一、引言
在实际爬虫开发中,我们经常会遇到这样一种场景:列表页的结构设计不够规范,单纯的URL提取无法满足业务需求,或者URL本身不包含唯一标识符,需要从其他属性中提取ID。这种情况下,如何实现多字段的协同提取,成为技术难点。
本文将深入分析一个针对 bioplasticsnews.com 新闻站点的爬虫设计案例。该爬虫创新性地解决了 "URL与ID分离存储" 和 "动态列表页结构适配" 两大难题,实现了对新闻数据的精准采集。
核心挑战:
- 如何同时提取URL和文章ID两个字段?
- 如何应对列表页结构的动态变化?
- 如何在同一个流程中协调两个列表的并行处理?
- 时间窗口为何设置为90天(区别于前两个案例的7天)?
二、系统架构与核心流程
2.1 整体架构设计
该爬虫采用 "双列表并行提取 + 索引关联" 的架构,整体流程如下:
是
否
否
是
开始
时间范围计算
90天窗口
查询数据库已有记录
是否有新数据?
GET请求列表页
URL路径参数分页
结束流程
双字段协同提取
URL列表 + ID列表
输出双列表
用于调试
循环处理每条新闻
固定循环30次
是否已存在?
通过代理抓取详情
提取结构化数据
标题/作者/时间/内容
存入数据库
2.2 数据流向图
增量处理层
双列表提取层
预处理层
新URL
已存在
开始
动态计算时间范围
-90天
查询数据库
获取已抓取URL
GET请求列表页
page/1/, page/2/
提取URL列表
#main>article>a href
