内容来自:程序员老廖
很多同学不知道 C++ 方向该做什么项目,于是选择学习或模仿陈硕老师的 muduo。这本身是非常棒的学习路径,很多同学存在两个问题。
第一:把网络库作为独立完整的项目写到简历,是很难有大厂面试机会的。
第二 即使有面试机会,当面试官问:"你实现的这个框架,为什么是高性能的?" 很多人的回答止步于:"我是参考 muduo 的,网上都说它性能很高。"
这句话一出口,面试官心里基本就给你打了个问号:你只是写了代码,但没理解原理。
虽然我们不能直接把网络框架作为一个完整的项目,但掌握网络框架的开发原理是必须的,面试也可能问到你的网络框架是怎么实现的,今天,我就带大家拆解:如何把网络库这个问题答出专业性,让你从"代码搬运工"变成"原理洞察者"。
如果简历不知道写什么项目,可以参考下面这几个项目:
C++项目推荐,QT项目推荐-仿微信聊天,QT客户端+Linux C++后端![]() https://www.bilibili.com/video/BV1XukbYmEY5/
https://www.bilibili.com/video/BV1XukbYmEY5/
C++校招项目推荐:高性能协程+RPC项目,一个项目打通后端8大核心技术![]() https://www.bilibili.com/video/BV1RVADz4Ey4/
https://www.bilibili.com/video/BV1RVADz4Ey4/
C++项目推荐-真正可以媲美redis的kv存储项目-包括性能如何逐步优化![]() https://www.bilibili.com/video/BV12oemzEEjQ/
https://www.bilibili.com/video/BV12oemzEEjQ/
C++进阶项目:LSM磁盘存储引擎,比"仿写redis"更容易打动面试官的项目![]() https://www.bilibili.com/video/BV1ZaPxzcEz6/
https://www.bilibili.com/video/BV1ZaPxzcEz6/
部分简历情况


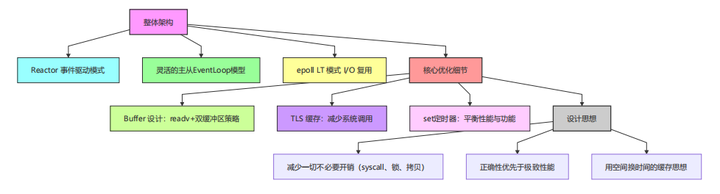
一、muduo 高性能核心框架总览
muduo 的高性能并非单一技术支撑,而是由"线程模型+I/O复用+事件处理模式+内存优化"构成的完整架构体系。先通过框架图建立整体认知:

接下来,我们逐一拆解每个核心模块的设计逻辑与高性能原理,搭配图文让技术点更易理解。
二、四大核心维度深度拆解
2.1 muduo 线程模型深度解析
2.1.1 四种灵活可配置的线程模型分析
muduo 网络库提供了四种灵活可配置的线程模型,可以根据不同的应用场景选择最合适的模型。理解这些模型对于设计和优化高性能网络服务至关重要。
1. 单Reactor单线程模型
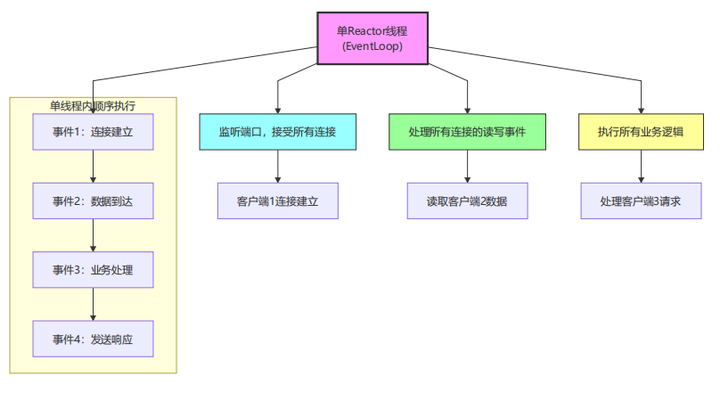
模型特点:
-
所有操作(accept、I/O、业务处理)都在同一个线程中完成
-
类似Redis的单线程模型
-
无需线程同步,编程简单
适用场景:
-
连接数较少(< 1000)
-
业务逻辑简单快速
代码示例:
EventLoop loop;
InetAddress listenAddr(8080);
TcpServer server(&loop, listenAddr, "SingleThreadServer");
// 不设置线程数,默认为0(单线程)
server.setThreadNum(0);
server.start();
loop.loop();性能特点:
-
吞吐量受限于单核CPU性能
-
一个慢请求会阻塞所有其他请求
-
上下文切换开销最小
2. 单Reactor多线程模型
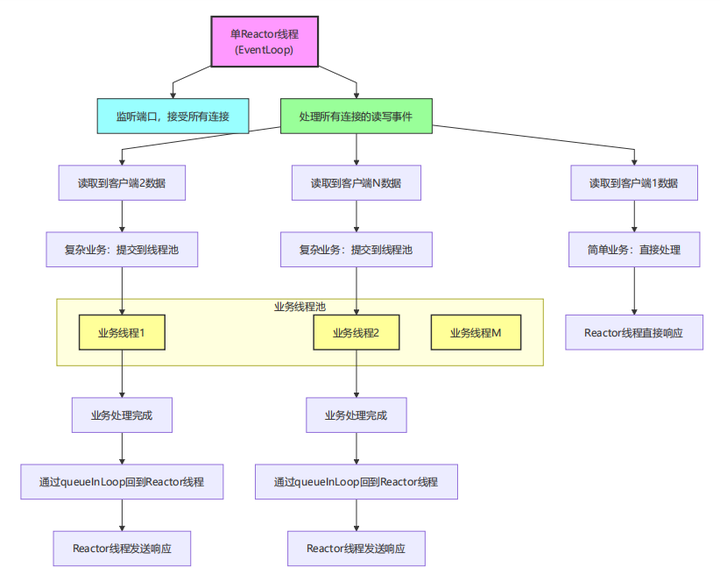
模型特点:
-
单Reactor线程处理所有I/O操作
-
业务线程池处理耗时业务逻辑
-
I/O线程不阻塞,保持高响应性
适用场景:
-
中等并发规模
-
业务逻辑包含耗时操作(数据库、文件I/O等)
-
