本章将介绍上下文工程(Context Engineering) ,并解释为什么它已经成为构建和使用现代 AI 智能体时的一个关键概念。很多 AI 系统常被描述为"不过是包了一层 Prompt 的大语言模型(LLM)",但本章会说明:随着智能体变得更复杂、运行周期更长、对工具的依赖更强,这种看法为什么会失效。你将了解到上下文从何而来、为什么它会持续增长,以及糟糕的上下文处理为何会导致性能下降、成本升高、幻觉增加,以及行为不一致。
本章的目标,是帮助你建立一个关于上下文工程的清晰心智模型,并展示它在实践中是如何落地的。我们会先解释上下文工程是如何从提示词工程(Prompt Engineering)演化而来的,然后以 Claude Code 为具体案例,说明现代智能体如何编写、选择、压缩和隔离上下文。在本章后半部分,我们还会考察系统提示词(System Prompt),分析它为什么依然重要,以及应当如何高效地设计它。
你购买本书后可获得一份免费的 PDF 副本以及代码包。
你的购买内容包括:本书的无 DRM PDF 副本、代码包,以及其他额外的专属福利。请参阅前言中的"随书附赠权益"部分,以立即解锁这些内容并最大化你的学习收益。
本章将涵盖以下主题:
- 上下文工程导论
- Claude Code 及其上下文工程理念
- 系统提示词及其重要性
本章讨论基于公开可获得的信息,包括 Anthropic 的工程博客文章以及社区分析内容。它并不代表 Anthropic 的官方声明。
上下文工程导论
在本节中,我们将讨论什么是上下文工程。现在,如果你一直在使用 AI 智能体,尤其是像 Cursor 和 Claude Code 这样的编码智能体,或者你甚至已经为自己的公司、或为个人用途开发过 AI 智能体,那么你大概率已经知道:归根到底,这一切基本上都是一个被发送给 LLM 的 Prompt,再加上围绕它的大量工程工作。
把 Cursor 和 Claude Code 这样的应用称作只是套在 LLM 外面的一层"壳",这种说法并非完全没有道理。但问题在于,想把这个"壳"做得真正优秀,需要非常深的知识积累,以及大量工程投入。另一个常被用来描述这套外围系统的术语,是 agent harness(智能体运行框架 / harness) 。这个 harness 是围绕 LLM 的编排层。它负责管理工具调用、控制智能体循环、处理错误、实施护栏(guardrails),以及最关键的一点:决定在每一步到底把哪些上下文发送给模型。
在实践中,绝大多数真正的工程工作,并不发生在那次 LLM 调用本身内部,而是发生在它的外围。模型调用通常本身很直接。真正决定一个智能体是否能可靠工作的,是外围系统如何管理状态、工具、记忆和上下文。这是因为,对 LLM 的调用永远都伴随着上下文,而这些上下文来自多种来源和持续进行的过程。
例如,上下文可能来自多个地方:
- 来自应用的开发者
- 来自用户
- 来自用户之前的交互、工具调用结果,或其他外部数据
每天都会有新的上下文来源被加入进来,而上下文的总量也在不断增长。将正确且相关的上下文发送给 LLM,远没有早期人们想象的那么简单。
从提示词工程到上下文工程
在早期,我们曾经以为提示词工程就已经足够了。我们以为,只要写出一些漂亮的 Prompt,就能修复问题并得到我们想要的结果。然而问题在于,Prompt 是静态的,而上下文却是极其动态的。
