注:本文为 "浮点数运算原理" 相关合辑。
英文引文,机翻未校。
图片清晰度受引文原图所限。
如有内容异常,请看原文。
Floating Point Demystified, Part 1
浮点数详解,第 1 部分
September 15, 2014
2014 年 9 月 15 日
Author's note: this article used to be called "What Every Computer Programmer Should Know About Floating Point, part 1". Some people noted that this was perhaps too similar to the name of the existing article "What Every Computer Scientist Should Know About Floating Point". Since I have a bunch of other articles called "X Demystified", I thought I'd rename this one to remove confusion.
作者注:本文原名为《每位计算机程序员都应了解的浮点数知识(第 1 部分)》。有读者指出该名称与已有文章《每位计算机科学家都应了解的浮点数知识》过于相近。因作者另有多篇题为《X 详解》的文章,故更改本文标题以避免混淆。
The subject of floating-point numbers can strike vague uncertainty into all but the hardiest of programmers. The first time a programmer gets bitten by the fact that 0.1 + 0.2 is not quite equal to 0.3, the whole thing can seem like an inscrutable mess where nothing behaves like it should.
浮点数相关主题常使程序员产生不确定性认知。当程序员首次发现 0.1 + 0.2 与 0.3 并非严格相等时,整个浮点数体系可能显得难以理解,各类运算表现似乎均不符合预期。
But lying amidst all of this seeming insanity are a lot of things that make perfect sense if you think about them in the right way. There is an existing article called [What Every Computer Scientist Should Know About Floating-Point Arithmetic, but it is very math-heavy and focuses on subtle issues that face data scientists and CPU designers. This article is aimed at the general population of programmers. I'm focusing on simple and practical results that you can use to build your intuition for how to think about floating-point numbers.
然而,这些看似反常的现象背后存在诸多符合逻辑的规则,只需以合理视角分析即可理解。现有文章《每位计算机科学家都应了解的浮点运算》数学推导较多,侧重数据科学家与 CPU 设计者关注的细节问题。本文面向普通程序员,围绕简洁实用的结论展开,帮助读者建立对浮点数运行机制的直观认知。
As a practical guide I'm concerning myself only with the IEEE 754 floating point formats single (float) and double that are implemented on current CPUs and that most programmers will come into contact with, and not other topics like decimal floating point, arbitrary precision, etc. Also my goal is to build intuition and show the shapes of things, not prove theorems, so my math may not be fully precise all the time. That said, I don't want to be misleading, so please let me know of any material errors!
作为实用指南,本文仅讨论当前 CPU 实现、多数程序员会接触的 IEEE 754 单精度(float)与双精度(double)浮点数格式,不涉及十进制浮点数、任意精度等内容。本文旨在建立直观认知、呈现规律特征,而非证明定理,因此部分数学表述并非全程严格精确。若存在实质性错误,欢迎读者指正。
Articles like this one are often written in a style that is designed to make you question everything you thought you knew about the subject, but I want to do the opposite: I want to give you confidence that floating-point numbers actually make sense. So to kick things off, I'm going to start with some good news.
同类文章常以颠覆既有认知的风格撰写,本文则相反,旨在让读者确信浮点数体系具备逻辑合理性。文章开篇先给出积极结论。
Integers are exact! As long as they're not too big.
整数可精确表示,前提是数值不超出范围
It's true that 0.1 + 0.2 != 0.3. But this lack of exactness does not apply to integer values! As long as they are small enough, floating point numbers can represent integers exactly.
0.1 + 0.2 != 0.3 是客观事实,但该精度问题不适用于整数。只要数值足够小,浮点数可精确表示整数。
1.0 == integer(1) (exactly)
5.0 == integer(5) (exactly)
2.0 == integer(2) (exactly)This exactness also extends to operations over integer values:
整数间的运算结果同样可精确表示:
1.0 + 2.0 == 3.0 (exactly)
5.0 - 1.0 == 4.0 (exactly)
2.0 * 3.0 == 6.0 (exactly)Mathematical operations like these will give you exact results as long as all of the values are integers smaller than 2 53 2^{53} 253 (for double) or 2 24 2^{24} 224 (for float).
当所有参与运算的数值均为小于 2 53 2^{53} 253(双精度)或 2 24 2^{24} 224(单精度)的整数时,此类数学运算可得到精确结果。
So if you're in a language like JavaScript that has no integer types (all numbers are double-precision floating point), and you have an application that wants to do precise integer arithmetic, you can treat JS numbers as 53-bit integers, and everything will be perfectly exact. Though of course if you do something inherently non-integral, like 8.0 / 7.0, this exactness guarantee doesn't apply.
对于 JavaScript 这类无整数类型(所有数值均为双精度浮点数)的语言,若应用需执行精确整数运算,可将 JS 数值视为 53 位整数,结果完全精确。若执行非整数运算,如 8.0 / 7.0,则该精确性不再成立。
And what if you exceed 2 53 2^{53} 253 for a double, or 2 24 2^{24} 224 for a float? Will that give you strange dreaded numbers like 16777220.99999999 when you really wanted 16777221?
若双精度数值超出 2 53 2^{53} 253、单精度数值超出 2 24 2^{24} 224,是否会出现预期为 16777221 却得到 16777220.99999999 这类异常数值?
No --- again for integers the news is much less dire. Between 2 24 2^{24} 224 and 2 25 2^{25} 225 a float can exactly represent half of the integers: specifically the even integers. So any mathematical operation that would have resulted in an odd number in this range will instead be rounded to one of the even numbers around it. But the result will still be an integer.
答案是否定的,整数场景下的情况并未如此糟糕。单精度浮点数在 2 24 2^{24} 224 至 2 25 2^{25} 225 区间内可精确表示半数整数,即偶数。该区间内运算结果本应为奇数时,会舍入至邻近偶数,结果仍为整数。
For example, let's add:
以加法运算为例:
16,777,216 (2^24)
+ 5
------------
16,777,221 (exact result 精确结果)
16,777,220 (rounded to nearest representable float 舍入为可表示的单精度浮点数)You can generally think of floating point operations this way. It's as if they computed exactly the correct answer with infinite precision, but then rounded the result to the nearest representable value. It's not implemented this way of course (putting infinite precision arithmetic in silicon would be expensive), but the results are generally the same as if it had.
浮点数运算可按此逻辑理解:运算先以无限精度得到精确结果,再舍入至最接近的可表示数值。硬件层面并未采用该实现方式(无限精度运算的硬件成本过高),但运算结果与该逻辑一致。
We can also represent this concept visually, using a number line:
该规律可通过数轴直观呈现:

The green line represents the addition and the red line represents the rounding to the nearest representable value. The tick marks above the number line indicate which numbers are representable and which are not; because these values are in the range 2 24 , 2 25 2\^{24}, 2\^{25} 224,225, only the even numbers are representable as float.
绿色线段表示加法运算,红色线段表示向可表示数值的舍入过程。数轴刻度标记可表示与不可表示的数值;因数值处于 2 24 , 2 25 2\^{24}, 2\^{25} 224,225 区间,单精度浮点数仅可表示偶数。
This model can also explain why adding two numbers that differ wildly in magnitude can make the smaller one get lost completely:
该模型可解释数量级差异极大的两数相加时,较小数值为何会完全丢失:
16,777,216
+ 0.0001
-----------------
16,777,216.0001 (exact result 精确结果)
16,777.216 (rounded to nearest representable float 舍入为可表示的单精度浮点数)Or in the number line model:
数轴模型示意如下:
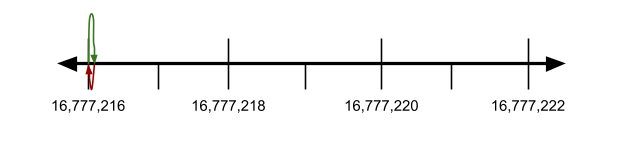
The smaller number was not nearly big enough to get close to the next largest representable value (16777218), so the rounding caused the smaller value to get lost completely.
