在你每天登录 B站、腾讯视频的时候,有没有想过一个问题:
👉 为什么你关闭浏览器之后,再打开居然不用重新登录?
👉 又为什么,有些网站一旦 Cookie 被偷,就能"免密登录"?
更可怕的是------
如果有人拿到了你的 Cookie,他甚至可以直接冒充你登录账号。
这背后,其实涉及三个核心知识:
- Cookie(身份凭证)
- Session(服务端身份管理)
- HTTPS(真正的安全保障)
今天这篇博客,直接从"中间人视角"来了解一下整个流程。
Cookie
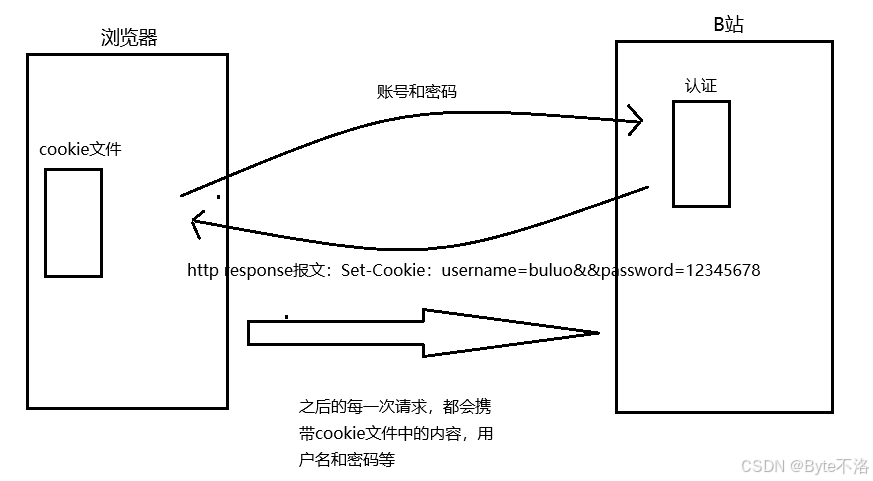
现在我们通过生活中的例子进行理解cookie,相信大家在网页中登录B站,或则腾讯视频等等网页的时候,一般都需要我们进行账号登录,我们完成账号登录之后就可以对其进行访问了,但是当我们访问完成之后,将其关闭,在一段时间内如果我们重新登录,我们就不需要再进行账号登录,可以直接使用,这是怎么做到的呢,这其实就是HTTP会对登录用户的会话具有保持的功能,具体情况就是如下:
-
浏览器发送请求(带用户名+密码)
-
B站服务器认证
-
服务器返回:
Set-Cookie: username=bulouo&password=12345678
-
浏览器保存 Cookie
-
后续请求自动携带 Cookie(用户名+密码)
我们也可以通过我们上一篇博客中的代码进行验证,只在响应报文中的报头中增加Set-Cookie: username=bulouo&password=12345678
class HttpServer
{
public:
HttpServer(uint16_t port, std::string ip)
: port_(port), ip_(ip)
{
}
void Init()
{
listenfd_.Init();
listenfd_.Bind(port_, ip_);
listenfd_.Listen();
}
void start()
{
while (1)
{
uint16_t client_port;
std::string client_ip;
int sockfd = listenfd_.Accept(&client_port, &client_ip);
if (sockfd < 0)
{
continue;
}
ThreadData *td = new ThreadData(sockfd, this);
pthread_t tid;
pthread_create(&tid, nullptr, ThreadRun, td);
}
}
static void *ThreadRun(void *arg)
{
pthread_detach(pthread_self());
ThreadData *td = (ThreadData *)arg;
td->ts_->HttpHandler(td->sockfd_);
delete td;
return nullptr;
}
std::string ReadHtmlContent(std::string &htmlpath)
{
std::string content;
std::ifstream in(htmlpath.c_str());
