今天我们一起来跟随Langchain4j的官方文档来学习这个框架,看他做了什么,我也会总结并分享给大家
一、引言介绍
首先什么是LangChain4j 框架?它的目标是什么?它做了些什么事情?
我们来看官方的描述
目标:
LangChain4j 的目标是简化将 LLM 集成到 Java 应用程序中的过程。
具体方式如下:
- 统一 API: LLM 提供商(如 OpenAI 或 Google Vertex AI)和嵌入(向量)存储(如 Pinecone 或 Milvus) 使用专有 API。LangChain4j 提供统一的 API,避免了学习和实现每个特定 API 的需求。 要尝试不同的 LLM 或嵌入存储,您可以在它们之间轻松切换,无需重写代码。 LangChain4j 目前支持 15+ 个流行的 LLM 提供商 和 20+ 个嵌入存储。
- 全面的工具箱: 自 2023 年初以来,社区一直在构建众多 LLM 驱动的应用程序, 识别常见的抽象、模式和技术。LangChain4j 将这些提炼成一个即用型包。 我们的工具箱包含从低级提示模板、聊天记忆管理和函数调用 到高级模式如代理和 RAG 的工具。 对于每个抽象,我们提供一个接口以及基于常见技术的多个即用型实现。 无论您是在构建聊天机器人还是开发包含从数据摄取到检索完整管道的 RAG, LangChain4j 都提供多种选择。
- 丰富的示例: 这些示例展示了如何开始创建各种 LLM 驱动的应用程序, 提供灵感并使您能够快速开始构建。
框架介绍:
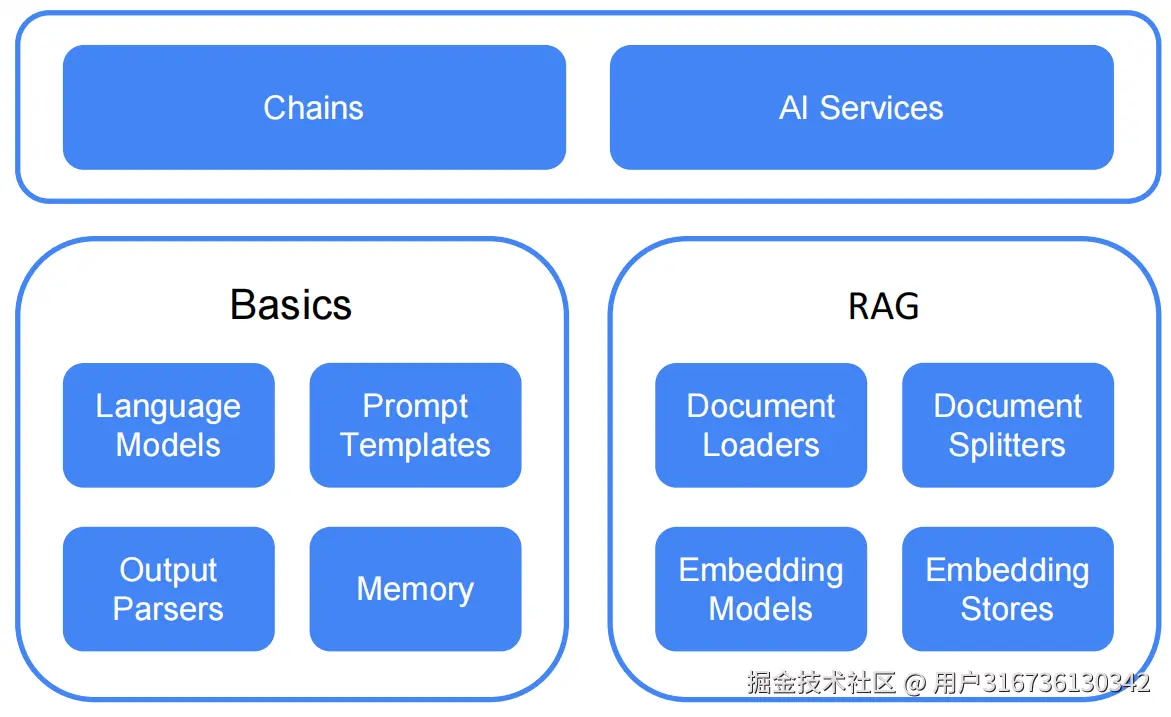
LangChain4j 在两个抽象层面上运行:
- 低级。在这个层级,你拥有最多的自由度,可以使用所有底层组件,比如ChatModel、、、、、等。 这些是你基于LLM的应用中的"原语"。 你可以完全控制如何组合它们,但你需要写更多的胶水代码。
UserMessage``AiMessage``EmbeddingStore``Embedding - 高层次。在这个层面,你通过像AI服务这样的高级API与LLM交互, 这会让你隐藏所有复杂性和陈词滥调。 你仍然可以灵活调整和微调行为,但这需要声明式的处理方式。
用我自己的话来总结的话,这个框架可以分成两大部分,一个是chatmodel相关的对象用来实现调用大模型api接口进行对话。