较小数值的增量不足以接近下一个可表示数值(16777218),舍入后该数值完全丢失。
This rounding behavior also explains the answer to question number 4 in Ridiculous Fish's excellent article Will It Optimize? It's tempting to have floating-point anxiety and think that transforming (float)x * 2.0f into (float)x + (float)x must be imprecise somehow, but in fact it's perfectly safe. The same rule applies as our previous examples: compute the exact result with infinite precision and then round to the nearest representable number. Since the x + x and x * 2 are mathematically exactly the same, they will also get rounded to exactly the same value.
该舍入特性可解释 Ridiculous Fish 文章《能否优化?》中的第四个问题。开发者易对浮点数产生顾虑,认为将 (float)x * 2.0f 转换为 (float)x + (float)x 会损失精度,实际该转换完全可靠。规则与前文一致:先以无限精度计算精确结果,再舍入至可表示数值。x + x 与 x * 2 数学等价,舍入结果完全相同。
So far we've discovered that a float can represent:
截至目前,单精度浮点数可表示的数值范围为:
- all integers 0 , 2 24 0, 2\^{24} 0,224 exactly
精确表示 0 , 2 24 0, 2\^{24} 0,224 内的所有整数 - half of integers 2 24 , 2 25 2\^{24}, 2\^{25} 224,225 exactly (the even ones)
精确表示 2 24 , 2 25 2\^{24}, 2\^{25} 224,225 内的半数整数(偶数)
Why is this? Why do things change at 2 24 2^{24} 224?
该规律的成因是什么?为何分界点为 2 24 2^{24} 224?
It turns out that this is part of a bigger pattern, which is that floating-point numbers are more precise the closer they are to zero. We can visualize this pattern again with a number line. This illustration isn't a real floating-point format (it has only two bits of precision, much less than float or double) but it follows the same pattern as real floating-point formats:
该现象属于更普遍的规律:浮点数越接近 0,精度越高。该规律可通过数轴直观呈现。下图并非真实浮点数格式(仅含 2 位精度,远低于单精度与双精度),但遵循真实浮点数的分布规律:
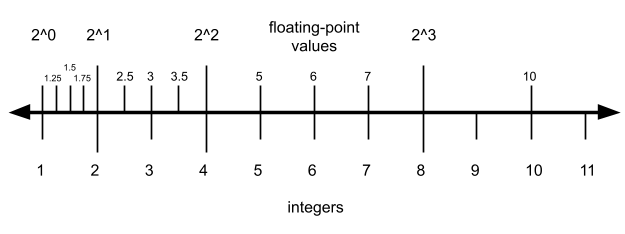
This diagram gets to the essence of the relationship between floating point values and integers. Up to a certain point (4 in this case), there are multiple floating point values per integer, representing numbers between the integers. Then at a certain point (here between 4 and 8) the set of floating point and integer values are the same. Once you get larger than that, the floating point values skip some integer values.
该图体现了浮点数与整数的核心关联。在特定阈值(本例为 4)以内,每个整数对应多个浮点数,可表示整数间的数值;超过该阈值(本例为 4 至 8 区间),浮点数与整数集合重合;数值继续增大,浮点数会跳过部分整数。
We can diagram this relationship to get a better sense and intuition for what numbers floats can represent compared to integers:
通过下图可更直观对比浮点数与整数的可表示范围:
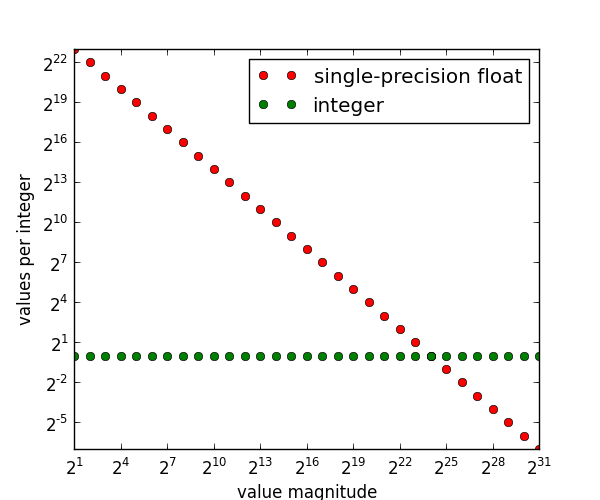
This plot is just a continuation of what we've said already. The green dots are boring and only appear for reference: they are saying that no matter how large or small your values are for an integer representation like int32, they can represent exactly one value per integer. That's a complicated way of saying that integer representations exactly represent the integers.
该图延续前文结论。绿色点为参考标记:int32 等整数类型无论数值大小,每个整数均对应唯一可表示值,即整数类型可精确表示整数。
But where it gets interesting is when we compare integers to floats, which appear as red dots. The green and red dots intersect at 2 24 2^{24} 224; we've already identified this as the largest value for which floats can represent every integer. If we go larger than this, to 2 25 2^{25} 225, then floats can represent half of all integers, ( 2 − 1 2^{-1} 2−1 on the graph), which again is what we have said already.
红色点代表浮点数,与整数的对比更具意义。绿点与红点在 2 24 2^{24} 224 处交汇,该值为浮点数可表示所有整数的最大值。数值超过该值至 2 25 2^{25} 225 时,浮点数仅可表示半数整数(图中为 2 − 1 2^{-1} 2−1),与前文结论一致。
The graph shows that the trend continues in both directions. For values in the range 2 25 , 2 26 2\^{25}, 2\^{26} 225,226, floats can represent 1/4 of all integers (the ones divisible by 4). And if we go smaller , in the range 2 23 , 2 24 2\^{23}, 2\^{24} 223,224, floats can represent 2 values per integer. This means that in addition to the integers themselves, a float can represent one value in between each integer, that being x .5 x.5 x.5 for any integer x x x.
图表显示该规律向两端延伸。在 2 25 , 2 26 2\^{25}, 2\^{26} 225,226 区间,浮点数可表示 1/4 的整数(可被 4 整除的数);在更小的 2 23 , 2 24 2\^{23}, 2\^{24} 223,224 区间,每个整数对应 2 个浮点数,即除整数本身外,还可表示各整数间的 x .5 x.5 x.5 数值。
So the closer you get to zero, the more values a float can stuff between consecutive integers. If you extrapolate this all the way to 1, we see that float can represent 2 23 2^{23} 223 unique values between 1 and 2. (Between 0 and 1 the story is more complicated).
浮点数越接近 0,相邻整数间可表示的数值越多。延伸至数值 1 附近,单精度浮点数在 1 至 2 之间可表示 2 23 2^{23} 223 个独立数值(0 至 1 区间的规律更为复杂)。
Range and Precision
范围与精度
I want to revisit this diagram from before, which depicts a floating-point representation with two bits of precision:
回顾前文 2 位精度浮点数表示示意图:
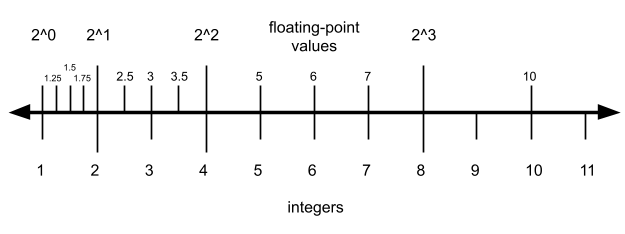
A useful observation in this diagram is that there are always 4 floating-point values between consecutive powers of two. For each increasing power of two, the number of integers doubles but the number of floating-point values is constant.
