动手学深度学习------实战 Kaggle 比赛:预测房价,从零理解完整流程
一、前言
学深度学习时,前面我们经常在做一些相对"标准化"的任务,比如:
-
识别图片
-
分类文本
-
搭建全连接网络
-
理解卷积和激活函数
但真正到了实际项目或者比赛中,问题就没有那么"规整"了。
尤其是像 Kaggle 这样的数据竞赛平台,给你的往往不是已经处理好的训练样本,而是一份带有大量特征、缺失值、类别字段、数值字段混杂在一起的原始表格数据。
这时候,真正考验人的就不只是"会不会写网络",而是:
-
会不会读懂数据
-
会不会做特征预处理
-
会不会处理缺失值
-
会不会标准化数值
-
会不会把类别特征变成模型能吃的形式
-
会不会设计训练集和验证集
-
会不会根据比赛评价指标来调整模型
李沐老师《动手学深度学习》中的 "实战 Kaggle 比赛:预测房价" ,就是一个非常经典的入门案例。
它用一个真实比赛任务,带我们完整走了一遍:
从读取数据,到预处理特征,到训练模型,再到生成提交文件的完整流程。
这一节非常适合初学者,因为它不像前面那些纯理论章节那么抽象,而是更接近"真实机器学习项目"。
二、这节课到底在做什么
这一节课的任务很明确:
根据房屋的各种属性信息,预测房子的销售价格。
也就是说,这是一个回归问题,不是分类问题。
输入可能包括很多特征,例如:
-
房屋面积
-
建造年份
-
地下室面积
-
房间数量
-
所在区域
-
是否有车库
-
外墙材料
-
地段条件
-
装修情况
输出则是一个连续值:
- 房价
SalePrice
所以本质上,这是在做:
\\text{根据房屋特征} \\rightarrow \\text{预测最终价格}
三、为什么这个案例很重要
我觉得这个案例特别适合刚学完基础神经网络的人,原因有三个。
1. 它非常接近真实数据分析任务
前面很多练习都是已经整理好的数据集,但 Kaggle 比赛里的表格数据通常更"脏":
-
有缺失值
-
有字符串类别
-
有数值尺度差异
-
有训练集和测试集字段不完全一致的问题
这才是真实任务里经常会遇到的情况。
2. 它把"数据预处理"的重要性体现得非常明显
很多初学者一说深度学习,就立刻开始搭模型。
但在这个案例里你会发现:
模型本身并不复杂,真正重要的反而是前面的数据处理。
也就是说,比赛不只是比谁网络深,很多时候比的是:
-
特征工程
-
数据清洗
-
评价指标理解
-
训练细节控制
3. 它让我们第一次接触完整比赛流程
这一节不是单独讲某个知识点,而是在教我们如何把前面学过的内容串起来:
-
线性回归
-
损失函数
-
数据加载
-
训练循环
-
验证评估
-
结果提交
学完之后,你会对"怎么从 0 做一个机器学习项目"有更直观的认识。
四、这是一个什么类型的问题
房价预测本质上是一个监督学习中的回归任务。
1. 为什么是监督学习
因为我们有一批历史房屋数据,并且知道它们对应的真实售价。
也就是每个样本都带有标签。
2. 为什么是回归
因为输出不是类别,而是一个连续实数,比如:
-
120000
-
235500
-
486000
所以不是判断"属于哪一类",而是预测一个数值。
五、Kaggle 比赛的基本结构
Kaggle 这类比赛通常会给我们几个文件:
1. train.csv
训练集,里面有:
-
各种特征
-
目标值
SalePrice
2. test.csv
测试集,里面有:
-
各种特征
-
但是没有
SalePrice
因为这个价格需要我们自己预测。
3. sample_submission.csv
提交样例,告诉我们最后应该按什么格式生成结果文件。
通常需要提交一个 CSV 文件,里面包含:
-
Id -
SalePrice
六、这个案例的难点不在模型,而在数据
这一点非常关键。
很多人一看到"预测房价",第一反应就是:
要不要上很复杂的深度网络?