如果上下文是动态的,那么构造正确上下文这件事,也就需要一个动态系统来完成。它已经不再只是"写一个静态 Prompt"这么简单了。这正是我们进入上下文工程领域的原因。它是提示词工程的自然演进,但它本身是一个更深层次的概念。
为什么上下文对智能体如此重要
我们都知道一句老话:garbage in, garbage out(垃圾进,垃圾出) 。这正是很多 agentic system(智能体系统)表现不如预期的最常见原因之一:它们根本没有拿到正确的上下文。
LLM 并不会读心术。我们必须为它提供正确的信息。顺便说一句,这里说的并不总只是"信息"或"数据"。有时候,我们还需要给它正确的工具,让它能够去获取其他信息、执行操作,并替我们完成任务。
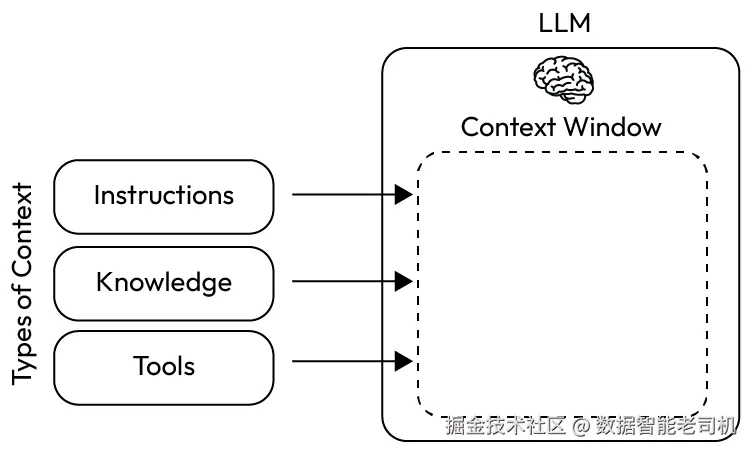
图 1.1 ------ LLM 上下文窗口 (改编自 LangChain 讨论的相关概念,www.langchain.com)
LLM 的推理能力正在变得越来越强。现在我们已经有了工具调用(tool calling)能力,也可以构建能够运行工具、调用它们、获取输出并循环执行直到任务完成的 AI 智能体。
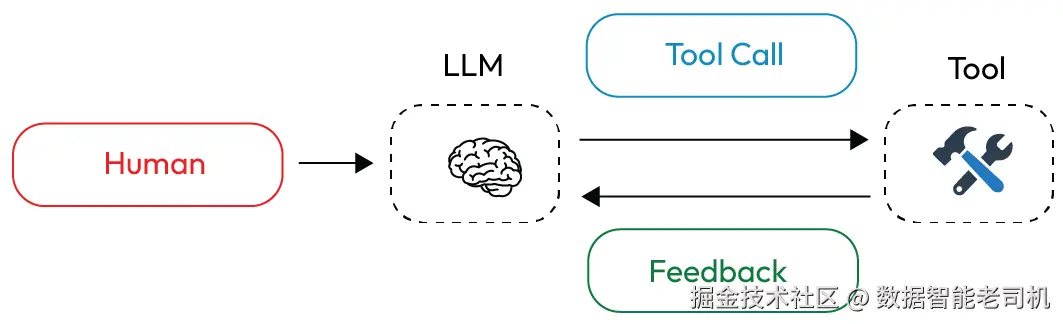
图 1.2 ------ LLM 工具调用循环 (改编自 LangChain 讨论的相关概念,www.langchain.com)
然而,一旦任务变得复杂且运行时间较长,我们往往会不断积累来自工具调用的反馈结果。
这会导致上下文窗口不断膨胀,里面塞满了工具调用结果和中间输出。
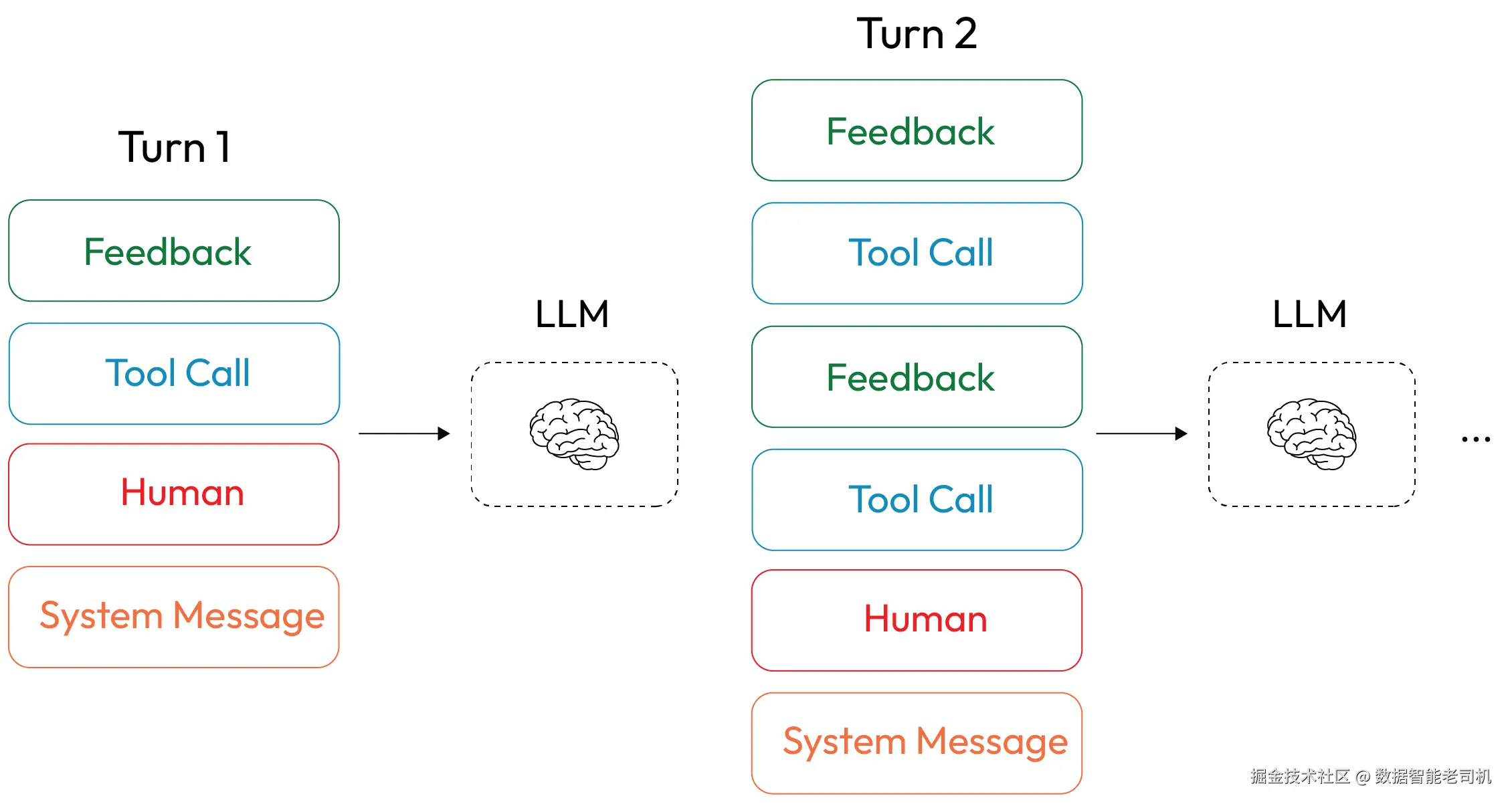
图 1.3 ------ 多轮交互中的上下文增长 (改编自 LangChain 讨论的相关概念,www.langchain.com)
这会带来若干问题:
- 上下文窗口可能超出其容量上限
- 成本和延迟上升
- 智能体性能开始下降
如果不采取任何措施,这种退化几乎是不可避免的。近期已经有不少讨论在研究:为什么长上下文在实践中会失效,以及这种性能退化是如何随着无关信息或冲突信息不断积累而逐步出现的。若想深入了解,可参考 Dan Breunig 的那篇精彩博客《How Long Contexts》(www.dbreunig.com/2025/06/22/...)。如果让上下文在没有结构、没有筛选、没有控制的情况下持续增长,那么智能体系统中就会开始出现各种问题,例如:
- 上下文污染(Context poisoning) :某次工具调用或 LLM 调用产生的幻觉信息被带入上下文,并开始影响后续输出
- 上下文混淆(Context confusion) :不必要的上下文对响应产生了影响,尽管它与当前任务其实并不相关
- 上下文冲突(Context clash) :上下文的不同部分彼此矛盾
在下一节中,我们将讨论更好的上下文工程技术。其中一些技术由应用开发者来实现,比如在 Claude Code 这样的工具中。还有一些技术则掌握在用户自己手中。
作为 Claude Code 的用户,我们其实对最终发送给 LLM 的上下文、以及因此得到的回答,有很大的影响力。这意味着:即便不是开发者,如果你想从 AI 系统和 AI 智能体那里获得更好的响应,也同样需要理解上下文工程。
