本文作者:kaiyuan
大模型推理并行策略(DP/TP/PP/SP/EP)原理简介
想深耕AI Infra领域?欢迎访问InfraTech库!内容涵盖大模型基础、PyTorch/vLLM/SGLang框架入门、性能加速等核心方向,配套50+知识干货及适合初学者的notebook练习:https://github.com/CalvinXKY/InfraTech
在大模型推理部署中,由于模型参数量常超出单GPU显存容量,或单GPU算力无法满足推理性能要求,通常需要借助并行策略来解决这类问题。又因计算流程存在差异,推理与训练的并行策略实现并不相同。本文旨在帮助读者快速理解常见并行策略的基本原理。
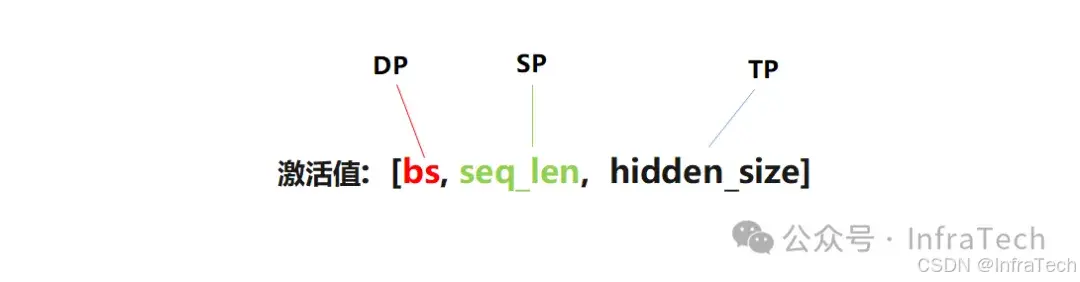
推理主要应用的并行方式包括:数据并行(DP)、序列并行(SP/CP)、张量并行(TP)、层并行(PP)。可根据输入激活值的切分维度对应不同的并行策略,一般切batch为DP、切序列为SP/CP、切隐藏层尺寸为TP。
1 DP策略
1.1 基本原理
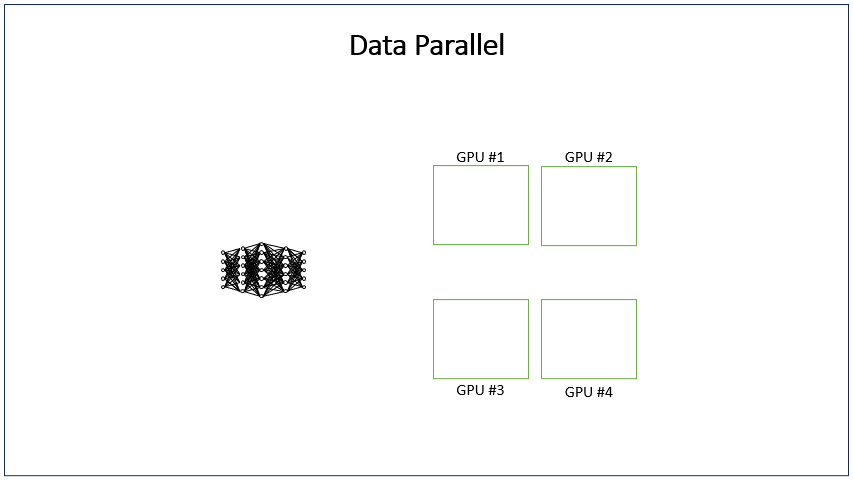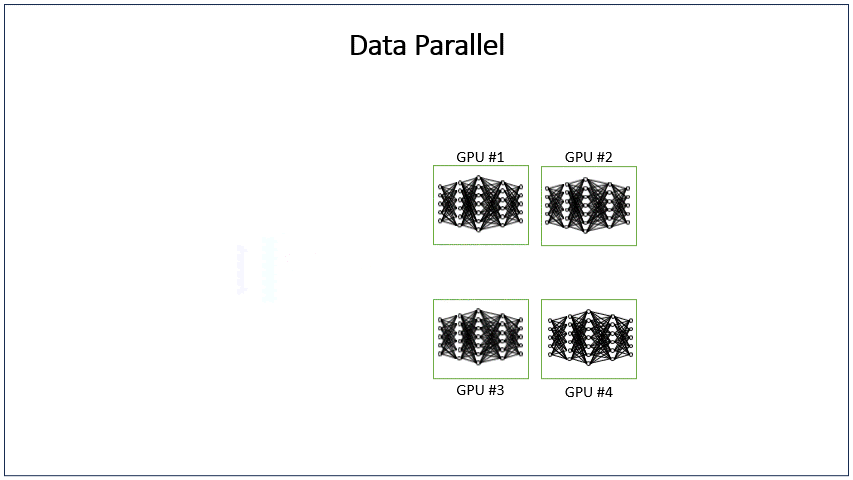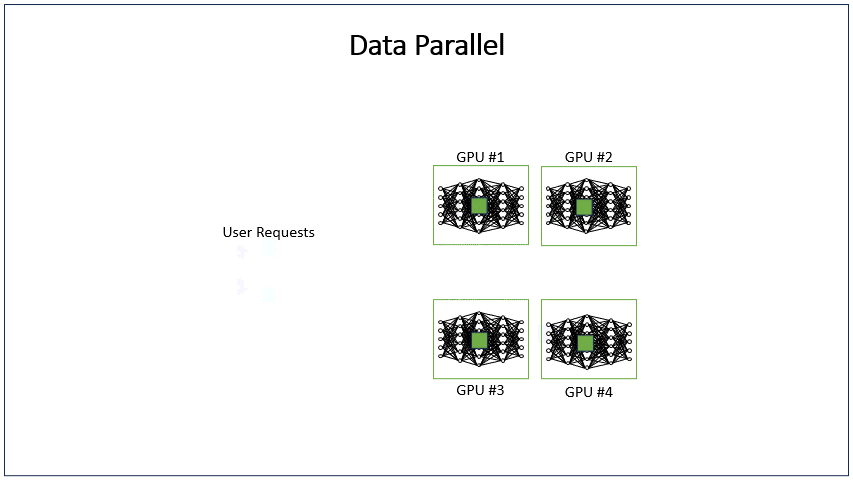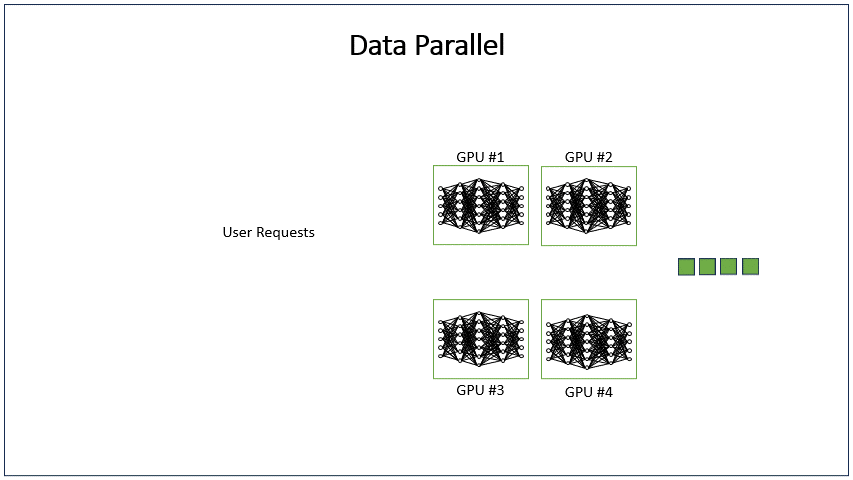
