ThreadPoolExecutor七参数详解:拒绝Executors,手动掌控线程池
作者 :Weisian
发布时间:2026年3月

直击痛点:
"生产环境突然OOM(内存溢出),排查发现是
Executors.newFixedThreadPool创建的线程池,任务队列无界堆积,撑爆了堆内存;或者newCachedThreadPool在高并发下创建了上万个线程,导致CPU 100%系统假死。90%的开发者还在用阿里禁止的Executors工具类创建线程池,却不知道手动配置ThreadPoolExecutor才是保命的唯一正解。"
在Java并发编程中,ThreadPoolExecutor是线程池的"终极实现",它提供了7个可配置参数,让你能精准控制线程池的行为:
- 核心参数 :
corePoolSize、maximumPoolSize、keepAliveTime、unit、workQueue、threadFactory、handler; - 执行流程:任务提交后,先判断核心线程→再入队→最后创建非核心线程→触发拒绝策略;
- 阿里规范 :《阿里巴巴Java开发手册》强制规定"线程池不允许使用Executors去创建,推荐通过ThreadPoolExecutor方式";
- 面试高频问:"ThreadPoolExecutor的7个参数含义?""任务提交流程是什么?""为什么不能用Executors?"------答不上来=错失大厂offer。
本文将从生产事故案例 切入,结合动态图解 、源码分析 、实战模板 ,彻底讲透ThreadPoolExecutor的设计原理和最佳实践:
✅ 警示:Executors创建线程池导致OOM的血泪案例;
✅ 图解:ThreadPoolExecutor七大参数的核心含义与生活类比;
✅ 核心:任务提交的"三步走"执行流程(源码级拆解);
✅ 实战:生产环境线程池标准创建模板(CPU/IO密集型适配);
✅ 进阶:线程池五种状态与优雅停机方案;
✅ 避坑:拒绝策略选型、线程工厂定制、keepAliveTime调优;
✅ 面试:高频真题标准答案(直接背)。
📌 核心一句话 :
ThreadPoolExecutor通过7个参数实现精细化资源管控:核心线程保底,队列缓冲峰值,非核心线程应急,拒绝策略兜底 。手动创建线程池能避免OOM和线程爆炸,是生产环境的唯一选择。CPU密集型线程池大小设为CPU核心数+1,IO密集型设为CPU核心数×2或更高。
📌 面试金句先记牢:
- 线程池七大参数:
corePoolSize(核心线程数)、maximumPoolSize(最大线程数)、keepAliveTime(非核心线程空闲超时时间)、unit(时间单位)、workQueue(任务队列)、threadFactory(线程工厂)、handler(拒绝策略);- 任务提交流程:先判断核心线程→未满则创建核心线程;已满则尝试入队;入队失败则创建非核心线程;仍失败则触发拒绝策略;
- Executors的坑 :
newFixedThreadPool和newSingleThreadExecutor使用无界队列 (LinkedBlockingQueue),可能导致OOM;newCachedThreadPool允许最大线程数为Integer.MAX_VALUE,可能导致线程爆炸;- 队列选型 :高并发场景用有界队列(如ArrayBlockingQueue),避免内存溢出;
- 拒绝策略 :默认
AbortPolicy抛异常,生产环境常用CallerRunsPolicy(调用者运行)或自定义策略;- 线程池五种状态:RUNNING(运行)、SHUTDOWN(关闭接收新任务)、STOP(停止所有任务)、TIDYING(整理)、TERMINATED(终止);
- CPU密集型线程池大小 = CPU核心数 + 1,IO密集型 = CPU核心数 × 2(或根据IO等待时间调整);
keepAliveTime可通过allowCoreThreadTimeOut(true)作用于核心线程;- 线程工厂必须定制线程名称,便于问题排查。
- 阿里规范:强制要求手动创建ThreadPoolExecutor,明确指定所有参数。
一、血的教训:Executors创建线程池导致OOM
1.1 生产事故现场
某电商大促期间,订单系统突然崩溃,日志显示java.lang.OutOfMemoryError: Java heap space。排查发现,开发使用了Executors.newFixedThreadPool(10):
java
// 错误示范:使用Executors创建线程池
ExecutorService executor = Executors.newFixedThreadPool(10);
// 高并发下,大量任务提交
for (int i = 0; i < 1000000; i++) {
executor.submit(() -> {
// 模拟慢SQL查询,耗时5秒
Thread.sleep(5000);
});
}问题根源:
Executors.newFixedThreadPool()内部使用无界队列LinkedBlockingQueue(容量为Integer.MAX_VALUE);- 当任务处理速度 < 提交速度时,任务在队列中无限堆积;
- 每个任务对象占用内存,最终撑爆堆内存,导致OOM。
堆栈信息:
Exception in thread "main" java.lang.OutOfMemoryError: Java heap space
at java.util.concurrent.LinkedBlockingQueue.offer(LinkedBlockingQueue.java:416)
at java.util.concurrent.ThreadPoolExecutor.execute(ThreadPoolExecutor.java:1371)
at com.example.OrderService.processOrder(OrderService.java:45)
...1.2 Executors的三大"坑"
Executors提供的线程池工具类看似便捷,实则隐藏致命缺陷:
| 方法 | 内部实现 | 风险 | 后果 |
|---|---|---|---|
newFixedThreadPool(n) |
new ThreadPoolExecutor(n, n, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<>()) |
无界队列 | 任务堆积,OOM |
newSingleThreadExecutor() |
new ThreadPoolExecutor(1, 1, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<>()) |
无界队列 | 任务堆积,OOM |
newCachedThreadPool() |
new ThreadPoolExecutor(0, Integer.MAX_VALUE, 60L, TimeUnit.SECONDS, new SynchronousQueue<>()) |
最大线程数无界 | 线程爆炸,CPU 100% |

错误示范:
java
// 生产环境严禁使用!