像 Claude Code 这样的编码智能体,就是一个非常典型的例子,它展示了上下文工程技术如何同时作用在开发者侧和用户侧。这也正是我们下一节要讨论的重点,以及我们应当如何更好地设计自己的上下文。
Claude Code 及其上下文工程策略
在本节中,我们会讨论 Claude Code、它的上下文工程理念,以及 Claude Code 是如何应对这些挑战的。Claude Code 通过实现以下四种方法来落地这些上下文工程策略:
- Write Context:写入上下文------持久化记忆系统
- Select Context:选择上下文------智能的上下文检索与注入
- Compress Context:压缩上下文------高效的上下文表达与摘要
- Isolate Context:隔离上下文------多智能体与作用域化上下文管理
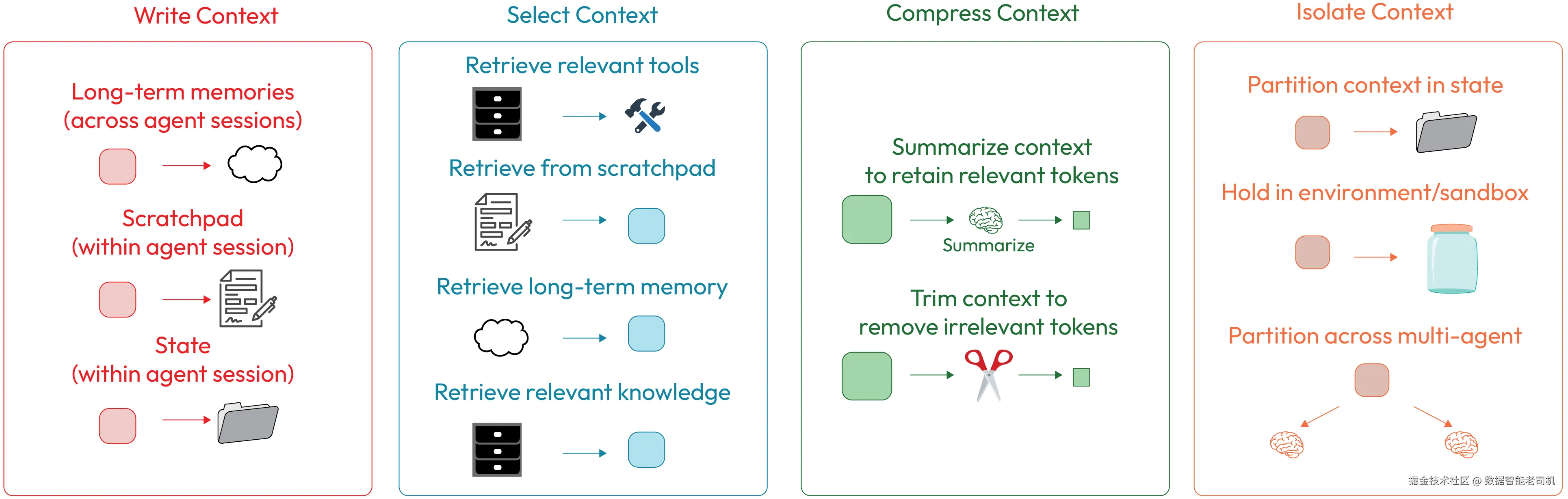
图 1.4 ------ 上下文工程的分类 (改编自 LangChain 讨论的相关概念,www.langchain.com)
我们先从第一种开始。
策略 1:写入上下文与持久化记忆
第一种策略是写入上下文(writing context)及其持久化记忆架构(persistent memory architecture) 。Claude 拥有一个多层记忆系统,而 Claude Code 则实现了一个三层记忆层级结构,用来在使用 Claude Code 编码的过程中跨会话持久保存上下文。
首先是项目记忆(project memory) ,也就是 ./CLAUDE.md。这是一种团队共享的上下文,适合存放项目架构、团队规范,或任何与特定项目相关的内容。这类记忆通常会被纳入版本控制,对所有团队成员可见。
markdown
# Project Context
## Architecture Overview
This is a microservices application using:
- Node.js with Express for API services
- React with TypeScript for frontend
- PostgreSQL with Prisma ORM
- Redis for caching
## Coding Standards
- Use functional components with hooks
- Implement error boundaries for all route components
- Follow RESTful API conventions
- Write unit tests for all business logic接着是用户记忆(user memory) ,即 ~/.claude/CLAUDE.md。它存放在用户主目录下的 claude 目录中,具体文件是 CLAUDE.md。这里保存的是这个用户跨所有项目共享的个人偏好和快捷习惯。它不会被提交到 GitHub,是用户私有的。每个用户这里的内容都可能不同,并且它会在所有 Claude Code 会话之间持续保留。
markdown
# Personal Development Preferences
## Code Style
- Always use explicit return types in TypeScript