需要保持I/O高响应的场景
代码示例:
EventLoop loop;
InetAddress listenAddr(8080);
TcpServer server(&loop, listenAddr, "SingleReactorMultiThread");
server.setThreadNum(0); // 单Reactor线程
// 创建业务线程池
ThreadPool businessPool(4, "BusinessPool");
server.setMessageCallback([&businessPool](const TcpConnectionPtr& conn,
Buffer* buf,
Timestamp time) {
string request = buf->retrieveAllAsString();
if (isSimpleRequest(request)) {
// 简单请求:Reactor线程直接处理
string response = processSimple(request);
conn->send(response);
} else {
// 复杂请求:提交到业务线程池
businessPool.run([conn, request]() {
string result = heavyComputation(request);
// 回到Reactor线程发送响应
conn->getLoop()->queueInLoop(
[conn, result]() {
conn->send(result);
}
);
});
}
});
server.start();
loop.loop();关键机制:
-
queueInLoop:将任务从业务线程安全地提交到Reactor线程
-
线程安全Buffer:数据在Reactor线程读取,安全传递给业务线程
-
智能指针管理:使用shared_ptr确保连接对象生命周期
3. 多Reactor多线程模型(主从模型)
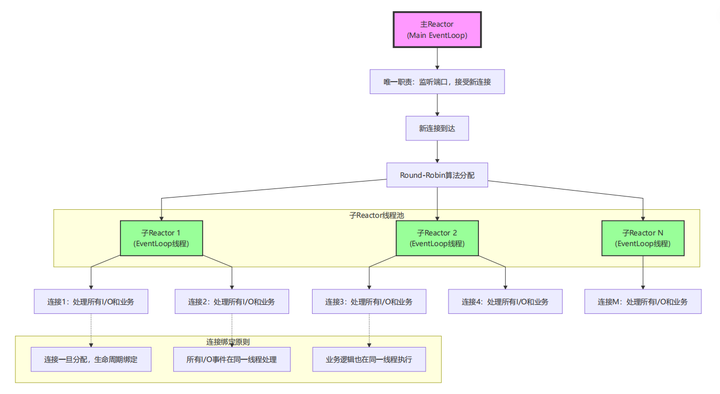
模型特点(muduo推荐模型):
-
主从分离:主Reactor只负责accept,子Reactor处理具体连接
-
连接绑定:一个连接的所有操作都在固定的子Reactor中
-
天然线程安全:无需加锁,避免竞争
适用场景:
-
高并发连接(> 10K)
-
I/O密集型应用
-
业务逻辑简单快速
-
需要极致性能的场景
代码示例:
EventLoop mainLoop;
InetAddress listenAddr(8080);
TcpServer server(&mainLoop, listenAddr, "MasterSlaveServer");
// 设置子Reactor数量(通常等于CPU核心数)
size_t numThreads = std::thread::hardware_concurrency();
server.setThreadNum(numThreads);
// 所有回调函数会自动在对应的子Reactor线程中执行
server.setConnectionCallback([](const TcpConnectionPtr& conn) {
if (conn->connected()) {
LOG_INFO << "新连接在线程" << CurrentThread::tid() << "处理";
}
});
server.setMessageCallback([](const TcpConnectionPtr& conn,
Buffer* buf,
Timestamp time) {
// 自动在连接绑定的子Reactor线程中执行
string msg = buf->retrieveAllAsString();
conn->send(msg); // Echo服务
});
server.start();
mainLoop.loop();核心优势:
-
扩展性:随着CPU核心增加,性能线性增长
-
低延迟:无锁设计,减少上下文切换
-
