三月份又过去了一大半,马上接近尾声。这个月又有哪些新冒出的开源项目,有哪些热点出现,又有哪些比较好玩的项目呢?今天给大家做个盘点
1、MoneyPrinter(AI自动化工具)
MoneyPrinterTurbo 是一款功能强大的 AI 工具,支持通过主题或关键词自动生成视频文案、素材、字幕与背景音乐,并合成高清短视频
-
视频文案生成:支持 AI 自动生成文案,也支持用户自定义文案
-
高清视频尺寸:支持竖屏 9:16(1080x1920)和横屏 16:9(1920x1080)
-
批量视频生成:一次生成多个视频,方便用户选择最满意的结果
-
字幕生成:支持调整字体、位置、颜色、大小,并支持字幕描边设置
-
背景音乐:支持随机或指定音乐文件,可调节背景音乐音量
-
多语言支持:支持中文和英文视频文案生成
-
语音合成:支持多种语音合成模式,可实时试听效果
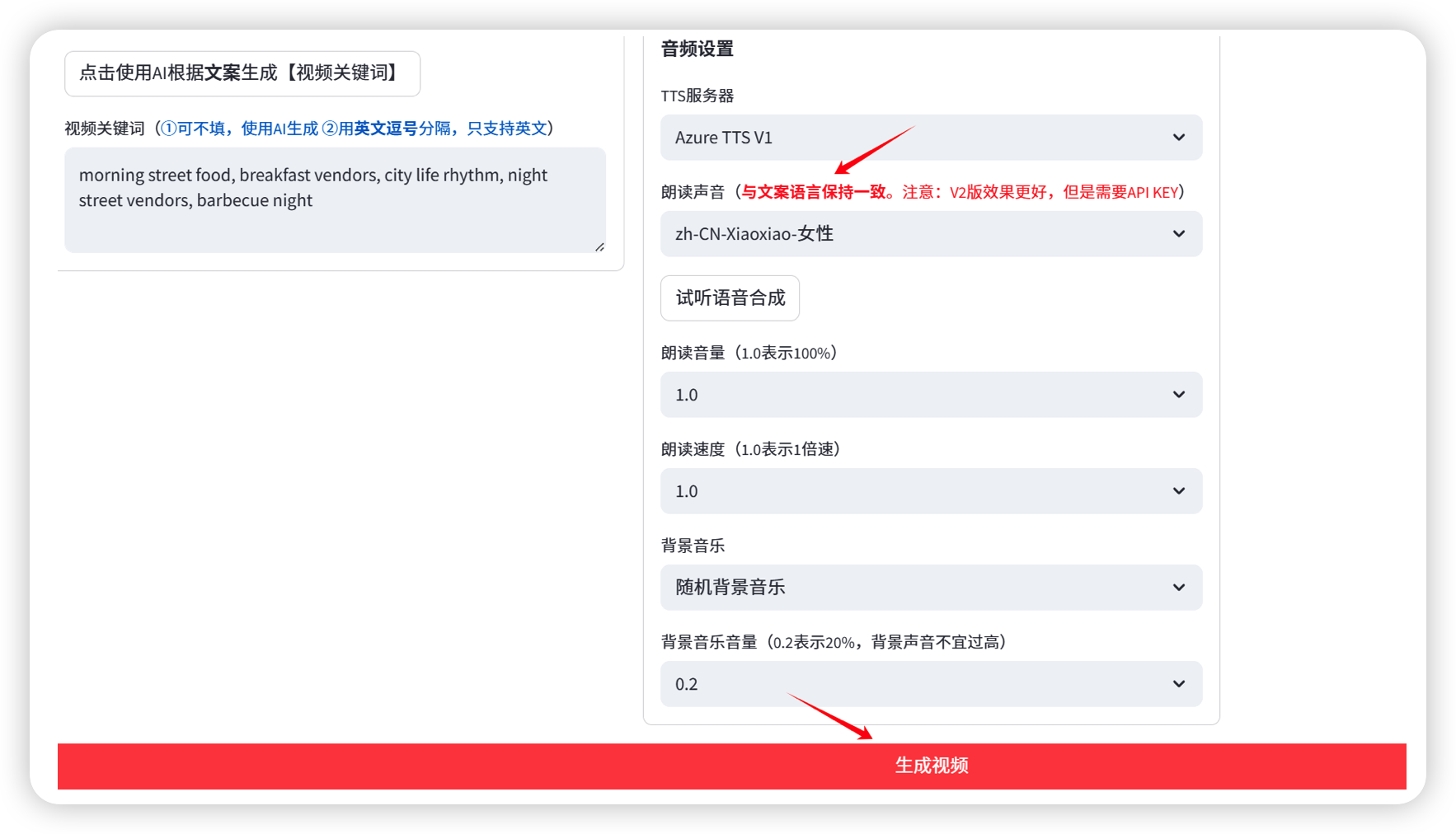
项目地址:https://github.com/FujiwaraChoki/MoneyPrinterV2
2、Project NOMA D(离线生存计算机)
一款火爆 GitHub 的开源离线生存计算机,主打无网环境下的知识与 AI 服务,内置精简维基、教育课程、离线 AI、地图导航、医疗与生存知识库等模块,采用模块化架构可本地部署,兼顾隐私与极端场景可用性,被称作数字末日的 "知识瑞士军刀",上线即快速斩获万星。
项目特点:
根据项目官方介绍,系统整合了多种离线内容与工具,包括通过 Kiwix 提供的离线维基百科与医学资料、通过 Kolibri 提供的可汗学院课程,以及基于 OpenStreetMap 数据的离线地图(需提前按区域下载)。
此外,系统还支持本地运行的AI问答功能,由 Ollama 驱动,并结合向量数据库实现文档检索。
项目地址:https://github.com/Crosstalk-Solutions/project-nomad
3、OpenViking(AI Agent 专用上下文数据库)
字节跳动火山引擎开源的AI Agent 专用上下文数据库,以 "一切皆文件" 为核心,用虚拟文件系统范式统一管理 Agent 的记忆、资源与技能,抛弃传统 RAG 扁平向量存储,支持目录化组织、分层加载与路径式调用,大幅降低 Token 消耗、简化调试与多 Agent 协同,兼容本地 / 云端部署,Apache-2.0 协议开源。
项目特点:
- 文件系统管理范式,实现统一结构化管理,轻松浏览和操作上下文,像管理本地文件一样简单 - L0/L1/L2三层上下文分级加载,按需调用,大幅降低Token消耗 - 目录递归检索策略,结合目录位置和语义搜索,实现更精准、更全局的上下文获取 - 可视化检索轨迹,完整呈现检索过程,方便调试和优化 - 会话自动管理,自动提取长期记忆,Agent能"用得越久越聪明"
支持Python包安装,也有Rust CLI工具;支持多家主流模型提供商,包含Volcengine、OpenAI、Anthropic、本地vLLM等等;同时提供详尽配置示例,轻松上手。