public class BadThreadPoolDemo {
// 固定线程池+无界队列 → 任务堆积OOM
private static ExecutorService executor = Executors.newFixedThreadPool(50);
public void processOrder(Order order) {
executor.submit(() -> {
// 处理订单逻辑
saveOrder(order);
sendMessage(order);
});
}
}为什么会OOM :
newFixedThreadPool的队列是LinkedBlockingQueue,默认容量为Integer.MAX_VALUE,相当于"无限大"。
结论 :Executors隐藏了关键参数,导致开发者无法控制队列长度和最大线程数,生产环境必须手动创建ThreadPoolExecutor
二、ThreadPoolExecutor七大参数:从原理到生活类比
2.1 核心设计思想
线程池的本质是池化技术,核心目标:
- 复用线程:避免频繁创建/销毁线程的性能开销;
- 管控资源:限制最大线程数,防止CPU/内存耗尽;
- 缓冲任务:通过队列平滑突发流量,削峰填谷。
ThreadPoolExecutor的7个参数共同构成了线程池的"资源管控体系",先看整体结构:
java
// ThreadPoolExecutor核心构造方法
public ThreadPoolExecutor(
int corePoolSize, // 核心线程数
int maximumPoolSize, // 最大线程数
long keepAliveTime, // 非核心线程空闲超时时间
TimeUnit unit, // 时间单位
BlockingQueue<Runnable> workQueue, // 任务队列
ThreadFactory threadFactory, // 线程工厂
RejectedExecutionHandler handler // 拒绝策略
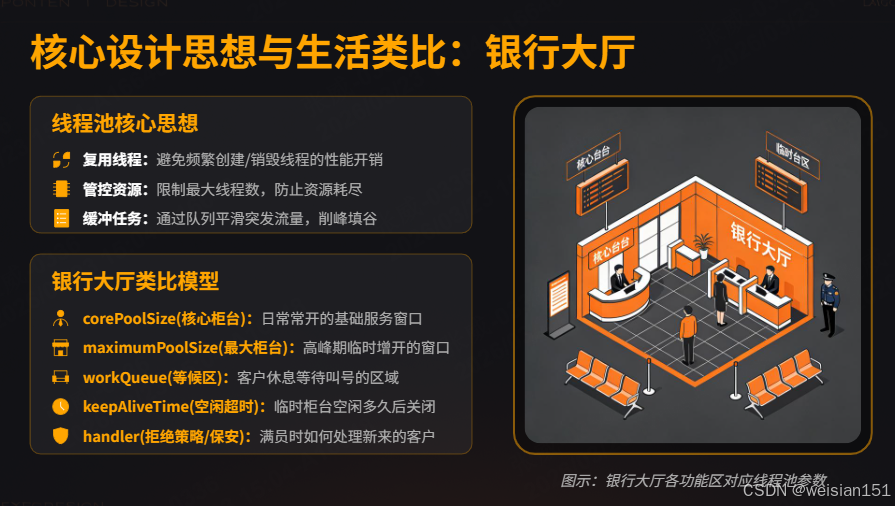
)想象一个银行大厅,有若干柜台(线程)和一个等候区(队列):
- 核心柜台(corePoolSize):常开的柜台数量,即使没人也要保留;
- 最大柜台(maximumPoolSize):高峰期临时增开的柜台数量;
- 等候区(workQueue):客户排队等待的区域,容量有限;
- 空闲超时(keepAliveTime):临时柜台空闲多久后关闭;
- 保安(handler):等候区满了且所有柜台都在忙,新来的客户如何处理(拒绝策略)。
业务流程(三步走):
- 第一步:客户到来,如果核心柜台有空闲,直接办理;如果核心柜台全满,进入第二步;
- 第二步:客户进入等候区排队;如果等候区已满,进入第三步;
- 第三步:开启临时柜台(非核心线程)办理;如果所有柜台(核心+临时)都在忙,保安介入(拒绝策略)。
2.2 七大参数逐个拆解(附生活类比)
2.2.1 corePoolSize:核心线程数(常驻线程数)
- 定义 :线程池长期保持的线程数量,即使线程空闲也不会销毁(除非设置
allowCoreThreadTimeOut(true)); - 生活类比:餐厅的"正式员工",即使没客人也会留在店里,随时待命;
- 配置技巧 :
- CPU密集型:
N + 1(N为CPU核数); - IO密集型:
2N或N / (1 - 阻塞系数);
- CPU密集型:
- 核心特性 :
- 任务提交时,若核心线程数未达
corePoolSize,立即创建新线程处理任务; - 核心线程默认不会被销毁,避免频繁创建线程的开销。
- 任务提交时,若核心线程数未达
2.2.2 maximumPoolSize:最大线程数(总线程数上限)
- 定义:线程池允许创建的最大线程数,包含核心线程+非核心线程;
- 生活类比:餐厅的"正式员工+临时工"总数上限,忙时招临时工,闲时辞退临时工;