if (!in.is_open())
{
return "404";
}
std::string line;
while (std::getline(in, line))
{
content += line;
}
in.close();
return content;
}
void HttpHandler(int sockfd)
{
char buffer[1024];
ssize_t s = read(sockfd, buffer, sizeof buffer - 1);
std::string request;
if (s > 0)
{
buffer[s] = 0;
std::cout << buffer << std::endl;
request = buffer;
std::vector<std::string> req_header;
while (!request.empty())
{
ssize_t pos = request.find("\r\n", 0);
if (pos == std::string::npos)
{
break;
}
std::string line = request.substr(0, pos);
if (line.empty())
{
break;
}
req_header.push_back(line);
request.erase(0, pos + 2);
}
std::stringstream ss(req_header[0]);
std::string method;
std::string url;
std::string http_version;
ss >> method >> url >> http_version;
//std::cout << "method:" << method << "url:" << url << "httpversion" << http_version << std::endl;
std::string path = url;
if (path == "/" || path == "/index.html")
{
path = wwwroot + "/index.html";
}
else
{
path = wwwroot + url;
}
std::string text = ReadHtmlContent(path);
std::string response;
if (text == "404")
{
std::string body = "<h1>404 Not Found</h1>";
response = "HTTP/1.0 404 Not Found\r\n";
response += "Content-Length: " + std::to_string(body.size()) + "\r\n";
response += "Content-Type: text/html\r\n";
response += "\r\n";
response += body;
}
else
{
response = "HTTP/1.0 200 OK\r\n";