DP(Data Parallel)数据并行,是解决数据并发量大时使用的策略,DP方法在不同的GPU运行LLM模型的多个副本,并在每个模型副本上独立处理用户请求组。其原理与开多个推理实例并发处理一样,不同的是,开DP是多个模型副本共用一个推理实例,由推理实例中的调度器负责分配请求给不同DP的模型副本。
1.2 代码演示
通过多线程处理模拟多GPU,可以构造两个计算场景:
- 场景1:一个模型副本,我们用一个线程来运行这个模型,然后有4个数据任务,我们用一个线程池(4个线程)来同时发送数据给这个模型,但是模型处理是串行的,所以我们可以在模型内部加锁,使得同时只能有一个线程(即一个数据)被处理。
- 场景2:四个模型副本,每个模型副本在一个线程中,然后有4个数据,我们同样用4个线程来发送数据,但是每个数据发送给不同的模型副本,这样就能并行处理。
代码位置 :InfraTech/llm_infer/parallel_strategies.ipynb Case1[1]

计算示例
注意,这里只是用线程模拟计算,不同的计算设备得到速度不一样。
2 TP策略
2.1 基本原理
Tensor Parallelism (TP)张量并行,将模型的每一层分割到不同GPU上执行,用户请求(输入数据)会在GPU间流转,每个GPU计算的部分结果最终重新组合为完整输出。TP的计算理论基础是矩阵的分块运算,该运算不会改变最终计算结果。
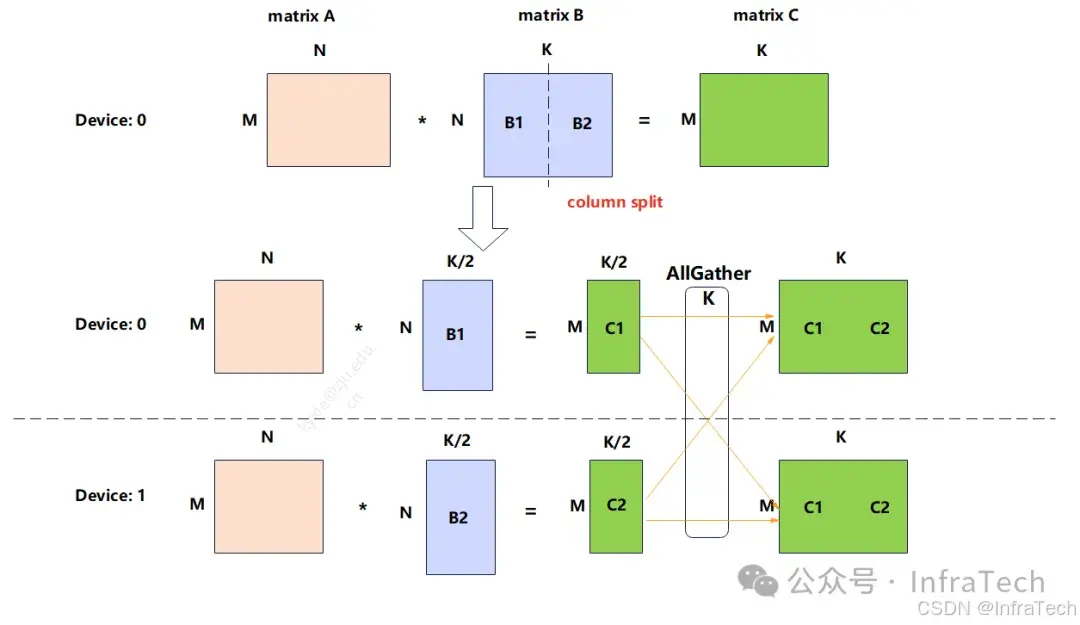
矩阵列切(column split)
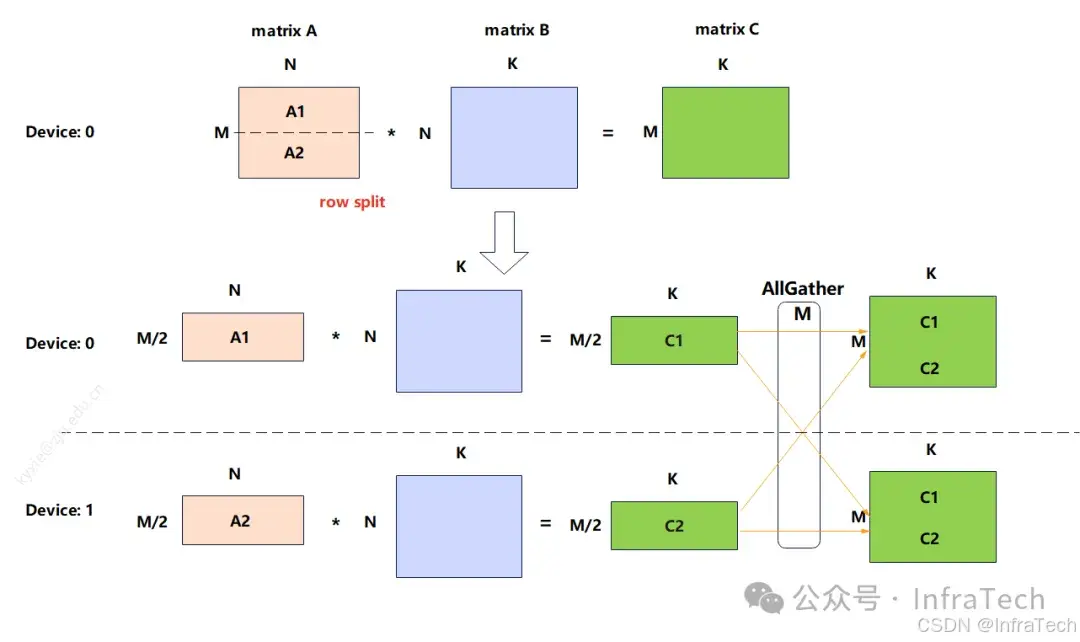