图中可观察到:相邻 2 的幂次之间始终存在 4 个浮点数。2 的幂次每增大一级,整数数量翻倍,浮点数数量保持恒定。
This is also true for float ( 2 23 2^{23} 223 values per power of two) and double ( 2 52 2^{52} 252 values per power of two). For any two powers-of-two that are in range, there will always be a constant number of values in between them.
单精度(每个 2 的幂次区间含 2 23 2^{23} 223 个数值)与双精度(每个 2 的幂次区间含 2 52 2^{52} 252 个数值)浮点数均遵循该规律。有效范围内任意相邻 2 的幂次之间,可表示数值数量恒定。
This gets to the heart of how range and precision work for floating-point values. The concepts of range and precision can be applied to any numeric type; comparing and contrasting how integers and floating-point values differ with respect to range and precision will give us a deep intuition for how floating-point works.
该特性体现了浮点数范围与精度的运行机制。范围与精度适用于所有数值类型,对比整数与浮点数在该维度的差异,可深入理解浮点数机制。
Range/precision for integers and fixed-point numbers
整数与定点数的范围及精度
For an integer format, the range and precision are straightforward. Given an integer format with n n n bits:
整数类型的范围与精度规则直观。对于 n n n 位整数格式:
- every value is precise to the nearest integer, regardless of the magnitude of the value.
无论数值大小,精度均为精确到最近整数。 - range is always 2 n 2^n 2n between the highest and lowest value (for unsigned types the lowest value is 0 and for signed types the lowest value is − ( 2 n − 1 ) -(2^{n-1}) −(2n−1)).
最值间范围恒为 2 n 2^n 2n(无符号类型最小值为 0,有符号类型最小值为 − ( 2 n − 1 ) -(2^{n-1}) −(2n−1))。
If we depict this visually, it looks something like:
直观示意如下:

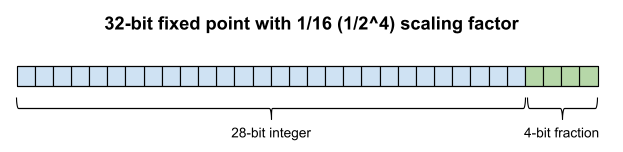
If you ever come across fixed point math, for example the [fixed-point support in the Allegro game programming library, fixed point has a similar range/precision analysis as integers. Fixed-point is a numerical representation similar to integers, except that each value is multiplied by a constant scaling factor to get its true value. For example, for a 1/16 scaling factor:
若接触定点数运算,如 Allegro 游戏编程库的定点数支持模块,其范围与精度分析逻辑与整数相近。定点数与整数类似,区别为各数值需乘以恒定比例因子得到真实值。以 1/16 比例因子为例:
| integers 整数 | equivalent fixed point value 等效定点数值 |
|---|---|
1 |
1 * 1/16 = 0.0625 |
2 |
2 * 1/16 = 0.125 |
3 |
3 * 1/16 = 0.1875 |
4 |
4 * 1/16 = 0.25 |
| ... | ... |
16 |
16 * 1/16 = 1 |
| ... | ... |
Like integers, fixed point values have a constant precision regardless of magnitude. But instead of a constant precision of 1, the precision is based on the scaling factor. Here is a visual depiction of a 32-bit fixed point value that uses a 1/16 ( 1 / 2 4 1/2^4 1/24) scaling factor. Compared with a 32-bit integer, it has 16x the precision, but only 1/16 the range:
与整数相同,定点数精度不随数值大小变化,但其精度并非 1,而是由比例因子决定。下图为采用 1/16( 1 / 2 4 1/2^4 1/24)比例因子的 32 位定点数示意。与 32 位整数相比,其精度提升 16 倍,范围仅为整数的 1/16:

The fixed-point scaling factor is usually a fractional power of two in (ie. 1 / 2 n 1/2^n 1/2n for some n n n), since this makes it possible to use simple bit shifts for conversion. In this case we can say that n n n bits of the value are dedicated to the fraction.
定点数比例因子通常为 2 的负整数次幂(即 1 / 2 n 1/2^n 1/2n),便于通过移位实现转换。此时数值中有 n n n 位用于表示小数部分。
The more bits you spend on the integer part, the greater the range. The more bits you spend on the fractional part, the greater the precision. We can graph this relationship: given a scaling factor, what is the resulting range and precision?
整数部分位数越多,范围越大;小数部分位数越多,精度越高。该关系可通过图表呈现:给定比例因子,对应范围与精度如下:
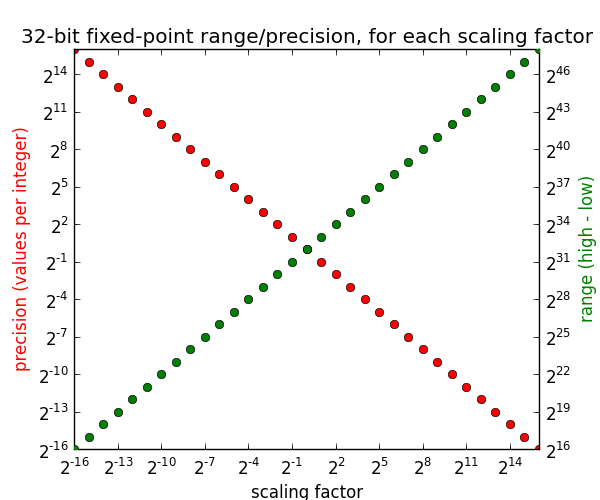
Looking at the first value on the left, for scaling factor 2 − 16 2^{-16} 2−16 (ie. dedicating 16 bits to the fraction), we get a precision of 2 16 2^{16} 216 values per integer, but a range of only 2 16 2^{16} 216. Increasing the scaling factor increases the range but decreases the precision.
左侧首个数据点:比例因子为 2 − 16 2^{-16} 2−16(16 位表示小数)时,每个整数对应 2 16 2^{16} 216 个数值,范围仅为 2 16 2^{16} 216。增大比例因子会扩大范围、降低精度。
At scaling factor 2 0 = 1 2^0=1 20=1 where the two lines meet, the precision is 1 value per integer and the range is 2 32 2^{32} 232 --- this is exactly the same as a regular 32-bit integer. In this way, you can think of regular integer types as a generalization of fixed point. And we can even use positive scaling factors: for example with a scaling factor of 2, we can double the range but can only represent half the integers in that range (the even integers).
比例因子 2 0 = 1 2^0=1 20=1 处两条曲线交汇,此时每个整数对应 1 个数值,范围为 2 32 2^{32} 232,与标准 32 位整数一致。由此可见,标准整数类型可视为定点数的特例。也可采用大于 1 的比例因子,如比例因子为 2 时,范围翻倍,但仅可表示区间内半数整数(偶数)。
The key takeaway from our analysis of integers and fixed point is that we can trade off range and precision, but given a scaling factor the precision is always constant, regardless of how big or small the values are.
整数与定点数分析的结论为:范围与精度可相互权衡,给定比例因子后,精度恒定,与数值大小无关。
Range/precision for floating-point numbers
浮点数的范围及精度
Like fixed-point, floating-point representations let you trade-off range and precision. But unlike fixed point or integers, the precision is proportional to the size of the value.