简单可靠:连接状态管理简单
4. 多Reactor多线程+线程池模型
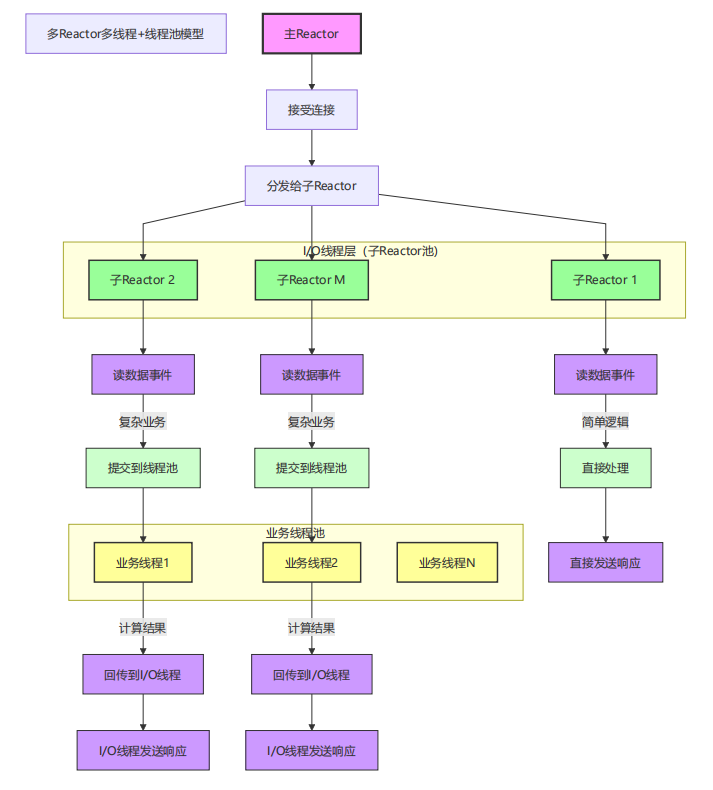
模型特点:
-
在模型3的基础上增加业务线程池
-
I/O线程专注网络操作,保持高响应
-
业务线程处理耗时逻辑,避免阻塞I/O
适用场景:
-
超高并发连接
-
复杂业务逻辑(数据库、计算、外部服务调用)
-
需要同时保证高吞吐和低延迟
代码示例:
EventLoop mainLoop;
InetAddress listenAddr(8080);
TcpServer server(&mainLoop, listenAddr, "HybridServer");
// I/O线程:CPU核心数
size_t ioThreads = std::thread::hardware_concurrency();
server.setThreadNum(ioThreads);
// 业务线程池:根据业务类型调整
ThreadPool businessPool(ioThreads * 2, "BusinessPool");
server.setMessageCallback([&businessPool](const TcpConnectionPtr& conn,
Buffer* buf,
Timestamp time) {
string request = buf->retrieveAllAsString();
// 获取当前I/O线程ID(用于调试)
pid_t ioThreadId = CurrentThread::tid();
if (shouldProcessInIOThread(request)) {
// 简单业务:在当前I/O线程处理
string response = quickProcess(request);
conn->send(response);
} else {
// 复杂业务:提交到业务线程池
// 捕获conn的智能指针,确保连接存活
TcpConnectionPtr connCopy = conn;
businessPool.run([connCopy, request, ioThreadId]() {
pid_t businessThreadId = CurrentThread::tid();
LOG_DEBUG << "业务从I/O线程" << ioThreadId
<< "转移到业务线程" << businessThreadId;
// 执行耗时操作
string result = heavyBusinessLogic(request);
// 回到原I/O线程发送响应
connCopy->getLoop()->runInLoop(
[connCopy, result]() {
connCopy->send(result);
}
);
});
}
});
server.start();
mainLoop.loop();2.1.2 muduo 实际配置建议
1.默认推荐模型3:
// 大多数场景的最佳选择
server.setThreadNum(std::thread::hardware_concurrency());2.线程数配置经验:
// I/O线程数 = CPU核心数
size_t ioThreads = std::thread::hardware_concurrency();
// 业务线程数根据业务类型调整
// CPU密集型:CPU核心数
// I/O密集型:CPU核心数 * 2
// 混合型:根据监控动态调整2.1.3 面试要点
-
理解每种模型的适用场景
-
掌握连接绑定和线程安全机制
-
能够根据业务特点选择合适的模型
-
了解性能调优的基本方法
muduo 的成功不仅在于其高性能,更在于它提供了一套实用、灵活、可维护的线程模型解决方案,让开发者能够根据实际需求做出最佳的技术选择。
2.2 I/O 复用模型:epoll 的 LT(Level-Triggered)模式