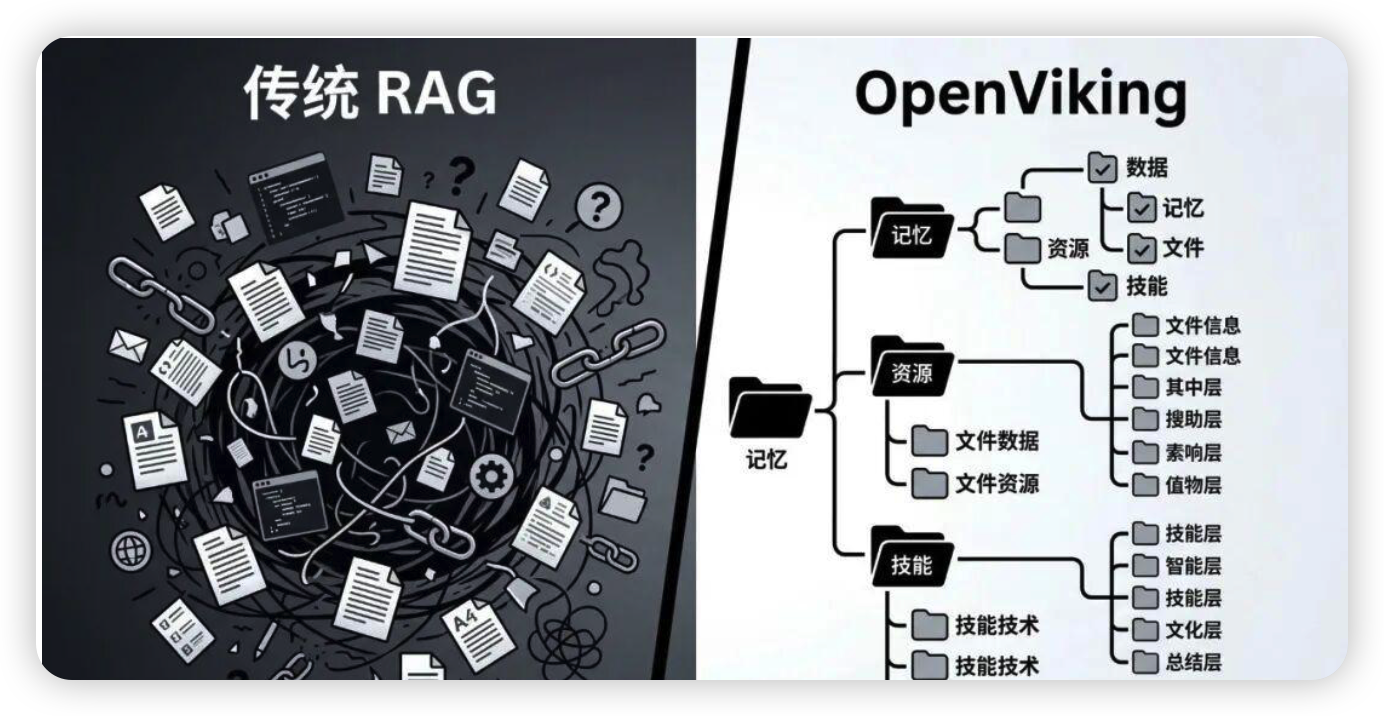
项目地址:github.com/volcengine/OpenVikin
4、deer-flow(超级智能体中枢)
字节跳动开源的超级智能体中枢框架,主打多智能体协同、任务自动拆解与端到端执行,可完成信息检索、代码沙箱运行、报告 / PPT / 播客生成等复杂研究任务,2.0 版本从零重构,支持持久记忆、技能扩展与多模型混用,开箱即用且工程化落地性强,上线即登顶 GitHub Trending。
项目特点:
-
多智能体协同调度,支持多角色智能体分工协作完成复杂任务
-
任务自动拆解与规划,可自主分解复杂研究 / 创作类目标
-
内置信息检索、网页浏览、代码执行等工具链,支持端到端自动执行
-
支持持久化记忆与上下文管理,跨任务保留历史信息
-
灵活接入各类大模型,可自由切换与组合不同模型能力
-
支持插件 / 技能扩展,可按需新增能力模块
-
工程化友好,开箱即用,部署与二次开发成本低
-
可自动生成报告、PPT、文档、播客等多种格式成果
-
支持长流程复杂任务,具备较强的任务容错与重试机制
-
界面简洁易用,支持可视化任务执行与进度查看
简单讲,DeerFlow是字节跳动推出的社区驱动型深度研究框架,基于 LangGraph 打造的模块化多 Agent 系统。
核心就是把大模型和网页搜索、爬虫、Python 代码执行这些实用工具揉在一起,还加了人机协同、私有知识库、多格式内容生成的功能,主打一个让 AI 替你做 "脏活累活",人类聚焦核心思考。