- 配置技巧 :
- 必须 >= corePoolSize;
- 仅当队列满且核心线程全忙时,才会创建非核心线程;
- 高并发场景需根据服务器资源合理设置,避免过大。
- 核心特性 :
- 仅当任务队列满时,才会创建非核心线程(核心线程已用完);
- 非核心线程是"临时线程",空闲超时后会被销毁。

2.2.3 keepAliveTime + unit:非核心线程空闲超时时间和单位
- 定义:非核心线程空闲超过该时间,会被销毁,释放资源;
- 生活类比:餐厅临时工空闲超过1小时,就被辞退;
- 特殊用法 :调用
allowCoreThreadTimeOut(true)后,核心线程也会超时回收; - 配置技巧 :
- 默认仅对非核心线程生效;
- IO密集型场景可设置较短时间(如30秒),快速释放资源;
- CPU密集型场景可设置较长时间或不回收。
- 核心特性 :
- 仅作用于非核心线程(默认);
- 调用
allowCoreThreadTimeOut(true)后,核心线程也会受该参数影响; unit指定时间单位(如TimeUnit.SECONDS)。

2.2.4 workQueue:任务队列(缓冲队列)
- 定义:核心线程满后,新任务会被放入队列等待执行;
- 生活类比:餐厅座位坐满后,客人排队等待的候客区;
- 配置技巧 :生产环境必须使用有界队列 (如
new ArrayBlockingQueue<>(1000)),避免OOM。 - 常用队列类型:
| 队列类型 | 特点 | 适用场景 |
|---|---|---|
ArrayBlockingQueue(有界数组队列) |
固定容量,FIFO,可防止OOM | 生产环境首选,可控队列大小 |
LinkedBlockingQueue(无界链表队列) |
默认无界,易OOM | 仅低并发场景使用 |
SynchronousQueue(同步队列) |
无缓冲,直接传递任务 | 高并发、低延迟场景(如newCachedThreadPool) |
PriorityBlockingQueue(优先级队列) |
按优先级执行任务 | 需任务优先级排序的场景 |

2.2.5 threadFactory:线程工厂
- 定义:创建线程的工厂类,可定制线程名称、优先级、是否守护线程;
- 生活类比:餐厅的"人事部门",负责招聘员工(创建线程),并给员工编号(线程名称);
- 核心价值 :
- 定制线程名称(如
order-thread-pool-1),便于日志排查问题; - 设置线程为守护线程,避免主线程退出后线程池残留。
- 定制线程名称(如
- 注意 :未指定时使用默认工厂,线程名为
pool-N-thread-M,不利于排查。
2.2.6 handler:拒绝策略
- 定义 :当线程数达
maximumPoolSize且队列满时,新任务的处理策略; - 生活类比:餐厅满员+候客区满,对新到客人的处理方式(道歉/等位/安排到分店);
- JDK内置拒绝策略:
| 拒绝策略 | 核心逻辑 | 适用场景 |
|---|---|---|
AbortPolicy(默认) |
抛出RejectedExecutionException |
核心业务,快速失败,便于监控 |
CallerRunsPolicy |
由提交任务的线程自己执行 | 兜底策略,避免任务丢失 |
DiscardPolicy |
静默丢弃任务,无任何提示 | 非核心业务,允许丢失 |
DiscardOldestPolicy |
丢弃队列中最老的任务,尝试提交新任务 | 允许丢弃旧任务的场景 |
- 自定义策略 :可实现
RejectedExecutionHandler接口,记录日志、报警或持久化任务。

2.3 线程池执行流程图
否
是
否
是
否
是
提交任务
核心线程数
corePoolSize 已满?
创建核心线程执行任务
任务队列
workQueue 已满?
任务入队等待
最大线程数
maximumPoolSize 已满?