矩阵行切(row split)
TP在LLM推理中应用得比较广泛,其主要作用是降低单卡显存消耗以及计算量。
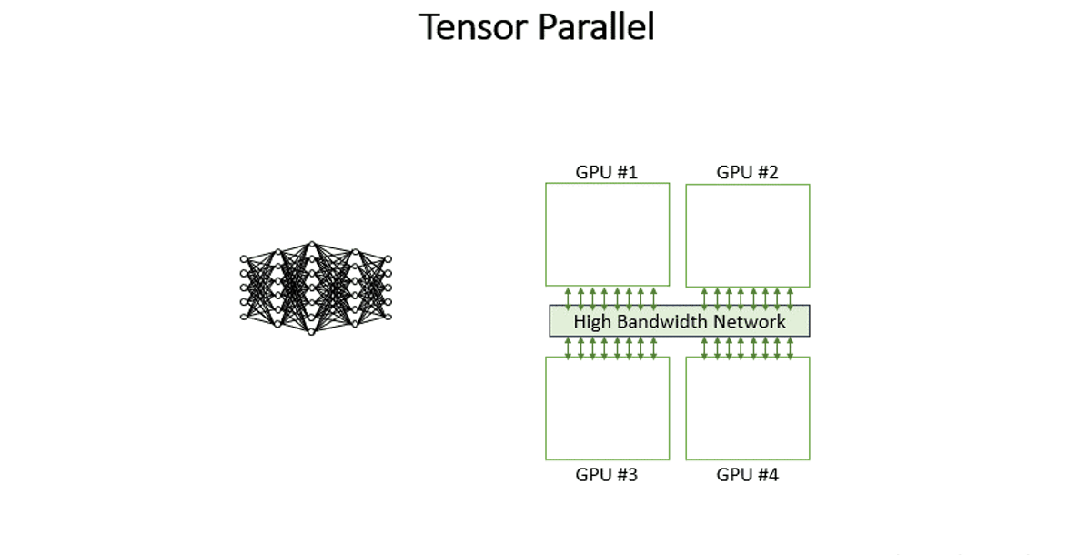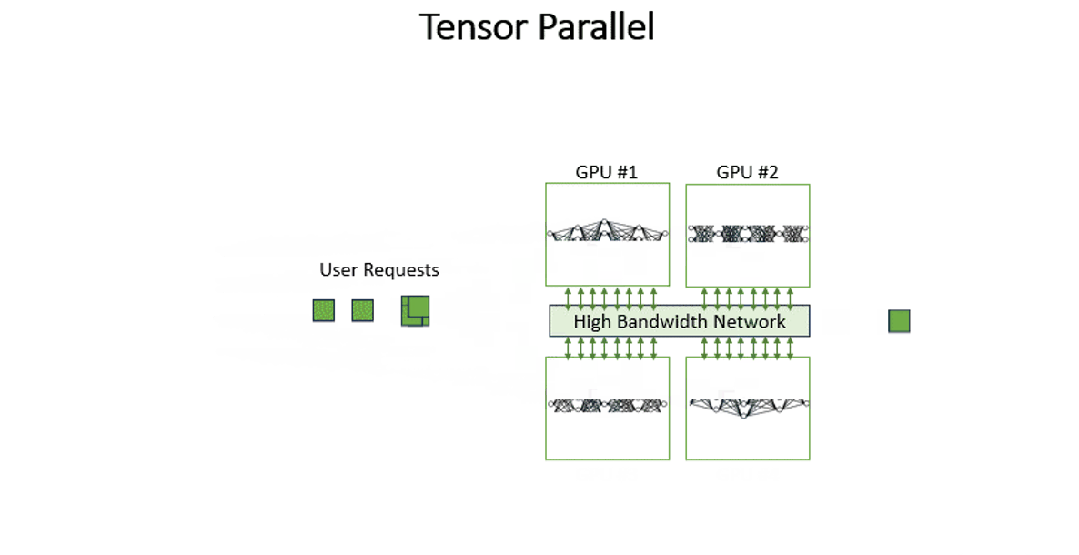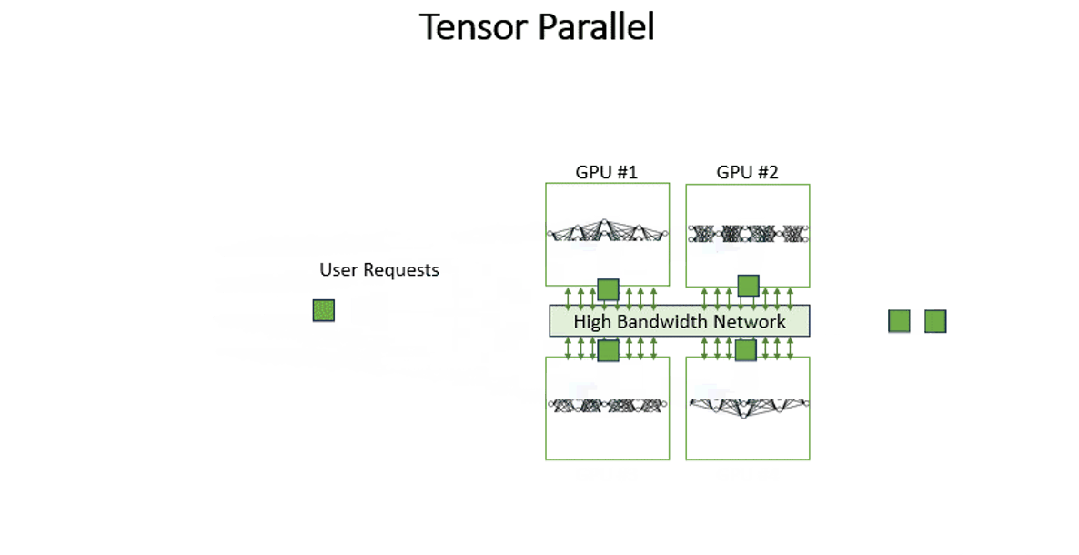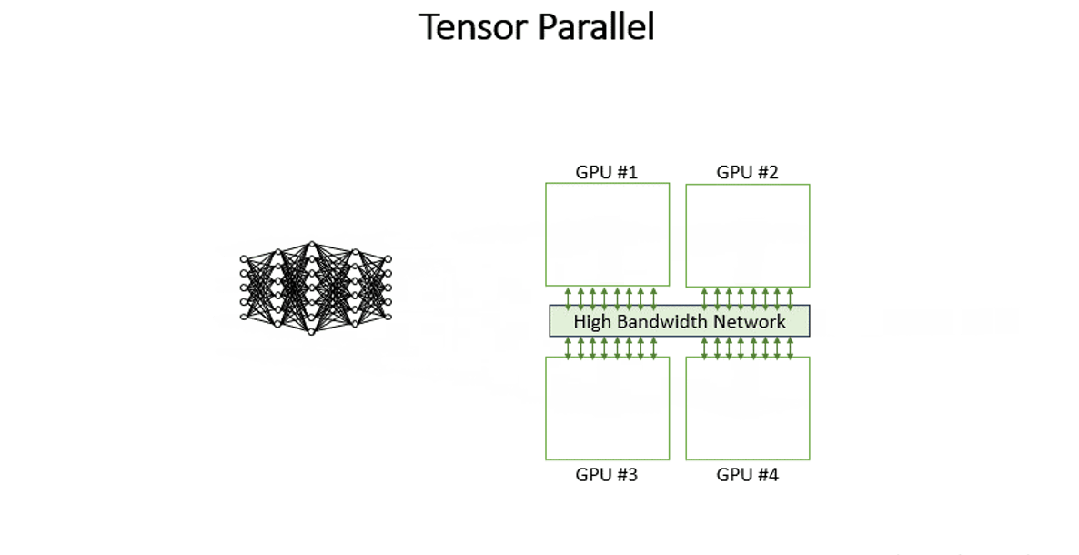
2.2 代码演示
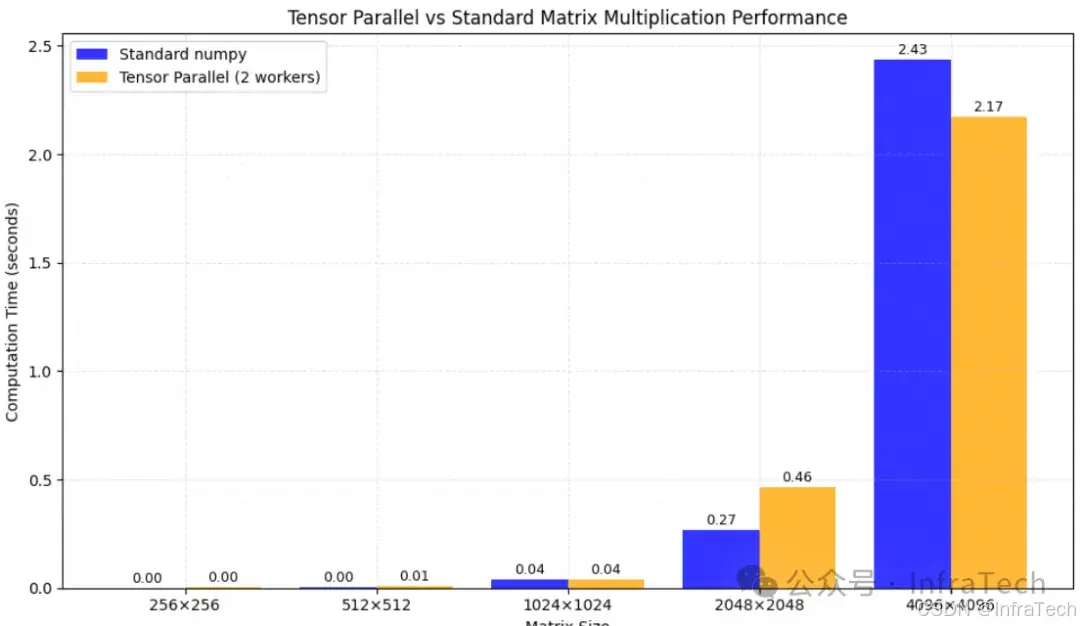
演示张量并行如何通过拆分大矩阵运算到多个计算单元的过程。选择大矩阵(如1024×1024)模拟真实计算场景。将输入矩阵按列分块(column-wise/column-split),计算分配:每个线程处理矩阵A与B的一个列块的乘积。最后,将所有线程的计算结果拼接成完整输出矩阵。对比机制:
- 基准测试:使用标准numpy矩阵乘法作为性能基准
- 并行实现:使用多线程模拟多设备并行计算
- 结果验证:确保并行计算与串行计算数值结果一致
性能对比:对比元计算与TP的速度差异,机器不同计算速度不一样,性能对比数据仅供参考。
代码位置:InfraTech/llm_infer/parallel_strategies.ipynb Case2[1],运行之后可获得速度对比差异:
3 SP策略
3.1 基本原理