- Prefer const assertions over type annotations
- Use descriptive variable names, avoid abbreviations
## Workflow Shortcuts
- When writing tests, use Jest with React Testing Library
- Always run
`npm run lint`
before commits
- Prefer composition over inheritance最后是动态记忆导入(dynamic memory imports) 。它允许我们使用 @ 符号及相应语法,从其他记忆文件中导入内容。这与向 Claude Code 加载普通上下文有些类似,但区别在于:现在我们可以拥有专门的记忆文件,把特定信息放进去,然后在记忆文件内部进行引用。
bash
# In any CLAUDE.md file
@path/to/memory/file.md
@./relative/path/context.md
@~/global/user/context.md我们还可以通过编写脚本,根据 Git 分支动态更新上下文,从而定制行为。然后再把这个脚本连接到一个上下文切换 hook 上,以构建更具适应性的工作流。
这里有一个很重要的细节需要注意:我们应当避免反复把同样的上下文引用追加到 CLAUDE.md 中。如果脚本每次执行时都只是简单地使用 >> 追加,那么文件就会无限增长,并充满重复条目。为了防止这种情况,我们需要加一个小的保护逻辑:在追加之前,先检查某个上下文引用是否已经存在。
下面是一个改进后的脚本版本,它可以避免重复导入:
bash
# Script to dynamically update context based on git branch
#!/bin/bash
# context-switcher.sh
# Dynamically load relevant context based on user query
# Safe against duplicate imports
CLAUDE_MD="CLAUDE.md"
# Create CLAUDE.md if it doesn't exist
touch "$CLAUDE_MD"
add_context() {
local context_ref="$1"
grep -qxF "$context_ref" "$CLAUDE_MD" || echo "$context_ref" >> "$CLAUDE_MD"
}
# --- Branch-based context ---
branch=$(git branch --show-current 2>/dev/null)
case $branch in
"feature/auth-"*)
add_context "@./context/auth-system.md"
;;
"feature/payment-"*)
add_context "@./context/payment-flow.md"
;;
"hotfix/"*)
add_context "@./context/production-hotfix.md"
;;
esac
# --- Query-based context ---
user_input="$1"