创建非核心线程执行任务
触发拒绝策略
RejectedExecutionHandler

关键点:
- 任务优先分配给核心线程;
- 核心线程满后,优先入队,而不是立即创建非核心线程;
- 只有队列满后,才创建非核心线程;
- 非核心线程空闲超过
keepAliveTime会被回收。
三、线程池执行流程:源码级拆解"三步走"
3.1 核心流程:任务提交的完整路径
线程池的execute()方法是任务提交的入口,核心逻辑可总结为"三步走":
第一步:核心线程池未满 → 创建核心线程执行任务
- 当线程池中的线程数 <
corePoolSize时,无论是否有空闲线程,都会创建新的核心线程处理任务; - 核心线程创建后,默认长期存活(除非设置
allowCoreThreadTimeOut(true))。
第二步:核心线程池已满 → 任务加入队列等待
- 核心线程数已达
corePoolSize,且有核心线程空闲 → 任务放入队列,空闲核心线程从队列取任务执行; - 队列是线程池"削峰填谷"的核心,避免瞬间创建大量线程。
第三步:队列已满 → 创建非核心线程(直到最大线程数)
- 队列已满,且线程数 <
maximumPoolSize→ 创建非核心线程处理任务; - 非核心线程空闲超时后,会被销毁,释放资源。
终极:线程数达最大 + 队列满 → 执行拒绝策略
- 所有线程都在工作,队列也满了 → 触发拒绝策略,处理新任务。

3.2 源码拆解:execute()方法核心逻辑
java
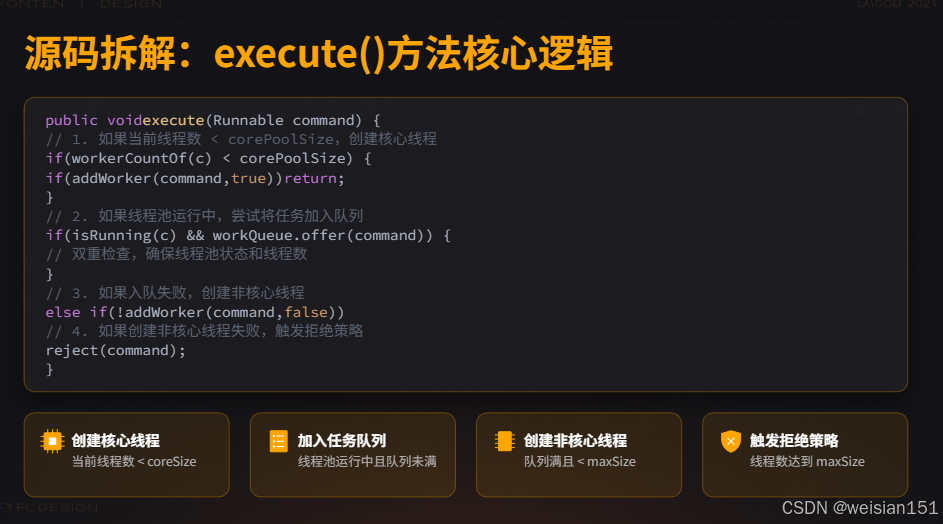
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
int c = ctl.get(); // ctl是线程池状态+线程数的复合变量
// 1. 如果当前线程数 < corePoolSize,创建核心线程
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true)) // true表示核心线程
return;
c = ctl.get();
}
// 2. 如果线程池处于RUNNING状态,尝试将任务加入队列
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
// 双重检查:如果线程池已关闭,移除任务并执行拒绝策略
if (!isRunning(recheck) && remove(command))
reject(command);
// 如果当前无线程,创建一个线程处理队列中的任务
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
// 3. 如果入队失败(队列满),创建非核心线程
else if (!addWorker(command, false))
// 4. 如果创建非核心线程失败(达到maxPoolSize),触发拒绝策略
reject(command);
}
3.3 动态图解:任务执行流程
假设配置:corePoolSize=2,maximumPoolSize=4,workQueue=ArrayBlockingQueue(2)
| 任务数 | 执行动作 | 线程数 | 队列状态 |
|---|---|---|---|
| 任务1 | 创建核心线程1执行 | 1 | 空 |
| 任务2 | 创建核心线程2执行 | 2 | 空 |
| 任务3 | 加入队列 | 2 | 任务3 |
| 任务4 | 加入队列 | 2 | 任务3, 任务4 |
| 任务5 | 创建非核心线程3执行 | 3 | 任务3, 任务4 |
| 任务6 | 创建非核心线程4执行 | 4 | 任务3, 任务4 |
| 任务7 | 队列满+线程数达最大 → 执行拒绝策略 | 4 | 任务3, 任务4 |
四、线程池的五种状态:从运行到终止
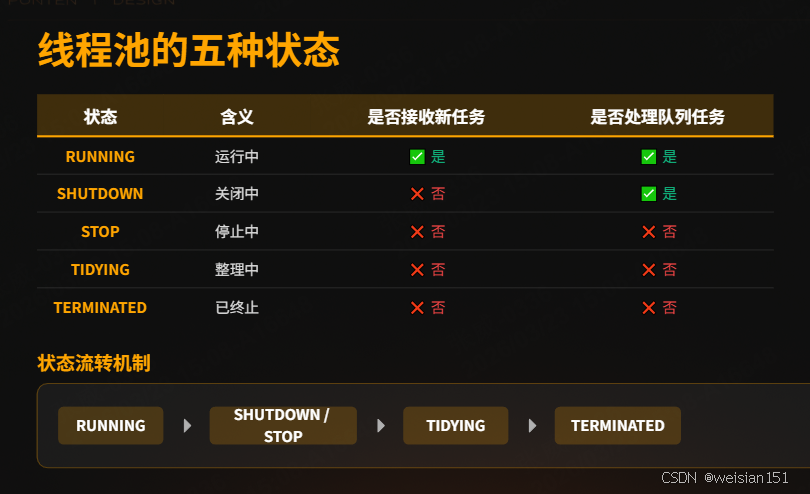
4.1 状态定义
线程池通过ctl变量(AtomicInteger)维护状态,高3位表示状态,低29位表示线程数:
| 状态 | 二进制值 | 含义 | 是否接收新任务 | 是否处理队列任务 |
|---|---|---|---|---|
| RUNNING | 111... | 运行中 | ✅ 是 | ✅ 是 |
| SHUTDOWN | 000... | 关闭中 | ❌ 否 | ✅ 是 |
| STOP | 001... | 停止中 | ❌ 否 | ❌ 否 |
| TIDYING | 010... | 整理中 | ❌ 否 | ❌ 否 |
| TERMINATED | 011... | 已终止 | ❌ 否 | ❌ 否 |
4.2 ### 状态转换图
shutdown()
shutdownNow()
队列空且线程数为0
线程数为0
terminated()回调完成
RUNNING
SHUTDOWN
STOP
TIDYING
TERMINATED
状态说明:
- RUNNING:正常状态,接收新任务,处理队列任务;
- SHUTDOWN :调用
shutdown()后进入,不再接收新任务,但会处理完队列中的任务; - STOP :调用
shutdownNow()后进入,不再接收新任务,中断正在执行的任务,丢弃队列任务; - TIDYING :所有任务完成,线程数为0,准备调用
terminated(); - TERMINATED :
terminated()执行完毕,线程池彻底终止。
4.3 优雅停机实践
生产环境必须手动关闭线程池,避免资源泄漏:
java
// 优雅关闭线程池
public void shutdownThreadPool(ExecutorService executor) {
// 第一步:关闭接收新任务,处理队列任务
executor.shutdown();
try {
// 第二步:等待60秒,让队列任务执行完毕
if (!executor.awaitTermination(60, TimeUnit.SECONDS)) {
// 第三步:超时未完成,强制关闭,中断所有线程
List<Runnable> unfinishedTasks = executor.shutdownNow();