与定点数相同,浮点数可权衡范围与精度;区别在于,浮点数精度与数值大小成正比。
Floating-point numbers divide the representation into the exponent and the significand (the latter is also called the mantissa or coefficient ). The number of bits dedicated to the exponent dictates the range, and the number of bits dedicated to the significand determines the precision.
浮点数将存储位分为指数 与有效数字 (亦称尾数、系数)。指数位数决定数值范围,有效数字位决定精度。
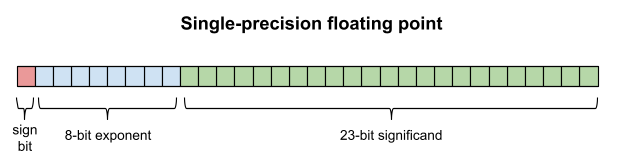
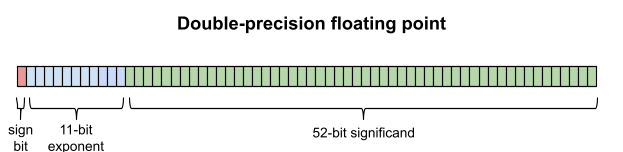
We will discuss the precise meanings of the exponent and significand in the next installment, but for now we will just discuss the general patterns of range and precision.
指数与有效数字的精确含义将在后续章节讨论,本节仅分析范围与精度的普遍规律。
Range works a little bit differently in floating-point than in fixed point or integers. Have you ever noticed that FLT_MIN and DBL_MIN in C are not negative numbers like INT_MIN and LONG_MIN? Instead they are very small positive numbers:
浮点数的范围规则与整数、定点数存在差异。C 语言中 FLT_MIN 与 DBL_MIN 并非 INT_MIN、LONG_MIN 这类负数,而是极小的正数:
##define FLT_MIN 1.17549435E-38F
##define DBL_MIN 2.2250738585072014E-308Why is this?
成因如下:
The answer is that floating point numbers, because they are based on exponents, can never actually reach zero or negative numbers "natively". Every time you decrease the exponent you get closer to zero but you can never actually reach it. So the smallest number you can reach is FLT_MIN for float and DBL_MIN for double. (denormalized numbers can go smaller, but they are considered special-case and are not always enabled. FLT_MIN and DBL_MIN are the smallest normalized numbers.)
浮点数基于指数构建,原生无法表示 0 与负数。指数每减小一级,数值更接近 0 但无法达到。因此单精度最小可表示值为 FLT_MIN,双精度为 DBL_MIN。非规格化数可表示更小数值,但属于特殊情形且并非默认启用,FLT_MIN 与 DBL_MIN 为最小规格化数。
You may protest that float and double can clearly represent zero and negative numbers, and this is true, but only because they are special-cased. There is a sign bit that indicates a negative number when set.
读者可能提出,float 与 double 可表示 0 和负数,该结论成立,但依赖特殊规则:存在符号位,置 1 时表示负数。
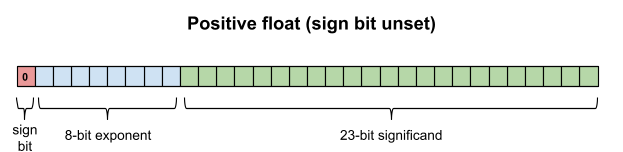
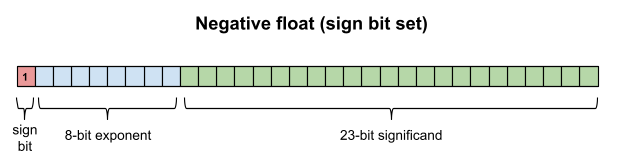
And when the exponent and significand are both zero, this is special-cased to be the value zero. (If the exponent is zero but the significand is non-zero, this is a denormalized number; a special topic for another day.)
指数与有效数字均为 0 时,特殊定义为数值 0。(指数为 0 但有效数字非 0 时为非规格化数,该内容后续讨论。)
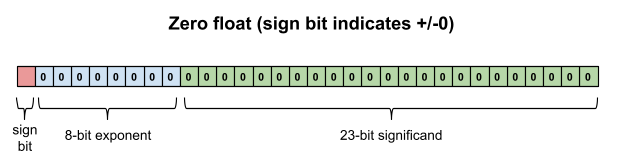
Put these two special cases together and you can see why positive zero and negative zero are two distinct values (though they compare equal).
结合两项特殊规则,可解释正 0 与负 0 为两个独立数值(但比较结果相等)。
Because floating-point numbers are based on exponents, and can never truly reach zero, the range is defined not as an absolute number, but as a ratio between the largest and smallest representable value. That range ratio is entirely determined by the number of bits alloted to the exponent.
浮点数基于指数且无法真正达到 0,其范围不以绝对差值定义,而以最大与最小可表示值的比值衡量。该比值由指数位数决定。
If there are n n n bits in the exponent, the ratio of the largest to the smallest value is roughly 2 2 n 2^{2n} 22n. Because the n n n-bit number can represent 2 n 2^n 2n distinct values, and since those values are themselves exponents we raise 2 to that value.
若指数为 n n n 位,最大与最小数值的比值约为 2 2 n 2^{2n} 22n。 n n n 位可表示 2 n 2^n 2n 个独立指数,再以 2 为底进行幂运算。
We can use this formula to determine that float has a range ratio of roughly 2 256 2^{256} 2256, and double has a range ratio of roughly 2 2048 2^{2048} 22048. (In practice the ranges are not quite this big, because IEEE floating point reserves a few exponents for zero and NaN.)
据此公式,单精度范围比值约为 2 256 2^{256} 2256,双精度约为 2 2048 2^{2048} 22048。实际范围略小,因 IEEE 浮点数保留部分指数用于表示 0 与 NaN。
This alone doesn't say what the largest and smallest values actually are, because the format designer gets to choose what the smallest value is. If FLT_MIN had been chosen as 2 0 = 1 2^0 = 1 20=1, then the largest representable value would be 2 256 ≈ 10 77 2^{256} \approx 10^{77} 2256≈1077.
该公式无法确定最值的具体数值,因最小可表示值由格式设计者设定。若 FLT_MIN 设为 2 0 = 1 2^0 = 1 20=1,则最大可表示值为 2 256 ≈ 10 77 2^{256} \approx 10^{77} 2256≈1077。
But instead FLT_MIN was chosen as 2 − 126 ≈ 10 − 37 2^{-126} \approx 10^{-37} 2−126≈10−37, and FLT_MAX is ≈ 2 128 ≈ 3.4 × 10 38 \approx 2^{128} \approx 3.4 \times 10^{38} ≈2128≈3.4×1038. This gives a true range ratio of ≈ 2 254 \approx 2^{254} ≈2254, which roughly lines up with our previous analysis that yielded 2 256 2^{256} 2256 (reality is a bit smaller because two exponents are stolen for special cases: zero and NaN/infinity).