if [[ -n "$user_input" ]]; then
if [[ $user_input == *"database"* || $user_input == *"migration"* ]]; then
add_context "@./context/database-context.md"
elif [[ $user_input == *"API"* || $user_input == *"endpoint"* ]]; then
add_context "@./context/api-context.md"
elif [[ $user_input == *"frontend"* || $user_input == *"component"* ]]; then
add_context "@./context/frontend-context.md"
fi
fi这里的关键变化是 add_context 这个辅助函数。它使用 grep -qxF 来检查某个上下文引用是否已经存在于 CLAUDE.md 中。如果已经存在,就不会重复追加。这样一来,这个脚本就是幂等的(idempotent) ,可以安全地在每次 Prompt 提交时执行。
然后我们再把这个脚本连接到一个 hook 上:
bash
{
"hooks": {
"UserPromptSubmit": {
"command": "./scripts/context-switcher.sh "$PROMPT""
"description": "Dynamically load relevant context based on
branch and user query"
}
}
}通过这套机制,上下文切换就变成了动态的,同时又能够随着时间推移保持稳定。
策略 2:智能上下文检索
第二种策略是智能上下文检索(intelligent context retrieval) ,它通常通过动态上下文发现(dynamic context discovery) 来实现。
Claude 会自动浏览文件夹,寻找有帮助的上下文文件。如果我们当前位于某个子文件夹中,它也会从父级文件夹中拉取上下文,但当更具体的信息存在时,它会优先使用更具体的内容。它还会优先考虑最近使用过、以及被频繁访问的信息。
这属于应用层面的上下文工程,这部分逻辑是由 Claude Code 的开发者实现的。不过,用户也可以通过 /memory 命令自行添加持久化上下文。例如:
bash
/memory add Always use descriptive variable namesClaude 会进一步询问,这条记忆应当被存储在项目级别还是用户级别,然后自动更新对应的 CLAUDE.md 文件。这样一来,用户就可以在不手工编辑上下文文件的情况下,影响 Claude 未来的行为。
根据所使用的工具不同,传播给 LLM 的上下文也会不同。比如,当 Claude Code 即将编辑一个文件时,它会自动记住一些和编辑工具相关的信息,比如:先检查现有代码风格、在创建新函数之前先寻找已有函数等。这些就是与编辑工具最相关的上下文。
再比如,当 Claude Code 即将运行一个终端命令时,它会记住另一类上下文,例如:先检查是否已有现成的 npm script 可用,再决定是否执行命令;又或者先确认文件路径存在,再进行执行。
策略 3:压缩上下文