SP(Seqeunce Parallel)序列并行是将长序列切分成多个片段,分配到不同GPU设备上并行处理的模型并行策略。示意图如下:
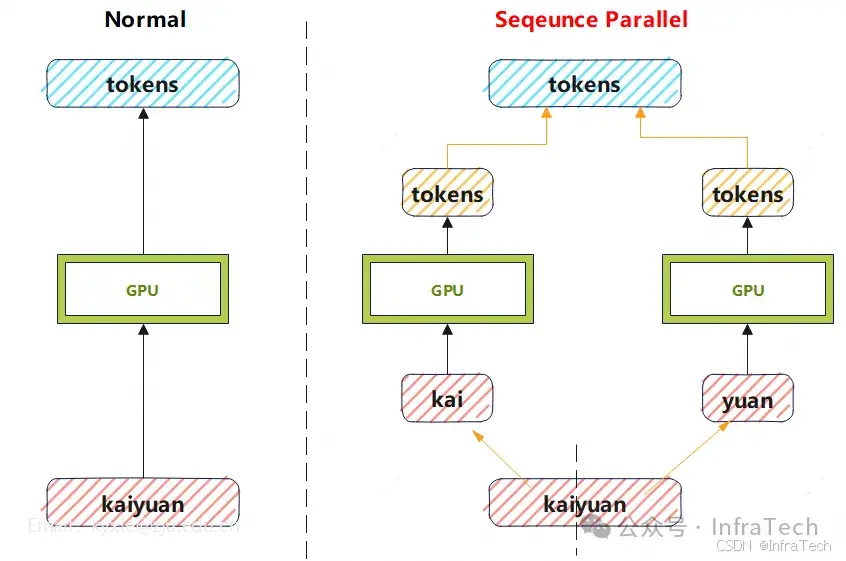
3.2 代码演示
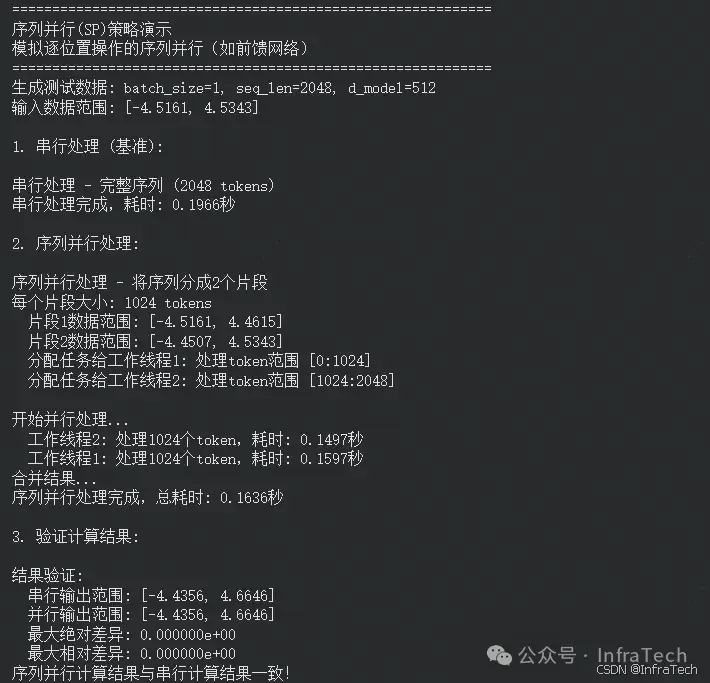
使用线程模拟多设备,并且使用简单的全连接层。对比:
- 不切序列:整个序列数据通过一个完整的模型(多个层)进行计算。
- 切序列(序列并行):将序列分成多个部分,每个部分通过一个设备(用线程模拟)上的子模型计算,然后将结果合并。
步骤:
- 定义模型
- 生成输入数据
- 运行不切序列版本
- 运行切序列版本(序列并行)
- 比较结果和时间
代码位置:InfraTech/llm_infer/parallel_strategies.ipynb Case3 [1]
3.3 SP与其它策略结合
Megatron中TP与SP结合的例子:
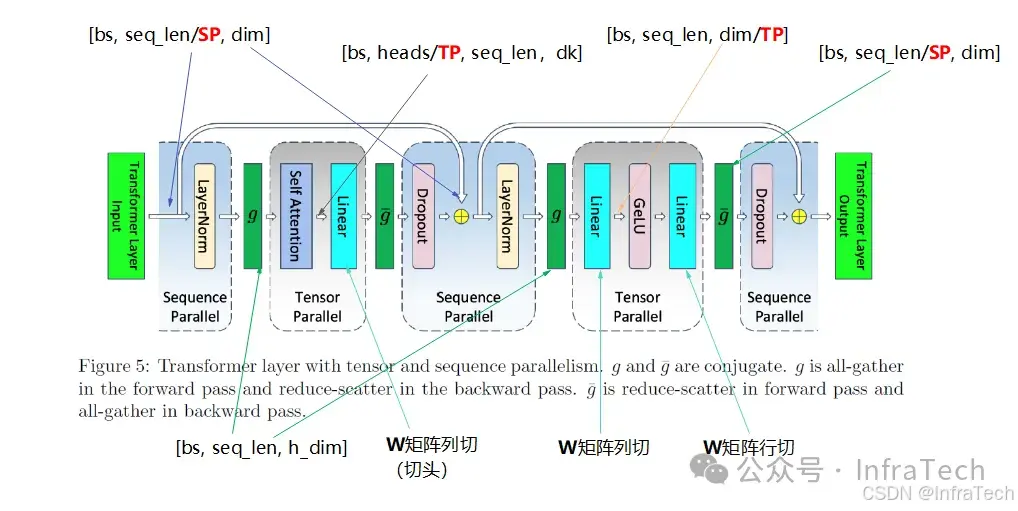
megatron并行示例
负载均衡中SP与DP结合案例:
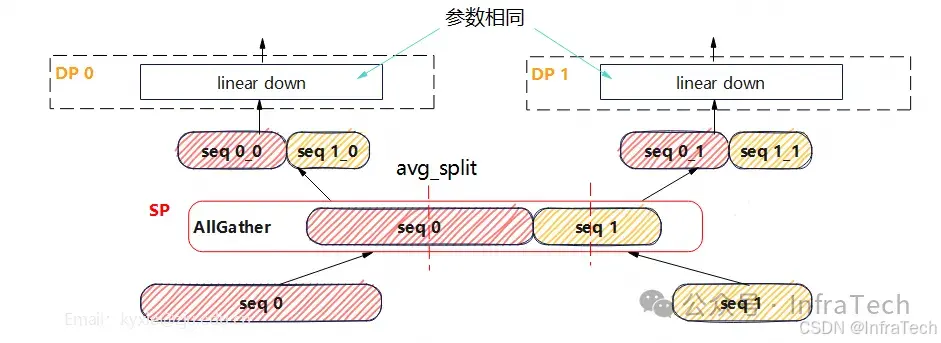
4 PP策略
4.1 基本原理
PP(Pipeline Parallel)并行是将模型按层拆分到不同设备,数据以流水线方式在不同设备间顺序流动处理。PP最先是在训练中广泛使用(Megatron2[2])。PP前向与后向计算中会出现空泡,训练中需要考虑空泡的消除。