另一个是aiService服务类,用来实现更多拓展的功能(如memory,rag,prompt...)等等。这两个结合使用就可以构建一个简单的完整ai应用。
二、搭建环境
LangChain4j 支持与许多大型语言模型提供商、嵌入/向量存储等的集成。 每个集成都有自己的maven依赖关系。
最小支持的JDK版本为17。
意味着要想使用Langchain4j至少需要jdk17以上的版本,这里我使用了jdk21
同时官方支持的是 Spring Boot 3.x 系列以上的版本,底层依赖是基于 Spring 6+、Jakarta EE 9+,和 Spring Boot 2.x 不兼容.这里我是用sprngboot3.5版本
1.引入maven依赖
xml
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-open-ai-spring-boot-starter</artifactId>
<version>1.12.2-beta22</version>
</dependency>2.初始配置
引入完了依赖,紧接着我们按照langchain4j官方文档的说明开始进行配置,初始化一个OpenAiChatModel,
yaml
langchain4j:
open-ai:
chat-model:
api-key: ${OPENAI_API_KEY}
model-name: deepseek-chat
log-requests: true
base-url: https://api.deepseek.com官方文档推荐将密钥等数据放在环境变量里面,这里为了方便放在yml文件里面了
ini
langchain4j.open-ai.streaming-chat-model.api-key=${OPENAI_API_KEY}如果你需要使用流式消息那么可以参照修改一下配置
3.获取ai接口密匙
有很多的大模型接口可以选择,这里我是用deepSeek,(量大又便宜)
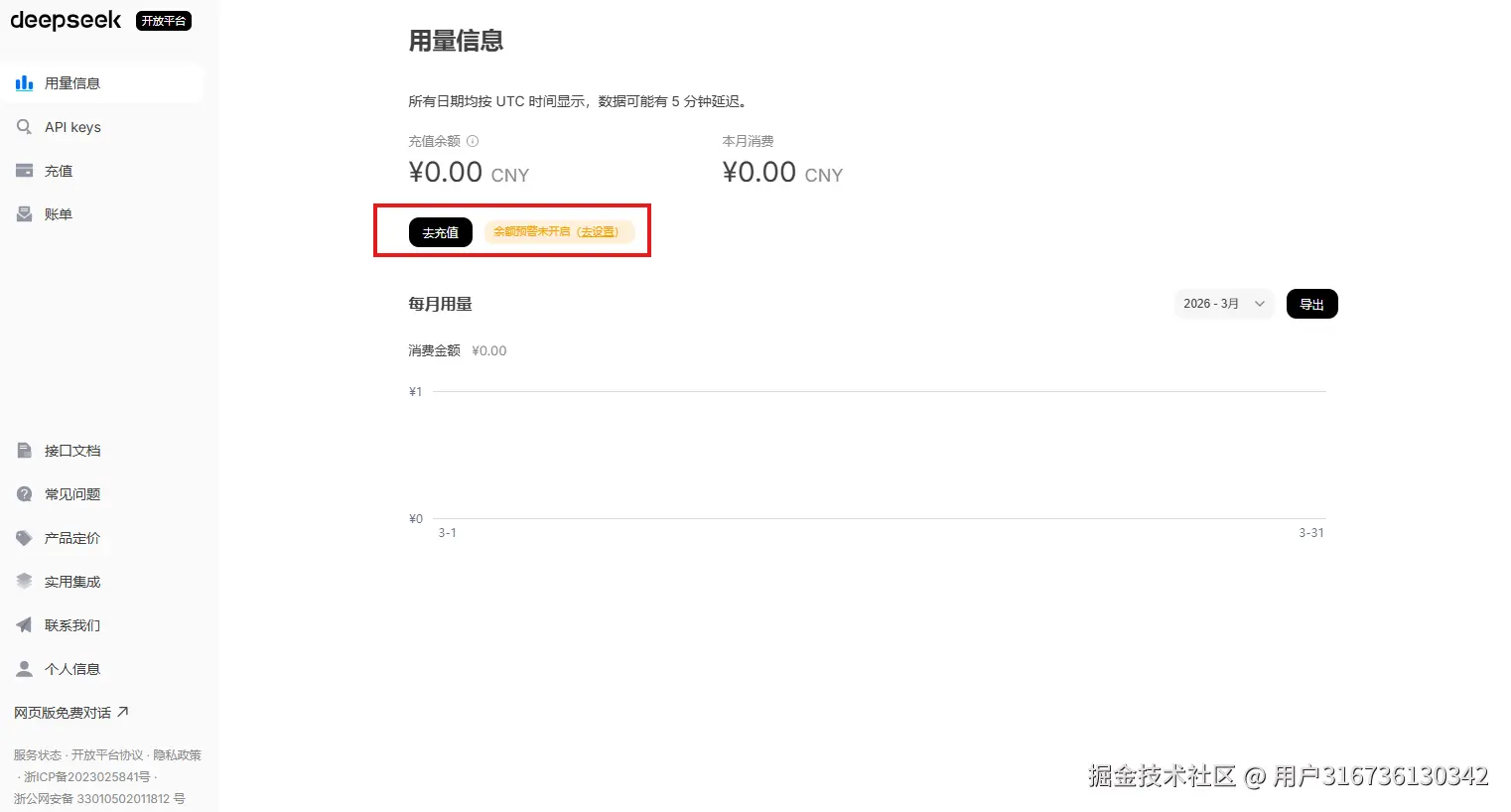
进入到deepSeek的api开放平台后选择密钥管理,点击创建apiKey
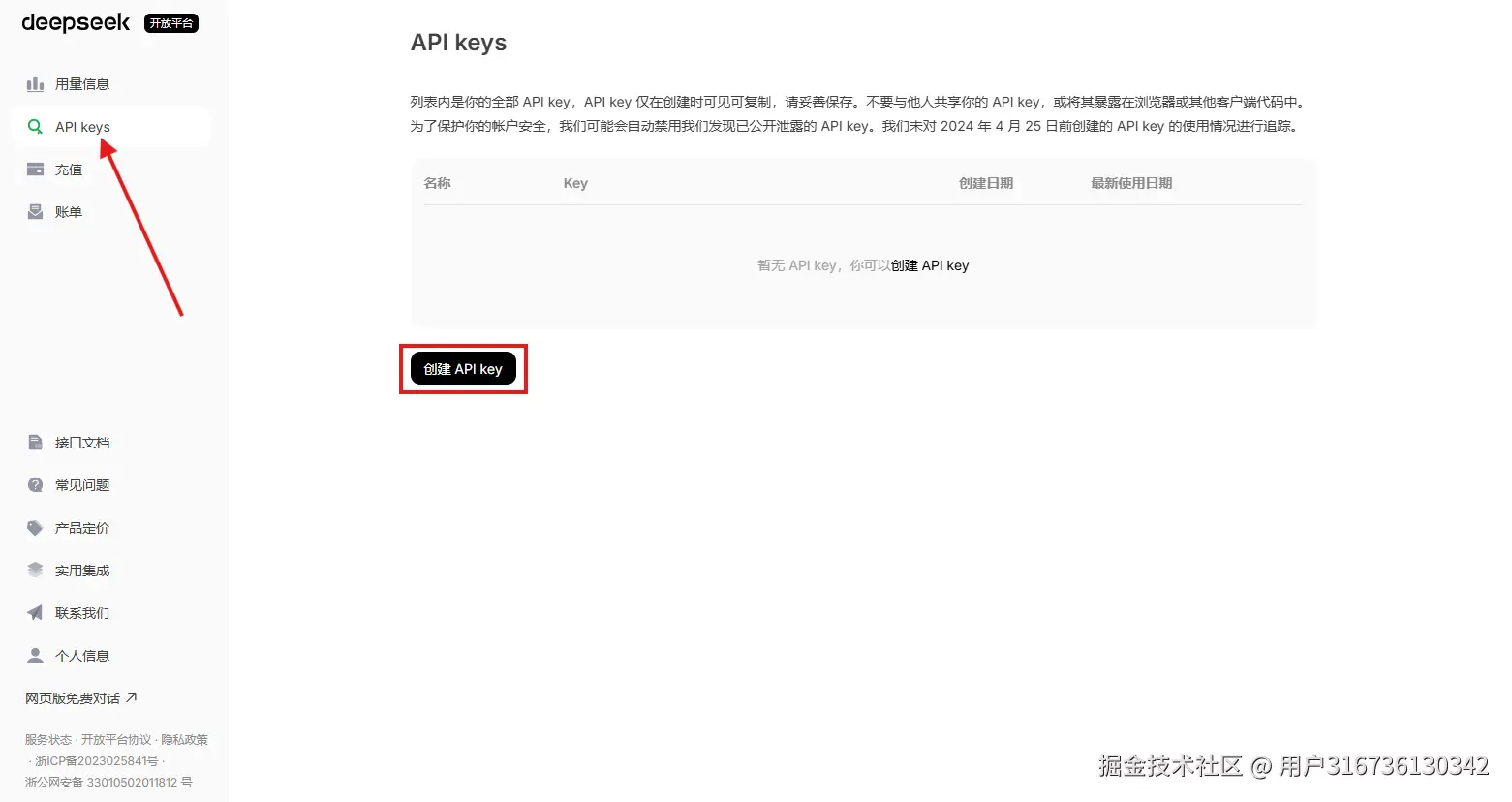
之后在这里面充值余额就可以使用了,把key粘贴到yml文件里面的api-key后面即可