第三种策略是压缩上下文(compression of context) ,重点在于更高效地表示上下文。Claude Code 内置了上下文压缩命令。
/clear 命令会重置当前上下文窗口中的对话历史,但会保留底层的项目记忆和用户记忆。当当前对话已经朝着一个无益方向发展,或者你希望重新开始一次全新的交互、但又不想丢掉系统已经学到的项目知识时,这个命令就会非常有用。
/compact 命令则会把现有对话压缩总结成一个更短的形式。它不是把所有内容都丢掉,而是保留关键决策和重要信息,同时舍弃次要细节。这样压缩后的历史会占用更少的上下文窗口,进而降低成本与延迟,并为模型留出更多空间来处理新的输入。
策略 4:通过子智能体进行上下文隔离
第四种策略是上下文隔离(context isolation) 。为此,Claude Code 使用了子智能体(sub-agents) 。每个子智能体都运行在自己独立隔离的上下文窗口中,并不会继承主智能体的完整对话历史。这个策略的核心,在于为不同任务创建不同的 Claude Code 专家版本,每个版本都拥有自己聚焦的知识范围。
与其让 Claude Code 一次性带着所有信息去处理所有事情,不如创建专门的子智能体,让它们分别成为某个领域的专家。我们可以有一个主 Claude 智能体,作为管理者来分派任务;还可以有一个代码审查智能体,专注于代码质量与安全;一个测试智能体,专注于编写和运行测试;以及一个研究智能体,专注于查找信息和最佳实践。示例如下:
less
// Code review agent -- focused context
Task(
description: "Code review",
prompt: "Review this PR focusing only on security and performance",
subagent_type: "code-reviewer"
)
// Research agent -- broad context
Task(
description: "Research implementation",
prompt: "Find best practices for OAuth2 implementation",
subagent_type: "general-purpose"
)这样做的好处在于:如果不进行隔离,Claude Code 往往会因为试图一次性处理所有事情、并同时考虑所有可能信息而陷入混乱。而通过隔离,每个专家型子智能体都有明确的知识边界,并能在自己的职责范围内高效完成工作。
需要说明的是,上述语法只是为了演示而做的说明性简化示例。Claude Code 当前并不真正使用这种精确格式。实际情况下,定义子智能体需要借助带有 frontmatter 的 YAML 配置文件,我们会在本书后面的章节中进一步介绍。
系统提示词及其重要性
在这一节中,我们将讨论系统提示词,以及它们在上下文工程中的重要性。你大概已经在 X 和 LinkedIn 上看过成千上万次类似的说法:系统提示词很重要,你应该认真打磨它们、不断迭代它们、把它们做得非常好。说一句"你得有个好的 system prompt",大概已经成了 AI 工程里最泛泛而谈的建议之一。
目前已经有一些公共仓库,专门收集知名 AI 智能体所使用的系统提示词示例。这些仓库通常会汇总那些已经在公开来源中被分享或讨论过的 Prompt。很多示例都聚焦于像 Claude Code、Cursor 和 Devin 这样的编码智能体,但其中也可能包含来自其他智能体型系统的提示词。