// 记录未完成的任务,便于排查
log.warn("线程池强制关闭,未完成任务数:{}", unfinishedTasks.size());
}
} catch (InterruptedException e) {
// 捕获中断异常,再次强制关闭
executor.shutdownNow();
Thread.currentThread().interrupt();
}
}
五、实战:生产环境线程池标准创建模板
5.1 线程池大小设置原则
线程池大小直接影响性能,需根据任务类型调整:
5.1.1 CPU密集型任务
- 特点:任务主要消耗CPU资源(如计算、排序),CPU利用率高,线程切换开销大;
- 公式 :线程池大小 =
N + 1(N为CPU核数); - 原因:+1是为了防止某个线程因页缺失故障或IO操作暂停时,有备用线程利用CPU资源。
5.1.2 IO密集型任务
- 特点:任务大量等待IO(如数据库查询、网络请求、文件),CPU利用率低,线程大部分时间在等待;;
- 公式 :线程池大小 =
CPU核心数 × 2(或CPU核心数 / (1 - 阻塞系数),阻塞系数通常0.8~0.9); - 示例:8核CPU,阻塞系数0.9 → 8 / (1-0.9) = 80个线程。

5.2 标准创建模板(可直接落地)
java
import lombok.extern.slf4j.Slf4j;
import java.util.concurrent.*;
import java.util.concurrent.atomic.AtomicInteger;
/**
* 生产环境线程池标准创建模板
* 核心:拒绝Executors,手动配置所有参数
*/
@Slf4j
public class StandardThreadPool {
// 获取CPU核心数
private static final int CPU_CORES = Runtime.getRuntime().availableProcessors();
// 订单处理线程池(IO密集型)
private static ExecutorService orderThreadPool;
// 数据计算线程池(CPU密集型)
private static ExecutorService computeThreadPool;
// 静态初始化线程池
static {
// 1. 订单处理线程池(IO密集型)
orderThreadPool = new ThreadPoolExecutor(
CPU_CORES * 2, // 核心线程数:8核CPU → 16
CPU_CORES * 4, // 最大线程数:8核CPU → 32
60, // 非核心线程空闲超时时间:60秒
TimeUnit.SECONDS, // 时间单位
new ArrayBlockingQueue<>(1000), // 有界队列:容量1000,防止OOM
new CustomThreadFactory("order-thread-pool"), // 定制线程工厂
new CustomRejectedHandler() // 定制拒绝策略
);
// 允许核心线程超时销毁(可选,根据业务调整)
((ThreadPoolExecutor) orderThreadPool).allowCoreThreadTimeOut(true);
// 2. 数据计算线程池(CPU密集型)
computeThreadPool = new ThreadPoolExecutor(
CPU_CORES + 1, // 核心线程数:8核CPU → 9
CPU_CORES + 1, // 最大线程数:8核CPU → 9(无临时线程)
0, // 非核心线程超时时间:0(无意义)
TimeUnit.SECONDS,
new ArrayBlockingQueue<>(100), // 有界队列:容量100
new CustomThreadFactory("compute-thread-pool"),
new ThreadPoolExecutor.CallerRunsPolicy() // 兜底拒绝策略
);
}
/**
* 定制线程工厂:统一命名线程,便于排查问题
*/
static class CustomThreadFactory implements ThreadFactory {
// 线程编号
private final AtomicInteger threadNum = new AtomicInteger(1);
// 线程池名称前缀
private final String namePrefix;
public CustomThreadFactory(String namePrefix) {
this.namePrefix = namePrefix;
}
@Override
public Thread newThread(Runnable r) {
Thread thread = new Thread(r, namePrefix + "-" + threadNum.getAndIncrement());
// 设置为非守护线程,避免主线程退出后线程池被销毁
thread.setDaemon(false);
// 设置线程优先级:默认5,避免抢占核心线程资源
thread.setPriority(Thread.NORM_PRIORITY);
// 设置未捕获异常处理器,避免线程异常退出无日志
thread.setUncaughtExceptionHandler((t, e) ->
log.error("线程{}执行异常", t.getName(), e));
return thread;
}
}
/**
* 定制拒绝策略:记录日志+抛出异常(核心业务)
*/
static class CustomRejectedHandler implements RejectedExecutionHandler {
@Override
public void rejectedExecution(Runnable r, ThreadPoolExecutor executor) {