response += "Content-Length: " + std::to_string(text.size()) + "\r\n";
response += "Content-Type: text/html\r\n";
response += "Set-Cookie: name=buluo&&password=12345678\r\n";
response += "\r\n";
response += text;
}
write(sockfd, response.c_str(), response.size());
}
close(sockfd);
}
~HttpServer()
{
}
private:
Socket listenfd_;
uint16_t port_;
std::string ip_;
};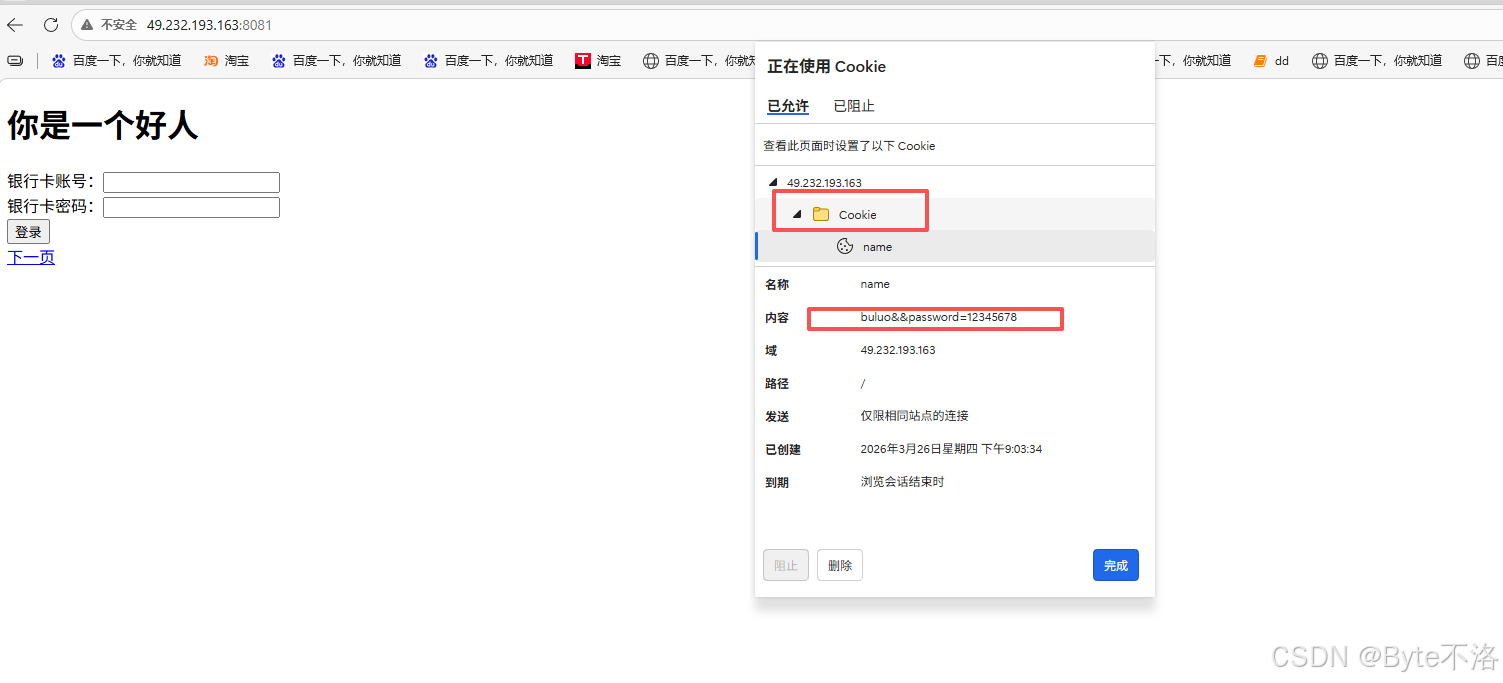
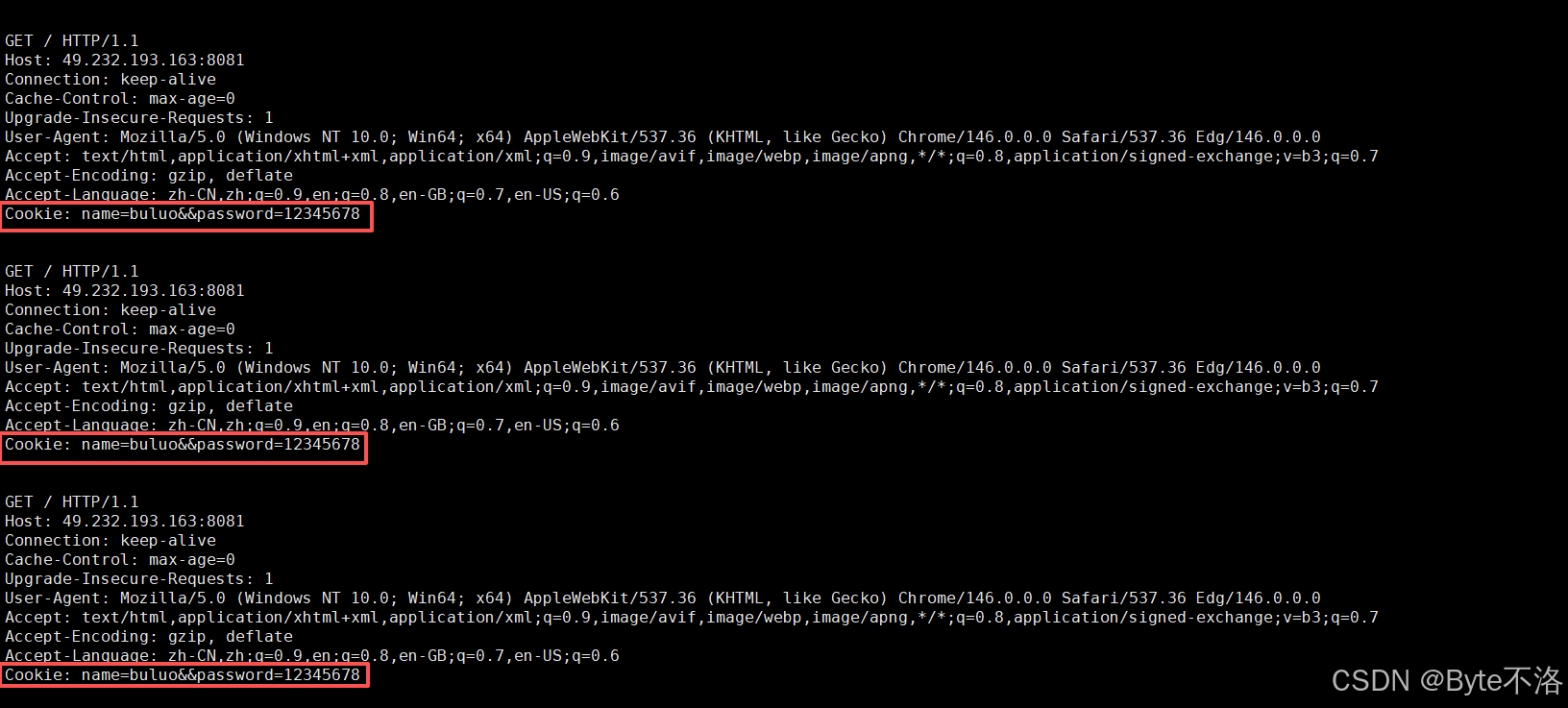
从结果来看,我们的浏览器就将我们的登录信息保存到了cookie文件中,并且当我们再次进行访问服务器时,会在请求报头中增加一个Cookie字段,通过这样的方式,我们就可以在一次登录之后的一段时间内,可以直接访问服务器,不需要再进行身份验证。
这就是Cookie的作用。现在我们通过这个内容结合一个例子引出我们今天的主要内容。
在一个月黑风高的夜晚,你闲来无事,一不小心打开一些视频网站进行学习,在你学习的过程中,这些网站的程序员就很有可能会在你的电脑上种植一些木马病毒,这些人就有可能在你的电脑上启动一些软件,这些软件就有可能会全文式的扫描你的浏览器中的cookie文件,一旦就你的cookie文件拿走之后,他一旦通过这个cookie文件和你访问同一个网页,就有可能直接就免密登录,甚至通过cookie文件,我们一些个人信息就被泄漏了,那么这样的情况该如何解决呢?
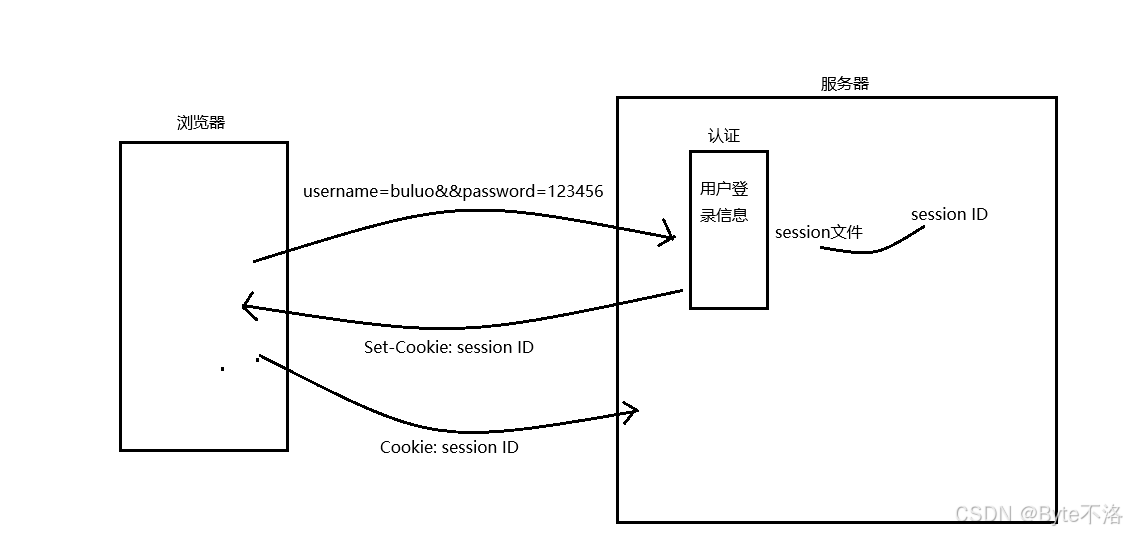
正确流程是这样子的:
-
浏览器发送:
username + password
-
服务器认证成功后:
- 生成 session_id
- 在服务器保存 session(session文件/内存/数据库),将用户信息内容保存在其中
-
返回给用户:
Set-Cookie: session_id
-
浏览器保存 Cookie
-
后续请求:
Cookie: session_id
-
服务器通过 session_id 找到用户,一旦如果错误,就会要求用户重新进行登录验证
这样就保护了我们的个人信息不再泄漏,即使黑客再次拿到我们的cookie文件,cookie中只会有一个session_id ,这样就确保了我们个人信息的安全,至于黑客拿到我们的cookie文件想要获取我们的密码,就让这些黑客去和服务器的程序员进行battle吧,这样就不需要我们普通人进行担心了。
虽然通过这样的方式保证了我们的个人信息不会轻易泄漏,但是我们的http是明文进行传输的,我们通过POST方法传输我们的账号信息时,对于小白来讲不懂,但是对于稍微懂一点的程序员都知道,账号信息其实就在请求报文中的正文部分,所以这样明文传送的方式,是很容易让其它人抓包然后获取到的,所以http是不安全的,所以为了安全起见,就会有另一个协议的诞生,就是HTTPS