实际 FLT_MIN 设为 2 − 126 ≈ 10 − 37 2^{-126} \approx 10^{-37} 2−126≈10−37,FLT_MAX 约为 2 128 ≈ 3.4 × 10 38 2^{128} \approx 3.4 \times 10^{38} 2128≈3.4×1038,真实范围比值约为 2 254 2^{254} 2254,与前文 2 256 2^{256} 2256 的估算接近(差值源于 2 个指数位被预留用于 0、NaN 与无穷大)。
What about precision? We have said several times that the precision of a floating-point value is proportional to its magnitude. So instead of saying that the number is precise to the nearest integer (like we do for integer formats), we say that a floating-point value is precise to X % X\% X% of its value . Using our sample from before of an imaginary floating point format with a two-bit significand, we can see:
精度方面,前文多次提及浮点数精度与数值大小成正比。与整数"精确到最近整数"的表述不同,浮点数精度表述为数值自身的 X % X\% X%。以之前 2 位有效数字的虚拟浮点数格式为例:
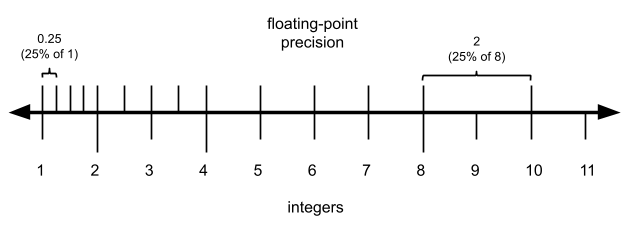
So at the low end of each power of two, the precision is always 25% of the value. And at the high end it looks more like:
每个 2 的幂次区间低端,精度为数值的 25%;区间高端则为:
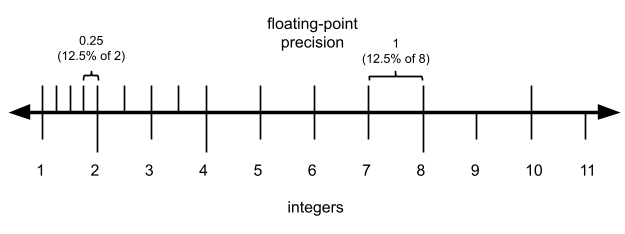
So for a two-bit significand, the precision is always between 12.5% and 25% of the value. We can generalize this and say that for an n n n-bit significand, the precision is between 1 / 2 n 1/2^n 1/2n and 1 / 2 n + 1 1/2^{n+1} 1/2n+1 of the value (ie. between 100 2 n % \frac{100}{2^n}\% 2n100% and 100 2 n + 1 % \frac{100}{2^{n+1}}\% 2n+1100% of the value. But since 1 / 2 n 1/2^n 1/2n is the worst case, we'll talk about that because that's the figure you can count on.
2 位有效数字的浮点数精度介于数值的 12.5% 至 25% 之间。推广至 n n n 位有效数字,精度介于数值的 1 / 2 n 1/2^n 1/2n 至 1 / 2 n + 1 1/2^{n+1} 1/2n+1 之间(即 100 2 n % \frac{100}{2^n}\% 2n100% 至 100 2 n + 1 % \frac{100}{2^{n+1}}\% 2n+1100%)。 1 / 2 n 1/2^n 1/2n 为最差精度,可作为可靠参考值。
We have finally explored enough to be able to fully compare/contrast fixed-point and integer values with floating point!
至此可完整对比定点数、整数与浮点数:
| range 范围 | precision 精度 | |
|---|---|---|
| fixed point and integer 定点数与整数 | scalar (high − low) 2 n × scaling factor 2^n \times \text{scaling factor} 2n×scaling factor 标量型(最大值−最小值) 2 n × 2^n \times 2n× 比例因子 | absolute/constant equal to the scaling factor 绝对恒定值,等于比例因子 |
| floating point 浮点数 | ratio (high / low) 2 2 e 2^{2e} 22e 比值型(最大值/最小值) 2 2 e 2^{2e} 22e | relative (X%) 100 2 n % \displaystyle\frac{100}{2^n}\% 2n100% (worst case) 相对精度(X%),最差为 100 2 n % \displaystyle\frac{100}{2^n}\% 2n100% |
If we apply these formulas to single-precision floating point vs. 32-bit unsigned integers, we get:
将公式应用于单精度浮点数与 32 位无符号整数,结果如下:
| range 范围 | precision 精度 | |
|---|---|---|
| integer 整数 | 2 32 2^{32} 232 2 32 2^{32} 232 | 1 1 |
| floating point 浮点数 | 2 256 / 1 2^{256}/1 2256/1 2 256 / 1 2^{256}/1 2256/1 | 0.00001% (worst case) 最差 0.00001% |
Practical trade-offs between fixed/floating point
定点数与浮点数的实际权衡
Let's step back for a second and contemplate what all this really means, for us humans here in real life as opposed to abstract-math-land.
抛开纯数学理论,从实际应用角度分析上述规律的意义。
Say you're representing lengths in kilometers. If you choose a 32-bit integer, the shortest length you can measure is 1 kilometer, and the longest length you can measure is 4,294,967,296 km (measured from the Sun this is somewhere between Neptune and Pluto).
以千米为单位表示长度时,若选用 32 位整数,最小可测长度为 1 km,最大为 4294967296 km(以太阳为起点,该距离介于海王星与冥王星轨道之间)。
On the other hand, if you choose a single-precision float, the shortest length you can measure is 10 − 26 10^{-26} 10−26 nanometers --- a length so small that a single atom's radius is 10 24 10^{24} 1024 times greater. And the longest length you can measure is 10 25 10^{25} 1025 light years.
若选用单精度浮点数,最小可测长度为 10 − 26 10^{-26} 10−26 纳米,该尺度远小于原子半径(原子半径为其 10 24 10^{24} 1024 倍);最大可测长度为 10 25 10^{25} 1025 光年。
The float's range is almost unimaginably wider than the int32. And what's more, the float is also more accurate until we reach the magic inflection point of 2 24 2^{24} 224 that we have mentioned several times in this article.
浮点数范围远大于 32 位整数。此外,在本文多次提及的 2 24 2^{24} 224 阈值以内,浮点数精度更高。
So if you choose int32 over float, you are giving up an unimaginable amount of range, and precision in the range 0 , 2 24 0, 2\^{24} 0,224, all to get better precision in the range 2 24 , 2 32 2\^{24}, 2\^{32} 224,232. In other words, the int32's sole benefit is that it lets you talk about distances greater than 16 million km to kilometer precision. But how many instruments are even that accurate?
选择 32 位整数而非浮点数,会牺牲极大范围与 0 , 2 24 0, 2\^{24} 0,224 区间内的精度,仅换取 2 24 , 2 32 2\^{24}, 2\^{32} 224,232 区间的更高精度。换言之,32 位整数仅在 1600 万 km 以上距离可保持千米级精度,而多数测量设备难以达到该精度。
So why does anyone use fixed point or integer representations?
为何仍有场景使用定点数或整数?
To turn things around, think about time_t. time_t is a type defined to represent the number of seconds since the epoch of 1970-01-01 00:00 UTC. It has traditionally been defined as a 32-bit signed integer (which means that it will overflow in the year 2038). Imagine that a 32-bit single-precision float had been chosen instead.
以 time_t 为例,该类型表示自协调世界时 1970 年 1 月 1 日 0 时起的秒数,传统定义为 32 位有符号整数(将在 2038 年溢出)。假设改用 32 位单精度浮点数。
With a float time_t, there would be no overflow until the year 5395141535403007094485264579465 AD, long after the Sun has swallowed up the Earth as a Red Giant, and turned into a Black Dwarf. However! With this scheme the granularity of timekeeping would get worse and worse the farther we got from 1970. Unlike the int32 which gives second granularity all the way until 2038, with a float time_t we would already in 2014 be down to a precision of 128 seconds --- far too coarse to be useful.