但实际上,在这个案例里,真正的重点不是堆复杂模型,而是把数据处理好。
因为原始表格数据会有很多问题:
1. 数值特征和类别特征混在一起
比如:
-
LotArea是数值 -
Neighborhood是类别 -
HouseStyle是类别 -
YearBuilt虽然是数字,但也带有时间意义
模型不能直接吃字符串,所以类别特征必须转换。
2. 存在大量缺失值
并不是每个房子都有所有字段。
比如:
-
有的没有车库
-
有的没有地下室
-
有的没有泳池
-
某些记录压根就没填
如果不处理缺失值,模型通常无法正常训练。
3. 特征尺度差异很大
比如:
-
房屋面积可能是几百到几千
-
房间数可能是 1 到 10
-
年份可能是 1900 到 2010
如果不标准化,某些数值大的特征会在训练中占据更强影响。
七、这一节的整体流程
整个房价预测案例,大体可以分成下面几个步骤:
1. 读取训练集和测试集
先把 CSV 文件读进来。
2. 合并训练特征和测试特征
为了让预处理过程保持一致,通常会把二者的特征拼接起来一起处理。
3. 处理数值特征
对数值特征做标准化,并处理缺失值。
4. 处理类别特征
对字符串类别做 one-hot 编码。
5. 划分训练特征和测试特征
处理完之后再拆回训练集和测试集。
6. 训练模型
使用线性回归模型或者简单神经网络。
7. 验证模型效果
通常使用对数均方根误差等指标。
8. 生成预测结果并提交 Kaggle
将测试集预测值写入 CSV 文件。
八、为什么要把训练集和测试集特征合并处理
这是这节课里非常重要的一个操作。
很多人会疑惑:
为什么不分别处理训练集和测试集?
原因在于:
如果你分别独立做 one-hot 编码,可能会出现字段不一致的问题。
举个例子:
训练集里 Neighborhood 有:
-
A
-
B
-
C
测试集里 Neighborhood 有:
-
A
-
C
-
D
如果分别编码,最后得到的列可能不同。
这样训练出来的模型就没法直接用于测试集。
所以更稳妥的做法是:
先把训练集和测试集的特征合并,再统一做预处理。
这样处理完后,二者的列结构就一致了。
九、数值特征如何处理
1. 标准化
数值特征通常需要做标准化:
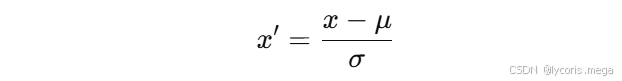
也就是:
-
减去均值
-
除以标准差
这样做的好处是:
-
不同特征尺度更加统一
-
训练更稳定
-
优化更容易收敛
2. 缺失值处理
标准化后,如果有缺失值,通常会用 0 填充。
为什么可以用 0?
因为标准化后,数据大致围绕 0 分布。
这时用 0 填补,某种程度上相当于用"平均水平"进行补全。
十、类别特征如何处理
类别特征通常是字符串,比如:
-
Neighborhood -
Exterior1st -
MSZoning
神经网络和线性模型都不能直接处理字符串,所以要转成数值形式。
最常用的方法就是:
独热编码(one-hot encoding)
例如某个字段有三种取值:
-
A
-
B
-
C
那么它会变成三列:
-
是否为 A
-
是否为 B
-
是否为 C
这样,原本的类别字段就转成了模型可以处理的 0/1 特征。
十一、为什么房价预测常用对数误差
这一点很关键,也是 Kaggle 比赛思维的体现。
房价这个目标值通常跨度很大:
-
便宜房可能十几万
-
贵一点的可能几十万
-
豪宅可能上百万
如果直接用普通均方误差,大价格样本会主导损失。
而比赛更关注相对误差,所以经常使用:
对数均方根误差(RMSE on log scale)
也就是先对预测值和真实值取对数,再计算误差。
这样有几个好处:
1. 降低极大值的影响
高价房不会过度支配整体损失。
2. 更符合"相对误差"的直觉
预测 10 万差 1 万,和预测 100 万差 10 万,虽然绝对误差不同,但相对误差其实类似。
3. 让目标值分布更平稳
很多经济类数据本身就更适合取对数处理。
十二、这一节为什么先从线性模型做起
有同学会觉得:
都学深度学习了,为什么还在线性回归这里绕?