背景:在高并发场景下,单个线程需处理大量连接,I/O 复用技术能让线程高效监控多个连接的事件状态。muduo 选择 epoll(Linux 下最优 I/O 复用方案)的 LT 模式,而非 ET 模式。
LT 与 ET 模式对比图:

muduo 选择 LT 模式的核心原因:
-
代码的正确性和可维护性,本身就是一种长期的性能保障(陈硕老师核心观点)
-
现代硬件性能充足,LT 模式的微小开销已不是瓶颈
-
降低开发难度,减少线上 bug 风险,这对框架稳定性至关重要
2.3 Reactor 事件处理模式
Reactor 模式是 muduo 框架的核心骨架,核心思想是"事件驱动",将"事件监听与分发"和"业务逻辑处理"彻底解耦。
Reactor 模式工作流程图:
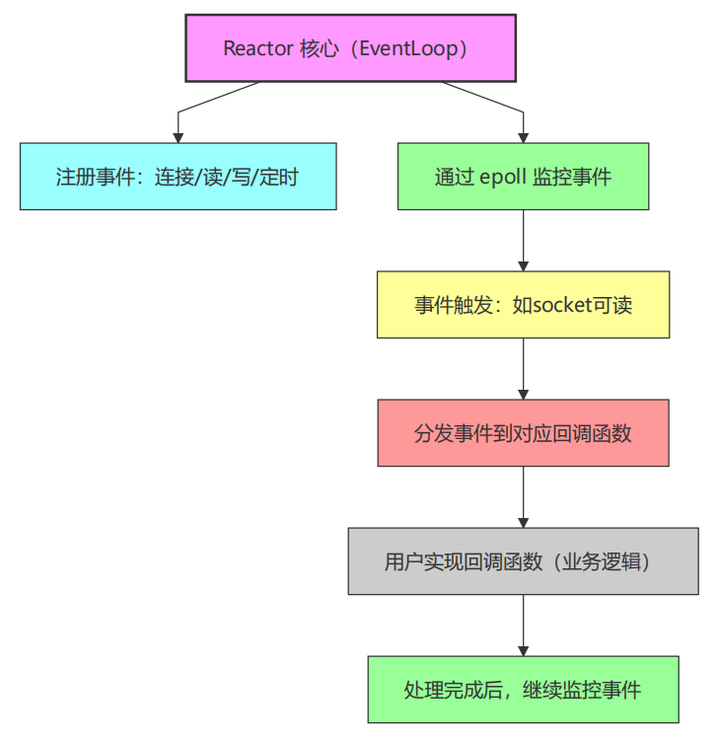
该模式的优势:
-
解耦核心框架与业务逻辑:框架只负责高效的事件监控与分发,不侵入业务
-
框架核心轻量、稳定、可复用:无论何种业务,核心事件处理逻辑不变
-
灵活扩展:用户无需关注底层事件监控、分发逻辑,只需基于muduo提供的接口完成配置与业务回调编写,即可实现不同业务需求(如 HTTP 服务、RPC 服务)。具体核心接口与回调类型如下:
-
服务配置接口:用于绑定IP和端口,启动服务,核心接口为 TcpServer::TcpServer(EventLoop* loop, const InetAddress& listenAddr, const string& nameArg),通过传入监听地址(包含IP和端口)初始化服务,再调用 TcpServer::start() 启动监听;
-
连接事件回调:用于处理客户端连接建立与断开,核心接口为 TcpServer::setConnectionCallback(const ConnectionCallback& cb),用户需实现回调函数 void onConnection(const TcpConnectionPtr& conn),通过 conn->connected() 判断连接状态(建立/断开)并执行对应逻辑;
-
消息接收回调:用于处理客户端发送的消息,核心接口为 TcpServer::setMessageCallback(const MessageCallback& cb),用户需实现回调函数 void onMessage(const TcpConnectionPtr& conn, Buffer* buf, Timestamp receiveTime),通过 buf->retrieveAsString() 获取消息内容并处理;
-
消息发送接口:用于向客户端发送消息,核心接口为 TcpConnection::send(const string& message) 或 TcpConnection::send(Buffer* buf),可在连接回调或消息回调中通过 TcpConnectionPtr 对象调用,实现数据发送;
-
连接关闭接口:用于主动关闭客户端连接,核心接口为 TcpConnection::shutdown(),通常在超时处理、业务结束等场景调用。
2.4 数据结构与内存优化(体现深度的关键)
muduo 的高性能不仅靠架构设计,更藏在细节的内存与数据结构优化中------核心思路是"减少一切不必要的开销"(减少系统调用、减少内存拷贝、减少锁竞争、减少内存分配)。
重点优化点图文解析:
2.4.1 缓冲区设计:readv + 预分配内存(真实 muduo 实现)
问题:高频小包读取时,频繁系统调用会严重影响性能。muduo 用分散-聚集 I/O(readv)和可增长 Buffer 解决该问题。以下是 muduo 中 Buffer 类与 readv 相关的真实源码:
// muduo/net/Buffer.cc 中的真实实现
ssize_t Buffer::readFd(int fd, int* savedErrno)
{
// saved an ioctl()/FIONREAD call to tell how much to read
char extrabuf[65536];
struct iovec vec[2];