HTTPS是什么
HTTPS也是一个应用层协议,就是在HTTP协议的基础上引入一个加密层。
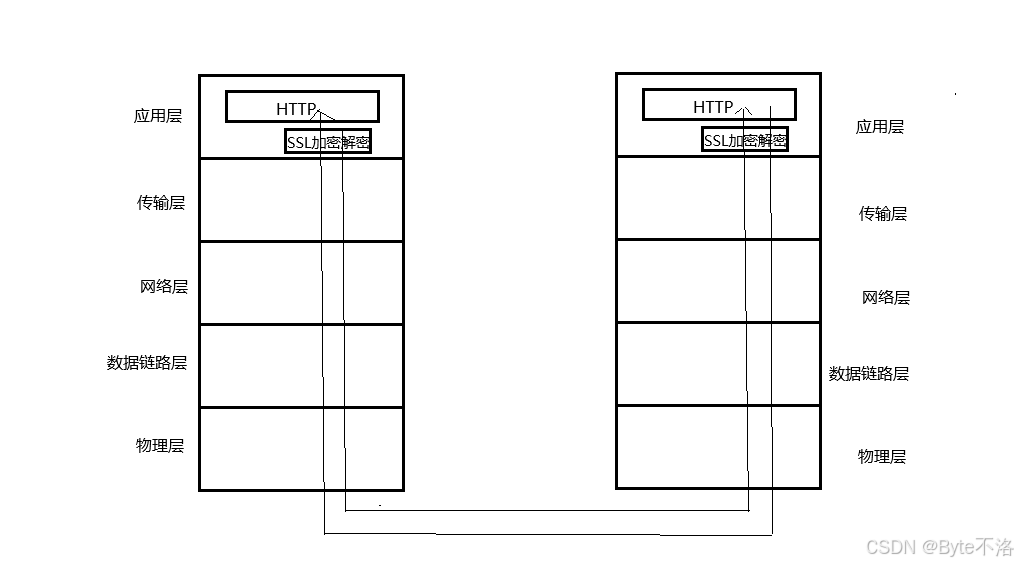
这张图本质上展示的是 HTTPS 的分层结构和数据传输过程。HTTPS 并不是替代 HTTP,而是在应用层的 HTTP 与传输层的 TCP 之间加入了一层 SSL/TLS 加密层。具体来说,客户端在发送请求时,首先由 HTTP 生成明文请求数据,然后交由 SSL/TLS 层进行加密处理,加密后的数据再通过 TCP 在网络中传输;服务器接收到数据后,先由 TCP 层接收密文,再交给 SSL/TLS 层进行解密,还原出原始的 HTTP 请求,随后服务器处理请求并生成 HTTP 响应,同样经过 SSL/TLS 加密后再通过 TCP 发送给客户端,客户端再进行解密得到最终内容。也就是说,HTTP 负责定义"传输什么内容",而 SSL/TLS 负责保证"如何安全传输",因此在网络中实际传输的始终是加密后的密文,从而有效防止数据被窃取或篡改。这也意味着,即使在使用 Cookie 和 Session 机制的情况下,只有在 HTTPS 环境下,这些敏感信息才能在传输过程中得到真正的安全保障。
什么是加密和解密
加密就是把要传输的明文内容进行一系列的变化,生成密文。
解密就是把密文再进行一系列的变化,还原为明文。
在这个加密和解密的过程中,往往需要一个或者多个中间的数据进行辅助这个过程,这样的数据称为密钥
这个是什么意思呢?举一个简单的例子就明白了。
假设我想向另一个人发送数字 7(明文),但我们事先约定了一种规则:所有发送的数据都要与数字 5 进行异或运算(XOR)。那么在发送之前,我会先对数据进行处理:
7 ^ 5 = 2
于是我发送的实际上是数字 2(密文)。接收方在拿到 2 之后,同样按照约定规则再进行一次异或运算:
2 ^ 5 = 7
这样就成功还原出了原始数据 7。
在这个过程中:
- 7 是明文
- 2 是密文
- 5 就是用于加密和解密的密钥
为什么要加密
著名的就是臭名昭著的就是"运营商劫持"
说起这个名字大家可能没有感觉,但是一说到具体的事情,大家就了解的一清二楚了,在我们小时候,一到寒暑假的时候,大家都迫不及待的想可以玩到电脑,于是拿着自己的零花钱就到附近的网吧去开机上网,打开电脑的第一件事就是下载你想要完的游戏,于是你打开了浏览器,看到了一个你想玩游戏的下载链接,于是你点击进行下载,但是下载完成之后,你却发现下载了一个其它的不知道是干什么的玩意,与你想要下载的游戏八竿子打不到一起去,这就是运营商劫持。
由于我们通过网络传输的任何数据包都会经过运营商的网络服务器,那么运营商的网络设备就可以解析出你传输的数据内容,并进行篡改,当我们点击下载按钮之后,其实就是给服务器发送一个HTTP请求,获取到的HTTP响应其实就包含了你想要下载游戏的下载链接,但是由于你的传送方式是通过HTTP这种明文方式传送,这就很容易被运营商劫持,就将你想要下载的内容篡改为其它软件的下载地址,这样就导致幼小的我们傻傻的下载成其它的软件。
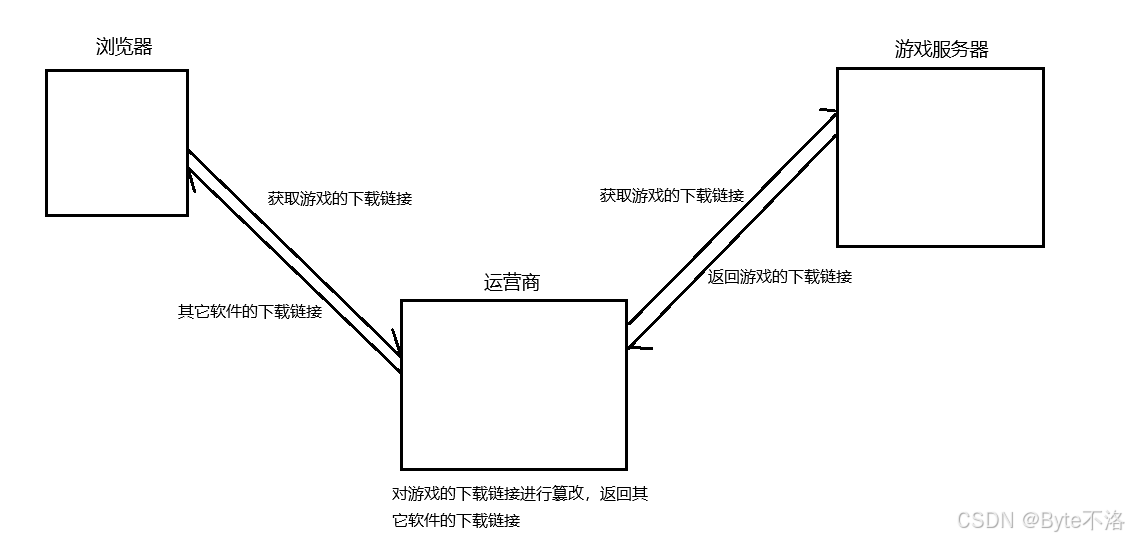
