:
resource.dns_duration = 0resource.connect_duration = 0resource.ssl_duration = 0- 存在
callStart → connectionAcquired的等待时间(连接池查找时间)
这个等待时间是一个重要的性能指标,如果过长可能说明连接池配置不当。
2.4.3 TCP 与 SSL 连接关系
对于 HTTPS 请求,连接建立分为两个阶段:
scss
connectStart (TCP开始)
↓
[TCP三次握手]
↓
secureConnectStart (SSL握手开始)
↓
[SSL/TLS握手]
↓
secureConnectEnd (SSL握手结束)
↓
connectEnd (连接建立完成)时间关系:
scss
总连接时间 = connectEnd - connectStart
纯TCP时间 = secureConnectStart - connectStart (近似)
SSL时间 = secureConnectEnd - secureConnectStart2.5 控制台指标查看
进入 RUM 控制台-选择您的应用-点击"API 请求"模块-点击具体的一条明细详情,可以查看请求各阶段耗时与耗时分布。
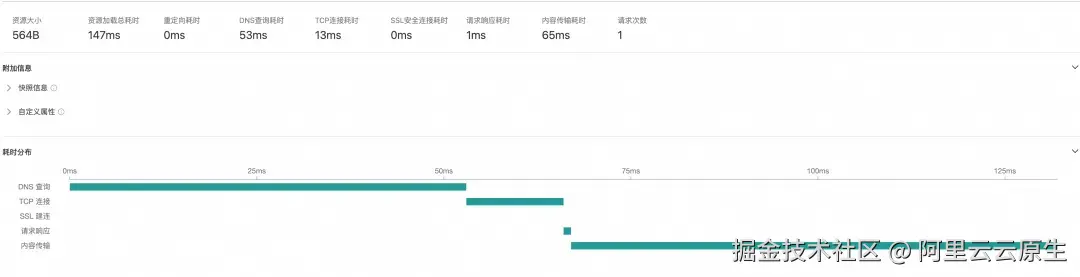
理解了数据模型和计算口径后,让我们通过一个真实的线上案例,看看如何利用这些指标数据快速定位性能问题。
真实用户案例分析
3.1 案例背景
某 APP 收到线上用户投诉,反馈"页面加载特别慢"、"经常转圈超过 1 秒"。开发团队第一时间排查后端服务,却发现了一个令人困惑的现象:客户端反馈某核心接口响应时间经常超过 1 秒(部分用户甚至达到 2-3 秒),无论 WiFi 还是 4G 网络环境都存在此问题,且具有随机性,在开发环境中难以稳定复现;而后端监控却显示接口服务端处理时间稳定在 400ms 左右,数据库查询性能正常无慢查询,服务器 CPU、内存负载也都健康。两边数据对不上!客户端说 1.2 秒,服务端只用了 400ms,那剩下的 800ms 去哪了?在没有细粒度监控的情况下,团队陷入了"盲人摸象"的困境:客户端和服务端相互甩锅,问题迟迟无法解决。通过接入阿里云 RUM Android SDK,我们采集到了详细耗时数据,看看问题是如何被精准定位的。
3.2 Timing Data 原始数据
在 resource.timing_data 字段中,我们获取到了请求各阶段的原始时间点(单位:纳秒):
json
{
"requestHeadersEnd": 1560814315115219,
"responseBodyStart": 1560814719308917,
"requestType": "OkHttp3",
"connectionAcquired": 1560814312934751,
"connectionReleased": 1560814721700948,
"requestBodyEnd": 1560814315850323,
"responseHeadersEnd": 1560814718722250,
"requestHeadersStart": 1560814312975011,
"responseBodyEnd": 1560814719441625,
"requestBodyStart": 1560814315146573,
"callEnd": 1560814721840948,
"duration": 1232825780,
"callStart": 1560813486615845,
"responseHeadersStart": 1560814718314125
}关键观察:
- 没有 DNS/TCP/SSL 相关的回调时间点→ 说明使用了连接池复用;
callStart到connectionAcquired间隔 826ms → 连接池等待时间异常长;- 总耗时