其实这是很合理的。
因为在这个比赛中,输入是结构化表格数据,特征工程做好之后,线性模型本身就能有不错效果 。
这说明:
数据处理往往比盲目堆复杂网络更重要。
而且从学习角度看,先用简单模型有几个优势:
1. 更容易排查问题
如果结果差,可以先看是不是预处理出了问题。
2. 更容易理解完整流程
从简单模型入手,能先把比赛框架跑通。
3. 能建立基线
后面你再换更复杂模型,才知道有没有真正提升。
十三、交叉验证为什么重要
在比赛中,只看训练误差是没有意义的。
因为训练误差低,不代表泛化能力强。
所以我们通常会做 K 折交叉验证。
1. 基本思想
把训练集分成 K 份:
-
每次拿 1 份做验证集
-
剩下 K-1 份做训练集
-
重复 K 次
-
最后取平均结果
这样可以更稳定地评估模型泛化能力。
2. 为什么很适合 Kaggle
因为 Kaggle 的测试集没有标签,我们看不到真正成绩。
所以只能依靠本地验证集评估模型好坏。
如果交叉验证做得稳,通常线上分数也更靠谱。
十四、这个案例教会我们的,不只是"预测房价"
我觉得这一节真正的价值,不只是会了一个房价预测任务,而是第一次理解了:
一个真实机器学习问题,到底应该怎么落地。
它让我们知道,一个完整项目通常不是"上来先写模型",而是:
1. 先看数据是什么样
是图像、文本还是表格。
2. 再看特征类型
数值、类别、缺失值各怎么处理。
3. 再决定模型
简单模型先跑通,再逐步优化。
4. 最后根据评价指标调参
不是你觉得好就算好,而是比赛指标说了算。
这种思路比单纯记几个 API 重要得多。
十五、PyTorch 实战代码示例
下面给你一版适合放 CSDN 的基础代码,风格尽量清晰,方便你学习和讲解。
import torch
from torch import nn
import pandas as pd
import numpy as np
# 1. 读取数据
train_data = pd.read_csv('train.csv')
test_data = pd.read_csv('test.csv')
# 2. 去掉第一列 Id,并合并训练集和测试集的特征
all_features = pd.concat((train_data.iloc[:, 1:-1], test_data.iloc[:, 1:]))
# 3. 处理数值特征:标准化
numeric_features = all_features.dtypes[all_features.dtypes != 'object'].index
all_features[numeric_features] = all_features[numeric_features].apply(
lambda x: (x - x.mean()) / x.std()
)
# 4. 标准化后将缺失值填为 0
all_features[numeric_features] = all_features[numeric_features].fillna(0)
# 5. 处理类别特征:one-hot 编码
all_features = pd.get_dummies(all_features, dummy_na=True)
# 6. 转成张量
n_train = train_data.shape[0]
train_features = torch.tensor(all_features[:n_train].values, dtype=torch.float32)
test_features = torch.tensor(all_features[n_train:].values, dtype=torch.float32)
train_labels = torch.tensor(
train_data.SalePrice.values.reshape(-1, 1), dtype=torch.float32
)
# 7. 定义模型
loss = nn.MSELoss()
in_features = train_features.shape[1]
def get_net():
net = nn.Sequential(nn.Linear(in_features, 1))
return net
# 8. 对数均方根误差
def log_rmse(net, features, labels):
clipped_preds = torch.clamp(net(features), 1, float('inf'))
rmse = torch.sqrt(loss(torch.log(clipped_preds), torch.log(labels)))
return rmse.item()
# 9. 训练函数
def train(net, train_features, train_labels, test_features, test_labels,
num_epochs, learning_rate, weight_decay, batch_size):
train_ls, test_ls = [], []
dataset = torch.utils.data.TensorDataset(train_features, train_labels)