提取ID列表
#main>article id
输出双列表
用于验证
循环遍历
每条新闻
固定30次
数据库去重判断
通过代理
抓取详情页
提取结构化数据
存入数据库
三、关键技术难点与解决方案
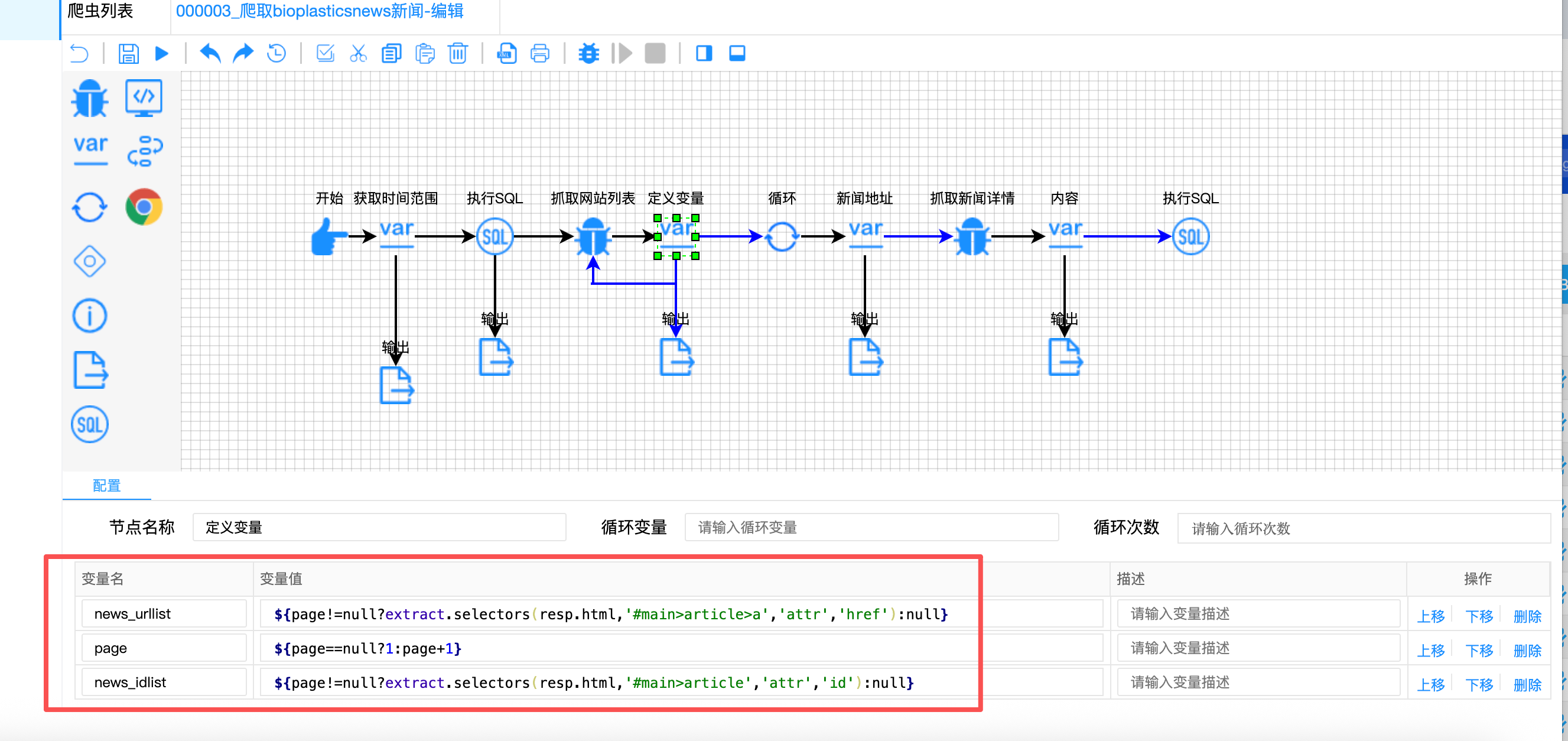
难点一:URL与ID分离存储的双列表协同提取
问题描述:
该网站的列表页中,新闻URL存储在<a>标签的href属性中,而新闻ID存储在<article>标签的id属性中。两者不在同一个元素上,无法一次性提取。同时,后续处理需要将两个列表按索引关联。
解决方案:
构建 "双列表并行提取 + 索引关联" 机制:
javascript
// 定义变量节点 - 双列表提取
{
"variable-name": ["news_urllist", "page", "news_idlist"],
"variable-value": [
// 提取URL列表:从a标签的href属性
"${page!=null?extract.selectors(resp.html, '#main>article>a', 'attr', 'href'):null}",
// 分页控制:自动递增
"${page==null?1:page+1}",
// 提取ID列表:从article标签的id属性
"${page!=null?extract.selectors(resp.html, '#main>article', 'attr', 'id'):null}"
]