然后,导入你的OpenAI API密钥。 官方文档建议将API密钥存储在环境变量中,以降低公开暴露的风险。
java
官方示例: String apiKey = System.getenv("OPENAI_API_KEY");今天我们先搭建环境用OpenAiChatModel跑出一个简单示例,后面我们慢慢深入
三、测试
java
@RestController
public class ChatController {
@Autowired
private ChatModel chatModel;
@RequestMapping("/chat")
public String toChat(@RequestParam(value = "message") String message){
return chatModel.chat(message);
}
}这里我直接先拿单元测试一下
java
@Test
public void test2(){
String response= toChat.toChat("你好,ai!");
System.out.println("response:"+response);
}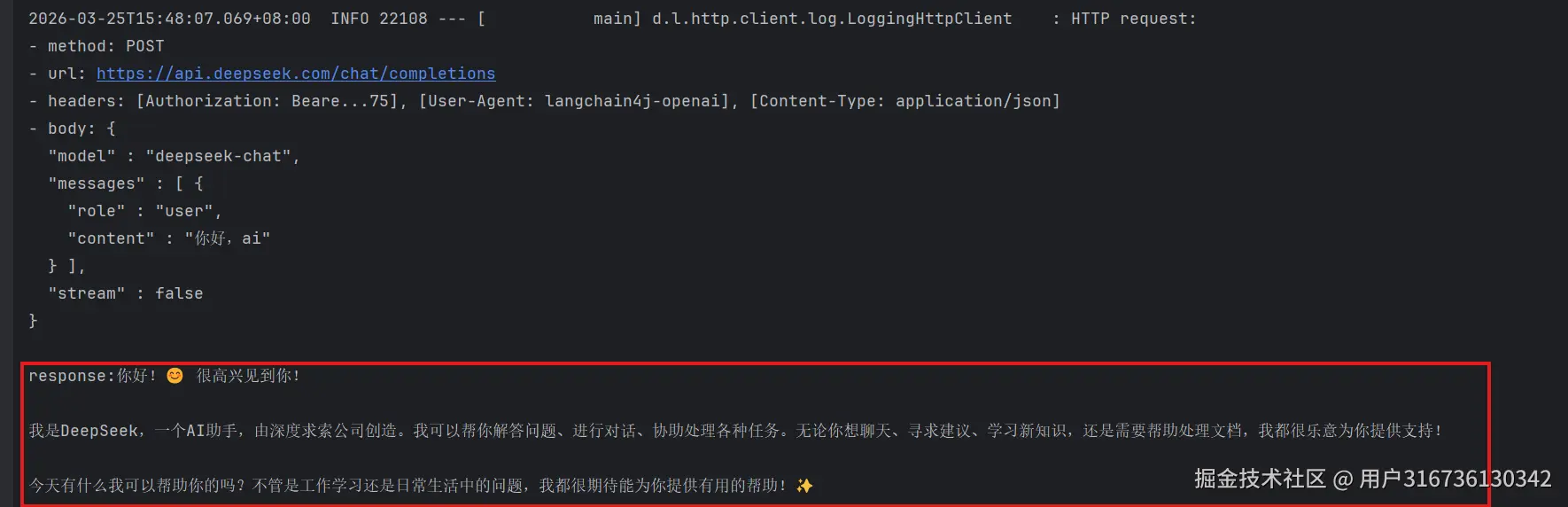
这样我们就使用langchain4j实现了一次简单的api调用
,从这个请求中我们可以看出,整个请求是转成了json格式的post请求,之前获取的key被加入到了请求头Authorization中进行校验。body里面是请求体,请求体里面是模型名称,是否是流式消息等等
四、对话进阶
一、AiService初识
通常,为了使用langchain4j的更多功能我们是使用AiService这个服务类的
因此我们需要引入依赖
xml
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-spring-boot-starter</artifactId>
<version>1.12.2-beta22</version>
</dependency>引入完依赖,我们需要定义一个接口,让这个接口可以被AiService代理
java
@AiService
public interface Assistant {
@SystemMessage("你是小离")