官方给了个在线Demo地址:https://deerflow.tech/

2.0版本则对整体结构进行了全面重构,从底层骨架到上层能力都实现了飞跃。
新版本采用单一主智能体+11 层中间件链+动态子智能体 的全新架构,将核心能力收敛到工具集与中间件链中,让整个系统更轻量、更灵活、更易扩展。
相比1.0需要调整整体结构才能新增能力,2.0只需添加新技能就能完成拓展,无需改动底层框架。
项目地址:https://github.com/bytedance/deer-flow
5、MiroFish(AI数字推演、沙盘)
MiroFish是一款基于AI智能体推演的模拟工具,旨在通过构建虚拟环境来预测现实事件的发展走向。该工具通过输入"现实种子"(如政策草案、营销方案等),自动提取关键信息并生成具有独立人格和行为逻辑的AI智能体,在虚拟环境中进行互动,从而输出预测报告。
-
核心机制 构建高保真虚拟环境,模拟智能体互动及"蝴蝶效应",支持中途加入变量
-
实测数据 在模拟舆情发酵、用户行为及政策影响方面,官方数据显示准确率可达75%以上
-
适用场景 自媒体选题反应预判、职场方案推演、舆情应对模拟、商业决策风险评估
-
使用门槛 无需代码基础,支持本地部署,数据隐私有保障
3月7日,MiroFish登上全球最大的软件项目托管平台GitHub全球趋势榜第一位置;两天后,项目星标数突破1万,这意味着它已跻身GitHub所有开源项目的前5%,进入"精英俱乐部"。