浮点型 time_t 可表示至公元 5395141535403007094485264579465 年才溢出,远晚于太阳演化为红巨星吞噬地球并最终成为黑矮星的时间。但该方案下,计时精度随距离 1970 年的时长增加持续降低。32 位整数可在 2038 年前保持秒级精度,而浮点型 time_t 在 2014 年精度已降至 128 秒,无法满足实用需求。
So clearly floating point and fixed point / integers all have a place. Integers are still ideal for when you are counting things, like iterations of a loop, or for situations like a time counter where you really do want a constant precision over its range. Integer results can also be more predictable since the precision doesn't vary based on magnitude. For example, integers will always hold the identity x + 1 - 1 == x, as long as x doesn't overflow. The same can't be said for floating point.
浮点数、定点数与整数各有适用场景。整数适用于计数场景(如循环迭代),或需全程恒定精度的计时场景。整数运算结果更可预测,精度不随数值变化,如无溢出时恒满足 x + 1 - 1 == x,浮点数则无该特性。
Conclusion
总结
There is more still to cover, but this article has grown too long already. I hope this has helped build your intuition for how floating point numbers work. In the next article(s) in the series, we'll cover: the precise way in which the value is calculated from exponent and significand, fractional floating point numbers, and the subtleties of printing floating-point numbers.
系列内容仍有后续章节,本文篇幅已足够。希望本文帮助读者建立浮点数运行机制的直观认知。后续文章将讨论指数与有效数字计算数值的精确规则、小数形式浮点数,以及浮点数输出的细节问题。
Floating Point Demystified, Part 2: Why Doesn't 0.1 + 0.2 == 0.3?
浮点数详解,第 2 部分:为何 0.1 + 0.2 ≠ 0.3?
February 6, 2016
2016 年 2 月 6 日
This is the second article in a series. My previous entry Floating Point Demystified, Part 1 was pretty dense with background information. For part 2 let's answer a burning, practical question that bites almost every new programmer at some point:
本文为系列第二篇。前篇《浮点数详解(第 1 部分)》包含大量背景知识。第二篇解答几乎所有新手程序员都会遇到的实际问题:
Why oh why doesn't 0.1 + 0.2 == 0.3?
为何 0.1 + 0.2 不等于 0.3?
The answer is: it does! In mathematics. But floating point has failed at this before we even get to the addition part. Double-precision floating point is totally incapable of representing 0.1, 0.2, or 0.3. When you think you're adding those numbers in double-precision, here is what you are actually adding:
答案:数学运算中该等式成立,但浮点数在加法运算前已无法精确表示数值。双精度浮点数无法精确表示 0.1、0.2 与 0.3。双精度运算中看似相加的三个数,实际数值如下:
0.1000000000000000055511151231257827021181583404541015625
+ 0.200000000000000011102230246251565404236316680908203125
-----------------------------------------------------------
0.3000000000000000444089209850062616169452667236328125But if you just type in 0.3 directly, what you're getting is:
直接输入 0.3 时,实际存储的数值为:
0.299999999999999988897769753748434595763683319091796875Since those last two numbers aren't the same, the equality comparison returns false.
两组结果数值不同,因此相等判断返回假。
Some of you reading this probably won't believe me. "You've just printed a bunch of decimal places, but what you have is still an approximation, just like 0.1 and 0.2 are!" I can't blame you for your distrust. Computer systems have traditionally made it extraordinarily difficult to see the precise value of a floating-point number. Anything you've seen printed out before probably was an approximation. You may have even lost faith that floating point values even have an exact value that can be printed. You might think that their true value is an infinitely repeating decimal like 0. 1 ˉ 0.\bar{1} 0.1ˉ. Or maybe it's an irrational number like 2 \sqrt{2} 2 whose decimal expansion never repeats or terminates.
部分读者可能难以信服,认为上述长串小数仍为近似值。该疑虑可以理解,传统计算机系统难以展示浮点数精确值,输出内容多为近似值。读者甚至可能怀疑浮点数不存在可打印的精确值,认为其真实值为 0. 1 ˉ 0.\bar{1} 0.1ˉ 这类无限循环小数,或 2 \sqrt{2} 2 这类无限不循环无理数。
The truth is that floating-point numbers are rational and can always have their exact value printed out in a finite decimal. The numbers above are absolutely precise renderings of the double's true value! You can try it yourself by using the built-in decimal module in Python, which supports arbitrary precision decimal numbers:
事实为浮点数均为有理数,可通过有限小数精确表示。上文数值为双精度浮点数的真实精确值。读者可使用 Python 内置 decimal 模块验证,该模块支持任意精度十进制数:
$ python
>>> from decimal import Decimal, getcontext
>>> getcontext().prec = 1000 # To prevent truncation/rounding
>>> Decimal(0.1)
Decimal('0.1000000000000000055511151231257827021181583404541015625')Of course for single-precision, the precise number would be different. 0.1 in single precision is a little shorter:
单精度浮点数的精确值不同,0.1 的单精度表示更短:
0.100000001490116119384765625Then Why Does The Computer Print 0.1?
为何计算机输出显示为 0.1?
The reason everyone gets so confused to begin with is that basically every programming language will natively print 0.1 instead of the double's true value:
读者产生困惑的根源在于,主流编程语言均默认输出 0.1,而非双精度浮点数的真实值:
$ python
Python 2.7.10 (default, Oct 23 2015, 18:05:06)
[GCC 4.2.1 Compatible Apple LLVM 7.0.0 (clang-700.0.59.59)] on darwin
>>> 0.1
0.1
$ node
> 0.1
0.1
$ irb
irb(main):001:0> 0.1
=> 0.1
$ lua
Lua 5.3.2 Copyright (C) 1994-2015 Lua.org, PUC-Rio
> print(0.1)
0.1Why did four languages in a row "lie" to me about the value of 0.1?
为何四种语言均对 0.1 的数值进行简化显示?
Things get a little interesting here. While all four languages printed the same approximation here, they did it for two totally different reasons. In other words, they got to their answer in two totally different ways.
该现象背后存在两种不同机制。四种语言输出结果相同,但实现逻辑完全不同。
You can see the difference between them if you try to print a slightly different value:
打印其他数值可观察到差异:
$ python
Python 2.7.10 (default, Oct 23 2015, 18:05:06)
[GCC 4.2.1 Compatible Apple LLVM 7.0.0 (clang-700.0.59.59)] on darwin
>>> 0.1 + 0.2
0.30000000000000004
$ node
> 0.1 + 0.2
0.30000000000000004
$ irb
irb(main):001:0> 0.1 + 0.2
=> 0.30000000000000004
$ lua
Lua 5.3.2 Copyright (C) 1994-2015 Lua.org, PUC-Rio
> print(0.1 + 0.2)
0.3Lua is the odd person out here: everyone else got a really long number with "4" at the end, but Lua just printed 0.3. What's going on here?
此处 Lua 表现与众不同:其他语言均输出末尾带 4 的长串数值,而 Lua 仅输出 0.3。其原因如下:
If you look in the Lua source, you'll see that it is using printf() with a %.14g format string (this technically varies based on the platform, but it's probably true on your platform). With this format string, printf() is specified to print the double according to this algorithm:
查看 Lua 源码可知,其使用 printf() 并采用格式字符串 %.14g(该设置随平台略有差异,但主流平台均为此配置)。该格式下 printf() 按以下规则输出双精度数值:
- The value rounded to an N-digit decimal value (14 in this case). For us this yields
0.30000000000000.
将数值舍入至 N 位十进制数(本例为 14 位),得到0.30000000000000。 - Trailing zeros are removed, yielding
0.3.