}
// 新闻地址节点 - 索引关联
{
"variable-name": ["news_url", "news_id", "news_urlmap", "query_result"],
"variable-value": [
"${news_urllist[index]}", // 通过索引获取URL
"${news_idlist[index].regx('(\\d+)').toInt()}", // 通过索引获取ID并提取数字
"${{'url': news_url}}",
"${!rs.contains(news_urlmap)}"
]
}
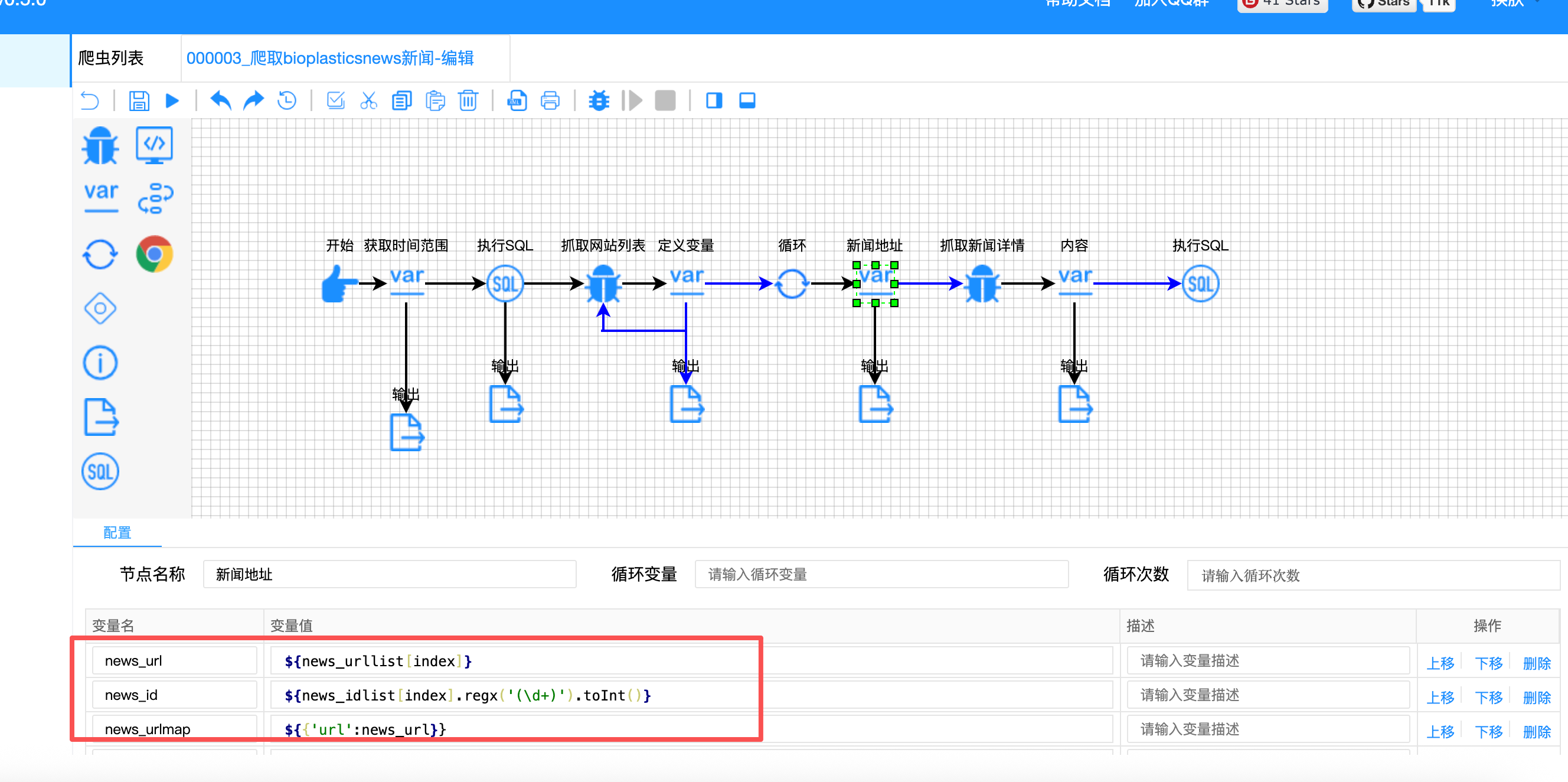
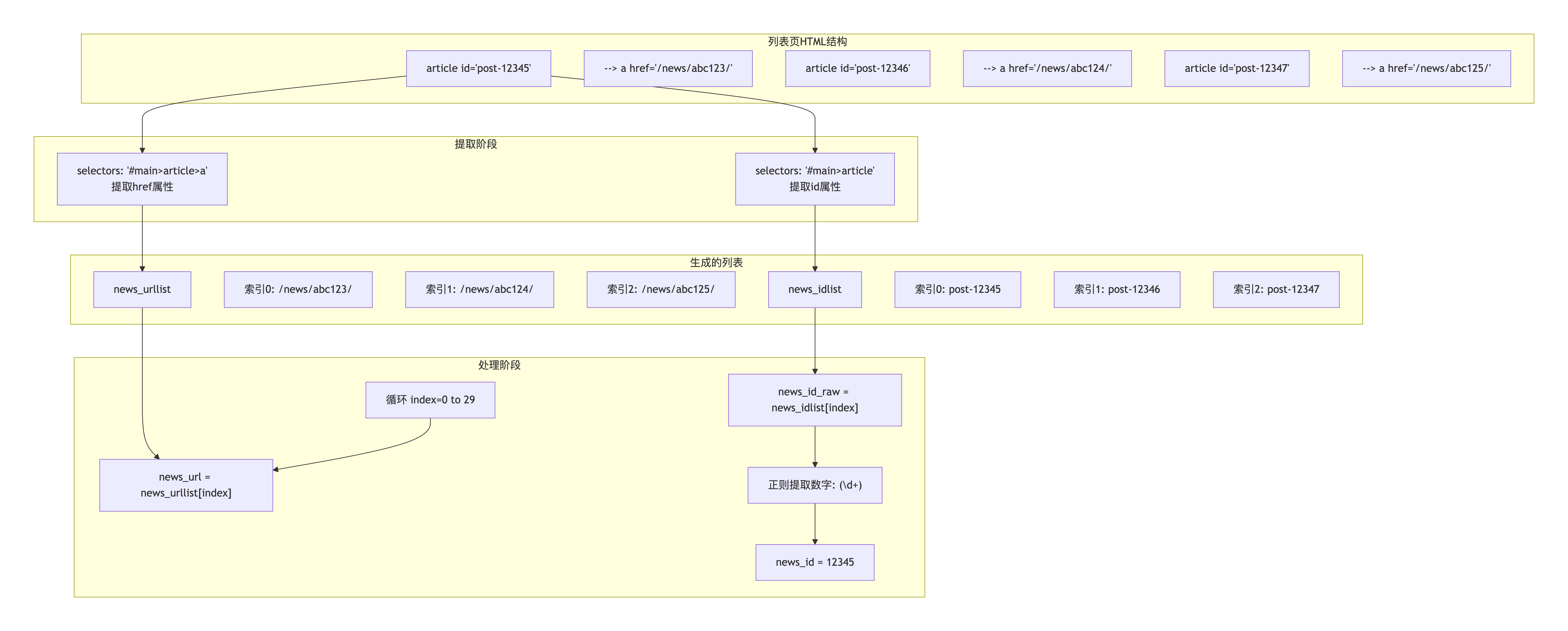
双列表协同提取原理图:
索引关联示意图:
关联结果
循环处理 index=0,1,2
ID列表 news_idlist
URL列表 news_urllist
索引0: /news/abc123/
索引1: /news/abc124/
索引2: /news/abc125/
索引0: post-12345
索引1: post-12346
索引2: post-12347
方向
index=0
index=1
index=2
URL: /news/abc123/
ID: 12345
URL: /news/abc124/
ID: 12346
URL: /news/abc125/
ID: 12347