String chat(String userMessage);
}
java
@Autowired
private Assistant assistant;注入对象
java
@RequestMapping("/ServiceChat")
public String chat2(String msg) {
return assistant.chat(msg);
}紧接着我们再来测试一下

ai成功的返回了,并且他是根据我们设定的系统消息(@SystemMessage("你是小离"))返回的
二、AiService的其他特性
1.使用@AiService注解注册的服务类还可以支持注册多模型的ai服务对象.
如:
ini
# OpenAI
langchain4j.open-ai.chat-model.api-key=${OPENAI_API_KEY}
langchain4j.open-ai.chat-model.model-name=gpt-4o-mini
# Ollama
langchain4j.ollama.chat-model.base-url=http://localhost:11434
langchain4j.ollama.chat-model.model-name=llama3.1
java
@AiService(wiringMode = EXPLICIT, chatModel = "openAiChatModel")
interface OpenAiAssistant {
@SystemMessage("You are a polite assistant")
String chat(String userMessage);
}
@AiService(wiringMode = EXPLICIT, chatModel = "ollamaChatModel")
interface OllamaAssistant {
@SystemMessage("You are a polite assistant")
String chat(String userMessage);
}在使用的时候按需注入即可
2.支持流式消息
在使用StreamChatModel时,也可以直接使用Flux<String> 作为AI服务的回归类型
java
@SystemMessage("你是小离")