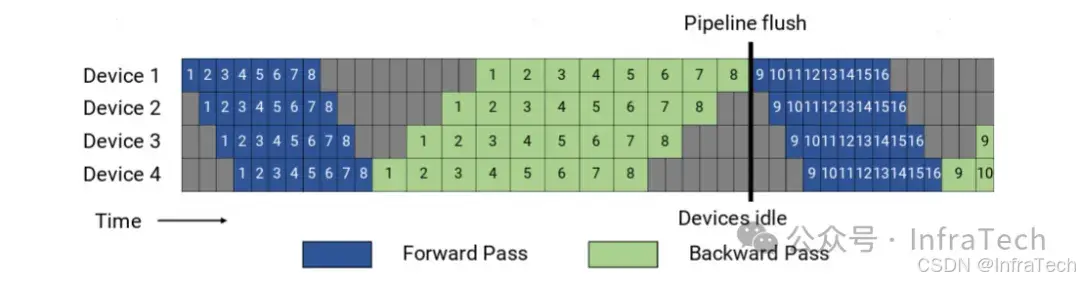
在推理任务中,流水线并行(PP)虽然仅涉及前向传播,但其实际应用场景相对有限,通常仅在GPU显存确实无法容纳相应的模型权重时才会被采用。
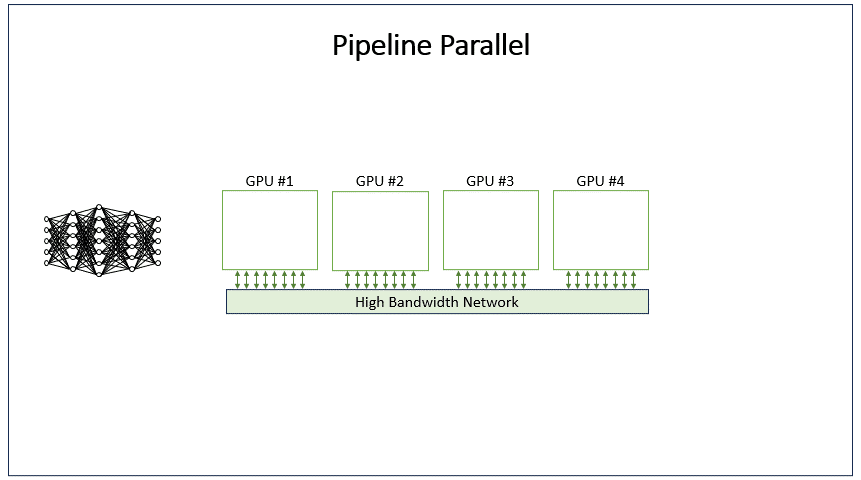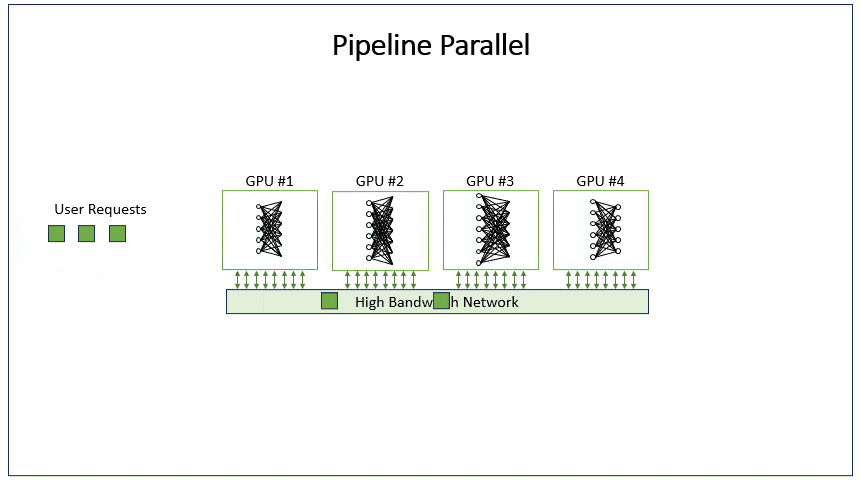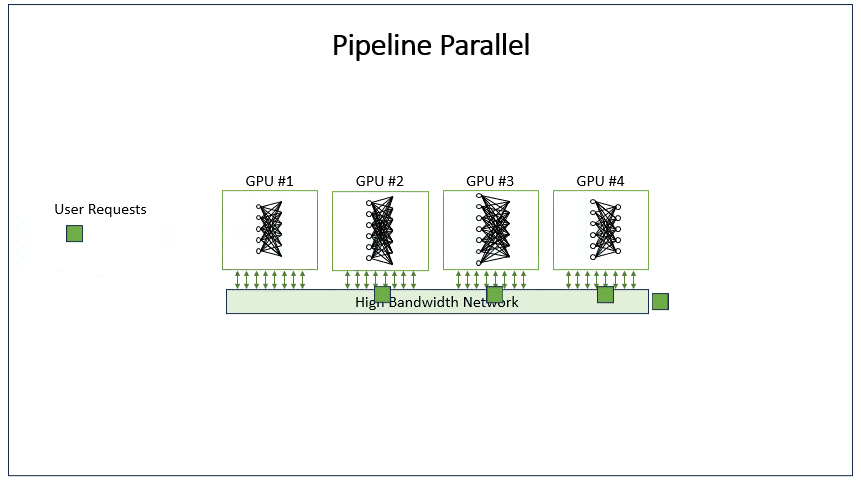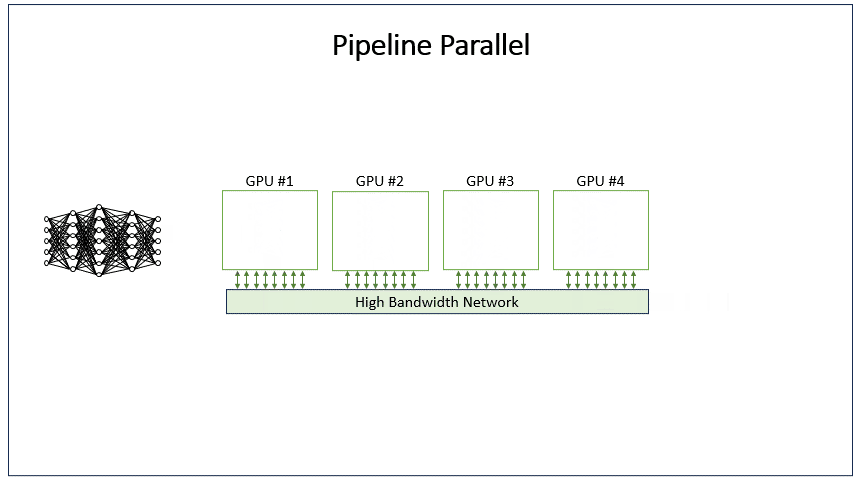
4.2 代码演示
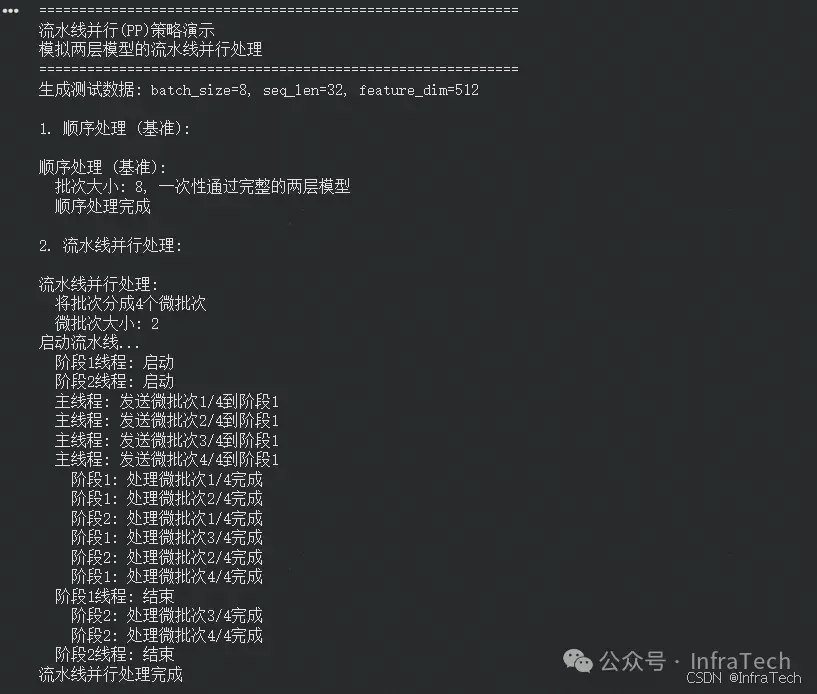
构建一个流水线并行的演示:假设模型有两层,我们将这两层分别放在两个线程(或设备)上。流水线并行中,数据被分成多个微批次(micro-batches),每个微批次依次通过模型的各个阶段(层)。在这个例子中,有两个阶段(两个线程),每个线程处理模型的一层。模拟:将一个批次的数据分成两个微批次,然后通过流水线的方式处理。
代码位置:InfraTech/llm_infer/parallel_strategies.ipynb Case4 [1]
5 EP策略
5.1 基本原理
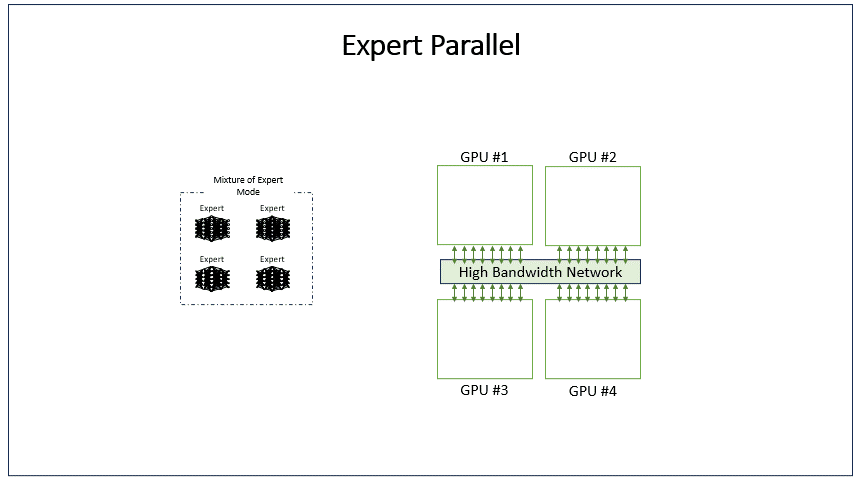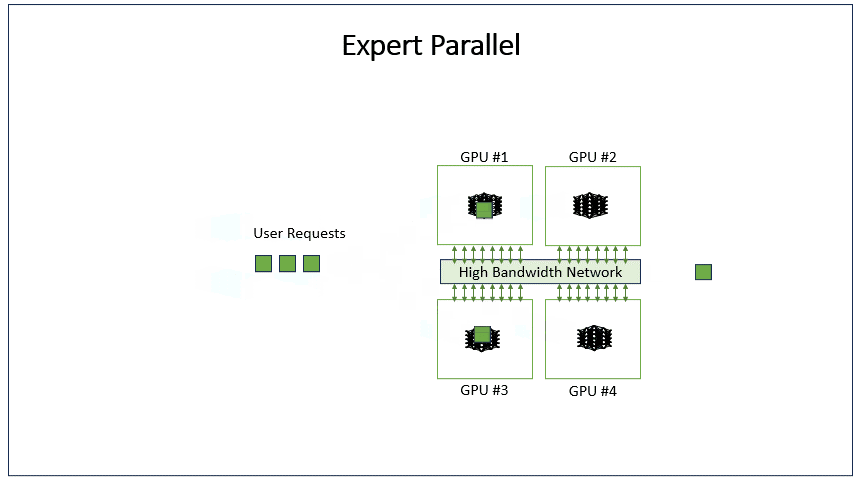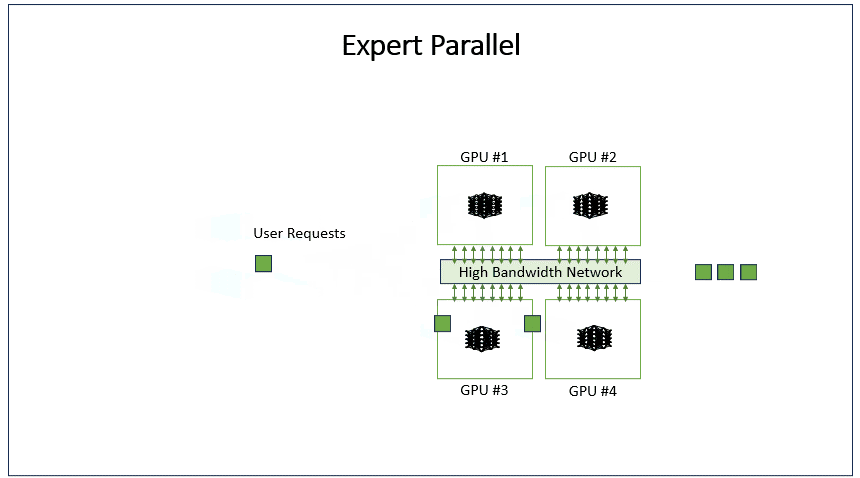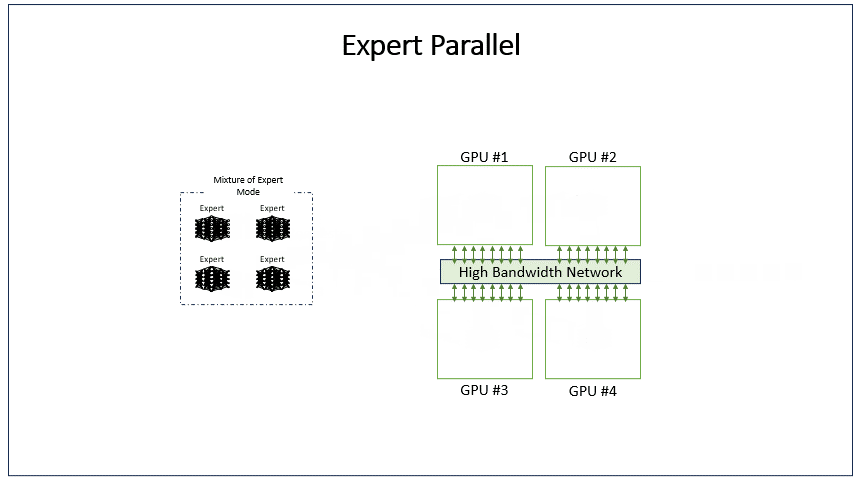