项目地址:https://github.com/666ghj/MiroFish
6、Lightpanda-browser
一款用 Zig 语言从零构建 的开源无头浏览器 ,专为 AI 代理、LLM 训练、网页抓取与自动化测试设计。它基于 V8 引擎支持完整 JS 执行与 DOM 操作,兼容 Playwright、Puppeteer 等工具的 CDP 协议,内存占用仅为 Chrome 的 1/9、执行速度快 11 倍、启动瞬间完成。项目以 AGPL‑3.0 开源,提供单一二进制与 Docker 部署,无图形渲染开销。
项目地址:https://github.com/lightpanda-io/browser
7、Scrapling
一款面向现代网页的Python 自适应爬虫框架,核心解决网页改版失效与反爬拦截难题,内置智能元素追踪算法,可在 HTML 结构变化时自动重定位目标数据,搭配 StealthyFetcher 模块模拟真实浏览器指纹,高效绕过 Cloudflare 等反爬系统;支持动态 JS 渲染、高并发采集与断点续爬,提供简洁 API 与命令行工具,轻量化易上手,还可对接 AI 智能体做自动化数据提取,兼顾稳定性、易用性与工程化能力。
用OpenClaw挂机,抓取网页时频频翻车的烦人bug终于有解了,这个名为Scrapling的数据采集神器,几乎一夜之间就成了OpenClaw的"最强外挂"。
性能数据:
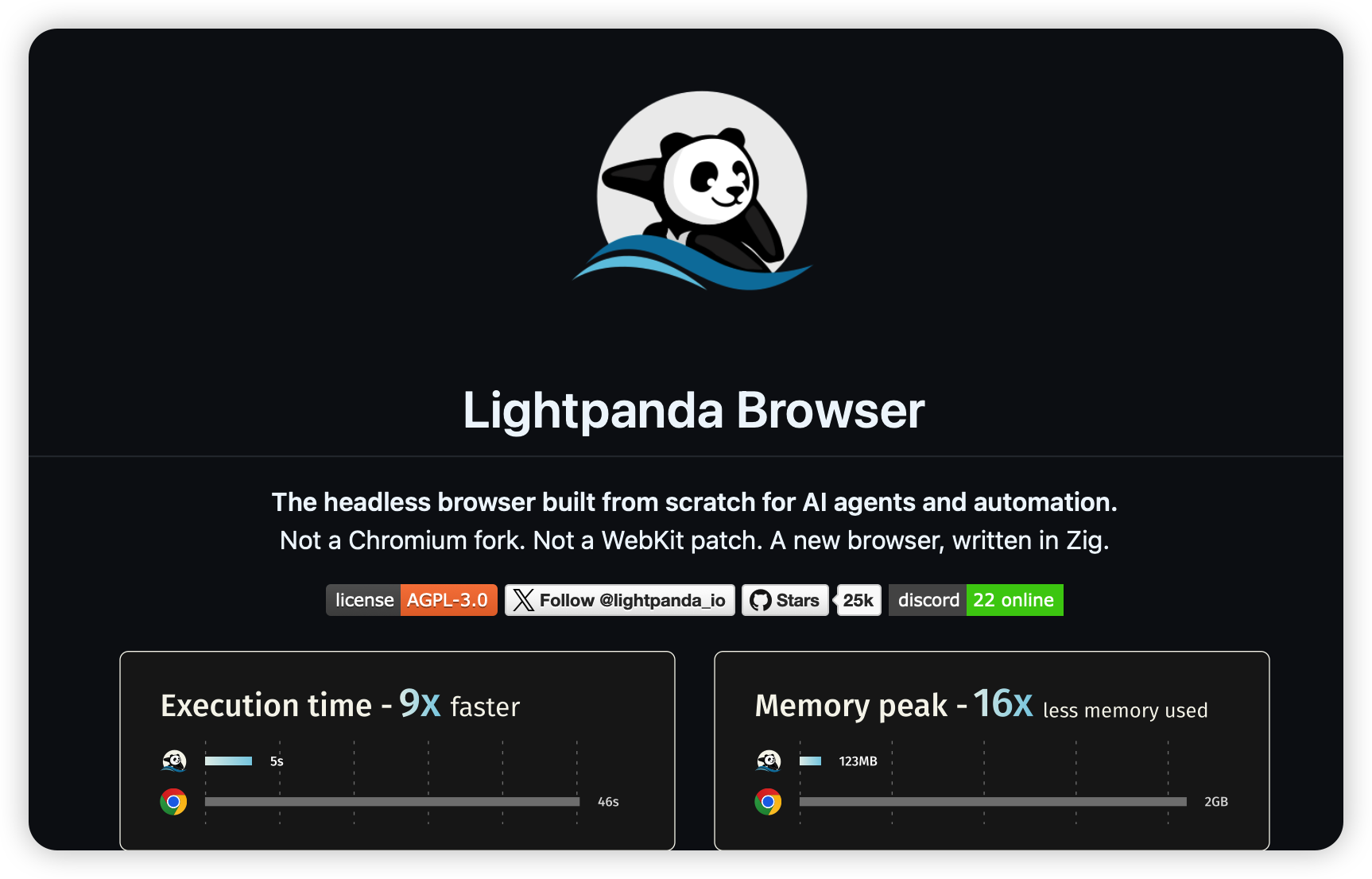