duration= 1232.8ms。
这里已经有了明确的线索:问题不是出在 DNS、TCP 或 SSL 握手上,而是等待连接池分配连接的时间过长。
3.3 详细阶段分析
基于原始数据,结合 2.4 的数据计算口径,我们进行逐阶段耗时计算,精准定位性能瓶颈:
阶段 1:等待连接池分配
ini
callStart → connectionAcquired
耗时: (1560814312934751 - 1560813486615845) / 1,000,000 = 826.32 ms ⚠️说明:
- 从连接池获取可用连接的等待时间;
- 没有 DNS/TCP 回调 = 复用现有连接;
- 这是最大的性能瓶颈!占总耗时的 67%。
阶段 2:发送请求头
ini
requestHeadersStart → requestHeadersEnd
耗时: (1560814315115219 - 1560814312975011) / 1,000,000 = 2.14 ms ✅阶段 3:发送请求体
ini
requestBodyStart → requestBodyEnd
耗时: (1560814315850323 - 1560814315146573) / 1,000,000 = 0.70 ms ✅阶段 4:等待服务器响应(TTFB)
ini
requestBodyEnd → responseHeadersStart
耗时: (1560814718314125 - 1560814315850323) / 1,000,000 = 402.46 ms说明:服务器处理请求的时间,与后端日志吻合,正常范围内。
阶段 5:接收响应头
ini
responseHeadersStart → responseHeadersEnd
耗时: (1560814718722250 - 1560814718314125) / 1,000,000 = 0.41 ms ✅阶段 6:接收响应体
ini
responseBodyStart → responseBodyEnd
耗时: (1560814719441625 - 1560814719308917) / 1,000,000 = 0.13 ms ✅阶段7:连接释放
ini
responseBodyEnd → connectionReleased
耗时: (1560814721700948 - 1560814719441625) / 1,000,000 = 2.26 ms ✅通过这个分析,我们清晰地看到连接池等待时间是性能瓶颈。
3.4 问题诊断
异常点诊断
核心问题:连接池等待时间过长(826ms)
可能的原因:
-
连接池已满 - 所有连接都在使用中,需要等待其他请求释放连接;
-
串行请求排队 - 对同一 Host 的请求过多,受限于
maxRequestsPerHost配置; -
连接泄漏 - 之前的请求没有正确释放连接;
-
连接池配置不当 -
maxIdleConnections设置过小。
诊断步骤
Step 1:检查连接池配置
ini
// 查看当前OkHttpClient的连接池配置
ConnectionPool connectionPool = okHttpClient.connectionPool();
// 默认配置:最多5个空闲连接,保活5分钟检查后发现:应用使用的是 OkHttp 默认配置,只有 5 个空闲连接。
Step 2:监控同时进行的请求数量
通过 RUM 控制台查看该时间段内对同一 Host 的并发请求数量。
Step 3:检查是否有连接泄漏
查看应用日志,确认所有请求都正确关闭了 Response Body:
ini
Response response = client.newCall(request).execute();
try {
String body = response.body().string();
// 处理响应
} finally {
response.close(); // 必须关闭!