EP(Expert Parallel)是MoE模型中的并行策略,将不同专家网络分配到不同GPU上。每个GPU只存储部分专家参数,输入数据根据路由机制被分发到对应专家GPU计算,最后汇总结果。这显著扩展了模型总参数量,同时控制单个GPU内存占用,适用于超大稀疏模型训练。
当前EP与DP的结合常见场景,Attention使用DP、FFN使用EP。
当前EP与DP的结合常见场景,Attention使用DP、FFN使用EP。
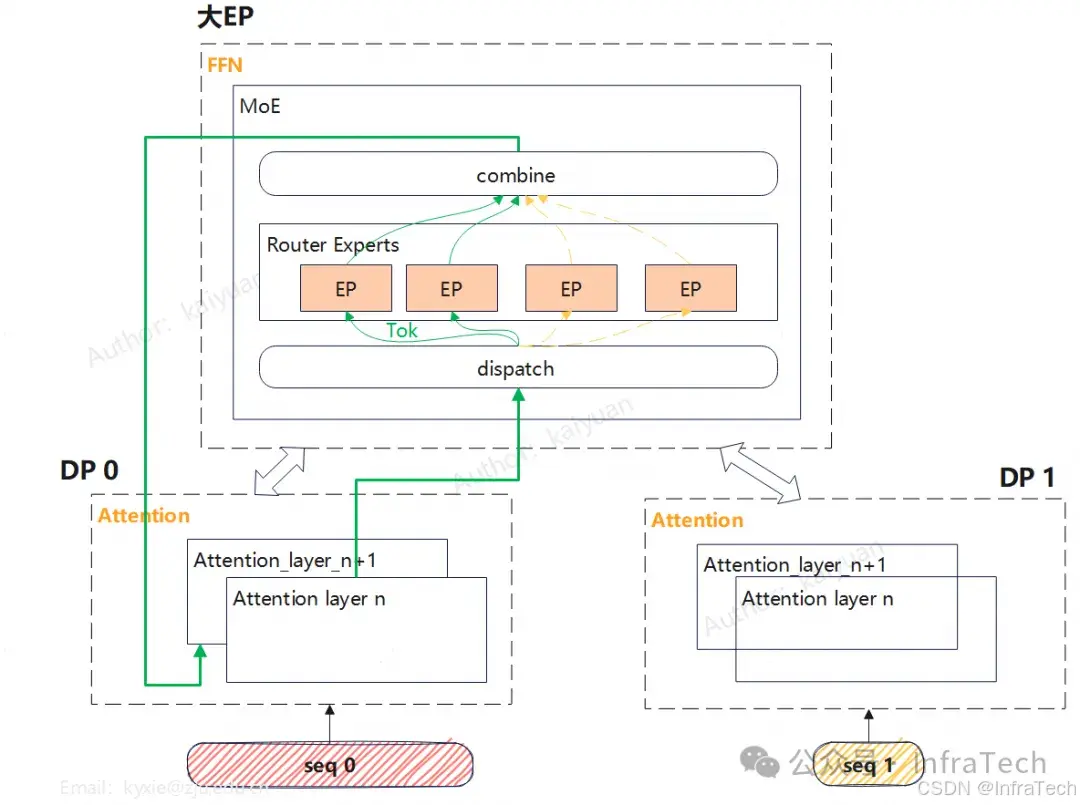
EP切分会带来负载不均的问题,可通过EPLB解决,参考《LLM推理EPLB原理:用可视化深度解析DeepEP》[3]。
6 其它策略
6.1 CP策略
CP(Context Parallel)上下文并行与序列并行SP均是针对序列维度进行划分的并行策略,且两者最初均在训练并行中被提出。其发展脉络如下:首先出现的是SP策略,它主要解决了模型前向与反向传播中(除Attention计算外)由序列切分带来的内存与计算开销。随后,为了进一步解决Attention模块自身的序列并行问题,Megatron框架中引入了CP策略。二者原理相似,但针对的计算阶段有所不同。具体参考《并行训练Context Parallelism的原理与代码浅析[4]》
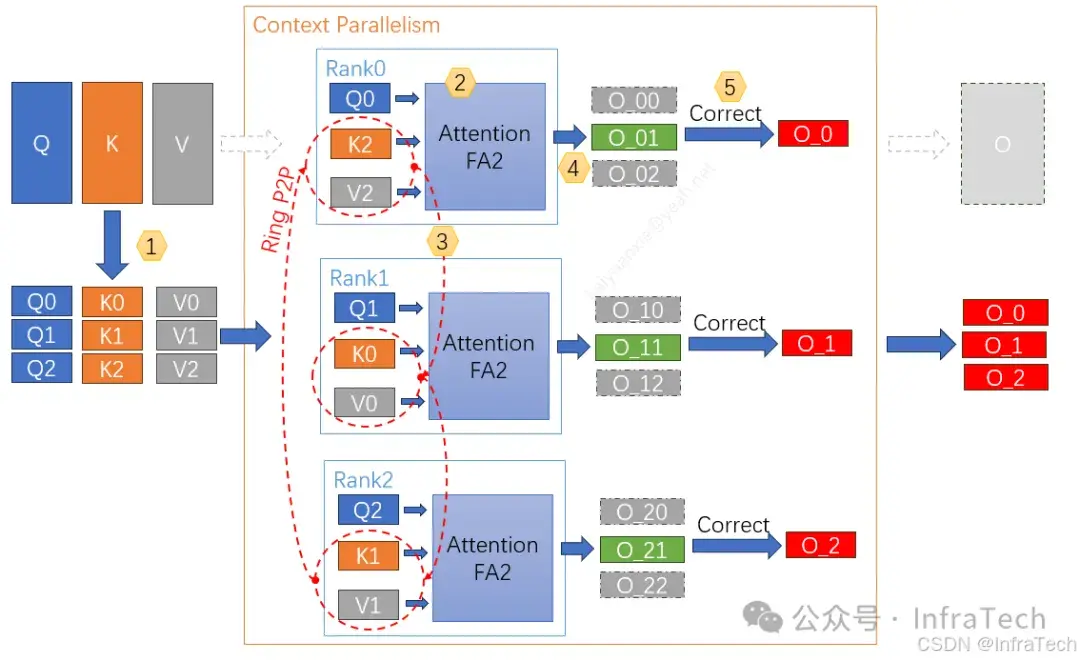