就是因为http的内容是明文进行传送的,明文数据在经过路由器,通信服务运营商等多个物理节点,如果信息在传输的过程中被劫持了,传输的内容就会暴露。劫持者就可以篡改传输的内容,并且客户端和服务器还不知道,这个就是中间人攻击,所以我们要对我们传输的信息进行加密。
至于运营商为什么这么做呢?

总而言之就是在互联网中,明文进行传输是非常危险的事情,HTTPS就是在HTTP的基础上进行了加密,进一步保护用户的数据安全。
常见的加密方式
对称加密
- 采用单钥密码系统的加密方式,同一个密钥可以同时用作信息的加密和解密,这种加密方式就是对称加密,也称为单密钥加密,特征:就是加密和解密所使用的密钥是相同的。
- 常见的对称加密算法:DES、3DES、AES、TDEA等
- 特点:计算量小,加密速度快,加密效率高,算法公开。
对称加密就是通过同一个密钥,把明文加密成密文,再将密文解密为明文,就如同我们上面7^5 = 2 , 2^5 = 7,这就是一个简单的对称加密。
非对称加密
- 需要两个密钥进行加密和解密,这两个密钥叫做公开密钥和私有密钥
- 常见的非对称加密算法:RSA,DSA,ECDSA
- 特点:就是算法强度复杂,安全性依赖于算法于密钥,但是由于算法的复杂,所以加密解密的速度相对之下没有对称加密快
非对称加密要用到的两个密钥,一个叫做"公钥",一个叫做"密钥",公钥和私钥是配对的。
通过公钥对明文进行加密,变成密文。
通过私钥对密文进行解密,变成明文。
也可以反着来
通过私钥对明文进行加密,变成密文。
通过公钥对密文进行解密,变成明文。
举一个生活中的例子就是假如有一天你的朋友要给你一个很重要的东西,但是你不在宿舍,这个时候,你就对你的朋友说,你将这个东西放到我桌子上的盒子里,然后拿旁边的锁将它锁起来,我回头拿我的钥匙将他再打开。
在这个例子中这个锁就是公钥,钥匙就是密钥,公钥给谁都行,无所谓,但是密钥只能是我们自己持有才行,这样只有我们才能对其进行解密。
数据摘要(数据指纹)
数据摘要(数据指纹),其基本原理是利用单向散列函数(Hash函数)对信息进行运算,生成一串固定长度的数字摘要。数字指纹并不是一种加密机制,但是可以用来判断数据有没有被篡改。
数据摘要常见的算法:有MD5,SHA1,SHA256等,但是也会有数据碰撞的问题(就是两个不同的信息,算出的摘要确实相同的,有这种可能,但是概率是比较低的)
数据摘要的特征:和加密算法的区别是:摘要的严格意义其实不是加密,因为并没有解密,只不过从摘要很难发推原信息,通常用来进行数据对比。
例如:
"hello" → MD5 → 5d41402abc4b2a76b9719d911017c592
即使只改一个字符:
"hello!" → MD5 → 不同的摘要
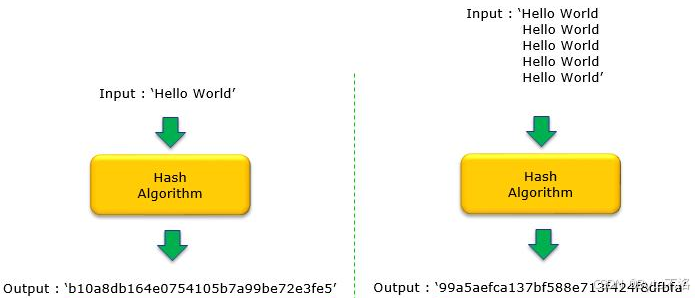
所以数据摘要就是通过Hash算法将任意长度数据映射为固定长度摘要的方式。
数字签名
就是将数据摘要通过非对称加密,就得到了数字签名。
HTTPS的工作过程的探究
既然要保护数据的安全,那就需要进行"加密"。网络传输中不再直接传输明文了,而是加密之后的密文。加密的方式很多,整体分为两大类:对称加密和非对称加密。
方案一:只是用对称加密
如果通信双发都各自持有同一个密钥X,并且没有人知道,那么彼此双方的通信安全就是可以被保证的(除非密钥被破解)。