train_iter = torch.utils.data.DataLoader(dataset, batch_size, shuffle=True)
optimizer = torch.optim.Adam(net.parameters(),
lr=learning_rate,
weight_decay=weight_decay)
for epoch in range(num_epochs):
for X, y in train_iter:
optimizer.zero_grad()
l = loss(net(X), y)
l.backward()
optimizer.step()
train_ls.append(log_rmse(net, train_features, train_labels))
if test_labels is not None:
test_ls.append(log_rmse(net, test_features, test_labels))
return train_ls, test_ls
# 10. 开始训练
net = get_net()
train_ls, _ = train(net, train_features, train_labels, None, None,
num_epochs=100, learning_rate=5, weight_decay=0, batch_size=64)
print("训练 log rmse:", train_ls[-1])
# 11. 预测并生成提交文件
preds = net(test_features).detach().numpy()
test_data['SalePrice'] = pd.Series(preds.reshape(1, -1)[0])
submission = pd.concat([test_data['Id'], test_data['SalePrice']], axis=1)
submission.to_csv('submission.csv', index=False)
print("提交文件已生成!")十六、代码核心逻辑讲解
这段代码虽然不长,但已经完整体现了 Kaggle 表格比赛的基本套路。
1. pd.concat() 合并特征
确保训练集和测试集做一致预处理。
2. numeric_features
选出数值列,只对数值特征做标准化。
3. fillna(0)
处理缺失值。
4. pd.get_dummies()
对类别变量做独热编码。
5. torch.tensor()
把处理后的表格转成神经网络可以训练的张量。
6. nn.Linear(in_features, 1)
本质上就是一个线性回归模型。
7. log_rmse()
按照比赛常用评价方式来评估模型。
8. submission.to_csv()
生成最终提交文件。
十七、这一节最值得学的几个思想
我觉得这节课最重要的,不是背代码,而是理解下面几个思想。
1. 先处理数据,再谈模型
真实问题里,数据质量往往比模型结构更关键。
2. 表格数据不一定需要很深的网络
在很多结构化数据任务上,简单模型也可能效果不错。
3. 评价指标决定优化方向
比赛看什么指标,你就必须围绕那个指标设计训练和验证。
4. 交叉验证很重要
没有好的本地验证,线上成绩往往靠运气。
5. 机器学习项目是完整流程,不只是一个模型
真正的项目思维应该包括:
-
数据读取
-
预处理
-
特征转换
-
建模
-
验证
-
提交
十八、我对这一节的理解
学完这一节后,我最大的感受是:
以前觉得"做比赛"很高深,好像一定要特别复杂的模型。
但这个案例让我明白,入门 Kaggle 最重要的不是一上来追求花哨,而是先把最基础的流程打通。
尤其是表格数据任务,很多时候真正决定上限的,是:
-
数据预处理做得细不细
-
缺失值处理得合不合理
-
类别特征编码方式是否统一
-
验证方案是否稳妥
所以这一节的意义,不只是学会了"预测房价",而是让我第一次真正理解了:
深度学习和机器学习在真实任务中,到底是怎么一步一步落地的。
十九、结语
"实战 Kaggle 比赛:预测房价" 是《动手学深度学习》里非常经典的一节。
它不像前面那些章节主要讲原理,而是更偏向完整项目实战。
通过这一节,我们可以学到:
-
如何处理真实表格数据
-
如何统一处理训练集和测试集
-
如何做数值特征标准化
-
如何做类别特征 one-hot 编码
-
如何理解 Kaggle 的评价指标
-
如何生成提交文件
对于刚入门比赛或者机器学习实战的同学来说,这一节非常有价值。
因为它让我们从"会写模型"进一步走向"会做项目"。
二十、重点速记版
1. 这是分类还是回归
是回归,因为预测的是连续房价。
2. 这个案例最关键的是什么
不是复杂模型,而是数据预处理。
3. 为什么合并训练集和测试集特征
为了保证预处理后列结构一致。
4. 数值特征怎么处理
标准化,再填充缺失值。
5. 类别特征怎么处理
one-hot 编码。
6. 为什么用对数误差
因为房价跨度大,对数形式更稳定,也更符合相对误差直觉。
7. 为什么交叉验证重要
因为测试集没标签,只能靠本地验证评估泛化能力。