// 1. 记录拒绝日志(包含线程池状态、队列大小等)
log.error("线程池拒绝执行任务!线程池状态:{},核心线程数:{},最大线程数:{},队列大小:{},活跃线程数:{}",
getPoolState(executor),
executor.getCorePoolSize(),
executor.getMaximumPoolSize(),
executor.getQueue().size(),
executor.getActiveCount());
// 2. 核心业务抛出异常,触发告警
throw new RejectedExecutionException("订单处理线程池已满,拒绝执行任务:" + r.toString());
}
// 获取线程池状态字符串
private String getPoolState(ThreadPoolExecutor executor) {
if (executor.isShutdown()) return "SHUTDOWN";
if (executor.isTerminating()) return "TERMINATING";
if (executor.isTerminated()) return "TERMINATED";
return "RUNNING";
}
}
// 获取订单线程池
public static ExecutorService getOrderThreadPool() {
return orderThreadPool;
}
// 获取计算线程池
public static ExecutorService getComputeThreadPool() {
return computeThreadPool;
}
// 优雅关闭线程池
public static void shutdown() {
log.info("开始关闭订单线程池...");
shutdownThreadPool(orderThreadPool);
log.info("开始关闭计算线程池...");
shutdownThreadPool(computeThreadPool);
}
// 通用关闭方法
private static void shutdownThreadPool(ExecutorService executor) {
executor.shutdown();
try {
if (!executor.awaitTermination(60, TimeUnit.SECONDS)) {
List<Runnable> unfinished = executor.shutdownNow();
log.warn("线程池强制关闭,未完成任务数:{}", unfinished.size());
}
} catch (InterruptedException e) {
executor.shutdownNow();
Thread.currentThread().interrupt();
}
}
// 测试
public static void main(String[] args) {
// 提交订单任务
ExecutorService orderPool = StandardThreadPool.getOrderThreadPool();
for (int i = 0; i < 20; i++) {
int taskId = i;
orderPool.submit(() -> {
log.info("处理订单任务:{},线程:{}", taskId, Thread.currentThread().getName());
try {
Thread.sleep(100); // 模拟IO操作
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
});
}
// 提交计算任务
ExecutorService computePool = StandardThreadPool.getComputeThreadPool();
for (int i = 0; i < 10; i++) {
int taskId = i;
computePool.submit(() -> {
log.info("执行计算任务:{},线程:{}", taskId, Thread.currentThread().getName());
long sum = 0;
for (long j = 0; j < 100000000; j++) {
sum += j; // 模拟CPU计算
}
});
}
// 关闭线程池
StandardThreadPool.shutdown();
}
}核心亮点:
- 拒绝Executors:手动配置所有参数,使用有界队列防止OOM;
- 线程工厂定制:统一线程命名,设置未捕获异常处理器,便于问题排查;
- 拒绝策略定制:记录详细日志+抛出异常,触发监控告警;
- 分场景配置:IO/CPU密集型线程池参数差异化配置;
- 优雅停机:提供统一的线程池关闭方法,避免资源泄漏。
六、避坑指南:线程池配置的常见错误

6.1 错误1:使用无界队列(LinkedBlockingQueue)
java
// 错误:无界队列导致任务堆积,最终OOM
ExecutorService executor = new ThreadPoolExecutor(
10, 20, 60, TimeUnit.SECONDS,
new LinkedBlockingQueue<>(), // 无界队列
new DefaultThreadFactory(),
new AbortPolicy()
);解决 :生产环境必须使用有界队列(ArrayBlockingQueue),并设置合理容量。
6.2 错误2:最大线程数设置过大
java
// 错误:8核CPU设置1000个最大线程,导致CPU上下文切换飙升
ExecutorService executor = new ThreadPoolExecutor(
50, 1000, 60, TimeUnit.SECONDS,
new ArrayBlockingQueue<>(100),
new DefaultThreadFactory(),