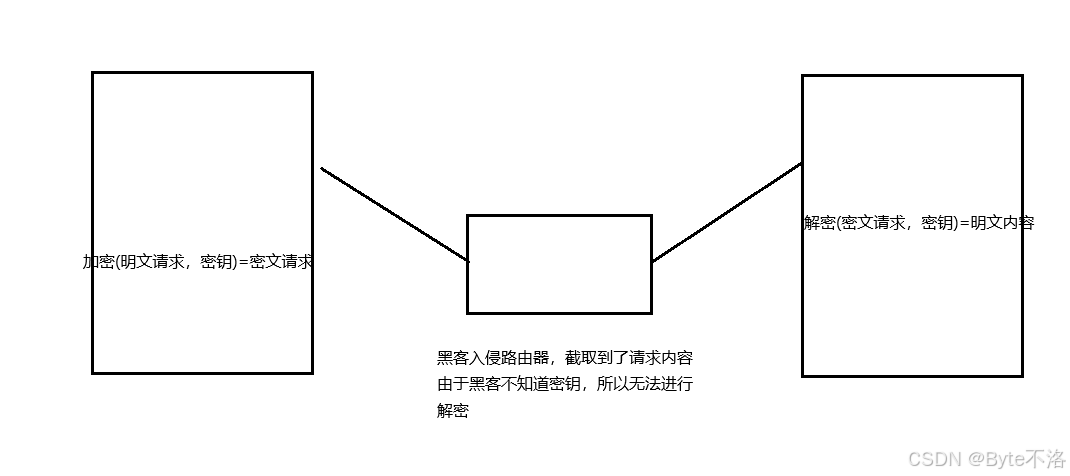
引入对称加密之后,即使数据被截获,由于黑客是不知道密钥是什么,所以也就无法进行解密,也就不知道数据的真实内容是什么。但是,事情是没有这么简单的,服务器同一时刻其实是给很多客户端提供服务的,这么多的客户端,每个人用的密钥都必须不同,如果相同,万一那一天一个密钥被黑客拿到了,这不是整锅都被端了,所以服务器需要维护每一个客户端和每个密钥之间的关联关系,这是相当麻烦的事情。
但是其实客户端和服务器约定好一个密钥这样的事情是十分不靠谱的,因为服务器是公司在进行维护,相对是安全的,而客户端的使用者一般都是小白,其实黑客只要入侵了你的电脑,想要获取到你的密钥内容是很容易的,这样对数据的保护成本就大大增加了。
并且假如有一天服务器需要对密钥进行更新的话,已经使用的客户端时成百上千的用户也得跟着改,这样牵一发而动全身的事情,是不利用产品的使用的,所以这样的方式是不可取的。
这时候就有人想到了一种解决办法就是,既然客户端保管不利,直接让客户端在使用之前先申请密钥,获得密钥之后再进行数据的传输,这样客户端就不需要一直持有密钥了。
但是这样就有点左脑攻击右脑的现象了,既然我们在获取密钥的时候,不也是要进行数据传输的么,这个时候是明文传送还是密文传送,明文传送,黑客直接就拿到了,密文传送,你又没有密钥如何进行密文传送,即使你这边加密形成密文传输了,对端如何解密,这不就是脱裤子放屁,多此一举么,所以通过对称加密的方式是不可取的。
方案二:只使用非对称加密
鉴于非对称加密的机制,如果服务器先把公钥以明文的方式交给客户端,之后客户端向服务器传输数据前先用这个公钥加密之后进行传输,这样似乎从客户端到服务器的信道就是安全的,因为只有服务器的密钥才能解开公钥加密的数据,但是服务器到客户端如何才能保障安全?
如果服务器用它的私钥加密的数据传给客户端,那么客户端可以用公钥进行解密,这个公钥也是明文进行传输的,一旦这个公钥被黑客拿到了,那他同样也可以使用公钥来对服务器传送的数据进行解密。
方案三:双方都使用非对称加密
- 服务端拥有公钥S和对应的私钥S'。客户端拥有公钥C和对应的密钥C'
- 客户端和服务器交换公钥
- 客户端给服务器发送消息,先用S对数据进行加密,在发送,然后服务器进行解密,因为只有服务器有密钥S'
- 服务器给客户端发送消息,先用C对数据进行加密,再发送,然后客户端进行解密,因为只有客户端有密钥C'
方案四:非对称加密+对称加密
- 服务端具有非对称加密的公钥S和私钥S'
- 客户端发送https请求,获得了服务端的公钥S
- 客户端在本地生成对称加密的密钥C,通过公钥S加密,发送给服务器
- 由于黑客没有私钥,即使截获了数据,也无法还原明文数据,也就无法获取到对称加密的密钥
- 服务器通过私钥S'解密,还原了客户端发来的对称加密的密钥C,并且使用这个对称加密的密钥对响应的数据进行加密传输。
- 后续只需要客户端与服务器的通信使用对称加密即可,由于该密钥只要客户端和服务器两个主机知道,其他人并不知道密钥,所以即使截获了数据,也是没有任何用。
虽然看上去方案二,三,四可行,但是都存在一个致命的问题就是,如果刚开始的时候,黑客就进行攻击了呢?