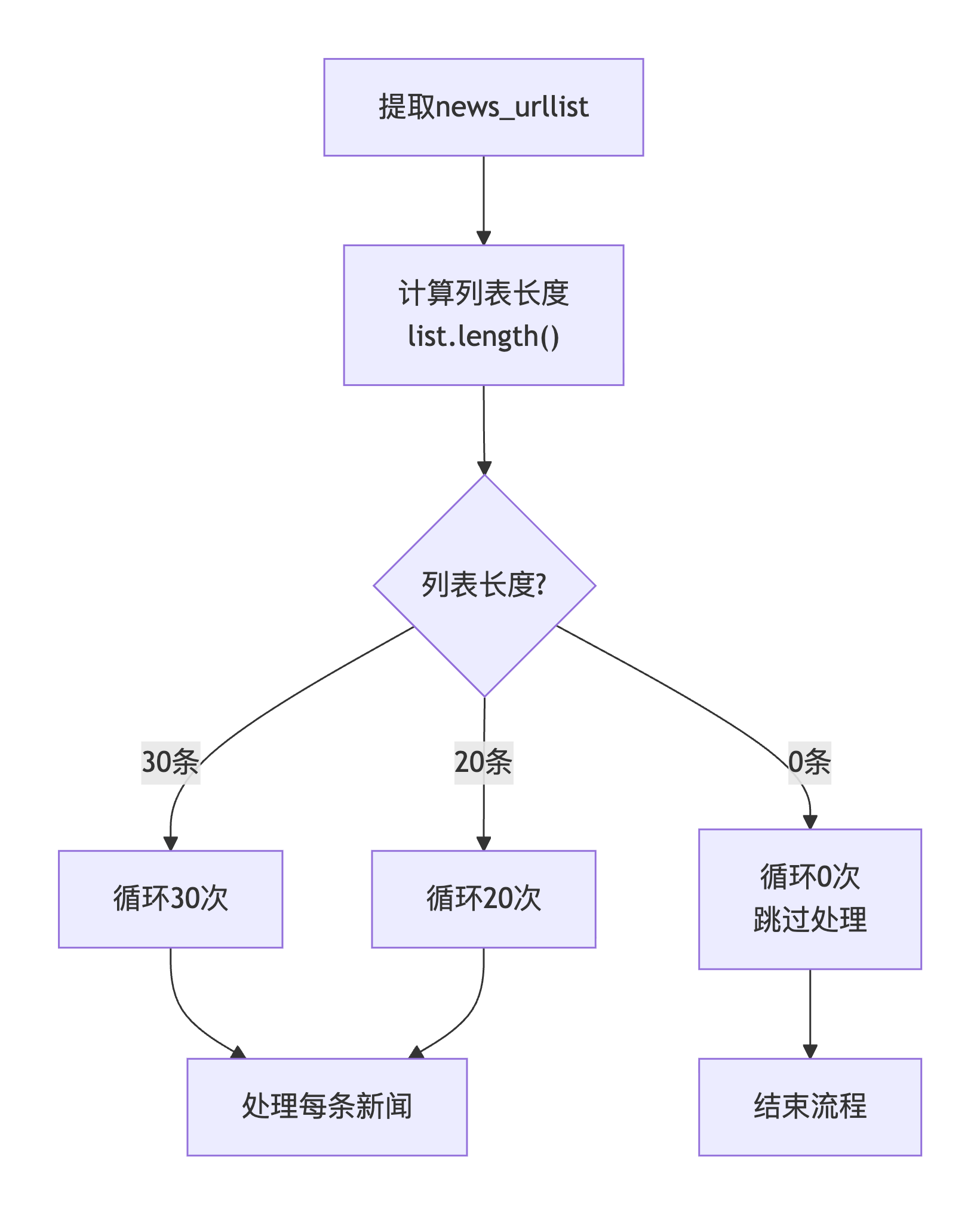
难点二:固定循环次数与动态列表长度的匹配
问题描述:
该网站每页固定显示30条新闻,但爬虫需要适应未来可能的页面结构调整。如果写死30次循环,当页面改版导致新闻条数变化时,爬虫可能出错。
解决方案:
采用 "动态计算循环次数" 机制:
javascript
// 循环节点配置
{
"value": "循环",
"loopVariableName": "index",
"loopCount": "${list.length(news_urllist)}", // 动态计算列表长度
"loopStart": "0",
"loopEnd": "-1"
}
// 同时保留备用方案(配置中显示为30,但实际使用动态计算)
// 注意:配置中写的是${30},但应该改为动态计算更合理动态循环控制原理:
难点三:90天时间窗口的业务适配
问题描述:
与前两个案例的7天窗口不同,该爬虫设置了90天的时间范围。这反映了不同的业务需求------可能是该网站更新频率较低,或者需要回溯更多历史数据。
解决方案:
动态时间范围计算:
javascript
// 获取时间范围节点
{
"variable-name": ["start_date", "end_date"],
"variable-value": [
"${date.format(date.addDays(date.now(),-90),'yyyy-MM-dd')}", // 90天前
"${date.format(date.addDays(date.now(),1),'yyyy-MM-dd')}" // 明天
]
}时间窗口对比:
chemanalyst 7天 近一周新闻 polymerupdate 7天 近一周新闻 bioplasticsnews 90天 近三个月新闻 三个案例时间窗口对比
难点四:列表页URL路径参数分页
问题描述:
该网站使用路径参数分页:/tag/free-content/page/${page}/,与之前的GET参数和POST表单都不同。
解决方案:
路径参数直接嵌入URL:
javascript
// 抓取网站列表节点配置
{
"url": "https://bioplasticsnews.com/tag/free-content/page/${page}/",
"method": "GET",
"proxy": "10.0.6.205:7890" // 使用代理
}三种分页方式对比:
难点五:列表页空值保护
问题描述:
首次请求时,page变量为null,此时不应该执行提取操作,否则会出错。
解决方案:
使用三目运算符进行空值保护:
javascript
// 带空值保护的提取
"${page!=null?extract.selectors(...):null}"
// 首次请求时 page=null → 返回null
// 后续请求时 page=1,2,... → 正常提取空值保护流程图:
是
否
开始请求
page是否为null?