const size_t writable = writableBytes();
vec[0].iov_base = begin()+writerIndex_;
vec[0].iov_len = writable;
vec[1].iov_base = extrabuf;
vec[1].iov_len = sizeof extrabuf;
// 关键优化:当缓冲区有足够空间时,不使用 extrabuf
// 使用 extrabuf 时,最多读取 128k-1 字节
const int iovcnt = (writable < sizeof extrabuf) ? 2 : 1;
const ssize_t n = sockets::readv(fd, vec, iovcnt);
if (n < 0)
{
*savedErrno = errno;
}
else if (implicit_cast<size_t>(n) <= writable)
{
writerIndex_ += n;
}
else
{
writerIndex_ = buffer_.size();
append(extrabuf, n - writable);
}
return n;
}代码核心逻辑说明:
1.双缓冲区策略:
-
vec0: Buffer 内部的可写空间
-
vec1: 栈上 64KB 临时缓冲区 (extrabuf)
-
只有当内部缓冲区空间不足(writable < sizeof extrabuf)时才使用栈缓冲区
2.智能缓冲区选择:
const int iovcnt = (writable < sizeof extrabuf) ? 2 : 1;-
内部缓冲区足够大(≥64KB):只使用内部缓冲区,避免内存拷贝
-
内部缓冲区较小(<64KB):使用双缓冲区,确保一次读取足够数据
3.内存管理优化:
-
使用 implicit_cast 进行安全类型转换,而非 static_cast
-
数据量 ≤ 内部缓冲区可写空间:直接移动写指针
-
数据量 > 内部缓冲区可写空间:先填满内部缓冲区,再通过 append() 追加剩余数据
4.性能优化亮点:
-
一次 readv 系统调用读取多个缓冲区,减少系统调用次数
-
栈缓冲区避免堆内存分配开销
-
智能的缓冲区选择策略,最大化内存利用率
Buffer 结构示意图:
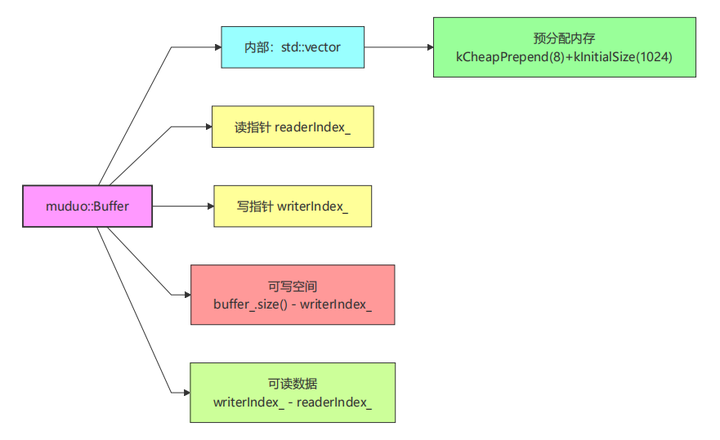
优化逻辑:
-
用 readv 一次性读取数据到多个缓冲区,减少系统调用次数
-
Buffer 内部预分配大块内存,通过读写指针管理空间,避免频繁 realloc(内存重新分配)
-
当可写空间不足时,自动扩容,且扩容时会移动未读数据到缓冲区起始位置,充分利用空间
2.4.2 定时器管理:使用 std::set 实现 TimerQueue
框架需支持定时任务(如超时断开连接、定时日志),muduo 使用 std::set(基于红黑树)实现 TimerQueue,而非时间轮或二叉堆。
两种定时器方案对比:
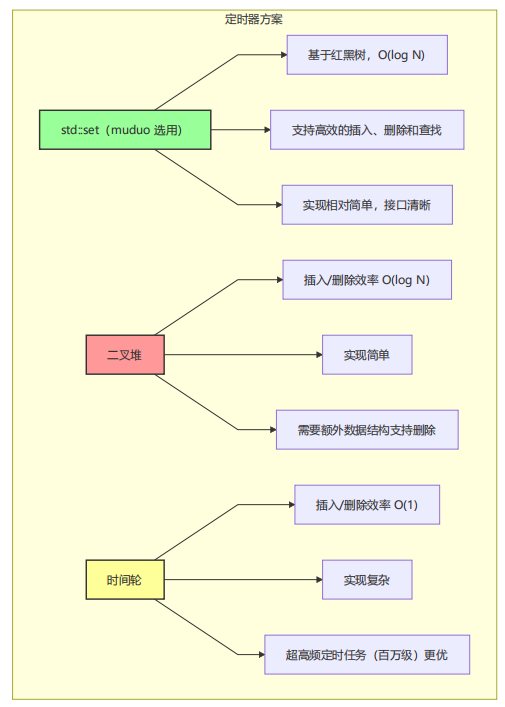
选择逻辑:权衡实现复杂度与功能需求,std::set 提供了有序性和高效的删除操作,对于大多数常规高并发场景已能满足需求,且实现清晰、bug 少。
TimerQueue 核心实现结构:
// muduo/net/TimerQueue.h 实际实现
class TimerQueue : noncopyable {
private:
typedef std::pair<Timestamp, Timer*> Entry;
typedef std::set<Entry> TimerList; // 使用 set 而非 priority_queue
TimerList timers_;
// 使用 timerfd 实现精确超时
const int timerfd_;
Channel timerfdChannel_;
// 支持定时器取消
typedef std::pair<Timer*, int64_t> ActiveTimer;