中间人攻击
这种攻击方式叫做:"MIMT攻击"。
在方案二,三,四中,客户端获取到公钥之后,对客户端形成的对称密钥用服务端的公钥进行加密,中间人即使截取到了数据,此时也是无法解出客户端形成的密钥,因为只有服务端有私钥。但是一旦黑客在刚开始的时候就进行了攻击,这一切的努力就化为泡影了。
- 服务器现在具有非对称加密算法的公钥S和私钥S'
- 黑客也同样准备好一个非对称加密算法的公钥M和私钥M'
- 客户端向服务器发送请求,服务器明文传送公钥S给客户端
- 这个时候黑客劫持了数据内容,提取出了其中的公钥S并且保存下来,然后将报文中的公钥S替换为自己的公钥M,然后将伪造后的报文给客户端。
- 客户端在拿到报文之后,提取公钥M(客户端完全不知道公钥已经被替换了),客户端自己形成对称密钥X,用公钥M加密X,形成报文发送给服务器。
- 这个时候黑客再次截取了数据内容,直接用自己的私钥M'进行解密,获得了客户端传送的对称加密的密钥X,然后他再用之前截取到服务端的公钥S加密后,将报文传送给服务器。
- 服务器拿到报文之后,用自己的私钥S'进行解密,得到了密钥X。
- 客户端和服务器就开始采用X进行对称加密,开始通信,但是黑客也早已知道了对称加密的密钥X,所以客户端和服务器传送的一切数据,对于黑客来讲和明文数据没什么区别。
所以问题的本质出在哪里呢?其实就是客户端无法确认收到含有公钥的数据报文,是不是就是服务器发送过来的!
引入证书
CA认证
服务端在使用HTTPS之前,需要向CA机构申领一份数字证书,数字证书里含有证书申请者信息,公钥信息等。服务器把证书传送给浏览器,浏览器从证书中获取公钥即可,证书就像身份证一样,证明服务端公钥的正确性。
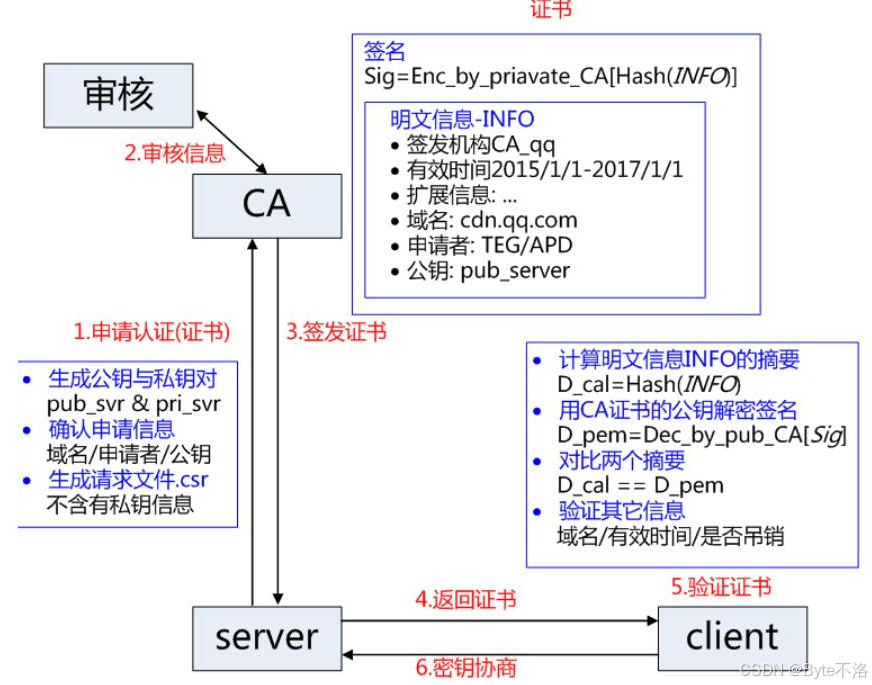
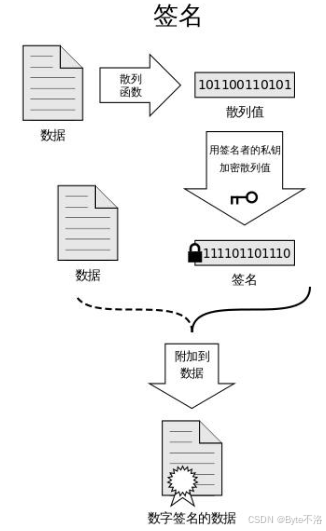
首先就是服务端将自己的域名,申请者(公司法人),以及自己的公钥等等信息提交给CA机构,然后CA机构会使用一些公开的hash算法对这些信息进行运算,形成一串固定长度的数据摘要,然后CA机构会使用自己的私钥(注:CA机构会有自己的公钥和私钥),将这个数据摘要信息形成密文数据,这个密文数据就是数据签名,然后CA机构会将服务端提交上来的数据与数据签名合在一起,这样就形成了CA证书。
当服务端申请CA证书的时候,CA机构会对服务端进行审核,并且为其形成专门的数字签名,过程如下:
- CA机构也拥有属于自己的非对称加密的公钥A和私钥A'
- CA机构对服务端申请的证书的明文数据(就是上图中CA证书中的明文信息)进行hash算法,形成数据摘要