}诊断结论:
问题是由连接池配置过小导致的。大量请求在等待连接释放,造成严重的性能瓶颈。
明确了问题原因后,接下来我们将介绍常见的网络性能问题排查方法和优化思路。
常见问题最佳排查实践
通过上述案例,我们看到了如何利用 RUM 数据定位问题。本章节将系统性地介绍 4 类最常见的网络性能问题及其排查方法。
4.1 连接池等待时间过长
症状:在 resource.timing_data 中观察到连接获取耗时异常。
callStart → connectionAcquired 耗时 > 500ms诊断步骤:
Step 1:查看连接池配置
ini
// 检查当前配置
ConnectionPool pool = okHttpClient.connectionPool();
// 默认:5个空闲连接Step 2:查看并发请求数
通过 RUM 控制台查看该时间段的并发请求数:
sql
-- 在RUM控制台执行查询
SELECT
COUNT(*) as concurrent_requests
FROM rum_resource
WHERE
timestamp BETWEEN start_time AND end_time
AND resource.url LIKE 'https://api.example.com%'
GROUP BY timestamp
ORDER BY concurrent_requests DESCStep 3:检查连接泄漏
less
// 添加日志监控连接池状态
interceptor.addInterceptor(chain -> {
ConnectionPool pool = chain.connection().connectionPool();
Log.d("Pool", "Active: " + pool.connectionCount() +
", Idle: " + pool.idleConnectionCount());
return chain.proceed(chain.request());
});优化思路:
scss
// 方案1:增加连接池大小
.connectionPool(new ConnectionPool(30, 5, TimeUnit.MINUTES))
// 方案2:增加每个Host的最大并发数
.dispatcher(new Dispatcher() {{
setMaxRequestsPerHost(10); // 默认5
setMaxRequests(64); // 默认64
}})
// 方案3:请求合并4.2 DNS 解析缓慢
症状:在控制台观察到 DNS 解析耗时持续偏高。
resource.dns_duration > 500ms诊断步骤:
Step 1:确认是 DNS 问题
arduino
检查 resource.dns_duration 是否持续偏高
检查不同网络环境(WiFi vs 4G)的差异Step 2:分析特定域名
vbnet
// 在RUM控制台按域名分组
SELECT
resource.url_host,
AVG(resource.dns_duration) as avg_dns_time,
MAX(resource.dns_duration) as max_dns_time
FROM rum_resource
WHERE resource.dns_duration > 0
GROUP BY resource.url_host
ORDER BY avg_dns_time DESC解决思路:
scss
// 方案1:使用自定义DNS
.dns(new CustomDns())
// 方案2:使用HttpDNS
.dns(new AliHttpDns())
// 方案3:DNS预解析
DnsPreloader.preload(client);4.3 SSL 握手耗时高
症状:在控制台观察到 SSL 握手耗时异常。
resource.ssl_duration > 1000ms诊断步骤:
Step 1:确认 SSL 版本
ini
// 添加拦截器查看SSL信息
interceptor.addInterceptor(chain -> {
Connection connection = chain.connection();
if (connection != null) {
Handshake handshake = connection.handshake();
if (handshake != null) {
Log.d("SSL", "Protocol: " + handshake.tlsVersion());
Log.d("SSL", "Cipher: " + handshake.cipherSuite());
}
}
return chain.proceed(chain.request());
});Step 2:检查连接复用率
sql
// 在RUM控制台查询
SELECT
COUNT(CASE WHEN resource.ssl_duration = 0 THEN 1 END) * 100.0 / COUNT(*) as reuse_rate
FROM rum_resource