这里引用这些仓库的目的,并不是为了验证每一个 Prompt 的真实性,而是为了说明:在实践中,系统提示词往往确实是体量庞大、结构化强、经过精心工程化设计的。
本节的目标也不是逐条分析每一个 Prompt,或解释其中每一种技巧。光是系统提示词这个主题,本身就足以写成一本完整的书,或单独开一门课程。
我在这里真正想表达的是:系统提示词确实重要。 系统提示词在持续演化。随着 LLM 的演进,系统提示词也在一起演进。为了打磨这些 Prompt,让它们越来越好,背后投入了大量工程努力。这是一个持续迭代的过程。
设计系统提示词的最佳实践
现在我们来谈一些在整理和设计系统提示词时的最佳实践。你可以把它理解成"给别人指路"。
如果我们只说一句"往那边走",对方一定会困惑,因为他根本不知道该去哪里。但如果我们给他一本 50 页厚的说明书,把每一个可能的转弯和街道都写进去,那么信息又会多到让人不堪重负,最后他依然未必能到达目标地点。
所以,我们想要做到的是:表达清楚、足够具体,并且提供恰到好处的信息,让对方能顺利到达目标。最难的地方,正是在于找到那个"刚刚好"的平衡点。
系统提示词的"金发姑娘区"(Goldilocks Zone)
在编写系统提示词时,我们追求的是 Anthropic 所说的 Goldilocks zone(金发姑娘区) :既不过于模糊,也不过于细碎,而是恰到好处。
你可以把它想象成一条刻度线。最左边,是那些过于具体的 Prompt;最右边,是那些过于模糊的 Prompt。我们真正想要的,是正中间那个位置。

图 1.5 ------ 系统提示词的 Goldilocks Zone (来源:Anthropic,《Effective Context Engineering for AI Agents》,www.anthropic.com/engineering...
我们来把它拆开看。
过于具体的提示词有什么问题
在最左侧,我们面对的是非常具体的 Prompt。这里的核心问题在于:我们把 LLM 当成了一个确定性的状态机(deterministic state machine) ,而不是一个智能体。我们在硬编码逻辑。
例如,我们可能会写:如果用户的意图是事故处理(incident resolution),那就追问三个后续问题。可为什么偏偏是三个?如果两个就够了怎么办?如果需要五个呢?
我们还会看到一种现象:穷举式枚举。也就是试图把所有可能的升级处理场景全都列出来。这件事实际上是不可能做完的,而且它会强迫模型沿着预设路径运行,即便这些路径和真实输入并不匹配。与此同时,这也会带来可维护性的噩梦:每出现一个新的边界情况,你都得去改 Prompt。
到了那个地步,如果一切都已经被预先决定好了,那我们甚至可能根本不需要一个自主智能体。一个确定性的工作流,可能就已经足够。
过于模糊的提示词有什么问题
而在光谱的另一端,我们看到的是非常模糊的 Prompt。它的核心问题是:它没有为模型提供足够的信号,无法支撑一致性的行为。
在这种 Prompt 里,我们经常会看到缺乏可执行指导的情况。比如,考虑下面这个例子:
你是一名面包店助手。你应当按照公司品牌的原则和精神来帮助顾客解决问题。如有需要,请升级给人工处理。
问题是:这些"原则"到底是什么?