- 然后对数据摘要用CA机构的私钥A'对其进行加密,得到数字签名S
服务端申请的证书明文和数字签名就共同构成了数字证书,这样一份数字证书就可以颁发给服务端了。
方案五:非对称加密+对称加密+证书认证
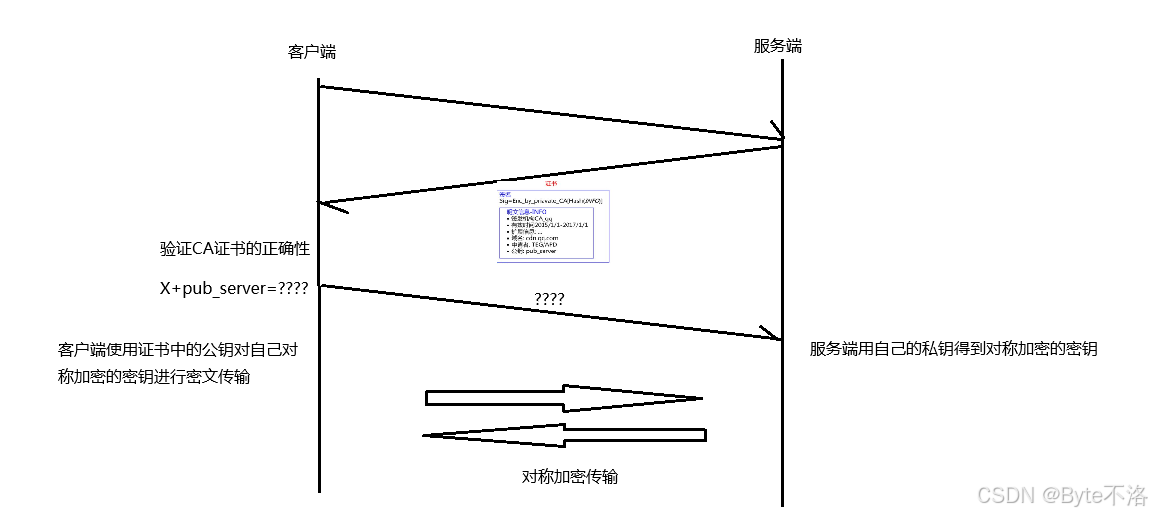
在客户端和服务器刚建立连接的时候,服务器给客户端返回一个证书,证书包含之前服务端的公钥,以及一些身份信息,以及数据签名,客户端在拿到CA证书之后,验证CA证书的合法性,验证成功之后,将使用证书中的公钥对自己接下来要使用的对称加密传输的密钥进行密文传输,然后服务器拿到这个密文之后,使用自己的私钥进行解密,得到对称加密的密钥信息,之后客户端和服务器就可以进行对称加密方式的信息传输。
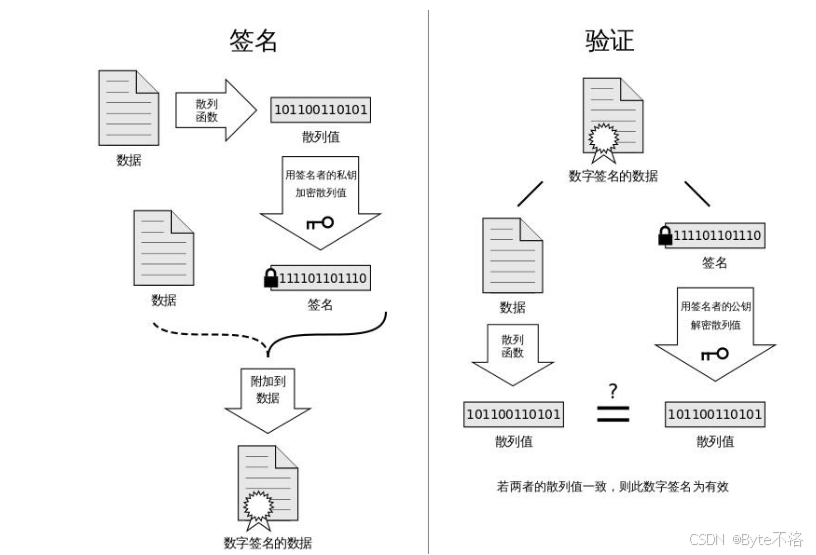
那么客户端是如何对这个CA证书进行验证呢?
将CA证书中的数据(服务器交给CA机构的信息)和数据签名进行分离,然后将数据通过和CA机构使用一样的hash算法,形成一个数据摘要,而由于数据签名是CA机构通过密钥形成的,所以我们只需要使用CA机构的公钥(CA机构的公钥在我们的电脑中会内置)就可以将数字签名反转回数据摘要,这样对比两个数据摘要是否相同,这样就可以判断这个CA证书是否属于合法。如果相同,就证明这个CA证书是可信的,这样就保证了CA证书中的公钥是合法的,不是中间人篡改后的。
现在如果中间人拿到这个CA认证之后,想要替换CA证书中的公钥已经是不可能了,一旦他将公钥进行替换,客户端在进行CA验证的时候,就会发现数据形成的数据摘要,和数据签名形成的数据摘要不一致,这样就这知道了有人修改了我们的公钥。
那有人就会说如果中间人将这个数据签名也修改了呢?
- 由于它没有CA机构的私钥,所以无法hash之后用私钥加密形成签名,也就没有办法对篡改后的证书形成匹配的签名
- 如果强行篡改,客户端收到该证书之后会发现明文和签字解密后的值是不一样的,这样就证明证书被篡改,证书不可信。
那要是将中间人整急眼了,自己申请一个真的证书,然后进行掉包怎么办?
- 弄一个真的证书,是要提交申请人的信息,这样相当于自投罗网了,得不偿失。
- 另外就算中间人将整个证书替换为自己申请的证书,证书中的明文内容又域名信息的,我们总不可能要访问百度的首页,跳转到谷歌的首页,这样客户端一下子就看出来了
- 总之,就是中间人没有CA私钥,对证书是无法尽心修改的。
我们可以看看我们浏览器中一些CA机构公开的公钥。
所以CA机构的公钥我们是可以获取到的,不用担心。
总之就是:
HTTPS = 非对称加密(交换密钥) + 对称加密(传输数据) + CA证书(身份认证)