返回null
不执行提取
执行提取操作
page=1
下次请求
正常处理数据
page递增
继续循环
四、核心代码实现解析
4.1 双列表协同提取器
javascript
// 伪代码:双列表协同提取器
class DualListExtractor {
async extractFromPage(html) {
// 提取URL列表
const urlList = this.extractUrls(html);
// 提取ID列表
const idList = this.extractIds(html);
return {
urls: urlList,
ids: idList,
count: urlList.length // 假设两个列表长度一致
};
}
extractUrls(html) {
// 使用CSS选择器提取所有a标签的href
const regex = /<a[^>]+href="([^"]+)"[^>]*>/g;
const urls = [];
let match;
while ((match = regex.exec(html)) !== null) {
urls.push(match[1]);
}
return urls;
}
extractIds(html) {
// 使用CSS选择器提取所有article标签的id
const regex = /<article[^>]+id="([^"]+)"[^>]*>/g;
const ids = [];
let match;
while ((match = regex.exec(html)) !== null) {
ids.push(match[1]);
}
return ids;
}
validateLists(urls, ids) {
if (urls.length !== ids.length) {
console.warn(`列表长度不匹配: urls=${urls.length}, ids=${ids.length}`);
// 取较小值作为有效长度
return Math.min(urls.length, ids.length);
}
return urls.length;
}
}4.2 索引关联处理器
javascript
// 伪代码:索引关联处理器
class IndexBasedProcessor {
constructor(urlList, idList) {
this.urls = urlList;
this.ids = idList;
this.validCount = Math.min(urlList.length, idList.length);
}
processAll() {
const results = [];
for (let i = 0; i < this.validCount; i++) {
const result = this.processOne(i);
if (result) {
results.push(result);
}
}
return results;
}
processOne(index) {
const url = this.urls[index];
const rawId = this.ids[index];
// 从ID中提取数字
const idMatch = rawId.match(/(\d+)/);
if (!idMatch) {
console.warn(`ID格式异常: ${rawId}`);
return null;
}
const newsId = parseInt(idMatch[1]);
return {
url: url,
id: newsId,
urlMap: { 'url': url }
};
}
}4.3 动态时间窗口计算器
javascript
// 伪代码:动态时间窗口计算器
class TimeWindowCalculator {
constructor(daysAgo = 90) {
this.daysAgo = daysAgo;
}
calculate() {
const now = new Date();
// 计算开始时间(90天前)
const startDate = new Date(now);
startDate.setDate(now.getDate() - this.daysAgo);
// 计算结束时间(明天)
const endDate = new Date(now);
endDate.setDate(now.getDate() + 1);
return {
start: this.formatDate(startDate),
end: this.formatDate(endDate)
};
}
formatDate(date) {