WHERE resource.url LIKE 'https://%'优化思路:
scss
// 方案1:启用SSL Session复用
.sslSocketFactory(SslConfig.createSSLSocketFactory())
// 方案2:增加连接保活时间
.connectionPool(new ConnectionPool(30, 10, TimeUnit.MINUTES)) // 延长到10分钟
// 方案3:使用证书固定
.certificatePinner(certificatePinner)4.4 TTFB 过长
症状:从请求发送到收到首字节的时间过长,在控制台上观察"请求响应耗时"较长。
resource.first_byte_duration > 2000ms诊断步骤:
Step 1:排除客户端问题
确认以下指标正常:
- DNS解析时间 < 300ms;
- 连接建立时间 < 500ms;
- 请求发送时间 < 100ms。
Step 2:分析服务器响应时间
TTFB 主要由服务器处理时间决定,如果客户端指标正常,需要:
markdown
1. 检查服务器负载
2. 检查数据库查询性能
3. 检查接口业务逻辑复杂度
4. 使用APM工具追踪服务端性能Step 3:网络路径分析
vbnet
// 通过RUM控制台查看不同地域/运营商的TTFB差异
SELECT
user.region,
user.isp,
AVG(resource.first_byte_duration) as avg_ttfb
FROM rum_resource
GROUP BY user.region, user.isp
ORDER BY avg_ttfb DESC优化思路:
less
// 方案1:使用CDN加速
// 将静态资源和API部署到CDN节点
// 方案2:启用服务器缓存
// 在服务端实现合理的缓存策略
// 方案3:数据预取
// 在用户可能访问前提前请求数据
PreloadManager.preload("https://api.example.com/user/profile");
// 方案4:请求优先级管理
.dispatcher(new Dispatcher() {{
// 高优先级请求使用单独的线程池
}})案例小结
通过前面 4 类常见问题的排查方法,我们掌握了系统化的诊断思路。现在,让我们回到第 3 章那个困扰团队多日的真实案例------连接池等待时间 826ms 的性能瓶颈。通过 RUM 数据的精准定位,我们发现问题的根源在于连接池配置不当导致请求排队等待,而解决方案其实很简单:根据不同应用类型选择合适的连接池配置。
配置建议:
针对 OkHttpClient 的 maxIdleConnections 参数(默认值为 5),建议根据应用特点进行调整,根据经验常见的配置如下:
-
高并发应用:
maxIdleConnections = 30-50这类应用用户活跃度高,网络请求频繁且并发量大,需要充足的连接池支撑;
-
一般应用:
maxIdleConnections = 10-20适中的请求频率和并发量,保持适度的连接池规模即可;
-
低频应用:
maxIdleConnections = 5-10用户请求较少,保持默认配置或略微增加即可满足需求。
从事后优化到主动监控:
然而,这个案例也给我们带来了更深层的思考------性能优化不应该是"亡羊补牢"式的事后补救。除了掌握事后排查和优化的方法,更重要的是建立一套完善的性能监控体系,通过 RUM 控制台实时掌握应用的网络性能指标,将"被动救火"转变为"主动观测"。如果有需要,还可以基于 RUM 平台自定义配置告警规则(如连接池等待时间P95 > 500ms 时触发通知),进一步提升问题响应速度。
监控告警配置建议
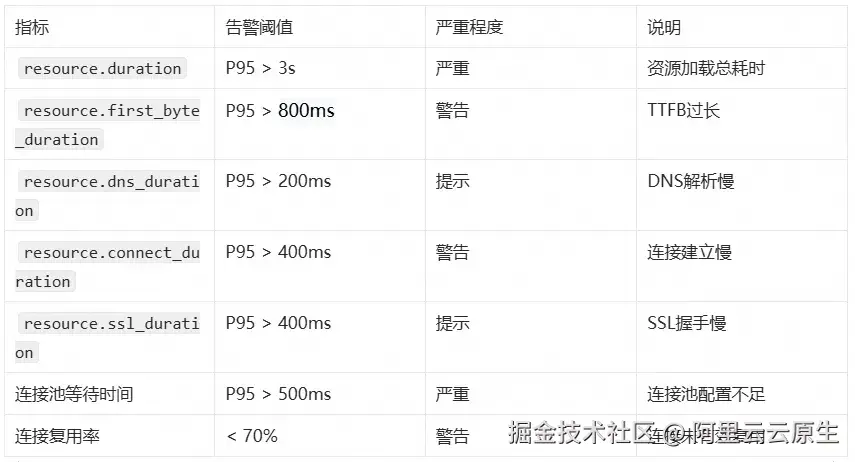
RUM 数据允许用户创建自定义告警进行实时监控,建立科学的监控告警体系,可以在问题影响用户之前及时发现并处理。
指标告警阈值参考
根据 RAIL 模型、 Google Web Vitals 等业界实践,常见的阈值参考如下:
总结
在移动应用开发中,网络请求性能直接影响用户体验。通过接入阿里云 RUM Android SDK,开发者可以获得以下核心能力:
精准定位性能瓶颈
- 细粒度的阶段耗时(DNS、TCP、SSL、TTFB 等)帮助快速识别问题;
- 从"请求慢"的模糊描述,到"连接池等待 826ms"的精准定位。
连接复用分析
- 自动识别连接池使用效率;
- 发现连接泄漏、连接池配置不当等隐藏问题。
真实用户体验监控
- 基于真实用户的网络环境采集数据;
- 按地域、运营商、网络类型等维度分析性能差异。
数据驱动优化
- 优化前后对比清晰可见;
- 建立性能基准和告警机制,持续改进。
阿里云 CMS 2.0 的 RUM 针对 Android 端实现了对应用性能、稳定性、和用户行为的无侵入式监控采集 SDK,可以参考接入文档 ** **1 体验使用。除了 Android 外,RUM 也支持Web、小程序、iOS、鸿蒙等多种平台监控分析,相关问题可以加入"RUM 用户体验监控支持群"(钉钉群号: 67370002064)进行咨询。
相关链接:
1 接入文档