项目地址:https://github.com/D4Vinci/Scrapling
8、worldmonitor(全球实时情报)
一个很有意思的项目
AI 驱动的开源全球实时情报仪表盘,聚合 400 + 公开数据源,在 3D 地球 / 2D 地图上直观呈现地缘冲突、军事动态、基础设施、灾害预警与金融市场态势;支持 Ollama 本地大模型生成智能简报,提供 Tauri 桌面客户端与网页版,可自定义区域监控、关键词过滤与风险预警,被称作开源版全球态势感知中心,适合情报分析、研究与风险监控场景。
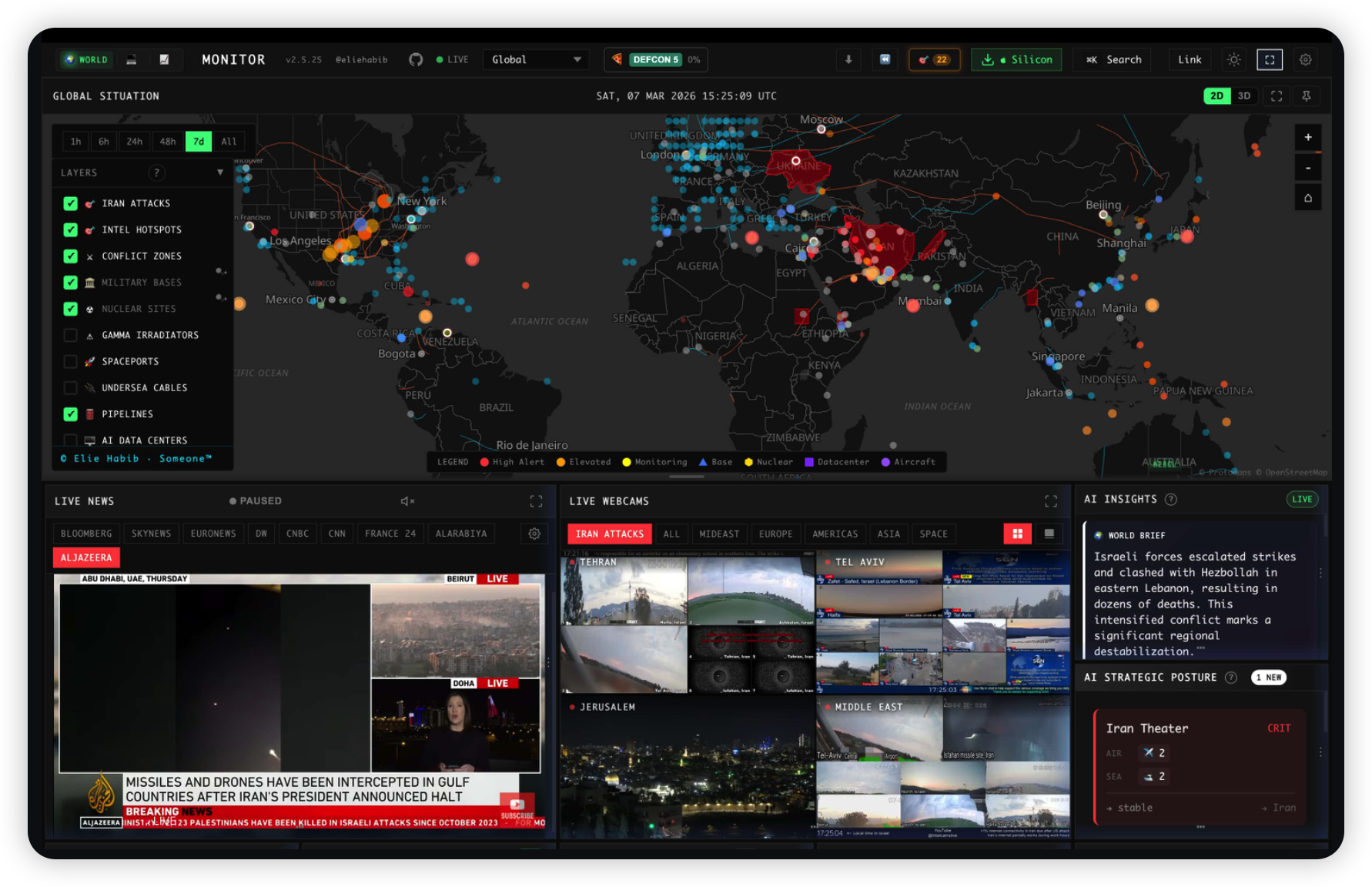
项目地址:https://github.com/koala73/worldmonitor
9、superpowers(AI 编程工作流)
爆款开源AI 编程 Agent 工程化工作流框架,专为 Claude Code 等编码助手设计,以 20 + 可组合 Skills 强制 AI 先规划设计、再 TDD 开发、后代码审查,覆盖需求梳理、架构拆分、分支管理、迭代交付全流程,告别随机写码,输出工程规范级代码;MIT 协议开源,支持本地部署与多 AI 助手适配,是提升 AI 编程可靠性与规模化交付的核心工具。
一套为 AI 编程代理设计的"操作系统",包含 14 个可组合的技能模块,覆盖从需求澄清到代码上线的完整开发流程。
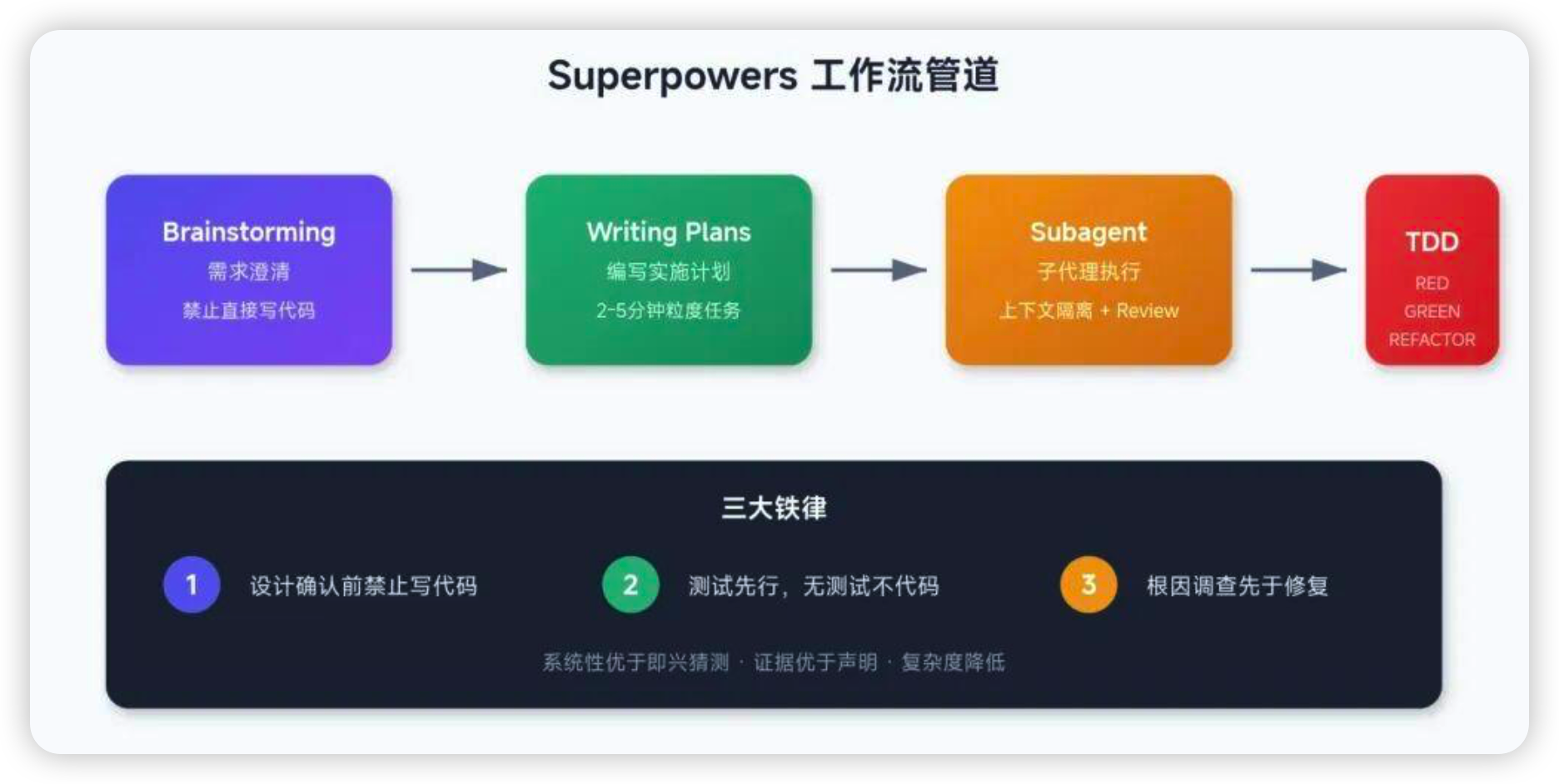
功能特点:
1. 标准化开发工作流(强制 AI 走正规工程流程)