new AbortPolicy()
);后果 :线程数远超CPU处理能力,大量时间消耗在上下文切换,系统响应变慢。
解决:按CPU/IO密集型原则设置,8核CPU的IO密集型线程池最大线程数建议不超过100。
6.3 错误3:核心线程数=最大线程数,却设置keepAliveTime
java
// 无意义:核心线程数=最大线程数,无临时线程,keepAliveTime无效
ExecutorService executor = new ThreadPoolExecutor(
20, 20, 60, TimeUnit.SECONDS, // 核心=最大
new ArrayBlockingQueue<>(100),
new DefaultThreadFactory(),
new AbortPolicy()
);优化 :若无需临时线程,可设置keepAliveTime=0,或调用allowCoreThreadTimeOut(true)让核心线程超时销毁。
6.4 错误4:拒绝策略选DiscardPolicy(核心业务)
java
// 错误:核心订单业务用DiscardPolicy,任务丢失无感知
ExecutorService executor = new ThreadPoolExecutor(
10, 20, 60, TimeUnit.SECONDS,
new ArrayBlockingQueue<>(100),
new DefaultThreadFactory(),
new DiscardPolicy() // 静默丢弃
);解决 :核心业务优先选AbortPolicy(抛异常)或CallerRunsPolicy(兜底执行),非核心业务才用DiscardPolicy。
6.5 错误5:未优雅关闭线程池
java
// 错误:直接退出,任务可能丢失
public void process() {
ThreadPoolExecutor executor = ...;
// 提交任务
// 方法结束,executor未关闭
}解决 :应用关闭前调用shutdown()等待任务完成。
七、面试高频真题(标准答案直接背)
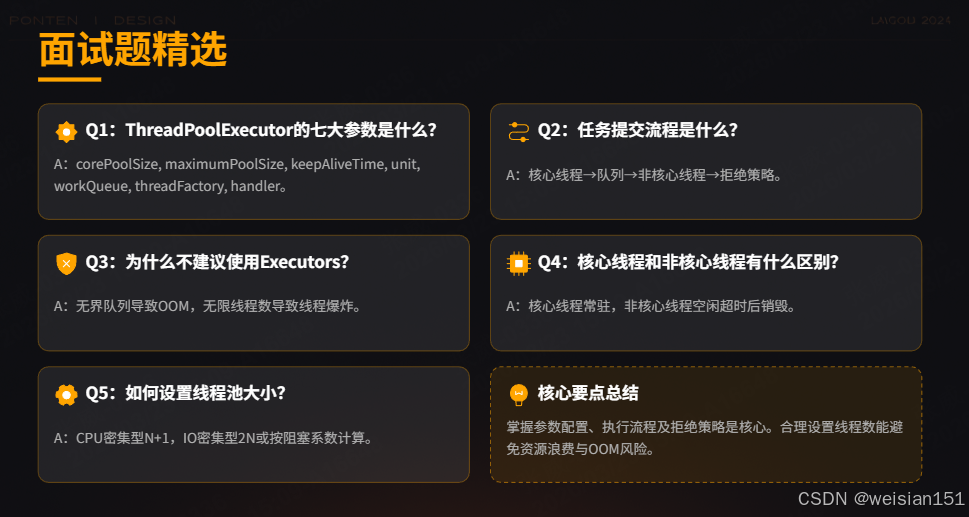
7.1 基础必答
Q1:ThreadPoolExecutor的七大参数是什么?分别有什么作用?
答案:
corePoolSize:核心线程数,线程池常驻线程数,空闲时不销毁(除非设置allowCoreThreadTimeOut(true));maximumPoolSize:最大线程数,线程池允许创建的总线程数(核心+非核心);keepAliveTime:非核心线程空闲超时时间,超时后销毁;unit:keepAliveTime的时间单位(如秒、毫秒);workQueue:任务队列,核心线程满后存放待执行任务的队列;threadFactory:线程工厂,定制线程名称、优先级、异常处理器;handler:拒绝策略,线程数达最大且队列满时,新任务的处理策略。
Q2:线程池的任务提交流程是什么?(核心面试题)
答案 :
线程池处理任务的核心流程分为四步:
- 若线程数 <
corePoolSize,创建核心线程执行任务; - 若线程数 ≥
corePoolSize,将任务加入workQueue队列等待; - 若队列已满,且线程数 <
maximumPoolSize,创建非核心线程执行任务; - 若队列已满且线程数 ≥
maximumPoolSize,执行handler拒绝策略。
Q3:为什么不建议使用Executors创建线程池?有什么问题?
答案 :
Executors创建的线程池存在以下致命问题:
newFixedThreadPool/newSingleThreadExecutor:使用无界队列LinkedBlockingQueue,高并发下任务堆积导致OOM;newCachedThreadPool:最大线程数为Integer.MAX_VALUE,高并发下创建无限多线程,导致OOM或CPU 100%;- 无法定制线程名称、拒绝策略,不利于问题排查和故障处理;
生产环境必须手动创建ThreadPoolExecutor,配置有界队列和合理的线程数。
7.2 深度追问
Q4:线程池的核心线程和非核心线程有什么区别?keepAliveTime如何影响它们?
答案:
- 核心区别 :
- 核心线程:线程池常驻线程,默认空闲时不销毁,优先级高于非核心线程;
- 非核心线程:临时线程,仅队列满时创建,空闲超时后销毁;
- keepAliveTime影响 :
- 默认仅作用于非核心线程,超时后销毁;
- 调用
allowCoreThreadTimeOut(true)后,核心线程也会受该参数影响,空闲超时后销毁; - 核心线程数=最大线程数时,
keepAliveTime无意义(无临时线程)。
Q5:线程池的四种拒绝策略分别适用于什么场景?核心业务该选哪种?
答案:
AbortPolicy(默认):抛异常,适用于核心业务,快速失败并触发告警;CallerRunsPolicy:提交任务的线程自己执行,适用于所有场景的兜底策略,避免任务丢失;DiscardPolicy:静默丢弃,适用于非核心业务(如日志收集),允许丢失;DiscardOldestPolicy:丢弃最老任务,适用于允许丢弃旧任务的场景(如实时数据统计);
核心业务优先选AbortPolicy(便于监控)或CallerRunsPolicy(兜底),严禁使用DiscardPolicy(无感知丢失)。
Q6:如何设置线程池的大小?CPU密集型和IO密集型有什么区别?
答案:
- CPU密集型 :
- 特点:任务消耗CPU资源,CPU利用率高;
- 公式:线程池大小 = CPU核心数 + 1;
- 原因:+1防止某个线程暂停时,备用线程利用CPU资源;
- IO密集型 :
- 特点:任务大量等待IO,CPU利用率低;
- 公式:线程池大小 = CPU核心数 × 2(或 CPU核心数 / (1 - 阻塞系数));
- 原因:更多线程可充分利用CPU,等待IO时切换线程执行;
- 实际配置需结合压测调整,避免线程数过多导致上下文切换飙升。
Q7:线程池的五种状态是什么?如何优雅关闭线程池?