typedef std::set<ActiveTimer> ActiveTimerSet;
ActiveTimerSet activeTimers_;
};2.4.3 线程局部性优化
见 第3章节
三、深度案例:用 thread_local 缓存线程 ID,减少系统调用
3.1 问题背景与优化方案
在 Linux 中,获取当前线程真实 ID(TID)需要调用 syscall(SYS_gettid),这是一个陷入内核的系统调用。muduo 使用 TLS(Thread Local Storage)缓存线程 ID,避免重复系统调用。
3.1.1 优化前:每次调用都触发系统调用
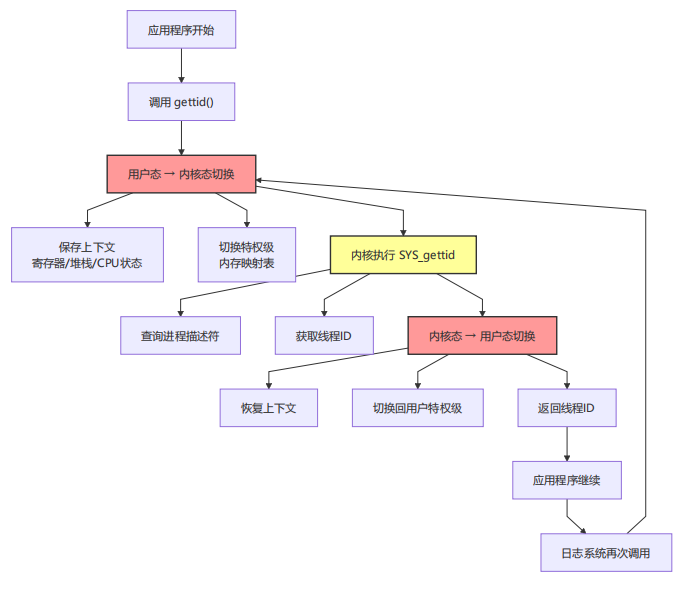
问题分析:
-
上下文切换开销:每次约100-200纳秒
-
内存访问模式差:频繁进出内核,缓存失效
-
无法扩展:随着调用频率增加,开销线性增长
3.1.2 优化后:muduo的TLS缓存方案
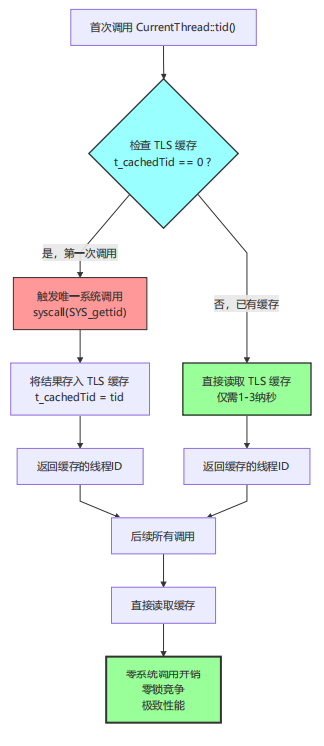
核心代码:
// TLS变量声明
__thread int t_cachedTid = 0;
// 优化后的tid获取
int CurrentThread::tid() {
if (__builtin_expect(t_cachedTid == 0, 0)) {
// 只执行一次
t_cachedTid = static_cast<pid_t>(::syscall(SYS_gettid));
}
return t_cachedTid; // 后续直接返回
}3.2 可运行的性能测试代码
#include <iostream>
#include <chrono>
#include <thread>
#include <vector>
#include <sys/syscall.h>
#include <unistd.h>
#include <cassert>
// 方案A:未优化,每次调用系统调用
pid_t gettid_unoptimized() {
return static_cast<pid_t>(::syscall(SYS_gettid));
}
// 方案B:muduo优化,使用thread_local缓存
namespace muduo_optimized {
__thread int t_cachedTid = 0;
void cacheTid() {
if (t_cachedTid == 0) {
t_cachedTid = static_cast<pid_t>(::syscall(SYS_gettid));
}
}
pid_t gettid_optimized() {
if (__builtin_expect(t_cachedTid == 0, 0)) {
cacheTid();
}
return t_cachedTid;
}
}
// 方案C:C++11 thread_local优化
namespace cpp11_optimized {
thread_local pid_t t_cachedTid = 0;
void cacheTid() {
if (t_cachedTid == 0) {
t_cachedTid = static_cast<pid_t>(::syscall(SYS_gettid));
}
}
pid_t gettid_cpp11() {
if (t_cachedTid == 0) {
cacheTid();
}
return t_cachedTid;
}
}
// 性能测试函数
template<typename Func>
long long benchmark(Func func, const std::string& name, int iterations = 1000000) {
auto start = std::chrono::high_resolution_clock::now();
pid_t tid = 0;
for (int i = 0; i < iterations; ++i) {