框架内置固定开发链路,AI 必须按步骤执行,不能跳过、不能乱写:
-
需求拆解:自动把模糊需求拆分成清晰的开发任务、用户故事
-
架构设计:先出技术方案、模块划分、目录结构、依赖关系
-
TDD 测试驱动开发 :先写测试用例,再写功能代码,保证代码质量
-
迭代编码:分模块、分文件编写,保持代码结构清晰
-
代码审查:AI 自动自查代码,修复 bug、优化逻辑、补充注释
-
版本管理:自动生成 Git 提交信息、分支策略
2. 20+ 可组合技能库(Skills)
提供开箱即用的专业开发能力,AI 可直接调用:
-
代码生成、重构、优化、注释补全
-
单元测试 / 集成测试编写
-
项目结构搭建、依赖管理
-
文档生成、API 接口定义
-
错误排查、性能分析
-
Git 操作、部署脚本生成
3. 多模型兼容
不绑定单一 AI,支持主流编程大模型:
-
原生适配 Claude 3/4 Code
-
兼容 GPT-4、DeepSeek-Coder、通义千问等编程助手
4. 工程化约束规则
从根源解决 AI 代码不规范问题:
-
强制统一代码风格、命名规范
-
禁止硬编码、冗余代码、不安全实现
-
保证代码可维护、可扩展、可测试
-
输出企业级可直接上线的代码产物
项目地址:https://github.com/obra/superpowers
10、everything-claude-code