答案:
- 五种状态 :
- RUNNING:运行中,接收新任务+处理队列任务;
- SHUTDOWN:关闭接收新任务,继续处理队列任务;
- STOP:关闭接收新任务,中断正在执行的任务,丢弃队列任务;
- TIDYING:所有任务执行完毕,线程数为0;
- TERMINATED:终止状态,
terminated()执行完毕;
- 优雅关闭步骤 :
- 第一步:调用
shutdown()关闭接收新任务; - 第二步:调用
awaitTermination(timeout, unit)等待队列任务执行完毕; - 第三步:超时未完成,调用
shutdownNow()强制关闭,中断所有线程; - 第四步:捕获
InterruptedException,恢复中断状态并再次强制关闭。
- 第一步:调用
Q8:SynchronousQueue有什么特点?适用于什么场景?
答案:
- 特点:容量为0,不存储元素,任务直接移交线程处理;
- 流程:核心线程满后,入队即失败,直接创建非核心线程;
- 适用场景 :高吞吐、低延迟场景,需配合较大的
maximumPoolSize; - 风险 :若
maximumPoolSize设置过小,容易触发拒绝策略。
Q9:生产环境中,如何监控线程池状态?
答案:
- 定期调用
getPoolSize()、getActiveCount()、getQueue().size()获取指标; - 集成监控系统(如Prometheus+Grafana),上报线程池指标;
- 设置告警阈值:活跃线程占比>80%、队列使用率>80%时报警;
- 自定义拒绝策略,记录日志并发送告警。
Q10:设计一个订单处理系统的线程池,要求抗住每秒1万订单,IO密集型,如何配置参数?
答案:
- 参数配置 :
corePoolSize:CPU核数 * 2(假设8核 → 16);maximumPoolSize:CPU核数 * 4(32);keepAliveTime:60秒;workQueue:ArrayBlockingQueue(5000);handler:CallerRunsPolicy;threadFactory:自定义线程名"order-pool-%d"。
- 理由 :
- IO密集型需较多线程等待IO;
- 有界队列防OOM;
CallerRunsPolicy降低提交速度,避免雪崩;- 自定义线程名便于排查。
- 补充:需结合压测结果微调参数。
Q11:如果线程池队列满了,拒绝策略选择了CallerRunsPolicy,会发生什么?有什么优缺点?
答案:
- 行为:提交任务的线程(调用者)亲自执行该任务;
- 优点 :
- 不会丢失任务;
- 降低任务提交速度,给线程池缓冲时间;
- 避免雪崩效应。
- 缺点 :
- 调用者线程被阻塞,影响上层业务响应时间;
- 若调用者是Web容器线程(如Tomcat),可能导致HTTP请求超时。
- 适用场景:允许短暂降低吞吐量,但不允许任务丢失的核心业务。
总结
1. 核心知识点速记口诀
线程池七参数,核心要记牢,
core是常驻,max是上限,
keepAlive管临时,超时就销毁,
队列是缓冲,有界才安全,
线程工厂定名称,拒绝策略别乱选。
任务提交三步走,核心→队列→最大,
Executors是深坑,手动配置才靠谱,
CPU密集+1,IO密集×2,
优雅停机要牢记,shutdown+awaitTermination。2. 关键点回顾
- 禁止使用Executors:无界队列和无限线程数是OOM和CPU 100%的元凶;
- 七参数核心:核心线程保底,队列缓冲,非核心应急,拒绝兜底;
- 执行流程:核心→队列→最大→拒绝,顺序不可颠倒;
- 队列选型 :生产环境必须用有界队列(ArrayBlockingQueue);
- 线程数设置:CPU密集型N+1,IO密集型2N或按公式计算;
- 拒绝策略:核心业务用CallerRunsPolicy,非核心可用DiscardPolicy;
- 优雅关闭 :应用退出前调用
shutdown(),等待任务完成。 - 优雅停机 :
shutdown()+awaitTermination()+shutdownNow()是线程池关闭的标准流程。
3. 实战建议
- 生产环境必须手动创建
ThreadPoolExecutor,禁止使用Executors; - 所有线程池必须定制线程名称,便于日志排查;
- 核心业务拒绝策略优先选
AbortPolicy或CallerRunsPolicy; - 线程池必须提供优雅关闭方法,避免JVM退出时资源泄漏;
- 上线前必须压测,验证线程池参数的合理性。

写在最后
线程池是Java并发的"基本功",也是生产环境的"生命线"。很多开发者觉得"能用就行",却忽略了参数配置的细节,最终导致OOM、任务丢失、系统卡顿等问题。
ThreadPoolExecutor的7个参数看似复杂,实则围绕"资源管控"展开:核心线程保证基础处理能力,队列缓冲突发流量,最大线程限制资源上限,拒绝策略处理极端情况。理解这一设计思想,就能根据业务场景灵活配置,而非死记硬背参数。
记住:最好的线程池配置,是既能处理日常流量,又能扛住峰值流量,还能在极端情况下优雅降级的配置。拒绝"拿来主义",手动掌控线程池,才是并发编程的核心能力。
如果觉得有帮助,欢迎点赞、收藏、转发!