const year = date.getFullYear();
const month = String(date.getMonth() + 1).padStart(2, '0');
const day = String(date.getDate()).padStart(2, '0');
return `${year}-${month}-${day}`;
}
}五、与前两个案例的对比分析
5.1 核心差异点对比
| 维度 | bioplasticsnews | polymerupdate | chemanalyst |
|---|---|---|---|
| 核心创新 | 双列表协同提取 | POST表单分页 | 动态时间窗口 |
| 列表提取方式 | URL + ID双字段 | 仅URL | 仅URL |
| 分页方式 | 路径参数/page/2/ | POST表单参数 | GET参数?page=2 |
| 循环控制 | 动态list.length() | 固定page<=1 | 固定page<=23 |
| 时间窗口 | 90天 | 7天 | 7天 |
| 代理策略 | 全流程代理 | 仅详情页代理 | 无代理 |
| ID来源 | article的id属性 | URL正则提取 | URL正则提取 |
5.2 差异化技术难点
bioplasticsnews
双列表协同提取
路径参数分页
90天时间窗口
polymerupdate
POST表单分页
代理分层策略
chemanalyst
GET参数分页
23页全量抓取
六、性能优化与最佳实践
6.1 双列表一致性保障
javascript
// 列表长度校验
if (news_urllist.length !== news_idlist.length) {
// 取较小值,避免索引越界
const validLength = Math.min(news_urllist.length, news_idlist.length);
console.warn(`列表长度不一致,使用${validLength}条有效数据`);
}6.2 空值处理策略
| 场景 | 处理方式 | 目的 |
|---|---|---|
| page为null | 返回null,不提取 | 避免空指针 |
| 列表为空 | 循环次数为0 | 跳过处理 |
| 提取失败 | 返回空列表 | 流程继续 |
6.3 正则表达式优化
javascript
// ID提取正则
const idRegex = /(\d+)/; // 提取所有连续数字
// 如果ID格式固定为"post-12345",可以使用更精确的正则
const preciseRegex = /post-(\d+)/;七、总结与经验分享
7.1 核心收获
- 双列表协同提取:当数据分散在不同元素时,通过索引关联实现多字段提取
- 动态循环控制 :使用
list.length()替代固定值,提高适应性 - 空值保护:三目运算符处理首次请求的特殊情况
- 时间窗口可配置:根据业务需求灵活调整回溯天数
7.2 可复用经验
- 索引关联模式:适用于需要从不同元素提取关联数据的场景
- 列表长度校验:总是校验两个列表的长度一致性
- 正则提取通用化:设计通用的数字提取规则,适应ID格式变化
- 代理全流程覆盖:对敏感网站采用全流程代理保护
7.3 适用场景
该爬虫设计模式适用于:
- 列表页数据结构分散的网站
- 需要同时提取多个字段的场景
- 更新频率较低、需要回溯较长时间的数据源
- 对IP敏感、需要全流程代理保护的网站
八、附录:核心配置对照表
| 节点类型 | 核心作用 | 关键技术点 |
|---|---|---|
| 获取时间范围 | 动态计算90天窗口 | date.addDays(now,-90) |
| 执行SQL(查询) | 获取已抓取记录 | between语句,like模糊匹配 |
| 抓取网站列表 | 路径参数分页 | /page/${page}/ 路径嵌入 |
| 定义变量 | 双列表协同提取 | 两个selectors并行提取 |
| 输出(双列表) | 调试验证 | 同时输出URL和ID列表 |
| 循环 | 动态循环控制 | list.length(news_urllist) |
| 新闻地址 | 索引关联处理 | 通过index关联两个列表 |
| 抓取新闻详情 | 全流程代理 | 代理IP配置 |
| 内容 | 结构化提取 | 标题/作者/时间/内容 |
| 执行SQL(插入) | 存储数据 | source='bioplasticsnews' |
通过以上设计,该爬虫成功应对了双字段分离存储和路径参数分页的双重挑战,实现了对bioplasticsnews.com新闻网站的高效增量抓取。其中的双列表协同提取、索引关联处理等思路,对于处理复杂HTML结构的爬虫开发具有很高的参考价值。