一个专为 Claude Code 打造的超全工程化指令集 / 工作流合集,整合了高质量提示词、开发模板、规范约束与最佳实践,覆盖前端、后端、AI、脚本、文档等全场景开发;能让 Claude Code 自动遵循软件工程标准,完成需求拆解、架构设计、TDD 开发、代码审查、部署上线全流程,大幅提升 AI 编码的规范性、可靠性与交付效率,无需复杂配置即可直接复用。
核心使用场景:个人 / 团队用 AI 快速从零搭建项目、重构维护旧代码、生成企业级规范代码、自动化完成全栈开发与文档编写,是提升 AI 编程效率的必备工具库。
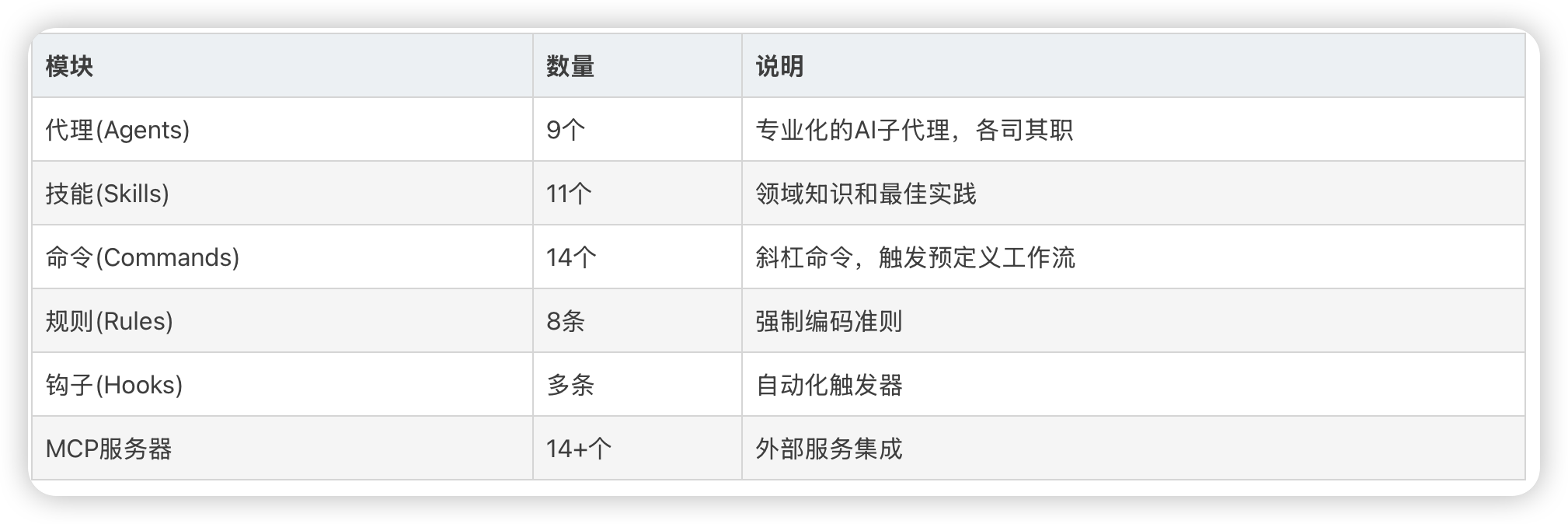
以Agent为例,每个 Agent 只做一件事,并且做到最好。不同工作由不同Agent负责,分工明确
| 场景 | 对应 Agent |
|---|---|
| 规划新功能 | planner |
| 系统架构决策 | architect |
| 测试驱动开发 | tdd-guide |
| 代码质量审查 | code-reviewer |
| 安全漏洞扫描 | security-reviewer |
| 构建错误修复 | build-error-resolver |
| Go 代码审查 | go-reviewer |
| PyTorch 训练错误 | pytorch-build-resolver |
| Kotlin/Android 构建 | kotlin-build-resolver |
GitHub 地址 :https://github.com/obra/everything-claude-code