移除末尾多余的 0,最终输出0.3。
This explains why Lua got the answer it did. But what about the other implementations. They printed a number that was much longer. It still wasn't the number's true value -- that would be an even longer:
以上即为 Lua 输出结果的成因。其他语言的输出更长,且仍非数值的真实精确值,其精确值为:
0.3000000000000000444089209850062616169452667236328125Why did the other languages all decide to stop printing at that first "4"? The fact that they all print the same thing should hint to us that there is something significant about that answer.
其他语言为何在首个 4 处截断输出?三者输出完全一致,说明该结果具备特殊意义。
The other three languages all follow this rule: print the shortest string that will unambiguously convert back to the same number. In other words, the shortest string such that float(str(n)) == n. (This guarantee of course doesn't apply to Infinity and NaN).
另外三种语言遵循同一规则:输出可唯一还原为原浮点数的最短字符串 ,即满足 float(str(n)) == n 的最短字符序列(该规则不适用于无穷大与非数值 NaN)。
So while the values printed by the other three languages are not exact, they are unique . No two values will map to the same string. And each string will map back to the correct float. These are useful properties, even if they do cause confusion sometimes by hiding the fact that float(0.1) is not exactly 0.1.
因此这些语言输出的数值虽非精确值,但具备唯一性,不同浮点数不会映射至同一字符串,且字符串可还原为对应浮点数。该特性具备实用价值,尽管会掩盖 float(0.1) 并非精确等于 0.1 的事实,引发部分困惑。
We can ask one more question about Lua. If you analyze the precision available in a double (which has a 52-bit mantissa), you can work out that 17 decimal digits is enough to uniquely identify every possible value. In other words, if Lua used the format specifier %.17g instead of %.14g, it would also have the property that tonumber(tostring(x)) == x Why not do that, so that Lua's number to string formatting can also precisely represent the underlying value?
针对 Lua 可提出另一问题:双精度浮点数含 52 位有效数字,17 位十进制数即可唯一标识所有可表示值。若 Lua 采用格式符 %.17g 替代 %.14g,同样可满足 tonumber(tostring(x)) == x,为何未采用该方式以精确表示底层数值?
I can't find any reference where the Lua authors directly explain their motivation on this ([someone did ask once but [the author's response didn't give a specific rationale). I can speculate though.
笔者未找到 Lua 开发者对此的直接说明(曾有用户提问,但开发者未给出具体理由),仅能进行合理推测。
If we try that out, the downside quickly becomes clear. Let's use printf from Ruby to demonstrate:
采用 17 位格式的弊端十分明显,以 Ruby 的 printf 为例:
$ irb
irb(main):001:0> printf("%.17g\n", 0.1)
0.10000000000000001Ah, we've lost the property that 0.1 prints as 0.1. That trailing 1 isn't junk -- as we saw at the beginning of the article, the precise value of this number does include about 40 more digits of real, non-zero data. But the extra digits aren't necessary for uniqueness, since float(0.1) and float(0.10000000000000001) map to exactly the same value. I am guessing that the Lua authors decided that making these common cases print short strings was more important than capturing full precision. In Lua you can always use string.format('%.17g', num) if you really want to.
此时 0.1 不再简洁输出为 0.1,末尾的 1 并非无效数据。本文开头已说明,该数值的精确表示包含约 40 位非零有效数字,但额外位数对唯一性无意义,float(0.1) 与 float(0.10000000000000001) 对应同一浮点数。推测 Lua 开发者认为,常用数值的简洁输出比完整精度展示更重要。若用户需要精确表示,可在 Lua 中使用 string.format('%.17g', num)。
The printf() function doesn't offer the functionality of "shortest unambiguous string." The best it can do is omit trailing zeros. There is no printf() format specifier that will do what Ruby, Python, and JavaScript are doing above. And since Lua is trying to stay small, it wouldn't make sense to include this somewhat complicated functionality.
printf() 函数不支持"最短唯一字符串"输出,仅能移除末尾 0,无格式符可实现 Ruby、Python、JavaScript 的输出逻辑。Lua 追求体积精简,无需集成该复杂功能。
How to calculate this "shortest unambiguous string" efficiently is more tricky than you might expect. In fact the best known algorithms for calculating it were published in 2010 ([Printing Floating-Point Numbers Quickly and Accurately with Integers) and in 2016 ([Printing Floating-Point Numbers: A Faster, Always Correct Method). There is a surprising amount of work that goes into these most basic and low-level problems in Computer Science!
高效计算"最短唯一字符串"的难度超出预期,目前最优算法分别发表于 2010 年与 2016 年。计算机科学中这类基础底层问题,往往需要大量研究工作支撑。
Tutorial: IEEE-754 Standard for Storing Floating-Point Variables in Memory with C18 Compiler
教程:基于 C18 编译器,采用 IEEE-754 标准在内存中存储浮点数变量
When using high-level languages in microcontroller systems as Basic or C, it is possible to define the variables used in programs such as: positive integer, signed integer, or floating point. The floating point representation permits to store real numbers (ie, values that can be positive or negative and handle decimal point), which can take any value, always in a fixed format of 24 or 32 bits of memory, depending on the language and compiler used. The most widely used standard for microcontroller applications, is IEEE-754, 32 bits. This format is used by the compiler C18 and is described below.
在单片机系统中使用 Basic、C 等高级语言时,可定义无符号整数、有符号整数、浮点数等程序变量。浮点数表示方式可存储实数(含正负与小数点),数值范围宽泛,内存占用固定为 24 位或 32 位,具体取决于语言与编译器。单片机应用中最常用的标准为 32 位 IEEE-754,C18 编译器采用该格式,具体规则如下:
IEEE-754 Standard for the Representation of Real Numbers in Floating-Point Format:
IEEE-754 浮点数实数表示标准:
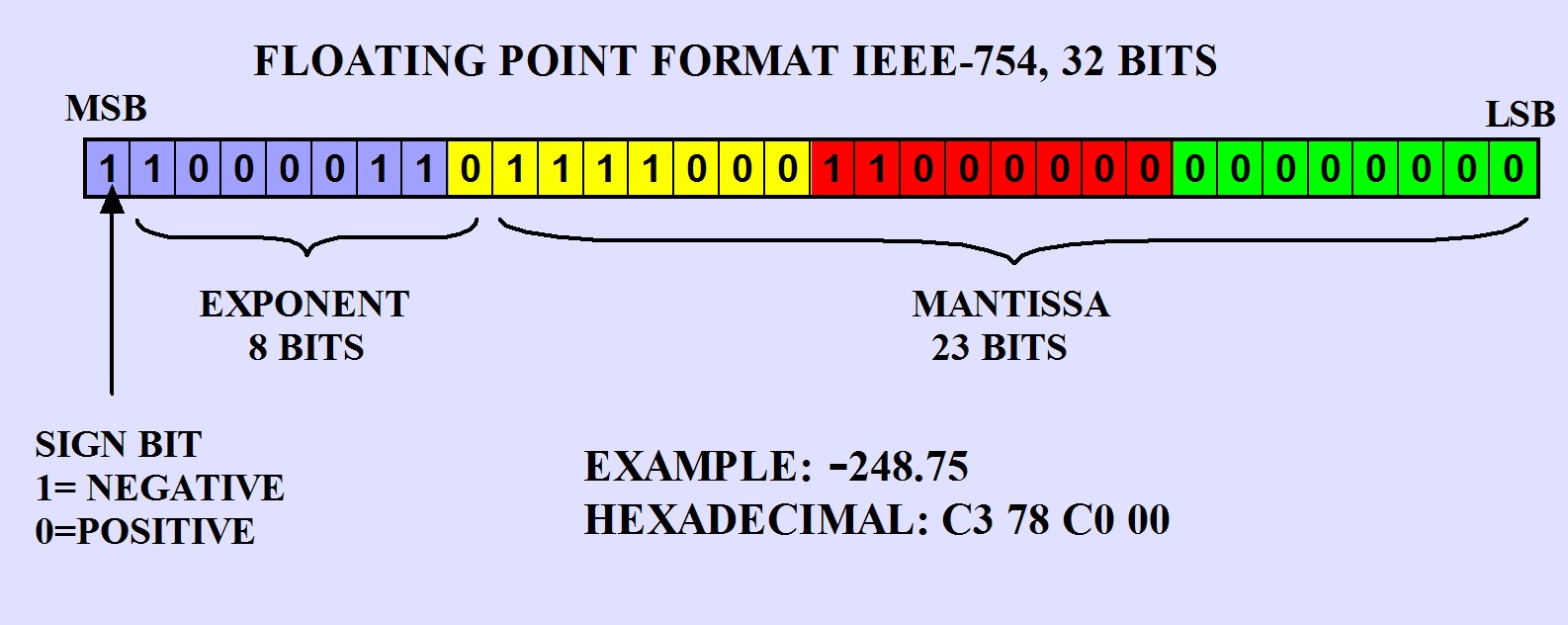
When you define a variable of type "float" in memory, the value is stored in 4 bytes, or 32 bits, distributed as follows: a sign bit, 8 bit exponent and a mantissa of 23 bits.