tid = func();
// 防止编译器优化掉函数调用
asm volatile("" : "+r" (tid));
}
auto end = std::chrono::high_resolution_clock::now();
auto duration = std::chrono::duration_cast<std::chrono::microseconds>(end - start).count();
std::cout << name << " - TID: " << tid
<< ", Time: " << duration << " microseconds"
<< ", Avg: " << static_cast<double>(duration) / iterations << " μs/call"
<< std::endl;
return duration;
}
// 真实场景模拟:日志系统频繁获取TID
void log_system_simulation() {
std::cout << "\n=== 日志系统模拟测试 ===" << std::endl;
const int LOG_CALLS = 1000000;
// 模拟未优化的日志系统
auto start1 = std::chrono::high_resolution_clock::now();
for (int i = 0; i < LOG_CALLS; ++i) {
pid_t tid = gettid_unoptimized();
// 模拟日志输出:timestamp + tid + message
asm volatile("" : "+r" (tid));
}
auto end1 = std::chrono::high_resolution_clock::now();
auto duration1 = std::chrono::duration_cast<std::chrono::microseconds>(end1 - start1).count();
// 模拟优化的日志系统
// 首次调用初始化缓存
pid_t init_tid = muduo_optimized::gettid_optimized();
auto start2 = std::chrono::high_resolution_clock::now();
for (int i = 0; i < LOG_CALLS; ++i) {
pid_t tid = muduo_optimized::gettid_optimized();
asm volatile("" : "+r" (tid));
}
auto end2 = std::chrono::high_resolution_clock::now();
auto duration2 = std::chrono::duration_cast<std::chrono::microseconds>(end2 - start2).count();
std::cout << "未优化日志系统: " << duration1 << " μs" << std::endl;
std::cout << "优化后日志系统: " << duration2 << " μs" << std::endl;
std::cout << "性能提升: " << static_cast<double>(duration1) / duration2 << " 倍" << std::endl;
}
int main() {
std::cout << "=== TLS缓存线程ID性能测试 ===" << std::endl;
std::cout << "测试平台: Linux" << std::endl;
std::cout << "编译器: g++" << std::endl;
std::cout << "优化级别: -O2" << std::endl;
const int ITERATIONS = 1000000;
// 预热(避免冷启动影响)