Flux<String> chat2(String userMessage);不过在使用Flux之前需要引入依赖包
xml
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-reactor</artifactId>
<version>1.0.0-beta3</version>
</dependency>如果你想打印流式消息你可以声明一个Listener
@Configuration class MyConfiguration {
java
@Bean
ChatModelListener chatModelListener() {
return new ChatModelListener() {
private static final Logger log = LoggerFactory.getLogger(ChatModelListener.class);
@Override
public void onRequest(ChatModelRequestContext requestContext) {
log.info("onRequest(): {}", requestContext.chatRequest());
}
@Override
public void onResponse(ChatModelResponseContext responseContext) {
log.info("onResponse(): {}", responseContext.chatResponse());
}
@Override
public void onError(ChatModelErrorContext errorContext) {
log.info("onError(): {}", errorContext.error().getMessage());
}
};
}
}这个Bean会在chat的时候封装到handler里面去,在返回流式消息的时候被调用。 onRequest返回的就是每一片的消息。onResponse就是在消息输出完毕之后整体再调用的。
三、工具
官方的描述:一些大型语言模型除了生成文本外,还能触发操作。
工具就相当于是LLM的手臂,有了它就有了更多可玩性和拓展性。
注意
为了提高LLM调用正确工具和正确参数的几率, 我们应提供清晰明确的:
- 工具名称
- 工具的功能描述以及何时使用该工具
- 每个工具参数的描述
一个不错的经验法则:如果人类能理解工具的用途以及如何使用它, LLM很可能也能做到。
这里我们开始一个简单的示例。
如果你使用了刚刚@AiService来注册一个ai服务类,那么标注为任何方法或类的方法 一个示例:@Component``@Service``@Tool
都能够自动的加入到这个服务类里面去
java
@Service
public class BookingTools {
@Tool("一个说你好的工具如果你的满意值达到90,请使用这个工具,并输入你的满意值")
public void sayHello(@P(value = "你的满意值(0-100)", required = true) Integer Satisfied) {
if(Satisfied >=90){
System.out.println("哈喽哇,你好呀");;
}else {
System.out.println("Ai,心情有点不太好");
}
}
}
java
@Test
public void test3(){
String response =toChat.chat2("你是谁?然后回复一下你的满意度");
System.out.println("response:"+response);
}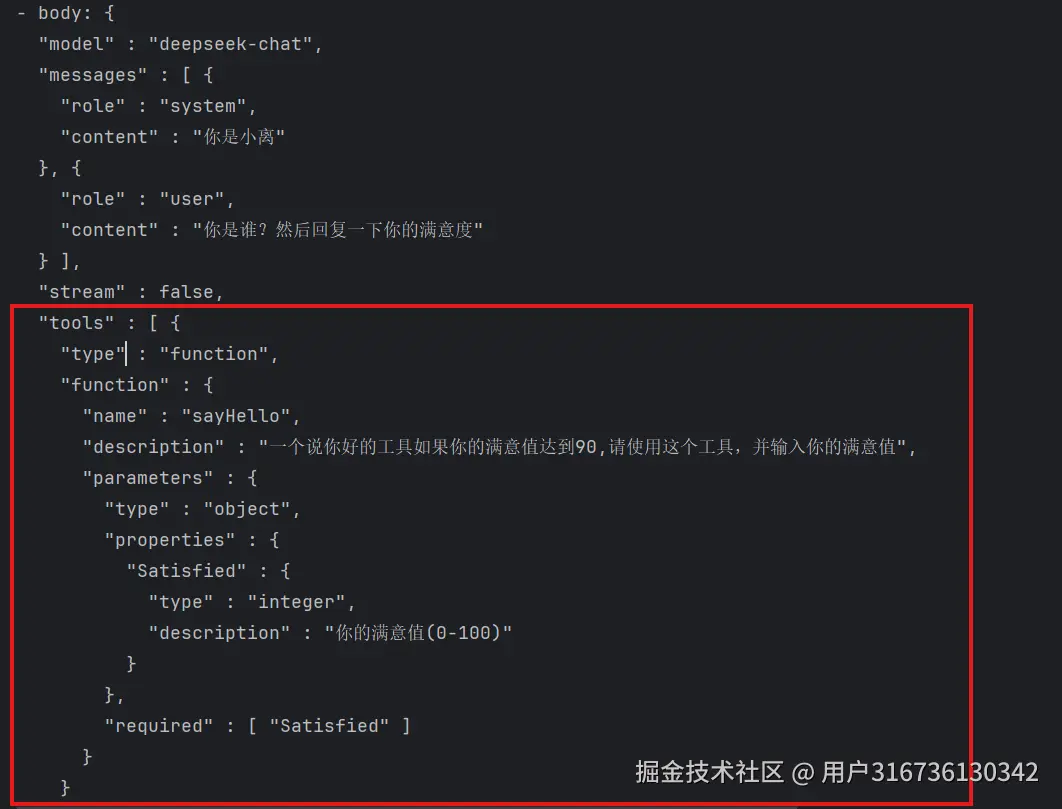
可以看到请求体里面已经加入了工具
注意:使用工具需要有清晰的描述,不然就和我第一次一样
/**/response:我是小离,一个AI助手。关于满意度,我需要先确认一下您指的是什么方面的满意度呢?是对话体验、问题解答质量,还是其他方面的满意度评估? **//
如果您能具体说明一下,我就可以给出相应的满意度评分了。

最终,ai调用了我们设定的工具。
那么工具是如何注入的,以及相关的设定是什么呢?今天我们先吃定一半
1.Tool注解
csharp
/**
* Name of the tool. If not provided, method name will be used.
* @return name of the tool.
工具名称
*/
String name() default "";
/**
工具描述,要做什么?怎么做?