定义 float 类型变量时,数值占用 4 字节(32 位)内存,分布为:1 位符号位、8 位指数位、23 位有效数字位。
| BYTE 1 | BYTE 2 | BYTE 3 | BYTE 4 |
|---|---|---|---|
| 字节 1 | 字节 2 | 字节 3 | 字节 4 |
The numbers represented in floating point are generated from a mantissa and an exponent and can take values very large or very small. The exponent moves the binary point value expressed in the mantissa, to positions +127...-127 shifting the binary point right or left respectively.
浮点数由有效数字与指数组合构成,可表示极大或极小数值。指数可使有效数字的二进制小数点移动 ± 127 \pm 127 ±127 位,实现小数点左移或右移。
To convert the floating point format to a decimal value, an implicit "1" is added to the 23 bit mantissa forming a 24 bit mantissa.
将浮点数转换为十进制数值时,需在 23 位有效数字前添加隐含的 1,构成 24 位有效数字。
The complete 32 bit representation of the floating point value is organized as follows. Please see picture.
32 位浮点数的完整结构如下,详见附图。
Sign: is bit 7 of byte 1. If the value is 0, the number is positive, if 1, negative.
符号位:位于字节 1 的第 7 位,数值为 0 表示正数,为 1 表示负数。
Exponent: is an 8 bit value, with an offset of 7FH. To find the real value of the exponent, you must subtract -7FH to the value stored in memory. The 8 bits of the exponent forms with the seven least significant bits of byte 1 and the most significant bit of byte 2. The real exponent expresses the number of positions to the right (when the value is positive) or left (when the value is negative) that should move the binary point in the mantissa.
指数位:8 位数值,采用偏移量 7FH。计算真实指数需用内存存储值减去 7FH。8 位指数由字节 1 的低 7 位与字节 2 的最高位构成。真实指数表示有效数字的二进制小数点右移(指数为正)或左移(指数为负)的位数。
Mantissa: consists of 23 bits. These bits are the least significant 7 bits of byte 2 and the 8 bit bytes 3 and 4. When converting to its real value, you must add an implicit "1", as indicated below.
有效数字位:共 23 位,由字节 2 的低 7 位、字节 3 与字节 4 的全部 8 位构成。转换为真实值时需添加隐含的 1。
The implicit "1": when converting to decimal the binary value stored in memory, the mantissa must be added a "1" to the left of the binary value of 23 bits, to form the 24-bit representation.
隐含 1:将内存中的二进制值转换为十进制时,需在 23 位有效数字左侧添加 1,构成 24 位表示形式。
The binary point position: the position of the binary point that separates the integer part of the fractional part, is always after (right) the implicit "1" of the mantissa. This initial position will move to the right or left, according to the real exponent value. Please see the examples below.
二进制小数点位置:分隔整数与小数部分的二进制小数点,始终位于有效数字隐含 1 的右侧。初始位置随真实指数左移或右移,详见下方示例。
Examples:
示例:
| Decimal number 十进制数值 | Floating point format 浮点数格式 | Sign bit 符号位 | Real exponent 真实指数 | Mantissa including implicit "1" 含隐含 1 的有效数字 |
|---|---|---|---|---|
| +1.0 | 3F 80 00 00 | 0 | 7 F − 7 F = 0 7F - 7F = 0 7F−7F=0 | 1.0 ... 1.0 \ldots 1.0... |
| +2.0 | 40 00 00 00 | 0 | 80 − 7 F = + 1 80 - 7F = +1 80−7F=+1 | 10.0 ... 10.0 \ldots 10.0... |
| +3.0 | 40 40 00 00 | 0 | 80 − 7 F = + 1 80 - 7F = +1 80−7F=+1 | 11.0 ... 11.0 \ldots 11.0... |
| -3.0 | C0 40 00 00 | 1 | 80 − 7 F = + 1 80 - 7F = +1 80−7F=+1 | 11.0 ... 11.0 \ldots 11.0... |
| +0.5 | 3F 00 00 00 | 0 | 7 E − 7 F = − 1 7E - 7F = -1 7E−7F=−1 | .10 ... .10 \ldots .10... |
| +10.0 | 41 20 00 00 | 0 | 82 − 7 F = + 3 82 - 7F = +3 82−7F=+3 | 1010.0 ... 1010.0 \ldots 1010.0... |
| -100.0 | C2 C8 00 00 | 1 | 85 − 7 F = + 6 85 - 7F = +6 85−7F=+6 | 1100100.0 ... 1100100.0 \ldots 1100100.0... |
| +3.1416 | 40 49 0F F9 | 0 | 80 − 7 F = + 1 80 - 7F = +1 80−7F=+1 | 11.00100100010 ... 11.00100100010 \ldots 11.00100100010... |
| -1.25 | BF A0 00 00 | 1 | 7 F − 7 F = 0 7F - 7F = 0 7F−7F=0 | 1.010 ... 1.010 \ldots 1.010... |
| -248.75 | C3 78 C0 00 | 1 | 86 − 7 F = + 7 86 - 7F = +7 86−7F=+7 | 11111000.11000011 11111000.11000011 11111000.11000011 |
Definition of a Floating Point Variable in C:
C 语言中浮点数变量的定义:

reference
- Floating Point Demystified, Part 1
https://blog.reverberate.org/2014/09/what-every-computer-programmer-should.html - Floating Point Demystified, Part 2: Why Doesn't 0.1 + 0.2 == 0.3?
https://blog.reverberate.org/2016/02/06/floating-point-demystified-part2.html - Why your computer thinks 0.1 + 0.2 ≠ 0.3 - YouTube
https://www.youtube.com/watch?v=EjzVWL98mM4 - IEEE-754 Floating Point Representation Of Variables Mantissa Exponent Punto Flotante S.a.
https://www.puntoflotante.net/FLOATING-POINT-FORMAT-IEEE-754.htm