这里还存在一种错误假设:它默认模型与我们共享相同背景。这个 Prompt 假设模型知道公司是什么、品牌是什么、客户服务规范是什么,但事实并非如此。
我们还会看到边界不清的问题,比如"如有需要,请升级给人工处理"。那到底什么情况下算"有需要"?模型根本无从判断。
它也没有为模型提供一个系统性处理问题的框架或结构。这就会导致行为不一致:面对同一个问题,不同次运行可能会采取截然不同的处理方式。归根到底,这类 Prompt 本质上只是在说一句"做正确的事",却并没有定义"正确"到底是什么。
一个好的中间态 Prompt 长什么样
现在我们来看中间地带。请看下面这个例子:
你是 Claude's Bakery 的客户支持专员。
你专门帮助顾客处理订单问题以及关于面包店的基础咨询。请使用你可用的工具,高效且专业地解决问题。
你可以访问订单管理系统、商品目录和门店政策。你的目标是在可能的情况下尽快解决问题。在提出解决方案之前,先完整理解当前情况;如果你还没有弄清楚,就继续追问。
响应框架:
- 识别核心问题 ------ 不要停留在表层抱怨上,要理解顾客真正需要的是什么
- 收集必要上下文 ------ 在回复之前,使用可用工具核实订单详情、检查库存或查看政策
- 提供清晰解决方案 ------ 给出具体的后续步骤和现实可行的时间预期
- 确认顾客满意度 ------ 确保顾客理解了解决方案,并知道后续该如何跟进
指导原则:
- 当存在多个解决方案时,选择那个最简单且能完整解决问题的方案
- 如果用户提到订单,在建议下一步之前先检查订单状态
- 调用人工协助工具
- 对于法律问题、健康/过敏紧急情况,或涉及超出标准政策范围的财务调整场景,应调用人工协助工具
- 对用户语气中的挫败感或紧迫感予以识别,并用恰当的同理心进行回应
你可以看到:
这里首先给出了一个清晰的身份和职责边界。这会立刻建立范围:它是做客户支持,不是做市场营销,也不是做销售;它处理订单和基础咨询,而不是复杂的业务运营问题。
其次,这种 Prompt 是在赋能模型,而不是束缚模型。它并没有规定在每一种情形下都必须使用哪个工具,而是定义了一个目标------比如高效且专业地解决问题。这里的启发式思路是:我们信任智能体能够在需要时选择合适的工具。
我们给出的也不是一个死板的流程图,而是一个推理框架。这里使用了一个四步响应框架:识别核心问题、收集必要上下文、提供清晰解决方案、确认顾客满意度。这样的框架能够适用于各种不同场景,而不是刚性分支逻辑。
最后,我们还明确建立了边界和原则。比如:如果有多个解决方案,就选最简单的那个。这是一条启发式原则,而不是硬规则,它有点类似计算机科学里的贪心策略。
过于具体的 Prompt 试图替 LLM 完成思考,一旦现实情况不符合预设脚本,它就会崩溃。过于模糊的 Prompt 则没有给 LLM 足够的抓手去开展工作。
而居中的 Prompt,恰恰利用了现代 LLM 最擅长的事情:识别模式,并把一般原则应用到具体情境中。
它之所以能较好地处理新情况,是因为它教给模型的是原则,而不是规则。它之所以高效,是因为它不浪费字数。每一条指导都能覆盖大量场景。这些原则是被压缩过的,不存在重叠或相互矛盾的指令。
总结
在本章中,我们介绍了上下文工程,并解释了为什么它对于构建可靠且可扩展的 AI 智能体至关重要。我们分析了上下文与静态 Prompt 的差异、上下文从何而来,以及为什么失控的上下文会导致性能退化、幻觉和行为不一致等问题。
以 Claude Code 为实际案例,我们探讨了四种核心的上下文工程策略:通过持久化记忆来写入上下文、动态选择相关上下文、通过压缩来控制上下文规模,以及利用专门化子智能体实现上下文隔离。我们还讨论了系统提示词的作用,并说明高质量的 Prompt 应当在"过于刚性"和"过于模糊"之间取得平衡。
到这里,你应该已经对现代 AI 智能体是如何管理上下文的,以及开发者和用户分别如何影响这种行为,有了一个整体认识。在下一章中,我们会在这个基础之上继续深入,开始接触更高级的 agentic workflow(智能体工作流),并借助 HookHub 项目来探索 Claude Code 如何协调任务、管理上下文,以及如何超越简单的单步交互来运行。
在下一章中,我们还将进一步考察 Claude Code,以及它是如何与一个代码库进行交互的。