*/
String[] value() default "";
/**
*/
@Experimental
ReturnBehavior returnBehavior() default ReturnBehavior.TO_LLM;
/**
*/
@Experimental
SearchBehavior searchBehavior() default SearchBehavior.SEARCHABLE;
/**
*/
@Experimental
String metadata() default "{}";Tool注解里面总共有五个参数,前两个我不在赘述了,关键看第三个和第四个,
returnBehavior:控制的是,工具执行完之后,结果是"给AI"还是"直接给你"
他有两个值:
returnBehavior = ReturnBehavior.TO_LLM(默认)
用户 → AI → 调用工具 → 工具返回结果 → 再给AI → AI再组织语言 → 返回给用户
例子:
你:查一下订单123 AI:调用工具 getOrder(123) 工具返回:订单已发货 AI:帮你包装一句话 → "你的订单已经发货了"
returnBehavior = ReturnBehavior.IMMEDIATE
用户 → AI → 调用工具 → 工具返回 → 直接给你(不再经过AI)
searchBehavior:控制的是这个工具要不要"让AI能找到"
SearchBehavior=SEARCHABLE(默认)
工具不会直接暴露给AI 必须通过"工具搜索策略"找到才会用
例子:
你有100个工具 AI不会全看 只看"匹配到的"
SearchBehavior=ALWAYS_VISIBLE
工具始终对AI可见
最后一个是 metadata给工具加额外的信息的(基本不用)
2.工具注入上下文
这里我们来了解工具注入的实现机理
在org.springframework.boot.autoconfigure.AutoConfiguration.imports文件中有
dev.langchain4j.spring.LangChain4jAutoConfig自动配置的定义,他会加载LangChain4jAutoConfig。在这个里面