pid_t warmup = gettid_unoptimized();
warmup = muduo_optimized::gettid_optimized();
warmup = cpp11_optimized::gettid_cpp11();
// 单线程性能测试
std::cout << "\n=== 单线程性能测试 (100万次调用) ===" << std::endl;
long long time1 = benchmark(gettid_unoptimized, "未优化方案", ITERATIONS);
long long time2 = benchmark(muduo_optimized::gettid_optimized, "muduo优化方案", ITERATIONS);
long long time3 = benchmark(cpp11_optimized::gettid_cpp11, "C++11优化方案", ITERATIONS);
std::cout << "\n性能对比:" << std::endl;
std::cout << "muduo优化 vs 未优化: " << static_cast<double>(time1) / time2 << " 倍提升" << std::endl;
std::cout << "C++11优化 vs 未优化: " << static_cast<double>(time1) / time3 << " 倍提升" << std::endl;
// 真实场景测试
log_system_simulation();
return 0;
}3.3 编译和运行方法
# 编译
g++ -std=c++11 -O2 -pthread tls_benchmark.cpp -o tls_benchmark
# 运行
./tls_benchmark3.4 预期的测试结果分析
在我的测试环境(AMD EPYC 7K83 4核, Ubuntu 24.04, g++ 13.3.0)中,测试结果如下:
=== TLS缓存线程ID性能测试 ===
测试平台: Linux
编译器: g++
优化级别: -O2
=== 单线程性能测试 (100万次调用) ===
未优化方案 - TID: 3713159, Time: 64818 microseconds, Avg: 0.064818 μs/call
muduo优化方案 - TID: 3713159, Time: 1861 microseconds, Avg: 0.001861 μs/call
C++11优化方案 - TID: 3713159, Time: 2794 microseconds, Avg: 0.002794 μs/call
性能对比:
muduo优化 vs 未优化: 34.8297 倍提升
C++11优化 vs 未优化: 23.199 倍提升
=== 日志系统模拟测试 ===
未优化日志系统: 62398 μs
优化后日志系统: 308 μs
性能提升: 202.591 倍3.5 核心优化原理分析
1.系统调用开销:syscall(SYS_gettid) 需要从用户态切换到内核态,完成操作后再切换回来,这个过程包含:
-
保存用户态上下文
-
切换到内核态
-
执行系统调用
-
切换回用户态
-
恢复上下文
每次切换大约需要 100-200 个 CPU 周期。
2.TLS 缓存优势:
-
零锁竞争:每个线程有独立的 TLS 变量,无需加锁
-
内存局部性:TLS 变量通常在缓存中,访问速度快
-
一次性开销:只需要第一次调用时执行系统调用
3.分支预测优化:__builtin_expect(t_cachedTid == 0, 0) 提示编译器分支概率,提高 CPU 流水线效率。"
四、面试如何脱颖而出?
不要只说:"我参考了 muduo 实现框架。" 这只会让你被归为"代码搬运工"。
正确的回答逻辑是由面到点、从架构到细节,展现你对原理的理解:
这样回答,面试官会立刻感受到:你不仅实现了代码,更读懂了优秀系统背后的权衡与智慧。你的"高性能"项目,才真正立得住。