CP计算流程
6.2 Ulysses并行
Ulysses的全称是DeepSpeed‑Ulysses,其核心逻辑:开启序列并行后,在多头Attention运算之前,多个GPU设备之间会进行数据交换,使单个GPU能够拥有完整的序列;Attention 计算完成后,再通过集合通信将序列还原为原本被切分的形状。
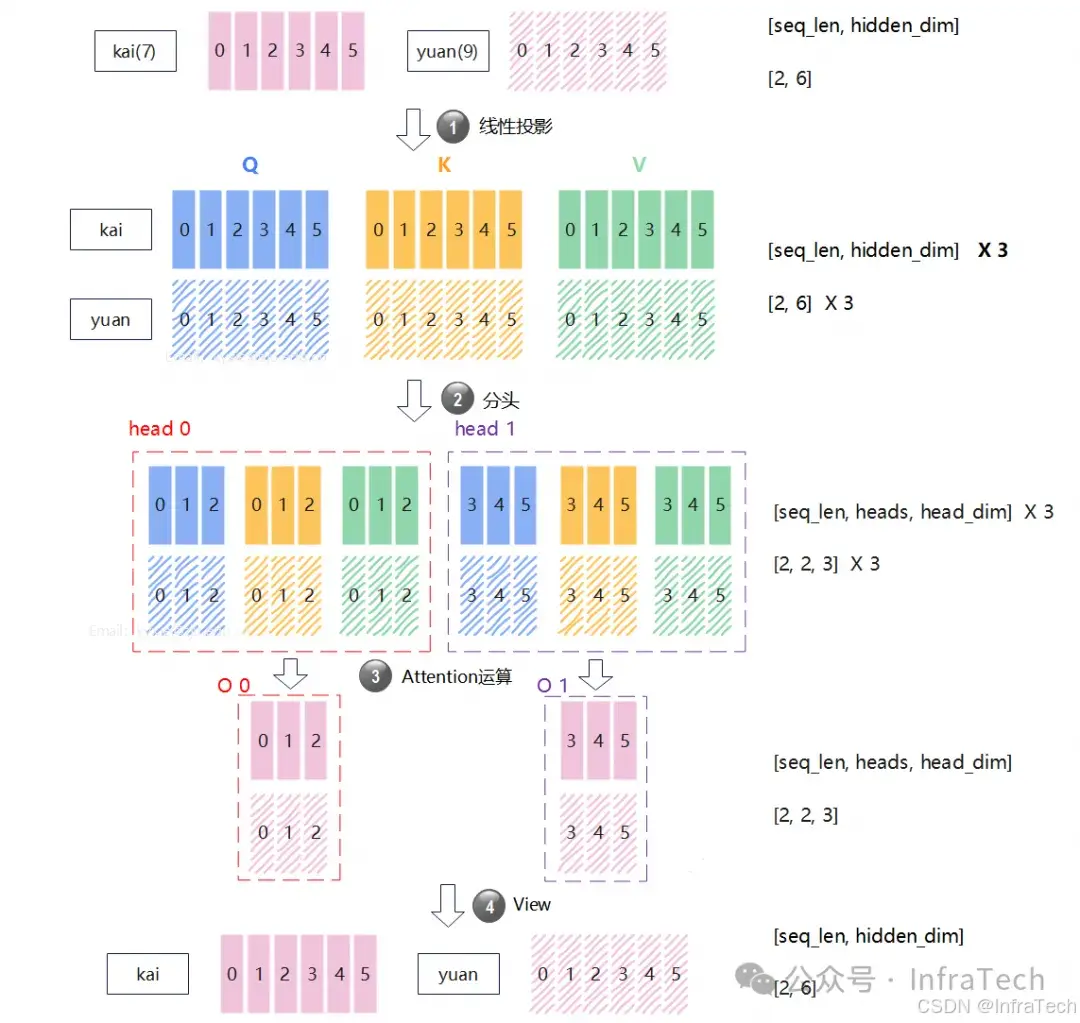
在《实测3x提速!DeepSeekV3/V3.2推理的Ulysses并行优化实践[5]》中对Ulysses原理有详细解释,此处不做赘述。
总结
在大模型推理场景中,主流推理框架均已支持多种并行策略。每种策略各有其优缺点,旨在解决不同层面的性能与资源瓶颈。
| 并行策略 | 大模型推理中的优缺点 |
|---|---|
| 数据并行 (DP) | 优点:处理多请求的基础且常用策略,实现简单。缺点:内存冗余,每个设备需保存完整模型副本。PD分离架构下,其角色常转化为请求级调度。 |
| 张量并行 (TP) | 优点:最常用于解决单层参数过大问题,能将大层(如FFN)拆分到多卡。缺点:设备间通信密集,延迟敏感,对设备间互联带宽要求极高。 |
| 流水线并行 (PP) | 优点:可拆分极深模型(层数多)。缺点:推理中不常用。因天然存在串行依赖,会引入"气泡",极大降低推理效率和增加延迟。 |
| 序列并行 (SP) | 优点:较常用于处理长序列,可拆分激活内存和注意力计算,是TP的有效补充。缺点:同样引入额外通信,实现复杂度较高。其思想与CP(上下文并行)类似。 |
| 专家并行 (EP) | 优点:MoE模型专用的高效扩容方式,仅激活部分参数,扩展性好。缺点:仅限于MoE架构,需要复杂的负载均衡与路由。 |
| 上下文并行 (CP) | 优点:一种更细粒度的SP,专注于优化KV Cache在长上下文中的内存分布。缺点:通常不作为独立策略,而是被融入SP的优化中。 |
实际选用时,需结合具体场景综合考虑,例如模型参数量、PD/AF分离需求、硬件拓扑特点等因素[6][7]。关于推理并行策略优化推荐进一步阅读:
参考:
- 1abcdhttps://github.com/CalvinXKY/InfraTech/blob/main/llm_infer/parallel_strategies.ipynb
- 2https://arxiv.org/abs/2104.04473
- 3LLM推理EPLB原理:用可视化深度解析DeepEP
- 4并行训练Context Parallelism的原理与代码浅析
- 5实测3x提速!DeepSeekV3/V3.2推理的Ulysses并行优化实践
- 6https://developer.nvidia.cn/blog/demystifying-ai-inference-deployments-for-trillion-parameter-large-language-models/
- 7https://arxiv.org/pdf/2101.03961
InfraTech申明:未经允许不得转载!