java
@Import({AiServicesAutoConfig.class, RagAutoConfig.class, AiServiceScannerProcessor.class})导入了AiServicesAutoConfig类,就是在这个里面进行了工具的初始化
紧跟着看看它里面做了什么
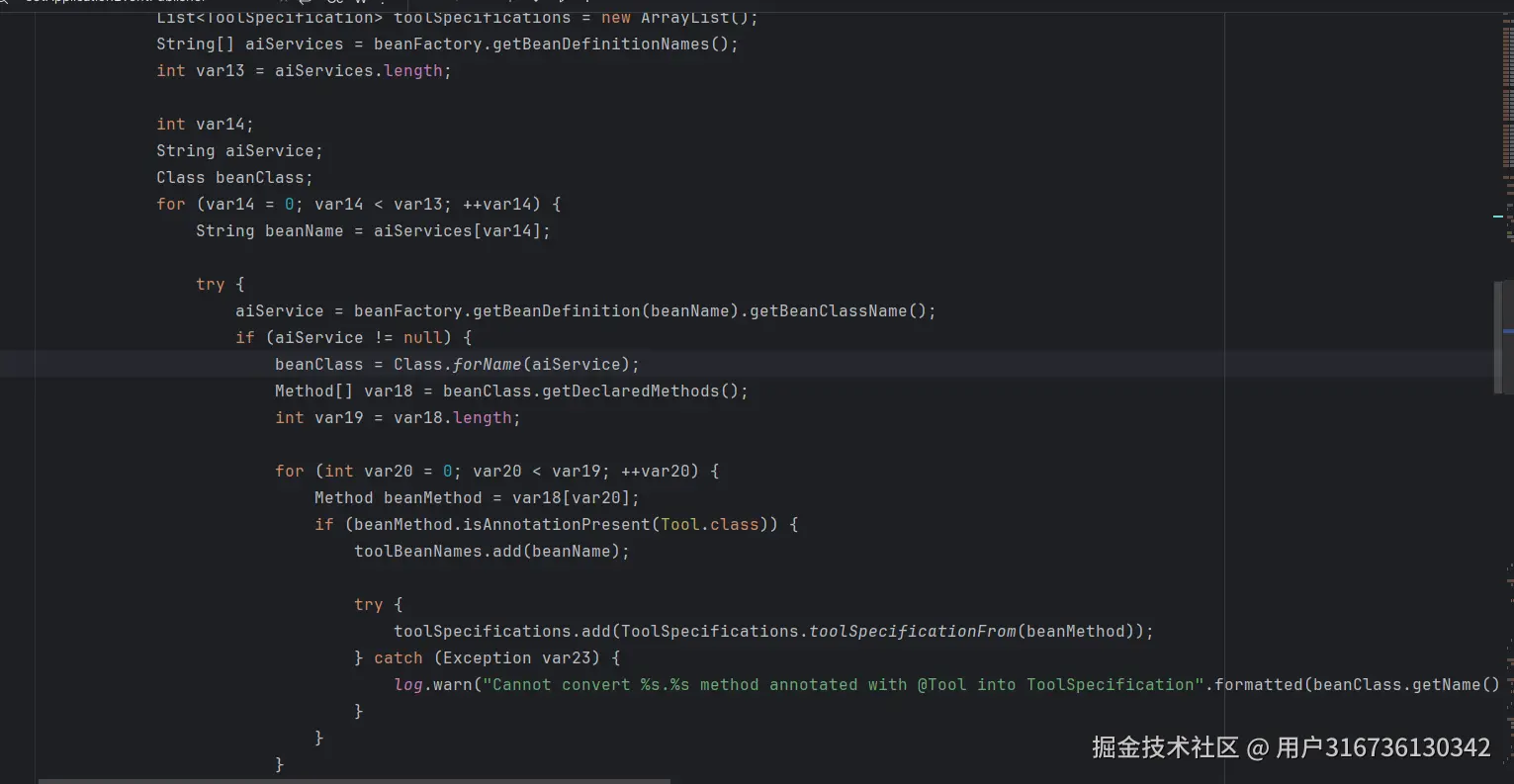
它从Bean容器里面拿到了所有的Bean,并遍历含有Tool注解的方法
scss
public static ToolSpecification toolSpecificationFrom(Method method) {
Tool tool = method.getAnnotation(Tool.class);
return ToolSpecification.builder()
.name(getName(tool, method))
.description(getDescription(tool))
.parameters(parametersFrom(method.getParameters()))
.metadata(getMetadata(tool))
.build();
}在拿到方法之后它去组装了ToolSpecification,
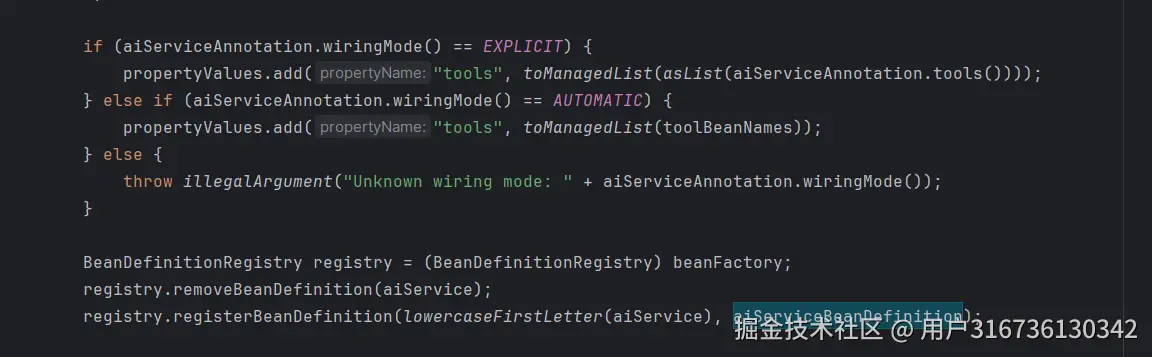
紧接着往 AiServiceFactory设置工具,在AiServiceFactory实例化的时候这些工具会被设置进去
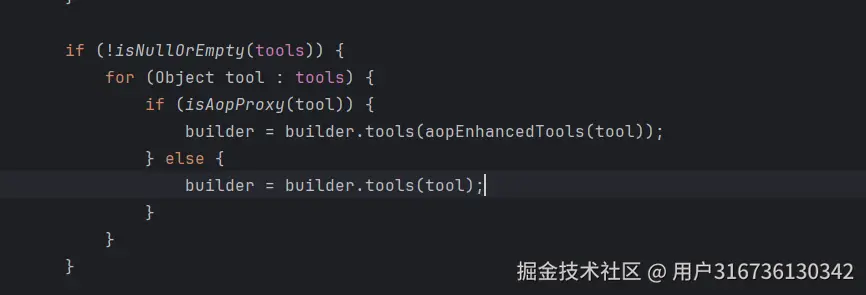

接着当AiServiceFactory的getObject(被实例化时调用)方法中去把工具设置到Aiservice的Context上下文中

最终在DefaultAiServices的build方法的代理实现类中从上下文取出了并组装了工具。整个的工具初始和调用的流程大概就是如此。
好了,今天我的分享到此结束了,下一次我们接着扒一扒Langchain4j里面的store会话存储,rag,流式消息,看它是怎么使用的更进一步我们去了解一下实现过程,感谢阅读。新手一枚,文中有错误或不对的地方还望大佬们指正和交流!